Lung X-ray Segmentation using Deep Convolutional Neural Networks on Contrast-Enhanced Binarized Images



Abstract
:1. Introduction
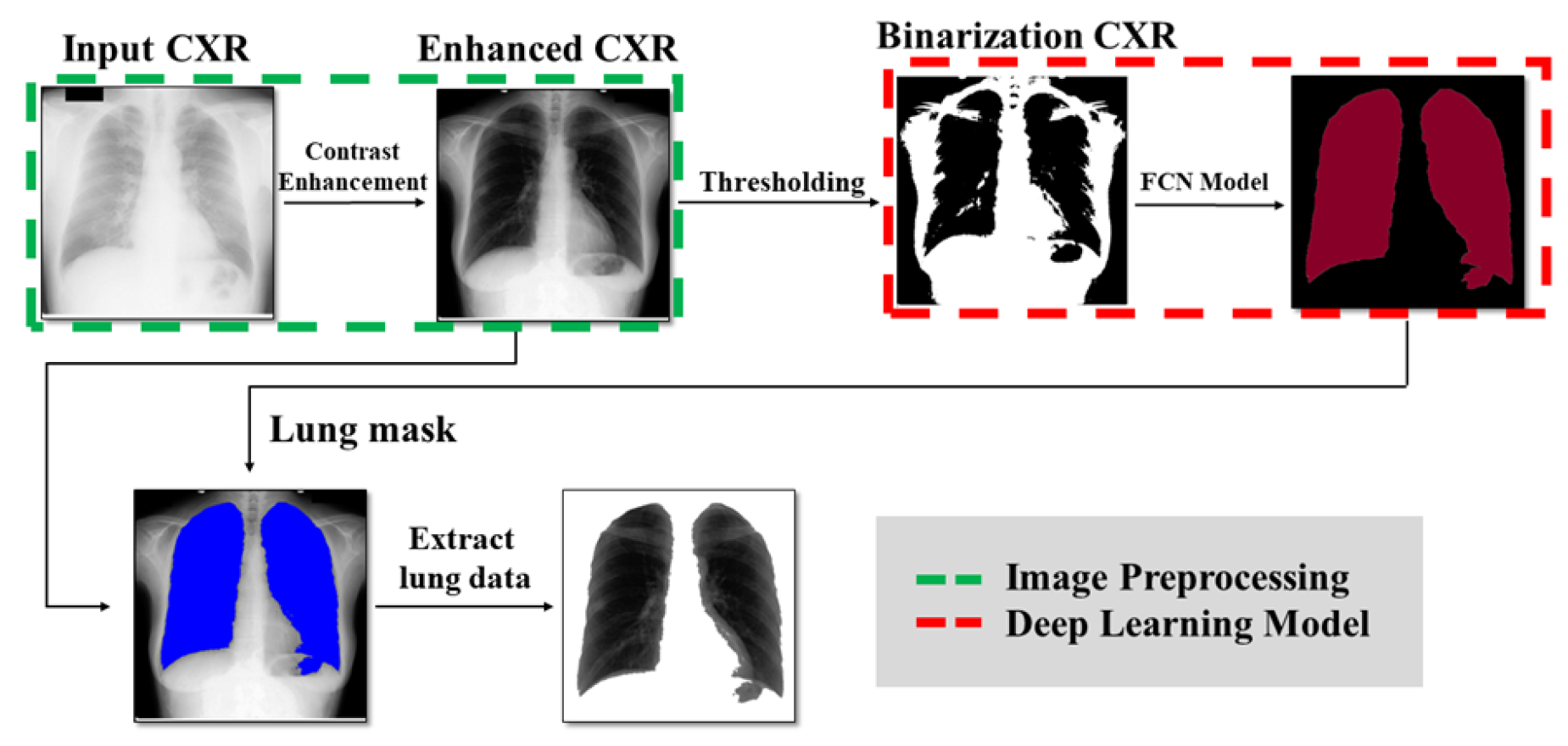
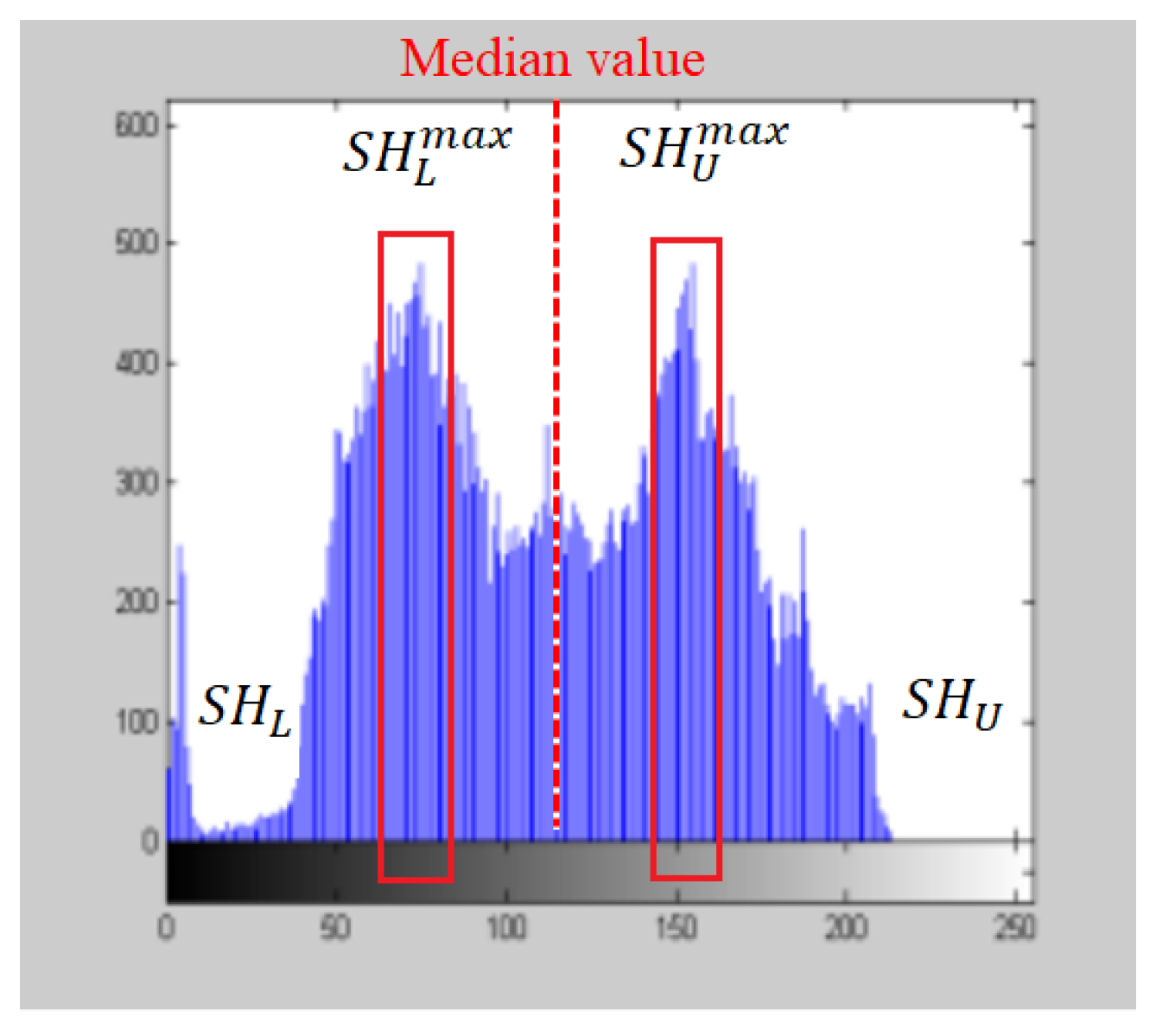
- The confined-region-based histogram equalization method is applied to CXR images for increasing the difference (contrast) between the lungs and their surrounding regions (both bony structures and other soft tissues), which is proven to increase accuracy based on the experimental results.
- The grayscale CXR images are transformed into binary images based on the adaptive binarization method, which can reduce of the storage space usage with only a slight drop in prediction accuracy ().
- We verify and compare performance of the proposed method for the lung segmentation task using various convolutional-neural-network-based models that are actively adopted for semantic segmentation, especially for lung segmentation [14], including Fully Convolutional neural Networks (FCNs) [11], U-net [12], and SegNet [13], using the preprocessed CXR datasets. The experimental results revealed that the proposed pre-processing steps could make the model training process faster while maintaining comparable segmentation accuracy compared to those of the state-of-the-art method.
2. Related Work
2.1. CXR Contrast Enhancement
2.2. Image Binarization
2.3. Lung Segmentation
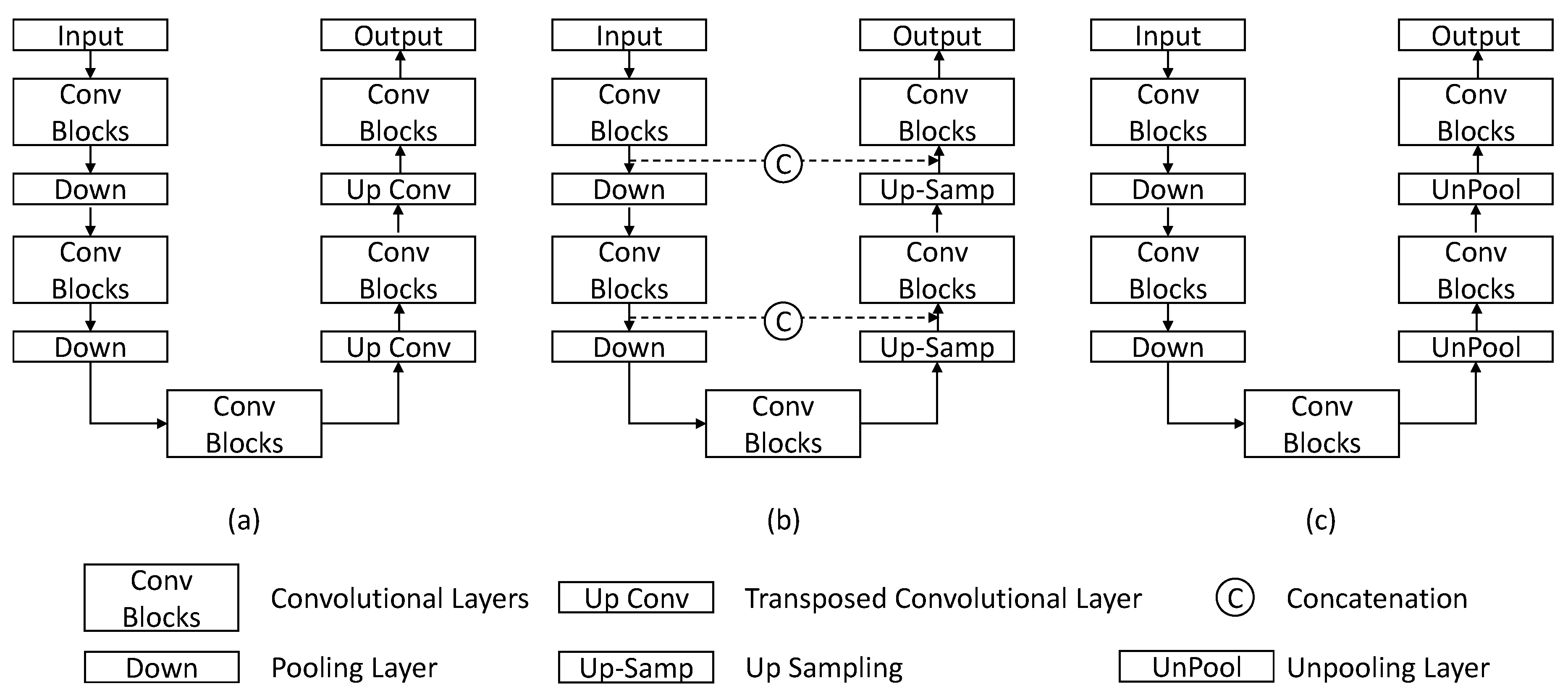
2.4. Common Convolutional Neural Network Models for Segmentation
3. Proposed Method
3.1. Contrast Enhancement with Confined-Region-Based HE
3.2. Image Binarization
3.3. Image Segmentation Based on Deep Neural Networks
4. Experimental Results
4.1. Chest X-ray Datasets
- Japan Society of Radiology Technology (JSRT) dataset, which contains manually-annotated segmentation labels of lung fields, heart, and clavicles. The JSRT dataset contains 154 nodule-containing digital CXR images (100 malignant cases, 54 benign cases) and 93 normal digital images [43]. The images are grayscale with their bit depth of 12. The size of the images is . Both the vertical and horizontal pixel spacing is mm.
- The Department of Health and Human Services of Maryland (Montgomery dataset) collected X-ray images over many years under Montgomery County’s Tuberculosis Control scheme. The dataset consists of 58 digital CXR images with manifestations of tuberculosis and 80 normal digital CXR images [44]. The X-ray images are 12-bit grayscale images, and their size is with mm pixel resolution.
- The dataset from a private clinic in India includes 397 chest X-rays with resolutions of , , and . They are all 12-bit grayscale images. The vertical and horizontal pixel spacing are both mm.
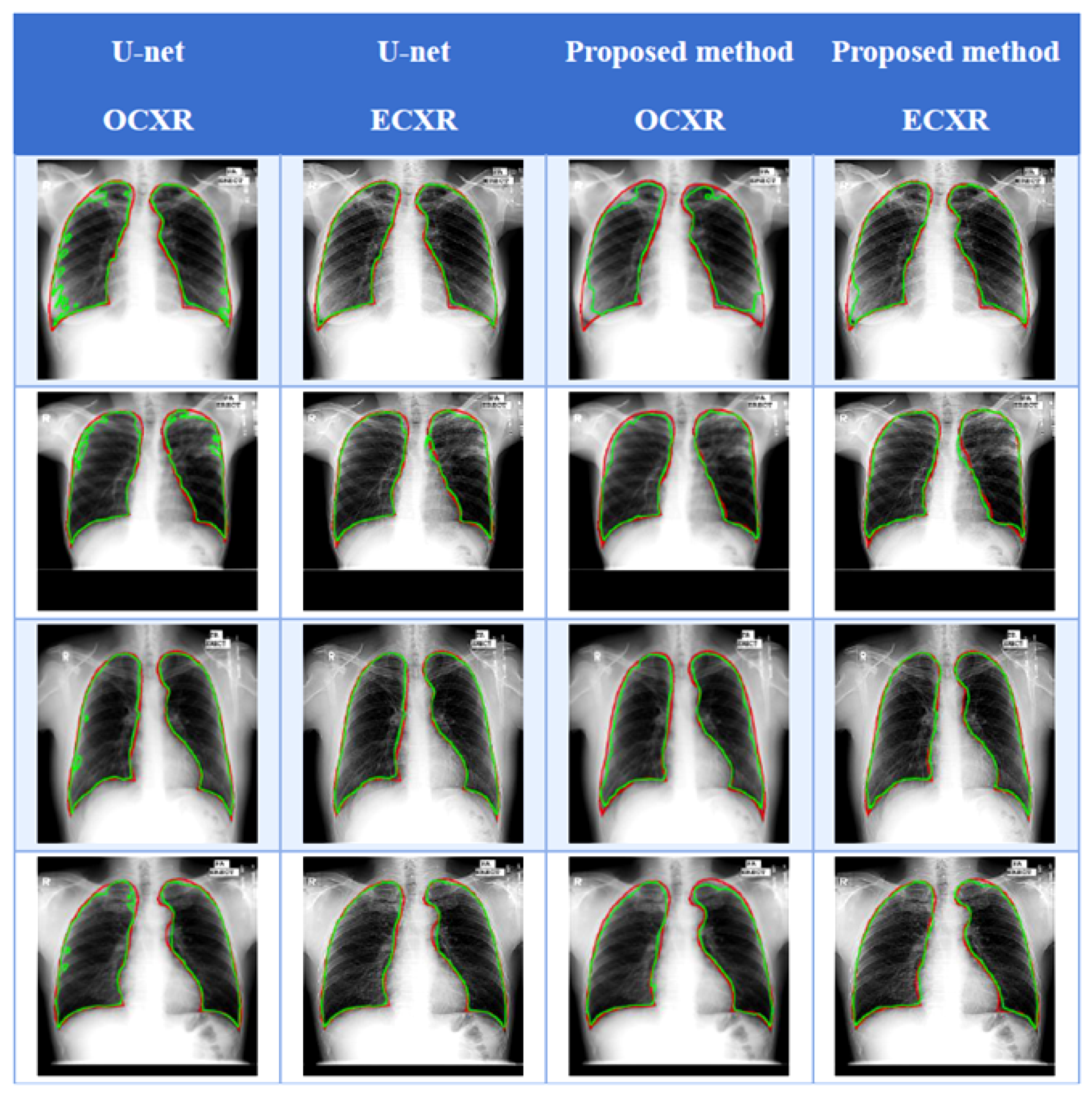
4.2. Object Evaluation
4.3. Convergence Rate
5. Conclusions
Author Contributions
Funding
Conflicts of Interest
Abbreviations
| CLAHE | Contrast Limited Adaptive Histogram Equalization |
| CXR | Chest X-ray |
| ASM | Active Shape Model |
| AAM | Active Appearance Model |
| FCN | Fully Convolutional neural Network |
| CAD | Computer-Aided Diagnosis |
| TB | Tuberculosis |
| CNN | Convolutional Neural Network |
| FCN | Fully Convolutional Network |
| HE | Histogram Equalization |
| JSRT | Japan Society of Radiology Technology |
| OCXR | Original Chest X-ray |
| ECXR | Enhanced Chest X-ray |
| BOCXR | Binarized OCXR |
| BECXR | Binarized ECXR |
| MAE | Mean Absolute Error |
References
- Kligerman, S.; Cai, L.; White, C.S. The effect of computer-aided detection on radiologist performance in the detection of lung cancers previously missed on a chest radiograph. J. Thorac. Imaging 2013, 28, 244–252. [Google Scholar] [CrossRef] [PubMed]
- Cecil, R.L.F.; Goldman, L.; Schafer, A.I. Goldman’s Cecil Medicine, Expert Consult Premium Edition–Enhanced Online Features and Print, Single Volume, 24: Goldman’s Cecil Medicine; Elsevier Health Sciences: Amsterdam, The Netherlands, 2012. [Google Scholar]
- Mazzone, P.J.; Obuchowski, N.; Phillips, M.; Risius, B.; Bazerbashi, B.; Meziane, M. Lung cancer screening with computer aided detection chest radiography: design and results of a randomized, controlled trial. PLoS ONE 2013, 8, e59650. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Candemir, S.; Jaeger, S.; Palaniappan, K.; Musco, J.P.; Singh, R.K.; Xue, Z.; Karargyris, A.; Antani, S.; Thoma, G.; McDonald, C.J. Lung segmentation in chest radiographs using anatomical atlases with nonrigid registration. IEEE Trans. Med. Imaging 2013, 33, 577–590. [Google Scholar] [CrossRef] [PubMed]
- Chondro, P.; Yao, C.Y.; Ruan, S.J.; Chien, L.C. Low order adaptive region growing for lung segmentation on plain chest radiographs. Neurocomputing 2018, 275, 1002–1011. [Google Scholar] [CrossRef]
- LeCun, Y.; Bottou, L.; Bengio, Y.; Haffner, P. Gradient-based learning applied to document recognition. Proc. IEEE 1998, 86, 2278–2324. [Google Scholar] [CrossRef] [Green Version]
- Krizhevsky, A.; Sutskever, I.; Hinton, G.E. Imagenet classification with deep convolutional neural networks. In Proceedings of the Advances in Neural Information Processing Systems 25 (NIPS 2012), Lake Tahoe, NV, USA, 3–6 December 2012. [Google Scholar]
- Simonyan, K.; Zisserman, A. Very deep convolutional networks for large-scale image recognition. arXiv 2014, arXiv:1409.1556. [Google Scholar]
- Szegedy, C.; Liu, W.; Jia, Y.; Sermanet, P.; Reed, S.; Anguelov, D.; Erhan, D.; Vanhoucke, V.; Rabinovich, A. Going deeper with convolutions. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition 2015, Boston, MA, USA, 7–12 June 2015. [Google Scholar]
- Zeiler, M.D.; Fergus, R. Visualizing and understanding convolutional networks. In Proceedings of the European Conference on Computer Vision 2014, Zurich, Switzerland, 6–12 September 2014; Springer: Berlin/Heidelberg, Germany, 2014. [Google Scholar]
- Long, J.; Shelhamer, E.; Darrell, T. Fully convolutional networks for semantic segmentation. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition 2015, Boston, MA, USA, 7–12 June 2015. [Google Scholar]
- Ronneberger, O.; Fischer, P.; Brox, T. U-net: Convolutional networks for biomedical image segmentation. In Proceedings of the International Conference on Medical Image Computing And Computer-Assisted Intervention, Munich, Germany, 5–9 October 2015; Springer: Berlin/Heidelberg, Germany, 2015. [Google Scholar]
- Badrinarayanan, V.; Kendall, A.; Cipolla, R. Segnet: A deep convolutional encoder-decoder architecture for image segmentation. IEEE Trans. Pattern Anal. Mach. Intell. 2017, 39, 2481–2495. [Google Scholar] [CrossRef]
- Hooda, R.; Mittal, A.; Sofat, S. An efficient variant of fully-convolutional network for segmenting lung fields from chest radiographs. Wirel. Pers. Commun. 2018, 101, 1559–1579. [Google Scholar] [CrossRef]
- Parveen, N.R.S.; Sathik, M.M. Enhancement of bone fracture images by equalization methods. In Proceedings of the 2009 International Conference on Computer Technology and Development, Kota Kinabalu, Malaysia, 13–15 November 2009; Volume 2, pp. 391–394. [Google Scholar]
- Ahmad, S.A.; Taib, M.N.; Khalid, N.E.A.; Taib, H. An analysis of image enhancement techniques for dental X-ray image interpretation. Int. J. Mach. Learn. Comput. 2012, 2, 292. [Google Scholar] [CrossRef] [Green Version]
- Mustapha, A.; Hussain, A.; Samad, S.A. A new approach for noise reduction in spine radiograph images using a non-linear contrast adjustment scheme based adaptive factor. Sci. Res. Essays 2011, 6, 4246–4258. [Google Scholar]
- Patin, F. An Introduction to Digital Image Processing. 2003. Available online: https://pdfhall.com/an-introduction-to-digital-image-processing-fr_5b221dea097c47246a8b460a.html (accessed on 20 August 2019).
- Sauvola, J.; Pietikäinen, M. Adaptive document image binarization. Pattern Recognit. 2000, 33, 225–236. [Google Scholar] [CrossRef] [Green Version]
- Otsu, N. A threshold selection method from gray-level histograms. IEEE Trans. Syst. Man Cybern. 1979, 9, 62–66. [Google Scholar] [CrossRef] [Green Version]
- Ridler, T.; Calvard, S. Picture thresholding using an iterative selection method. IEEE Trans. Syst. Man Cybern. 1978, 8, 630–632. [Google Scholar]
- Reeves, A.P.; Kostis, W.J. Computer-aided diagnosis of small pulmonary nodules. In Seminars in Ultrasound, CT and MRI; Elsevier: Amsterdam, The Netherlands, 2000. [Google Scholar]
- Li, L.; Zheng, Y.; Kallergi, M.; Clark, R.A. Improved method for automatic identification of lung regions on chest radiographs. Acad. Radiol. 2001, 8, 629–638. [Google Scholar] [CrossRef]
- Toriwaki, J.; Ji, T.; Ji, H. Computer analysis of chest photofluorograms and its application to automated screening. Iyō denshi to seitai kōgaku. Jpn. J. Med Electron. Biol. Eng. 1980, 3, 63–81. [Google Scholar]
- Yue, Z.; Goshtasby, A.; Ackerman, L.V. Automatic detection of rib borders in chest radiographs. IEEE Trans. Med. Imaging 1995, 14, 525–536. [Google Scholar] [PubMed]
- Annangi, P.; Thiruvenkadam, S.; Raja, A.; Xu, H.; Sun, X.; Mao, L. A region based active contour method for X-ray lung segmentation using prior shape and low level features. In Proceedings of the 2010 IEEE International Symposium on Biomedical Imaging: From Nano to Macro, Rotterdam, The Netherlands, 14–17 April 2010. [Google Scholar]
- Van Ginneken, B.; Stegmann, M.B.; Loog, M. Segmentation of anatomical structures in chest radiographs using supervised methods: A comparative study on a public database. Med. Image Anal. 2006, 10, 19–40. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Loog, M.; Ginneken, B. Segmentation of the posterior ribs in chest radiographs using iterated contextual pixel classification. IEEE Trans. Med. Imaging 2006, 25, 602–611. [Google Scholar] [CrossRef] [PubMed]
- Loog, M.; van Ginneken, B. Supervised segmentation by iterated contextual pixel classification. In Proceedings of the Object Recognition Supported by User Interaction for Service Robots, Quebec City, QC, Canada, 11–15 August 2002. [Google Scholar]
- Redmon, J.; Divvala, S.; Girshick, R.; Farhadi, A. You only look once: Unified, real-time object detection. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, CVPR 2016, Las Vegas, NV, USA, 26 June–1 July 2016. [Google Scholar]
- Liu, W.; Anguelov, D.; Erhan, D.; Szegedy, C.; Reed, S.; Fu, C.Y.; Berg, A.C. Ssd: Single shot multibox detector. In Proceedings of the European Conference on Computer Vision, ECCV 2016, Amsterdam, The Netherlands, 11–14 October 2016; Springer: Berlin/Heidelberg, Germany, 2016. [Google Scholar]
- Suzuki, K.; Abe, H.; MacMahon, H.; Doi, K. Image-processing technique for suppressing ribs in chest radiographs by means of massive training artificial neural network (MTANN). IEEE Trans. Med. Imaging 2006, 25, 406–416. [Google Scholar] [CrossRef] [Green Version]
- Cootes, T.F.; Taylor, C.J.; Cooper, D.H.; Graham, J. Active shape models-their training and application. Comput. Vis. Image Underst. 1995, 61, 38–59. [Google Scholar] [CrossRef] [Green Version]
- Yu, T.; Luo, J.; Ahuja, N. Shape regularized active contour using iterative global search and local optimization. In Proceedings of the 2005 IEEE Computer Society Conference on Computer Vision and Pattern Recognition (CVPR’05), San Diego, CA, USA, 20–25 June 2005. [Google Scholar]
- Van Ginneken, B.; Frangi, A.F.; Staal, J.J.; ter Haar Romeny, B.M.; Viergever, M.A. Active shape model segmentation with optimal features. IEEE Trans. Med. Imaging 2002, 21, 924–933. [Google Scholar] [CrossRef] [PubMed]
- Van Ginneken, B.; Katsuragawa, S.; ter Haar Romeny, B.M.; Doi, K.; Viergever, M.A. Automatic detection of abnormalities in chest radiographs using local texture analysis. IEEE Trans. Med. Imaging 2002, 21, 139–149. [Google Scholar] [CrossRef] [PubMed]
- Seghers, D.; Loeckx, D.; Maes, F.; Vandermeulen, D.; Suetens, P. Minimal shape and intensity cost path segmentation. IEEE Trans. Med. Imaging 2007, 26, 1115–1129. [Google Scholar] [CrossRef]
- Shi, Y.; Qi, F.; Xue, Z.; Chen, L.; Ito, K.; Matsuo, H.; Shen, D. Segmenting lung fields in serial chest radiographs using both population-based and patient-specific shape statistics. IEEE Trans. Med. Imaging 2008, 27, 481–494. [Google Scholar]
- Dawoud, A. Lung segmentation in chest radiographs by fusing shape information in iterative thresholding. IET Comput. Vis. 2011, 5, 185–190. [Google Scholar] [CrossRef]
- Coppini, G.; Miniati, M.; Monti, S.; Paterni, M.; Favilla, R.; Ferdeghini, E.M. A computer-aided diagnosis approach for emphysema recognition in chest radiography. Med. Eng. Phys. 2013, 35, 63–73. [Google Scholar] [CrossRef]
- Howard, A.G.; Zhu, M.; Chen, B.; Kalenichenko, D.; Wang, W.; Weyand, T.; Andreetto, M.; Adam, H. Mobilenets: Efficient convolutional neural networks for mobile vision applications. arXiv 2017, arXiv:1704.04861. [Google Scholar]
- Pal, N.R.; Pal, S.K. A review on image segmentation techniques. Pattern Recognit. 1993, 26, 1277–1294. [Google Scholar] [CrossRef]
- Shiraishi, J.; Katsuragawa, S.; Ikezoe, J.; Matsumoto, T.; Kobayashi, T.; Komatsu, K.I.; Matsui, M.; Fujita, H.; Kodera, Y.; Doi, K. Development of a digital image database for chest radiographs with and without a lung nodule: receiver operating characteristic analysis of radiologists’ detection of pulmonary nodules. Am. J. Roentgenol. 2000, 174, 71–74. [Google Scholar] [CrossRef]
- Hinton, G.E.; Srivastava, N.; Krizhevsky, A.; Sutskever, I.; Salakhutdinov, R.R. Improving neural networks by preventing co-adaptation of feature detectors. arXiv 2012, arXiv:1207.0580. [Google Scholar]
- Hillman, B.J.; Joseph, C.A.; Mabry, M.R.; Sunshine, J.H.; Kennedy, S.D.; Noether, M. Frequency and costs of diagnostic imaging in office practice—A comparison of self-referring and radiologist-referring physicians. N. Engl. J. Med. 1990, 323, 1604–1608. [Google Scholar] [CrossRef] [PubMed]





{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Model | Index | MAE | Model | Index | MAE | ||||||
|---|---|---|---|---|---|---|---|---|---|---|---|
| U-net | k = 2 | ECXR | 0.838 | 0.880 | 0.738 | FCN-8 | k = 2 | ECXR | 0.808 | 0.807 | 0.709 |
| OCXR | 0.832 | 0.738 | 0.737 | OCXR | 0.804 | 0.704 | 0.710 | ||||
| k = 16 | ECXR | 0.839 | 0.887 | 0.739 | k = 16 | ECXR | 0.809 | 0.810 | 0.709 | ||
| OCXR | 0.835 | 0.740 | 0.739 | OCXR | 0.805 | 0.706 | 0.709 | ||||
| k = 256 | ECXR | 0.840 | 0.891 | 0.740 | k = 256 | ECXR | 0.809 | 0.810 | 0.711 | ||
| OCXR | 0.836 | 0.739 | 0.740 | OCXR | 0.806 | 0.707 | 0.710 | ||||
| Original | ECXR | 0.842 | 0.893 | 0.739 | Original | ECXR | 0.809 | 0.811 | 0.711 | ||
| OCXR | 0.839 | 0.740 | 0.740 | OCXR | 0.808 | 0.707 | 0.709 | ||||
| FCN-32 | k = 2 | ECXR | 0.641 | 0.645 | 0.621 | SegNet | k = 2 | ECXR | 0.833 | 0.842 | 0.734 |
| OCXR | 0.638 | 0.541 | 0.620 | OCXR | 0.835 | 0.736 | 0.735 | ||||
| k = 16 | ECXR | 0.641 | 0.650 | 0.626 | k = 16 | ECXR | 0.835 | 0.845 | 0.735 | ||
| OCXR | 0.639 | 0.543 | 0.624 | OCXR | 0.835 | 0.735 | 0.734 | ||||
| k = 256 | ECXR | 0.642 | 0.653 | 0.630 | k = 256 | ECXR | 0.836 | 0.846 | 0.735 | ||
| OCXR | 0.640 | 0.541 | 0.629 | OCXR | 0.835 | 0.734 | 0.734 | ||||
| Original | ECXR | 0.642 | 0.655 | 0.632 | Original | ECXR | 0.837 | 0.851 | 0.736 | ||
| OCXR | 0.641 | 0.543 | 0.628 | OCXR | 0.835 | 0.734 | 0.735 | ||||
| Model | Iterations | OCXR vs. ECXR | OCXR vs. BOCXR | OCXR vs. BECXR | BOCXR vs. BECXR | ECXR vs. BECXR | |||
|---|---|---|---|---|---|---|---|---|---|
| OCXR | ECXR | BOCXR | BECXR | ||||||
| U-net | 11,321 | 9394 | 10,517 | 8664 | −17.02% | −7.10% | −23.47% | −17.62% | −7.77% |
| FCN-8 | 21,665 | 19,523 | 20,101 | 16,512 | −9.89% | −7.22% | −23.78% | −17.85% | −15.42% |
| FCN-32 | 19,433 | 17,576 | 18,298 | 15,273 | −9.56% | −5.84% | −21.41% | −16.53% | −13.10% |
| SegNet | 13,588 | 12,209 | 12,456 | 11,868 | −10.15% | −8.33% | −12.66% | −4.72% | −2.79% |
| Average | 16,502 | 14,676 | 15,343 | 13,079 | −11.07% | −7.02% | −20.74% | −14.75% | −10.88% |
© 2020 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (http://creativecommons.org/licenses/by/4.0/).
Share and Cite
Chen, H.-J.; Ruan, S.-J.; Huang, S.-W.; Peng, Y.-T. Lung X-ray Segmentation using Deep Convolutional Neural Networks on Contrast-Enhanced Binarized Images. Mathematics 2020, 8, 545. https://doi.org/10.3390/math8040545
Chen H-J, Ruan S-J, Huang S-W, Peng Y-T. Lung X-ray Segmentation using Deep Convolutional Neural Networks on Contrast-Enhanced Binarized Images. Mathematics. 2020; 8(4):545. https://doi.org/10.3390/math8040545
Chicago/Turabian StyleChen, Hsin-Jui, Shanq-Jang Ruan, Sha-Wo Huang, and Yan-Tsung Peng. 2020. "Lung X-ray Segmentation using Deep Convolutional Neural Networks on Contrast-Enhanced Binarized Images" Mathematics 8, no. 4: 545. https://doi.org/10.3390/math8040545
APA StyleChen, H. -J., Ruan, S. -J., Huang, S. -W., & Peng, Y. -T. (2020). Lung X-ray Segmentation using Deep Convolutional Neural Networks on Contrast-Enhanced Binarized Images. Mathematics, 8(4), 545. https://doi.org/10.3390/math8040545