1. Introduction
Nowadays, ranking of scientific impacts is a crucial task and it is a focus of research communities, universities, and governmental funding agencies. In this ranking, the target entities can be researchers, universities, countries, journals, or conferences. Performance analysis and benchmarking of scientific achievement has a variety of substantial purposes. At the researcher level, the research’s impact is an important measure to define the main rules of academic institutions and universities on determination of funding, hiring, and promotions [
1,
2,
3]. From the university’s view point, university rankings are considered as a source of strategic information for governments, funding agencies, and the media in order to compare universities; then students and their parents use university rankings as a selection criterion [
4]. As the assessment of scientific achievement has gained a great deal of attention for various interested groups, such as students, parents, institutions, academicians, policy makers, political leaders, donors/funding agencies, and news media; several assessment methods have been developed in the field of bibliometry and scientometrics through the utilization of mathematical and/or statistical methods [
1].
In order to measure a researcher’s performance, many indicators have been proposed which can also be utilized in other scientific areas. Traditional research indicators include the numbers of publications and citations, the average number of citations per paper, and the average number of citations per year [
5]. In 2005, Hirsch [
6] proposed a new indicator, called
h-index, which revolutionized scientometrics (informetrics). The original definition of the
h-index indicator is that, “A scientist has the index
h if
h of his/her
papers have at least received
h citations each, and the other
papers have no more than
h citations each.” Later, other indicators were proposed to enhance the
h-index. Additionally,
h-index was defined for other scientific aggregation levels [
7]. Ranking methods at researcher level tend to use only one indicator (
h-index or its improved versions), but at other aggregation scientific levels they prefer to have a more comprehensive set of indicators. Research works in the scientometrics can be divided into the following two main categories: the first category includes methods which focus on introducing new indicators to enhance the performances of assessment metrics, and in the second category, methods attempt to develop enhanced ranking methods for obtaining ranks by using several various indicators.
There are various kinds of ranking methods; first, methods which focus only on one indicator; and second, methods which combine several of them. Considering only a specific indicator makes differences among the quality assessments of research outcomes very hard to be revealed. On the other hand, there are a few challenges for considering several indicators simultaneously. For instance, the method needs to find the proper weights for combining the indicators and also an efficient merging strategy to combine several different types of indicators.
In the field of optimization, an algorithm tries to find the best solution in a search space in terms of an objective function which should be minimized or maximized [
8] accordingly. However, in singe-objective problems [
9], there is only one objective to be optimized; in the multi-objective version, the algorithm tries to find a set of solutions based on more than one objective [
10]. In the multi-objective optimization [
11,
12], the non-dominated sorting [
13,
14] is defined and used as a measure of efficiency in metaheuristic-based methods [
15,
16]. In [
17], the basic dominance ranking was used to identify the excellent scientists according to all selected criteria. They selected all researchers in the first Pareto-front as excellent scientists, but by increasing the number of criteria (more than three) most compared entities were placed in the first Pareto front [
17]. In this paper, we propose a modified, non-dominated sorting, which according to the basic dominance ranking, utilizes two main metrics and then two statistical metrics which are the computed means and medians of some ranks obtained by sorting each criterion’s value in all compared vectors. This ranking has many major advantages: (1) it can perform very well at ranking all compared vectors even with a large number of criteria; (2) each obtained Pareto front in the modified non-dominated sorting has a smaller number of vectors in compared to the basic non-dominated sorting approach; (3) it can consider the length time of academic research (called the research period) as an independent indicator, which makes it possible to compare junior and senior researchers; (4) it is independent and capable of accommodating new indicators; (5) there is no need to determine the optimal weights to combine indicators. The modified Pareto dominance ranking was used to rank two research datasets with many criteria, ranking universities (200 samples) and countries (231 samples); additionally, the basic dominance ranking was applied to rank two research datasets with a low number of the criteria, ranking computer science researchers based on h-index and period of publication (350 samples) and ranking of universities based on triple rankings resources (100 samples).
The remaining sections of this paper are organized as follows.
Section 2 presents a background review which provides state-of-the-art scientific indicators and ranking methods.
Section 3 describes the proposed ranking method in detail.
Section 4 presents case studies and corresponding discussions. Finally, the paper is concluded in
Section 5.
3. Proposed Methodology
As mentioned in the
Section 2, several indicators and ranking methods have been proposed to measure the scientific achievements. There are two main categories of ranking methods: in the first one, the methods use all indicators (multi-metric) and in the second one, the methods focus on only one indicator (single-metric). Ranking methods by focusing on one indicator of scientific achievements cannot reveal significant differences among compared entities. In ranking methods with several indicators, first they need to assign weights for indicators which have considerable impacts on the results of these raking methods [
55,
56]. Finding the proper weights according to importance of indicators is a challenging task [
57]. They also suffer from combining several different kinds of indicators to achieve a single score. In this paper, we modify the dominance depth ranking proposed in [
13,
14] utilized in the multi-objective optimization to rank scientific achievements. In 1964, Pareto [
58] proposed the Pareto optimality concept, which has been applied in a wide range of application, such as economics, game theory, multi-objective optimization, and the social sciences [
59]. Pareto optimality was mathematically defined as a measure of efficiency in the multi-objective optimization [
12,
60]. We explain Pareto optimality concepts and also the proposed method and how it can be applied to evaluate scientific achievements. Without loss of generality, it is assumed that the optimal value of each criterion as a preference be a minimal value. Seeking the optimal value among both the minimal and maximal values is analogous, and if a criterion value element
to be maximized, it is equivalent to minimize
.
In the following, the Pareto optimality definitions are described by the assumption of the minimal value as the optimal.
Definition 1 ((Pareto Dominance) [
61])
. A criterion vector dominates another criterion vector (denoted as ) if and only if and . This type of dominance is called weak dominance in which two vectors can be same in some objectives, but they should be different in at least one objective. However, in strict dominance, u has to be better on all objectives; i.e., it can not have the same objective value with v. The Pareto optimality concept is defined from the dominance concept as follows.
Definition 2 (Definition (Pareto Optimality) [
61])
. A criterion vector u in a set of criterion vectors (S) is a Pareto optimal vector (non-dominated) if for every vector x, x does not dominate u, . Figure 1 shows Pareto optimal solutions and dominated solutions for a criterion value vectors (2D) (
). According to this definition, for a set of objective function vectors or criterion value vectors, the Pareto set is denoted as all Pareto optimal vectors which have no elements (criterion values) that can be decreased without simultaneously causing an increase in at least one of the other elements of vectors (assuming a Min-Min case).
Definition 3 (Definition (Pareto-front) [
61])
. For a given set S, the Pareto front is defined as set S . Figure 2 shows the Pareto front for two dimensional space for all four possible cases for minimizing or maximizing of two objective function vectors (
) or a two criterion value vectors (
).
Dominance depth ranking in the non-dominated sorting genetic algorithm (NSGA-II) was proposed by Deb et al. [
13] to partition a set of objective function vectors (criterion value vectors) into several clusters by Pareto dominance concept. First, the non-dominated vectors in a set of criterion value vectors assigned to rank 1 and form the first Pareto front (PF1), and all these non-dominated vectors are removed. Then, non-dominated solutions are determined in the set and form the second Pareto front (PF2). This process is repeated for other remaining criterion value vectors until there is no vector left.
Figure 3 illustrates an example of this ranking for a set of eight points (criterion value vectors) and
Table 2 shows the coordinates of points. First points 1, 2, 3, and 4 as non-dominated solutions are ranked to rank 1. Then, for the rest of the points (points 5, 6, 7, and 8), non-dominated solutions are determined so points 5 and 6 as non-dominated solutions are ranked as 2 and removed. In the last iteration, the remaining points 7 and 8 are ranked as rank 3. The details of non-dominated sorting algorithm is presented in Algorithm 1.
| Algorithm 1 Non-dominated sorting algorithm. |
![Mathematics 08 00956 i001]() |
In [
17], the dominance concept was used to identify the excellent scientists whose performances cannot be surpassed by others with respect to all criteria. The proposed method can provide a short-list of the distinguished researchers in the case of award nomination. It computes the sum of all criteria and sorts all researchers according to this calculated sum value. After that, the researcher with the maximum sum
is placed in the skyline set. The second best researcher is compared with the researcher in the skyline set (
); if he/she is not dominated by
, he/she is added into the skyline set. This process is repeated for all remaining researchers to construct the skyline set: if they are not dominated by all researchers in the skyline set (
), then they are added into the skyline set. In fact, they select all researchers in the first Pareto front using the dominance concept. There is a well-known problem with the first Pareto created by the basic non-dominated sorting [
17]. By increasing the number of criteria (more than three criteria) in the set of the criterion value vectors, a large number of the compared vectors become non-dominated vectors and are placed in the first Pareto front. By increasing the number of criteria, the chance of placing a criterion value vector while having only one better criterion value in the first Pareto front is increased. In order to demonstrate this problem,
Table 3 shows three Pareto fronts by the non-dominated sorting for countries data extracted from the site “
http://www.scimagojr.com” including five indicators: citable documents (CI-DO), citations, self-citations (SC), citations per document (CPD), and
h-index;
Table 3 shows the results of the non-dominated sorting method. As it can be seen from
Table 3, three countries, Panama, Gambia, and Bermuda, are in the first Pareto front because they have higher values for only one criterion indicator (CPD) while other criteria values are low. Additionally, Montserrat has the rank 2 because it has the high value for only the CPD indicator.
In this paper, we propose a modified non-dominated sorting (described in Algorithm 2) to rank the scientific data. First we use the dominance depth ranking for all vectors; after that for each criterion value vector two new statistical metrics are calculated. For each vector, two metrics are the dominated number and the non-dominated number which show the number of the dominated vectors by this vector and the number of vectors which dominate this vector. Additionally, we used two other statistical measures proposed in [
62]. These statistical measures are computed to sort the criterion value vectors. In [
62], first for each criterion value
, all vectors are sorted according to this criterion value
in ascending order and their ranks are assigned based on their sorting order. After that, for each criterion value vector some statistical measures like the minimum of its rank or the sum of its rank are used to make Pareto fronts.
We also sort all vectors according to each criterion value and calculate the ranks of vectors corresponding this sorting; after that we compute the mean and median of ranks of each vector as two new metrics.
Table 2 shows an example of computed new metrics for eight points in
Figure 3.
and
are the values of sample points in
Figure 3 which are considered just as the numerical examples for a two-objective problem. For each point, ranks (two columns Ranks-F1 and Ranks-F2) for two criterion vectors (
) are computed according to their sorting order. Thus, we have four new statistical metrics (the mean and median of ranks, also the dominated number and the non-dominated number) which we use as criteria (objectives) to measure various levels of scientific achievement by applying dominance depth ranking again to make all Pareto fronts. We used the basic non-dominated sorting for data with two and three criteria and the modified non-dominated sorting for the data with more than three criteria. The proposed method has major advantages that are described in detail. In this method, vectors with one better criterion value than others cannot move toward the first front. Additionally, increasing the number of criteria cannot negatively influence the obtained ranks (no big portion of entities in the first front, as before); each rank corresponding to a Pareto front has a smaller number of vectors, so in total it assigns more ranks to the criterion vectors.
| Algorithm 2 Modified non-dominated sorting algorithm. |
![Mathematics 08 00956 i002]() |
In order to demonstrate the performance of this modified non-dominated sorting,
Table 4 shows four Pareto fronts by the modified non-dominated sorting for extracted country data. Because the considered criteria have different scales, in all experiments, in order to apply the proposed method, they are normalized. As can be seen in the first Pareto front, only the United States is placed and Panama is in the forth Pareto front. Additionally, other countries with only one high criterion value, Gambia and Bermuda, which are in the first Pareto front by the non-dominated sorting method (as it can be seen in
Table 3) are not placed in four Pareto fronts obtained by the modified non-dominated sorting method. Additionally, it can be seen that the number of countries in each Pareto front by using the modified non-dominated sorting is smaller than in basic non-dominated sorting.
In addition, we consider the period research as a new criterion value. Using Pareto dominance ranking makes it possible to have the research period as an independent indicator to be considered for ranking the scientific data. Considering the research period as the indicator provides a predication mean for some research cases. For example, suppose for comparing authors, criterion values be h-index and the research period : two authors and would be in the same Pareto front because based on Pareto optimality concept, they do not dominate each other; therefore, we can predict that the author probably will be able to have the same performance as the author (or even better) after some years. According to observed values of indicators for universities, authors, and countries, this method can be utilized for prediction of their future performance. Additionally, the time length indicator enhances this ranking method with a traceable feature; that means by collecting data during times, we can observe how the performances of universities or researchers change and if they can improve their Pareto front ranks or not. In addition, this method can be applied to compute ranks by using obtained ranks from other ranking methods (ranking by multiple resources). In this way, each indicator is an obtained rank from a ranking method and it is expected that the non-dominated vectors in the first Pareto front contain the vectors with the minimum/maximum values of indicators, for Min-Min or Max-Max cases, respectively. Pareto dominance ranking can take into account any new kind of indicator as a new criterion value.
4. Experimental Case Studies and Discussion
We run the basic Pareto dominance ranking on the following scientific data with two and three criteria and modified Pareto dominance ranking on the following scientific data with more than three criteria. The first dataset includes 350 top computer science researchers (
http://web.cs.ucla.edu/~palsberg/h-number.html) which contains a partial list of computer science researchers who each has an
h-index of 40 or higher according to the Google Scholar report. This data has two indicators: research period (a low value is better) and
h-index (a high value is better). The
h-index values were collected from Google Scholar for the year 2016 and research period values were calculated from the year of the first publication of an author so far. The second dataset includes the 200 top universities ranked by URAP (a nonprofit organization (
http://www.urapcenter.org)). This dataset has six indicators: article, citation, total document (TD), article impact total (AIT), citation impact total (CIT), and international collaboration (IC). The third dataset has 231 top countries (for the year 2015) extracted from the site SJR (
http://www.scimagojr.com), including six indicators: documents, citable documents (CI-DO), citations, self-citations (SC), citations per document (CPD), and
h-index. We do not consider the SC indicator because it is not certain that the maximum value or minimum value of this value is desirable. The forth dataset consists of the three ranks of 100 top common universities collected from three resources; the QS World University Rankings (
https://www.topuniversities.com), URAP (
http://www.urapcenter.org), and CWUR Rankings (
http://cwur.org). In the following, we report all results of mentioned approaches on the four datasets in detail.
4.1. The First Case Study: Ranking Researchers
Table A1 indicates the names of researchers, research period,
h-index, and the obtained Pareto ranks from the basic Pareto dominance ranking (Pareto ranking). From
Table A1, it can be seen that first Pareto ranks include researchers with high values of
h-index and low research period values. For instance, the researcher “Zhi-Hua Zhou” has the minimum value of research period 14 and the researcher “A. Herbert” has the maximum value of
h-index, 162. Researchers in the first Pareto front are A. Herbert, K. Anil, Han Jiawei, Van Wil, Buyya Rajkumar, Perrig Adrian, and Zhou Zhi-Hua; the second Pareto front contains Shenker Scott, Foster Ian, Salzberg Steven, Schlkopf Bernhard, Schmid Cordelia, Abraham Ajith, and Xiao Yang. Additionally, it can be observed that researchers with the maximum value of research year indicator (40) are associated with the higher rank because they are dominated by other researchers according to Pareto dominance concept. Researchers having values close to the value of
h-index 52 or higher are associated with the higher rank due to the Pareto dominance concept.
Figure 4 shows the ranks in terms of Pareto fronts for all researchers. It can be seen from
Figure 4 that the extent of improvement for a researcher
can change his/her Pareto front ranking by looking at researchers which dominate
and are located in the better Pareto fronts.
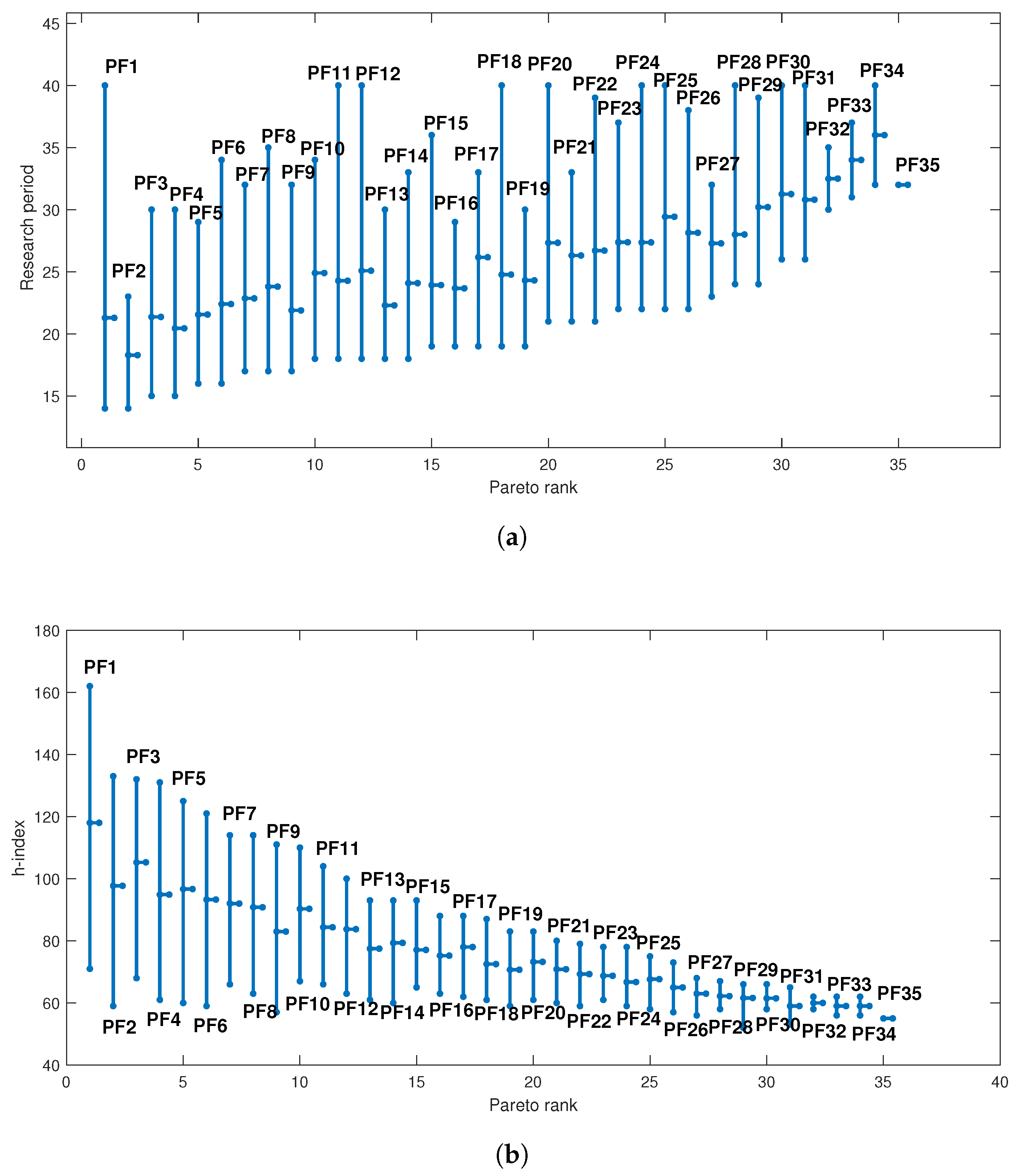
To gain a better understanding of the Pareto ranking with each indicator, we plot the obtained Pareto ranks from the first rank to the thirty fifth versus each indicator. In
Figure 5, vertical lines demonstrate Pareto ranks from the first rank to the thirty fifth, which at the top of each line indicates the maximum value of the indicator; its bottom is the minimum value of the indicator; and the short horizontal tick in the middle of each line is the average value of the indicator.
Figure 5 indicates that the research period of the first Pareto front includes values with the maximum and minimum of the length time. That is reasonable because it is expected that authors who have had more time have higher
h-index values so they could be located in the first Pareto front, and younger authors having had shorter research periods and reasonable
h-index values also could be in the first Pareto front. The average values of the research period for the beginning Pareto fronts are low values while the last Pareto fronts have higher average values. From
Figure 5, we can see that the maximum, average, and minimum of
h-index values for Pareto fronts decrease from the first Pareto front to the 35th. Additionally, the first Pareto front has the maximum
h-index values and the last Pareto front includes the minimum
h-index values.
4.2. The Second Case Study: Ranking of Universities
Six indicators of university dataset and their ranks obtained by modified Pareto dominance ranking are summarized in
Table A2. As mentioned in
Section 3, for fair comparison, we add the time period of academic research (the research period (RP)) mentioned in
Table A2 as an indicator in the data which is calculated as the length of the university established year to present. Based on the proposed method, the first Pareto front has six universities, including top universities; for example, Harvard University, University of Toronto, and Stanford University. In the basic Pareto dominance ranking, the first Pareto front has twenty universities. Additionally, the proposed ranking clusters this data into twenty three Pareto fronts but the Pareto dominance ranking has only eight Pareto fronts. As was mentioned in the
Section 3, the proposed method can assign more ranks to the criterion vectors even by increasing the number of criteria (many-metric cases).
In order to deep understand the behavior of the obtained Pareto ranks and indicators, we plot the maximum, minimum, and average of values for all indicators versus Pareto ranks in
Figure 6,
Figure 7 and
Figure 8 as mentioned before. It can be seen from these figures—all plots for six indicators—that there is a decreasing behavior in terms of the maximum, minimum, and average values, observable from the first Pareto front to the last Pareto front. In addition,
Figure 9 visualizes universities in the four top ranked Pareto fronts. Each line illustrates one university (a five dimensional vector) in which the values of five indicators are presented using vertical axes; i.e., coordinate’s value.
4.3. The Third Case Study: Ranking of Countries
Table A3 shows countries, the values of five indicators (documents, CI-DO, citations, CPD, and
h-index), and the obtained Pareto ranks from the proposed method (Pareto ranking). The United States is located in the first Pareto front because it has the maximum values of four indicators: documents, CI-DO, citations, CPD, and
h-index. The United States is assigned to the rank 1 and in the second Pareto front, Switzerland and the United Kingdom are placed. The proposed method ranks these countries into forty six ranks while in the Pareto dominance ranking, it has thirty Pareto fronts.
Additionally, for this data, we plot the maximum, minimum, and average of values for all indicators versus Pareto ranks in
Figure 10 and
Figure 11. Figures show a falling tendency of the average values from the first Pareto front to the last Pareto front. Additionally, we compute the percentage of the number of countries from the different continents (Asia, Europe, Latin America, Middle East, North America, and Pacific region) for each Pareto front.
Figure 12 shows the percentage number for each continent. In
Figure 12, the first largest and second largest percentages of the first Pareto front are North America and Europe. In addition,
Figure 13 visualizes the values of indicators for countries in the four top ranked Pareto fronts by the parallel coordinates visualization technique. Each line illustrates one country (a five dimensional vector) in which the values of five indicators are presented using vertical axes; i.e., coordinate’s value. For instance, the value of CI-DO indicator is in interval
for countries on the four first Pareto fronts.
4.4. The Forth Case Study: Resolution for Multi-Rankings of Universities
This case study collects the three ranks of 100 top common universities collected from the three mentioned resources, from which it is supposed that the criterion vectors with the lesser values for all three ranks are better vectors (i.e., Min-Min-Min).
Table A4 shows universities, the values of three ranks, and the obtained Pareto ranks from Pareto dominance ranking (Pareto ranking). As we can see, three universities, “Massachusetts Institute of Technology,” “Stanford University,” and “Harvard University” are located in the first Pareto front, which has elements with the values 1 and 2 as the obtained ranks from other ranking resources.
Figure 14 shows the numbers of Pareto fronts for all data. Additionally, the maximum, minimum, and average of values for three rankings versus Pareto ranks are plotted in
Figure 15. It can be seen from
Figure 15 that the average values of three ranks increase from the first Pareto front to 13th Pareto front.
At the end of this section, several points regarding the performance of the method and its differences with other ranking strategies are mentioned. First of all, a multi-criteria indicator is proposed for ranking the researchers, universities, and countries. Considering two or more objectives simultaneously can provide a fairer ranking. For instance, using research period along with other important criteria provides a fair comparison for senior and junior researchers to discover more-talented researchers. Secondly, since the considered criteria to assess the entities are different from indicators in other ranking strategies, the resultant rankings are completely different. In fact, they evaluate the universities in terms of different metrics. As a result, the comparison between the results of ranking strategies does not lead to a precise and meaningful conclusion. On the other hand, the proposed method clusters the entities based on multiple criteria into different levels. Accordingly, all universities in the same Pareto are ranked equally; for instance, based on this perspective, all universities in the first Pareto are the top ranked universities. Finally, this method does not actually define an evaluation measure; it gives a strategy to rank not only the case studies in the paper, but also any multi-criteria data entities. In addition, using this general platform provides the chance to utilize any metric to assess the related entities without modification to other parts of the algorithm.






{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}