1. Introduction
In recent years, towards more flexibility, many studies have been developed in which new methods are proposed to add one or more parameters to a baseline probability distribution. These methods have given way to the generation of models with more complex parametric structures and more flexibility in aspects such as the shapes of the density and hazard rate functions and the asymmetry or kurtosis of the distribution.
One of the most popular methods is to propose a new cumulative distribution function (cdf) considering a suitable transformation of the cdf of a certain random variable of interest. More specifically, if
X is a random variable with cdf
, then
where
is a nondecreasing function such that
as
, and
as
, for
, is a cdf.
Different analytical expressions for
can be found in the literature. If
,
, then the cdf in Equation (
1) corresponds to the cdf of the exponentiated distributions class; see Gupta et al. [
1], Nadarajah and Kotz [
2], Al-hussaini [
3], Castillo et al. [
4] and Gómez-Déniz et al. [
5], among others. If
, where
and
denotes the incomplete beta function ratio, then Equation (
1) corresponds to the cdf of the beta-generated distributions class; see Eugene et al. [
6], Jones [
7], Jones [
8] and Nadarajah and Kotz [
9], among others. Similarly, other alternative expressions for
can be found in Marshall and Olkin [
10], Shaw and Buckley [
11], Zografos and Balakrishnan [
12], Cordeiro and de Castro [
13], Lai [
14] and Badr et al. [
15], to name just a few.
In this paper, we propose a new distribution generator called the Lambert-
F generator. The proposed generator is obtained from Equation (
1) by considering a new analytical expression for the function
given by
, for
and
. The result is a new cdf with an extra shape parameter having the quantile function written in closed form in terms of the Lambert
W function, hence the name of the generator. Note that a Lambert-
F distribution is reduced to the baseline distribution when
; that is, the baseline distribution and the respective Lambert version are nested distributions. We will show that the hazard rate function (hrf) of a Lambert-
F distribution corresponds to a modification of the baseline hrf, greatly increasing or decreasing the baseline hrf for the lower values of
X (earlier times). This can be interpreted as a perturbation of the baseline hrf at earlier times.
The Lambert
W function, which corresponds to the inverse function of
, with
z being any complex number, plays an important role in this work. This is a many-valued function satisfying
, for every complex number
. By restricting
to be a real-valued function, the complex variable
z is then replaced by the real variable
x, and the function is defined only for
to be double-valued in the interval
and simple-valued (principal branch, denoted by
) for
. More details of the Lambert
W function can be found in Corless et al. [
16] and Brito et al. [
17]. Recently, Visser [
18] showed that the Lambert W function can be used in the distribution of prime numbers.
In the statistical literature, Goerg [
19] introduced new families of distributions using the Lambert
W function in the context of random variable transformations. In our approach we apply a transformation to a baseline cdf, as can be seen in Definition 1.
We emphasize the fact that the Lambert-F generator can be used to extend any arbitrary probability distribution, regardless of whether it is the distribution of a discrete or continuous random variable and whether it has positive, real or bounded support. However, in this paper we consider the case in which the baseline distribution is a continuous distribution with positive support. Other cases might be the subject of future research.
The remainder of the paper is organized as follows. In
Section 2, we propose the distributions generator. In
Section 3, main structural properties of the generator are studied. In
Section 4, two special models are derived with its main properties.
Section 6 discusses parameter estimation using the moments and maximum likelihood methods. In
Section 7, we describe a simulation study carried out to assess the performances of the estimators. In
Section 8, two applications evidence that the proposed distributions may present a better fit than other models such as the Weibull and gamma distributions. The conclusions of this work are presented in
Section 9. Computational code used in
Section 6,
Section 7 and
Section 8 is available on request.
4. Two Special Cases
In what follows, two new two-parameter models generated from the results in Corollary 1 are introduced. The well-known exponential and Rayleigh distributions are taken as baseline distributions in the generation of these new models.
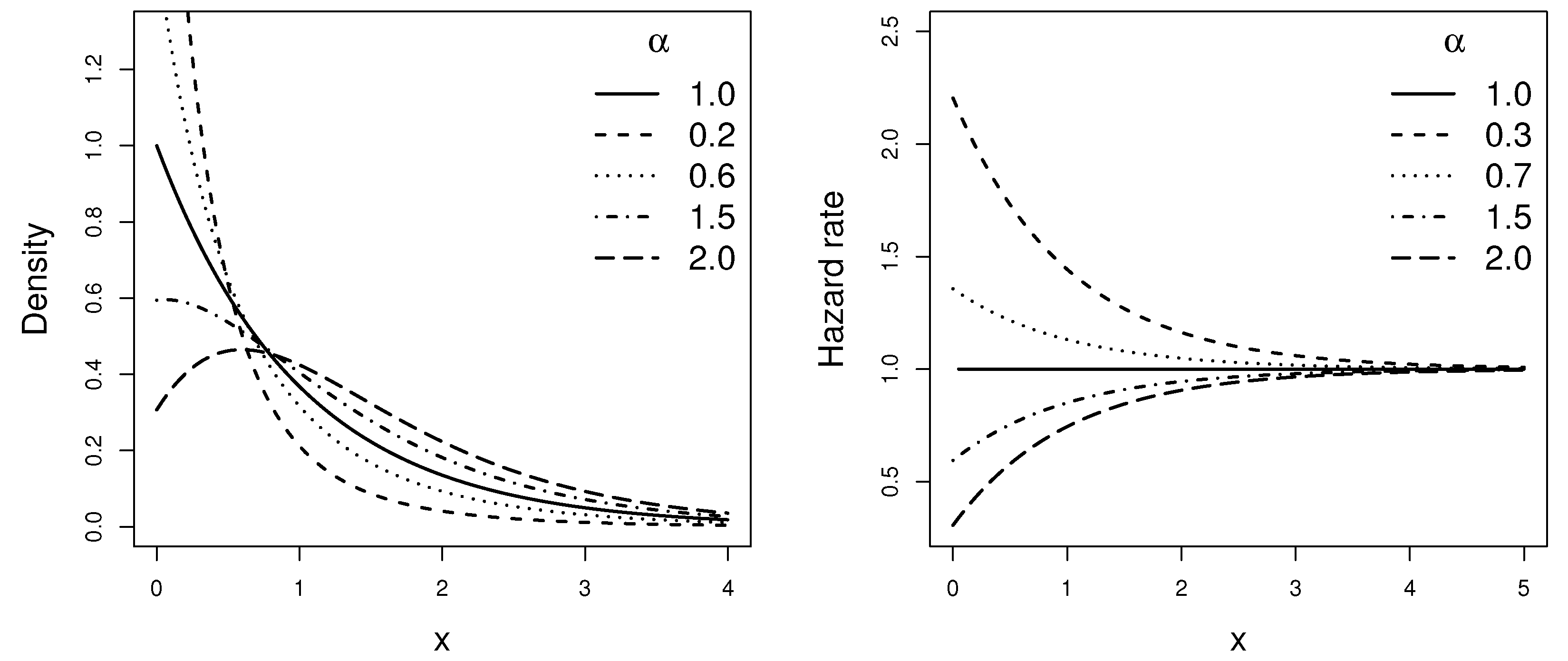
Lambert-exponential model. The random variable
X follows the Lambert-exponential distribution with scale parameter
, denoted as
, if its pdf and hrf for
are given, respectively, by
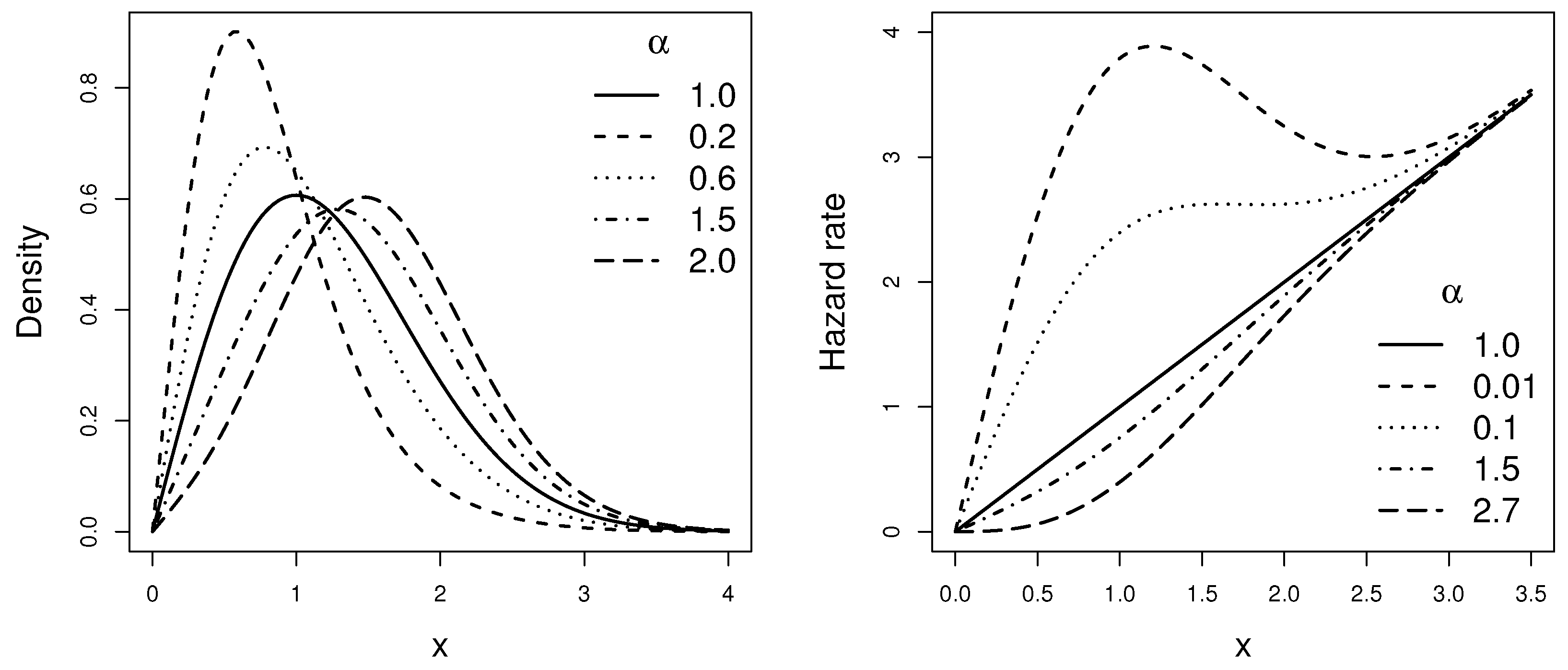
Lambert–Rayleigh model. The random variable
X follows the Lambert–Rayleigh distribution with scale parameter
, denoted as
, if its pdf and hrf for
are given, respectively, by
The new two-parameter distributions described above are members of the well-known and popular shape and scale distributions family. The scale
in both models is inherited from the respective baseline distribution, while the shape parameter
arises from the application of the Lambert transformation to the baseline distribution.
Figure 1 and
Figure 2 display some plots of the pdfs and the hrfs of the above models for
and different values of shape parameter.
7. Simulation Study
In this section, we present a simulation study done to assess the performances of the moments and maximum likelihood estimates for the parameters of the models in
Section 4. We generated
random samples of sizes
from the LE and LR distributions, respectively, for different values of its parameters. The random numbers were generated by through the following steps:
Generate ;
Compute , for ;
Compute , where is the baseline quantile function.
We used the W function of the LambertW package in R Goerg [
22] to compute the principal branch of Lambert
W function.
Table 4 and
Table 5 show averages, empirical standard deviations (SD), averages of asymptotic standard errors (SE) and roots of the simulated mean square errors (RMSE) of the estimates of
and
for the LE and LR distributions. Looking at
Table 4, it can be seen that both the moments method and the ML method provide acceptable estimates of the parameters of the LE distribution. However, the ML method provides estimates with lower biases, and the SD and RMSE were smaller than those provided by the moments method. In addition, SD, SE and RMSE were closer for the ML method. The same held for SD and RMSE from the moments method. The estimators of the parameters of the LR distribution in
Table 5 had similar behavior, with the exception that SD and RMSE were smaller for the moments method when the sample size was
.
9. Final Comments
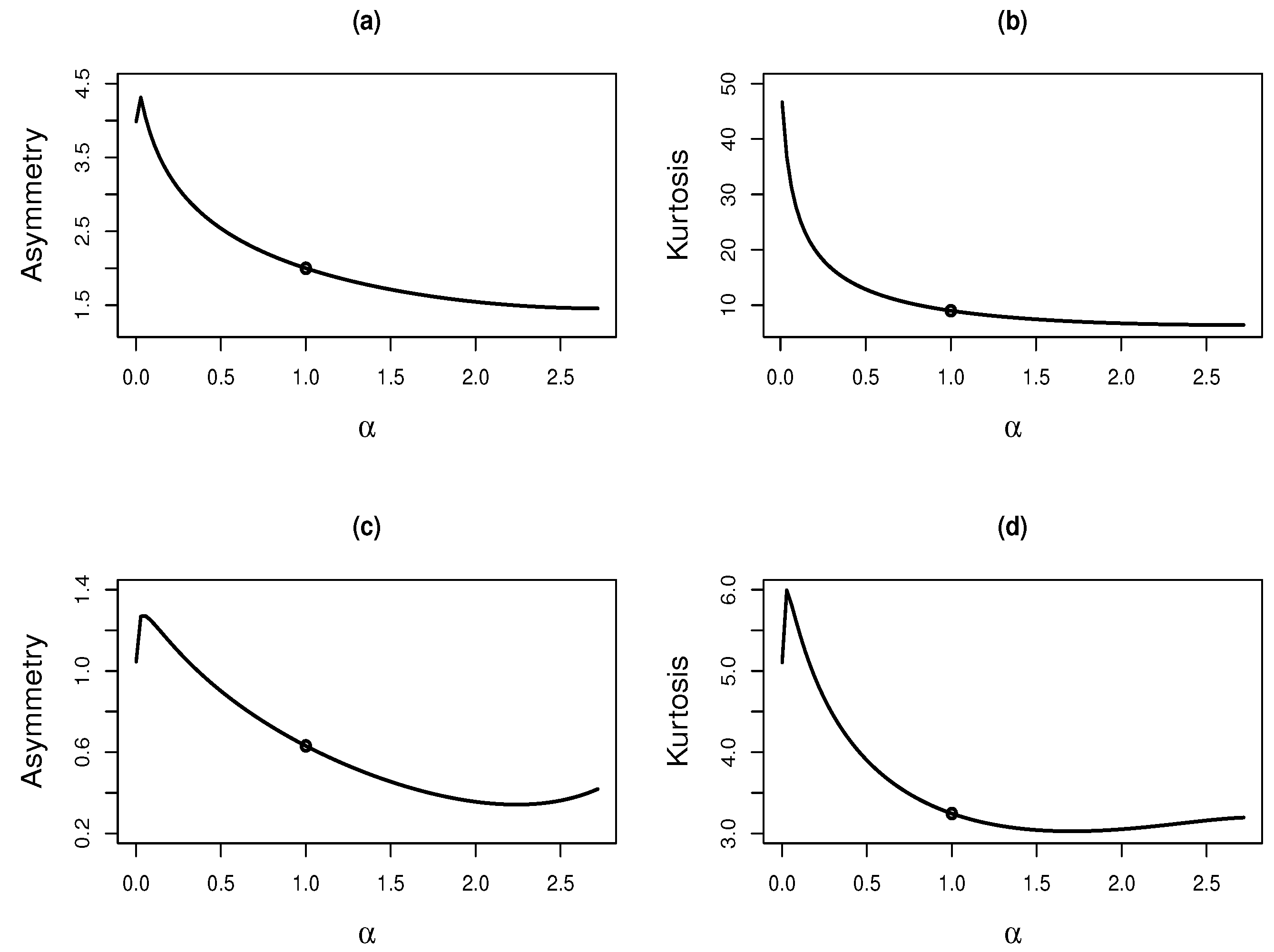
In this paper, we proposed a new probability distribution generator called the Lambert-F generator. For any baseline distribution F, continuous and with positive support, the Lambert-F version is derived by applying the generator. The result is a new distributions class with one extra parameter and that generalizes the baseline distributions. The quantile function of the new class of distributions can be expressed in closed form in terms of the Lambert W function.
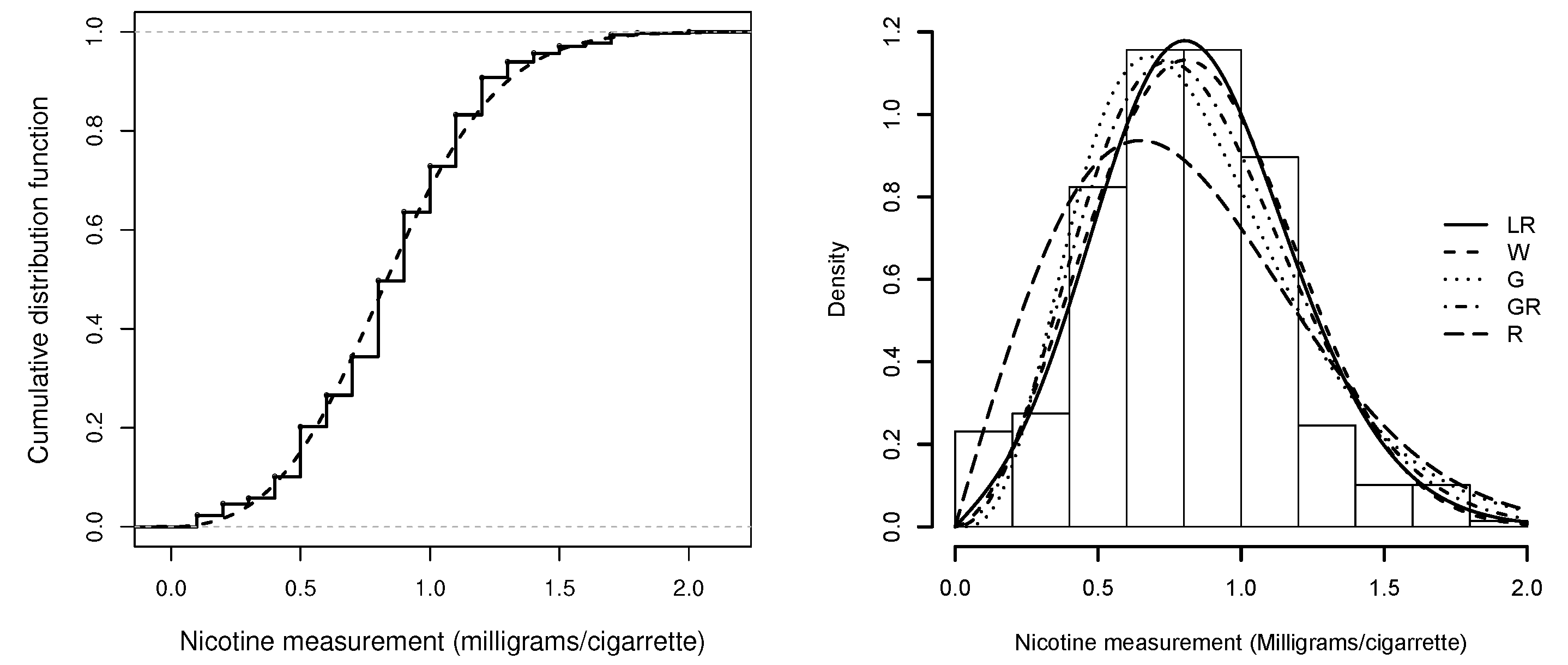
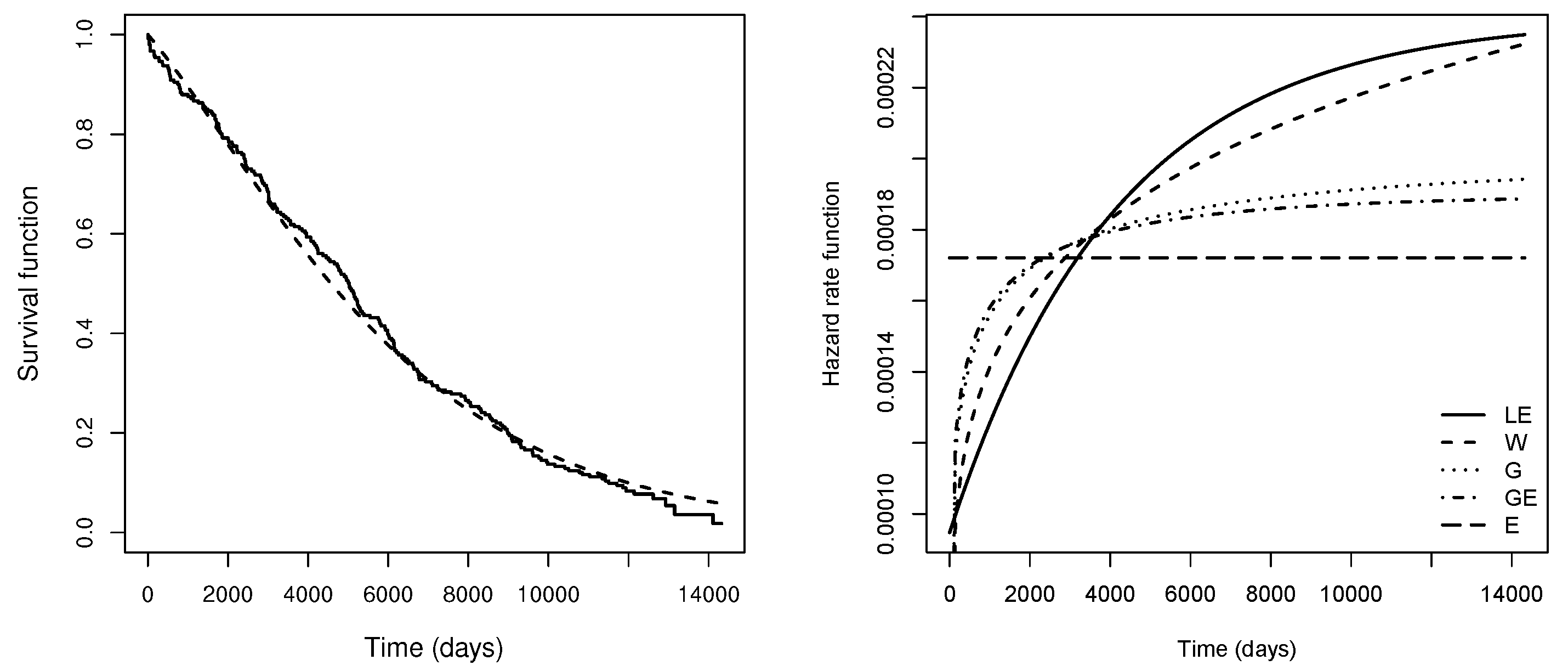
We proved that the hrf of a Lambert-F distribution corresponds to a perturbation of the baseline hrf, increasing or decreasing the baseline hrf for lower values of X (earlier times). We detailed two special cases corresponding to two-parameter extensions of the well-known exponential and Rayleigh distributions. We discussed moments and maximum likelihood estimators for the parameters of the proposed models. For both methods, we provided guidance on numerical procedures that might be used. Additionally, we carried out a simulation study to assess the behavior of the estimates. We found good performances for both estimators, but especially for maximum likelihood estimators, which yielded estimates with less bias. Finally, we developed two applications to real datasets, thereby providing evidence that the LE and LR distributions may present a better fit than other two-parameter distributions such as Weibull, gamma, generalized exponential and generalized Rayleigh.









{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}