1. Introduction
The lattice neural network discussed in this paper is a biomimetic neural network. The term biomimetic refers to man-made systems of processes that imitate nature. Accordingly, biomimetic artificial neurons are man-made models of biological neurons, while biomimetic computational systems deal mostly with information processing in the brain. More specifically, biomimetic computational systems are concerned with such questions as how do neurons encode, transform and transfer information, and how this encoding and transfer of information can be expressed mathematically.
In the human as well as other mammal brains, every neuron has a cell body, named soma, and two kinds of physiological processes called, respectively, dendrites and axons [
1]. Multiple dendrites conduct electric impulses toward the body of the cell whereas the axon conducts signals from the soma. Usually, dendrites have many branches forming complicated large trees and various types of dendrites are studded with many tiny branches known as spines. When present, dendrite spines are the main postsynaptic target for synaptic input. The input surface of the neuron is composed of the cell body and the dendrites. Those neurons receiving a firing signal coming from a presynaptic neuron are called postsynaptic neurons.
The axon hillock, usually located in the opposite pole of a neural cell, gives rise to the axon which is a long fiber whose branches form the axonal tree or arborization. In some neurons, besides its terminal arborization, the axon may have branches at intervals along its length. In general, a branch of an axon ends in several tips, called nerve terminals, synaptic knobs or boutons, and the axon, being the main fiber branch of a neuron, carries electric signals to other neurons. An impulse traveling along an axon from the axon hillock propagates all the way through the axonal tree to the nerve terminals. The boutons of the branches make contact at synaptic sites of the cell body and the many dendrites of other neurons. The synapse is a specialized structure whereby neurons communicate without actual physical contact between the two neurons at the synaptic site. The synaptic knob is separated from the surface of the soma or dendrite by a very short space known as the synaptic cleft. The mechanism characteristics of a synaptic structure are basically well known and there are two types of synapses, inhibitory synapses that prevent the neuron from firing impulses in response to excitatory synapses, which tend to depolarize the postsynaptic membrane and consequently exciting the postsynaptic cell to fire impulses.
In the cerebral cortex, the majority of synapses take place in the neural dendritic trees and much of the information processing is realized by the dendrites as brain studies have revealed [
2,
3,
4,
5,
6,
7,
8]. A human brain has around 85 billion neurons and the average number of synaptic connections a neuron may have with other nearby neurons is about
[
9,
10,
11,
12]. More specifically, a single neuron in the cerebral cortex has a number of synapses within the range 500 to
, and an adult’s cerebral cortex has an estimated number of synapses in the range of 100 to 500 trillion (
to
) [
10,
13,
14,
15]. In both volume and surface area of the brain, dendrites make up the largest component spanning all cortical layers in every region of the cerebral cortex [
2,
4,
16]. Thus, in order to model an artificial neural network that can represent more faithfully a biological brain network, it is not possible to ignore dendrites and their spines, which cover the membrane of a neuron in more than
. This is particularly true by considering that several brain researchers have proposed that dendrites (not the neuron) are the basic computing devices of the brain. Neurons together with its associated dendritic structure can work as multiple, almost independent, functional subunits where each subunit can implement different logical operations [
3,
4,
16,
17,
18,
19]. The interested reader may peruse the works of some researchers [
3,
4,
5,
6,
7,
8,
16,
20,
21], that have proposed possible biophysical mechanisms for dendritic computation of logical functions such as ‘AND’, ‘NOT’, ‘OR’, and ‘XOR’.
It is in light of these observations that we modeled biomimetic artificial neural networks based on dendritic computing. The binary logic operations ‘AND’ and ‘OR’ are naturally extended to non-binary numbers by considering their arithmetical equivalence, respectively, with finding the minimum and maximum of two numbers. Thus, the logic unary operation ‘NOT’, min and max together with addition belong to the class of machine operations that contribute to the high speed performance of digital computers. The preceding fact suggests us to select as the principal computational foundation, the algebraic structure provided by the bounded lattice ordered group
[
22,
23,
24]. Recall that,
stands for the set of extended real numbers and the binary operations of maximum, minimum, and extended additions are denoted, respectively, by ∨, ∧, and
.
The core issue in this research is a novel method for learning in biomimetic lattice neural networks. However, currently biomimetic neural networks and lattice based computational intelligence are not part of mainstream artificial neural networks (ANNs) and artificial intelligence (AI). To acquaint readers that are unfamiliar with these topics, we organized this paper as follows:
Section 2 deals with basic concepts from lattice theory that are essential conceptual background, while
Section 3 provides a short introduction to lattice biomimetic neural networks.
Section 4 discusses the construction of the biomimetic neural network during the learning stages, and the illustrative examples provided in
Section 5 show that the proposed neural architecture based on lattice similarity measures can be trained to give high percentages of correct classification in multiclass real-world pattern recognition datasets. The paper ends with
Section 6, where we give our conclusions and some relevant comments.
2. Lattice Theory Background Material
Lattice theory is based on the concept of partially ordered sets, while partially ordered sets rest on the notion of binary relations. More specifically, given a set X and , then R is called a binary relation on X. For example, set inclusion is a relation on any power set of a set X. In particular, if X is a set and with , then S is a binary relation on . Note that this example shows that a pair of elements of need not be a member pair of the binary relation. In contrast, the relation of less or equal, denoted by ≤, between real numbers is the set . Here, each pair of elements of is related. The two examples of a binary relation on a set belong to a special case of binary relations known as partial order relations. We shall use the symbol ≼ for denoting a binary relation on an unspecified set X.
Definition 1. A relation ≼ on a set P is called a partial order on P if and only if for every , the following three conditions are satisfied:
A set P together with a partial order ≼, denoted by , is called a partially ordered set or simply a poset. If in a partially ordered set, then we say that x precedes y or that x is included in y and that y follows x or that y includes x. If is a poset, then we define the notation , where , to mean that and . The following theorem is a trivial consequence of these definitions.
Theorem 1. Suppose is a poset. Consequently,
If , then is also a poset,
, and
if and , then , where .
If X is a set, then for any pair the set has a least upper bound and a greatest lower bound, namely and , respectively. Thus, with . The greatest lower bound and least upper bound of a subset are commonly denoted by glb and lub, respectively. Similarly, if , then lub and glb, so that and . The notions of least upper bound and greatest lower bound are key in defining the concept of a lattice.
More generally, if P is a poset and , then the infimum denoted by , if it exist, is the greatest element in P that is less than or equal to all elements of X. Likewise, the supremum written as , if it exists, is the least element in P that is greater than or equal to all elements of X. Consequently, the infimum and supremum correspond, respectively, to the greatest lower bound and the least upper bound.
A few fundamental types of posets are described next: (1) A lattice is a partially ordered set L such that for any two elements , and exist. If L is a lattice, then we denote by and by , respectively. The expression is also referred to as the meet or min of x and y, while is referred to as the join or max of x and y. (2) A sublattice of a lattice L is a subset X of L such that for each pair , we have that and . (3) A lattice L is said to be complete if and only if for each of its subsets X, and exist. The symbols and are also commonly used for and , respectively.
Suppose
L is a lattice and also an additive Abelian group, which we denote by
. Now, consider the function
defined by
. If
, then
and
since
. Likewise, if
, then
and
. Therefore,
. Similarly,
. This verifies the dual equations:
signifying that the function
is a dual isomorphism for any fixed pair
. Thus, in any lattice Abelian group the following identities hold:
These equations easily generalize to,
hence, if
, then,
Some of the most useful computational tools for applications of lattice theory to real data sets are mappings of lattices to the real number system. One family of such mappings are valuation functions.
Definition 2. A valuation on a lattice L is a function that satisfies: A valuation is said to be isotone if and only if and positive if and only if .
The importance of valuations on lattices is due to their close association with various measures. Among these measures are pseudometrics and metrics.
Theorem 2. If L is a lattice and v is an isotone valuation on L, then the function defined by:satisfies, , the following conditions: and ,
,
, and
.
An elegant proof of this theorem is provided by Birkhoff in [
25]. In fact, the condition:
or equivalently,
, yields the following corollary of Theorem 2.
Corollary 1. Suppose L is a lattice and v is an isotone valuation on L. The function is a metric on L if and only if the valuation v is positive.
The metric d defined on a lattice L in terms of an isotone positive valuation is called a lattice metric or simply an ℓ-metric, and the pair is called a metric lattice or a metric lattice space. The importance of ℓ-metrics is due to the fact that they can be computed using only the operations of ∨, ∧, and + for lattices that are additive Abelian groups. For the lattice group , they require far less computational time than any metric whenever . Just as different norms give rise to different metrics on , different positive valuations on a lattice will yield different ℓ-metrics. For instance, if , then the two positive valuations and define two different ℓ-metrics on L. In particular, we have:
Theorem 3. For , the induce metrics and on are given by, Proof. Considering (
1) through (4) establishes the following equalities:
Replacing the sum ∑ by the maximum operation ⋁ and using an analogous argument proves the second equality in (
10) of the theorem. □
In addition to ℓ-metrics, valuations also give rise to similarity measures. A similarity measure is a measure that for a given object x tries to decide how similar or dissimilar other objects are when compared to x. For objects represented by vectors, distance measures such as metrics, measure numerically how unlike or different two data points are, while similarity measures find numerically how alike two data points are. In short, a similarity measure is the antithesis of a distance measure since a higher value indicates a greater similarity, while for a distance measure a lower value indicates greater similarity. There exists an assortment of different similarity measures, depending on the sets, spaces, or lattices under consideration. Specifically, for lattices we have the following,
Definition 3. If L is a lattice with , then a similarity measure for is a mapping defined by the following conditions:
,
, and
.
The basic idea is that if has more features in common with z than any other or if y is closer to z than any other in some meaningful way, then . As an aside, there is a close relationship of similarity measures with fuzzy sets. Specifically, if , then is a fuzzy set with membership function .
3. Lattice Biomimetic Neural Networks
In ANNs endowed with dendrites whose computation is based on lattice algebra, a set
of presynaptic neurons provides information through its axonal arborization to the dendritic trees of some other set
of postsynaptic neurons [
26,
27,
28].
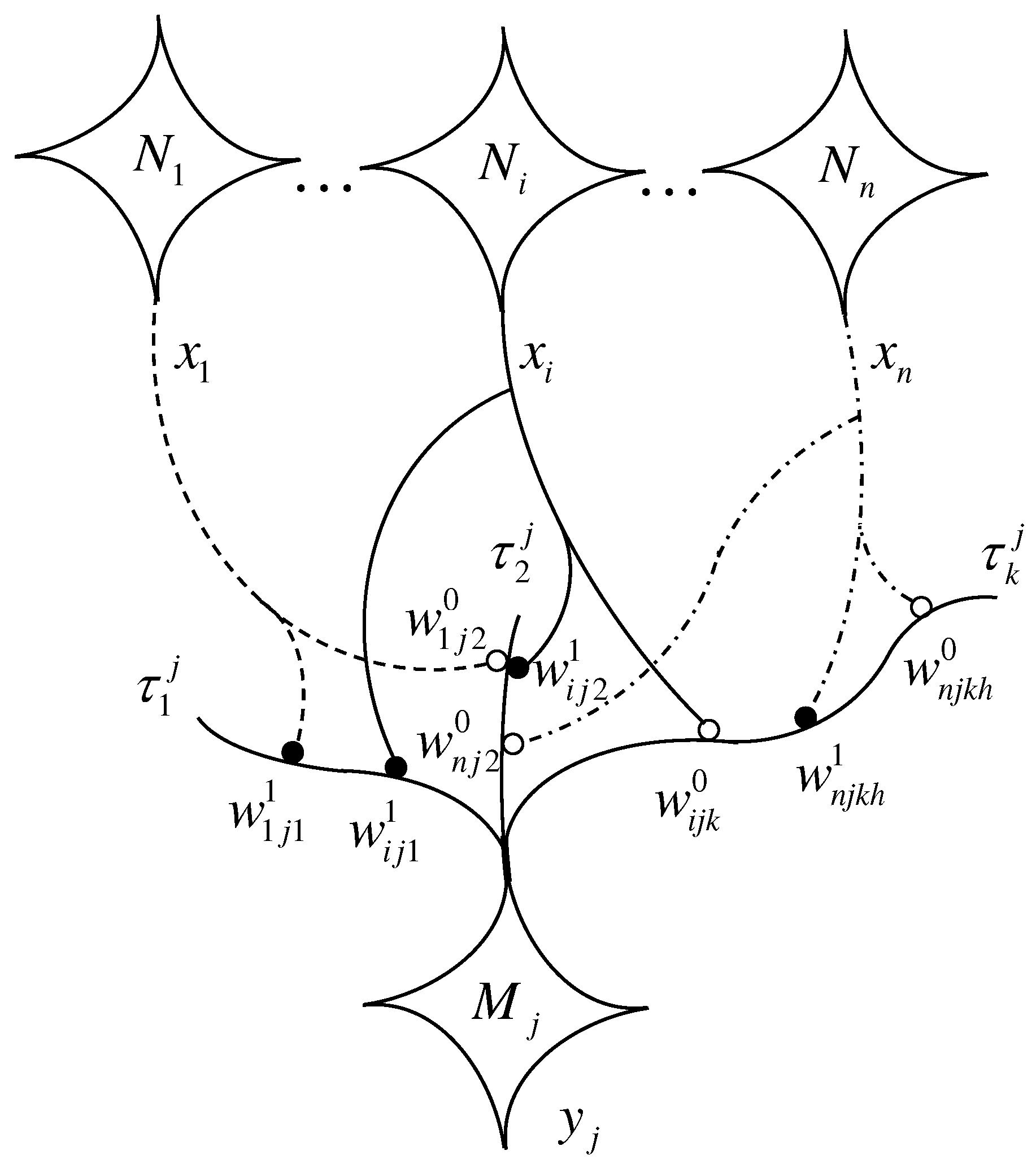
Figure 1 illustrates the neural axons and branches that go from the presynaptic neurons to the postsynaptic neuron
, whose dendritic tree has
branches, denoted by,
and containing the synaptic sites upon which the axonal fibers of the presynaptic neurons terminate. The address or location of a specific synapse is defined by the quintuple
, where
,
, and
, that a terminal axonal branch of
has a bouton on the
k-th dendritic branch
of
. The index
denotes the
h-th synapse of
on
since there may be more terminal axonal branches of
synapsing on
. The index
classifies the type of the synapse, where
indicates that the synapse at
is inhibitory (i.e., releases inhibitory neurotransmitters) and
indicates that the synapse is excitatory (releases excitatory neurotransmitters).
The strength of the synapse corresponds to a real number, commonly referred to as the synaptic weight and customarily denoted by . Thus, if S denotes the set of synapses on the dendritic branches of the set of the postsynaptic neurons , then w can be viewed as the function, , defined by where . In order to reduce notational overhead we simplify the synapse location and type as follows:
if and set (single input neuron),
if , set (single output neuron) and denote its dendritic branches by (multiple dendrites) or simply if (single dendrite), and
if (at most one synapse per dendrite).
The axon terminals of different presynaptic biological neurons that have synaptic sites on a single branch of the dendritic tree of a postsynaptic neuron may release dissimilar neurotransmitters, which, in turn, affect the receptors of the branch. Since the receptors serve as storage sites of the synaptic strengths, the resulting electrical signal generated by the branch is the result of the combination of the output of all its receptors. As the signal travels toward the cell’s body it again combines with signals generated in the other branches of the dendritic tree. In the lattice based biomimetic model, the various biological synaptic processes due to dissimilar neurotransmitters are replaced by different operations of a lattice group. More specifically, if represents the operations of a lattice group G, then the generic symbols ⊕, ⊗, and ⊙ will mean that , but are not explicitly specified numerical operations. For instance, if and , then , and if , then .
Let
and let
be the switching value that signals the final outflow from the
k-th branch reaching
; if excitatory, then
or if inhibitory then
. Also, let
represent the index set corresponding to all presynaptic neurons with terminal axonal fibers that synapse on the
k-th dendrite of
, and let
be the number of synaptic knobs of
contacting branch
. Therefore, if
sends the information value
via its axon and attached branches, the total output (or response) of a branch
to the received input at its synaptic sites is given by the general formula:
The cell body of
receives
, and its state is a function of the combined values processed by its dendritic structure. Hence, the state of
is computed as,
where
denotes the response of the cell to the received input. As explained before,
(excitation) means acceptance of the received input and
(inhibition) means rejection. This mimics the summation that occurs in the axonal hillock of biological neurons. In many applications of lattice neural networks (LNNs), the presynaptic neurons have at most one axonal bouton synapsing (
) on any given dendritic branch
. In these cases, (
11) simplifies to,
As in most ANNs, the next state of
is determined by an activation function
, which—depending on the problem domain—can be the identity function, a simple hard limiter, or a more complex function. The next state refers to the information being transferred via
’s axon to the next level neurons or the output if
is an output neuron. Any ANN that is based on dendritic computing and employs equations of type (
11) and (
12), or (
13) and (
12), will be called a lattice biomimetic neural network (LBNN). In the technical literature, there exist a multitude of different models of lattice based neural networks. The matrix based lattice associative memories (LAMs) discussed in [
22,
24,
29,
30] and LBNNs are just a few examples of LNNs. What sets LBNNs apart from current ANNs are the inclusion of the following processes employed by biological neurons:
The use of dendrites and their synapses.
A presynaptic neuron can have more than one terminal branch on the dendrites of a postsynaptic neuron .
If the axon of a presynaptic neuron has two or more terminal branches that synapse on different dendritic locations of the postsynaptic neuron , then it is possible that some of the synapses are excitatory and others are inhibitory to the same information received from .
The basic computations resulting from the information received from the presynaptic neurons takes place in the dendritic tree of .
As in standard ANNs, the number of input and output neurons is problem dependent. However, in contrast to standard ANNs where the number of neurons in a hidden layer, as well as the number of hidden layers are pre-set by the user or an optimization process, hidden layer neurons, dendrites, synaptic sites and weights, and axonal structures are grown during the learning process.
Substituting specific lattice operations in the general Equations (
11) and (
12) results in a specific model of the computations performed by the postsynaptic neuron
. For instance, two distinct specific models are given by,
or,
Unless otherwise mentioned, the lattice group
will be employed when implementing Equations (
11) and (
12) or (
13) and (
12). In contrast to standard ANNs currently in vogue, we allow both negative and positive synaptic weights as well as weights of value zero. The reason for this is that these values correspond to positive weights if one chooses the algebraically equivalent lattice group
, where
. The equivalence is given by the bijection
, which is defined by
. Consequently, negative weights correspond to small positive weights and zero weights to one.
4. Similarity Measure Based Learning for LBNNs
The focus of this section is on the pattern recognition capabilities of LBNNs. In particular, on how a lattice biomimetic neural network learns to recognize distinct patterns. However, since the learning method presented here is based on a specific similarity measure, we begin our discussion by describing the measure used [
31]. The lattice of interest in our discussion is
, with
, while the similarity measure for
is the mapping
defined by:
where
v is the isotone positive lattice valuation given by
. We used the lattice
in order to satisfy Condition (1) of Definition 3, and coordinates of pattern vectors considered here are nonnegative. Since data sets are finite, data sets consisting of pattern vectors that are subsets of
have always an infimum
and a supremum
. Thus, if
is a dataset whose pattern vectors have both negative and nonnegative coordinates, simply compute
and
. Note that the hyperbox
is a complete lattice and
. Setting
, then
and
. Finally, define the mapping
by setting
where
and
. It follows that
, which proves that Condition (1) of Definition 3 is satisfied, and the remaining two conditions are similarly proven.
There exist several distinct methods for learning in LBNNs. The method described here is novel in that it is based on the similarity measure given in (
16). To begin with, suppose
is a data set consisting of prototype patterns, where each pattern
belongs to one of
m different classes. Here
and we use the expression
if
belongs to class
by some predefined relationship. Letting
, then the association of patterns and their class membership is a subset of
specified by
.
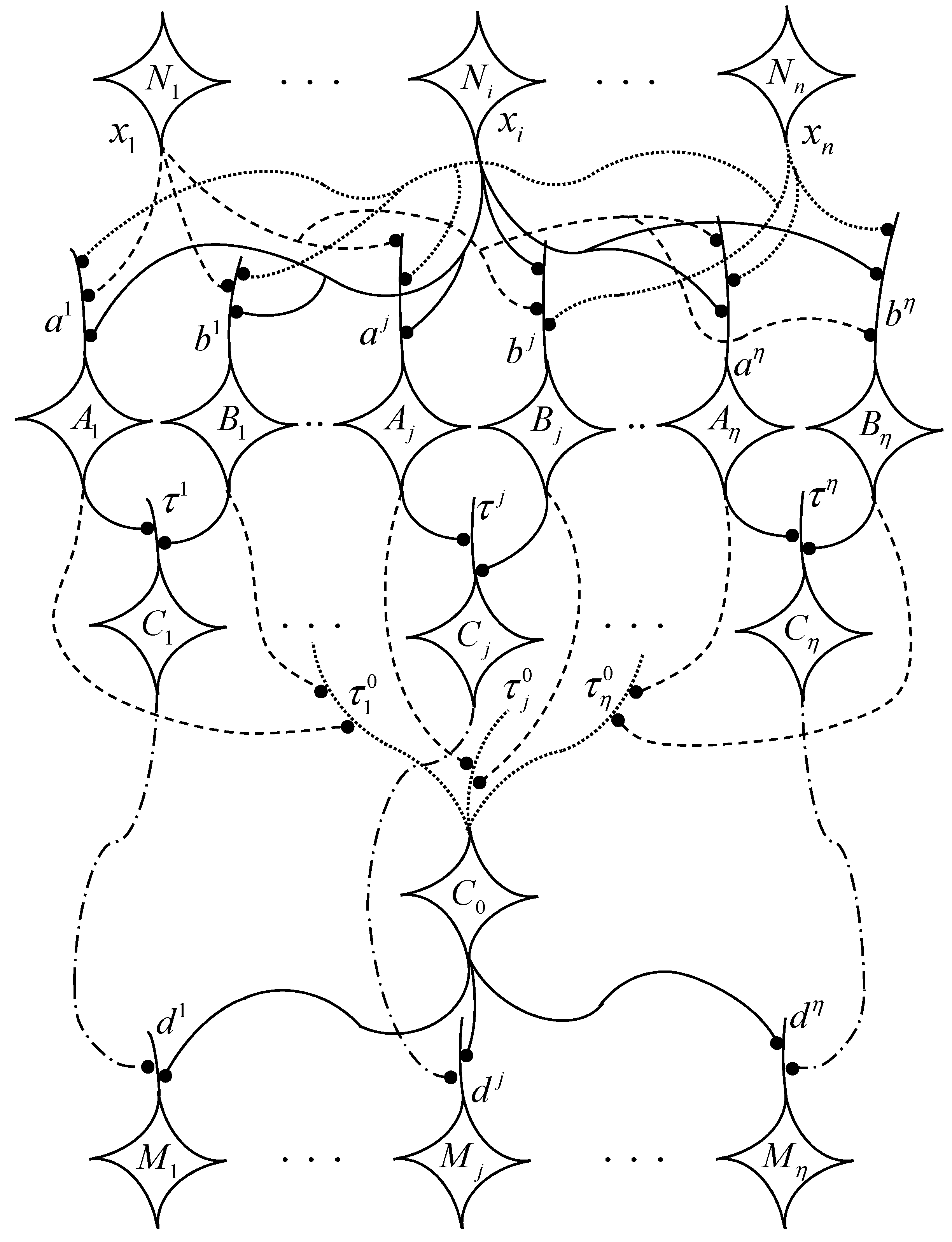
As in most learning methods for artificial neural networks, a lattice biomimetic neural network learns to recognize distinct patterns by using a subset of prototype patterns stored in a hetero-associative memory. Given the data set Q, learning in LBNNs begins with selecting a family of prototypes . The selection is random and the subscript p is a predefined percentage of the total number of the k samples in Q.
After selecting the training set
, precompute the values
for
. These values will be stored at the synaptic sites of the LBNN and in most practical situations
. Knowing the dimension
n and the size of the training set
, it is now an easy task to construct the network. As illustrated in
Figure 2, the network has
n input neurons denoted by
, two hidden layer neurons, and a layer of output neurons. The first hidden layer neurons consist of two different types of neurons denoted by
and
, where
. Each neuron
and
will have a single dendrite with each dendrite having
n synaptic sites. For the sake of simplicity we denote the dendrite of
and of
by
and
, respectively. The second hidden layer has
neurons denoted by
, where
. Here
has multiple dendrites, i.e.,
dendrites denoted by
, with each dendrite having two synaptic sites for
. Any other neuron
with
has one dendrite, with each dendrite having also two synaptic sites. The output layer is made up of
neurons, denoted by
for
, with each neuron
having a single dendrite with two synaptic sites.
In what follows, we describe the internal workings of the network. For a given
, the input neuron
receives the input
, and this information is sent to each of the neurons
and
. For each
, the axonal arborization of
consists of
terminal branches with one terminal on each
and
. The synaptic weight
at the
i-th synapse on
is given by
with
. Each synapse on
at location
results in
upon receiving the information
. The total response of the dendrite
is given by the summation
. In a similar fashion, the synaptic weight
at the
i-th synapse on
is given by
with
. However, here, each synapse on
at location
results in
upon receiving the information
, and each neuron
computes
. This information
and
travels through the soma towards its axon hillock of the respective neurons where the corresponding activation functions are given, for
and
respectively, by:
The information
and
is transferred via the axonal arborization of the first hidden layer neurons to the dendrites of the second layer neurons. The presynaptic neurons of
are all the neurons of the first hidden layer. A terminal axonal fibers of
and one from
terminate on
. The weight at each of the two synapses is
, where
and
,
are address labels for the respective terminal axonal fibers from
and
. Thus, each synapse accepts the information
and
. The total response of the dendrite is given by
. However, the total response of the neuron
is given by:
For
, the presynaptic neurons for the neuron
are the two neurons
and
. Denoting the single dendrite of
by
, then a terminal axonal fibers of
and one from
terminate on
. In lockstep with
, the weight at each of the two synapses is
, where
and
,
are address labels for the respective terminal axonal fibers from
and
. Again, the two synapses accept the information
and
, and the response of the single dendrite is:
The activation function for is the identity function for all . For the output layer, the presynaptic neurons for are the two neurons and . As mentioned earlier, each output neuron has one dendrite with two synaptic regions, one for the terminal axonal bouton of and one for . The synaptic weight at the synapse of on is given by , where and , while the synaptic weight at the synapse of on is given by , with and .
Because the activation function of is the identity function, the input at the synapse with weight is , and since , the synapse accepts the input. Likewise, the input from neuron at the synapse with weight is . However, because , the weight negates the input since . The dendrite adds the results of the synapses so that, . This information flows to the hillock of , and the activation function of is the hard-limiter and if .
Since for , it follows that . Suppose that and . If for any , we have that , then we say that , i. e. winner takes all. If there is another winner that is not a member of , then repeat the steps with a new randomly obtained set . If after several tries, a single winner cannot be found, it becomes necessary to increase the percentage of points in . Note that the method just described can be simplified by eliminating the neuron and using the to neurons as the output neurons. If there is one such that , then , where is the class of . If there is more than one winner where the other winner does belong to class , then repeat the steps with a new set as described earlier.
We close our theoretical description by pointing out the important fact that an extensive foundation with respect to the similarity measure given in Equation (
16) or more precisely the two separate expressions in (
17) has been developed earlier, although with a different perspective in mind, in related areas such as fuzzy sets [
32,
33,
34], fuzzy logic [
35,
36], and fuzzy neural networks [
37]. For example, the scalar lattice functions, defined by
and
, where
,
, and
for
, were treated in [
37]. Also, algorithms for computing subsethood and similarity for interval-valued fuzzy sets for the vectorial counterparts of
f and
g appear in [
38].
5. Recognition Capability of Similarity Measure Based LNNs
Before discussing the issue of interest, we must mention that a previous LNN based on metrics appears in [
39]. The proposed LBNN is trained in a fairly simple way in order to be able to recognize prototype-class associations in the presence of test or non-stored input patterns. As described in
Section 4, the network architecture is designed to work with a finite set of hetero-associations, that we denote by
. Using the prototype-class pairs of a training subset randomly generated from the complete data set, all network weights are preassigned. After weight assignment, non-stored input patterns chosen from a test set can be used to prove the memory network. A test set is defined as the complement of the training set of exemplar or prototype patterns. Clearly, test patterns are elements of one of the
m classes that the LBNN can recognize. If the known class of a given non-stored pattern matches the net output class, correct classification or a hit occurs, otherwise an error of misclassification happens. Consequently, by computing the fraction of hits relative to each input set used to test the network we can measure the recognition capability of the proposed LBNN.
In the following paragraphs, some pattern recognition problems are examined to show the performance classification of our LBNN model based on the similarity measure given in (
19). For each one of the examples described next, a group of prototype subsets
were randomly generated by fixing increasing percentages
, of the total number
k of samples in a given data set
Q. Selected percentages
p belong to the range
and generated test subsets, symbolized as
, were obtained as complements of
with respect to
Q. Computation of the average fraction of hits for each selected percentage of all samples requires a finite number of trials or runs, here denoted by
. Let
and
be the average (over all runs) and the number of misclassified test patterns in each run, then the average fraction of hits is given by,
Note that, if
,
,
, are the cardinalities of the data, prototype, and test sets, respectively, then
. In (
20), we set the number of runs,
, for any percentage
p of the training population sample in order to stabilize the mean value
. Although, for each run with the same value of
p, the number of elements of
and
does not change, the sample patterns belonging to each subset are different since they are selected in random fashion. Also, observe that a lattice biomimetic net trained for some
p with a prototype subset
, can be tested either with the whole data set
or with the test set
.
We will use a table format to display the computational results obtained for LBNN learning and classification of patterns for the example data sets, to give the mean capability performance in recognizing any element in Q. Each table is composed of six columns; the first column gives the dataset characteristics; the second column gives the percentage p of sample patterns used to generate the prototype and test subsets; the third column provides the number of randomly selected prototype patterns, and the fourth column gives the number of test patterns. The fifth column shows the average number of misclassified inputs calculated using the similarity lattice valuation measure and the sixth column gives the corresponding average fraction of hits for correct classifications.
5.1. Classification Performance on Artificial Datasets
The following two examples are designed to illustrate simple data sets with two and three attributes that can be represented graphically as scatter plots, respectively, in two and three dimensions. We remark that both sets are build artificially and do not correspond to data sets coming from realistic measurements taken from a real-world situation or application.
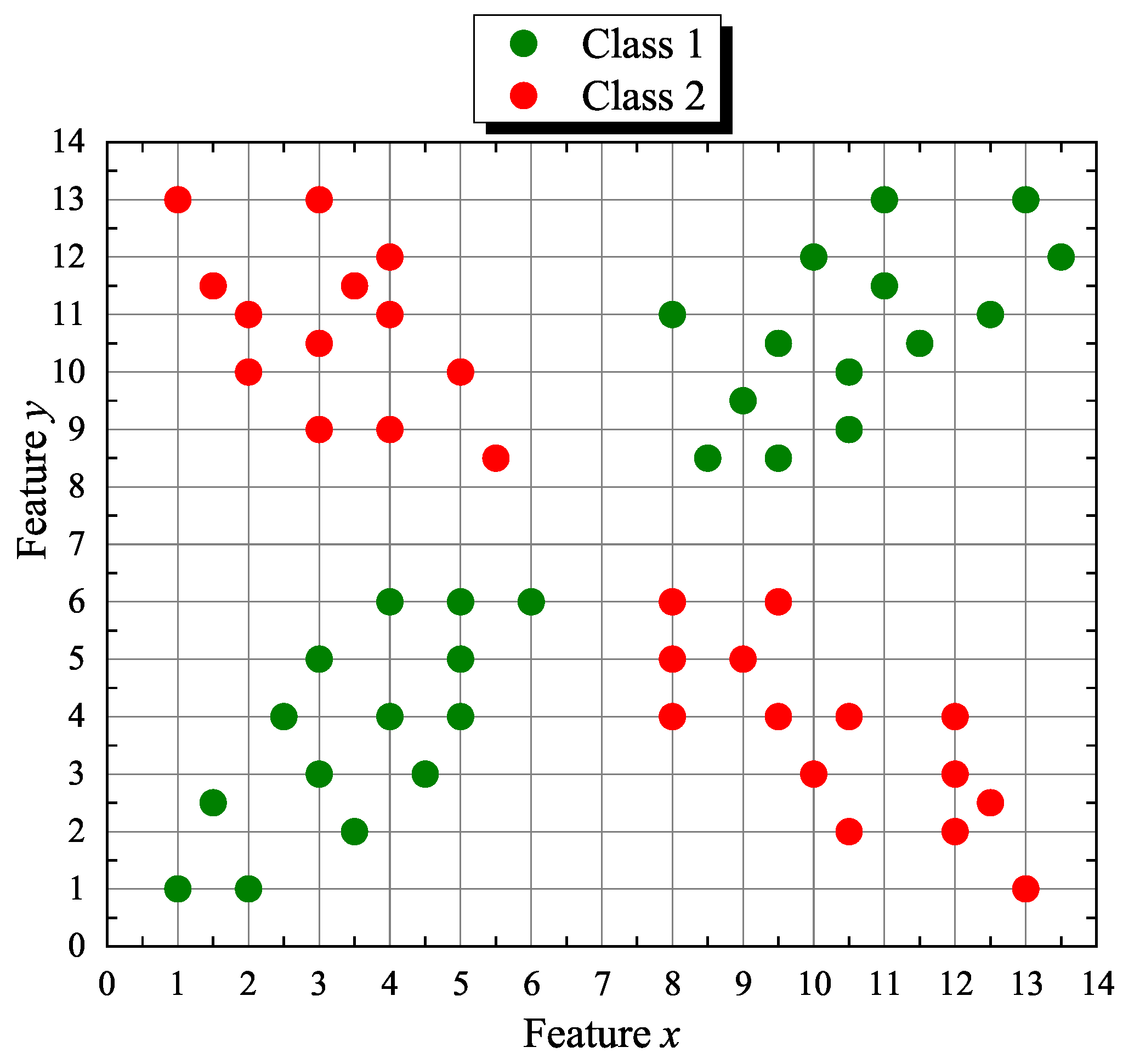
Our first artificial or synthetic data set
Q forms a discrete planar “X” shape with 55 points (samples) where coordinates
x and
y correspond to its two features. The points are distributed in two classes
where
. The corresponding 2D scatter plot is shown in
Figure 3. Similarly, the second synthetic set
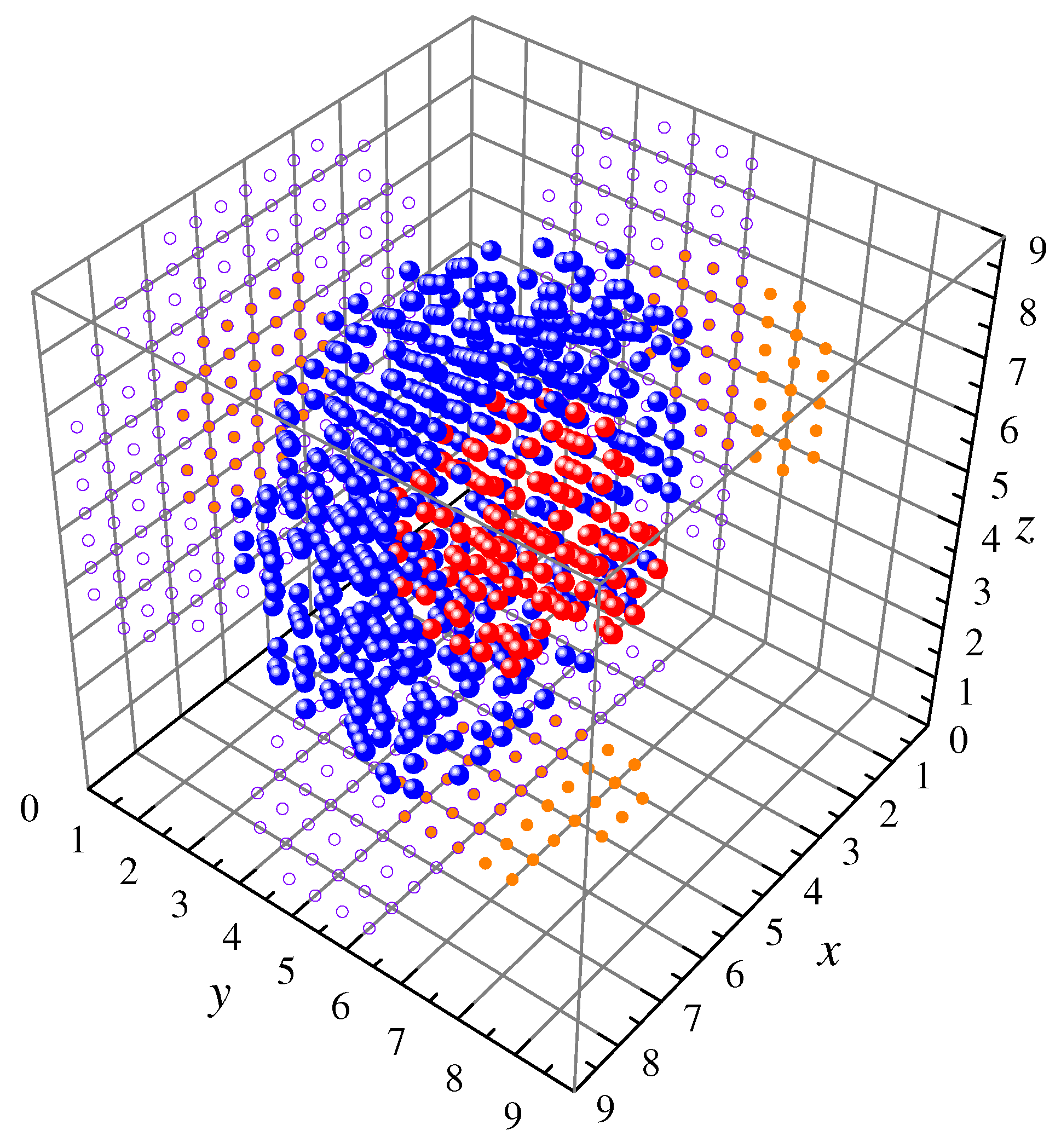
Q consists of 618 samples defined in the first octant of
. Points in class
belong randomly to a hemisphere of radius
centered at
with a hemispherical cavity of radius
concentric to the larger hemisphere and class
points belong, also randomly, to a sphere of radius
embedded in the cavity formed by class
points. Again, features are specified by the
x,
y, and
z coordinates and the corresponding three-dimensional scatter plot is depicted in
Figure 4.
Table 1 gives the numerical results for the “X-shape” (X-s) and “Hemisphere-sphere” (H-s) datasets.
The last column in
Table 1 shows the high classification rates achieved by training the similarity valuation based LBNN with, at least half the number of samples, and repeating the learning procedure several times in random fashion. For the sake of completeness, we explain graphically, using the X-shaped dataset, how the lattice based neural network shown in
Figure 2 assigns a class label to input patterns once the network is trained with a randomly generated prototype subset
of
Q setting
. Specifically,
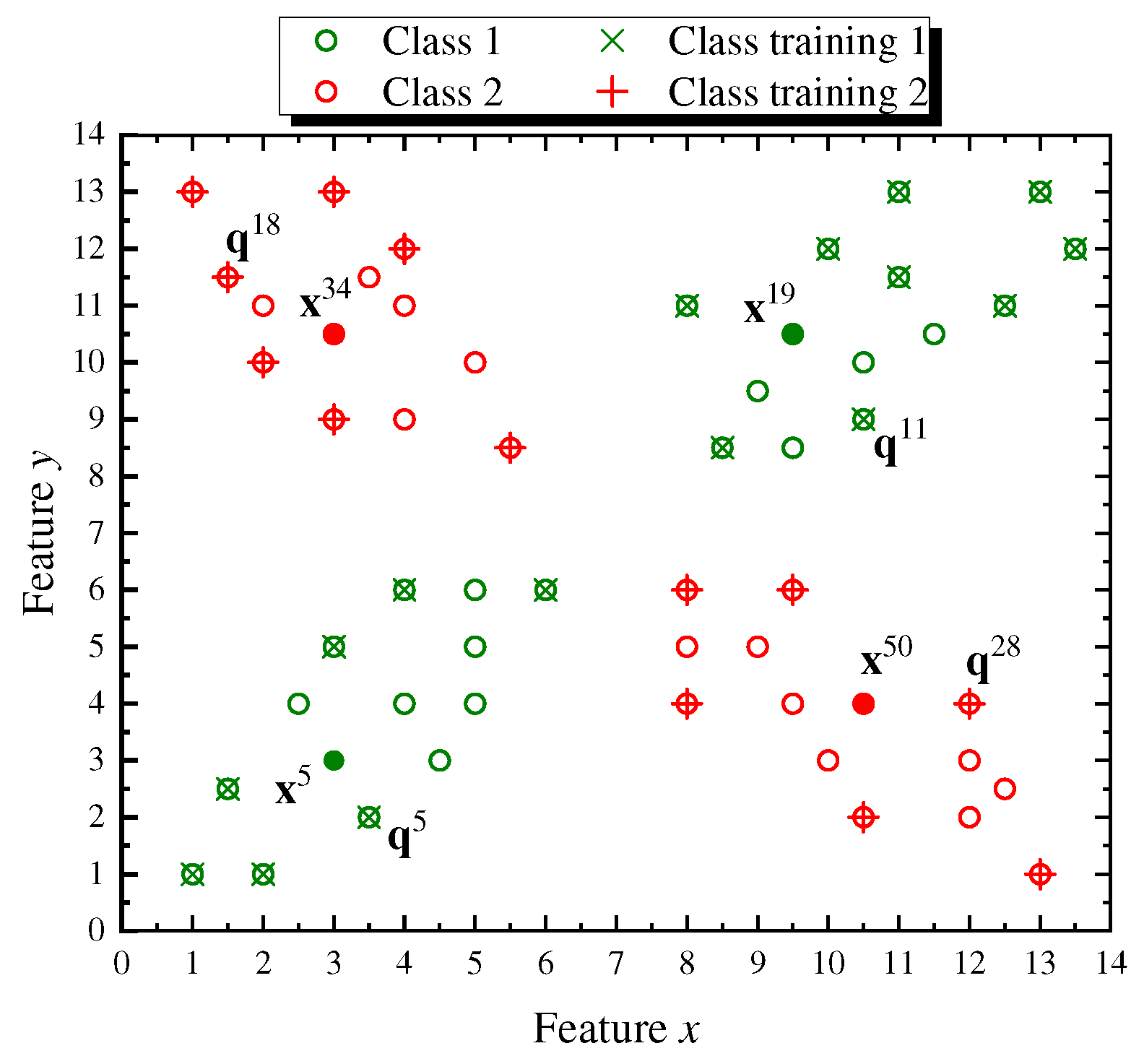
Figure 5 displays the
points in
Q that form the X-shaped set, where the point circles crossed with the symbol “×” (in olive green) denote class
training data and the point circles marked with a “+” sign (over the red circles) are class
training data totaling 29 elements belonging to
. In the same figure, test points
,
,
, and
, selected from the 26 elements of
, are shown as filled colored dots and its class is determined based on the neural similarity lattice valuation measure response given in (
18).
As can be seen in
Figure 5, class
is correctly attached to the test points,
and
, since the maximum similarity valuation measure computed using (
18), is obtained, respectively, for the training points,
and
, which are elements of
. Analogously, class
is correctly assigned to the test points,
and
, since the maximum similarity valuation measure is found for the training points,
and
, data elements of
. More specifically, the explicit calculation expression corresponding to (
18) for testing any point
is given by,
We end our discussion about the X-shaped artificial dataset by showing the similarity valuation measure graphs of the selected test points,
. Hence,
Figure 6 displays from top to bottom the similarity measure curves whose domain is the data training subset
and with values ranging on the interval
. The maximum similarity value
is represented with the symbol ▿ and the corresponding training pattern index within the set
is found at the bottom of the dropped vertical line (dashed). The LBNN then assigns the correct class to each one of the selected test points as depicted in the same figure with respect to the line dividing both classes.
5.2. Classification Performance on Real-World Application Datasets
Various application examples available at the UCI Machine Learning Repository [
40] are described and discussed in this subsection in order to exhibit the similarity valuation LBNN classification performance. The numeric results are compiled in
Table 2 that has the same organization as explained in the previous subsection on artificial datasets. However, in
Table 2 each block of rows in a given example is separated by a horizontal line.
Example 1. The “Iris” dataset has 150 samples where each sample is described by four flower features (sepal length, sepal width, petal length, petal width) and is equally distributed into three classes , , and , corresponding, respectively, to the subspecies of Iris setosa, Iris versicolor, and Iris virginica. A high average fraction of hits such as is obtained for percentages . The similarity valuation trained LBNN used as an individual classifier delivers similar performance against linear or quadratic Bayesian classifiers [41] for which and , respectively, or in comparison with an edge-effect fuzzy support vector machine [42] whose . Example 2. The “Column” dataset with 310 patient samples is specified by six biomechanical attributes derived from the shape and orientation of the pelvis and lumbar spine. Attributes 1 to 6 are numerical values of pelvic incidence, pelvic tilt, lumbar lordosis angle, sacral slope, pelvic radius, and grade of spondylolisthesis. Class of patients diagnosed with disk hernia has 60 samples, class of patients diagnosed with spondylolisthesis 150 samples, and class of normal patients 100 samples. Since feature 6 has several negative entries, the whole set is displaced to the positive octant of by adding to every vector in Q. In this case, a high average fraction of hits occurs for percentages p greater than , which is due to the presence of several interclass outliers. However, the LBNN with much less computational effort is still good if compared with other classifiers such as an SVM (support vector machine) or a GRNN (general regression neural network) [43] (with all outliers removed), which both give . Example 3. The “Wine” dataset has 178 samples subject to chemical analysis of wines produced from three different cultivars (classes) of the same region in Italy. The features in each sample represent the quantities of 13 constituents: alcohol, malic acid, ash, alkalinity of ash, magnesium, phenols, flavonoids, nonflavonoid phenols, proanthocyanins, color intensity, hue, diluted wines, and proline. Class has 59 samples, class 71 samples, and class 48 samples. In this last example, a high average fraction of hits occurs for percentages p greater than , and the LBNN performance is quite good if compared with other classifiers, based on the leave one-out technique, such as the 1-NN (one-nearest neighbor), LDA (linear discriminant analysis), and QDA (quadratic discriminant analysis) [44], which give, correspondingly, , , and , where , and training must be repeated times. Although not shown in Table 2, the LBNN net gives , since almost all samples in the given dataset are stored by the memory as prototype patterns. However, our LBNN model is outperformed by a short margin of misclassification error (), since , if compared to an FLNN classifier (fuzzy lattice neural network) that gives (leave-25%-out) [45]. 6. Conclusions
This paper introduces a new lattice based biomimetic neural network structured as a two hidden layer dendritic lattice hetero-associative memory whose total neural response is computed using a similarity measure derived from a lattice positive valuation. The proposed model delivers a high ratio of successful classification for any data pattern considering that the network learns random prototype patterns with a percentage level from up to of the total number of patterns belonging to a data set.
More specifically, the new LBNN model provides intrinsic capacity to tackle multivariate- multiclass problems in pattern recognition pertaining to applications whose features are specified by data measured numerically. Our network model incorporates a straightforward mechanism whose topology implements a similarity function defined by simple lattice arithmetical operation used to measure the resemblance between a set of
n-dimensional real vectors (prototype patterns) and a test input
n-dimensional vector, in order to match its class. Representative examples, such as the “Iris”, the “Column”, and the “Wine” datasets, were used to carry on several computational experiments to obtain the average classification performance of the proposed LBNN for diverse randomly generated test subsets. Furthermore, the proposed LBNN model can be applied in other areas such as cryptography [
46] or image processing [
47,
48,
49,
50].
The results given in this paper are competitive and look promising. However, future work with the LBNN classifier contemplates computational enhancements and comparisons with other challenging artificial and experimental data sets. Additionally, further analysis is required to deal with important issues such as data test set design, theoretical developments based on different lattice valuations, and comparisons with recently developed models based on lattice computing. We must point out that our classification performance experiments are actually limited due to its implementation in standard high-speed sequential machines. Nonetheless, LBNNs as described here and in early writings, can work in parallel using dedicated software or implemented in hardware to increase computational performance. Hence, a possible extension is to consider algorithm parallelization using GPUs or hardware realization as a neuromorphic system.









{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}