Abstract
Online reviews of hotels reflect tourist perception and evaluation, which are becoming an important perspective of studying hotel selection. In this paper, we prefer to use a probabilistic linguistic term set (PLTS) to fully reveal evaluation grades and the corresponding probability distribution in the online reviews of hotels. In this way, we propose a novel stochastic dominance-based approach based on stochastic dominance degrees of PLTSs and a stochastic multi-criteria acceptability analysis (SMAA) method that tolerates missing information. Among them, first-, second-, and third-order stochastic dominance degrees of PLTSs are calculated on the premise that the dominance relationships between PLTSs can be defined based on first-, second-, and third-order stochastic dominance rules of PLTSs. Based on these basic researches, five hotels are selected as alternatives in our case study to verify the validity and feasibility of the proposed approach. In the end, data analysis illustrates the influence of parameter and linguistic scale functions and how to choose appropriate parameter values. Furthermore, comparative analysis with other methods shows the stability of the proposed approach.
1. Introduction
With the development of network technology, different hotel reservation platforms are designed to facilitate people to choose and book hotels on the website. Location, environment, price and service facilities of different star hotels are exhibited on these platforms in detail. In addition, numerous reviews of hotels that are given by former tourists provide supplement features of hotels [1]. Practically, several factors such as price and location are taken into consideration when tourists choose hotels on the website. In other words, hotel selection is a complicated multi-criteria decision-making problem, which means that tourists should select favored hotels from hotel listings with considering these factors [2]. Hence, many studies that focused on hotels’ factors, tourists’ preferences and purposes have been conducted to help tourists make choices and provide managers with an insight into tourists’ preferences [3].
From the point of decision-making theory, each tourist is also an evaluator, and factors are identified as criteria [2,4]. Online reviews that are composed of ratings and natural language are used to evaluate hotels involved with multiple criteria [5,6]. During the solutions, some problems should be considered and solved firstly, such as how to extract valuable information from massive online reviews for further processing, or how to describe information. As we can see on the website, although different people optionally give their reviews, the numerous reviews about hotels’ criterion service are basically ‘good’, ‘bad’, and ‘excellent’. In this situation, a probabilistic linguistic term set (PLTS) composed by linguistic terms and probability values can be used to describe these reviews under different criteria correctly and precisely [7]. Subsequently, Gou and Xu [8] redefined some operational laws for PLTSs based on two equivalent transformation functions. Bai et al. [9] proposed a new possibility degree formula for PLTSs rating. Wu and Liao [10] proposed a probability aggregation method to integrate the individuals’ subjective evaluations into group ones expressed as PLTSs. Based on PLTS and relevant theory, Song et al. [11] proposed a novel text representation model named Word2PLTS for short text sentiment analysis. The superiority of PLTS attracts researchers to conduct studies to solve different problems [4,12,13,14,15,16,17]. Considering the advantage of PLTS in expressing massive online reviews of hotels, PLTS is used to describe these online hotel reviews in our study. Reviews containing natural language and ratings can be transformed into linguistic terms, and the frequency of each common review can be defined as the probability value of the corresponding linguistic term.
Explosive growth of online reviews about hotels on these platforms aggravate complication of hotel selection problems. For example, famous hotels tend to be preferred choice of tourists in most cases, and amount of online reviews for these hotels would exceed five thousand, even over ten thousand. Comments about any hotel service might be depicted by a PLTS . In this PLTS, , , , and stand for ‘excellent’, ‘very good’, ‘average’, ‘poor’, and ‘terrible’, respectively. Future tourist’s experience of this hotel’s service may be ‘excellent’ or ‘poor’. Based on this idea, the linguistic terms are treated as discrete random variables, and probability values of corresponding linguistic terms can be defined as the probability distribution of these discrete random variables. Therewith a probabilistic linguistic multi-criteria decision-making (PLMCDM) problem can be defined as a stochastic multi-criteria decision-making (SMCDM) problem. In addition, in this case in which evaluation values are random variables, how to calculate weights of hotel’s criteria is another difficult issue. To deal with random variables, Martel and Zaras [18] considered a stochastic dominance set that consists of First-degree Stochastic Dominance (FSD), Second-degree Stochastic Dominance (SSD) and Third-degree Stochastic Dominance (TSD). For the weight problem, Lahdelma et al. [19] proposed a stochastic multi-criteria acceptability analysis (SMAA) method to deal with imprecise weight information by exploring the weight space and obtained the most preferred weights of criteria. Stochastic dominances and the SMAA method have been researched and proved to solve SMCDM problems effectively in the last two decades [20,21,22]. However, the PLMCDM method based on stochastic dominance and the SMAA method has not been proposed and used to solve actual hotel selection problems.
The above issue should be solved in stages. The processing stages and our contributions are summarized as follows.
(1) Online hotel reviews are generated naturally on the website. We tend to treat linguistic terms of PLTS as discrete random variables, and calculate probability values of corresponding linguistic terms as a probability distribution of these discrete random variables.
(2) First-, second-, and third-order stochastic dominance rules of PLTSs are defined with different conditions. Moreover, first-, second-, and third-order stochastic dominance degrees of PLTSs are stated on the premise that stochastic dominance rules exist. Some theorems and properties are also proved to explain the meanings and features of these rules and degrees.
(3) Quality decision results are related to the accuracy of the information. Weights of criteria and evaluation values under different criteria on the website may often be missing. Thus, we construct a novel approach based on the SMAA method that tolerates missing information to deal with online hotel reviews and obtain reliable decision result in this paper.
On account of above analysis, cumulative distribution functions, stochastic dominance rules and stochastic dominance degrees are defined. Then, a novel approach is proposed based on stochastic dominance degrees and the SMAA method. The remainder of this paper is organized as follows. Related literature is reviewed and analyzed in Section 2. Some basic researches including stochastic dominance rules and stochastic dominance degrees are conducted in Section 3. A novel approach based on stochastic dominance degrees and the SMAA method is proposed in Section 4. A case study is presented to illustrate the feasibility and availability of the proposed approach in Section 5. Finally, originality, limitations, and further works are concluded in Section 6.
2. Literature Reviews
2.1. Studies on Transformation of Online Hotel Reviews
As a type of emerging information resource on the website, online hotel reviews have their uniqueness, such as public availability, and have an important impact on hotel selection [23]. According to the online reviews, researchers studied tourists’ basic requirements and preferences of hotels [24], and travel platforms could offer hotels’ ranking to help tourists choose a satisfying hotel [25,26,27]. Online hotel reviews contain review ratings and review texts [28]. Review ratings are a quantitative evaluation and review texts are in-depth qualitative analysis of hotels [29]. The lengthier review texts are more useful and enjoyable than shorter review texts [30]. However, the correlativity between ratings and hotels list can help tourists choose a hotel in a much simpler and more intuitive manner, and review texts that include less valuable information may have bad readability [29]. Thus, considering determinacy of ratings and complexity of texts, we focus on online hotel review ratings to conduct a case study in Section 5.
Hotel ratings are represented in ‘five-stars’, ‘four-stars’ and so forth. Although we can understand what these stars mean, we cannot use them directly in the operation process. Transforming hotel review ratings into computable values plays an important role in solving hotel selection problems. Several researchers began looking at the transformation and some methods were designed. Li et al. [31] normalized hotel rating scores into the range [0,1] before fitting them into computational function. Analogously, Gavilan et al. [32] used a 1–10 scale and four quartiles to differentiate these ratings. However, the meanings of ratings are close to the natural language. Therefore, for preferably keeping comprehensive information of ratings, several fuzzy sets are used to describe review ratings. Based on analyzing hotel’s reviews, Yu et al. [33] collected linguistic assessment values given by evaluators and expressed these values with interval type-2 trapezoidal fuzzy numbers (IT2FNs), and then an extended multi-attributive border approximation area comparison (MABAC) method based on the likelihood of IT2FNs. By utilizing the advantage of PLTS in depicting large linguistic values, Peng et al. [34] defined a novel concept of a probabilistic linguistic integrated cloud (PLIC) and established the hotel decision support model based on the essential algorithms and distance measure of PLICs.
2.2. Studies on Stochastic Multi-Criteria Decision-Making Problem
The common methods that are used to solve SMCDM problems are stochastic dominance method [35] and SMAA method [19]. Because of the variability and complexity of actual SMCDM problems, extended approaches based on the stochastic dominance method and SMAA method were proposed and applied in various fields. Furthermore, our proposed approach also has great relations with the stochastic dominance method and the SMAA method. As a result, studies on the above two methods are reviewed in detail in this section.
Stochastic dominance rules were defined to compare alternatives and construct dominance relations between alternatives, and then a stochastic dominance method was proposed [35]. Martel and Zaras [18] considered a stochastic dominance set composed of FSD, SSD and TSD, and then defined three stochastic dominances detailly. In order to deal with project evaluation problems of taking qualitative and quantitative information into consideration, Zaras [36] applied deterministic, stochastic, and fuzzy evaluations to build mixed-data multi-attribute dominance relations, and proposed a method based on the dominance-based rough set approach. Nowak [37] distinguished situations of strict and weak preference based on stochastic dominance rules and preference threshold, and then constructed a ranking method based on the ELECTRE-III method. Subsequently, Nowak [38] utilized stochastic dominance to generate efficient actions and constructed rankings of actions with respect to criteria, and proposed a new interactive technique for a discrete stochastic multiattribute decision making problem. However, overall ranking result of alternatives cannot be obtained based on dominance relationships between each alternative. Thus, Zhang et al. [39] defined stochastic dominance degree to describe the degree that one alternative dominated another alternative, and developed a method based on the PROMETHEE-II to obtain the overall ranking result of alternatives. In addition, the concept of stochastic dominance degree is applied to different methods to solve actual stochastic dominance problems [40,41].
Compared with the stochastic dominance method, the SMAA method that explored the weight space was suited to handle uncomplete weight information and random variables [19]. In order to consider all ranks in analysis, Lahdelma and Salminen [42] extended the original SMAA to the SMAA-2 method that could be used to identify good compromise candidates. Based on ELECTRE III-type pseudo-criteria (double threshold model), Lahdelma and Salminen [43] further extended original SMAA to the SMAA-3 method to deal with preference structure and inaccuracy of criteria. Along with these extended SMAA methods, not only other extended methods but also integrated methods of composing the SMAA method and classical decision methods were proposed under different situations. Considering the whole space of preference parameters compatible with the decision maker’s preference, Angilella et al. [44] integrated the SMAA method with the Choquet integral preference model to get robust recommendations. Corrente et al. [45] applied the SMAA method to the classical PROMETHEE method and to the bipolar PROMETHEE method. Okul et al. [46] developed the SMAA-TOPSIS method to analyze drug benefit-risk and select a machine gun. To address uncertainties that exist in TODIM at the same time, Zhang et al. [47] put forward the SMAA-TODIM method to explore simultaneously the uncertainties inherent. Govindan et al. [48] proposed a hybrid SMAA-ELECTRE I method to exploit all parameters of an outranking model compatible with the incomplete preference information, and then selected a reverse logistics provider. A series of SMAA methods and SMAA-based methods have been used to handle real-life decision-making problems, and the capacity of these methods in dealing with complex decision problems characterized by the existence of multiple conflicting criteria, uncertain criteria measurements, missing preference information and participation of multiple decision makers have been approved [49].
3. Basic Researches
Some basic definitions about PLTSs are presented before definitions of stochastic dominance rules and stochastic dominance degrees.
Definition 1.
[7] Letbe a linguistic term set (LTS), an PLTS can be defined as:
whereis the linguistic termassociated with the probability, andis the number of all different linguistic terms in.
Definition 2.
Given an PLTS with , then the normalized PLTS can be defined by
where .
Example 1.
Given a linguistic set . Let be a PLTS. Then
Definition 3.
Let be an LTS and be a normalized PLTS. In view of fact that a normalized PLTS contains several linguistic terms and the related probability values, is treated as a discrete random variable. Then, the discrete probability distribution function corresponding to is defined as:
According to Equation (1), the cumulative distribution function can be obtained by
Obviously, another cumulative distribution function that corresponds to values of linguistic terms can be defined based on and linguistic scale functions presented in [50]. is shown as
where is numerical value calculated by linguistic scale function , or . Then new stochastic dominance rules of PLTSs can be defined.
3.1. Stochastic Dominance Rules
Definition 4.
Let and be any two normalized PLTSs. Two cumulative distribution functions and are obtained by utilizing the above transformation process. When the important condition holds, the stochastic dominance rules of and exist and can be defined as follows:
(1) (First-order stochastic dominance rule) dominances in the first order, if and only if , . It can be denoted as or .
(2) (Second-order stochastic dominance rule) dominances in the second order, if and only if , . It can be denoted as or .
(3) (Third-order stochastic dominance rule) dominances in the third order, if and only if , . It can be denoted as or .
Theorem 1.
If () and (), and . Furthermore, .
Proof.
According to the known conditions , , , …, , holds. Then . Thus, . Similarly, . □
In addition, based on the conditions that () and (), (), we can obtain that . Transitivity of first-order stochastic dominance rule is proved as follows.
Property 1.
Let , and be any three normalized PLTSs, and , and be three cumulative distribution functions obtained based on , and . Then the following properties hold.
(1) if , then ;
(2) if , then ;
(3) if , then there is no ;
(4) if and , then .
The proof of the Property 1 is provided in Appendix A.
3.2. Stochastic Dominance Degrees
Though relations between PLTSs can be obtained based on the stochastic dominance rules of PLTSs, certain dominance degrees are unknown. As a result, stochastic dominance degrees of PLTSs are defined to measure the dominance degrees of PLTSs precisely.
Definition 5.
Given . Stochastic dominance degrees of can be defined as follows:
(1) (First-order stochastic dominance degree) If , the first-order stochastic dominance degree is denoted as and calculated by Equation (4).
(2) (Second-order stochastic dominance degree) If , the second order stochastic dominance degree is denoted as and calculated by Equation (5).
where .
(3) (Third-order stochastic dominance degree) If , the second order stochastic dominance degree is denoted as and calculated by Equation (6).
where , , .
Property 2.
, .
The proof of the Property 2 is provided in Appendix B.
Note: The stochastic dominance relation between PLTSs should be confirmed based on first-, second-, third-order stochastic dominance rules, and then the stochastic dominance degrees of PLTSs can be calculated. If not, the stochastic dominance degrees of PLTSs are meaningless.
4. A Novel Stochastic Dominance-Based Approach
In this section, the PLMCDM problem is formulated. A novel stochastic dominance-based approach is then proposed to solve the above problem.
4.1. Problem Formulation
Suppose there are m alternatives denoted by . Each alternative is assessed based on n criteria denoted by . The weight of criterion is unknown and denoted by , where , . Linguistic evaluation values of the LTS are selected to assess alternative with respect to criterion . To reduce the complexity of the calculation, one decision-maker only provides one linguistic evaluation value. However, the linguistic evaluation values increase with the number of decision-makers that are denoted by . Collect the linguistic evaluation values of alternative with respect to criterion separately, and then obtain the number of each linguistic evaluation value . In addition, probability is gained by calculating the ratio of the number of each linguistic evaluation value to the number of decision-makers . Thus, alternative can be evaluated by PLTS (, , ). As a result, the cumulative distribution functions can be obtained based on these PLTSs. A novel stochastic dominance-based approach is proposed based on stochastic dominance degrees and the SMAA method in the following.
4.2. Proposed Approach
The framework of the proposed approach is shown in Figure 1. The decision steps are described after Figure 1.
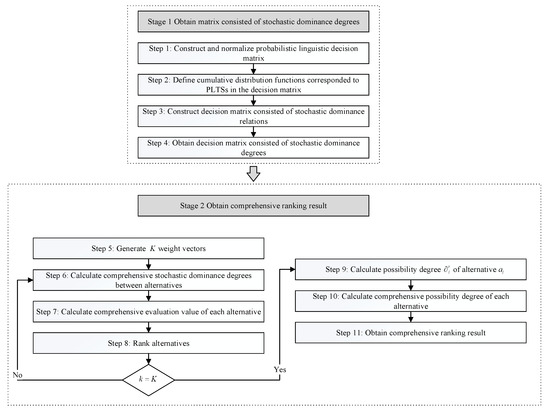
Figure 1.
Procedure of the proposed approach.
Stage 1. Obtain the matrix consisted of stochastic dominance degrees
In this stage, stochastic dominance degrees can be obtained based on Definitions 4 and 5.
Step 1: Construct and normalize the probabilistic linguistic decision matrix.
Basic probabilistic linguistic decision matrix is constructed in terms of criteria and evaluation value , and normalized decision matrix composed of is calculated based on Definition 2 and .
Step 2: Define cumulative distribution functions corresponding to PLTSs in the decision matrix.
Based on Equations (1) and (2), the cumulative distribution function corresponding to can be defined as follows.
Step 3: Construct decision matrix consisted of stochastic dominance relations.
According to the cumulative distribution functions and Definition 4, stochastic dominance relation between alternatives and under criterion can be judged and denoted by . Then
where means that there is no relation between alternatives and under each criterion . Subsequently, the decision matrix consisted of stochastic dominance relation can be constructed and denoted by .
Step 4: Obtain the decision matrix consisting of stochastic dominance degrees.
Based on and Definition 5, stochastic dominance degree between alternatives and under criterion can be calculated by Equation (9).
Thus, decision matrix consisted of stochastic dominance degrees can be obtained.
Stage 2. Obtain comprehensive ranking result.
In this stage, weight vectors are generated to calculate ranking results. The number of ranking results is related to the number of weight vectors.
Step 5: Generate weight vectors.
Each criterion is assigned a number ranging from 0 to 1 at random. The vector consisting of these numbers that satisfies the given constraint condition, such as , turns into weight vector , where and is the number of weight vectors.
Step 6: Calculate comprehensive stochastic dominance degrees between alternatives.
Combine the weight vector and decision matrix consisting of stochastic dominance degrees, and then comprehensive stochastic dominance degree between alternatives and can be calculated as
Step 7: Calculate comprehensive evaluation value of each alternative.
Inspired by the idea of calculating comprehensive evaluation values of alternatives in the TODIM method, comprehensive evaluation values are calculated based on comprehensive stochastic dominance degrees as
Step 8: Rank alternatives.
According to the values of , a ranking result can be obtained. In addition, steps 6–8 are repeated with assigning an integer between 2 and sequentially to the parameter until .
Step 9: Calculate possibility degree of alternative . ranking results are obtained based on steps 5–8. Then, is calculated as the probability that the alternative is placed on the -th position of the ranking results
where is the number of times the alternative is placed on the -th position of the ranking results, and .
Step 10: Calculate the comprehensive possibility degree of each alternative.
Comprehensive possibility degree of each alternative is calculated based on possibility degree and position weight . Generally speaking, position weight decreases with the increase of rank . The value of position weight can be confirmed based upon the idea of linear weight or reverse weight, and it can also be assigned numerical values as needed.
Step 11: Obtain the comprehensive ranking result.
According to values of , the comprehensive ranking results of alternatives are obtained. corresponding with the largest is the best alternative.
5. Case Study
As a leading large-scale travel website, TripAdvisor.com includes more than 500 million online reviews of hotels, restaurants and scenic spots. Furthermore, tens of thousands of online reviews are provided by tourists from different countries daily. Online reviews of a popular hotel can even reach more than 5000. It is difficult for tourists or hotel managers to pick out useful information from numerous online reviews and make decisions. Naturally, a hotel’s ratings on different criteria provided by tourists can be used to help people to understand this hotel fleetingly. Ratings on six criteria of Amari Phuket given by Penny C are presented on the TripAdvisor and shown in Figure 2. In general, although there exist numerous hotels on the TripAdvisor, several hotels can be chosen as alternatives from hotel listings by tourists based on experience. Each of these several hotels often has its advantages and it is difficult for a tourist to choose a suitable hotel. According to our proposed approach and the above analysis, five popular hotels that each has its advantages and disadvantages are selected as alternatives according to TripAdvisor. The five popular hotels denoted by are selected as appropriate alternatives and the best alternative could be picked out according to the novel stochastic dominance-based approach in Section 3. Six criteria, including sleep quality, location, rooms, service, value and cleanliness in Figure 2 that denoted hereafter by and , are used to assess the above five hotels. Five linguistic ratings named excellent, very good, average, poor, and terrible in Figure 3 are used and denoted hereafter by LFS .
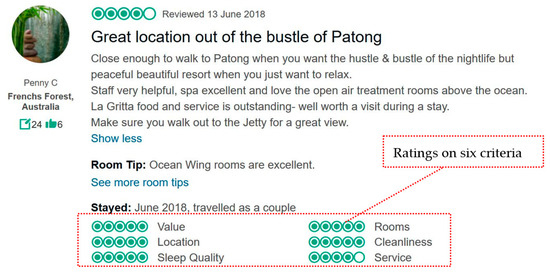
Figure 2.
Ratings on six criteria of Amari Phuket given by Penny C.
Figure 3.
Five ratings on TripAdvisor.
For one hotel, different linguistic ratings given by travelers under each criterion are collected and the ratio of the number of each linguistic rating to the number of this hotel’s reviews can be calculated. The linguistic ratings and the ratios are corresponding to linguistic terms and probabilities in PLTS. Then evaluation values for each hotel under each criterion can be expressed by PLTSs in this way and shown in Table 1, Table 2 and Table 3.

Table 1.
Evaluation values for each hotel under criteria and .
Table 2.
Evaluation values for each hotel under criteria and .
Table 3.
Evaluation values for each hotel under criteria and .
5.1. Results
According to the proposed approach in Section 3, the decision process can be obtained as follows.
Step 1: Construct and normalize the probabilistic linguistic decision matrix.
Based on the evaluation values for each hotel and the fact that six criteria are complete benefit criteria, a normalized probabilistic linguistic decision matrix can be constructed and represented by .
Step 2: Define cumulative distribution functions corresponding to PLTSs in the decision matrix.
Cumulative distribution function corresponding to can be defined based on Equations (1) and (2). Take for example, the cumulative distribution function is obtained as follows. The other cumulative distribution functions are omitted.
Step 3: Construct a decision matrix consisting of stochastic dominance relations.
Let . Decision matrix consisting of stochastic dominance relations that between alternatives and under criterion can be constructed according to Equation (8).
Step 4: Obtain the decision matrix consisting of stochastic dominance degrees.
By Equation (9), decision matrix consisted of stochastic dominance degrees between alternatives and under criterion can be obtained.
Step 5: Generate weight vectors.
Let . Weight vector is generated under constraint conditions , , , , and . Furthermore, the first weight vector is obtained as .
Step 6: Calculate comprehensive stochastic dominance degrees between alternatives.
With the first weight vector , comprehensive stochastic dominance degree is calculated by Equation (10) and shown in Table 4.
Table 4.
Comprehensive stochastic dominance degree .
Step 7: Calculate the comprehensive evaluation value of each alternative.
Based on Equation (11), comprehensive evaluation values of five hotels can be shown in Table 5.
Table 5.
Comprehensive evaluation values of five hotels.
Step 8: Rank alternatives.
The first ranking result can be calculated based on and steps 6–8 are repeated with assigning an integer between 2 and 1000 sequentially to the parameter , then 1000 ranking results are obtained.
Step 9: Calculate possibility degree of alternative .
The possibility degree of hotel can be calculated by Equation (12) and shown in Table 6.
Table 6.
Possibility degree .
Step 10: Calculate the comprehensive possibility degree of each alternative.
Based on the idea of linear weight and Equation (13), the comprehensive possibility degree of each hotel can be calculated, as shown in Table 7.
Table 7.
Comprehensive possibility degree of each hotel.
Step 11: Obtain comprehensive ranking result.
According to Table 7, the comprehensive ranking result of five hotels is , which means that is the best hotel.
5.2. Data Analysis
In this section, several ranking results of the five hotels in Section 4.1 can be obtained based on different parameter with the same linguistic scale function or different linguistic scale functions with the same parameter .
(1) Analysis on parameter with the same linguistic scale function.
In order to explore the influence of parameter on the final comprehensive ranking results of hotels, 10, 100, 1000, 10,000 and 100,000 are respectively assigned to but remains constant. The ranking results are shown in Table 8.
Table 8.
Ranking results based on different parameter .
Table 8 demonstrates that the ranking result when is distinguished from other ranking results and the ranking results are same when , 1000, 10,000, or 100,000. In addition, the comprehensive possibility degrees under and are approximately equal from to . The situation is related to the mutable weight vectors that are generated under given constraint conditions. The known constraint conditions , , , , and in Section 4.1 are so small and simple that numerous weight vectors satisfy above conditions. just means that ten weight vectors satisfying conditions are selected to calculate the final ranking result for one time. However, another ten weight vectors meeting the same conditions can be used to obtain the result, which may be different from the last result. Naturally, the ranking result holds relatively stable along with the increase of parameter because the weight vectors participated in calculation are adequate.
For further illustration, five ranking results are calculated under and another five ranking results are calculated with the same program under . The total ranking results are shown in Figure 4. The curves of comprehensive possibility degrees are obtained and markedly tend to be identical based on . In other words, the parameter should be as large as possible. Furthermore, the results based on and are also acceptable in complicated decision-making problems.
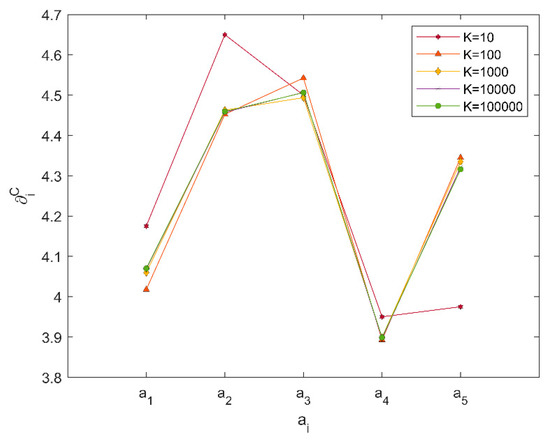
Figure 4.
Total ranking results based on different parameter .
(2) Analysis on linguistic scale functions with the same parameter .
Similarly, in order to explore the influence of linguistic scale functions on the final comprehensive ranking results of hotels, , and are respectively selected but remains constant. The ranking results are shown in Table 9.
Table 9.
Ranking results based on different linguistic scale functions.
Table 9 states that the linguistic scale functions have an impact on the comprehensive possibility degrees but such influences are not shown in the three ranking results. The features of linguistic scale functions are different and decision-makers can select appropriate linguistic scale functions in solving practical problems.
5.3. Comparison Analysis and Discussion
In this section, the study on feasibility and effectiveness of the proposed approach in this paper is done by means of comparison analysis. In order to reduce the impact of criteria’s weights, the central weight vector generated in the proposed approach is used. With this weight vector, the method based on stochastic dominance theory and the PROMETHEE method in Liang et al. [51], named Method 1, is used to solve the same problem. Furthermore, a method based on stochastic dominance degrees of PLTSs and the PROMETHEE method defined in this paper named Method 2, is also utilized to resolve the same problem. Then, decision processes of the above two methods are presented.
(1) The method based on stochastic dominance theory and the PROMETHEE method in [51]. Based on the stochastic dominance relations between hotels under each criterion and the method in [51], and expectation values of hotels under different criteria can be calculated, as shown in Table 10.
Table 10.
Expectation values of hotels under different criteria.
Preference threshold of criterion is defined as 0.055, 0.008, 0.004, 0.005, 0.008, 0.02, respectively, and then comprehensive dominance degrees between hotels can be obtained based on the comprehensive dominance degrees between hotels and criteria’s weights. The comprehensive dominance degrees between hotels are shown in Table 11.
Table 11.
Comprehensive dominance degrees between hotels in Method 1.
As a result, leaving flow , entering flow and comprehensive flow of hotels in Method 1 can be obtained and are shown in Figure 5.
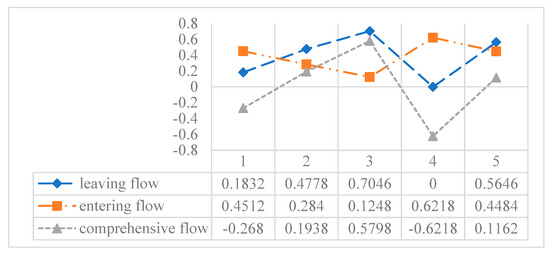
Figure 5.
Leaving flow, entering flow and comprehensive flow of hotels in Method 1.
Then the ranking result is obtained according to the comprehensive flows.
(2) A method based on stochastic dominance degrees of PLTSs and the PROMETHEE method.
Based on the weight and stochastic dominance degrees between hotels and under criterion , the comprehensive stochastic dominance degrees between hotels can be calculated and are shown in Table 12.
Table 12.
Comprehensive dominance degrees between hotels in Method 2.
Furthermore, the leaving flow , entering flow and comprehensive flow of hotels in Method 2 are presented in Figure 6. Then the ranking result is obtained.
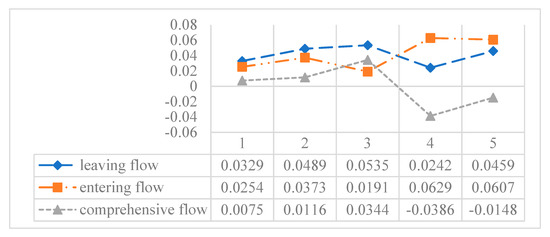
Figure 6.
Leaving flow, entering flow and comprehensive flow of hotels in Method 2.
According to the above two methods and the proposed approach in this paper, three ranking results are obtained, as shown in Table 13.
Table 13.
Ranking results of hotels based on different methods.
The similar ranking results in Table 13 demonstrate feasibility of the proposed approach. Hotel is always the best hotel but the deviations between each hotel under each method are different. As one of the outranking methods, the PROMETHEE method is reliable for managing dominance relations between each alternative under different criteria. Then the PROMETHEE method is often used to calculate the total ranking result based on the dominance degrees among alternatives. However, no matter the dominance relations or PROMETHEE methods, it cannot be applied to solve the weight problem. Furthermore, obtaining reasonable weights of criteria is one of the problems inevitably to settle in selecting a hotel on the website based online reviews. As a result, our proposed approach is more suitable to deal with the hotel selection problem.
Based on the decision processes of three methods, the features of the proposed approach can be summarized as follows.
(1) Considering that the gaps between two linguistic variables are incongruous under different situations, the stochastic dominance rules and stochastic dominance degrees of PLTSs are defined based on linguistic scale function. In this case, flexibilities of the stochastic dominance rules and stochastic dominance degrees are improved. Furthermore, PLMCDM problems under different semantic environments can be solved.
(2) Preference threshold of criterion is such as important parameter for Method 1 that it has a great influence on the comprehensive dominance degrees and further impacts the ranking. However, how to assign value to preference threshold is not specified in [51]. Compared with Method 1, the ranking results of Method 2 and the proposed approach are more stable. Although the ranking result of the proposed approach is impacted by parameter , the ranking result is tending toward stability along with the increase of .
(3) The weights of the criteria is another influencing factor in the decision process. The ranking results cannot be calculated in the case that the weights are unknown or some constraint conditions of weights are known in Method 1 and Method 2. However, the proposed approach can be used to deal with the PLMCDM problems that weights are partly known or some constraint conditions of weights are known. If there are several weight vectors satisfying known conditions, all these weight vectors can be used to calculate the final ranking result. In this paper, for avoiding the case that overmuch weight vectors may injure the calculation efficiency of the proposed approach, parameter is defined as the number of weight vectors and used to control the decision process. A reasonable can ensure stability and calculation efficiency of the proposed approach simultaneously.
Moreover, from the decision process, we notice that more than half of tourist’s attention has been attracted by sleep quality and location. Hoteliers need to ensure that tourists are satisfied with the sleep quality and location. Apart from the weight problem, we also recognize that the number of linguistic terms in the PLTS has great impact on the decision results. A smaller number means consensus among tourists about different criteria. For hoteliers and hotel managers, the problems emerge when online reviews contain so many kinds of opinion.
6. Conclusions
Researchers and hoteliers realize that online reviews on the website imply characteristics of the tourist and the features their tourism preference. The proposed novel stochastic dominance-based approach using PLTSs can help to describe reviews from tourist and obtain stability with less hotel criteria information. In this paper, linguistic terms and probability values of corresponding linguistic terms in PLTS are treated as discrete random variables and probability distributions of these discrete random variables respectively. Then we construct first-, second-, and third-order stochastic dominance rules of PLTSs for the next approach. According to these rules, first-, second-, and third-order stochastic dominance degrees of PLTSs are calculated and integrated into the decision procedure. Decision results illustrated the reliability and availability of this manner. Meanwhile, there still exists some limitations that should be addressed in the future. In the case study, we selected five hotels to be the research object, and the number of hotels was determined due to hesitation usually among several hotels. Our proposed approach can be improved to obtain the hotel listing on the website once we solve incomparable relations. Furthermore, the clustering method [52,53] can be used to deal with large scale online reviews to obtain reasonable decision sets. The preferences of tourists are different and varied. These preferences can be further refined by recognizing tourists’ positive or negative emotions.
Author Contributions
Conceptualization, funding acquisition, methodology, writing—original draft, writing—review and editing, S.-m.Y.; investigation, data curation, Z.-j.D.; software, validation, visualization, X.-d.L.; supervision, writing—review and editing, H.-y.L.; software, methodology, J.-q.W. All authors have read and agreed to the published version of the manuscript.
Funding
This work was supported by the National Natural Science Foundation of China (No. 71901151), the Major Project for National Natural Science Foundation of China (Nos. 71991461, 91846301), the Natural Science Foundation of Shenzhen University (No. 000002110552).
Conflicts of Interest
The authors declare that there is no conflict of interest regarding the publication of this paper.
Appendix A. The Proof of Property 1
Proof.
(1) If , , always holds. Based on this condition and , , always holds in the interval , in other words, .
(2) As the proof of Property 1(2) is similar to that of Property 1(1), it is not provided here.
(3) When , if , , always holds.
Then , is false.
Similarly, , and , are false.
Thus, , , and are not tenable.
In the same way, other cases can be proved.
(4) If and , and always hold. Then, holds, that is, . According to Property 1(1) and Property 1(2), and can be obtained.
Based on Theorem 1, Property 1(1) and Property 1(2), transitivity of second (third) order stochastic dominance rule can also be proved. In this case, if , and , can be proved on account of Property 1(1) and transitivity of stochastic dominance rule. □
Appendix B. The Proof of Property 2
Proof.
Since , we have that ().
() means that the function curve is totally under function curve . Moreover, there is no cross point.
Furthermore, () means that two function curves coincide.
Then is the difference between areas under function curves and . is the area under function curve . is the ratio of the difference between areas under two function curves to the area under function curve .
For convenience, the areas under function curves and are denoted by and separately. Obviously, .
Thus, , .
Similarly, and
can be proved.
The detailed proof is omitted. □
References
- Tan, H.; Lv, X.; Liu, X.; Gursoy, D. Evaluation nudge: Effect of evaluation mode of online customer reviews on consumers’ preferences. Tour. Manag. 2018, 65, 29–40. [Google Scholar] [CrossRef]
- Sohrabi, B.; Vanani, I.R.; Tahmasebipur, K.; Fazli, S. An exploratory analysis of hotel selection factors: A comprehensive survey of Tehran hotels. Int. J. Hosp. Manag. 2012, 31, 96–106. [Google Scholar] [CrossRef]
- Wang, L.; Wang, X.-K.; Peng, J.-J.; Wang, J.-Q. The differences in hotel selection among various types of travellers: A comparative analysis with a useful bounded rationality behavioural decision support model. Tour. Manag. 2020, 76, 103961. [Google Scholar] [CrossRef]
- Tian, Z.-P.; Nie, R.-X.; Wang, J.-Q. Probabilistic linguistic multi-criteria decision-making based on evidential reasoning and combined ranking methods considering decision-makers’ psychological preferences. J. Oper. Res. Soc. 2019, 71, 700–717. [Google Scholar] [CrossRef]
- Luo, S.; Xing, L. Picture Fuzzy Interaction Partitioned Heronian Aggregation Operators for Hotel Selection. Mathematics 2019, 8, 3. [Google Scholar] [CrossRef]
- Liang, X.; Liu, P.; Wang, Z. Hotel selection utilizing online reviews: A novel decision support model based on sentiment analysis and dl-vikor method. Technol. Econ. Dev. Econ. 2019, 25, 1139–1161. [Google Scholar] [CrossRef]
- Pang, Q.; Wang, H.; Xu, Z. Probabilistic linguistic term sets in multi-attribute group decision making. Inf. Sci. 2016, 369, 128–143. [Google Scholar] [CrossRef]
- Gou, X.; Xu, Z.; Xunjie, G. Novel basic operational laws for linguistic terms, hesitant fuzzy linguistic term sets and probabilistic linguistic term sets. Inf. Sci. 2016, 372, 407–427. [Google Scholar] [CrossRef]
- Bai, C.; Zhang, R.; Qian, L.; Wu, Y. Comparisons of probabilistic linguistic term sets for multi-criteria decision making. Knowl. Based Syst. 2017, 119, 284–291. [Google Scholar] [CrossRef]
- Wu, X.; Liao, H. An approach to quality function deployment based on probabilistic linguistic term sets and ORESTE method for multi-expert multi-criteria decision making. Inf. Fusion 2018, 43, 13–26. [Google Scholar] [CrossRef]
- Song, C.; Wang, X.-K.; Cheng, P.-F.; Wang, J.-Q.; Li, L. SACPC: A framework based on probabilistic linguistic terms for short text sentiment analysis. Knowl. Based Syst. 2020, 194, 105572. [Google Scholar] [CrossRef]
- Nie, R.-X.; Tian, Z.-P.; Wang, J.-Q.; Chin, K.S. Hotel selection driven by online textual reviews: Applying a semantic partitioned sentiment dictionary and evidence theory. Int. J. Hosp. Manag. 2020, 88, 102495. [Google Scholar] [CrossRef]
- Xiao, F.; Wang, J.-Q. Multistage decision support framework for sites selection of solar power plants with probabilistic linguistic information. J. Clean. Prod. 2019, 230, 1396–1409. [Google Scholar] [CrossRef]
- Peng, H.-G.; Wang, J.-Q.; Zhang, H. Multi-criteria outranking method based on probability distribution with probabilistic linguistic information. Comput. Ind. Eng. 2020, 141, 106318. [Google Scholar] [CrossRef]
- Wang, X.-K.; Wang, Y.-T.; Wang, J.-Q.; Cheng, P.-F.; Li, L. A TODIM-PROMETHEE Ⅱ Based Multi-Criteria Group Decision Making Method for Risk Evaluation of Water Resource Carrying Capacity under Probabilistic Linguistic Z-Number Circumstances. Mathematis 2020, 8, 1190. [Google Scholar] [CrossRef]
- He, S.-S.; Wang, Y.-T.; Wang, J.-Q.; Cheng, P.-F.; Li, L. A novel risk assessment model based on failure mode and effect analysis and probabilistic linguistic ELECTRE II method. J. Intell. Fuzzy Syst. 2020, 38, 4675–4691. [Google Scholar] [CrossRef]
- Yu, S.-M.; Du, Z.-J.; Xu, X.-H. Hierarchical Punishment-Driven Consensus Model for Probabilistic Linguistic Large-Group Decision Making with Application to Global Supplier Selection. Group Decis. Negot. 2020. [Google Scholar] [CrossRef]
- Martel, J.-M.; Zaras, K. Stochastic dominance in multicriterion analysis under risk. Theory Decis. 1995, 39, 31–49. [Google Scholar] [CrossRef]
- Lahdelma, R.; Hokkanen, J.; Salminen, P. SMAA—Stochastic multiobjective acceptability analysis. Eur. J. Oper. Res. 1998, 106, 137–143. [Google Scholar] [CrossRef]
- Jiang, Y.; Liang, X.; Liang, H.; Yang, N. Multiple criteria decision making with interval stochastic variables: A method based on interval stochastic dominance. Eur. J. Oper. Res. 2018, 271, 632–643. [Google Scholar] [CrossRef]
- Zhou, H.; Wang, J.-Q.; Zhang, H. Stochastic multicriteria decision-making approach based on SMAA-ELECTRE with extended gray numbers. Int. Trans. Oper. Res. 2017, 26, 2032–2052. [Google Scholar] [CrossRef]
- Yang, Y.; Wang, J.-Q. SMAA-based model for decision aiding using regret theory in discrete Z-number context. Appl. Soft Comput. 2018, 65, 590–602. [Google Scholar] [CrossRef]
- Sparks, B.; Perkins, H.E.; Buckley, R. Online travel reviews as persuasive communication: The effects of content type, source, and certification logos on consumer behavior. Tour. Manag. 2013, 39, 1–9. [Google Scholar] [CrossRef]
- Xiang, Z.; Schwartz, Z.; Gerdes, J.H.; Uysal, M. What can big data and text analytics tell us about hotel guest experience and satisfaction? Int. J. Hosp. Manag. 2015, 44, 120–130. [Google Scholar] [CrossRef]
- Fang, B.; Ye, Q.; Kucukusta, D.; Law, R.; Law, R. Analysis of the perceived value of online tourism reviews: Influence of readability and reviewer characteristics. Tour. Manag. 2016, 52, 498–506. [Google Scholar] [CrossRef]
- Viglia, G.; Minazzi, R.; Buhalis, D. The influence of e-word-of-mouth on hotel occupancy rate. Int. J. Contemp. Hosp. Manag. 2016, 28, 2035–2051. [Google Scholar] [CrossRef]
- Lui, T.-W.; Bartosiak, M.; Piccoli, G.; Sadhya, V. Online review response strategy and its effects on competitive performance. Tour. Manag. 2018, 67, 180–190. [Google Scholar] [CrossRef]
- Yu, S.-M.; Wang, J.; Wang, J.-Q.; Li, L. A multi-criteria decision-making model for hotel selection with linguistic distribution assessments. Appl. Soft Comput. 2018, 67, 741–755. [Google Scholar] [CrossRef]
- Kwok, L.; Xie, K.L.; Richards, T. Thematic framework of online review research. Int. J. Contemp. Hosp. Manag. 2017, 29, 307–354. [Google Scholar] [CrossRef]
- Liu, Z.; Park, S. What makes a useful online review? Implication for travel product websites. Tour. Manag. 2015, 47, 140–151. [Google Scholar] [CrossRef]
- Li, G.; Law, R.; Vu, H.Q.; Rong, J.; Law, R. Discovering the hotel selection preferences of Hong Kong inbound travelers using the Choquet Integral. Tour. Manag. 2013, 36, 321–330. [Google Scholar] [CrossRef]
- Gavilán, D.; Avello, M.; Martinez-Navarro, G. The influence of online ratings and reviews on hotel booking consideration. Tour. Manag. 2018, 66, 53–61. [Google Scholar] [CrossRef]
- Yu, S.-M.; Wang, J.; Wang, J.-Q. An Interval Type-2 Fuzzy Likelihood-Based MABAC Approach and Its Application in Selecting Hotels on a Tourism Website. Int. J. Fuzzy Syst. 2016, 19, 47–61. [Google Scholar] [CrossRef]
- Peng, H.-G.; Zhang, H.-Y.; Wang, J.-Q. Cloud decision support model for selecting hotels on TripAdvisor.com with probabilistic linguistic information. Int. J. Hosp. Manag. 2018, 68, 124–138. [Google Scholar] [CrossRef]
- Zaras, K. Rough approximation of a preference relation by a multi-attribute stochastic dominance for determinist and stochastic evaluation problems. Eur. J. Oper. Res. 2001, 130, 305–314. [Google Scholar] [CrossRef]
- Zaras, K. Rough approximation of a preference relation by a multi-attribute dominance for deterministic, stochastic and fuzzy decision problems. Eur. J. Oper. Res. 2004, 159, 196–206. [Google Scholar] [CrossRef]
- Nowak, M. Preference and veto thresholds in multicriteria analysis based on stochastic dominance. Eur. J. Oper. Res. 2004, 158, 339–350. [Google Scholar] [CrossRef]
- Nowak, M. INSDECM—An interactive procedure for stochastic multicriteria decision problems. Eur. J. Oper. Res. 2006, 175, 1413–1430. [Google Scholar] [CrossRef]
- Zhang, Y.; Fan, Z.; Liu, Y. A method based on stochastic dominance degrees for stochastic multiple criteria decision making. Comput. Ind. Eng. 2010, 58, 544–552. [Google Scholar] [CrossRef]
- Liu, Y.; Fan, Z.; Zhang, Y. A method for stochastic multiple criteria decision making based on dominance degrees. Inf. Sci. 2011, 181, 4139–4153. [Google Scholar] [CrossRef]
- Chen, X.; Liang, H.; Gao, Y.; Xu, W. A method based on the disappointment almost stochastic dominance degree for the multi-attribute decision making with linguistic distributions. Inf. Fusion 2020, 54, 10–20. [Google Scholar] [CrossRef]
- Lahdelma, R.; Salminen, P. SMAA-2: Stochastic Multicriteria Acceptability Analysis for Group Decision Making. Oper. Res. 2001, 49, 444–454. [Google Scholar] [CrossRef]
- Lahdelma, R.; Salminen, P. Pseudo-criteria versus linear utility function in stochastic multi-criteria acceptability analysis. Eur. J. Oper. Res. 2002, 141, 454–469. [Google Scholar] [CrossRef]
- Angilella, S.; Corrente, S.; Greco, S. Stochastic multiobjective acceptability analysis for the Choquet integral preference model and the scale construction problem. Eur. J. Oper. Res. 2015, 240, 172–182. [Google Scholar] [CrossRef]
- Corrente, S.; Figueira, J.R.; Greco, S. The SMAA-PROMETHEE method. Eur. J. Oper. Res. 2014, 239, 514–522. [Google Scholar] [CrossRef]
- Okul, D.; Gencer, C.; Aydogan, E.K. A Method Based on SMAA-Topsis for Stochastic Multi-Criteria Decision Making and a Real-World Application. Int. J. Inf. Technol. Decis. Mak. 2014, 13, 957–978. [Google Scholar] [CrossRef]
- Zhang, W.; Ju, Y.; Gomes, L.F.A.M. The SMAA-TODIM approach: Modeling of preferences and a robustness analysis framework. Comput. Ind. Eng. 2017, 114, 130–141. [Google Scholar] [CrossRef]
- Govindan, K.; Kadziński, M.; Ehling, R.; Miebs, G. Selection of a sustainable third-party reverse logistics provider based on the robustness analysis of an outranking graph kernel conducted with ELECTRE I and SMAA. Omega 2019, 85, 1–15. [Google Scholar] [CrossRef]
- Pelissari, R.; Oliveira, M.C.; Ben Amor, S.; Kandakoglu, A.; Helleno, A.L. SMAA methods and their applications: A literature review and future research directions. Ann. Oper. Res. 2019, 1–61. [Google Scholar] [CrossRef]
- Wang, J.-Q.; Wu, J.-T.; Wang, J.; Zhang, H.-Y.; Chen, X.-H. Interval-valued hesitant fuzzy linguistic sets and their applications in multi-criteria decision-making problems. Inf. Sci. 2014, 288, 55–72. [Google Scholar] [CrossRef]
- Liang, X.; Jiang, Y.P.; Gao, M. Product Selection Methods Based on Online Reviews. J. Northeast. Univ. (Nat. Sci.) 2017, 38, 143–147. [Google Scholar]
- Du, Z.-J.; Luo, H.-Y.; Lin, X.; Yu, S.-M. A trust-similarity analysis-based clustering method for large-scale group decision-making under a social network. Inf. Fusion 2020, 63, 13–29. [Google Scholar] [CrossRef]
- Du, Z.-J.; Yu, S.-M.; Xu, X. Managing noncooperative behaviors in large-scale group decision-making: Integration of independent and supervised consensus-reaching models. Inf. Sci. 2020, 531, 119–138. [Google Scholar] [CrossRef]






© 2020 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (http://creativecommons.org/licenses/by/4.0/).