1. Introduction
To this day, industrial processes have been pushed towards the mass employment of machinery, devices, personal, and work operations, among others; these objects of production increase the sheer complexity of monitoring tasks and of stability analyses. Control Charts (CC) are used in processes of monitoring and stability analysis. CC allows the visual identification of signals in behaviour-defining processes, which are, at times, determinant to product quality. However, most processes use CC in a univariate approach, which always brings forth several disadvantages such as the inherent need to satisfy statistical conditions: normality and independence. Secondly, CC do not help us analyse the correlation between variables. Moreover, the use of CC becomes rather complex for the analysis of more than one variable in a univariate approach, and in the same way, they depend on human judgment. Due to the disadvantages of the use of CC, multivariate control techniques have been developed such as Hotelling statistics [
1,
2], MEWMA statistic [
1], MCUSUM calculation [
1], and Mahalanobis Distance [
3], among others. Emerging methods such as Recurrence Density are suited to determine the periodicity in the repetitiveness of time series. Using this method, the data series (patterns) could be characterised to identify the extent to which a time series repeats the same sequence. It is observed that with this approach it will not be essential to assume normality in the data and it will make it possible to identify foreign structures to the behaviour of the data [
4].
Multivariate control techniques, in general, allow us to analyse process-related variables. Likewise, these techniques make it easy to make out the relationship between those variables and, also, provide graphs of variable behaviour. However, multivariate techniques have proven to carry inherent drawbacks that, ultimately, limit their flawless application within the industry. Among those drawbacks, there is the complexity of the calculations, the fact that they only seem to detect out-of-control signals, that they do not indicate the reason behind failure, and, lastly, that they do not provide adequate tools to determine the underlying issues that rise to the out-of-control signals. In addition, the operator needs to have the knowledge of multivariate statistical control to understand and interpret results [
1,
5]. Statistical process control techniques are tools limited to automate industries with a large number of elements to monitor [
5,
6]. Univariate control charts have been studied since 1929 and were developed by Dr. Walter A. Shewhart. These graphs are a horizontal diagram that displays the points (measurements) on a timeline and assumes that if the data generating process maintains a state in statistical control, then the points will have a visible random pattern; this random pattern is related to the normal distribution shape. In addition, these graphs display three lines parallel to each other and to the horizontal axis of the graph: limit lines and center line. The limit lines called upper and lower control limits are obtained at a distance of
from the mean when the process remains stable and the central line corresponds to the mean value. The pattern that demonstrates stability in the process is the natural one and, when its stability is broken due to the presence of some disturbance in the process, the stable state of the process is lost indicating instability or loss of control in the process. The patterns associated with stability and instability are strongly related to two types of statistical variability. This article considers two types of variability: special variation and natural variation, which correspond to unstable and stable cases, respectively. These variations can be discerned in the distribution of measurements corresponding to a certain variable with respect to a unit (time, sample number, space, data series). The distribution or shape of the measurements are identified as special patterns and natural patterns [
7]. The basic patterns for variable-behaviour identification and retrieval of potential causes are specified in the Western Electric Manual [
8]. The basic patterns have been defined as Increasing Trend (IT), Decreasing Trend (DT), Downward Shift (DS), Upward Shift (US), Mixed (M), Cycle (Cy), Systematic (S) and Normal (N).
The graphic representations for the basic patterns observed in the measurements are shown in
Figure 1.
The above patterns are defined as follows:
Normal Pattern: This pattern is characterised by its display of observations close to the mean value without exceeding control limits. Furthermore, it is considered normal behaviour for the process or a behaviour to bear an absence of disturbances.
Cycle Pattern: The cyclic behaviour in the process mean value is displayed as a sequence of data series with high value interspersed with low value data. The causes of such behaviour are prone to associate (in the case of machines) with a sequence of movements or positions.
Shift Pattern: It is defined as a sudden or abrupt change in the mean value. These patterns are associated with a change of material, a new operator, a change in the configuration of the machinery, etc.
Trend Pattern: These can be defined as continuous displacements in negative or positive trajectory, in addition to a prolonged series of data without a change of direction. This type of pattern can be associated with tooling wear, gradual improvement in the operator technique, poor maintenance, etc.
Considering the conjunction of univariate variables in a single variable leads to the need of simultaneously studying two or more variables at the same time. This fact is the basis of the multivariate statistical control that, in addition to what is written, is designed to detect the two states of the process (stable/not stable or in-control/out-of-control) when: (a) the variables are correlated with each other, and (b) the product quality should be evaluated as a unit and not as separate variables.
1.1. Related Work
Several investigative efforts [
6,
9,
10,
11,
12,
13,
14,
15,
16,
17,
18] have driven scientists to propose the use of Artificial Neural Networks (ANNs) in pattern recognition of CC to diagnose the variable’s behaviour. ANNs have been applied to the analysis, detection, recognition and classification of sets of sample data in patterns of natural variation and special variation. By recognising the pattern type, it is possible to learn if a variable or process lies within statistical control. Furthermore, ANNs present benefits such as the analysis of large chunks of data, the non-existent need to satisfy statistical conditions such as normality, and great noise tolerance; and lastly, they are able to work in real time (as stated in [
5,
6,
19]).
Several authors have been interested in this field of research, especially within the broader area of Artificial Intelligence, which encompasses the main findings. A large group of researchers has been working on ANNs. Sohaimi et al. presented in their work a method to monitor and diagnose the mean and/or variance of a bivariate process using pattern recognition through a multi-layer perceptron network for simulated data in a modular neural network scheme that identifies nine categories of patterns of bivariate SPC charts [
12]. Zhou et al. proposed to analyse the patterns observed in the control charts in a multiclass approach. They develop a model composed of a genetic algorithm and Support Vector Machine (SVM) using a hybrid kernel function (Gaussian function and a polynomial function) [
13]. Similarly, Guan and Cheng formulated a modification of the multiclass SVM. The proposed structure, a combination of “one against all” and “one against one” classifiers was generated to analyse simulated multivariate data with the Montecarlo method [
14]. Addeh et al. proposed an analysis of out-of-control signals through pattern recognition for continuous monitoring, where the method of association of rules for the extraction of characteristics was included. For the classification stage, an RBF ANN was used with a learning algorithm focused on the bee algorithm. The proposed method was tested on a data set containing 1600 samples (200 samples from each pattern) [
15]. Zheng and Yu integrated a hybrid system consisting of two different CNN topologies and a SVM classifier. The feature extracted by two CNNs was combined to train the SVM classifier. The experimental analysis showed that the proposed hybrid system had better performance than each technique separately [
16]. CNN has evolved successfully in many areas thanks to increased computing power and new Graphics Processing Units (GPUs) and specialised, reconfigurable hardware. Although these techniques have to address many other issues inherited by the BP algorithm, they certainly have a solid foundation for SPC, as some authors have recently shown. Miao and Yang suggested in their work, the extraction of characteristics in graphical control patterns and their analysis by deep learning with a CNN in data simulated by the Montecarlo method [
17]. A comprehensive study by Yu et al. using the Stacked Denoising Autoencoder (SDAE) learned discriminatory characteristics of process signals. The experimental results illustrated a cross-validation between the main techniques like Backpropagation Network (BPN), SVM, K-nearest neighbor, Decision Trees (DTs), and Learning Vector Quantisation (LVQ), ranking at the top as a good solution SDAE, BPN and SVM [
18].
An area of opportunity is found in the studies regarding the pattern recognition and the problem of detecting mixed (concurrent) patterns where, at least, two patterns coexist and are prone to be associated with different causes. The distance calculation of Mahalanobis has been used as a characteristic extraction technique. The has been considered an appropriate technique for this investigation for its distinctive characteristics. Among these characteristics is the use of data covariance and the scaling of differing variables, which is useful to the detection of outliers. In addition, analyses the data variability and its p-dimensionality.
1.2. Original Contribution
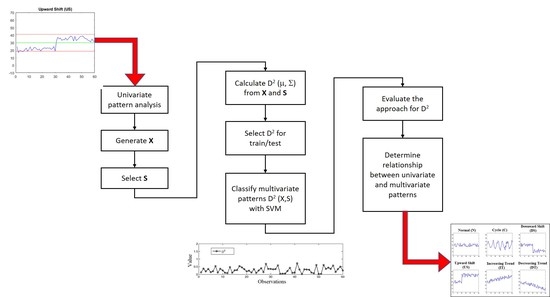
The purpose of this research is to recognise multivariate patterns in multivariate variables which is significant to SPC because the existence of an out-of-control condition locates the faults presented by the variables. The method proposes observation of multivariate patterns during the measurement of multivariate variables. When a pattern is identified, it is proposed to associate the multivariate pattern with the variations and their causes reflected in the univariate variables that formed that multivariate variable. A previous analysis on system or process behaviour must be carried out with regard for the establishment of relationships between multivariate patterns and underlying causes.
Considering the above, the method consists of the following steps:
Generate different types of multivariate variables.
Select a multivariate variable in control or close to normality (C).
Determine between C and multivariate variables X.
Evaluate if exhibits multivariate variation classes using SVM.
Determine the combination of variation classes.
Recognise each type of multivariate pattern in .
Determine the variable’s location and the causes that originated them.
The method considers the generation of multivariate variables using the “Synthetic Control Chart Time Series” public database which is composed by variation-class carrying vectors (special patterns and natural patterns). Following this methodology, it is expected to find out about the existence of an association between the multivariate patterns observed in the
and the patterns present in the univariate variables that formed each
. Two approaches are proposed for the calculation of
with the aim of obtaining quantitative measurements of similarity between observations of multivariate variables and the centroid of other multivariate variables. The methodology is depicted in
Figure 2.
1.3. Database Generation of Multivariate Variables
The “Synthetic Control Chart Time Series” database employed for our experiments was generated using control charts generated by the process described in Alcock RJ & Manolopoulos in [
7]. In the database, there are 100 pattern samples for each corresponding pattern type such as Increasing Trend (IT), Decreasing Trend (DT), Downward Shift (DS), Upward Shift (US), Cycle (Cy) and Normal (N). Thus, there are 600 samples corresponding to synthetically generated control charts.
The proposed method considers
p-variables of a random process
defined as a multivariate variable. In this form,
is defined as a multivariate variable formed by p univariate variables. In this paper, we present the approach with
univariate variables so that the composition of each multivariate variable is
.
Table 1 shows the configuration of these multivariate classes. To determine the quantity of multivariate variable types, the permutation formula applied is:
; where n = types of patterns to choose from and r = number of elements that forms the permutation. The procedure consisted in choosing 100 samples containing a type of pattern for
and another 100 samples for
and combining them to form a type of multivariate variable as shown in
Figure 3. Based on the above, 10,000 multivariate variable samples were generated for each of the 36 classes of multivariate variables
shown in
Table 1, making a total of 360,000 sample patterns as population study.
1.4. The Mahalanobis Distance Calculation ()
The use of Mahalanobis distance
is proposed to determine the existence and representation of multivariate patterns in different multivariate classes.
allows us to analyse the behaviour of multivariate variables providing a similarity measurement between observations comparing their centroids. As exposed in
Section 1.2, the method requires the calculation of
from a variable with stable behaviour, which, in this bivariate case, is the pattern represented by
that includes natural patterns in its elements
.
is then labelled as
to pinpoint its stable behaviour. Then,
is calculated from
and
.
Calculation of the Mahalanobis Distance with Respect to and .
is computed from Equation (
1) as follows:
where
and
are the mean and covariance from
, respectively.
As an example, consider
, which is constituted by two univariate variables with cyclic patterns
. The Mahalanobis distance is then calculated between the observations of the multivariate variable
and
of the multivariate variable
. These values
are shown in
Figure 4.
The next step is to calculate the Mahalanobis distance
between
and (
) from each of the 360,000 patterns previously generated.
is determined by Equation (
2)
where
and
are the mean and covariance calculated from the multivariate variable
. Similarly, a multivariate variable
is generated with the composition
=
= [Cy, Cy]. For the variable
, a multivariate variable generated with the composition
= [N, N] was selected.
Figure 5 shows the Mahalanobis distance calculation between the observations of
and
,
of
.
It is desirable to find a characteristic behaviour for each class of
related to the multivariate variable class it forms. In this way, the behaviour of the process could be determined by the information given by the
calculation. The generated
patterns were examined in both approaches, and no distinctive forms of multivariate patterns were found in comparison with the basic patterns in “Synthetic Control Chart Time Series” that originated them. SVM was proposed in order to determine if the multivariate pattern was identifiable, which is explained in the
Section 1.5.
1.5. Multivariate Pattern Recognition
The Support Vector Machine (SVM) is used for multivariate pattern recognition using
. The principle of SVM is to find a hyperplane that solves the problem of classifying a data set. The classification is produced by the separation of data belonging to different classes through a hyperplane and maximising the margin between classes in such a way that the data belonging to the same class is located on the same side of the hyperplane [
20].
In the case of linear classification, we have a training group of size
n composed of the data vector
in two classes labeled
. The classification function is expressed by the Equation (
3)
where vector
defines the hyperplane slope and the parameter
determines the optimal hyperplane. By means of the decision function
, it is expected to correctly classify both training and test data. However, most real problems do not have a normal distribution that can not be linearly separable. Given this case, the data from the input space (belonging to two different classes) must be mapped to the characteristics space of a larger dimension in such a way that the data be linearly separable through a hyperplane and the margin between the classes is maximized, with the process then reversed to the original dimension.
The data transformation was obtained through a kernel function which allows data separation. To find the best solution regarding the separation by the hyperplane, the following optimisation is proposed:
subject to
is the error margin between the point i and the separation limits. Parameter can be interpreted as a tuneable parameter, where a higher value corresponds to establishing a greater importance to the task of correctly classifying the training data. A lower value implies a hyperplane with greater flexibility that attempts to minimise the margin of error for each sample. For the tuning of parameters () in the training process, the Mesh Search and Validation strategies were proposed. and were used.
Different kernel functions were tested such as polynomial, Radial Basis Function (RBF), and, finally, the sigmoid as indicated in the
Table 2.
Simulation results during experiments using Equations (
1) and (
2) showed that the best kernel function was the sigmoid
, where
is a scale parameter of input data and
r is a displacement parameter controlling the mapping threshold [
21]. These results are presented in
Section 2.
Although SVM was designed to deal with binary classification problems, there are strategies that allow extension to the multiclass problem. One way to solve this problem is to consider it a series of binary classification problems. For the present work, it was decided to use the “one against all” strategy, where K SVM classifiers are built to differentiate each class from the others. In such a way that the ith classifier is trained with patterns of class i and value 1, the rest of the patterns’ classes are trained with a value of .
Distances were calculated to integrate the training and the test base. The 360,000 were divided into 36 classes corresponding to the classes of the multivariate variables with which they were calculated, i.e., 10,000. The training and test bases were analysed with SVM. In the training stage, SVM used the training database and a labelled vector to learn and recognise each multivariate pattern corresponding to each class. The outputs produced in the training stage by the SVM can be interpreted as the correct or incorrect learning of each .
For the test stage, the
of the test base is analysed using SVM with an unknown input. It is expected the SVM to be able to recognise it through the knowledge acquired in the training stage. In the test stage, by effectively recognising the types of multivariate patterns in the
, it is possible to define the exact pattern
the distances were obtained from (similar to the way
Table 1 was obtained). In addition, the patterns in
and
that make up each of the multivariate variables
with which the distances were calculated can be known. Also, by knowing the patterns in
and
it can be defined whether these variables are in-control or out-of-control. Similarly, it is possible to relate and infer what type of pattern each vector of the multivariate variable contains and associate it with its type of failure according to the Western Electric Manual [
8]. In
Section 2, the experimental results are presented.
3. Conclusions
In this paper, a method to recognise univariate patterns in multivariate patterns using the Mahalanobis distance has been shown. The method determines the association of multivariate patterns with univariate variables. During experiments, multivariate patterns formed by Mahalanobis distances were calculated with different multivariate variables. When visually inspecting the types of multivariate patterns as observed in the 36 classes of , no distinctive forms were found for each type of multivariate pattern compared to the characteristic forms presented by the univariate patterns of the “Synthetic Control Chart Time Series”. This was our main motivation for interchangeably analysing , and cases and their differences using the Mahalanobis distance through SVM recognition.
A first set of experiments (stable case with ) was presented, the computing of distances and the rest of multivariate pattern recognition was made using SVM obtaining a recognition rate as low as . A second set of experiments (unstable case) was envisioned and the outcome was far better than in the first experiment; in this second approach, a recognition of was obtained with a training/testing ratio of 2.
The relevance of this research lies upon the calculation of the
between a multivariate variable (with natural patterns) and the statistical values (
,
,
) of each of the generated multivariate variables. This modification saw an increase to the difference between each of the types or classes of multivariate patterns compared to other works that use Hotelling, MEWMA [
22], PCA, combination of variables and scatter plot [
23]. Our own results showed that using
with the synthetic data base resulted in efficiencies as low as 27.99%.
An important observation is that our proposal considered the calculation of covariance matrices by sub-data sets since these were obtained directly from the application of Equation (
2). For each equation the parameters
and
adjust to the changing values contained in the different combinations of X patterns and fixed periods were considered for the covariance matrix. However, an envisaged recognition of multivariate patterns using the periods of the covariance matrix in order to observe the changes in this matrix period by period would certainly reinforce our method.
By recognising each class or type of distance of Mahalanobis correctly, it is possible to make out the composition () of each distance of Mahalanobis. In addition, there is the potential ability to infer the composition ( and ) of each multivariate variable . Finally, by knowing the univariate patterns, it will be possible to infer errors that triggered them. If the number of variables increase, then the approach can also be used to find differentiable multivariate patterns for each type of classes, which is an ongoing research work.

 ,
, 






{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}