Sign, Wilcoxon and Mann-Whitney Tests for Functional Data: An Approach Based on Random Projections




{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
Abstract
:1. Introduction
2. Background
2.1. Sign, Wilcoxon and Mann-Whitney Tests
2.2. Functional Data and Random Projections
3. Sign, Wilcoxon and Mann Withney Tests for Functional Data
3.1. The Case of One Sample
- Define , for .
- Generate a Brownian motion , for .
- Obtain random projections , for .
- Let be the median of Z. Then, based on , for , test the hypotheses given byusing the statistics S and defined in (1). The critical values are defined in the same way as in Section 2.1.
3.2. The Case of Two Samples
4. Numerical Results
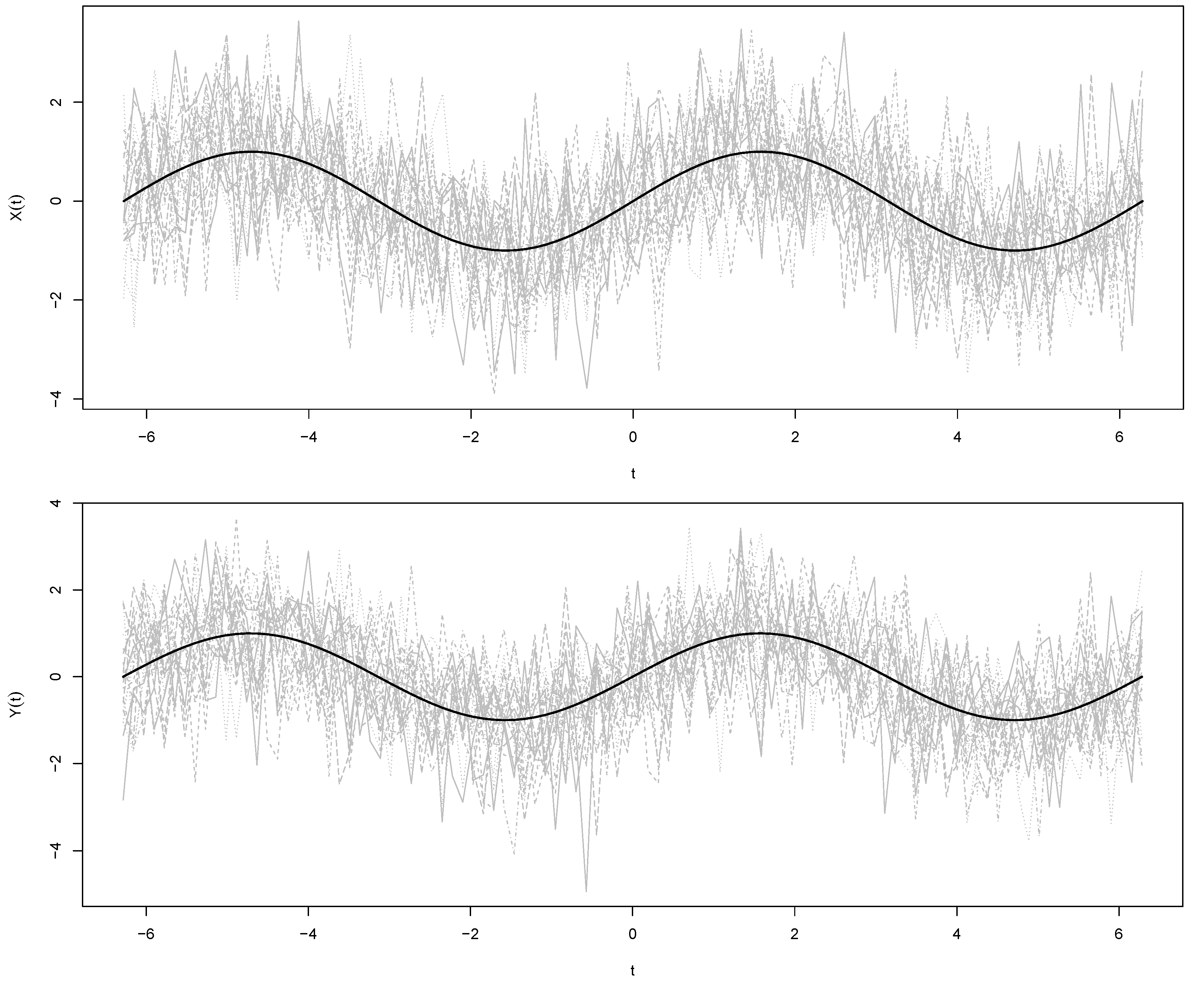
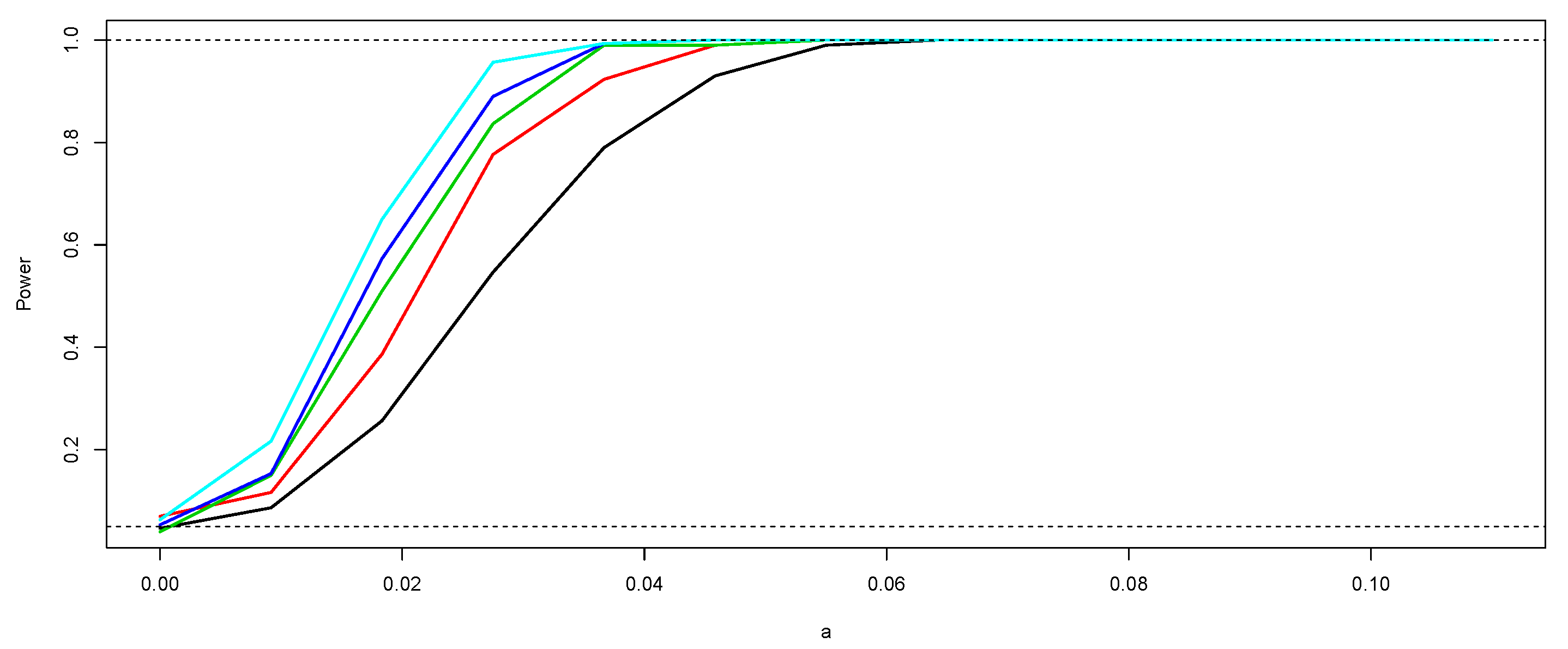
4.1. Simulation Study
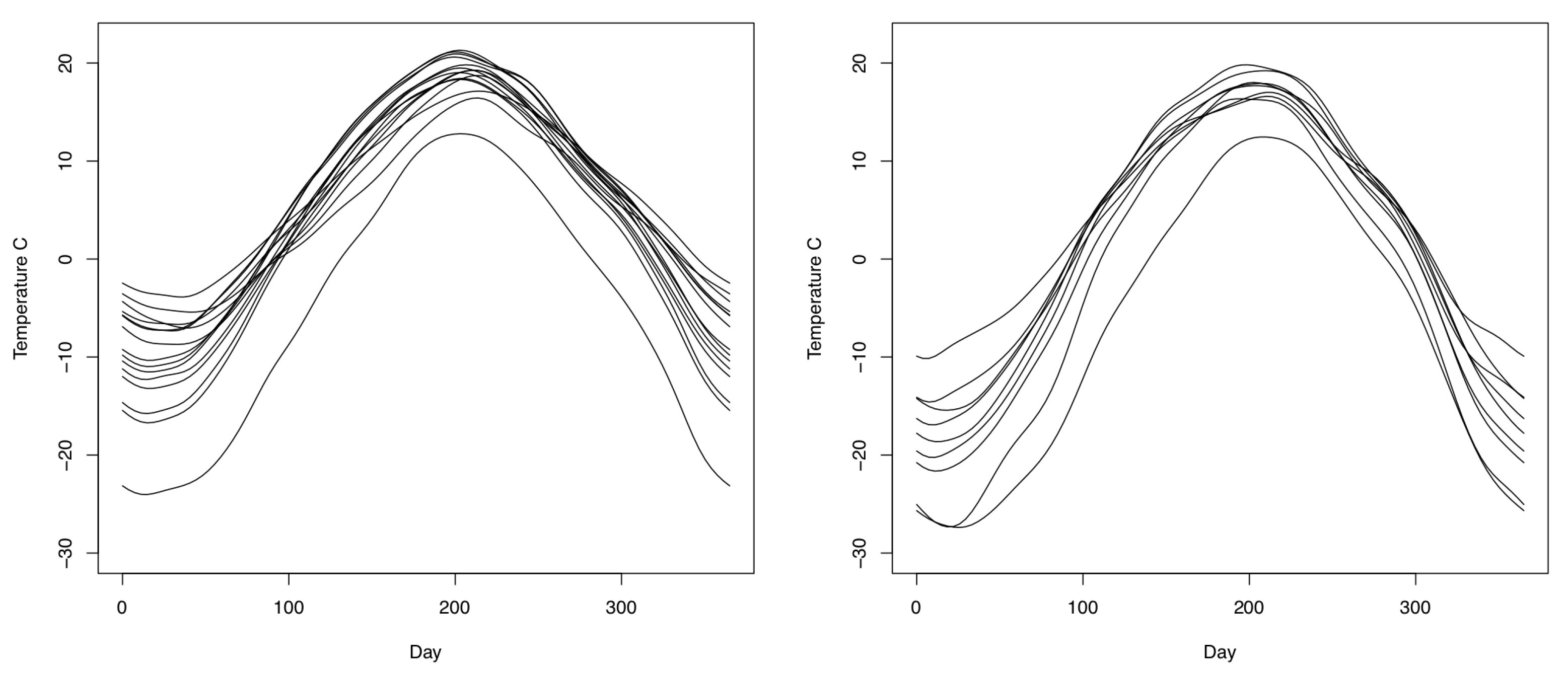
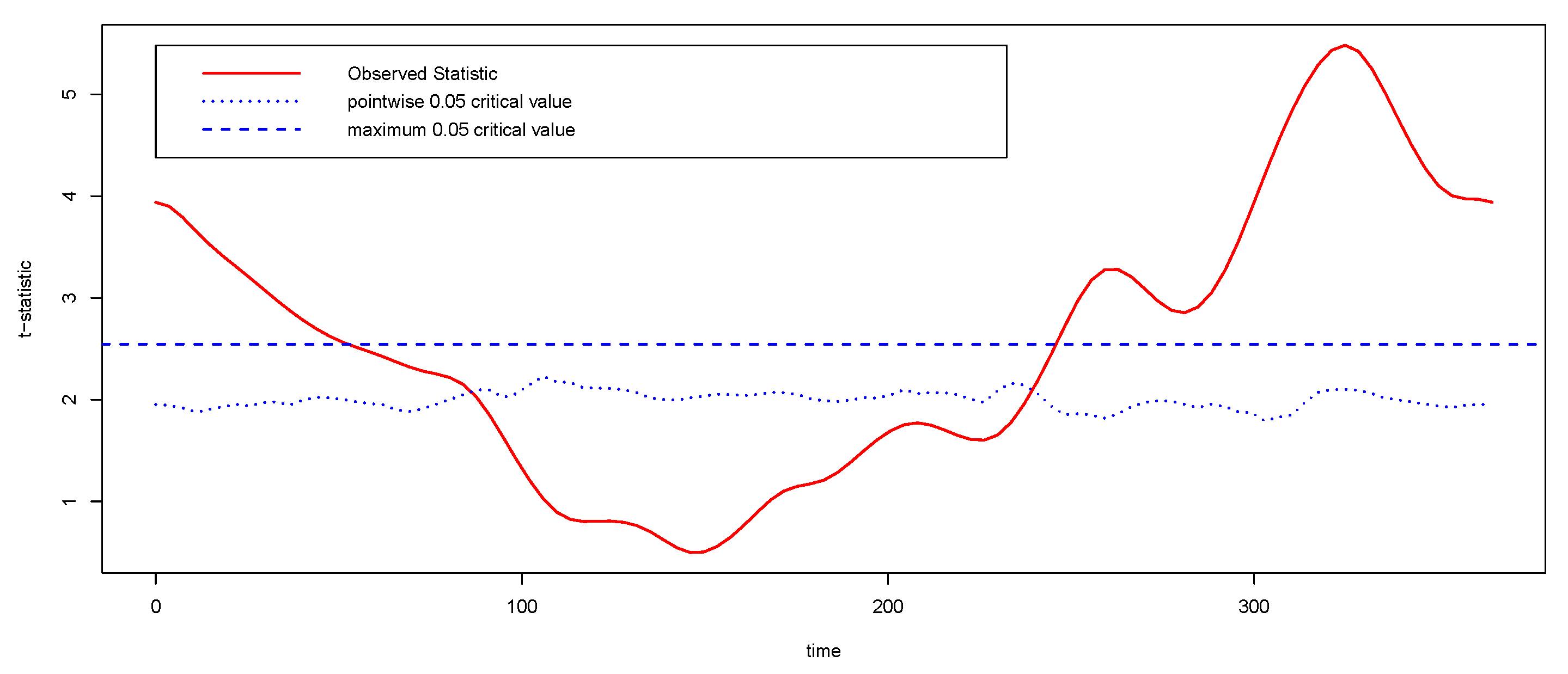
4.2. Application to Canadian Temperature Data
5. Conclusions, Discussion and Future Research
- (i)
- An extension of the sign test to the functional data context was proposed.
- (ii)
- The Wilcoxon test in the functional data field was derived.
- (iii)
- The Mann-Whitney test for functional data analysis was stated.
- (iv)
- The power of the tests for detecting differences between medians of two functional paired samples was evaluated by Monte Carlo simulations.
- (v)
- An illustration with a real data set was considered to show potential applications of the results proposed.
- (i)
- A power comparison between global tests for one-sample and two-sample problems with functional data can be considered.
- (ii)
- The extension to the case of a nonparametric test for the k-sample problem and designs in random blocks are also of interest.
- (iii)
- (iv)
- Usages of the methodology considered in this study may be of interest in diverse fields where the functional data analysis is employed [1].
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Data Availability Statement
Acknowledgments
Conflicts of Interest
References
- Ramsay, J.; Silverman, B. Functional Data Analysis; Springer: New York, NY, USA, 2005. [Google Scholar]
- Ferraty, F.; Vieu, P.; Viguier-Pla, S. Factor-based comparison of groups of curves. Comput. Stat. Data Anal. 2007, 51, 4903–4910. [Google Scholar] [CrossRef]
- Sangalli, L.M.; Secchi, P.; Vantini, S.; Veneziani, A. A case study in exploratory functional data analysis: Geometrical features of the internal carotid artery. J. Am. Stat. Assoc. 2009, 104, 37–48. [Google Scholar] [CrossRef]
- Cardot, H.; Sarda, P. Estimation in generalized linear models for functional data via penalized likelihood. J. Multivar. Anal. 2005, 92, 24–41. [Google Scholar] [CrossRef] [Green Version]
- Bohorquez, M.; Giraldo, R.; Mateu, J. Optimal sampling for spatial prediction of functional data. Stat. Methods Appl. 2010, 25, 39–54. [Google Scholar] [CrossRef]
- Hörmann, S.; Kokoszka, P. Weakly dependent functional data. Ann. Stat. 2019, 38, 845–1884. [Google Scholar] [CrossRef] [Green Version]
- Reyes, A.; Giraldo, R.; Mateu, J. Residual kriging for functional spatial prediction of salinity curves. Commun. Stat. Theory Methods 2015, 44, 798–809. [Google Scholar] [CrossRef] [Green Version]
- Górecki, T.; Krzyśko, M.; Waszak, T.; Wołyński, W. Selected statistical methods of data analysis for multivariate functional data. Stat. Pap. 2018, 59, 153–182. [Google Scholar] [CrossRef] [Green Version]
- Kokoszka, P.; Reimherr, M. Introduction to Functional Data Analysis; CRC: New York, NY, USA, 2017. [Google Scholar]
- Górecki, T.; Smaga, L. fdANOVA: An R software package for analysis of variance for univariate and multivariate functional data. Comput. Stat. 2019, 34, 571–597. [Google Scholar] [CrossRef] [Green Version]
- Horváth, L.; Kokoszka, P. Inference for Functional Data with Applications; Springer: New York, NY, USA, 2012. [Google Scholar]
- Aneiros, G.; Cao, R.; Fraiman, R.; Genest, C.; Vieu, P. Recent advances in functional data analysis and high-dimensional statistics. J. Multivar. Anal. 2019, 170, 3–9. [Google Scholar] [CrossRef]
- Zhang, J. Analysis of Variance for Functional Data; CRC: Boca Raton, FL, USA, 2013. [Google Scholar]
- Pomann, G.; Staicu, A.; Ghosh, S. A two-sample distribution-free test for functional data with application to a diffusion tensor imaging study of multiple sclerosis. J. R. Stat. Soc. C 2016, 65, 395–414. [Google Scholar] [CrossRef] [Green Version]
- Zhang, C.H.; Peng, H.; Zhang, J. Two samples tests for functional data. Commun. Stat. Theory Methods 2010, 39, 559–578. [Google Scholar] [CrossRef]
- Staicu, A.; Li, Y.; Crainiceanu, C.; Ruppert, D. Likelihood ratio tests for dependent data with applications to longitudinal and functional data analysis. Scand. J. Stat. 2014, 41, 932–949. [Google Scholar] [CrossRef] [Green Version]
- Zhang, J.; Liang, X.; Xiao, S. On the two-sample Behrens-Fisher problem for functional data. J. Stat. Theory Pract. 2010, 4, 571–587. [Google Scholar] [CrossRef]
- Zhang, J.; Liang, X. One-way ANOVA for functional data via globalizing the pointwise F-test. Scand. J. Stat. 2014, 41, 51–71. [Google Scholar] [CrossRef]
- Aristizabal, J.; Giraldo, R.; Mateu, J. Analysis of variance for spatially correlated functional data: Application to brain data. Spat. Stat. 2019, 32, 100381. [Google Scholar] [CrossRef]
- Cuevas, A.; Febrero, M.; Fraiman, R. An ANOVA test for functional data. Comput. Stat. Data Anal. 2004, 47, 111–122. [Google Scholar] [CrossRef]
- Cuesta-Albertos, A.; Febrero-Bande, M. A simple multiway ANOVA for functional data. TEST 2010, 19, 537–557. [Google Scholar] [CrossRef]
- Conover, W. Practical Nonparametric Statistics; Wiley: New York, NY, USA, 1999. [Google Scholar]
- Hollander, M.; Wolfe, D. Nonparametric Statistical Methods; Wiley: New York, NY, USA, 1999. [Google Scholar]
- Wilcoxon, F. Individual comparisons by ranking methods. Biometrics 1945, 1, 80–83. [Google Scholar] [CrossRef]
- Mann, H.; Whitney, D. On a test of whether one of two random variables is stochastically larger than the other. Ann. Math. Stat. 1947, 18, 50–60. [Google Scholar] [CrossRef]
- Ramsay, J.; Graves, S.; Hooker, G. fda: Functional Data Analysis, Manual. R Package Version 5.1. 2020. Available online: https://CRAN.R-project.org/package=fda (accessed on 22 November 2020).
- Vempala, S. The Random Projection Method; American Mathematical Society: Providence, RI, USA, 2005. [Google Scholar]
- Nieto-Reyes, A. Random projections: Applications to statistical data depth and goodness of fit test. Bol. Estad. Investig. Operat. 2019, 35, 7–22. [Google Scholar]
- Cuesta-Albertos, J.; del Barrio, E.; Fraiman, R.; Matrán, C. The random projection method in goodness of fit for functional data. Comput. Stat. Data Anal. 2007, 51, 4814–4831. [Google Scholar] [CrossRef]
- Cuevas, A.; Febrero, M.; Fraiman, R. Robust estimation and classification for functional data via projection-based depth notions. Comput. Stat. 2004, 22, 48–496. [Google Scholar] [CrossRef]
- Freimer, M.; Kollia, G.; Mudholkar, G.; Lin, C. A study of the generalized Tukey lambda family. Commun. Stat. Theory Methods 2007, 17, 3547–3567. [Google Scholar] [CrossRef]
- Champely, S. Paired Data Analysis, R Package Version 1.1.0. 2013. Available online: http://cran.r-project.org/package=Paired.Data (accessed on 22 November 2020).
- Arnholt, A. PASWR: Probability and Statistics with R, R Package Version 1.1. 2012. Available online: https://CRAN.R-project.org/package=PASWR (accessed on 22 November 2020).
- Babativa, G.; Corzo, J. A proposed runs trimming test for the hypothesis of symmetry. Rev. Colomb. Estad. 2010, 33, 251–271. [Google Scholar]
- Gastwirth, J.; Gel, J.; Hui, V.; Miao, W.; Noguchi, K. Lawstat: Tools for Biostatistics, Public Policy, and Law. R Package Version 3.3. 2019. Available online: https://CRAN.R-project.org/package=lawstat (accessed on 22 November 2020).
- Giraldo, R.; Delicado, P.; Mateu, J. Hierarchical clustering of spatially correlated functional data. Stat. Neerl. 2007, 66, 403–421. [Google Scholar] [CrossRef] [Green Version]
- Giraldo, R.; Herrera, L.; Leiva, V. Cokriging prediction using as secondary variable a functional random field with application in environmental pollution. Mathematics 2020, 8, 1305. [Google Scholar] [CrossRef]
- Ignaccolo, R.; Mateu, J.; Giraldo, R. Kriging with external drift for functional data for air quality monitoring. Stoch. Environ. Res. Risk Assess. 2014, 28, 1171–1186. [Google Scholar] [CrossRef] [Green Version]
- Diaz-Garcia, J.A.; Galea, M.; Leiva, V. Influence diagnostics for multivariate elliptic regression linear models. Commun. Stat. Theory Methods 2003, 32, 625–641. [Google Scholar] [CrossRef]
- Leiva, V.; Saulo, H.; Leao, J.; Marchant, C. A family of autoregressive conditional duration models applied to financial data. Comput. Stat. Data Anal. 2014, 79, 175–191. [Google Scholar] [CrossRef]
- Garcia-Papani, F.; Uribe-Opazo, M.A.; Leiva, V.; Aykroyd, R.G. Birnbaum-Saunders spatial modelling and diagnostics applied to agricultural engineering data. Stoch. Environ. Res. Risk Assess. 2017, 31, 105–124. [Google Scholar] [CrossRef] [Green Version]
- Martinez, S.; Giraldo, R.; Leiva, V. Birnbaum-Saunders functional regression models for spatial data. Stoch. Environ. Res. Risk Assess. 2019, 33, 1765–1780. [Google Scholar] [CrossRef]
- Sánchez, L.; Leiva, V.; Galea, M.; Saulo, H. Birnbaum-Saunders quantile regression models with application to spatial data. Mathematics 2020, 8, 1000. [Google Scholar] [CrossRef]





Publisher’s Note: MDPI stays neutral with regard to jurisdictional claims in published maps and institutional affiliations. |
© 2020 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (http://creativecommons.org/licenses/by/4.0/).
Share and Cite
Meléndez, R.; Giraldo, R.; Leiva, V. Sign, Wilcoxon and Mann-Whitney Tests for Functional Data: An Approach Based on Random Projections. Mathematics 2021, 9, 44. https://doi.org/10.3390/math9010044
Meléndez R, Giraldo R, Leiva V. Sign, Wilcoxon and Mann-Whitney Tests for Functional Data: An Approach Based on Random Projections. Mathematics. 2021; 9(1):44. https://doi.org/10.3390/math9010044
Chicago/Turabian StyleMeléndez, Rafael, Ramón Giraldo, and Víctor Leiva. 2021. "Sign, Wilcoxon and Mann-Whitney Tests for Functional Data: An Approach Based on Random Projections" Mathematics 9, no. 1: 44. https://doi.org/10.3390/math9010044
APA StyleMeléndez, R., Giraldo, R., & Leiva, V. (2021). Sign, Wilcoxon and Mann-Whitney Tests for Functional Data: An Approach Based on Random Projections. Mathematics, 9(1), 44. https://doi.org/10.3390/math9010044