Proof. Let
be a NSP with the underlying graph
and
for some
;
and
. Let further
. We construct the NUSP
;
and
, where
| , | , |
| , | , |
| , | |
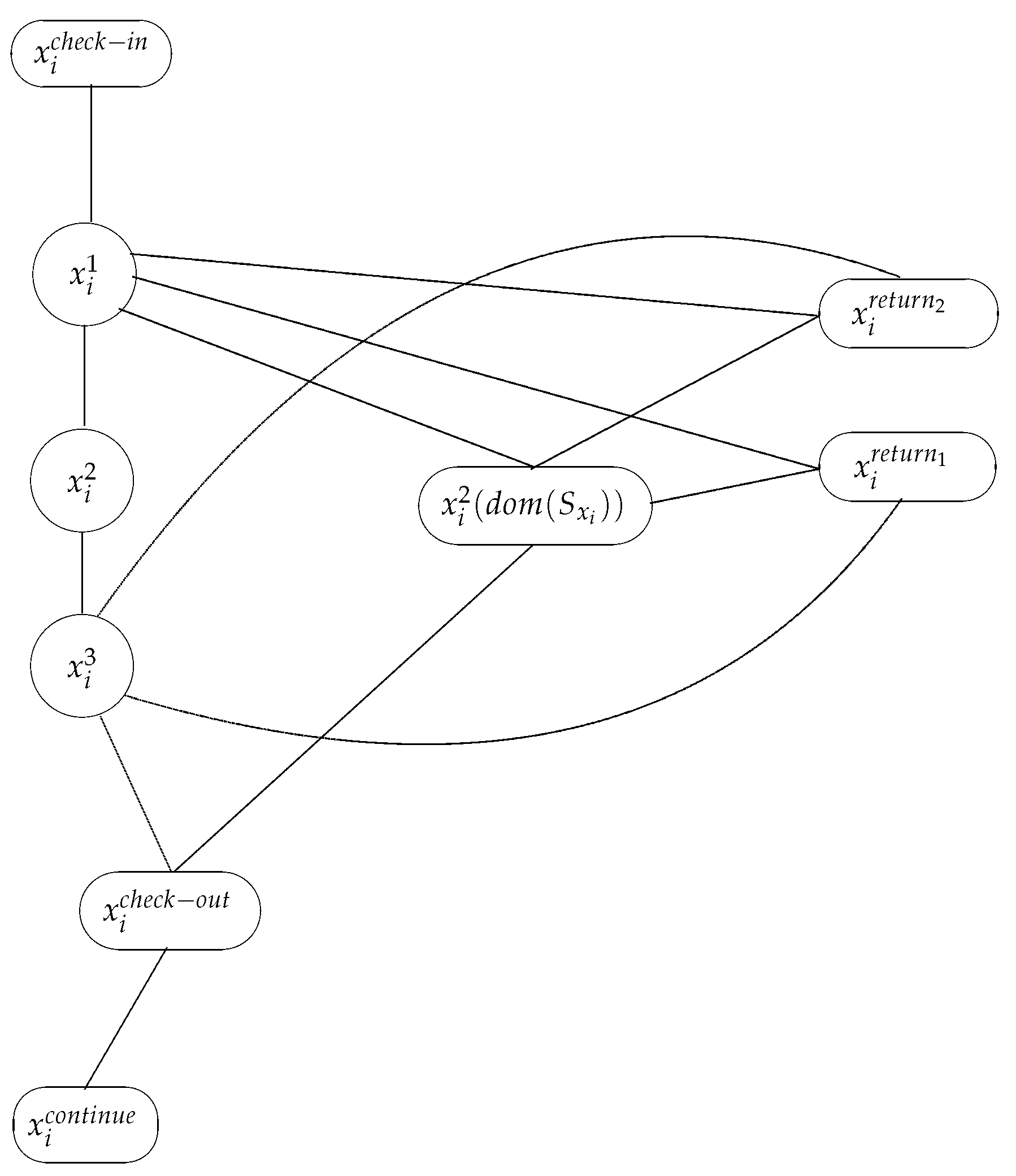
We now define the nodes of
by
Table 1,
Table 2 and
Table 3, while the edges of
are both listed as well as graphically represented.
and
Let
,
be a splicing node. If
, then the nodes defined in
Table 2 belong to
.
All the edges
– ,
– ,
– for ,
– , for ,
– , for ,
– for ,
– , ,
for ,
– ,
for ,
– for all , ,
– , for ,
belong to
. As we have mentioned above, we present also a graphical representation in
Figure 1.
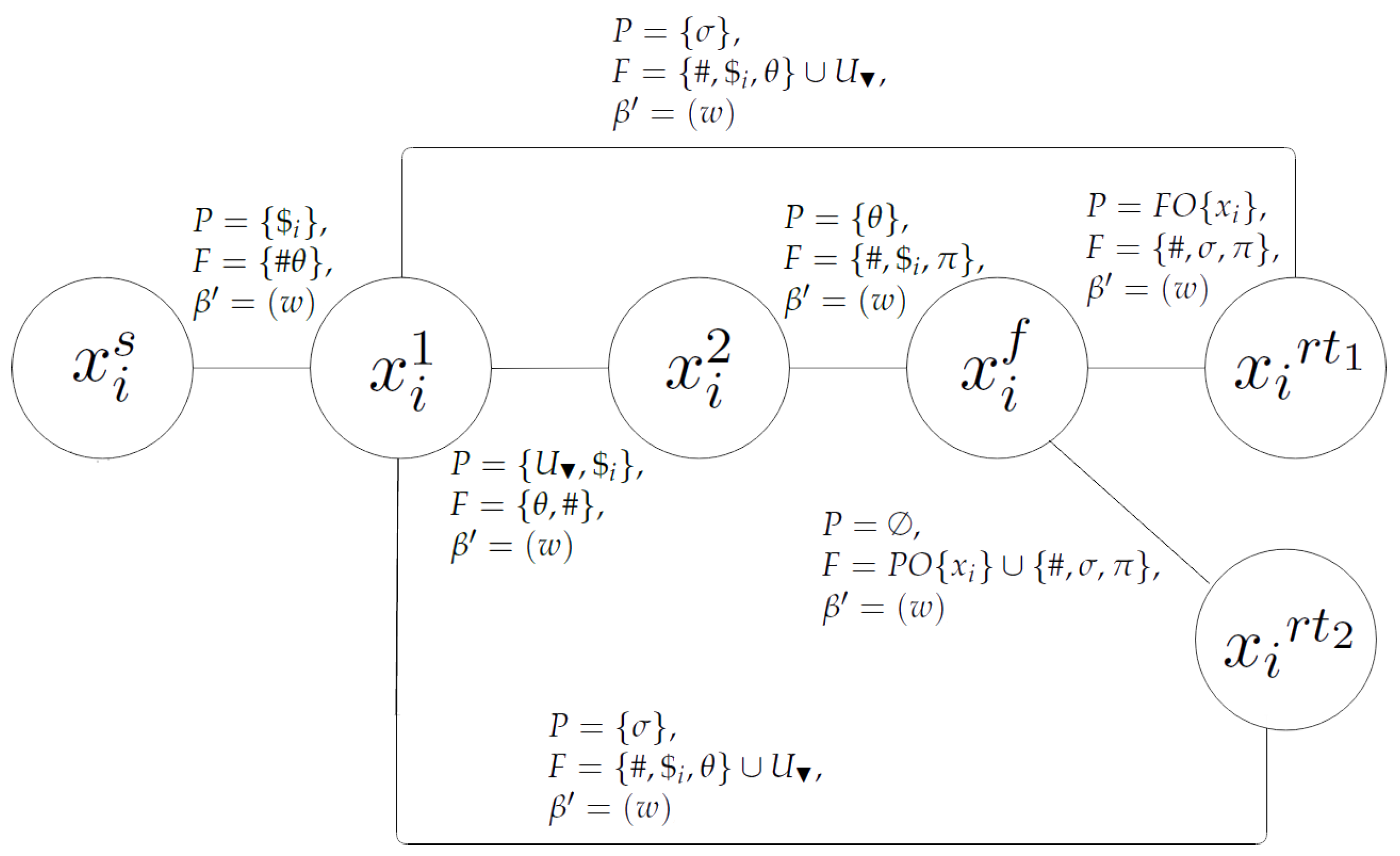
If
, then
is replaced by
nodes of the form
,
, where
,
. They are presented in
Table 3. Furthermore, if
, then
is removed. Analogously, if
, then
is removed. Now, an edge between
,
and
,
, on the one hand, and each node
, on the other hand, is added to
.
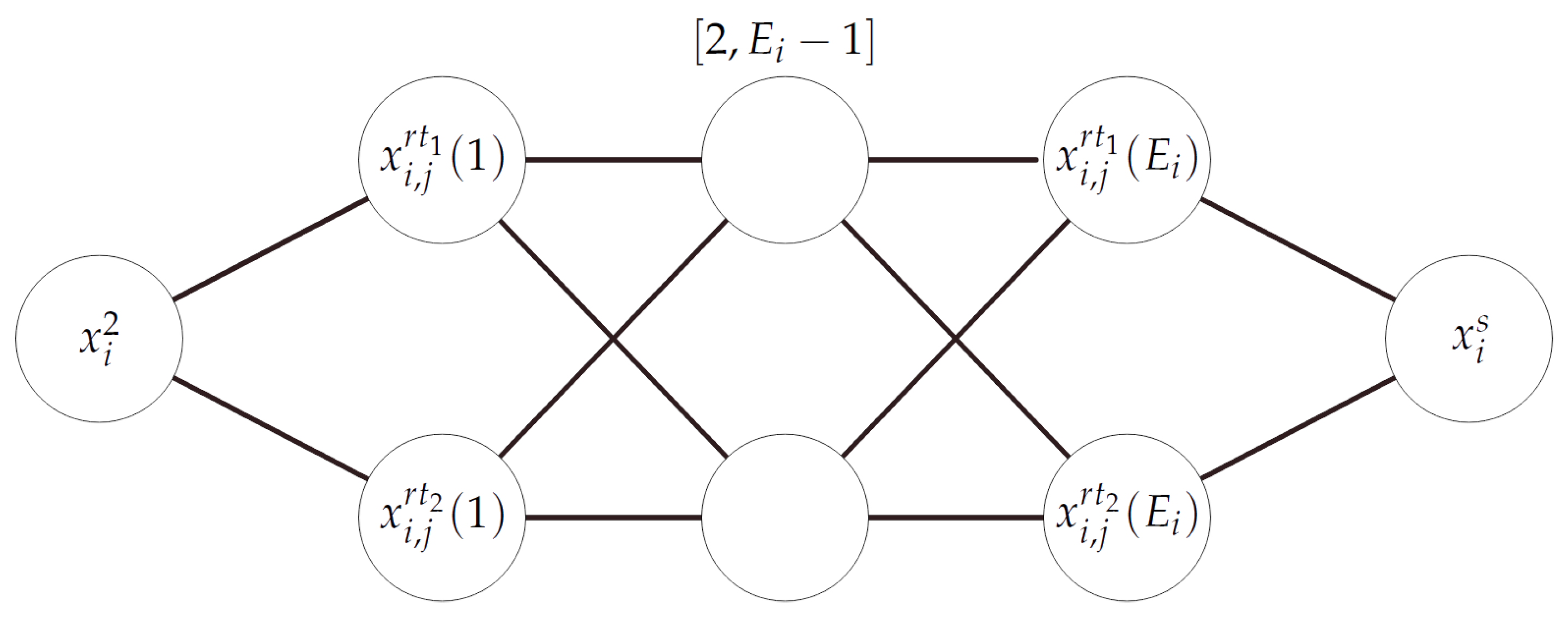
The output node is defined as follows: , and , with , . Finally, we add all the edges , to .
We now analyze a computation of on an input string . In the input node , > is replaced with the sequence . Then, enters , where is replaced with the symbols and the resulting string is sent to the node . Thus, the node contains the string associated to the input string placed in the node . More generally, we may assume that a string , for some , is in if contains the corresponding string . Note that any string produced in can return to . However, these strings have the character switched with , which is not accepted by the connected nodes and . Consequently, the node can be disregarded for the rest of the computation.
We now start the simulation of the first splicing step executed by .
Firstly, we analyze the procedure for the case of a splicing node . In , a rule is applied to producing and , if a rule can be applied to in the node . Let be one string obtained after a splicing step from in . Note that if the splicing rule cannot be applied, then may go out from and enter the following nodes:
, provided that satisfies the condition of the input filter of ,
and if or each of the nodes if , provided that does not satisfy the condition of the output filter of ,
.
All cases are to be analyzed. If leaves and enters , the symbol is replaced with , which locks the string in that node. If leaves and enters , then ping-pong processes between these two nodes as well as between and start. We distinguish here the cases of weak and strong filters. If , the string can also enter , starting an identical relationship to the one between and the nodes , . If , the string enters the nodes , provided that does not contain the character , followed by the same ping-pong process between these nodes and , . In this last case, the structure simulates the situation where a string remains in the node because it only contains a proper subset of the characters in .
If leaves and enters , then is replaced by ; the new string is simultaneously sent to all nodes , and . If it enters , then is replaced firstly by (in ) and secondly by some (in ) provided that . The newly obtained string is sent to . Note that this situation simulates exactly the situation when is sent to after staying unchanged for one splicing step in . The case when enters any of the nodes and is considered above.
The only case remaining to be analyzed is when is transformed into (either or ) after applying a splicing rule in . Then, leaves . We follow the route of this string through the network: , where is replaced by , then , where and are replaced by u and v, respectively. We analyze in detail the case for a string with . The application of the first splicing rule on a string yields two strings, namely and . These two strings cannot exit the node, as they contain # and , respectively. In the next splicing step, these two strings can only combine between themselves through the second splicing rule , yielding two new strings: and . The first one cannot be used in the computation anymore, while the latter is the original string with replaced by u. The procedure for a string with is analogous through the application of the other two splicing rules.
After leaving , the new string, say , can enter either or at least one of and . If it enters and consequently , then the following computational step in was simulated in as follows: was obtained from by means of a splicing rule in , then was sent to all neighbors of . The situation when enters one of the nodes and corresponds to the situation when remains in for a new splicing step, as it cannot pass the output filter of .
We now analyze the computational steps required for simulating a computation in . The input node and require 1 splicing step (or 2 computational steps) each. In the worst case, a splicing step in one of the nodes can be simulated in in 7 splicing steps (or 14 computational steps) distributed in the following way:
2 steps in .
2 steps in .
4 steps in .
2 steps in .
2 steps in .
2 steps in .
Note that the simulation only requires 12 computational steps if since is not simulated by a subnetwork and the computation halts once a string enters that node. By all the above considerations, we conclude that and . □








{kind=link}
{kind=link}
{kind=link}