2. Preliminaries
The q-ary convolutional codes were applied to multitone images. The procedure for constructing the proposed embedding scheme involves the following aspects: (i) how to generate multiple-level tone images from a grayscale image; and (ii) how to construct an embedding system using an optimal decoding algorithm.
Error diffusion is a popular halftoning technique. Two-level representations are used in this technique to replace the original grayscale image or color image. This technique can be considered a generalization of multiple tones. Let
and
be coordinates of a grayscale image and a multiple-tone image, respectively, after quantizing point
. The quantization error
is expressed as
. The multiple-tone point
can be obtained using the following expression:
To transform the grayscale image into a multiple-tone image, an error filter is used in all filtering areas to obtain the final multiple-tone image. By contrast, in the recovery procedure, the multiple-tone image is recovered as the grayscale image. A low-pass filter is used to filter the points in the grayscale image and to obtain a continuous tone image.
- 2
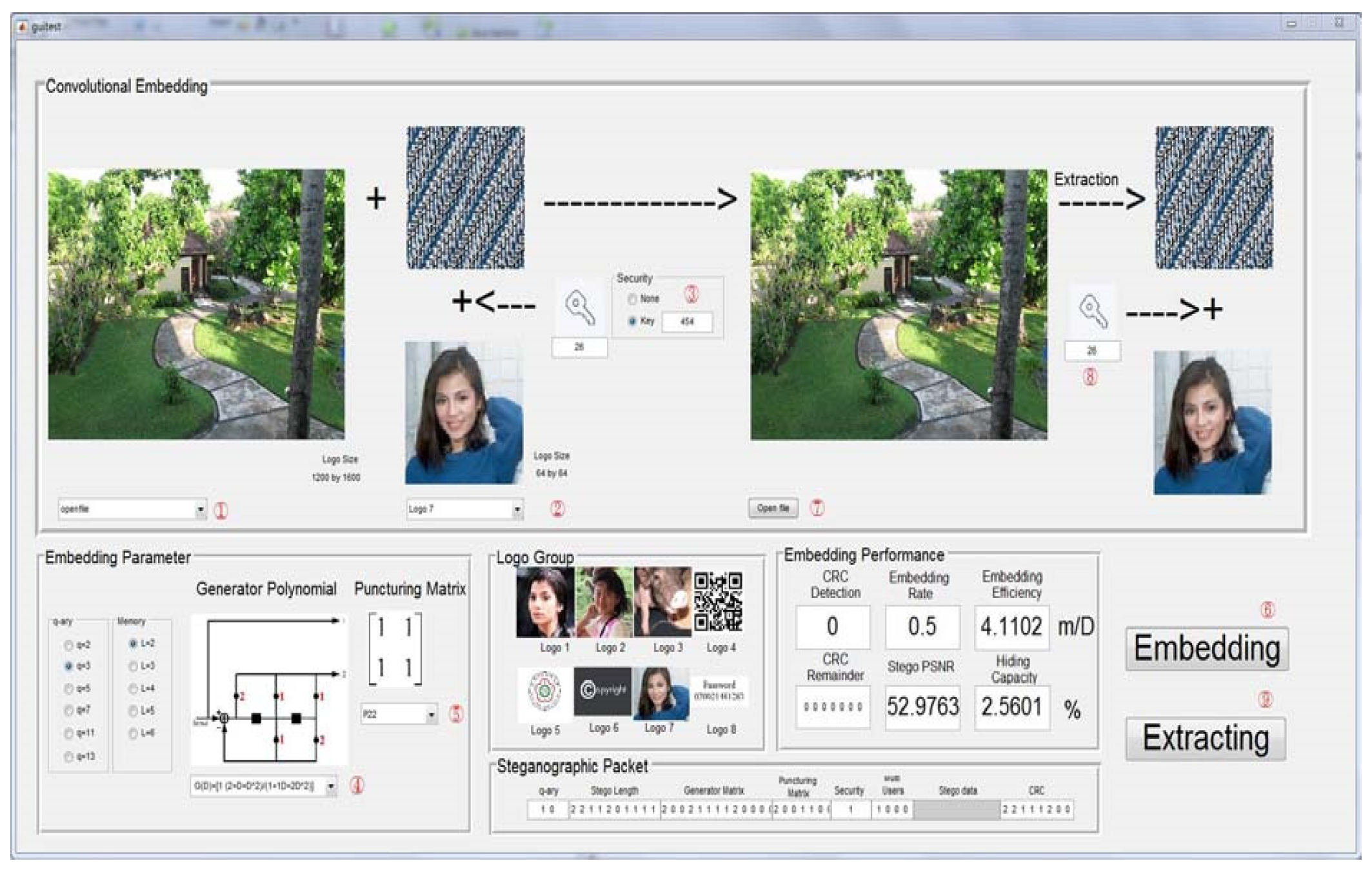
Embedding scheme and efficiency bound
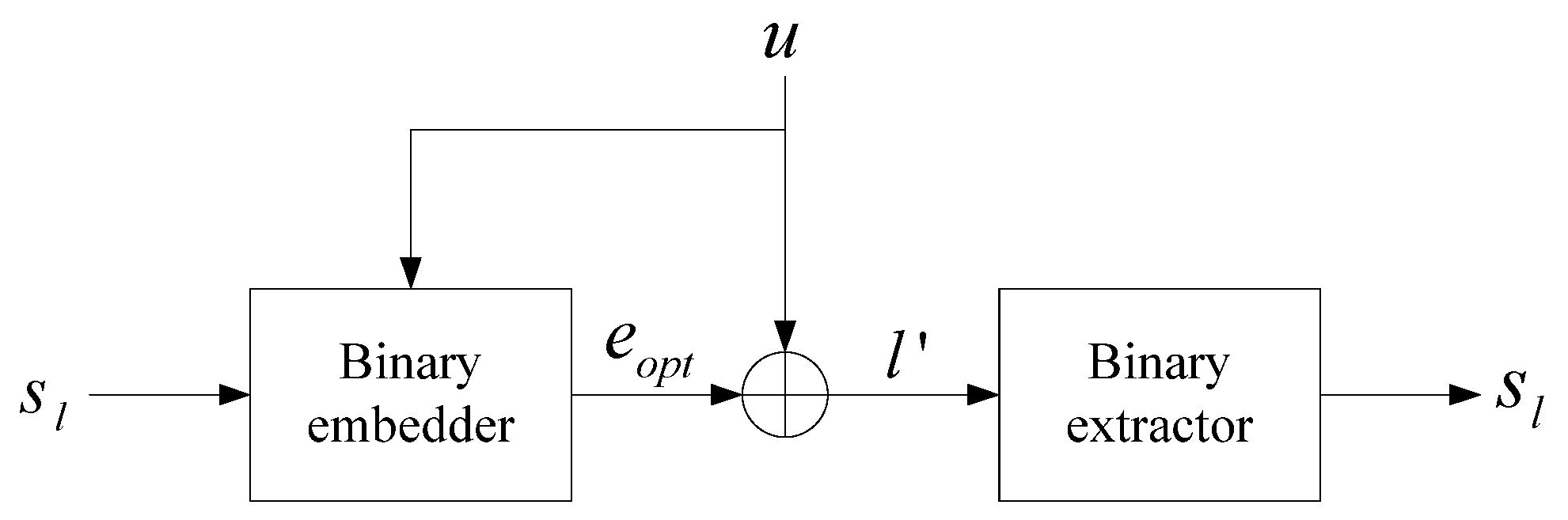
The goal of the binary embedding scheme is to quantify the source limited by the distortion theory. The embedded model and extraction model are shown in
Figure 1.
Under the assumption that a logo
embedded into a cover
is transmitted to the receiver, the optimal stego
is provided by the embedder. Thus, a message
, which is modified from
, corresponds to syndrome
. Given a cover
, which is a Bernoulli-1/2 process in the binary symmetric source, it subtracts some toggle
; thus
. Even though the embedder knows the cover
, it cannot simply cancel this known interference due to the constraint that the average number of 1s cannot exceed
, where
is the block length and
. We define the optimal or minimum quantized error
, where
denotes the Hamming distance between stego
and cover
. The optimal quantization error
is the optimal modified vector such that the host
and stego
are of optimal quantization error. The rate distortion can be calculated as
, where
denotes the bound and
denotes a binary entropy function, by an
linear code
with a code rate
. Thus, the embedding rate is
. Therefore, for a given good linear code with embedding rate
, optimal distortion
can be approached. Theoretically, the codeword of a linear code
can be regarded as a quantized message set
, with
as the average distance between an arbitrary cover set
. The upper bound of the embedding capacity can thus be expressed as follows:
where
is the embedding rate corresponding to the optimal distortion
. If a well-designed linear code exists, then the theoretical upper bound can be approached by an associated embedder. However, the major concern is to determine a parity-check matrix with a well-behaved
linear code and a code rate
. Furthermore, with the embedding rate requested in such a linear code
, the aforementioned equation can then be expressed as follows:
For a binary symmetric source and an
bit source sequence
, the average distortion per bit is defined as follows:
where
represents a quantized codeword existing in code
, and
is the average Hamming distortion between
and
per block. For an
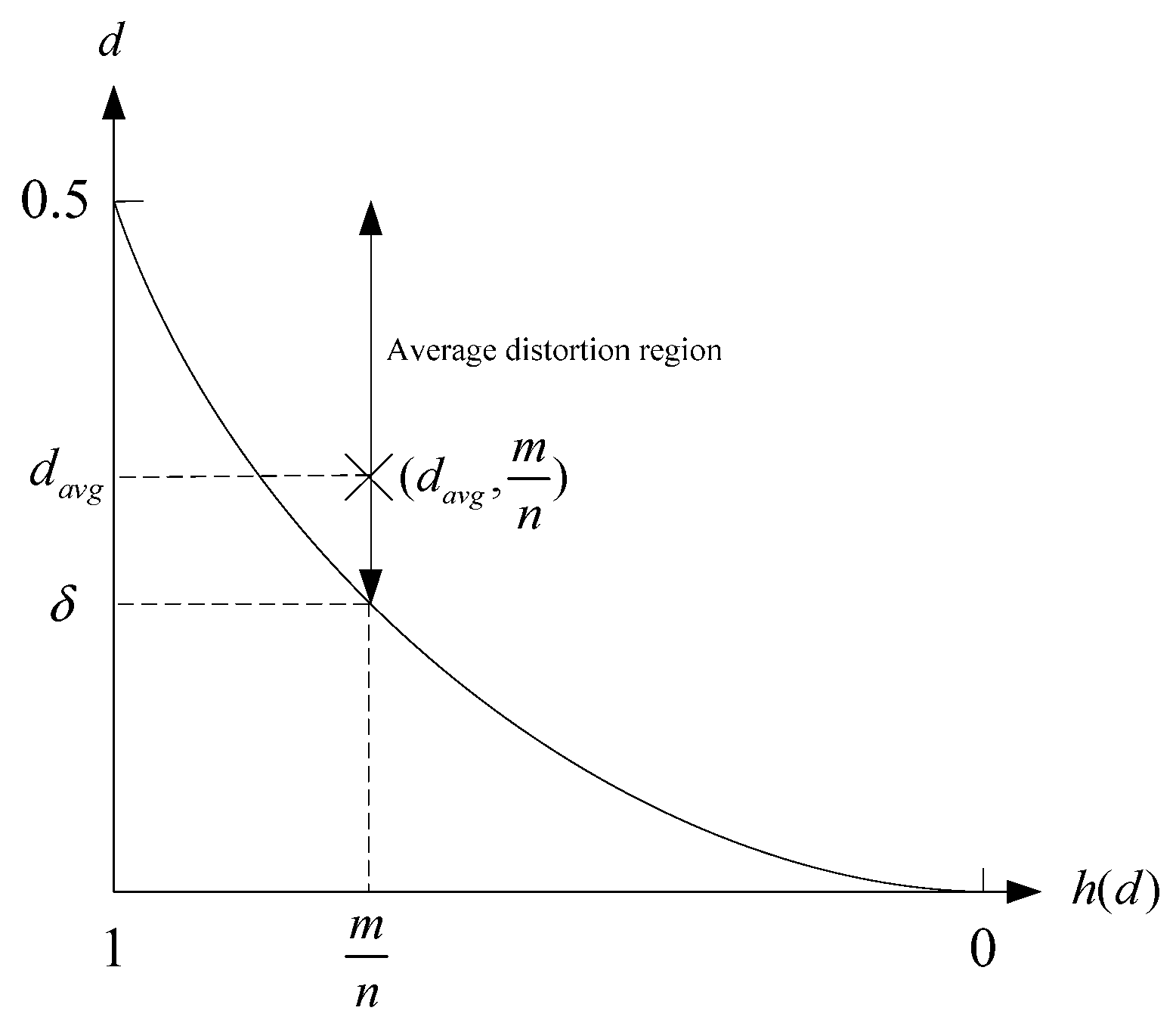
linear block code, the minimum average distortion can be expressed as follows:
where
is the inverse function of the binary entropy function
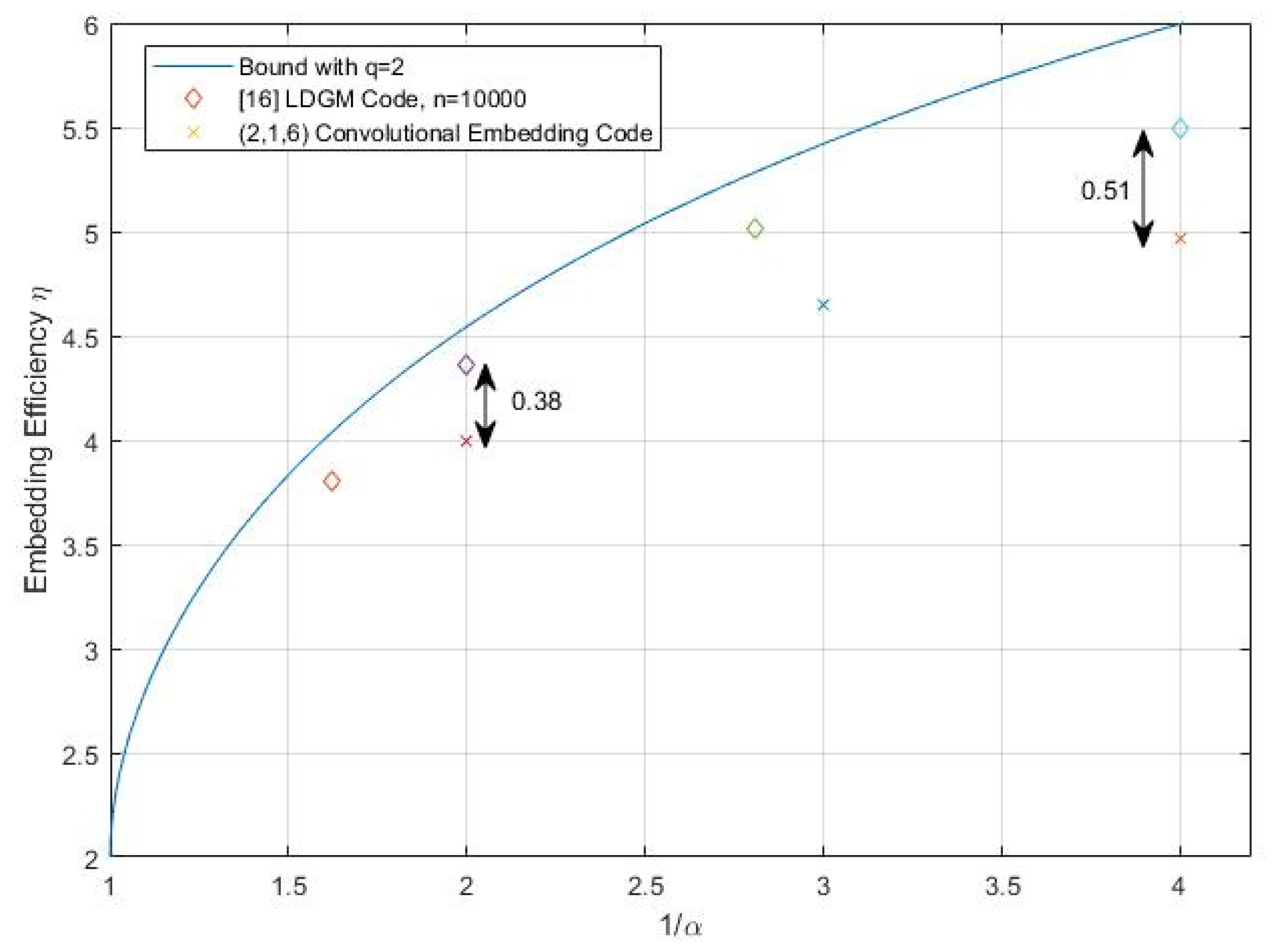
. The aforementioned equation is the rate-distortion function. The lower bound
of average distortion for each bit in a code block is
. The lower bound
of each bit average distortion in blocks is displayed in
Figure 2.
When performing the binary data embedding of a sequence of length
bits, the embedding efficiency is defined as follows:
3. Embedding Algorithm for Small and Large Payloads
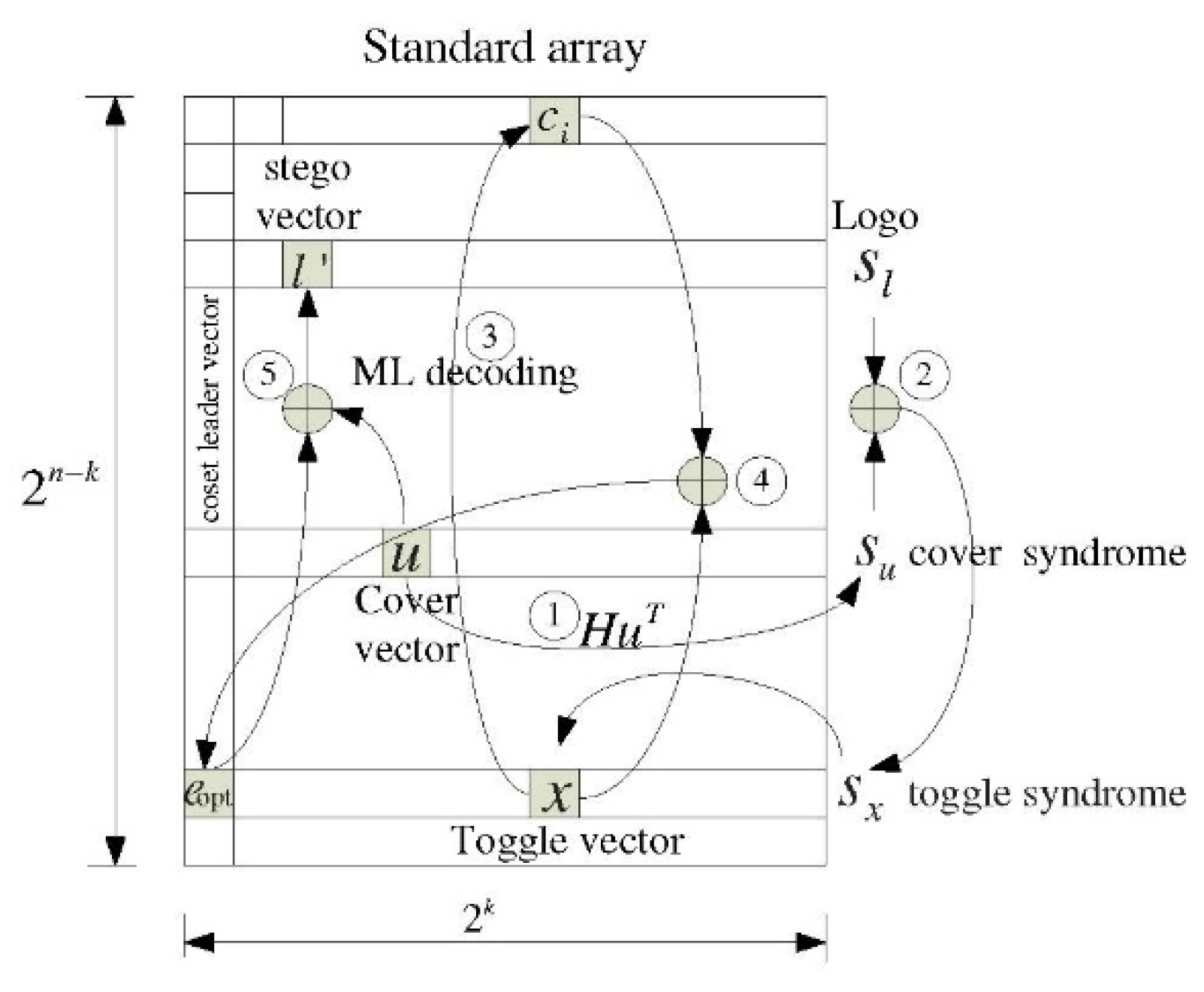
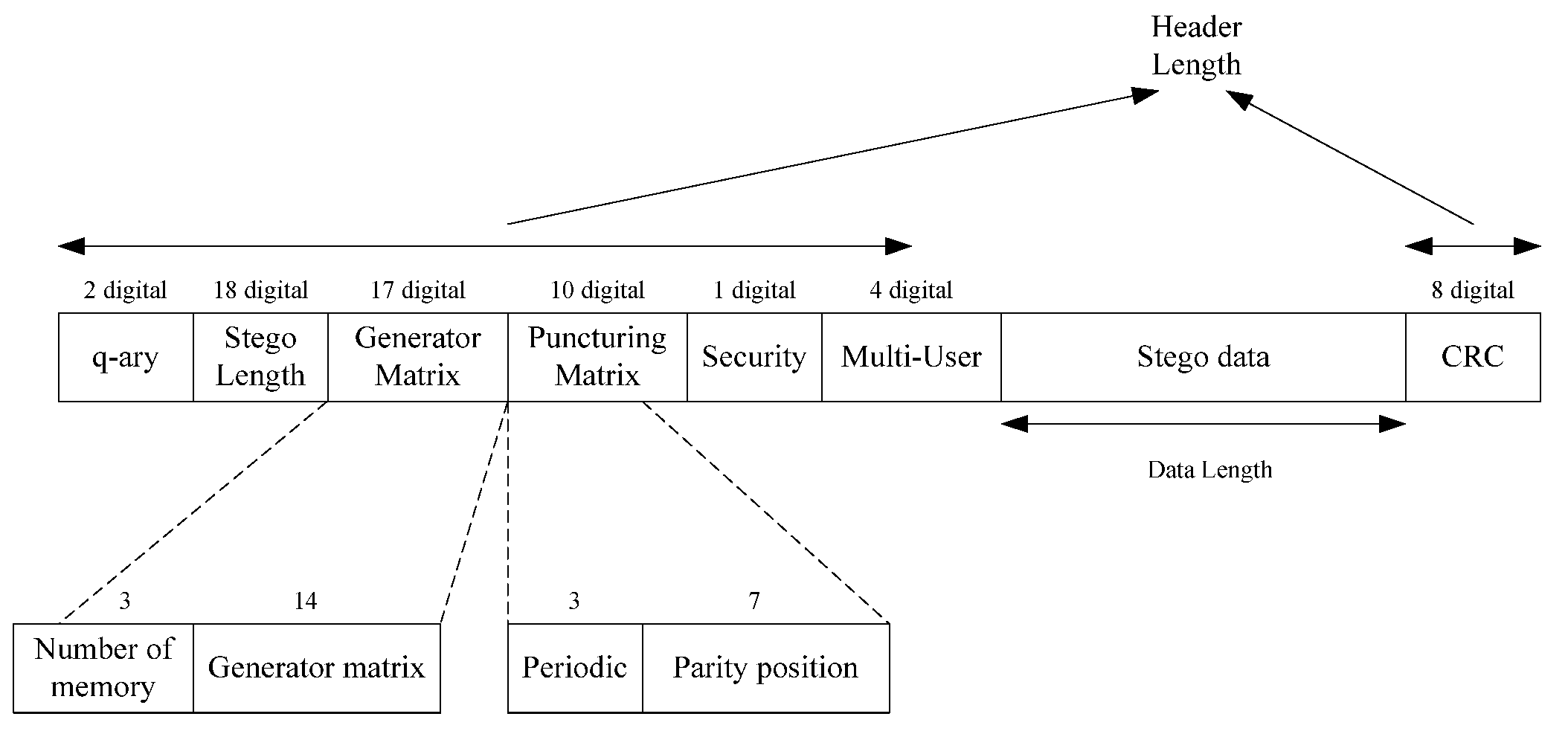
Binary data embedding was achieved by using a standard array as follows: with
linear code
, we developed a standard array with a size of
, as displayed in
Figure 3.
Alternatively, the required coset leader can be determined precisely to perform binary data embedding or optimal embedding. An
linear code
can be characterized with a parity-check matrix
of size
as follows:
where the sequence is
. Based on (7), the syndrome
of the sequence
is defined as
. Furthermore, the set composed of all the sequences
corresponding to identical
is referred to as the coset of code
and is defined as follows:
where
denotes the coset leader in the standard array. The term
can be derived through
from an arbitrary sequence
, and
can be expressed using an ML decoding function as follows:
where
represents the decoding function of the linear codes. Using ML decoding, the coset leader
is added to
to recover the codeword
, which is closest to the sequence
.
As displayed in
Figure 3, for convolutional codes, it is necessary to determine the minimal toggle vector,
, namely the coset leader, for a convolutional code
in the vector domain to solve the equation
, where
. We considered the following simple embedding method. Using a systematic form CE in the vector domain, the equation can be used to solve the following expression:
Assuming that is a solution for , toggle vector can be determined immediately with and ; toggle can also be determined immediately. This section focuses on the efficient identification of the toggle vector using a systematic encoding technique. A symbol must be defined to describe the embedding of algorithms based on convolutional codes. Assuming that the convolutional code is a non-system generator matrix, it can be converted into a system generator matrix using basic row operations. Alternatively, the code can be expressed in a system recursive form. We use CE to embed binary messages as follows:
An embedding scheme with small payloads is used for numerous applications. However, for a case of
CE codes with a low embedding rate, the trellis structure has high branches per state because of a large
, which indicates that a complex mechanism is required when performing the Viterbi algorithm. To avoid this disadvantage, we constructed a CE code at a low embedding rate. The
CE code was obtained through puncturing. In the time domain, we constructed an embedding rate
, where
is the puncturing period and
is the number of deleted bits. Systematic recursive CE codes can be obtained by puncturing the output of a
convolutional code with the puncturing matrix
as follows:
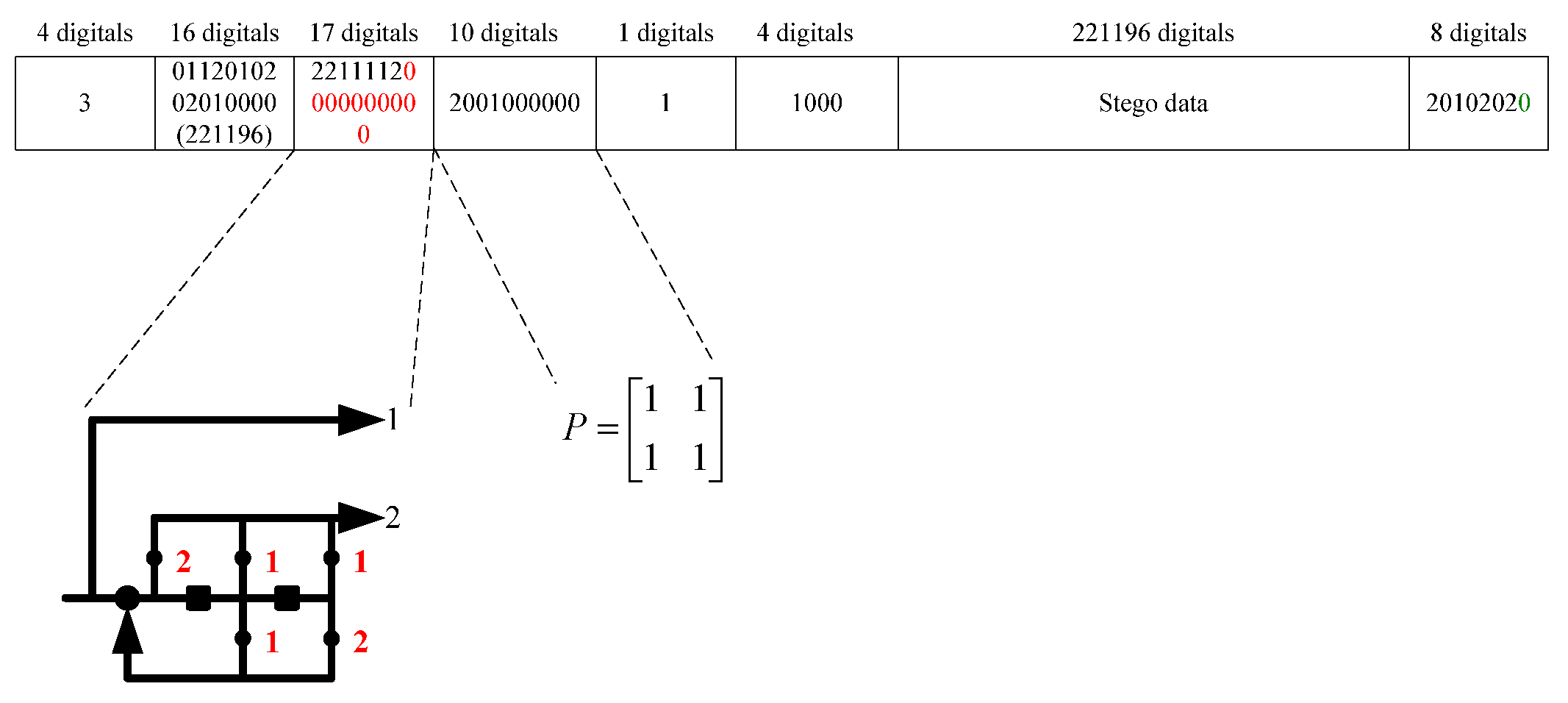
Based on (10), we selected
and
to obtain the required
. In puncturing matrix
, if
, the corresponding output bit from the CE code is embedded. Otherwise, the corresponding output bit from the CE code is deleted. To construct a systematic CE code by puncturing, the embedding algorithm must first locate the matrix
corresponding to message
with length
bits in period
. However, because of a systematic encoder,
is set in assigned locations with respect to the set of indices
. Here,
of the second-row sequence
in period
. We located
assigned indexes in
corresponding to the location
as follows:
where
and
is expressed as follows:
Thus, provided a cover matrix corresponding to , we can obtain the toggle matrix as in a puncturing period .
A notation must be defined to describe the embedding of a convolutional code-based algorithm. Here, CE is a nonsystematic generator matrix that can be translated into a systematic generator matrix using elementary row operations. Alternatively, it can be expressed in systematic recursive form. We used a CE to embed the binary message as follows:
A CE with a generator matrix
is defined as follows:
where the information sequence is
and the codeword sequence is
. Codeword
is closest to a random binary sequence
with respect to the Hamming distance over the binary symmetric source. Convolutional code
was used to generate the minimum error sequence
from a quantization perspective as follows:
where the
is the quantizer, which can be expressed as follows:
where
and
The nearest neighboring quantizer
, which we interpreted as the minimum error vector
in quantizing
using
and
, can be realized using the Viterbi algorithm for CE with a trellis structure. Finally, we defined the Voronoi cell of
as the set
Consider the use of algebraic equations for the coset code of CEs. Furthermore, assume the shifted coset code
of a convolutional code
, where
is defined as the sum of
and a minimum error sequence
. Subsequently, by using
, an arbitrary binary sequence
is quantized using coset code
as follows:
where the shift sequence
, that is,
and
, denotes the error sequence or coset leader sequence in quantizing toggle sequence
by
. It is assumed that cover sequence
is uniformly distributed in
; moreover, the toggle sequence
, which is obtained by subtracting message sequence
from cover sequence
, is also uniformly distributed. The minimum distance sequence
between cover sequence
and message sequence
is equal to (16). By quantizing a random binary sequence
by
, an average quantized distortion level is represented as follows:
Similar to the linear block codes, the optimal toggle vector must be determined using convolutional systematic codes. A simple method similar to the systematic coding approach is data embedding using linear block codes with a coset vector associated with . The method in which the toggle vector was obtained in a systematic block code binary embedding was applied to the systematic CE binary embedding. The embedding procedure for systematic CE is as follows:
For a message syndrome sequence
of length
, it is necessary to determine sequence
of length
with syndrome
as the linear code. For a special
systematic convolutional code case, a generator matrix
can be defined as follows:
where
. The transposition of
yields the following expression:
where
is an
matrix and embedded sequence
and is derived using the following expression:
which is used to solve the following expression:
This equation is complex. Due to the systematic encoder,
of size
can be solved. Furthermore, the toggle sequence
is obtained by subtracting
from
. Embedder
quantizes the arbitrary toggle sequence
to generate the optimal stego sequence
as follows:
Finally, sequence
closest to sequence
, corresponding to syndrome
, is derived as follows:
At the receiver, message sequence
is extracted as follows:
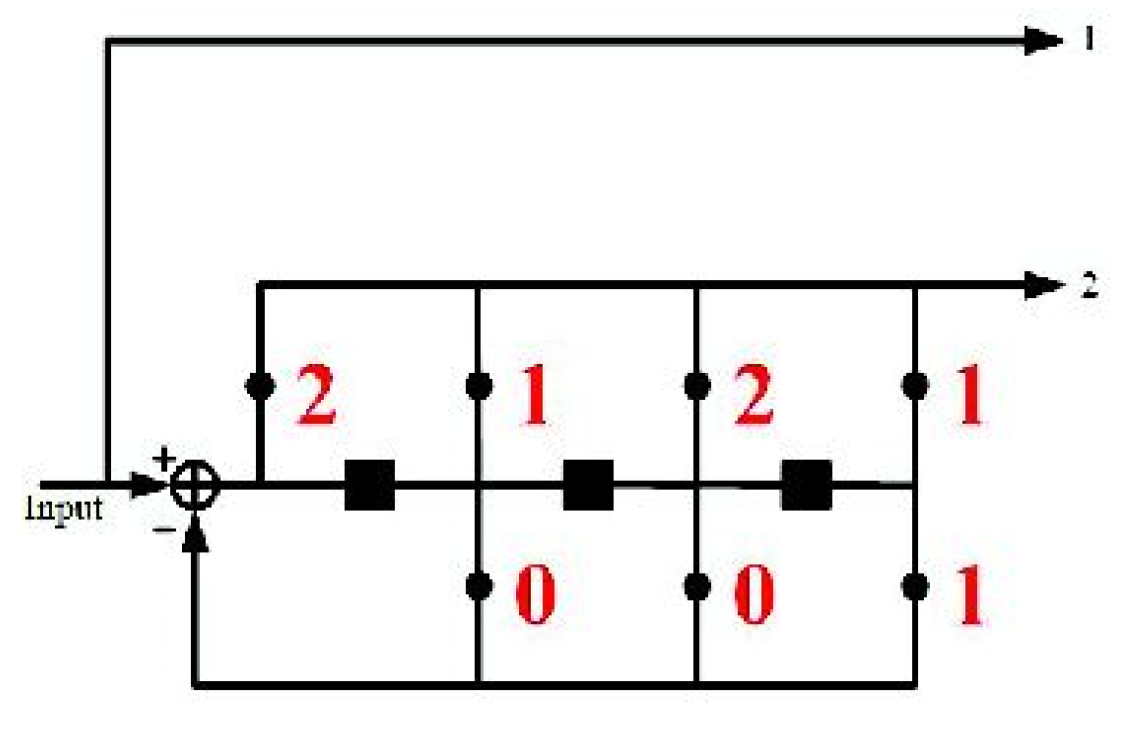
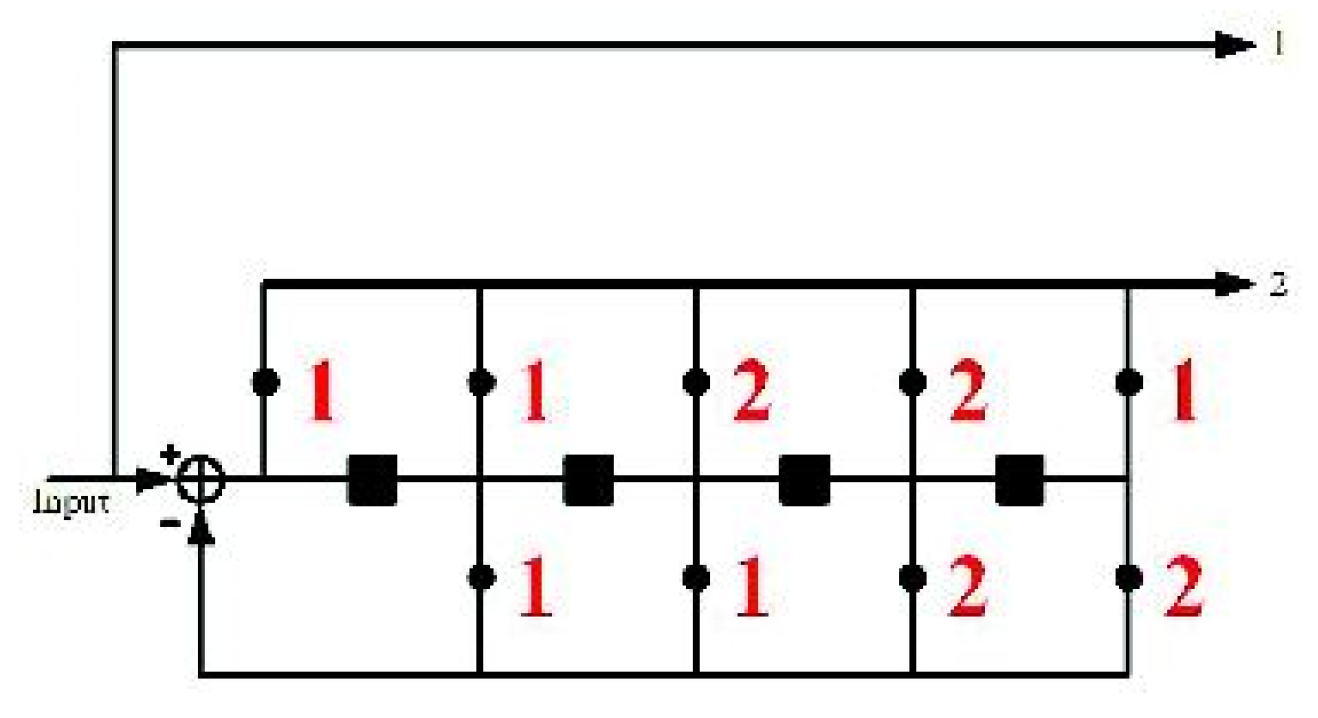
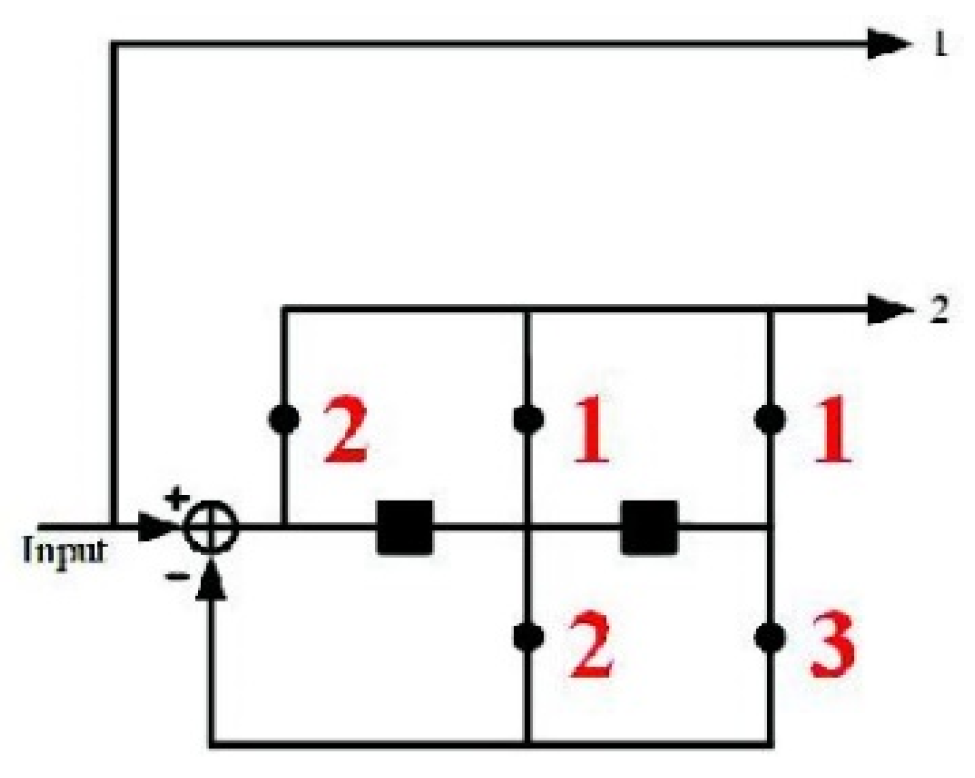
. To illustrate the nested CE algorithm, the following example is based on a systematic convolutional code to describe the embedding procedure, displayed as follows. Consider an embedded message sequence
and a cover sequence
. As the systematic convolutional codes are used, we easily obtain solution
corresponding to
. Subsequently, a systematic CE binary embedding is performed. Assuming that
is the symbol intended for embedding, vector
represents a sequence, that is, a (2, 1) systematic CE with the syndrome
,
, and the toggle sequence corresponding
to
and falling within the coset
can be determined as follows:
The optimal toggle sequence
corresponding to syndrome
can be discovered by performing Viterbi decoding of
as follows:
where
is a Viterbi decoding function. The procedure for finding an optimal toggle sequence
is displayed in as above. Finally, the stego sequence can be obtained as follows:
In the receiver, we reconstructed the message sequence as follows:
A crucial factor of CE codes is the method for determining the optimal generator matrix for large payloads.


{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}













