Abstract
The traditional machine-part cell formation problem simultaneously clusters machines and parts in different production cells from a zero–one incidence matrix that describes the existing interactions between the elements. This manuscript explores a novel alternative for the well-known machine-part cell formation problem in which the incidence matrix is composed of non-binary values. The model is presented as multiple-ratio fractional programming with binary variables in quadratic terms. A simple reformulation is also implemented in the manuscript to express the model as a mixed-integer linear programming optimization problem. The performance of the proposed model is shown through two types of empirical experiments. In the first group of experiments, the model is tested with a set of randomized matrices, and its performance is compared to the one obtained with a standard greedy algorithm. These experiments showed that the proposed model achieves higher fitness values in all matrices considered than the greedy algorithm. In the second type of experiment, the optimization model is evaluated with a real-world problem belonging to Human Resource Management. The results obtained were in line with previous findings described in the literature about the case study.
1. Introduction
Group technology (GT) is a manufacturing approach in which parts with a high percentage of similarities are grouped and manufactured with a small number of machines or processes [1]. GT is employed for product design and manufacturing system design. In the GT literature, the group of parts with common similarities is known as part family, and the group of machines employed to process an individual part family is denoted as machine cell. In this context, cellular manufacturing (CM) emerges as an application of GT in which a machine cell manufactures a part family [2,3,4]. The manufacturing efficiencies are generally improved by implementing GT techniques as the required operations may be reduced to only a small cell and thus avoiding the need for transportation of in-process parts [5].
Diverse algorithms, heuristic and nonheuristic approaches, have been proposed for solving the CF problem [6]. Those methods can be categorized as: (i) array-based clustering methods [5], (ii) mathematical programming methods [7] and (iii) heuristics models [8,9,10]. Additionally, the techniques implemented for addressing the CF problem can also be divided, according to their philosophy, into three groups: (i) those that consider the grouping of parts into part families followed by assignment of machines to part families [11]; (ii) those that consider the grouping of machines into machines cells followed by assignment of parts to machine cells [12], and (iii) those that are based on simultaneous grouping of parts and machines to manufacturing cells [13].
The methods implemented so far for the simultaneous grouping of family parts and machine cells are based on a machine-part incidence matrix composed of binary 0–1 elements. A “one” entry in that matrix indicates that this part has an operation scheduled in the corresponding machine; zero indicates that it does not. In this manuscript, we explore an alternative formulation of the CF problem with non-binary values. In the proposed formulation, the goal is to maximize the sum of mean performances of the different groups, and therefore, it is expressed as a multiple-ratio optimization model with quadratic terms. The model was reformulated as a mixed-integer linear programming (MILP) to reach, in this way, the global solution of the problem through standard MILP solvers. The novel optimization problem has multiple unexplored applications in areas such as machine learning (biclustering, feature and instance selection), human resources (to create groups of employees according to their skills), or education (for grouping students according to their competencies), among others. Specifically, the significance of the model was shown through its application into a real-world problem belonging to the area of Human Resource Management (HRM) in a complex setting as the accounting profession.
In the real-world problem, the goal was to simultaneously group employees and job quality indices to identify areas of enhancement in a specific group of employees. The sample used includes a set of accountants of the European Union, and its job quality was measured through seven indices (such as earnings, prospects, or work time quality) [14]. The accounting profession is an exciting setting because it faces job demands that can hardly be managed. On the one hand, there is a strict concentration of work around the closing of accounts and intense competition between accountancy firms [15]. On the other hand, the particularity of the corporations’ systems makes it complex to manage flexibly the teams which must face the increasing demand for work around the issuance of financial statements [16]. Unfortunately, inadequate pressure management can lead to a decrease in the quality of annual reports, their auditing, and, consequently, a deterioration in market confidence in an essential input for decision-making on resource allocation [17,18]. The way to deal with these pressures lies in managing job resources, and this paper contributes to shedding light on this issue in the specific case of the auditing profession.
Hence, the findings obtained in the research will allow human resources practitioners to implement tailored human resources incentives for their staff members. This new era of human talent management, where workers can develop their full potential through individualized work experiences, requires a better design and implementation of tailored human resource practices. In this sense, Berhil et al. pointed out that most human resource management issues (such as selection and recruitment, compensation, or turnover) need to be addressed on a case-by-case basis to ensure the effectiveness of the proposed strategies [19]. The systematic literature review carried out by these authors highlighted that artificial intelligence solutions tend to be the most frequent. In particular, the most commonly used methods and algorithms were Decision Tree (30%), Support Vector Machine (17%), Random Forest (17%), logistic regression (15%), K-Nearest Neighbor (11%), Multi-Layer Perceptron (4%), C4.5 algorithm (4%) and Gaussian Naïve Baye (2%). In this manuscript, we extend the set of methodologies to be implemented in the HRM area by proposing a novel method from Operations Research.
In summary, the main contributions of this manuscript are as follows:
- Contributions to the MPCF field:
- -
- To propose an alternative formulation of the MPCF for non-binary values.
- -
- To implement a MILP approach for the problem mentioned above.
- Contributions to the HRM field:
- -
- To understand how European accountants are grouped according to their job quality indices.
- -
- To propose a methodological approach to implement tailored human resource strategies.
- Contributions to the Accounting profession:
- -
- The high demands of the profession are mainly managed through workplace social climate.
- -
- Accountants assume work intensity as an intrinsic characteristic of the profession, and, due to this, they do not prioritize its improvement. In this context, accountancy firms must develop job resources to lessen the stress of their employees.
The remainder of the manuscript is organized as follows. Section 2 describes the foundations of the MPCF problem (main objective, performance metrics, and algorithms). Section 3 details the optimization model proposed to address the MPCF problem with non-binary values. Section 4 reports the empirical results obtained by the model in both randomized incidence matrices and a real-world problem related to the area of HRM, and Section 5 presents the conclusions that were reached in the study.
2. The Machine-Part Cell Formation Optimization Problem
The Machine-Part Cell formation (MPCF) problem is formulated from two different sets, and . The set encompasses the N machines and the set includes the D parts. The production incidence matrix indicates the interactions between the parts and the machines, and consequently each component stands for the interaction that the n-th machine, , has on the d-th part, ( if machine n process part d, 0 otherwise).
In the baseline MPCF optimization problem, a particular machine, n, processes several parts (as expected) and a part d may be processed by several machines. A production cell g, , includes a subgroup of machines and a subset of parts, . Thus, the goal is to compute a solution of G production cells, , as autonomous as possible.
It is important to stress that the optimization procedure produces partitions of the machines set and of the parts sets with the form:
for all pairs of different cell indices and In the interests of clarity, Table 1 reflects an example of matrix rearrangement according to the MCPF optimization problem with 7 machines and 11 parts. As can be seen, the output of the optimization process is a diagonalized matrix with 3 different cells, highlighted with gray color (3 machine groups and 3 families of parts ). The elements and are denoted in the MCPF literature as exceptional elements and correspond to entries with a value of 1 outside of the gray diagonal blocks. The elements or are called voids and correspond to 0s inside the diagonal blocks.

Table 1.
Example of matrix rearrangement in the baseline MPCF problem (extracted from [27]).
One of the first proposals for converting a binary matrix into a block diagonal form implemented a measure called bond energy [20], which is computed as follows:
where . In the field of MPCF optimization, several performance measures have been proposed in the literature [21,22,23,24]. The original metric was called grouping efficiency and it is defined as [21]:
where q is a weighting parameter, is the ratio of the number of 1s in the diagonal blocks concerning the total number of 0s in these diagonal blocks, and is the ratio of the number of 0s in the off-diagonal blocks for the number of 0s and 1s in the off-diagonal blocks. Another important performance measure is the well-known grouping efficacy which is defined as [22]:
where is the total number of 1s in the matrix , is the total number of exceptional elements and denotes the number of 0s in the gray diagonal blocks. Other alternative performance metrics proposed to evaluate MPCF structures include: the grouping index [25], the group capability index [23] or the doubly weighted grouping efficiency [26].
There are multiple ways to define the objective function of the MPCF problem. Despite this, one of the most common forms to express the function is the following:
where is a user-defined weighting parameter. The model is then reformulated as a 0–1 linear programming by introducing new additional binary variables to represent the product with their corresponding associated constraints [28].
Numerous algorithms, heuristic and nonheuristic approaches, have been proposed for addressing the MPCF problem [6,29,30]. Under the family of array-based clustering methods, some authors have presented different algorithms to approach the MPCF problem [5,31]. For example, Chandrasekharan and Rajagopalan proposed the modified rank order clustering method [32] or King implemented the rank order clustering model [5]. In the field of mathematical programming, there also important approaches to deal with the MPCF problem [7,11]. For instance, Adil et al. presented linear and nonlinear integer programming models that minimize the weighted sum of exceptional elements and voids [33] or Gunasingh and Lashkari [34] and Logendran [35] proposed the use of binary integer programming to maximize the weighted sum of total moves and in-cell uses. The main drawback of the mathematical programming models is their high computational burden, which grows significantly with the dimension of the problem. In this context, several authors have proposed the use of heuristics to solve the MPCF problem. Specifically, some methods already employed in the literature include: simulated annealing [36], genetic algorithms [9,10,37] or tabu search [38,39] among others.
Most of these proposals have been criticized due to their narrow scope (for example, it is often neglected the order in which operations are performed) [40]. Motivated by this fact, an extension of the well-known MPCF problem for non-binary incidence matrices is proposed here and presented in continuation. In the proposed model, the incidence matrix is called requirement matrix, and it is composed of natural numbers instead of binary ones. Hence, an objective function and a set of constraints (designed according to the characteristics of the requirement matrix) are proposed ad-hoc for the model.
A real-world problem belonging to human resources management has been implemented in the manuscript to show the applicability of the optimization model. The goal of the case study is to identify a group of employees and areas of enhancement (in terms of job quality) associated with each group. The idea is to group simultaneously employees and job quality dimensions to allow human resources practitioners to implement tailored human resources incentives for their staff members. Thus, machines are represented by employees (accountants in the case of study), and the parts are the levels of dissatisfaction (expressed by natural numbers) those employees have in different dimensions measuring job quality (such as prospect, earnings, work-life balance, or social support).
3. The Proposed Model
The goal of the proposed model is to group simultaneously N participants and D characteristics in G disjoint clusters. The optimization process is defined using as base information the one provided by a requirement matrix in which each component stands for the level of dissatisfaction that the n-th employee, , has on the d-th dimension characterizing job quality, . In the case of study, we consider the different levels of dissatisfaction in the set of job quality indices because the final goal is to identify areas of enhancement in a specific group of employees (to implement a tailored human resources strategy of incentives). As previously mentioned, the matrix is not a binary matrix, but a matrix of natural numbers, each encoding a level of dissatisfaction of a particular employee about a given job quality dimension. Thus, the two matrices that are the output of the optimization process are the matrix (for grouping the employees) and the matrix (for clustering the job quality dimensions). if participant n is assigned to group g and otherwise. if job quality dimension d is assigned to group g and 0 otherwise.
For the sake of clarity, it is presented in continuation a synthetic example with 12 employees and seven job quality indices. Thus, Table 2 (a) shows an example of an initial requirement matrix in a problem with 12 employees and seven job quality indices. Table 2 (b) depicts the final matrix obtained after the rearrangement process, in which three groups are identified. As can be seen, the output of the optimization process is a rearranged matrix with three different groups, highlighted with gray color (3 employee groups and three groups of job quality indices ). Consequently, the two matrices, and associated with the requirement matrix of the previous example will be equal to:
Table 2.
Example of matrix rearrangement in the MPCF problem with non-binary input values.
3.1. Base Formulation
The performance measures defined in the previous section for the MPCF problem are not suitable when implemented in non-binary matrices. For example, the model should generate well-balanced clusters in terms of performance, or it should also consider the ordinal nature of the values included in the new requirement matrix . For this reason, it is a must to propose a completely different objective function for the problem under study. Specifically, the proposed objective function, , is defined as the sum of the corresponding mean levels of dissatisfaction that the employees of a group have about the job quality dimensions assigned to that group. Thus, the proposed objective function fosters well-balanced clusters in terms of mean levels of job dissatisfaction (unlike the traditional formulation of the MPCF problem, which does not consider this issue):
The optimization problem has to also incorporate the constraints needed to ensure that each employee and each job quality dimension is assigned to exactly one group, respectively: (i) and (ii) , and those required to ensure that each group includes at least one employee and one job quality dimension: (i) and (ii) .
An additional constraint is included in the base model to control the numbers in the off-diagonal blocks. The constraint imposes a maximum value for the sum of those elements, and it is defined as follows:
where is the maximum allowed value for the sum of elements out of the diagonal blocks and, obviously, depends on the dimensions of the requirement matrix (N and D) and the range of values associated with the values of this matrix, represents to the sum of elements in the matrix and is the sum of elements out of the diagonal blocks. The constraint is expressed in the optimization model as:
where . Hence, the proposed optimization model is composed of decision variables and constraints. The model is expressed as a multiple-ratio optimization with quadratic terms in both the objective function and constraints, and it is defined as:
3.2. Model Conversion
The model presented in the previous section is a multiple-ratio quadratic 0–1 fractional programming model as the highest order of the product of binary variables in the objective function is two, and the objective function is expressed as the sum of G ratios [41,42,43,44]. A quadratic 0–1 programming model can be converted into a linear 0–1 programming one by introducing a new set of 0–1 variables (one for each quadratic term included in the base model) and additional constraints [28]. This idea is borrowed in this manuscript to represent the multiplication of 0–1 variables using additional binary variables, , as [45]:
with . Additionally, each new binary variable, , requires the introduction of two new inequality constraints to ensure that the new binary variable, representing the product of the two original variables, is equal to one when both are equal to one and zero otherwise. Thus, we have incorporated, for each new binary variable, the two following constraints:
where as . As a result, the model will increase considerably in the number of variables and constraints. Despite this increase, the advantage of performing this conversion is that the reformulated model (after performing the linearization described in the next section) can be solved by well-known optimization techniques such as the branch-and-bound (B&B) [46].
3.3. Linearizing the Objective Function
After the modifications implemented in the previous section, the optimization model can be categorized within the field of fractional (hyperbolic) 0–1 programming problems with linear constraints [43,47,48]. As stated in [48], these types of problems are NP-hard, and consequently, they have been traditionally solved through heuristics [49], or by global optimization approaches [50,51].
Another approach to globally solve the problem under study involves its transformation into a mixed-integer linear program (MILP), which can be solved using standard B&B-based MILP solvers. In the optimization problem proposed, we start defining:
for all , , where:
taking into account that and , , for all and satisfying, consequently, the constraint of having in each denominator values different from zero (to avoid undetermined expressions) [52,53]. Using these newly defined variables, the objective function can be equivalently posed as:
including as constraints that , for all .
The above problem includes the multiplication of continuous and binary variables but can be linearized using the approach defined in [54] as follows. For any , and , define a variable as , and introduce the four following inequality constraints to ensure that each additional variable, , represents the product of a binary variable with a continuous one:
where and are the lower and upper bounds of , for each . In this manuscript, these bounds can be readily obtained as for all , .
Therefore, problem (5) in is equivalent to:
This problem can be solved using MILP software such as CPLEX [55,56].
4. Numerical Examples
In this section, the competitive performance of the proposed model is shown through its application to two types of experiments. In the first group of experiments, the model is tested with a set of randomized requirement matrices, and its performance (concerning the objective function) is compared to the one obtained with a standard greedy algorithm (Section 4.1). In the second type of experiment, the optimization model is evaluated with a real-world problem belonging to the area of HRM (Section 4.2). The findings obtained in this part are compared with those reported in the specialized literature.
4.1. Experiments in Randomized Requirement Matrices
In this section, the MILP solution of the problem is compared to the one obtained through a standard greedy algorithm in which solutions are obtained in two sequential steps. In the first step, an initial solution is reached, whereas, in the second step of the algorithm, this initial solution is modified to obtain a feasible one [57]. The greedy heuristic algorithm obtains a local solution, unlike the proposed model that reaches an exact solution. The main advantage of the greedy algorithm concerning the proposed method lies in its reduced computational burden (if compared to the MILP solution). It is important to stress that the comparison method (the greedy algorithm) implements the optimization function defined in Section 3.1 whereas the proposed model the reformulated version of the problem, Section 3.3 (suitable to obtain an exact solution through the MILP solver).
The two implemented models were tested with randomly generated requirement matrices (with different number of employees and job quality indices). Specifically, eight requirement matrices were generated with the following dimensions (employees × job quality indices): , , , , , , , and . All matrices include in their elements natural values ranging from 0 to 5. For the sake of simplicity, the number of groups was set to 5 for all the experiments, . and were estimated for all , taking into account the dimension of the problem () and that the lower and upper bounds for each component in the requirement matrix are 0 and 5, respectively. The parameter was computed for each problem similarly. The fitness function to evaluate the quality of the solution was defined as:
Table 3 shows the empirical results obtained by the two methods implemented in the random requirement matrices employed in this experiment. The first three columns report the results of the two models in matrices with five columns, and the last three columns the results with matrices of dimension (columns) equal to ten. As shown in Table 3, the proposed method consistently obtains better fitness values than the greedy algorithm. Regarding the computational time, it is worth mentioning that the proposed method, in general, is 100 times more computationally expensive than the greedy algorithm (although this difference depends critically on the dimension of the requirement matrix). In any case, this is not a critical issue in the case of the study presented, as the model should be optimized just once (it is not required an online tuning of the parameters). An alternative solution in efficacy and efficiency could be a heuristic algorithm [8], although, as stated earlier, in our humble opinion, efficiency is not a significant issue in these types of problems.
Table 3.
Empirical results of the two methods implemented (the proposed model and the standard greedy algorithm).
4.2. A Real-World Application in the Field of Human Resources Management
The European Foundation conducts the VI European Working Conditions Survey (EWCS), aiming to understand and consequently improve European employees’ conditions of life and work [14]. In the 2015 edition, accounting professionals amounted to 739 subjects. After a data cleansing process, 241 valid subjects have remained [16]. The measurement of well-being can be approached through a multidimensional construct (Job Quality Index, JQI) composed of seven dimensions [14]:
- Physical environment (JQI 1) measures the physical risks employees encounter in their jobs.
- Work intensity (JQI 2) measures the level of job demands for employees.
- Work time quality (JQI 3) is a multidimensional metric composed of four elements: duration, scheduling, discretion, and short-term flexibility over working time.
- Social environment (JQI 4) measures the extent to which employees experience supportive relationships with both their peers and superiors.
- Skills and discretion (JQI 5) measure the possibility of professional development through work and the ability to set goals and organize work.
- Prospects (JQI 6) combines indicators of employment status, type of contract, and perceived career prospects by the employee.
- Earnings (JQI 7) measures monthly employee compensation.
In this experiment, the proposed optimization model was tested with the data provided by the European Foundation for the Improvement of the Conditions of Life and Work in its sixth EWCS regarding the job demands (concerning the values of job quality in the seven previously described indices) of the 241 accountants available in the sample. Hence, the requirement matrix is composed of 241 rows (), and 7 columns (). The participants of each group were characterized according to a set of demographics (participants with or without couple, participants with less or more than 40 years, and their gender), and to their mean level of WHO (World Health Organization) well-being. The WHO index is a validated scale consisting of 5 items that measure well-being by averaging the scores of the items in a single construct [58].
It is essential to clarify that the model received input only the requirement matrix composed of 241 accountants and five job quality indices. The demographics variables along with the WHO variables are not included in the optimization procedure. They are used only to characterize (regarding the demographics) the accountants included in each group (once the optimization procedure is finished). This characterization of the groups is helpful to compare the empirical findings with those reported in the existing literature.
Table 4 shows the results of the clustering procedure and the characterization of the employees of the five groups identified. Figure 1 graphically details the organization of the clusters in the different demographics variables (excluded of the optimization procedure). The plot combines a box-plot (to illustrate the results in numerical variables) and histogram (for qualitative/categorical variables) using two y-axes. The left y-axis is used to define the scale of the quantitative WHO variable (normalized in the [0, 1] range), whereas the right y-axis specifies the scale of the qualitative variables (in the original range of values).
Table 4.
Statistical characteristics of the five groups : JQI-associations, mean and standard deviation for the WHO index per cluster (), number of participants without and with a couple (N and Y), number of accountants younger and older than 40 years (<40 and >40) and number of females and males (F and M).
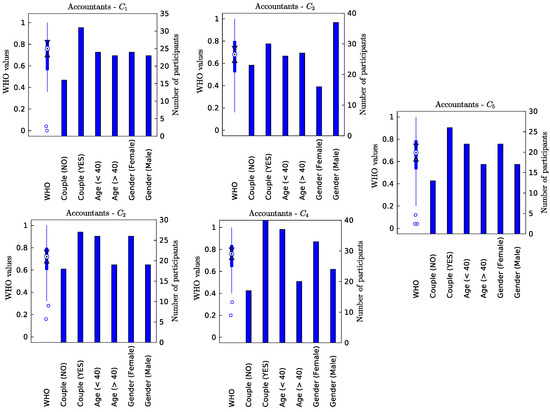
Figure 1.
Graphical representation of the main characteristics of the five clusters obtained.
The group with the worst level of well-being, , claims an improvement in the Social environment dimension (JQI-4). The accounting profession reacts to high levels of pressure by developing teamwork and strengthening the support of superiors and peers, as suggested by the Job Demands Control Support theory [59]. In the accounting profession, evidence shows the positive effect of the work climate on job satisfaction [60,61] and professionals’ commitment [62]. This category is formed by a group of professionals younger than in other groups for which the emotional dimension of the work may be relevant in their perception of well-being [16].
On the other hand, the group with a higher perception of well-being, , considers that the dimension that must improve is the work intensity index (JQI-2). This category is made up mainly of women who live with a couple and relatively young. Professionals find reasons for satisfaction in other dimensions of the quality of employment and thus neutralize this demand that is consubstantial to the seasonality experienced by the accounting profession. Tight deadlines and work overload have been widely described as job stressors of this profession [17,63] and sometimes used as a means to maintain a high level of productivity [64], as prescribed by the arousal theory [65,66,67].
In intermediate-high levels of well-being are groups 1 and 2, and . Group 1 is made up of professionals who demand an improvement in remuneration (JQI-7) although they maintain a high level of satisfaction, so there are other incentives, in addition to financial compensation. In addition, group 2 demands an improvement in skills application and job autonomy (JQI-5). The group of accountants is segmented into organizations with different business models and, consequently, human resources management. At the same time, a high level of professional development and a great diversity of clients in which to develop the work [15] characterize accountancy firms, employment in corporations is more standardized and offers fewer possibilities for professional growth.
Finally, at a low intermediate level of well-being is a group, , that calls for the improvement of three dimensions: the physical conditions of the workplace (JQI-1), the quality of working time (JQI-3), and the professional career (JQI-6). As claimed in previous research [15], the accounting profession offers an opportunity for promotion and has demanding conditions in work performed (there are tight deadlines that affect job flexibility and, sometimes, require trips to the client’s offices). Hence, well-being levels decrease when the promotion is unclear and the negative impact on work time quality is accentuated [68].
These results show that accounting professionals assume work intensity as a characteristic of work, as a constraint that is difficult to manage, and it affects to a lesser extent their perception of well-being. On the contrary, job resources are the levers that can be managed, such as teamwork, which is critical to cope with pressure, and the professional career, both being the JQI most demanded when the professional has a low perception of well-being. These findings are in line with those reported in the literature [15,16].
The following is the managerial implication of this study [69,70]:
- This study’s findings allow human resources practitioners to implement tailored human resources strategies that consider the different particularities of the groups under study. For example, in this research, we have shown that workplace well-being is strongly correlated with workplace social climate. Furthermore, we have also shown that accountants assume work intensity as an intrinsic characteristic of the profession. Human resources practitioners could employ those findings to improve the accountants’ satisfaction and optimize future incentives strategies within the profession.
- The proposed model can be easily adapted to other sectors (such as professors or nurses) to understand how employees are organized according to their job demands.
- The model can also be adapted to problems related to human resources, such as the team formation problem (in which employees are grouped according to their skills to perform a particular task).
5. Conclusions
In this manuscript, we have proposed a mixed-integer linear programming (MILP) formulation for an alternative to the machine-part cell formation (MPCF) problem in which the elements composing the input matrix are natural numbers instead of binary values. The optimization model presented has multiple applications in areas such as machine learning (biclustering, feature and instance selection), group technology, or social sciences (in education for grouping students according to their competencies), among others.
The proposed model was first compared to a greedy algorithm in a set of randomized matrices. These experiments showed that the proposed model achieves consistently higher fitness values than the greedy algorithm. The model was also tested in a real-world problem of Human Resources Management (HRM) to stress its high applicability. The results obtained were in line with previous findings described in the literature about the case study.
The main limitation of the model is its high computational burden (if compared to heuristic approaches). Thus, future research should be devoted to developing new models of parameter estimation (heuristics or alternatives formulations of the problem) for the problem explored in this manuscript. In any case, it is important to clarify that this is not a critical issue in the case of the study presented, as the model should be optimized just once (it is not required an online tuning of the parameters).
Author Contributions
Conceptualization, F.F.-N. and J.J.d.P.-A.; Methodology, F.F.-N. and M.C.-R.; Software, F.F.-N.; Validation, H.M.-S.; Formal analysis, F.F.-N. and M.C.-R.; Data curation, A.A.-M.; Writing—original draft preparation, F.F.-N.; Writing—review and editing, M.C.-R., A.A.-M., J.J.d.P.-A. and H.M.-S. All authors have read and agreed to the published version of the manuscript.
Funding
The research work of F.F.-N. is funded by the Spanish Ministry of Science under Project ENE2017-88889-C2-1-R.
Conflicts of Interest
The authors declare no conflict of interest.
Abbreviations
The following abbreviations are used in this manuscript:
| B&B | branch-and-bound |
| CM | Cell manufacturing |
| GT | Group technology |
| HRM | Human resource management |
| MPCF | Machine-part cell formation |
| MILP | Mixed-integer linear programming |
References
- Dekkers, R. Group technology: Amalgamation with design of organisational structures. Int. J. Prod. Econ. 2018, 200, 262–277. [Google Scholar] [CrossRef] [Green Version]
- Liu, C.; Wang, J.; Leung, J.Y.T. Integrated bacteria foraging algorithm for cellular manufacturing in supply chain considering facility transfer and production planning. Appl. Soft Comput. 2018, 62, 602–618. [Google Scholar] [CrossRef]
- Rostami, A.; Paydar, M.M.; Asadi-Gangraj, E. A hybrid genetic algorithm for integrating virtual cellular manufacturing with supply chain management considering new product development. Comput. Ind. Eng. 2020, 145, 106565. [Google Scholar] [CrossRef]
- Salimpour, S.; Pourvaziri, H.; Azab, A. Semi-robust layout design for cellular manufacturing in a dynamic environment. Comput. Oper. Res. 2021, 133, 105367. [Google Scholar] [CrossRef]
- King, J.R. Machine-component grouping in production flow analysis: An approach using a rank order clustering algorithm. Int. J. Prod. Res. 1980, 18, 213–232. [Google Scholar] [CrossRef]
- Chattopadhyay, M.; Dan, P.K.; Mazumdar, S. Application of visual clustering properties of self organizing map in machine–part cell formation. Appl. Soft Comput. 2012, 12, 600–610. [Google Scholar] [CrossRef] [Green Version]
- Srinlvasan, G.; Narendran, T.; Mahadevan, B. An assignment model for the part-families problem in group technology. Int. J. Prod. Res. 1990, 28, 145–152. [Google Scholar] [CrossRef]
- Agustín-Blas, L.E.; Salcedo-Sanz, S.; Ortiz-García, E.G.; Portilla-Figueras, A.; Pérez-Bellido, Á.M.; Jiménez-Fernández, S. Team formation based on group technology: A hybrid grouping genetic algorithm approach. Comput. Oper. Res. 2011, 38, 484–495. [Google Scholar] [CrossRef]
- Branco, R.M.; Rocha, C.R. Group Technology: Hybrid Genetic Algorithm with Greedy Formation and a Local Search Cluster Technique in the Solution of Manufacturing Cell Formation Problems. In International Joint conference on Industrial Engineering and Operations Management; Springer: Novi Sad, Serbia, 2019; pp. 60–68. [Google Scholar]
- Goli, A.; Tirkolaee, E.B.; Aydin, N.S. Fuzzy integrated cell formation and production scheduling considering automated guided vehicles and human factors. IEEE Trans. Fuzzy Syst. 2021. [Google Scholar] [CrossRef]
- Kusiak, A. The generalized group technology concept. Int. J. Prod. Res. 1987, 25, 561–569. [Google Scholar] [CrossRef]
- Askin, R.G.; Chiu, K.S. A graph partitioning procedure for machine assignment and cell formation in group technology. Int. J. Prod. Res. 1990, 28, 1555–1572. [Google Scholar] [CrossRef]
- Min, H.; Shin, D. Simultaneous formation of machine and human cells in group technology: A multiple objective approach. Int. J. Prod. Res. 1993, 31, 2307–2318. [Google Scholar] [CrossRef]
- Parent-Thirion, A.; Biletta, I.; Cabrita, J.; Vargas, O.; Vermeylen, G.; Wilczynska, A.; Wilkens, M. Sixth European Working Conditions Survey: Overview Report; Eurofound (European Foundation for the Improvement of Living and Working Conditions): Dublin, Ireland, 2016. [Google Scholar]
- Umar, M.; Sitorus, S.M.; Surya, R.L.; Shauki, E.R.; Diyanti, V. Pressure, dysfunctional behavior, fraud detection and role of information technology in the audit process. Australas. Account. Bus. Financ. J. 2017, 11, 102–115. [Google Scholar] [CrossRef]
- del Pozo-Antúnez, J.J.; Molina-Sánchez, H.; Ariza-Montes, A.; Fernández-Navarro, F. Promoting work Engagement in the Accounting Profession: A Machine Learning Approach. Soc. Indic. Res. 2021, 1–18. [Google Scholar] [CrossRef]
- Pierce, B.; Sweeney, B. Cost–quality conflict in audit firms: An empirical investigation. Eur. Account. Rev. 2004, 13, 415–441. [Google Scholar] [CrossRef]
- McNamara, S.M.; Liyanarachchi, G.A. Time budget pressure and auditor dysfunctional behaviour within an occupational stress model. Account. Bus. Public Interest 2008, 7, 1–43. [Google Scholar]
- Berhil, S.; Benlahmar, H.; Labani, N. A review paper on artificial intelligence at the service of human resources management. Indones. J. Electr. Eng. Comput. Sci. 2020, 18, 32–40. [Google Scholar] [CrossRef]
- Owsinski, J.W. Machine-Part Grouping and Cluster Analysis. IFAC Proc. Vol. 2008, 41, 296–301. [Google Scholar] [CrossRef]
- Chandrasekharan, M.; Rajagopalan, R. GROUPABIL1TY: An analysis of the properties of binary data matrices for group technology. Int. J. Prod. Res. 1989, 27, 1035–1052. [Google Scholar] [CrossRef]
- Suresh Kumar, C.; Chandrasekharan, M. Grouping efficacy: A quantitative criterion for goodness of block diagonal forms of binary matrices in group technology. Int. J. Prod. Res. 1990, 28, 233–243. [Google Scholar] [CrossRef]
- Sarker, B. Grouping efficiency measures in cellular manufacturing: A survey and critical review. Int. J. Prod. Res. 1999, 37, 285–314. [Google Scholar] [CrossRef]
- Sarker, B.R.; Khan, M. A comparison of existing grouping efficiency measures and a new weighted grouping efficiency measure. IIE Trans. 2001, 33, 11–27. [Google Scholar] [CrossRef]
- Seifoddini, H.; Djassemi, M. The threshold value of a quality index for formation of cellular manufacturing systems. Int. J. Prod. Res. 1996, 34, 3401–3416. [Google Scholar] [CrossRef]
- Sarker, B.R. Measures of grouping efficiency in cellular manufacturing systems. Eur. J. Oper. Res. 2001, 130, 588–611. [Google Scholar] [CrossRef]
- Boctor, F.F. A Jinear formulation of the machine-part cell formation problem. Int. J. Prod. Res. 1991, 29, 343–356. [Google Scholar] [CrossRef]
- Forrester, R.J.; Greenberg, H.J. Quadratic binary programming models in computational biology. Algorithmic Oper. Res. 2008, 3. [Google Scholar]
- Li, X.; Baki, M.F.; Aneja, Y.P. An ant colony optimization metaheuristic for machine–part cell formation problems. Comput. Oper. Res. 2010, 37, 2071–2081. [Google Scholar] [CrossRef]
- Su, C.T.; Hsu, C.M. Multi-objective machine-part cell formation through parallel simulated annealing. Int. J. Prod. Res. 1998, 36, 2185–2207. [Google Scholar] [CrossRef]
- McCormick, W.T., Jr.; Schweitzer, P.J.; White, T.W. Problem decomposition and data reorganization by a clustering technique. Oper. Res. 1972, 20, 993–1009. [Google Scholar] [CrossRef]
- Chandrasekharan, M.; Rajagopalan, R. MODROC: An extension of rank order clustering for group technology. Int. J. Prod. Res. 1986, 24, 1221–1233. [Google Scholar] [CrossRef]
- Adil, G.; Rajamani, D.; Strong, D. Cell formation considering alternate routeings. Int. J. Prod. Res. 1996, 34, 1361–1380. [Google Scholar] [CrossRef]
- Gunasingh, K.R.; Lashkari, R. Simultaneous grouping of parts and machines in cellular manufacturing systems—An integer programming approach. Comput. Ind. Eng. 1991, 20, 111–117. [Google Scholar] [CrossRef]
- Logendran, R. A biary integer programming approach for simultaneous machine-part grouping in cellular manufacturing systems. Comput. Ind. Eng. 1993, 24, 329–336. [Google Scholar] [CrossRef]
- Sofianopoulou, S. Application of simulated annealing to a linear model forthe formulation of machine cells ingroup technology. Int. J. Prod. Res. 1997, 35, 501–511. [Google Scholar] [CrossRef]
- Feng, Y.; Li, G.; Sethi, S.P. A three-layer chromosome genetic algorithm for multi-cell scheduling with flexible routes and machine sharing. Int. J. Prod. Econ. 2018, 196, 269–283. [Google Scholar] [CrossRef]
- Lozano, S.; Adenso-Diaz, B.; Eguia, I.; Onieva, L. A one-step tabu search algorithm for manufacturing cell design. J. Oper. Res. Soc. 1999, 50, 509–516. [Google Scholar] [CrossRef]
- Wu, T.H.; Low, C.; Wu, W.T. A tabu search approach to the cell formation problem. Int. J. Adv. Manuf. Technol. 2004, 23, 916–924. [Google Scholar] [CrossRef]
- Raminfar, R.; Zulkifli, N.; Vasili, M. A mathematical programming model for cell formation problem with machine replication. J. Appl. Math. 2013, 2013. [Google Scholar] [CrossRef]
- Kapoor, R.; Arora, S. Linearization of a 0–1 quadratic fractional programming problem. Opsearch 2006, 43, 190–207. [Google Scholar] [CrossRef]
- Kapoor, R.; Arora, S. Complexity of a particular class of single and multiple ratio quadratic 0–1 fractional programming problems. Oper. Res. 2007, 7, 285–298. [Google Scholar] [CrossRef]
- Borrero, J.S.; Gillen, C.; Prokopyev, O.A. Fractional 0–1 programming: Applications and algorithms. J. Glob. Optim. 2017, 69, 255–282. [Google Scholar] [CrossRef]
- Mehmanchi, E.; Gómez, A.; Prokopyev, O.A. Fractional 0–1 programs: Links between mixed-integer linear and conic quadratic formulations. J. Glob. Optim. 2019, 75, 273–339. [Google Scholar] [CrossRef]
- Mahdavi, I.; Javadi, B.; Fallah-Alipour, K.; Slomp, J. Designing a new mathematical model for cellular manufacturing system based on cell utilization. Appl. Math. Comput. 2007, 190, 662–670. [Google Scholar] [CrossRef]
- Taha, H.A. Integer Programming: Theory, Applications, and Computations; Academic Press: Cambridge, MA, USA, 2014. [Google Scholar]
- Prokopyev, O.A.; Meneses, C.; Oliveira, C.A.; Pardalos, P.M. On multiple-ratio hyperbolic 0–1 programming problems. Pac. J. Optim. 2005, 1, 327–345. [Google Scholar]
- Borrero, J.S.; Gillen, C.; Prokopyev, O.A. A simple technique to improve linearized reformulations of fractional (hyperbolic) 0–1 programming problems. Oper. Res. Lett. 2016, 44, 479–486. [Google Scholar] [CrossRef]
- Hansen, P.; de Aragão, M.V.P.; Ribeiro, C.C. Boolean query optimization and the 0–1 hyperbolic sum problem. Ann. Math. Artif. Intell. 1990, 1, 97–109. [Google Scholar] [CrossRef]
- Grunspan, M.; Thomas, M.E. Hyperbolic integer programming. Nav. Res. Logist. Q. 1973, 20, 341–356. [Google Scholar] [CrossRef]
- Tawarmalani, M.; Ahmed, S.; Sahinidis, N.V. Global optimization of 0–1 hyperbolic programs. J. Glob. Optim. 2002, 24, 385–416. [Google Scholar] [CrossRef]
- Li, H.L. A global approach for general 0–1 fractional programming. Eur. J. Oper. Res. 1994, 73, 590–596. [Google Scholar] [CrossRef]
- Wu, T.H. A note on a global approach for general 0–1 fractional programming. Eur. J. Oper. Res. 1997, 101, 220–223. [Google Scholar] [CrossRef]
- Adams, W.P.; Forrester, R.J. A simple recipe for concise mixed 0–1 linearizations. Oper. Res. Lett. 2005, 33, 55–61. [Google Scholar] [CrossRef]
- Bliek1ú, C.; Bonami, P.; Lodi, A. Solving mixed-integer quadratic programming problems with IBM-CPLEX: A progress report. In Proceedings of the Twenty-Sixth RAMP Symposium, Tokyo, Japan, 16–17 October 2014; pp. 16–17. [Google Scholar]
- Fernández-Navarro, F.; Martínez-Nieto, L.; Carbonero-Ruz, M.; Montero-Romero, T. Mean Squared Variance Portfolio: A Mixed-Integer Linear Programming Formulation. Mathematics 2021, 9, 223. [Google Scholar] [CrossRef]
- Cerrone, C.; Cerulli, R.; Golden, B. Carousel greedy: A generalized greedy algorithm with applications in optimization. Comput. Oper. Res. 2017, 85, 97–112. [Google Scholar] [CrossRef]
- Topp, C.W.; Østergaard, S.D.; Søndergaard, S.; Bech, P. The WHO-5 Well-Being Index: A systematic review of the literature. Psychother. Psychosom. 2015, 84, 167–176. [Google Scholar] [CrossRef]
- Karasek, R.A., Jr. Job demands, job decision latitude, and mental strain: Implications for job redesign. Adm. Sci. Q. 1979, 24, 285–308. [Google Scholar] [CrossRef]
- Herda, D.N.; Lavelle, J.J. The auditor-audit firm relationship and its effect on burnout and turnover intention. Account. Horizons 2012, 26, 707–723. [Google Scholar] [CrossRef]
- Cannon, N.H.; Herda, D.N. Auditors’ organizational commitment, burnout, and turnover intention: A replication. Behav. Res. Account. 2016, 28, 69–74. [Google Scholar] [CrossRef]
- Umans, T.; Broberg, P.; Schmidt, M.; Nilsson, S.; Olsson, E. Feeling well by being together: Study of Swedish auditors. Work 2016, 54, 79–86. [Google Scholar] [CrossRef]
- Rebele, J.E.; Michaels, R.E. Independent auditors’ role stress: Antecedent, outcome, and moderating variables. Behav. Res. Account. 1990, 2, 124–153. [Google Scholar]
- Guénin-Paracini, H.; Malsch, B.; Paillé, A.M. Fear and risk in the audit process. Account. Organ. Soc. 2014, 39, 264–288. [Google Scholar] [CrossRef]
- Espinosa-Pike, M.; Barrainkua, I. An exploratory study of the pressures and ethical dilemmas in the audit conflict. Rev. Contab. 2016, 19, 10–20. [Google Scholar] [CrossRef] [Green Version]
- Svanström, T. Time pressure, training activities and dysfunctional auditor behaviour: Evidence from small audit firms. Int. J. Audit. 2016, 20, 42–51. [Google Scholar] [CrossRef]
- Espinosa-Pike, M.; Barrainkua, I. El efecto de los valores profesionales y la cultura organizativa en la respuesta de los auditores a las presiones de tiempo. Span. J. Financ. Account./Rev. Esp. Financ. Contab. 2017, 46, 507–534. [Google Scholar] [CrossRef]
- Sweeney, J.T.; Summers, S.L. The effect of the busy season workload on public accountants’ job burnout. Behav. Res. Account. 2002, 14, 223–245. [Google Scholar] [CrossRef]
- Gupta, S.; Haq, A.; Ali, I.; Sarkar, B. Significance of multi-objective optimization in logistics problem for multi-product supply chain network under the intuitionistic fuzzy environment. Complex Intell. Syst. 2021, 1–21. [Google Scholar] [CrossRef]
- Tayyab, M.; Sarkar, B. An interactive fuzzy programming approach for a sustainable supplier selection under textile supply chain management. Comput. Ind. Eng. 2021, 155, 107164. [Google Scholar] [CrossRef]

Publisher’s Note: MDPI stays neutral with regard to jurisdictional claims in published maps and institutional affiliations. |
© 2021 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).