
Performance of Enhanced Multiple-Searching Genetic Algorithm for Test Case Generation in Software Testing


Abstract
:1. Introduction
2. Related Work
3. Search-Based Test Case Generation
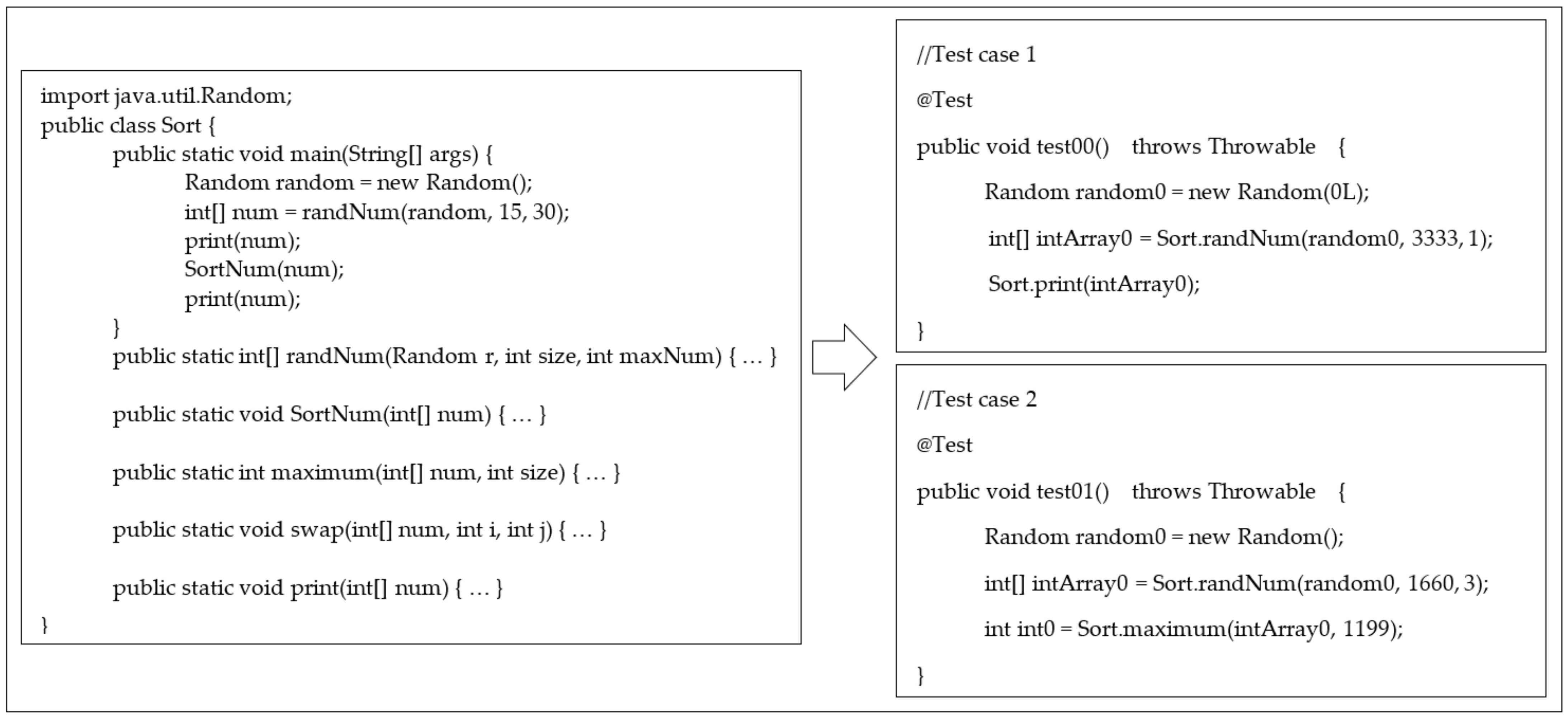
3.1. Representation
3.2. Fitness Function
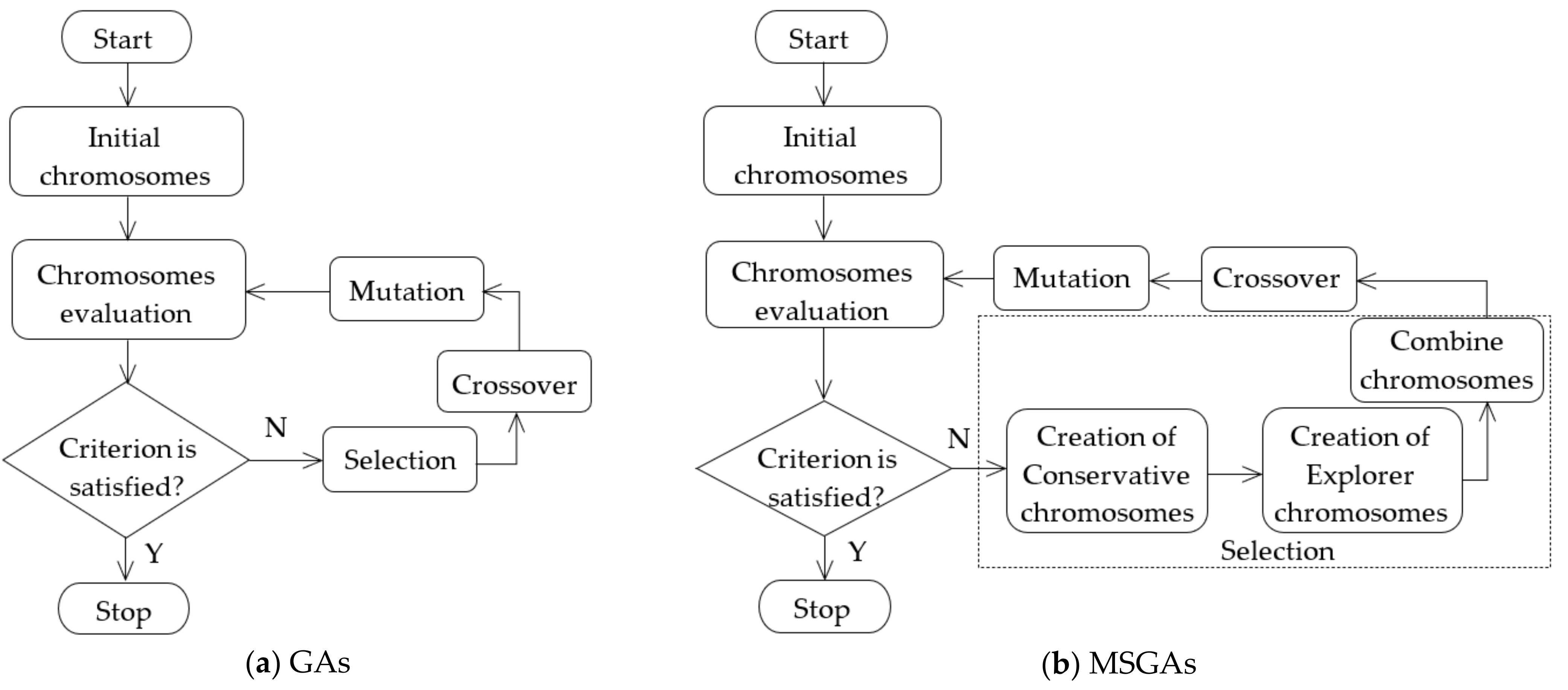
3.3. Genetic Algorithms
3.4. Chemical Reaction Optimization (CRO)
3.5. Random Search
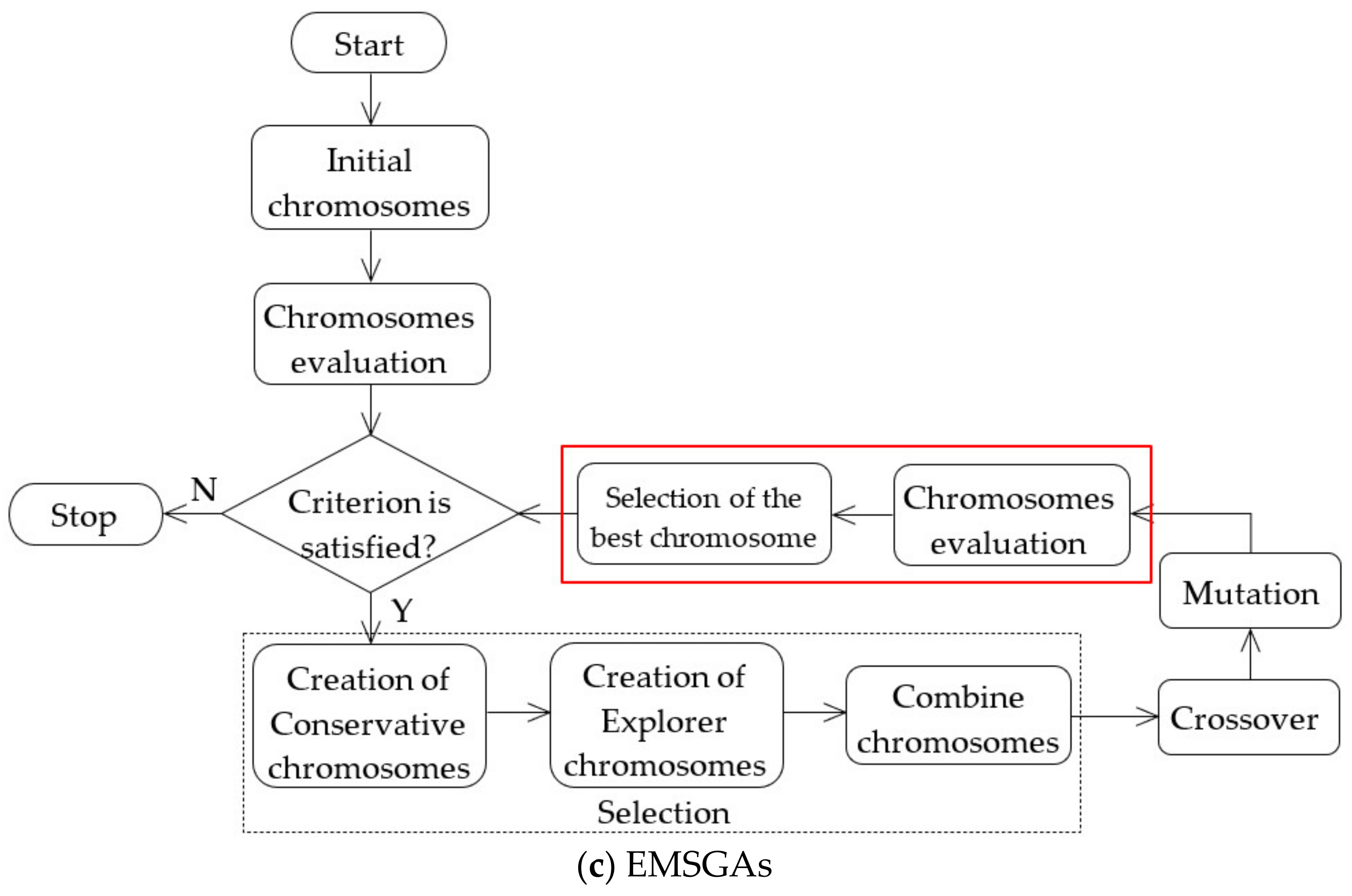
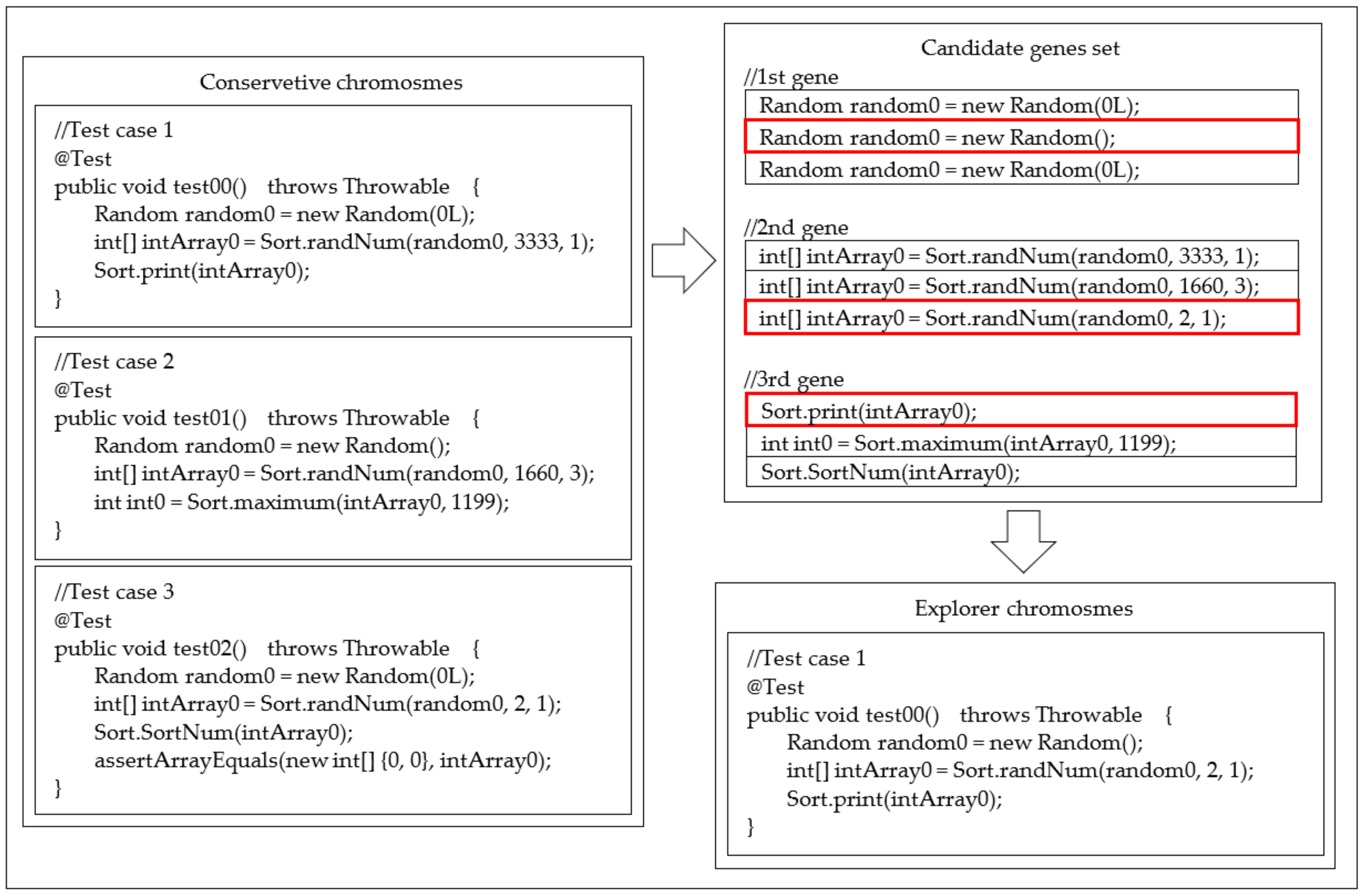
4. Proposed Algorithm: Enhanced Multiple-Searching Genetic Algorithm (EMSGA)
| Algorithm 1 Pseudocode for EMSGA |
|
5. Experimental Evaluation
5.1. Problem Instances
5.2. Test Generation Tool
5.3. Experimental Analysis
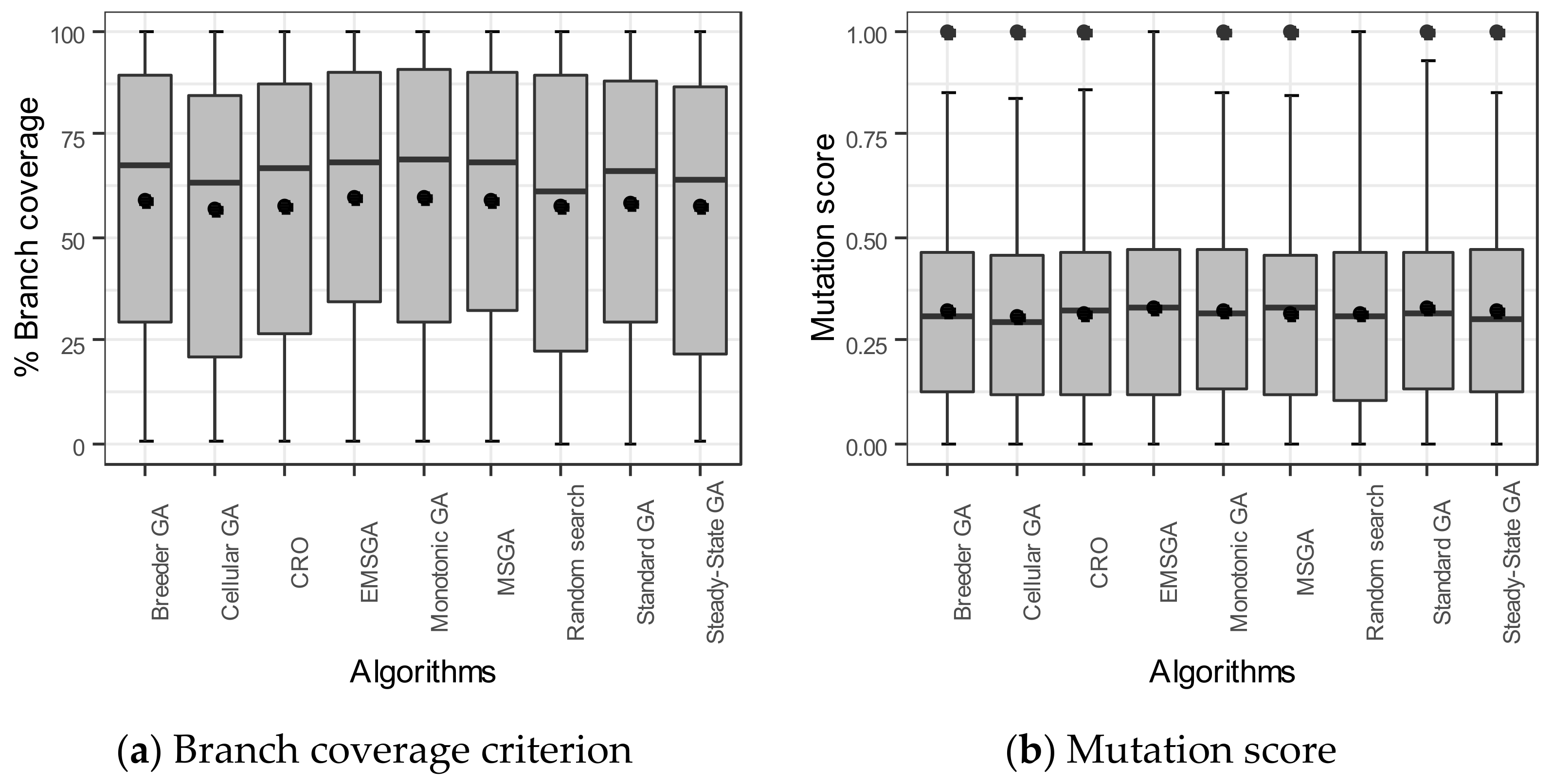
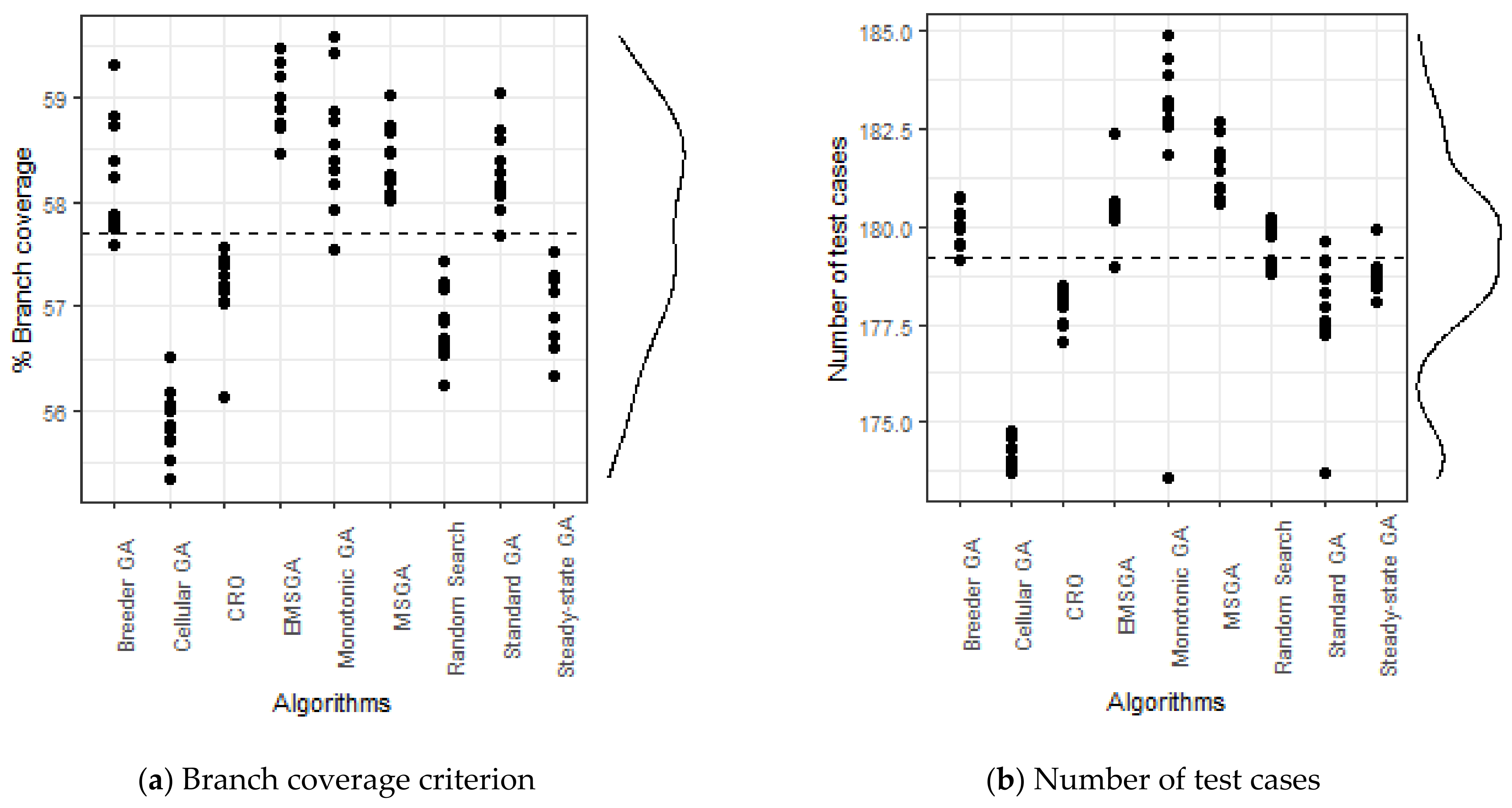
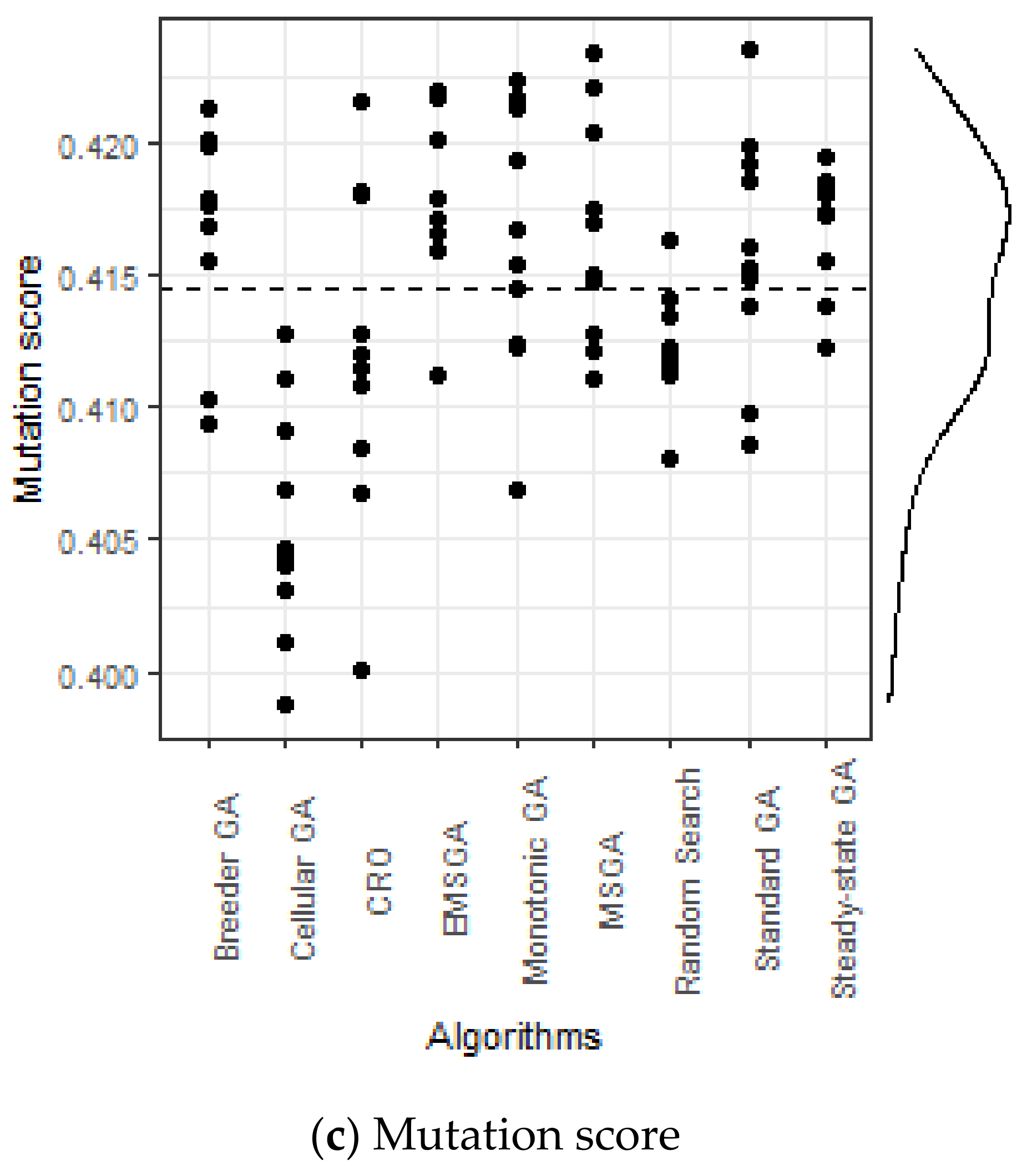
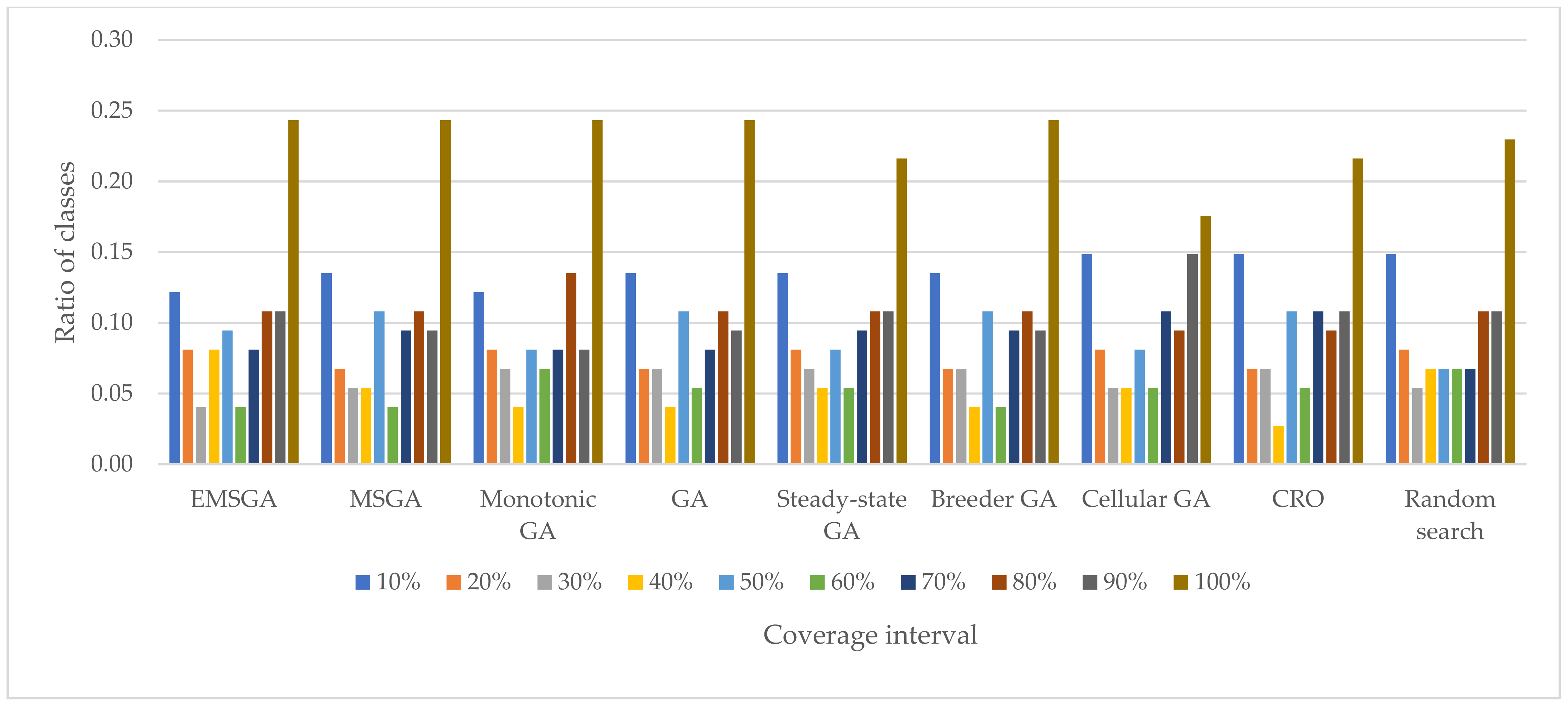
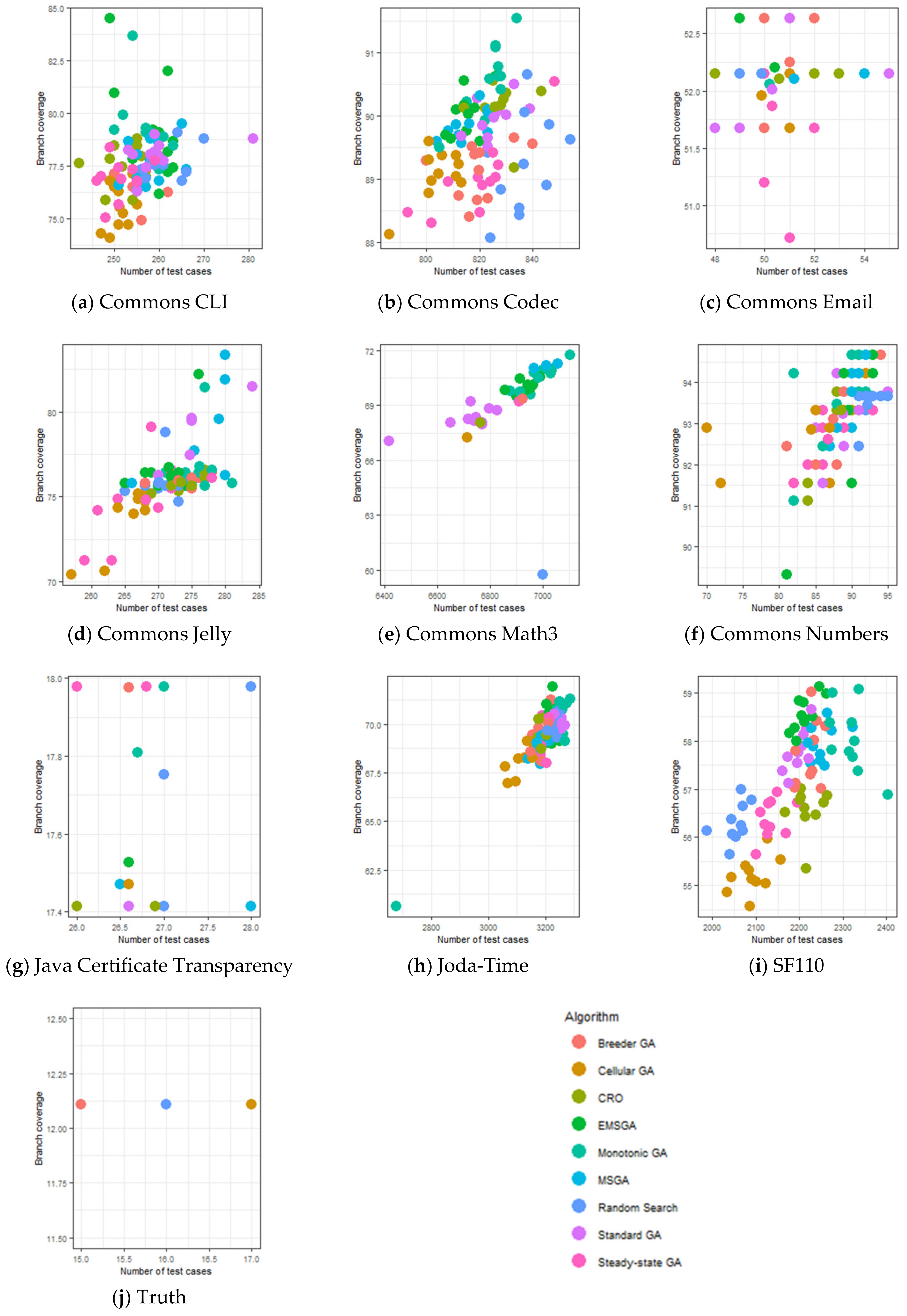
6. Experimental Results
7. Threats to Validity
8. Discussion
9. Conclusions
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Data Availability Statement
Acknowledgments
Conflicts of Interest
References
- Khan, R.; Amjad, M.; Srivastava, A.K. Optimization of Automatic Generated Test Cases for Path Testing Using Genetic Algorithm. In Proceedings of the 2nd International Conference on Computational Intelligence & Communication Technology, Ghaziabad, India, 12–13 February 2016; pp. 32–36. [Google Scholar] [CrossRef]
- Jatana, N.; Suri, B. Particle Swarm and Genetic Algorithm applied to mutation testing for test data generation: A comparative evaluation. J. King Saud Univ. Comput. Inf. Sci. 2020, 32, 514–521. [Google Scholar] [CrossRef]
- Aleti, A.; Grunske, L. Test data generation with a Kalman filter-based adaptive genetic algorithm. J. Syst. Softw. 2015, 103, 343–352. [Google Scholar] [CrossRef] [Green Version]
- Yang, S.; Man, T.; Xu, J.; Zeng, F.; Li, K. RGA: A lightweight and effective regeneration genetic algorithm for coverage-oriented software test data generation. Inf. Softw. Technol. 2016, 76, 19–30. [Google Scholar] [CrossRef] [Green Version]
- Kumar, D.; Mishra, M.M. The Impacts of Test Automation on Software’s Cost, Quality and Time to Market. Procedia Comput. Sci. 2016, 79, 8–15. [Google Scholar] [CrossRef] [Green Version]
- Tsai, C.F.; Tsai, C.W.; Wu, H.C. A novel algorithm for multimedia multicast routing in a large scale network. J. Syst. Softw. 2004, 72, 431–441. [Google Scholar] [CrossRef]
- Khamprapai, W.; Tsai, C.F.; Wang, P. Analyzing the Performance of the Multiple-Searching Genetic Algorithm to Generate Test Cases. Appl. Sci. 2020, 10, 7264. [Google Scholar] [CrossRef]
- Selim, M.; Siddik, M.S.; Gias, A.U.; Abdullah-Al-Wadud, M.; Khaled, S.M. A Ge-netic Algorithm for Software Design Migration fromStructured to Object Oriented Paradigm. In Proceedings of the 8th International Conference on Computer Engineering and Application (CEA 2014), Tenerife, Spain, 10–12 January 2014; pp. 187–192. [Google Scholar]
- Murillo-Morera, J.; Quesada-López, C.; Castro-Herrera, C.; Jenkins, M. A genetic algorithm based framework for software effort prediction. J. Softw. Eng. Res. Dev. 2017, 5, 4. [Google Scholar] [CrossRef] [Green Version]
- Bennett, T.E.; Brown, M.S.; Pelosi, M. A Genetic Algorithm for the Generation of Software Maintenance Release Plans without Human Bias. J. Softw. Eng. Practice 2015, 1, 6–21. [Google Scholar]
- Khari, M.; Kumar, P.; Shrivastava, G. Enhanced approach for test suite optimisation using genetic algorithm. Int. J. Comput. Aided Eng. Technol. 2019, 11, 653–668. [Google Scholar] [CrossRef]
- Mohi-Aldeen, S.M.; Mohamad, R.; Deris, S. Optimal path test data generation based on hybrid negative selection algorithm and genetic algorithm. PLoS ONE 2020, 15, e0242812. [Google Scholar] [CrossRef]
- Rathee, A.; Chhabra, J.K. A multi-objective search based approach to identify reusable software components. J. Comput. Lang. 2019, 52, 26–43. [Google Scholar] [CrossRef]
- Liu, Y.; An, K.; Tilevich, E. RT-Trust: Automated refactoring for different trusted execution environments under real-time constraints. J. Comput. Lang. 2020, 56, 100939. [Google Scholar] [CrossRef]
- Shahabi, M.M.D.; Badiei, S.P.; Beheshtian, S.E.; Akbari, R.; Moosavi, M.R. EVOTLBO: A TLBO based Method for Automatic Test Data Generation in EvoSuite. Int. J. Adv. Comput. Sci. Appl. 2017, 8, 214–226. [Google Scholar] [CrossRef] [Green Version]
- Fraser, G.; Arcuri, A.; McMinn, P. A Memetic Algorithm for whole test suite generation. J. Syst. Softw. 2015, 103, 311–327. [Google Scholar] [CrossRef] [Green Version]
- Panichella, A.; Kifetew, F.M.; Tonella, P. A large scale empirical comparison of state-of-the-art search-based test case generators. Inf. Softw. Technol. 2018, 104, 236–256. [Google Scholar] [CrossRef]
- Fraser, G.; Arcuri, A. A Large-Scale Evaluation of Automated Unit Test Generation Using EvoSuite. ACM Trans. Softw. Eng. Methodo 2014, 24, 1–42. [Google Scholar] [CrossRef]
- Wang, R.; Sato, Y.; Liu, S. Mutated Specification-Based Test Data Generation with a Genetic Algorithm. Mathematics 2021, 9, 331. [Google Scholar] [CrossRef]
- Rani, S.; Suri, B.; Goyal, R. On the Effectiveness of Using Elitist Genetic Algorithm in Mutation Testing. Symmetry 2019, 11, 1145. [Google Scholar] [CrossRef] [Green Version]
- Tian, T.; Gong, D.; Kuo, F.C.; Liu, H. Genetic algorithm based test data generation for MPI parallel programs with blocking communication. J. Syst. Softw. 2019, 155, 130–144. [Google Scholar] [CrossRef]
- Campos, J.; Ge, Y.; Albunian, N.; Fraser, G.; Eler, M.; Arcuri, A. An empirical evaluation of evolutionary algorithms for unit test suite generation. Inf. Softw. Technol. 2018, 104, 207–235. [Google Scholar] [CrossRef]
- Fraser, G.; Zeller, A. Mutation-Driven Generation of Unit Tests and Oracles. IEEE Trans. Softw. Eng. 2012, 38, 278–292. [Google Scholar] [CrossRef] [Green Version]
- Fraser, G.; Arcuri, A. Whole test suite generation. IEEE Softw. Eng. 2012, 39, 276–291. [Google Scholar] [CrossRef] [Green Version]
- Aleti, A.; Moser, I.; Grunske, L. Analysing the fitness landscape of search-based software testing problems. Autom. Softw. Eng. 2017, 24, 603–621. [Google Scholar] [CrossRef]
- Whitley, D. Next Generation Genetic Algorithms: A User’s Guide and Tutorial. In Handbook of Metaheuristics, 3rd ed.; Gendreau, M., Potvin, J.Y., Eds.; Springer: Cham, Switzerland, 2019; Volume 272, pp. 245–274. [Google Scholar] [CrossRef]
- Sundar, S. A Steady-State Genetic Algorithm for the Dominating Tree Problem. In Proceedings of the 10th International Conference on Simulated Evolution and Learning, Dunedin, New Zealand, 15–18 December 2014; pp. 48–57. [Google Scholar] [CrossRef]
- Agapie, A.; Wright, A.H. Theoretical analysis of steady state genetic algorithms. Appl. Math. 2014, 59, 509–525. [Google Scholar] [CrossRef] [Green Version]
- Muhlenbein, H.; Schlierkamp-Voosen, D. Predictive Models for the Breeder Genetic Algorithm I. Continuous Parameter Optimization. Evol. Comput. 1996, 1, 25–49. [Google Scholar] [CrossRef]
- Mühlenbein, H.; Schlierkamp-Voosen, D. The Science of Breeding and Its Application to the Breeder Genetic Algorithm. Evol. Comput. 1994, 1, 335–360. [Google Scholar] [CrossRef]
- Dorronsoro, B.; Alba, E. A Simple Cellular Genetic Algorithm for Continuous Optimization. In Proceedings of the IEEE International Conference on Evolutionary Computation, Vancouver, BC, Canada, 16–21 July 2006; pp. 2838–2844. [Google Scholar] [CrossRef]
- Pedemonte, M.; Panizo-LLedot, A.; Bello-Orgaz, G.; Camacho, D. Exploring Multi-objective Cellular Genetic Algorithms in Community Detection Problems. In Intelligent Data Engineering and Automated Learning; Analide, C., Novais, P., Camacho, D., Yin, H., Eds.; Springer: Cham, Switzerland, 2020; Volume 12490, pp. 223–235. [Google Scholar] [CrossRef]
- Whitley, D. A genetic algorithm tutorial. Stat. Comput. 1994, 4, 65–85. [Google Scholar] [CrossRef]
- Lam, A.Y.S.; Li, V.O.K. Chemical Reaction Optimization: A tutorial. Memetic. Comp. 2012, 4, 3–17. [Google Scholar] [CrossRef] [Green Version]
- Marrison, C.I.; Stengel, R.F. The use of random search and genetic algorithms to optimize stochastic robustness functions. In Proceedings of the 1994 American Control Conference, Baltimore, MD, USA, 29 June–1 July 1994; pp. 1484–1489. [Google Scholar] [CrossRef]
- Zabinsky, Z.B. Random search algorithms. In Wiley Encyclopedia of Operations Research and Management Science; Cochran, J.J., Cox, L.A., Keskinocak, P., Kharoufeh, J.P., Smith, J.C., Eds.; John Wiley & Sons: New York, NY, USA, 2010; pp. 1–13. [Google Scholar] [CrossRef]
- Rojas, J.M.; Fraser, G.; Arcuri, A. Seeding strategies in search-based unit test generation. Softw. Test. Verif. Reliab. 2016, 26, 366–401. [Google Scholar] [CrossRef] [Green Version]
- Panichella, A.; Kifetew, F.M.; Tonella, P. Automated Test Case Generation as a Many-Objective Optimisation Problem with Dynamic Selection of the Targets. IEEE Softw. Eng. 2016, 44, 122–158. [Google Scholar] [CrossRef] [Green Version]
- Grano, G.; Palomba, F.; Nucci, D.D.; Lucia, A.D.; Gall, H.C. Scented since the beginning: On the diffuseness of test smells in automatically generated test code. J. Syst. Softw. 2019, 156, 312–327. [Google Scholar] [CrossRef] [Green Version]
- Ma, P.; Cheng, H.; Zhang, J.; Xuan, J. Can This Fault Be Detected: A Study on Fault Detection via Automated Test Generation. J. Syst. Softw. 2020, 170, 110769. [Google Scholar] [CrossRef]
- Fraser, G. A Tutorial on Using and Extending the EvoSuite Search-Based Test Generator. In Proceedings of the 10th International Symposium, Montpellier, France, 8–9 September 2018; pp. 106–130. [Google Scholar] [CrossRef]
- Hansen, N.; Auger, A.; Finck, S.; Ros, R. Real-Parameter Black-Box Optimization Benchmarking 2010: Experimental Setup. 2010. Available online: https://hal.inria.fr/inria-00462481 (accessed on 31 May 2021).
- Arcuri, A.; Fraser, G. Parameter tuning or default values? An empirical investigation in search-based software engineering. Empir. Softw. Eng. 2013, 18, 594–623. [Google Scholar] [CrossRef]
- Črepinšek, M.; Liu, S.; Mernik, M. Replication and comparison of computational experiments in applied evolutionary computing: Common pitfalls and guidelines to avoid them. Appl. Soft. Comput. 2014, 19, 161–170. [Google Scholar] [CrossRef]
- Aston, E.; Channon, A.; Belavkin, R.V.; Gifford, D.R.; Krašovec, R.; Knight, C.G. Critical Mutation Rate has an Exponential Dependence on Population Size for Eukaryotic-length Genomes with Crossover. Sci. Rep. 2017, 7, 1–12. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Deb, K.; Deb, D. Analysing mutation schemes for real-parameter genetic algorithms. Int. J. Artif. Intell. Soft Comput. 2014, 4, 1–28. [Google Scholar] [CrossRef]
- Jia, Y.; Merayo, M.; Harman, M. Introduction to the special issue on Mutation Testing. Softw. Test. Verif. Reliab. 2015, 25, 461–463. [Google Scholar] [CrossRef]
- Luo, Q.; Moran, K.; Poshyvanyk, D.; Penta, M.D. Assessing Test Case Prioritization on Real Faults and Mutants. In Proceedings of the IEEE International Conference on Software Maintenance and Evolution, Madrid, Spain, 23–29 September 2018; pp. 240–251. [Google Scholar] [CrossRef] [Green Version]
- Ammann, P.; Offutt, J. Introduction to Software Testing, 2nd ed.; Cambridge University Press: New York, NY, USA, 2016; pp. 18–19. [Google Scholar]
- Fraser, G.; Arcuri, A. Achieving scalable mutation-based generation of whole test suites. Empir. Softw. Eng. 2015, 20, 783–812. [Google Scholar] [CrossRef]










{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Algorithm | Characteristic of Algorithm |
|---|---|
| Traditional GA | Applies only three basic operators: selection, crossover, and mutation |
| Monotonic GA | Still applies three basic operators but adds some processes to select the best chromosome for the next generation. |
| Steady-state GA | Adds some processes to select the best chromosome. Similar to the monotonic GA but replaces the best chromosome in the current population. |
| Breeder GA | Applies the principle of breeding to select chromosomes before performing the basic operators. |
| Cellular GA | Performs mutation operator on only one crossed chromosome. Chromosomes are selected for mutation by choosing at random. |
| Problem Instances | No. of Lines | No. of Classes | No. of Branches |
|---|---|---|---|
| Java Certificate Transparency | 955 | 30 | 178 |
| Commons CLI | 1480 | 22 | 961 |
| Commons Codec | 5545 | 68 | 3050 |
| Commons Email | 1505 | 20 | 209 |
| Commons Jelly | 4688 | 95 | 636 |
| Commons Math3 | 65,389 | 918 | 28,450 |
| Commons Numbers | 317 | 5 | 225 |
| Joda-Time | 19,441 | 166 | 9924 |
| Truth | 4117 | 58 | 223 |
| Total | 103,437 | 1382 | 43,856 |
| Parameters | Default Values |
|---|---|
| Population size | 50 |
| Chromosome length | 40 |
| Selection function | Rank |
| Crossover function | Single point relative |
| Crossover probability | 0.75 |
| Mutation function | Uniform |
| Mutation probability | 0.75 |
| Search budget | 60 s |
| Algorithm | Branch Coverage | Mut. Score | #T | p-Value | (EMSGA:Others) | ||||
|---|---|---|---|---|---|---|---|---|---|
| Avg. | CI | Avg. | CI | ||||||
| EMSGA | 0.5900 | 0.0032 | (0.5877, 0.5923) | 0.4174 | 0.0038 | (0.4146, 0.4201) | 180.49351 | - | - |
| MSGA | 0.5846 | 0.0033 | (0.5823, 0.5870) | 0.4166 | 0.0043 | (0.4135, 0.4196) | 181.5325 | 0.00578 | 0.87 |
| GA | 0.5829 | 0.0040 | (0.5801, 0.5858) | 0.4159 | 0.0046 | (0.4127, 0.4192) | 177.8818 | 0.00168 | 0.92 |
| Monotonic GA | 0.5855 | 0.0063 | (0.5810, 0.5901) | 0.4162 | 0.0050 | (0.4127, 0.4198) | 182.3091 | 0.03752 | 0.74 |
| Steady-State GA | 0.5699 | 0.0036 | (0.5673, 0.5725) | 0.4168 | 0.0023 | (0.4152, 0.4185) | 178.7455 | 0.00018 | 1 |
| Breeder GA | 0.5821 | 0.0059 | (0.5779, 0.5864) | 0.4167 | 0.0040 | (0.4138, 0.4195) | 180.0545 | 0.00466 | 0.88 |
| Cellular GA | 0.5588 | 0.0034 | (0.5563, 0.5612) | 0.4056 | 0.0044 | (0.4024, 0.4087) | 174.2039 | 0.00018 | 1 |
| CRO | 0.5717 | 0.0040 | (0.5688, 0.5746) | 0.4120 | 0.0062 | (0.4076, 0.4164) | 177.9416 | 0.00018 | 1 |
| Random search | 0.5683 | 0.0036 | (0.5657, 0.5709) | 0.4127 | 0.0025 | (0.4109, 0.4144) | 179.5857 | 0.00018 | 1 |
Publisher’s Note: MDPI stays neutral with regard to jurisdictional claims in published maps and institutional affiliations. |
© 2021 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Khamprapai, W.; Tsai, C.-F.; Wang, P.; Tsai, C.-E. Performance of Enhanced Multiple-Searching Genetic Algorithm for Test Case Generation in Software Testing. Mathematics 2021, 9, 1779. https://doi.org/10.3390/math9151779
Khamprapai W, Tsai C-F, Wang P, Tsai C-E. Performance of Enhanced Multiple-Searching Genetic Algorithm for Test Case Generation in Software Testing. Mathematics. 2021; 9(15):1779. https://doi.org/10.3390/math9151779
Chicago/Turabian StyleKhamprapai, Wanida, Cheng-Fa Tsai, Paohsi Wang, and Chi-En Tsai. 2021. "Performance of Enhanced Multiple-Searching Genetic Algorithm for Test Case Generation in Software Testing" Mathematics 9, no. 15: 1779. https://doi.org/10.3390/math9151779
APA StyleKhamprapai, W., Tsai, C.-F., Wang, P., & Tsai, C.-E. (2021). Performance of Enhanced Multiple-Searching Genetic Algorithm for Test Case Generation in Software Testing. Mathematics, 9(15), 1779. https://doi.org/10.3390/math9151779