
Node Generation for RBF-FD Methods by QR Factorization

Abstract
:1. Introduction
2. Background
2.1. RBF Setup
2.2. Calculating RBF-FD Weights
2.3. Accuracy Considerations
3. Node Sampling for RBF-FD Methods
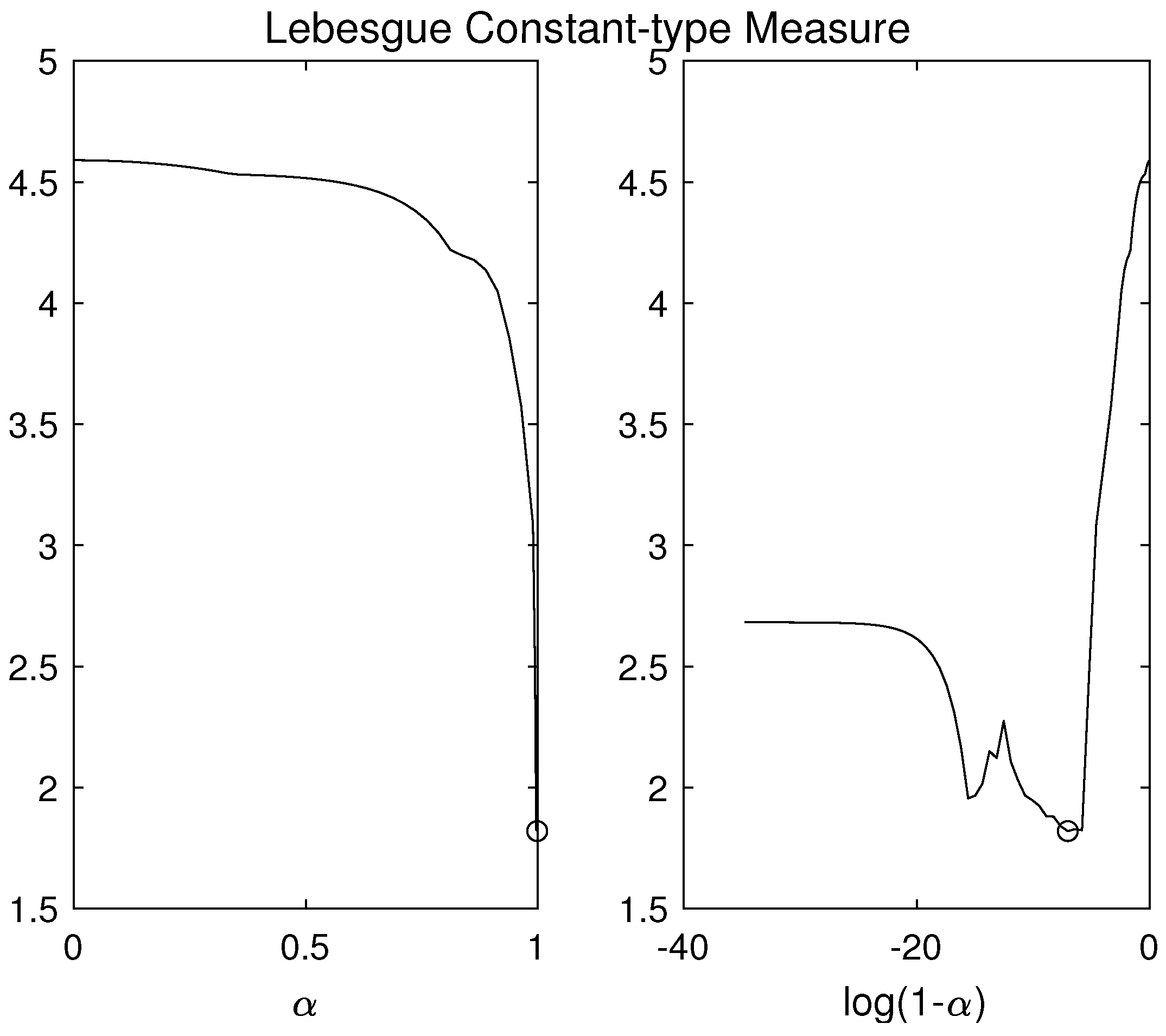
3.1. The Piecewise-Defined Lebesgue Constant for RBF-FD Methods
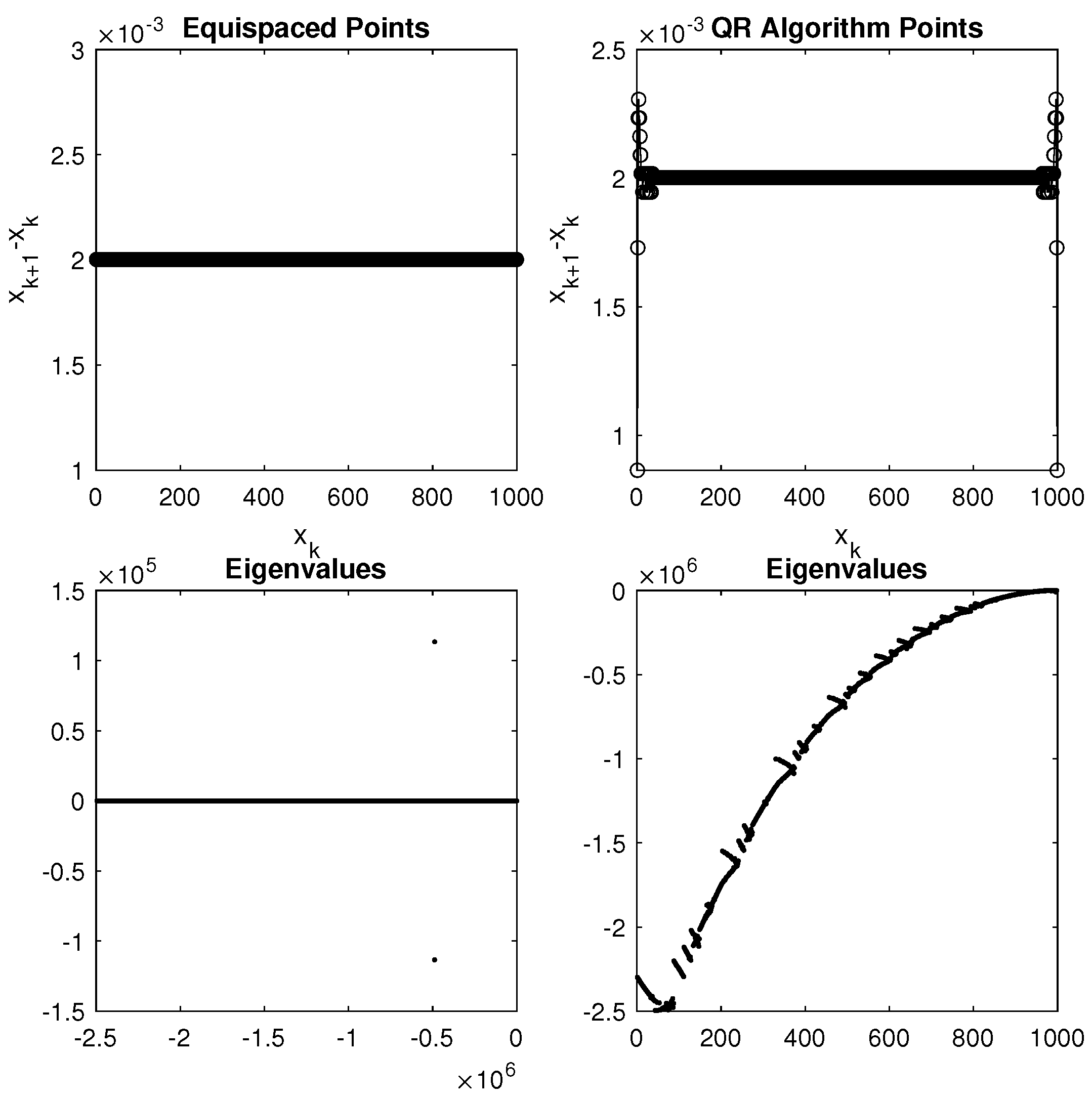
3.2. Modified Column-Pivoting QR Algorithm (MCpQR Algorithm)
| Algorithm 1 Greedy Volume Submatrix Algorithm |
|
| Algorithm 2 Example Column-Pivoting QR Algorithm |
|
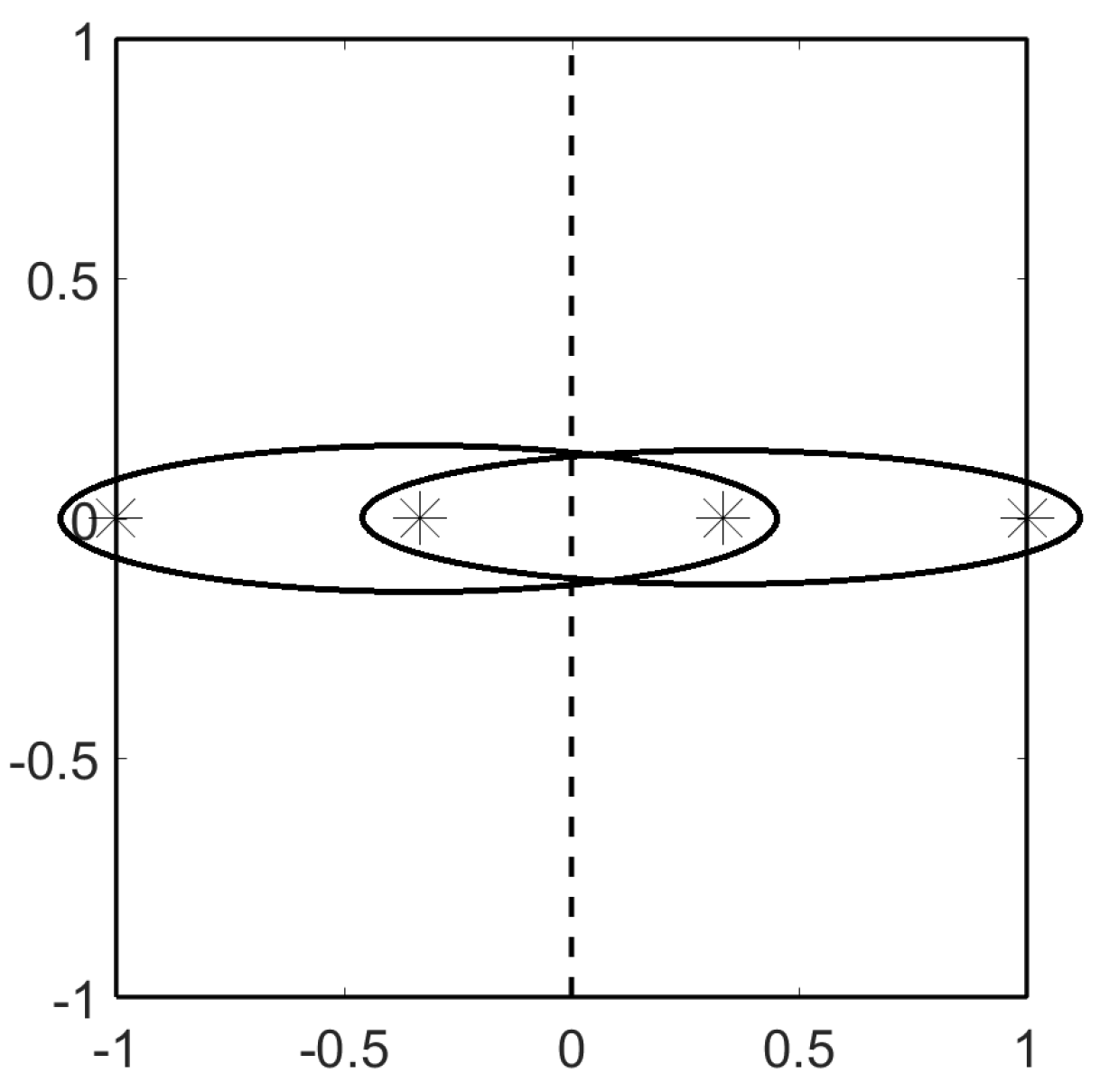
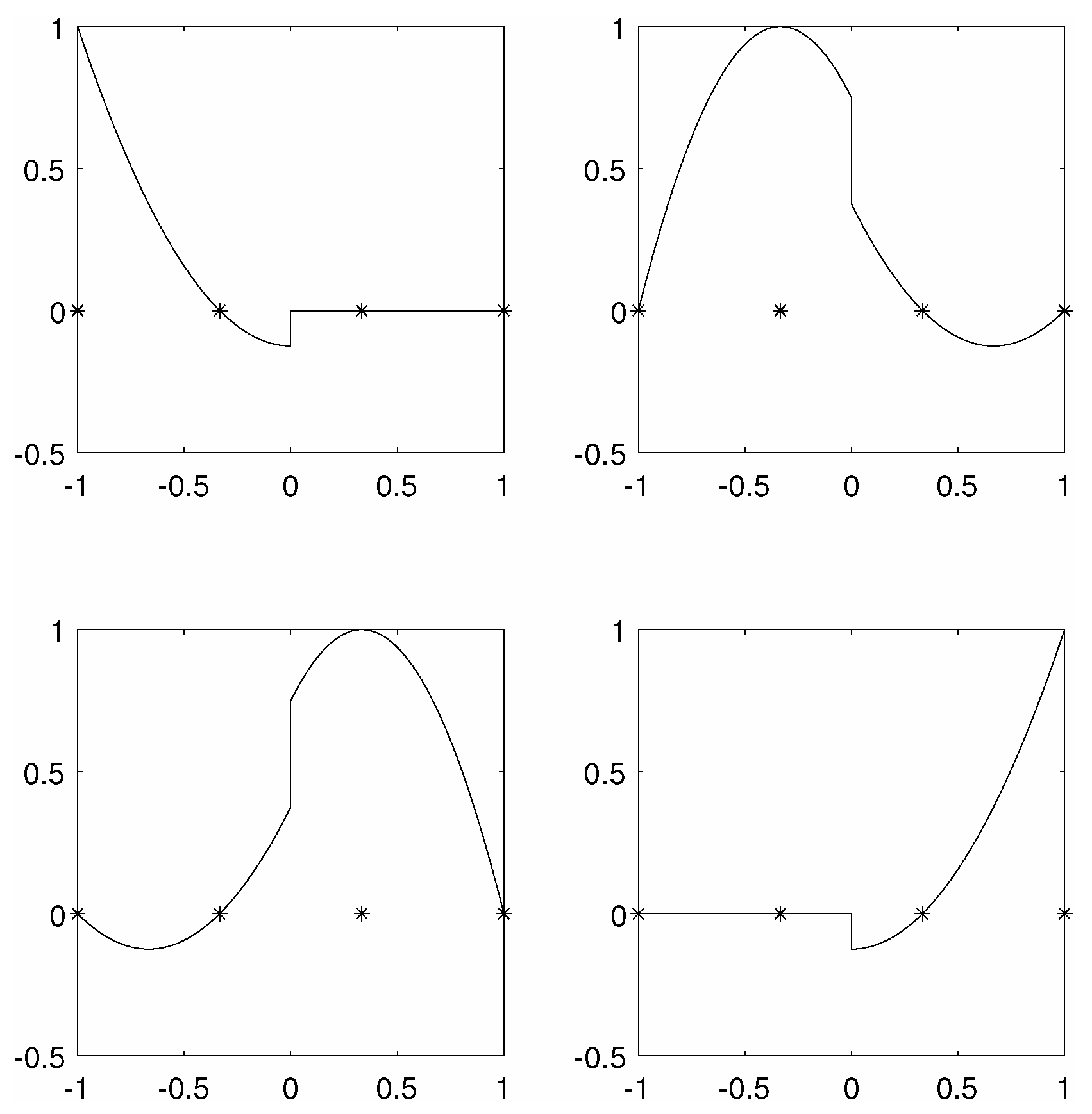
4. Results in 1D
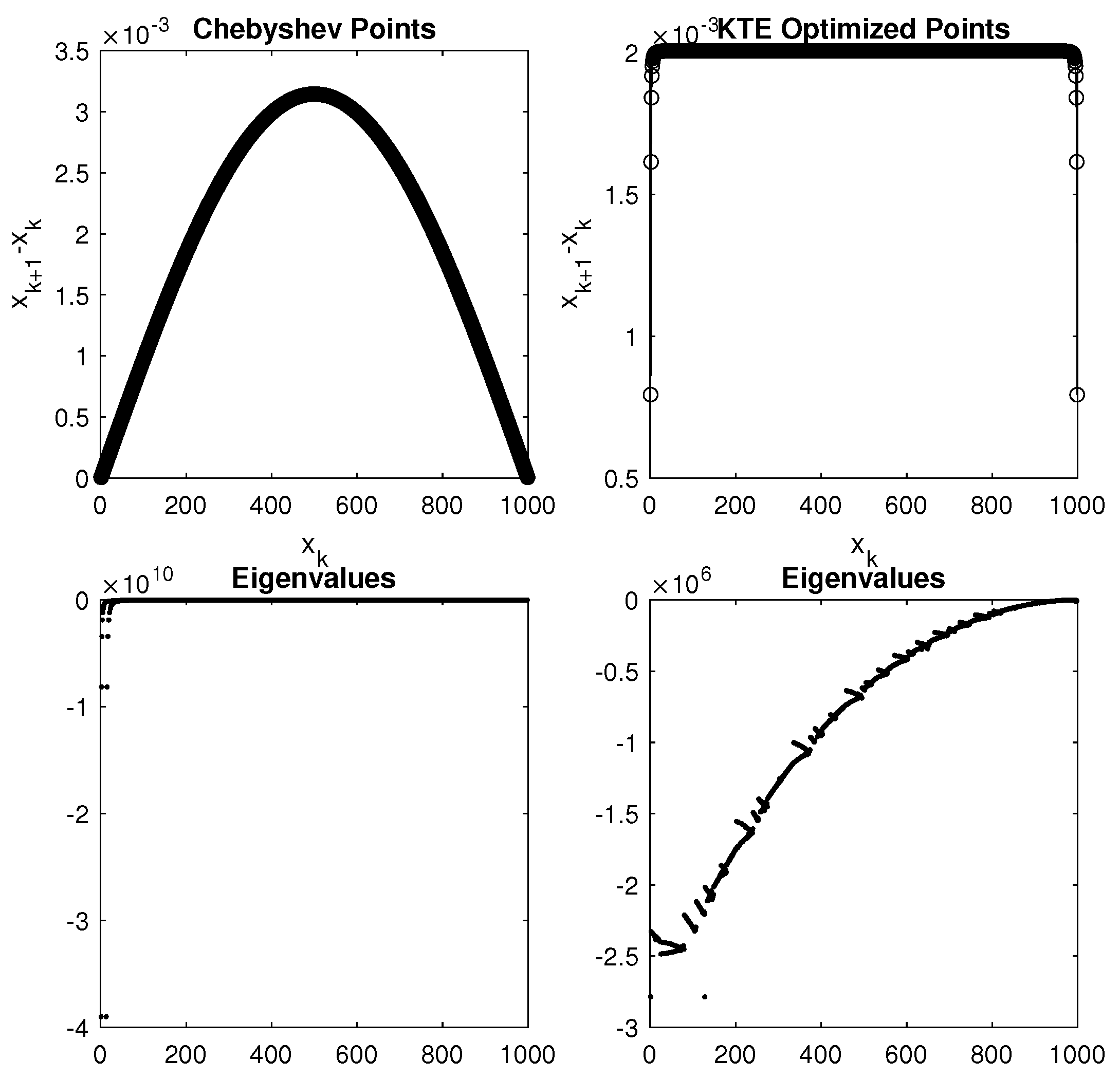
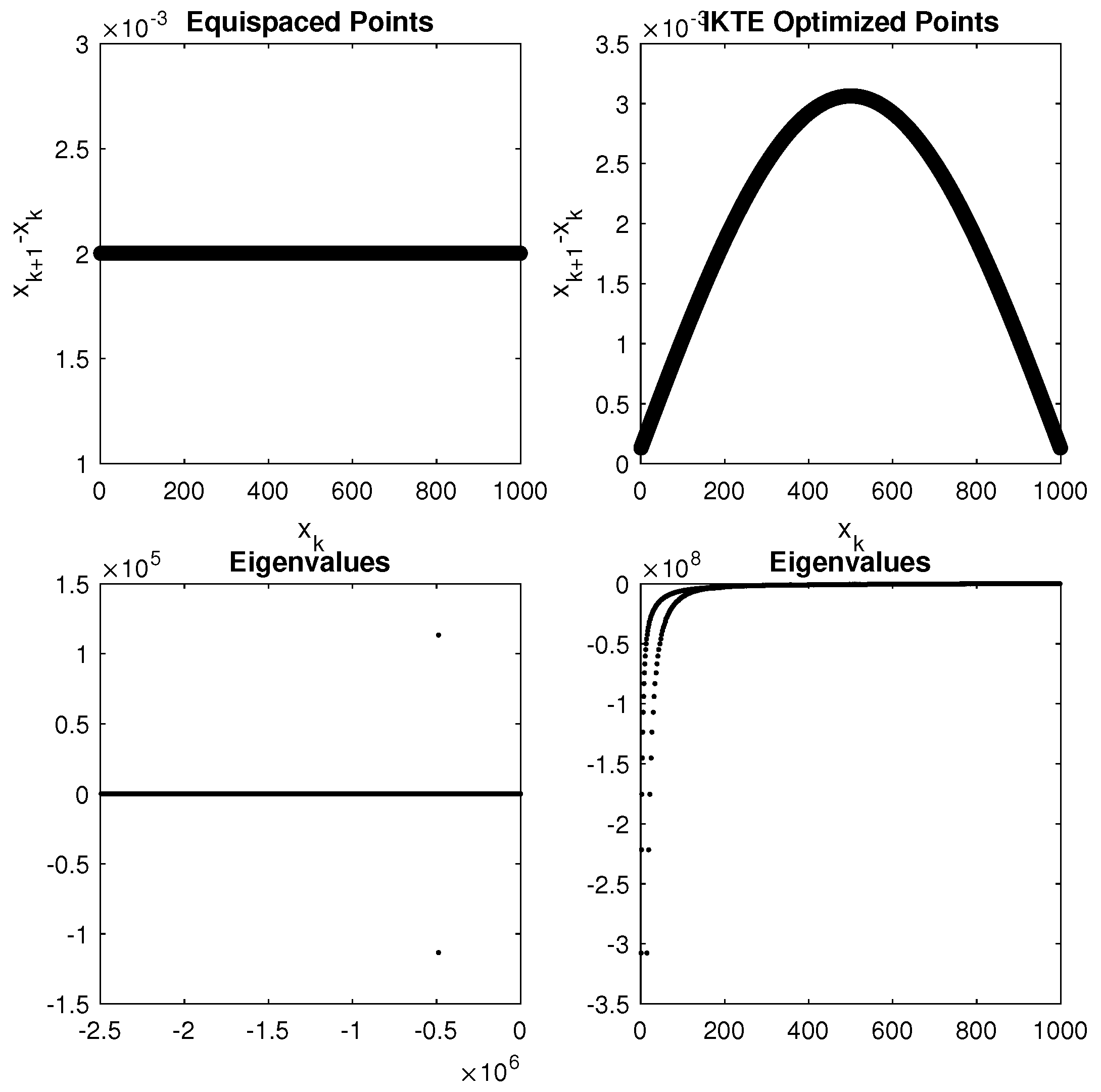
4.1. Mapped Point Sets
4.2. MCpQR Algorithm Point Sets
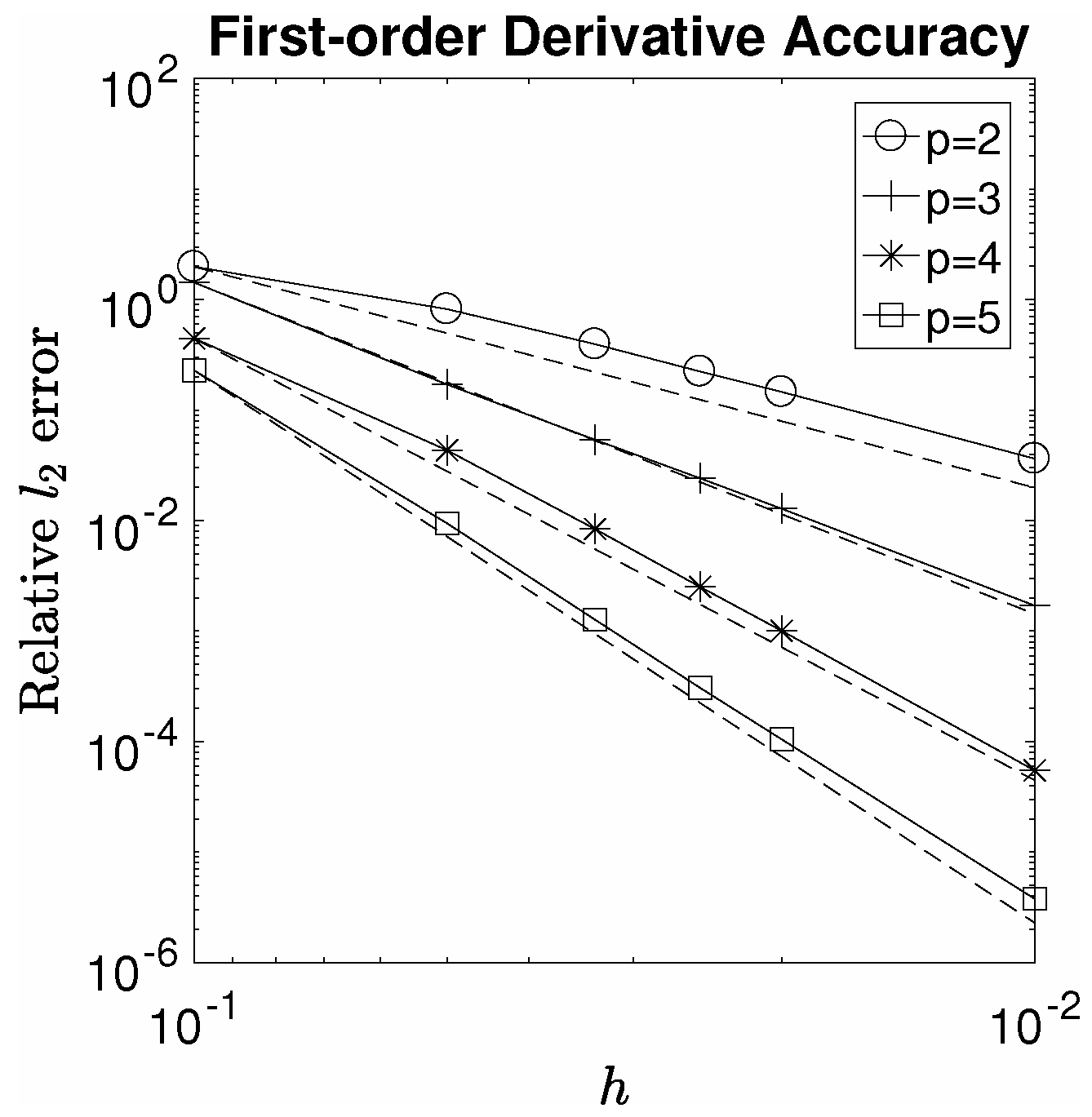
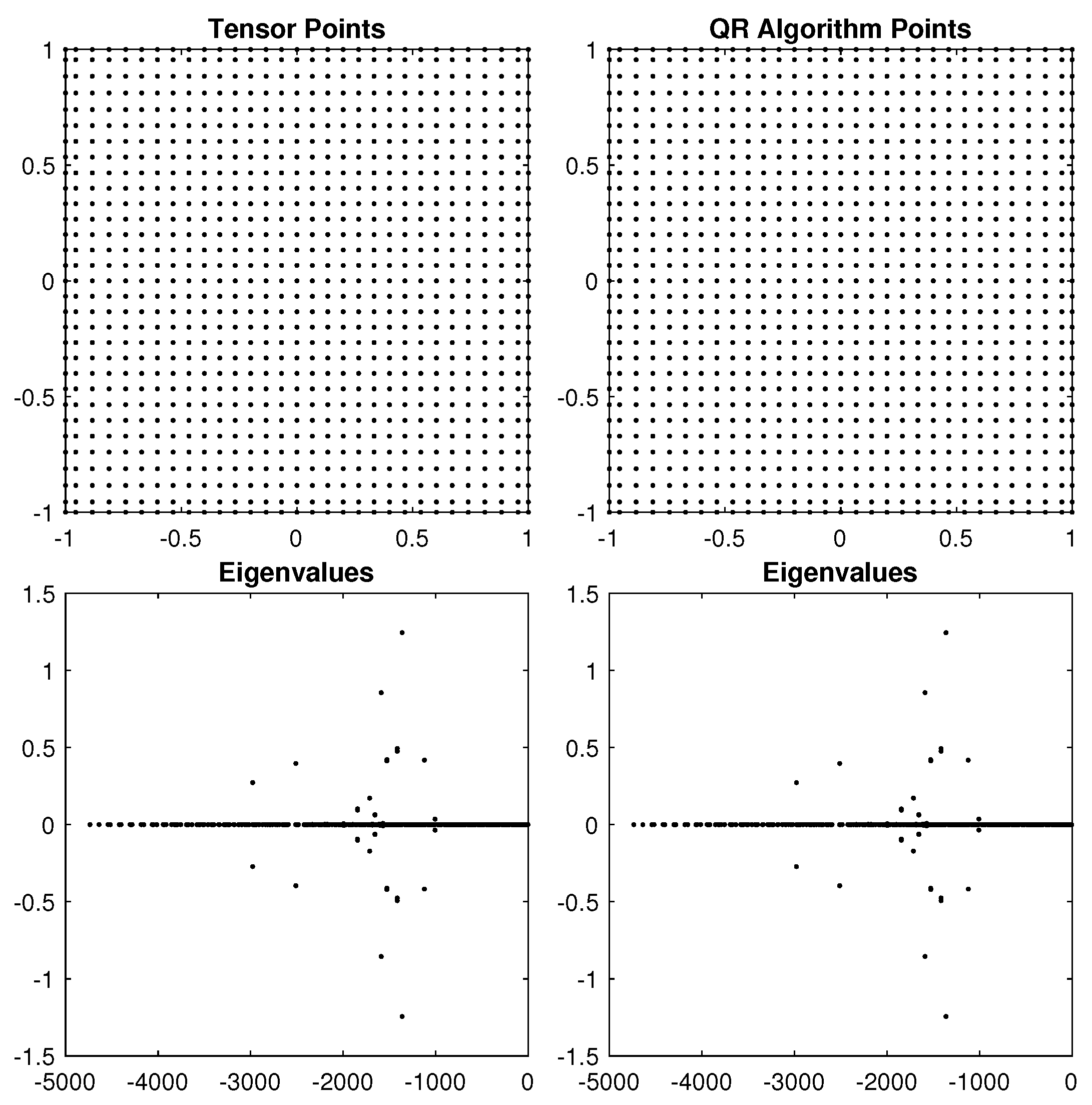
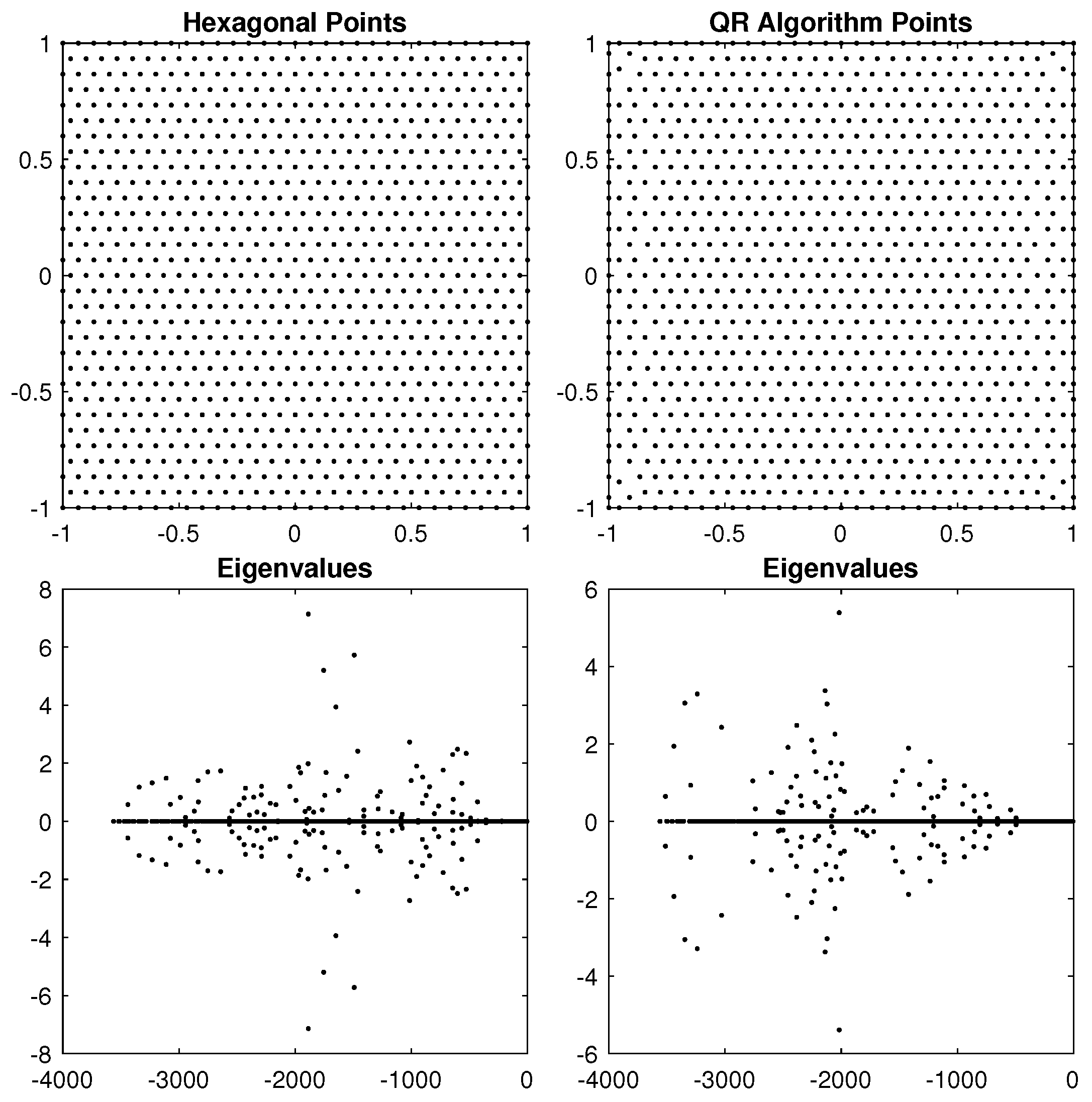
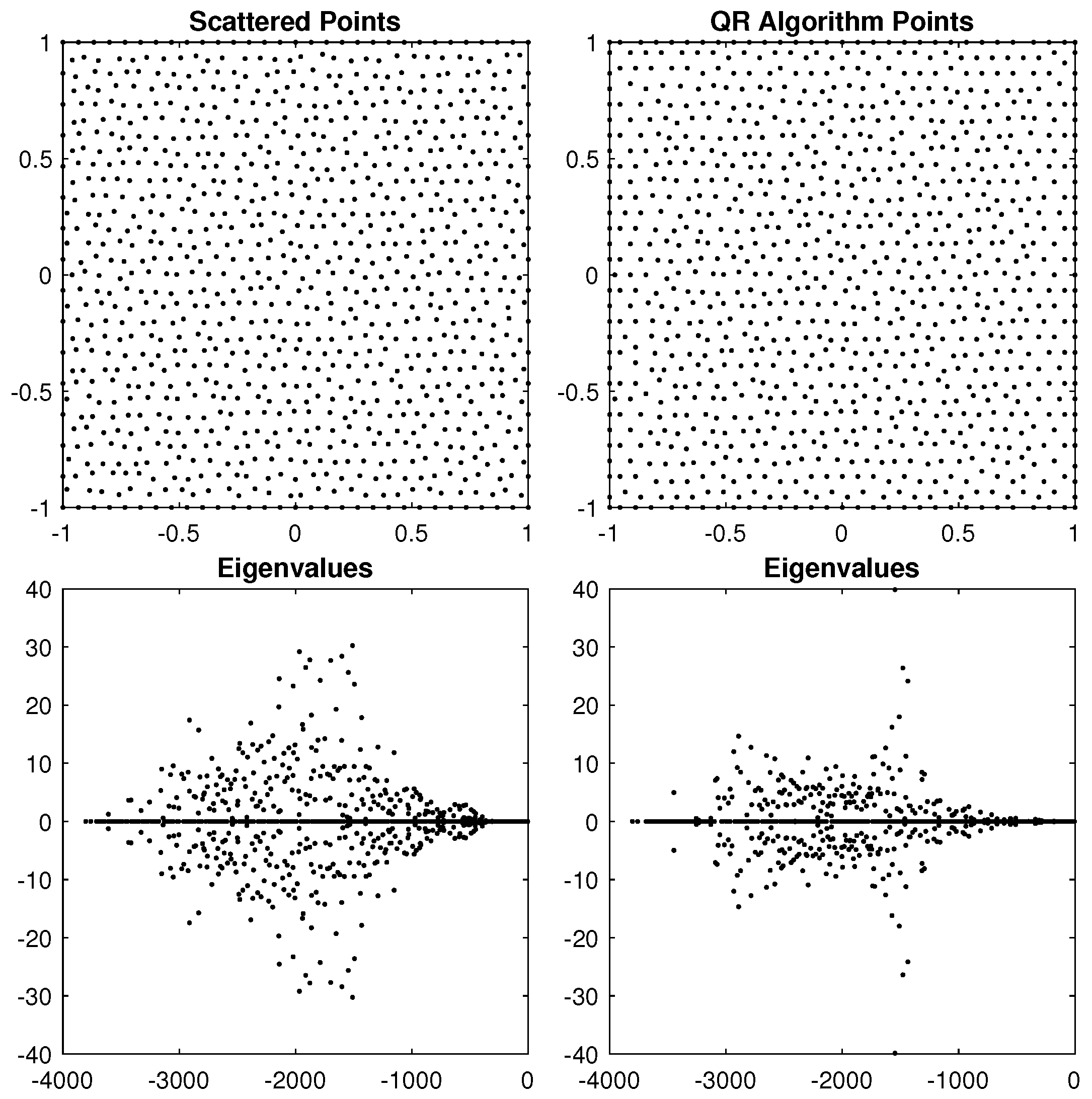
5. Results in 2D
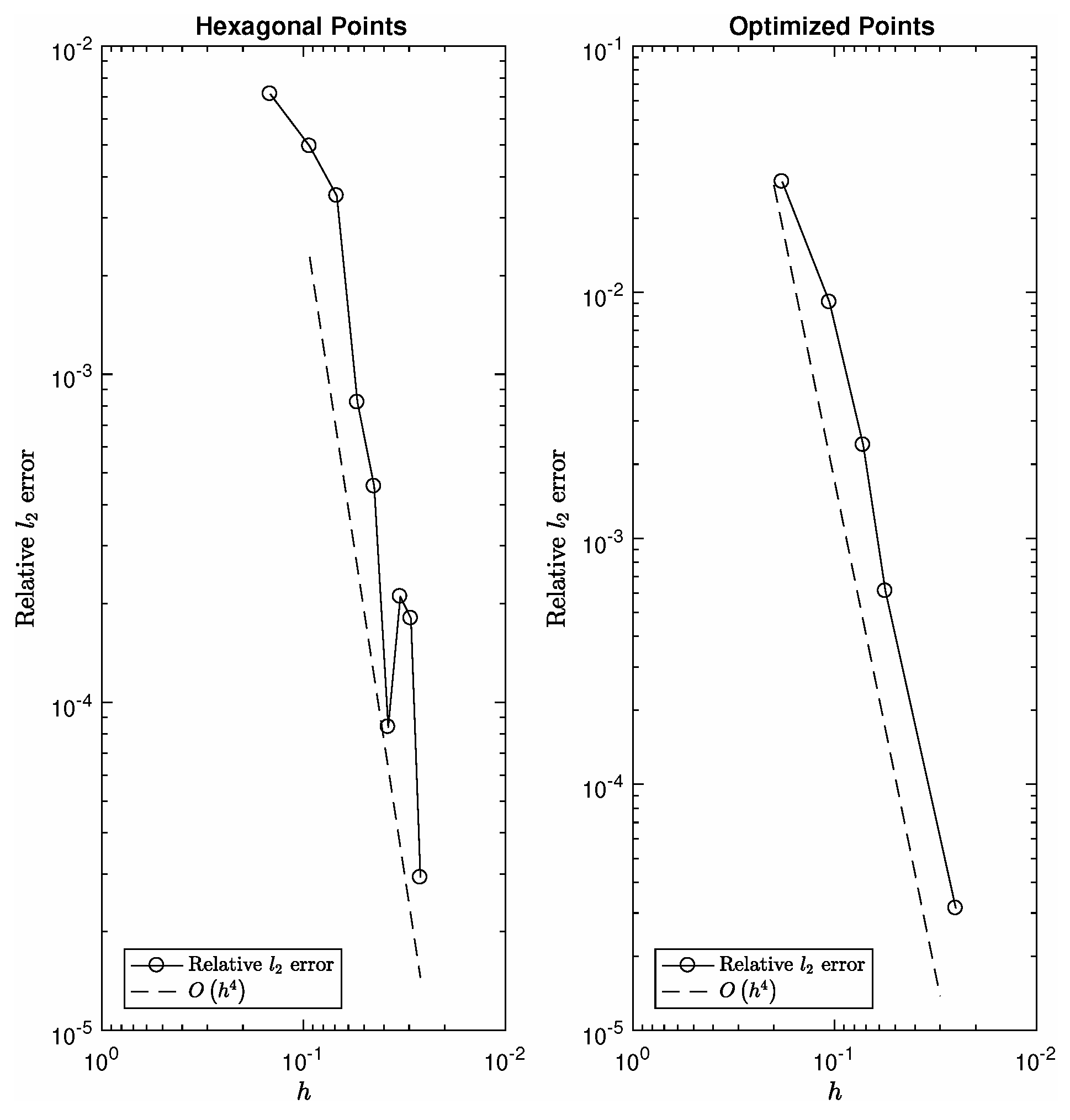
5.1. Unit Square Results
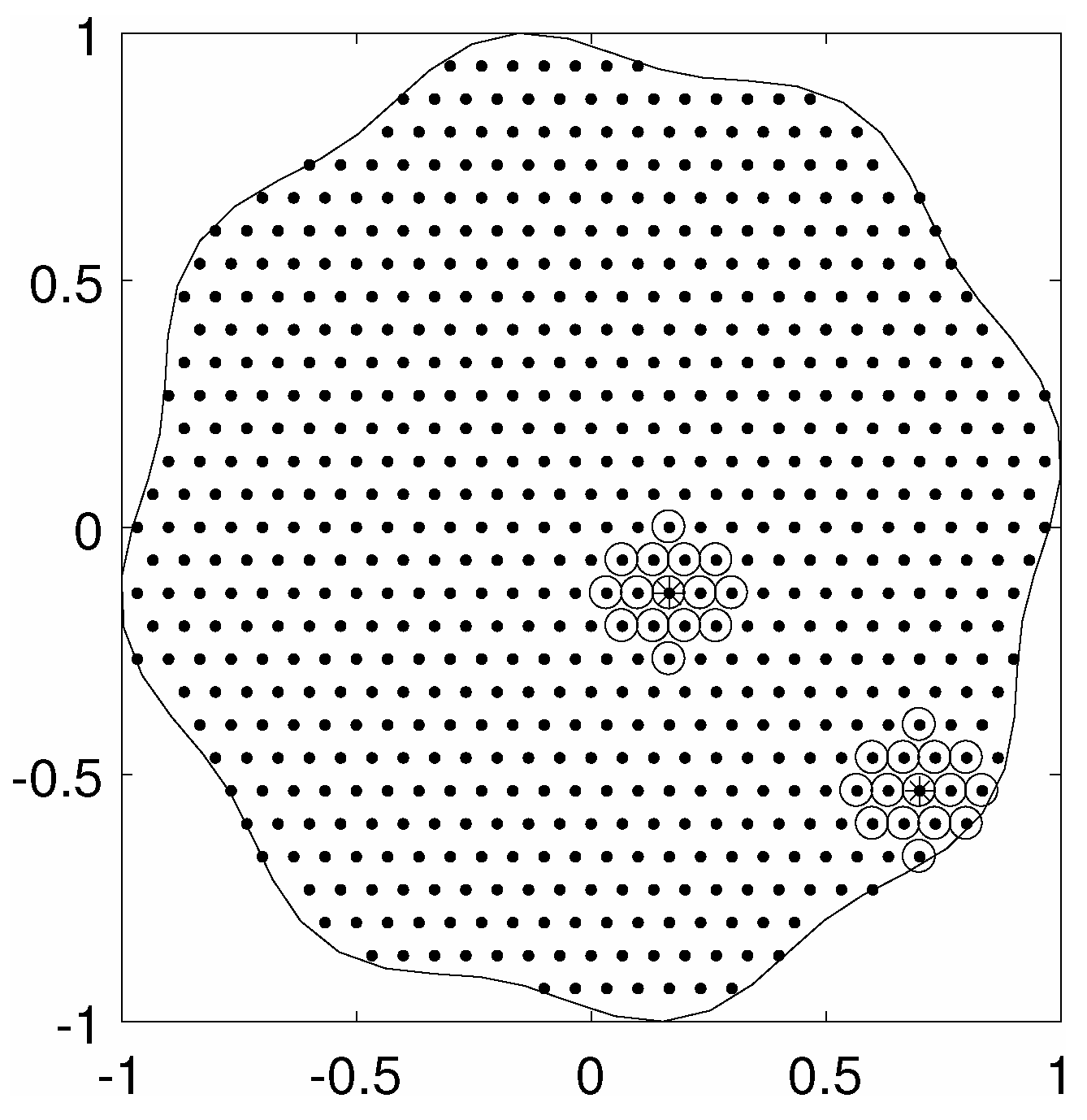
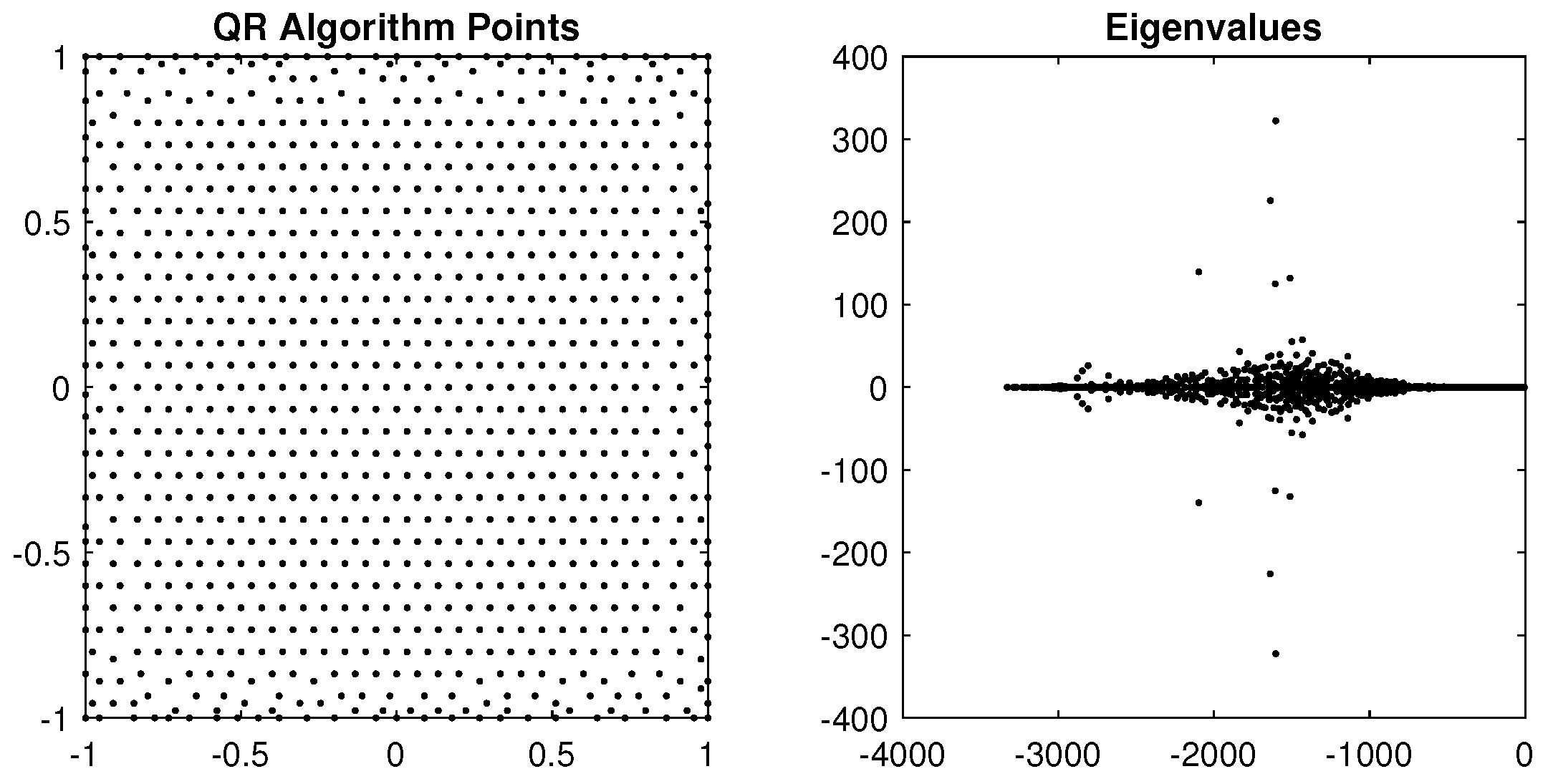
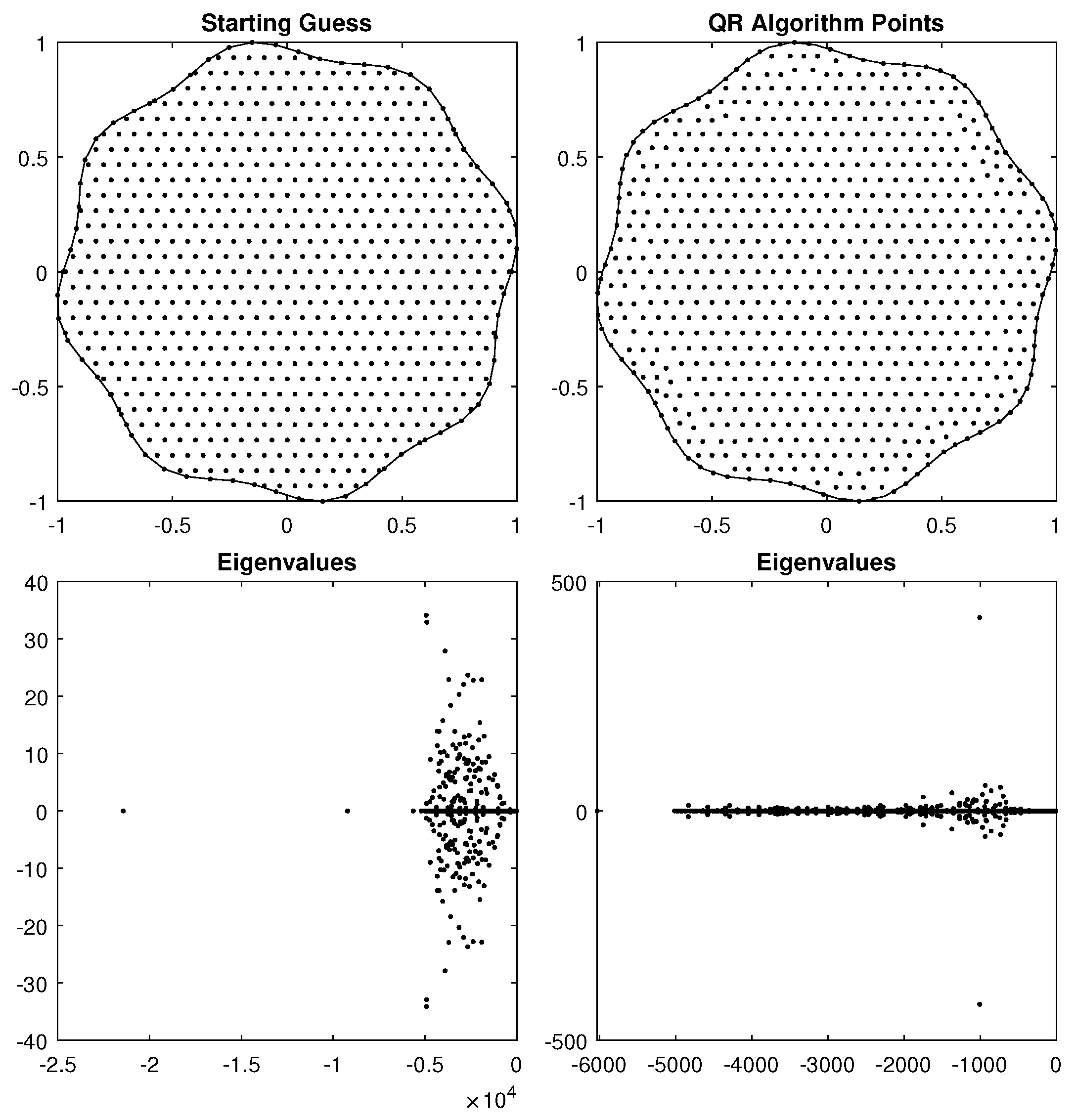
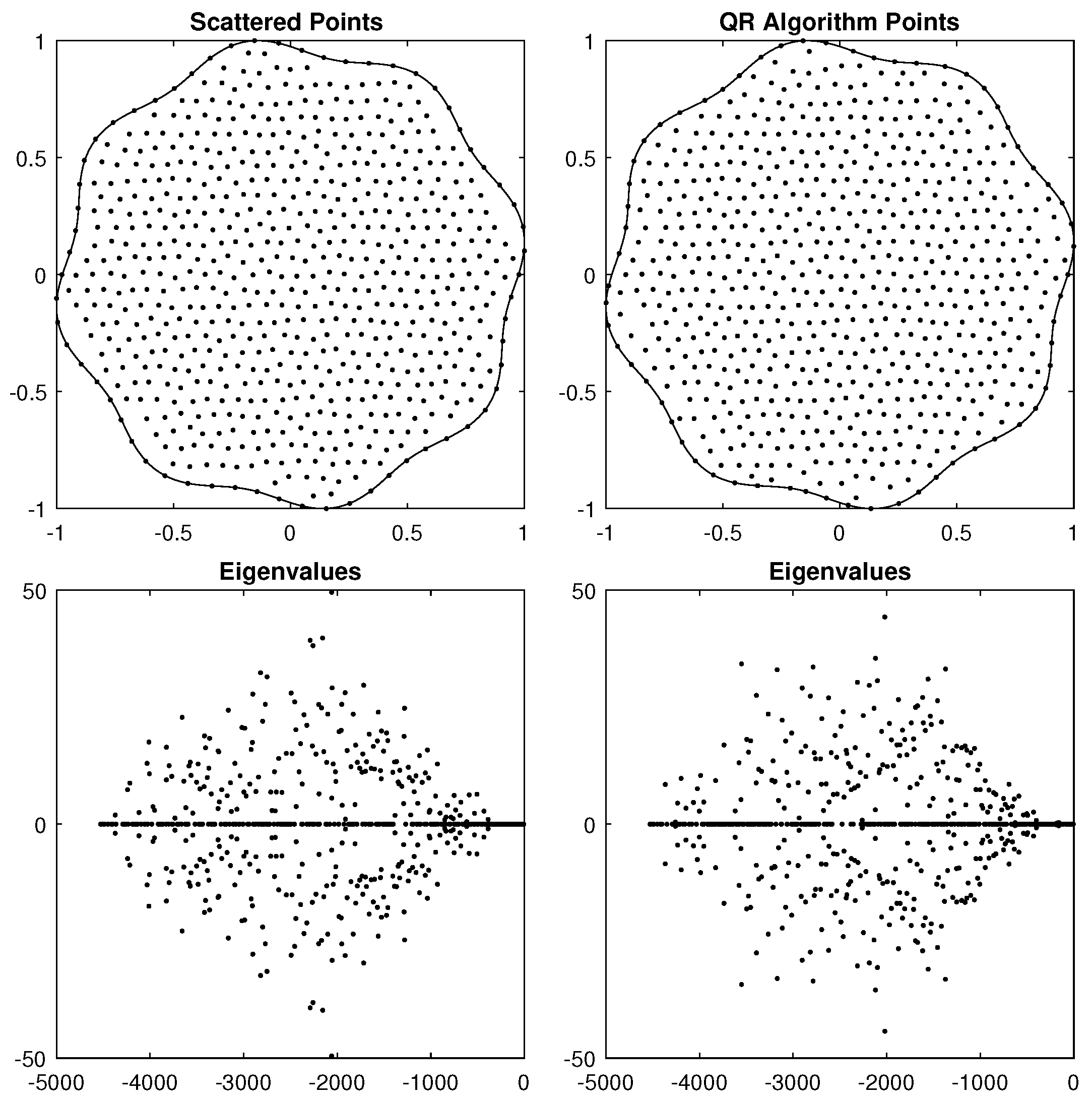
5.2. Complex 2D Regions
6. Test Cases Using MCpQR Algorithm Points
6.1. Diffusion Equation with Forcing Term
6.2. Wave Equation with Hyperviscosity
7. Conclusions
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Data Availability Statement
Acknowledgments
Conflicts of Interest
References
- Barnett, G. A Robust RBF-FD Formulation Based on Polyharmonic Splines and Polynomials. Ph.D. Thesis, University of Colorado Boulder, Boulder, CO, USA, 2015. [Google Scholar]
- Barnett, G.A.; Flyer, N.; Wicker, L.J. An RBF-FD polynomial method based on polyharmonic splines for the Navier-Stokes equations: Comparisons on different node layouts. arXiv 2015, arXiv:1509.02615. [Google Scholar]
- Bayona, V.; Flyer, N.; Fornberg, B. On the role of polynomials in RBF-FD approximations: III. Behavior near domain boundaries. J. Comput. Phys. 2019, 380, 378–399. [Google Scholar] [CrossRef] [Green Version]
- Bayona, V.; Flyer, N.; Fornberg, B.; Barnett, G.A. On the role of polynomials in RBF-FD approximations: II. Numerical solution of elliptic PDEs. J. Comput. Phys. 2017, 332, 257–273. [Google Scholar] [CrossRef] [Green Version]
- Flyer, N.; Barnett, G.A.; Wicker, L.J. Enhancing finite differences with radial basis functions: Experiments on the Navier-Stokes equations. J. Comput. Phys. 2016, 316, 39–62. [Google Scholar] [CrossRef] [Green Version]
- Flyer, N.; Fornberg, B.; Bayona, V.; Barnett, G.A. On the role of polynomials in RBF-FD approximations: I. Interpolation and accuracy. J. Comput. Phys. 2016, 321, 21–38. [Google Scholar] [CrossRef] [Green Version]
- Fasshauer, G.E.; Zhang, J.G. On choosing “optimal” shape parameters for RBF approximation. Numer. Algorithms 2007, 45, 345–368. [Google Scholar] [CrossRef]
- Mongillo, M. Choosing basis functions and shape parameters for radial basis function methods. SIAM Undergrad. Res. Online 2011, 4, 2–6. [Google Scholar] [CrossRef]
- Hagstrom, T.; Hagstrom, G. Grid stabilization of high-order one-sided differencing I: First-order hyperbolic systems. J. Comput. Phys. 2007, 223, 316–340. [Google Scholar] [CrossRef]
- Hagstrom, T.; Hagstrom, G. Grid stabilization of high-order one-sided differencing II: Second-order wave equations. J. Comput. Phys. 2012, 231, 7907–7931. [Google Scholar] [CrossRef]
- Hermanns, M.; Hernández, J.A. Stable high-order finite-difference methods based on non-uniform grid point distributions. Int. J. Numer. Methods Fluids 2008, 56, 233–255. [Google Scholar] [CrossRef] [Green Version]
- Zhong, X.; Tatineni, M. High-order non-uniform grid schemes for numerical simulation of hypersonic boundary-layer stability and transition. J. Comput. Phys. 2003, 190, 419–458. [Google Scholar] [CrossRef]
- Slak, J.; Kosec, G. On generation of node distributions for meshless PDE discretizations. SIAM J. Sci. Comput. 2019, 41, A3202–A3229. [Google Scholar] [CrossRef] [Green Version]
- Fornberg, B.; Flyer, N. Fast generation of 2D node distributions for mesh-free PDE discretizations. Comput. Math. Appl. 2015, 69, 531–544. [Google Scholar] [CrossRef]
- van der Sande, K.; Fornberg, B. Fast variable density 3-D node generation. arXiv 2019, arXiv:1906.00636. [Google Scholar]
- Shankar, V.; Kirby, R.M.; Fogelson, A.L. Robust node generation for mesh-free discretizations on irregular domains and surfaces. SIAM J. Sci. Comput. 2018, 40, A2584–A2608. [Google Scholar] [CrossRef] [Green Version]
- Wendland, H. Scattered Data Approximation; Cambridge University Press: Cambridge, UK, 2004; Volume 17. [Google Scholar]
- Fasshauer, G.E. Meshfree Approximation Methods with Matlab:(With CD-ROM); World Scientific Publishing Co Inc.: Hackensack, NJ, USA, 2007; Volume 6. [Google Scholar]
- Flyer, N.; Wright, G.B.; Fornberg, B. Radial basis function-generated finite differences: A mesh-free method for computational geosciences. Handb. GeoMath. Springer Ref. 2014, 130, 1–30. [Google Scholar]
- Fornberg, B.; Flyer, N. A Primer on Radial Basis Functions with Applications to the Geosciences; SIAM: Philadelphia, PA, USA, 2015. [Google Scholar]
- Shankar, V. The overlapped radial basis function-finite difference (RBF-FD) method: A generalization of RBF-FD. J. Comput. Phys. 2017, 342, 211–228. [Google Scholar] [CrossRef] [Green Version]
- Bayona, V. Comparison of moving least squares and RBF+ poly for interpolation and derivative approximation. J. Sci. Comput. 2019, 81, 486–512. [Google Scholar] [CrossRef]
- Bos, L.; Calvi, J.P.; Levenberg, N.; Sommariva, A.; Vianello, M. Geometric weakly admissible meshes, discrete least-squares approximations and approximate Fekete points. Math. Comput. 2011, 80, 1623–1638. [Google Scholar] [CrossRef]
- Bos, L.; De Marchi, S.; Sommariva, A.; Vianello, M. Computing multivariate Fekete and Leja points by numerical linear algebra. SIAM J. Numer. Anal. 2010, 48, 1984–1999. [Google Scholar] [CrossRef] [Green Version]
- Bos, L.; Levenberg, N. On the calculation of approximate Fekete points: The univariate case. Electron. Trans. Numer. Anal. 2008, 30, 377–397. [Google Scholar]
- Briani, M.; Sommariva, A.; Vianello, M. Computing Fekete and Lebesgue points: Simplex, square, disk. J. Comput. Appl. Math. 2012, 236, 2477–2486. [Google Scholar] [CrossRef]
- Caliari, M.; De Marchi, S.; Vianello, M. Bivariate polynomial interpolation on the square at new nodal sets. Appl. Math. Comput. 2005, 165, 261–274. [Google Scholar] [CrossRef]
- Gunzburger, M.; Teckentrup, A.L. Optimal point sets for total degree polynomial interpolation in moderate dimensions. arXiv 2014, arXiv:1407.3291. [Google Scholar]
- Guo, L.; Narayan, A.; Yan, L.; Zhou, T. Weighted approximate Fekete points: Sampling for least-squares polynomial approximation. arXiv 2017, arXiv:1708.01296. [Google Scholar] [CrossRef] [Green Version]
- Narayan, A.; Xiu, D. Stochastic collocation methods on unstructured grids in high dimensions via interpolation. SIAM J. Sci. Comput. 2012, 34, A1729–A1752. [Google Scholar] [CrossRef]
- Narayan, A.; Xiu, D. Constructing Nested Nodal Sets for Multivariate Polynomial Interpolation. SIAM J. Sci. Comput. 2013, 35, A2293–A2315. [Google Scholar] [CrossRef]
- Sommariva, A.; Vianello, M. Computing approximate Fekete points by QR factorizations of Vandermonde matrices. Comput. Math. Appl. 2009, 57, 1324–1336. [Google Scholar] [CrossRef] [Green Version]
- Van Barel, M.; Humet, M.; Sorber, L. Approximating optimal point configurations for multivariate polynomial interpolation. Electron. Trans. Numer. Anal. 2014, 42, 41–63. [Google Scholar]
- Shukla, R.K.; Zhong, X. Derivation of high-order compact finite difference schemes for non-uniform grid using polynomial interpolation. J. Comput. Phys. 2005, 204, 404–429. [Google Scholar] [CrossRef]
- Kosloff, D.; Tal-Ezer, H. A modified Chebyshev pseudospectral method with an O(N-1) time step restriction. J. Comput. Phys. 1993, 104, 457–469. [Google Scholar] [CrossRef]
- Platte, R.B. How fast do radial basis function interpolants of analytic functions converge? IMA J. Numer. Anal. 2011, 31, 1578–1597. [Google Scholar] [CrossRef] [Green Version]
- Li, T.; Pintus, N.; Viglialoro, G. Properties of solutions to porous medium problems with different sources and boundary conditions. Z. FÜR Angew. Math. Und Phys. 2019, 70, 1–18. [Google Scholar] [CrossRef] [Green Version]
- Marras, M.; Piro, S.V.; Viglialoro, G. Lower bounds for blow-up time in a parabolic problem with a gradient term under various boundary conditions. Kodai Math. J. 2014, 37, 532–543. [Google Scholar] [CrossRef]
- Fornberg, B.; Lehto, E. Stabilization of RBF-generated finite difference methods for convective PDEs. J. Comput. Phys. 2011, 230, 2270–2285. [Google Scholar] [CrossRef]
- Larsson, E.; Lehto, E.; Heryudono, A.; Fornberg, B. Stable computation of differentiation matrices and scattered node stencils based on Gaussian radial basis functions. SIAM J. Sci. Comput. 2013, 35, A2096–A2119. [Google Scholar] [CrossRef] [Green Version]
- Shankar, V.; Fogelson, A.L. Hyperviscosity-based stabilization for radial basis function-finite difference (RBF-FD) discretizations of advection–diffusion equations. J. Comput. Phys. 2018, 372, 616–639. [Google Scholar] [CrossRef]
- Gunderman, D.; Flyer, N.; Fornberg, B. Transport schemes in spherical geometries using spline-based RBF-FD with polynomials. J. Comput. Phys. 2020, 408, 109256. [Google Scholar] [CrossRef]







{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| RBF | Basis Function | Parameter |
|---|---|---|
| Polyharmonic Spline | ||
| Multiquadric | ||
| Inverse Multiquadric | ||
| Gaussian |
| Bumped-Disk Region, 734 Nodes | |||
|---|---|---|---|
| Polynomial Degree | PHS Degree | Two Times the Number of Polynomial Basis Vectors | Required Stencil Size (Optimized Pts) |
| deg = 3 | k = 20 | 15 | |
| deg = 3 | k = 20 | 15 | |
| deg = 3 | k = 20 | 15 | |
| deg = 4 | k = 30 | 19 | |
| deg = 4 | k = 30 | 21 | |
| deg = 4 | k = 30 | 21 | |
| deg = 5 | k = 42 | 31 | |
| deg = 5 | k = 42 | 31 | |
| deg = 5 | k = 42 | 27 | |
| Peanut Region, 830 Nodes | |||
|---|---|---|---|
| Polynomial Degree | PHS Degree | Two Times the Number of Polynomial Basis Vectors | Required Stencil Size (Optimized Pts) |
| deg = 3 | k = 20 | 15 | |
| deg = 3 | k = 20 | 15 | |
| deg = 3 | k = 20 | 15 | |
| deg = 4 | k = 30 | 21 | |
| deg = 4 | k = 30 | 25 | |
| deg = 4 | k = 30 | 25 | |
| deg = 5 | k = 42 | 31 | |
| deg = 5 | k = 42 | 31 | |
| deg = 5 | k = 42 | 33 | |
Publisher’s Note: MDPI stays neutral with regard to jurisdictional claims in published maps and institutional affiliations. |
© 2021 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Liu, T.; Platte, R.B. Node Generation for RBF-FD Methods by QR Factorization. Mathematics 2021, 9, 1845. https://doi.org/10.3390/math9161845
Liu T, Platte RB. Node Generation for RBF-FD Methods by QR Factorization. Mathematics. 2021; 9(16):1845. https://doi.org/10.3390/math9161845
Chicago/Turabian StyleLiu, Tony, and Rodrigo B. Platte. 2021. "Node Generation for RBF-FD Methods by QR Factorization" Mathematics 9, no. 16: 1845. https://doi.org/10.3390/math9161845
APA StyleLiu, T., & Platte, R. B. (2021). Node Generation for RBF-FD Methods by QR Factorization. Mathematics, 9(16), 1845. https://doi.org/10.3390/math9161845