Abstract
Unit distributions are commonly used in probability and statistics to describe useful quantities with values between 0 and 1, such as proportions, probabilities, and percentages. Some unit distributions are defined in a natural analytical manner, and the others are derived through the transformation of an existing distribution defined in a greater domain. In this article, we introduce the unit gamma/Gompertz distribution, founded on the inverse-exponential scheme and the gamma/Gompertz distribution. The gamma/Gompertz distribution is known to be a very flexible three-parameter lifetime distribution, and we aim to transpose this flexibility to the unit interval. First, we check this aspect with the analytical behavior of the primary functions. It is shown that the probability density function can be increasing, decreasing, “increasing-decreasing” and “decreasing-increasing”, with pliant asymmetric properties. On the other hand, the hazard rate function has monotonically increasing, decreasing, or constant shapes. We complete the theoretical part with some propositions on stochastic ordering, moments, quantiles, and the reliability coefficient. Practically, to estimate the model parameters from unit data, the maximum likelihood method is used. We present some simulation results to evaluate this method. Two applications using real data sets, one on trade shares and the other on flood levels, demonstrate the importance of the new model when compared to other unit models.
Keywords:
unit distributions; gamma/Gompertz distribution; moments; quantile; real data applications PACS:
60E05; 62E15; 62F10
1. Introduction
The development of unit distributions has accelerated significantly in recent years. They concentrate on modeling a wide range of events utilizing data with values between 0 and 1, including proportions, probabilities, and percentages, among other things. One reason is the growth of compositional data. On this subject, we can refer the reader to [1]. The construction of parametric, semi-parametric, and regression models is also a strong demand in applied fields for the analysis of such data in particular. The list of unit distributions is lengthy, and it continues to grow year after year. Most modern unit distributions are created by transforming existing distributions through suitably modified schemes. For example, if a random variable X has a lifetime distribution, the inverse-exponential scheme considers the random variable or with , which mechanically has a unit distribution. This particular scheme is also known to transpose some characteristics of the distribution of X to the unit interval. With this inverse-exponential scheme, we may refer the reader to the construction of the log-gamma distribution developed by [2] and based on the standard gamma distribution, log-Lindley distribution established by [3] and based on the Lindley distribution, unit Weibull distribution examined by [4,5] and using the Weibull distribution, unit Gompertz distribution developed by [6] and based on the Gompertz distribution, unit Burr-XII (UBXII) created by [7] distribution and based on the Burr-XII distribution, log-weighted exponential distribution motivated by [8] and based on the weighted exponential distribution, log-Xgamma distribution proposed by [9] and based on the Xgamma distribution, and unit Rayleigh (UR) distribution studied in [10] and using the Rayleigh distribution, among others.
Our study follows this spirit by considering a lifetime distribution never used in this context: the gamma/Gompertz (G/G) distribution. To begin with, the G/G distribution is a three-parameter continuous probability distribution introduced in probability and statistics by [11]. It was first used as a customer lifetime model and an aggregate model of mortality risks. From the mathematical side, the cumulative distribution function (cdf) defining the G/G distribution is
with , and for . The probability density function (pdf) derived to this cdf is
and for . For the sake of clarity, let us mention that the “constant term” in must be read as b multiplied by s, multiplied by . The corresponding hazard rate function (hrf) is easily obtained; it is given as . That is
and for . Some important facts about the G/G distribution are: (a) It is reduced to an exponential distribution with the parameter for ; (b) It corresponds to a gamma mixing of Gompertz distributions, and, more precisely, to a Gompertz distribution with the shape parameter considered as random and varying according to a gamma distribution; (c) Its pdf has a zero mode or an interior mode, and it is shape-adaptable, and by adjusting the parameters, it can be skewed to the left or right; (d) Its hrf has monotonically increasing, decreasing, or constant shapes; (e) The overall shape forms of the pdf and hrf imply that the G/G distribution can be thought of as a generalization of the Pareto distribution; (f) Finally, it has a manageable number of parameters, which, combined with the previously mentioned flexibility of the primary functions, makes the G/G distribution quite appealing for statistical modeling; (g) Standard estimation methods can be applied with the use of real-life data; the G/G paradigm can support a wide range of conceivable scenarios. Natural conjugacy and bounded intensity are also expressed in [11]. Modern studies related to the G/G distribution include those of [12] about the estimation of the three parameters based on the maximum likelihood estimation method, Ref. [13] where some differential equations involving the functions of the G/G distribution are demonstrated, and [14] about the theory and practice of the transmuted version of the G/G distribution.
With the aforementioned facts in mind, we propose to construct a unique flexible distribution over the unit interval by merging the capabilities of the G/G distribution with the inverse-exponential scheme. This new three-parameter unit distribution can be mathematically described as follows. Let X be a random variable with the G/G distribution parameterized as in Equation (1). The inverse-exponential random variable then has a unit distribution, which we can refer to as the unit G/G (UG/G) distribution. We are motivated by the following facts, which we admit at this point: (a) It has strong connections with existing and useful unit distributions, such as the P and MOEP distributions; (b) The flexibility of the G/G distribution is perfectly transposed to the unit interval, with the expected wide panels of shapes for the primary functions; the pdf can be increasing, decreasing, “increasing-decreasing”, and “decreasing-increasing”, with asymmetry to the left or right, and the hrf has monotonically increasing, decreasing, or constant shapes; (c) In-depth moments and quantile analysis are entirely feasible; (d) The parameters may be estimated by all the classical methods and by the powerful maximum likelihood method in particular; (e) The UG/G distribution rivalizes the most useful unit statistical models in the literature. All these claims are the objects of the study with evidence and details.
The following is an overview of the article. Section 2 presents the UG/G distribution with an emphasis on its primary functions and their shape behavior. Section 3 is devoted to its relevant probabilistic and statistical properties, including stochastic ordering, quantile, moments, and reliability coefficient. A parametric estimation strategy is proposed in Section 4. Applications of the UG/G model are developed in Section 5. The article comes to an end in Section 6.
2. Primary Functions
This section focuses on the definition and properties of the primary functions of the UG/G distribution.
2.1. Cumulative Distribution Function
The UG/G distribution is defined by the following cdf: , , where denotes the probability measure, and Y is a random variable with the UG/G distribution. Since, in the distribution sense, we can write , where X has the G/G distribution, we obtain
It follows from Equation (1) and that
Moreover, as any unit distribution, we have for , and for . Alternatively, we can write this function as the following ratio for :
Let us provide some new elements in the connection of the UG/G distribution with some existing unit distributions in the literature. Based on Equation (2) or Equation (3), we can conclude that the UG/G distribution unifies a number of important unit distributions. First, when , we get
which is equivalent to the main term of the cdf of the power distribution with parameter . Second, when , we get
This expression defines the cdf of the Marshall–Olkin extended power distribution by [15] reduced to the unit interval, i.e., with in the distribution defined in the previous reference. The above distributions have been demonstrated to be useful in a number of statistical issues. Thus, the UG/G distribution, which may be considered a generalization of them, is likely to meet the same fate.
2.2. Probability Density Function
The pdf of the UG/G distribution is obtained by differentiating the cdf in Equation (2). That is
and for . We can remark that, for , and are connected via the following functional equation:
or, equivalently,
This relationship can be useful for theoretical purposes, especially in the context of ordering statistics, which are not treated in this study.
Some analytical properties of are now being studied. To begin, the following asymptotic properties hold:
The shape behavior of is shown in the following result.
Proposition 1.
The shape behavior of can be summarized as follows:
- If or , then is monotonic. In particular:
- –
- If , is increasing.
- –
- If , is decreasing.
- If , then is non-monotonic. In particular:
- –
- If , is “increasing-decreasing”.
- –
- If , is “decreasing-increasing”.
Proof.
Let us examine the logarithmic function of instead of directly, which is a more manageable function from the analytical standpoint. After standard derivative developments, we have
Hence, we have if
Therefore, if the parameters b, s and satisfy , i.e., or , is non-monotonic. It is monotonic in the other cases.
By proceeding step by step, the following facts are observed. If or , and , we have ; is increasing. Similarly, if or , and , ; is decreasing. If , and , we have for and for , is a maximum point and is “increasing-decreasing”. If , and , we have for and for , is “decreasing-increasing”. This concludes the proof of Proposition 1. □
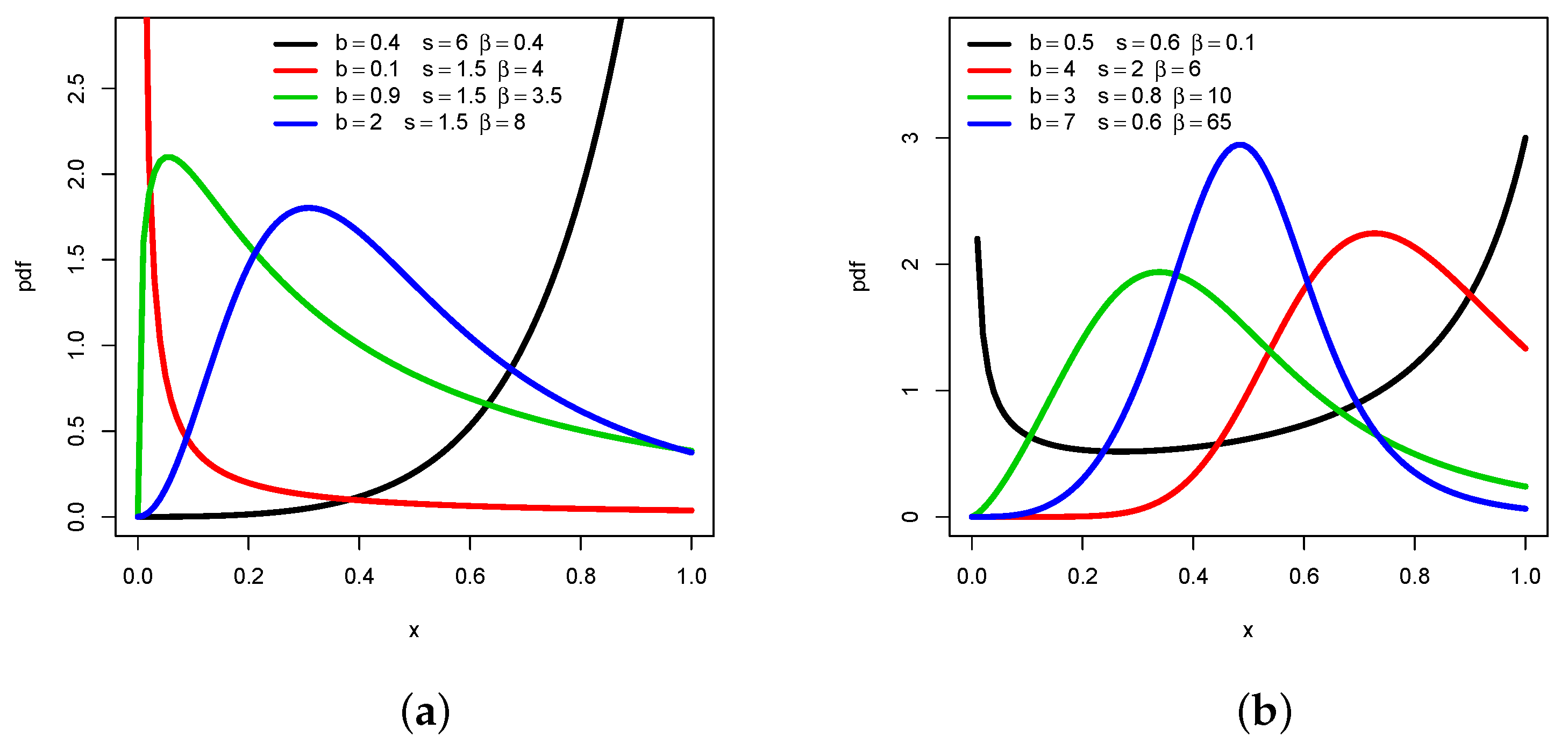
Proposition 1 reveals that has a wide variety of shapes, depending on some precise conditions on the involved parameters. This is illustrated in Figure 1 by selecting parameters in such a way to present a maximum of different shapes.
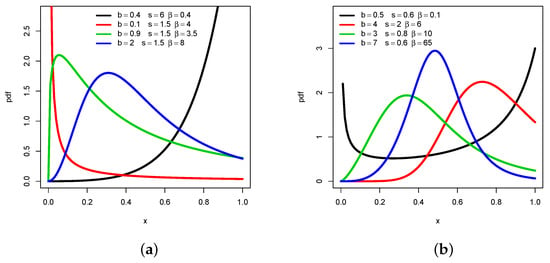
Figure 1.
Plots of for several values of b, s and showing (a) decreasing, increasing, and “increasing-decreasing” highly right-skewed shapes, and (b) “increasing-decreasing” moderately right-skewed or almost symmetric and “decreasing-increasing” shapes.
From Figure 1a, the decreasing, increasing, and “increasing-decreasing” shapes of are observed, with the additional information that it can be skewed to the right in an abrupt manner. The green curve illustrates this last point. On the other hand, Figure 1b completes Figure 1a by showing “increasing-decreasing” with moderate right-skewed or almost symmetric shapes (see the blue line), and “decreasing-increasing” shapes. In particular, the black line is typical of what can be called a U shape. The wide variety of curvature possibilities possessed by this pdf is clearly a huge advantage of the UG/G distribution. It is useful in diverse statistical applications demanding a flexible distribution to capture all the information behind the data.
2.3. Survival and Hazard Rate Functions
It follows immediately from Equation (3) that the survival function (sf) of the UG/G distribution is given by . That is
which can be completed with for and for . The corresponding hrf is obtained quite standardly; it is given as . That is
and for . Since they are informative in the modelling sense, some analytical properties of are now being examined. To begin, the following asymptotic properties hold:
For a fine analysis of the shape behavior of , let us present the following function:
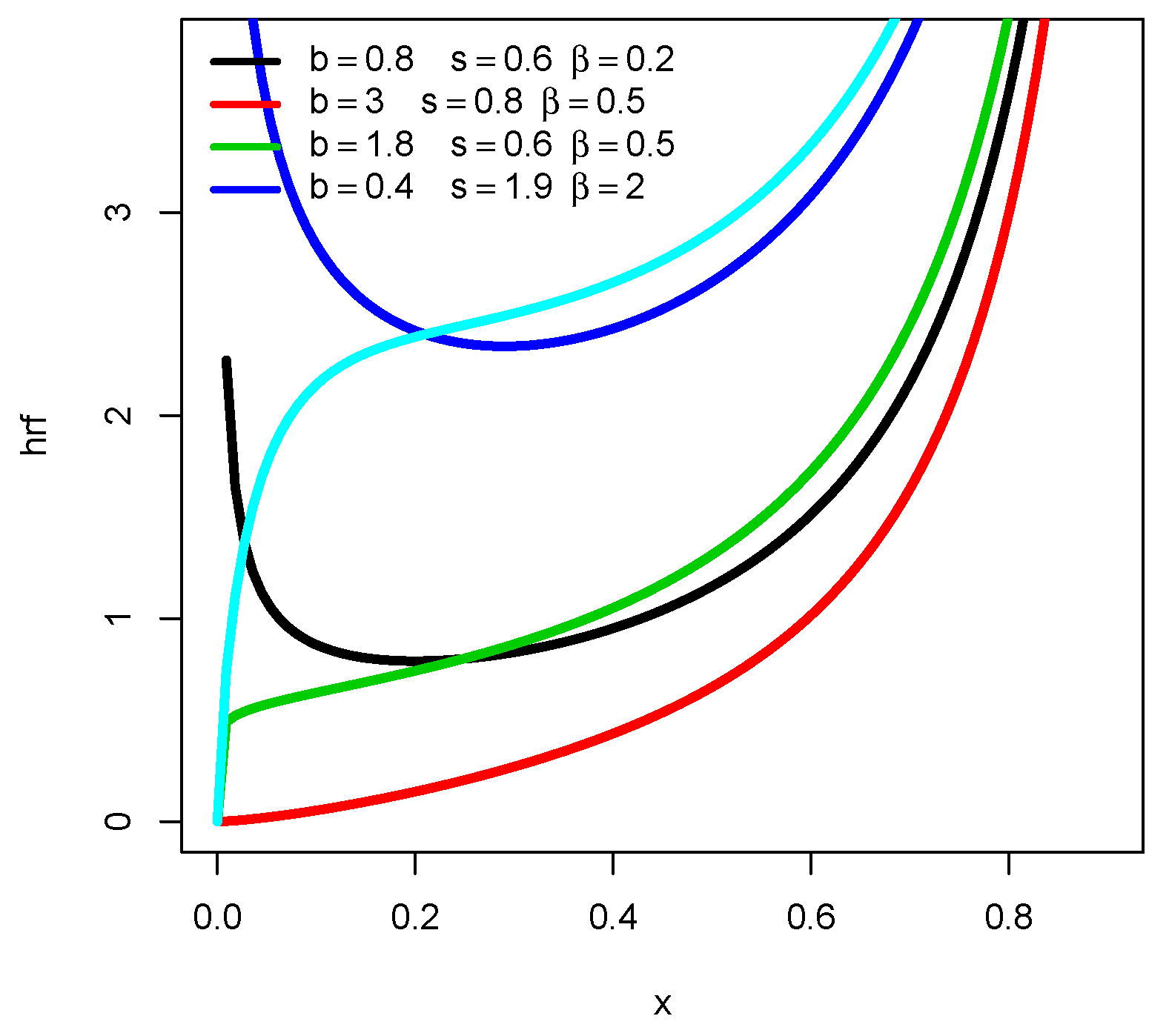
This function is of high complexity, and its sign depends on some configurations of the parameters. As an immediate remark, we can notice that, for and , then , implying that is increasing. This result is completed with a graphical approach in Figure 2, demonstrating the capability of in terms of shapes.
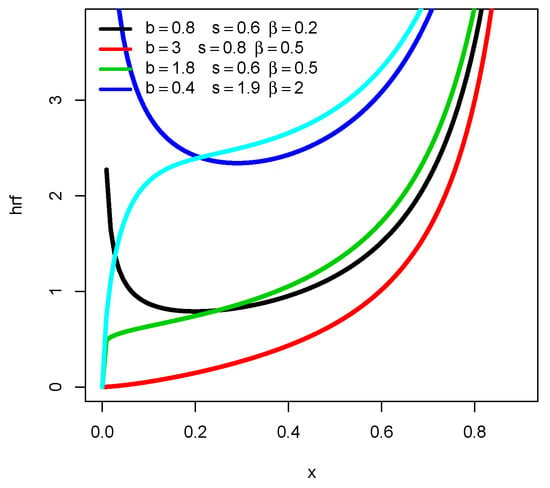
Figure 2.
Plots of for several values of b, s, and .
Hence, as shown in Figure 2, has a number of convex properties when it is increasing, and it can be “decreasing-increasing”. As a result, the U shape property is obtained for both the pdf and hrf of the UG/G distribution.
3. Relevant Properties
This section summarizes our most important results on the technical properties of the UG/G distribution.
3.1. Distributional Inequalities
The next result investigates some inequalities satisfied by the cdf of the UG/G distribution. These inequalities are the foundation of first order stochastic dominance (see [16]).
Proposition 2.
The function is
- decreasing with respect to the parameter b,
- decreasing with respect to the parameter s,
- increasing with respect to the parameter β.
Proof.
Several ways of proof are possible. Here, we focus on the derivative approach.
- After several developments, we establish thatThus, the function is decreasing with respect to the parameter b.
- With the same approach, we haveSincewe have , and the function is decreasing with respect to the parameter s.
- Algebraic operations provideAs a result, the function is increasing with respect to the parameter . Proposition 2 is proven. □
Based on Proposition 2 and the remarks made in Equations (4) and (5), the following corollary involving the power and Marshall–Olkin extended power distributions is fulfilled.
Corollary 1.
The following first order stochastic order dominance results are valid.
In comparison to the power and Marshall–Olkin extended power distributions, Corollary 1 shows how the UG/G distribution is placed in the stochastic sense. Based on the values of and s, we can see that the UG/G distribution achieves different modeling objectives. Further developments related to the first stochastic order can be found in [16].
3.2. Moment Properties
The raw moments of the UG/G distribution are the subject of the next proposition.
Proposition 3.
For any integer m, the mth moment of a random variable Y with the UG/G distribution is given as
where denotes the Hypergeometric function defined by
Proof.
Let X be a random variable with the G/G distribution. Then, the moment generating function of X is given by , and it is expressed in [11]. Since the distribution of Y is the one of , by remarking that , the desired expressions comes by taking into . The proof of Proposition 3 ends. □
Based on Proposition 3, we can calculate the mean of Y given by and variance of Y given by . The standard deviation follows immediately by taking the square root. The moments skewness of Y is obtained by
and the moment kurtosis of Y can be expressed as
We can expand the expressions of these measures by applying the standard binomial formula. Table 1 displays some numerical values of the aforementioned moment measures. The considered values of the parameters are picked haphazardly in order to demonstrate the adaptability of the above-moment measures.

Table 1.
The values of some moment measures for the UG/G distribution for several values of b, s, and .
From Table 1, we observe that the UG/G distribution can be left and right skewed due to some negative and positive values for S. Furthermore, the UG/G distribution encompasses all kurtosis states; when we compare K to 3, which is the value of reference for a kurtosis associated to a standard normal distribution, we can see that it can be lower, nearly equal, or greater. The observations presented in Figure 1 substantiate these findings.
3.3. Quantile Properties
The quantile function (qf) of the UG/G distribution is given as , . That is, after some elementary operations, we obtain
The concept of qf has been used in a number of academic and practical publications. Several measures of position, skewness, and kurtosis can be defined based on this function. For example, the median of the UG/G distribution is just the second main quartile, which may be written as
As useful quantile skewness measure, we can mention the Bowley skewness expressed as
where denotes the ith quartile of the UG/G distribution, i.e., , and . Furthermore, as a famous quantile kurtosis measure, the Moors kurtosis is defined by
where denotes the ith octile of the UG/G distribution, i.e., , , and 4. Finally, we can create values from the UG/G distribution by taking advantage of the fact that has the UG/G distribution for any random variable Z with the unit uniform distribution. To put it another way, the qf converts values from the unit uniform distribution to values from the UG/G distribution. The book of [17] contains more material on the issue of quantile analysis.
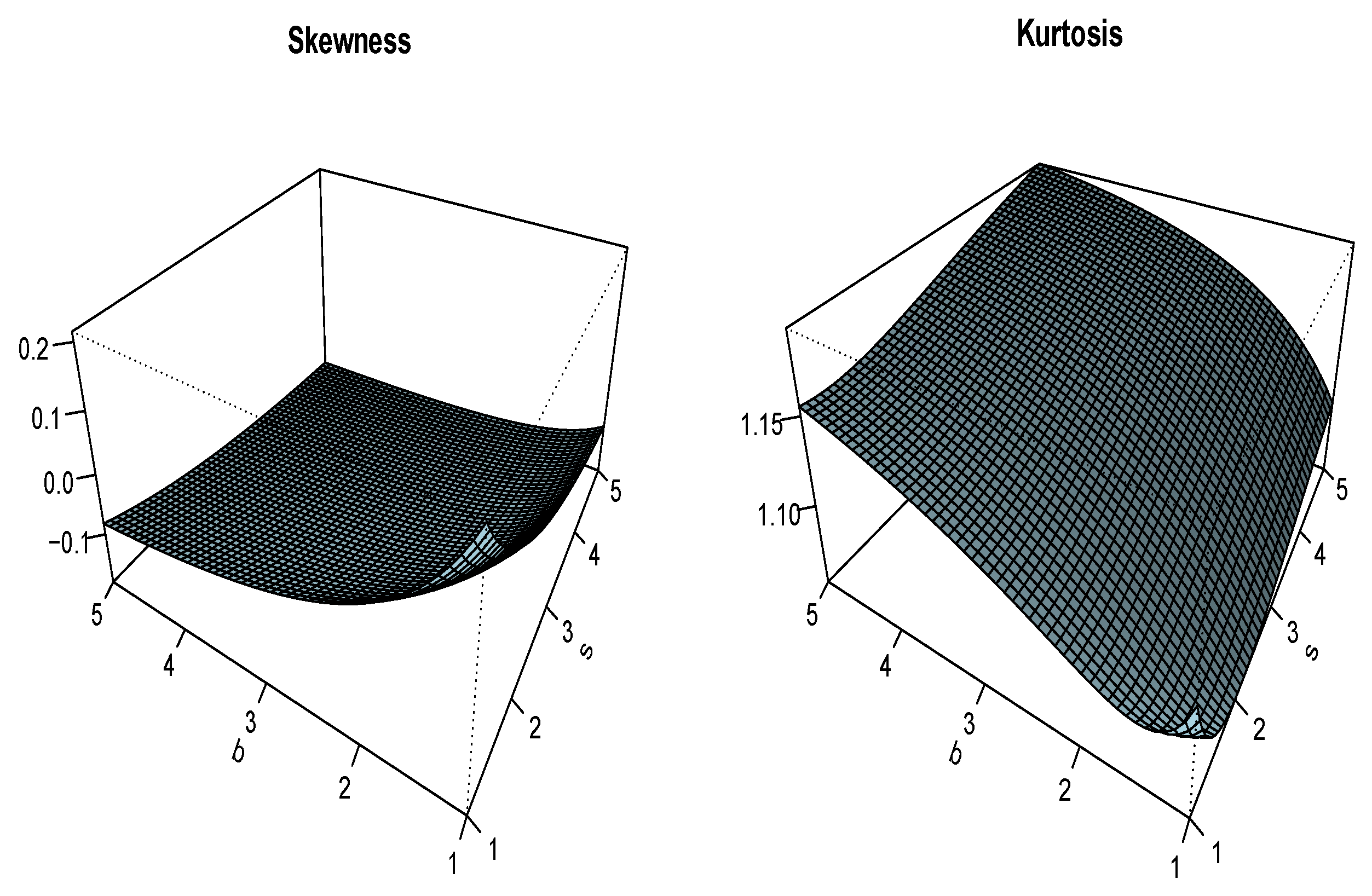
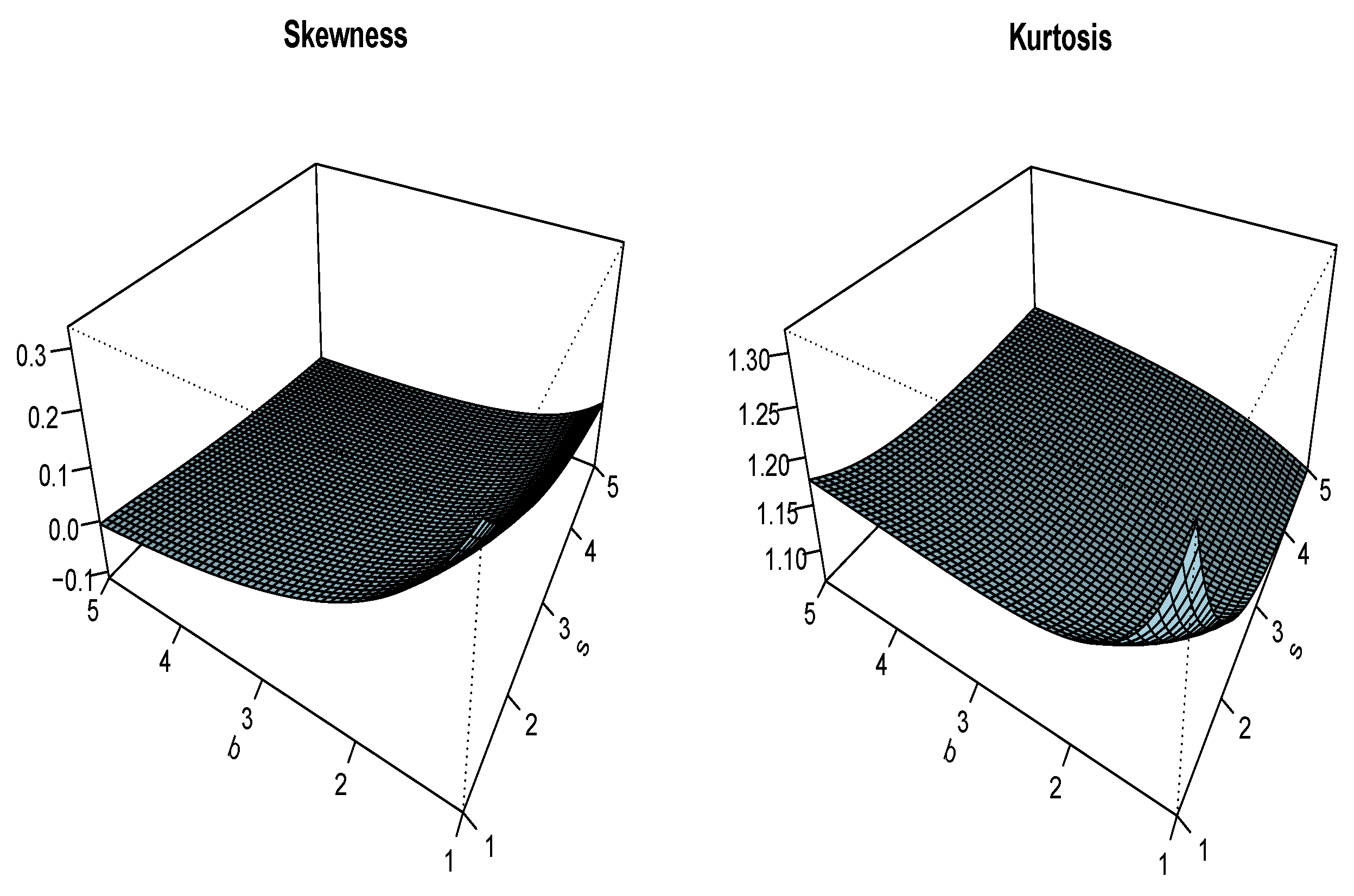
Figure 3 and Figure 4 complete the quantile study above by presenting three-dimensional plots of the Bowley skewness and Moors kurtosis of the UG/G distribution for several values of b, s, and .
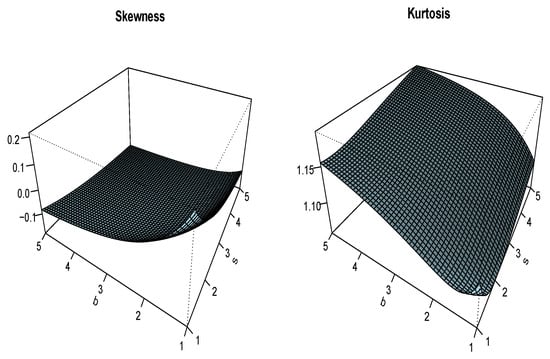
Figure 3.
Plots of the Bowley skewness and Moors kurtosis of the UG/G distribution for and .
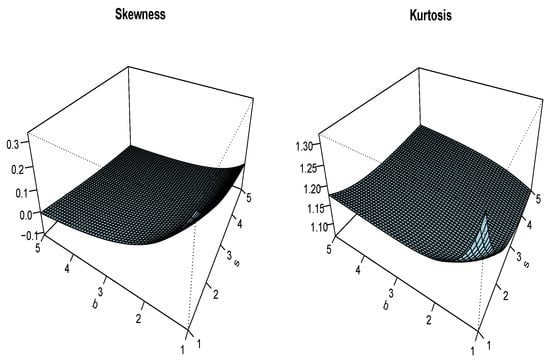
Figure 4.
Plots of the Bowley skewness and Moors kurtosis of the UG/G distribution for and .
3.4. Reliability Coefficient
The strength loss and system collapse strategies are prevalent in many physical systems. It is vital to consider valuable measures of reliability when evaluating them. This is especially true when a component of a system is subjected to random stress and random strength. The chance that stress surpasses strength is critical. In this scenario, we can describe the stress with a random variable and the stress with a random variable . Then, can be used to calculate the chances that the stress surpasses the strength. Further modeling and detail on this coefficient can be found in [18]. In the following result, we determine in a special distributional configuration involving the UG/G distribution.
Theorem 1.
Let and be two independent random variables with the UG/G distribution with parameters and , respectively. Then, we have
Proof.
The proof is primarily mathematical; we have
The right result is accomplished. □
The analysis of the stress-strength UG/G model is possible using Theorem 1. Thanks to the simple form of , which only depends on and , the substitution approach can be used to estimate it. It is worth noting that, when and are identically distributed, we get , which is the expected value, whatever the assumptions made on the common distribution.
4. Estimation with Simulation
A parameter estimation strategy is now being developed for the proposed unit distribution.
4.1. Estimation
Let be n positive values that are expected to be observed from a random variable with the UG/G distribution in which the parameters b, s, and are supposed to be unknown. In particular, by nature, we have for any . Then, the log-likelihood function related to b, s and is defined by
The maximum likelihood estimates (MLEs) of b, s, and depending only on , can be defined as , , and , where . The maximization is taken over the possible values of the parameters. These MLEs also satisfy the following partial derivative equations: , , and , where
and
Due to the complexity of these partial derivatives, there are few opportunities to find closed-form expressions for , , and . To discover accurate numerical solutions, numerical approaches such as the (quasi) Newton–Raphson method can be utilized.
Using , , and , we can estimate the pdf of the UG/G distribution by the substitution method; we can consider as a pertinent functional estimate of . The same method can be applied to estimate the cdf, hrf, and so on.
The theory underlying the MLEs is well-known and can be applied in the setting of the UG/G distribution without any problem. In particular, the asymptotic distribution of the random version of can be identified by a three-dimensional normal distribution with the mean and matrix of covariance: , where denotes the following symmetric matrix:
The components in can be found in the Appendix A. The matrix can be numerically calculated using mathematical tools. Based on the obtained three-dimentional normal distribution, we can define approximate confidence intervals (CIs) for b, s, and at a given level, say with . The formulas for the related lower bounds (CI-Ls) and upper bounds (CI-Us) of such intervals remain conventional; if we focus on the unknown parameter , these bounds are given by CI-L and CI-U , where is defined by , where Z denotes a random variable with the standard normal distribution, and refers to the standard error (SE) of , defined by the square root of the element of the diagonal of the matrix of covariance located at the same position of in the unknown vector . The technical developments behind the MLEs can be found in [19].
4.2. Simulation
In the sequel, we illustrate and provide simulation results to evaluate the behavior of the obtained MLEs. In this case, we use the R software developed by [20]. The following process is considered:
- We generate 5000 random samples of the form from the UG/G distribution, where, using Equation (6), is calculated by the following formula:where denotes a sample of values generated from the uniform distribution over .
- Different sample sizes are considered as , 200, 300, and 1000.
- Five different configurations for the vector of parameters are chosen as Config1: , Config2: , Config3: , Config4: , and Config5: .
- The average MLEs, mean square errors (MSEs), CI-Ls, CI-Us, and lengths (LENs) of the CIs with two different levels (90% and 95%) for the considered configurations are calculated.
- The obtained results are mentioned in Table 2, Table 3, Table 4, Table 5 and Table 6, for Config1, Config2, Config3, Config4, and Config5, respectively.
Table 2. Numerical values of the MLEs, MSEs, CI-Ls, CI-Us, and LENs for the parameters of the UG/G model for Config1.
Table 3. Numerical values of the MLEs, MSEs, CI-Ls, CI-Us, and LENs for the parameters of the UG/G model for Config2.
Table 4. Numerical values of the MLEs, MSEs, CI-Ls, CI-Us, and LENs for the parameters of the UG/G model for Config3.
Table 5. Numerical values of the MLEs, MSEs, CI-Ls, CI-Us, and LENs for the parameters of the UG/G model for Config4.
Table 6. Numerical values of the MLEs, MSEs, CI-Ls, CI-Us, and LENs for the parameters of the UG/G model for Config5.
We can see from these tables that, when n increases, the values of MLEs are close to the values of the parameters specified in the configurations. Moreover, when n increases, the values of the MSEs and LENs decrease as expected.
5. Applications
In this section, we use two real data sets to demonstrate the accuracy of the UG/G model. In the first example, we look at trade share data, and in the second, we look at flood level data.
5.1. Application 1
The first data set, named as the trade share data set, considers the values of the variable trade share involved in the famous “Determinants of Economic Growth Data". The growth rates of up to 61 countries, along with variables that are potentially related to growth, are taken. The data are freely available as an online complement to [21]. Numerically, the following values constitute the trade share data set: 0.140501976, 0.156622976, 0.157703221, 0.160405084, 0.160815045, 0.22145839, 0.299405932, 0.31307286, 0.324612707, 0.324745566, 0.329479247, 0.330021679, 0.337879002, 0.339706242, 0.352317631, 0.358856708, 0.393250912, 0.41760394, 0.425837249, 0.43557933, 0.442142904, 0.444374621, 0.450546652, 0.4557693, 0.46834656, 0.473254889, 0.484600782, 0.488949597, 0.509590268, 0.517664552, 0.527773321, 0.534684658, 0.543337107, 0.544243515, 0.550812602, 0.552722335, 0.56064254, 0.56074965, 0.567130983, 0.575274825, 0.582814276, 0.603035331, 0.605031252, 0.613616884, 0.626079738, 0.639484167, 0.646913528, 0.651203632, 0.681555152, 0.699432909, 0.704819918, 0.729232311, 0.742971599, 0.745497823, 0.779847085, 0.798375845, 0.814710021, 0.822956383, 0.830238342, 0.834204197, and 0.979355395.
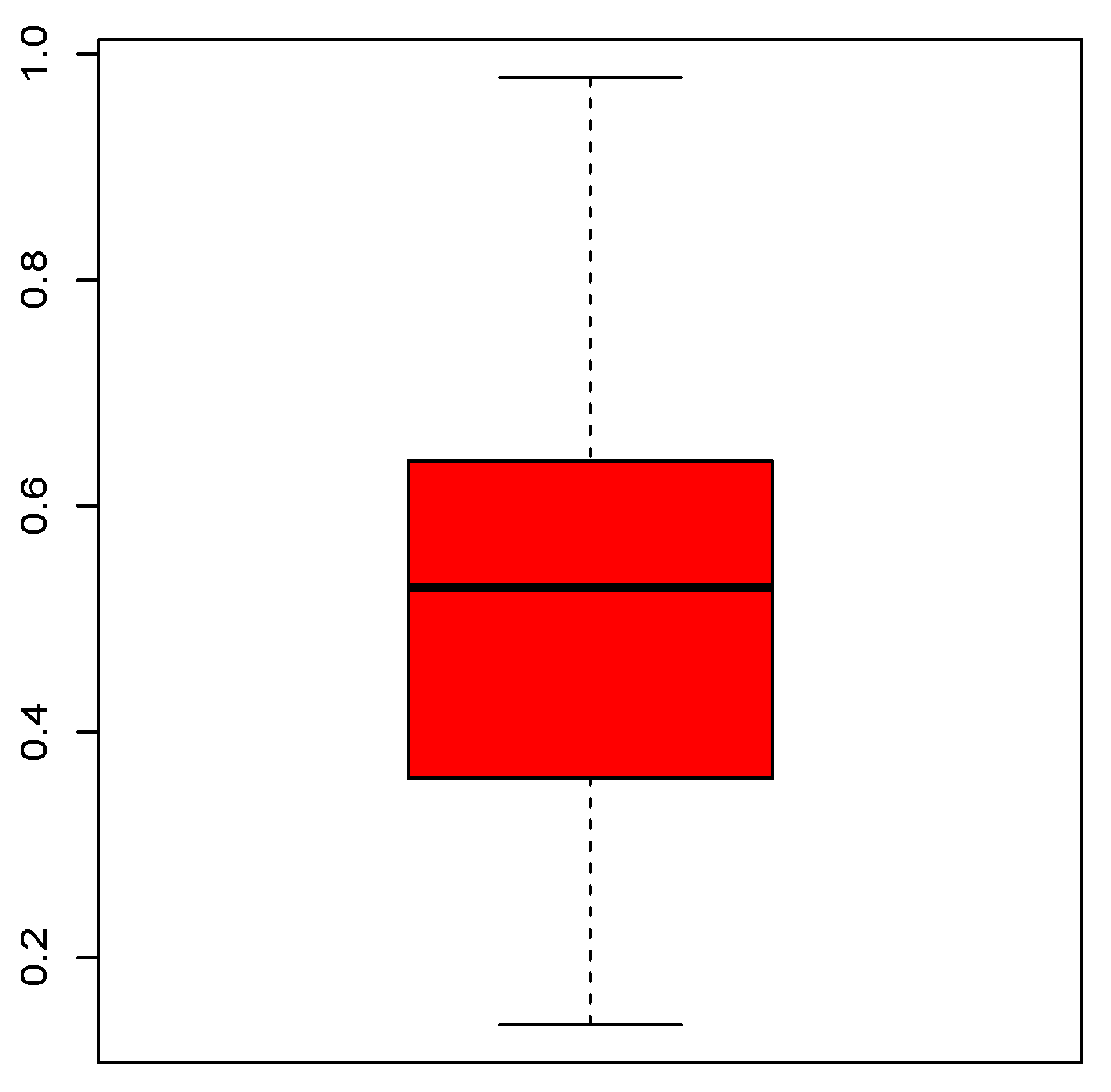
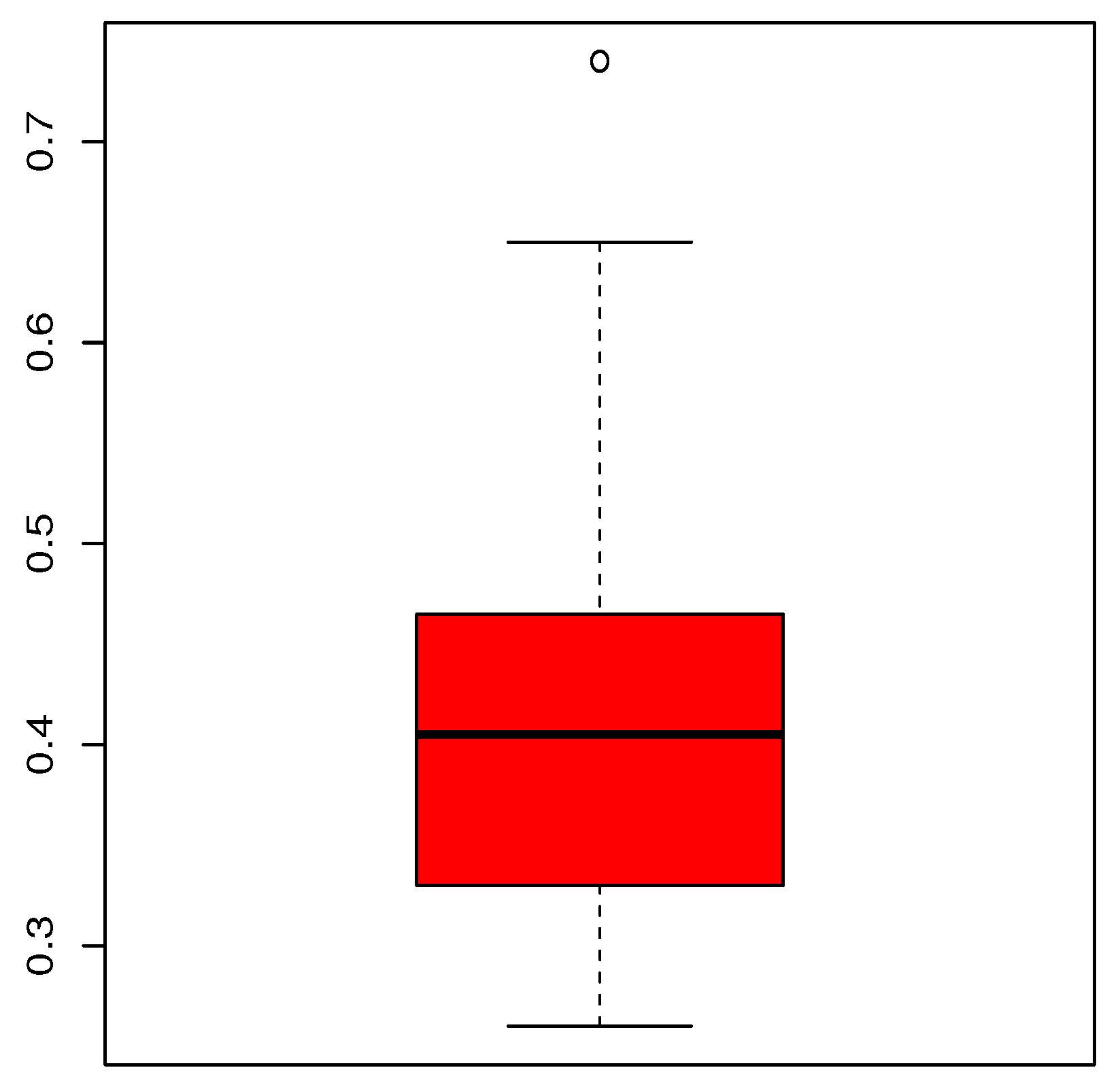
Figure 5 shows the quantile characteristics of the trade share data set via a boxplot.
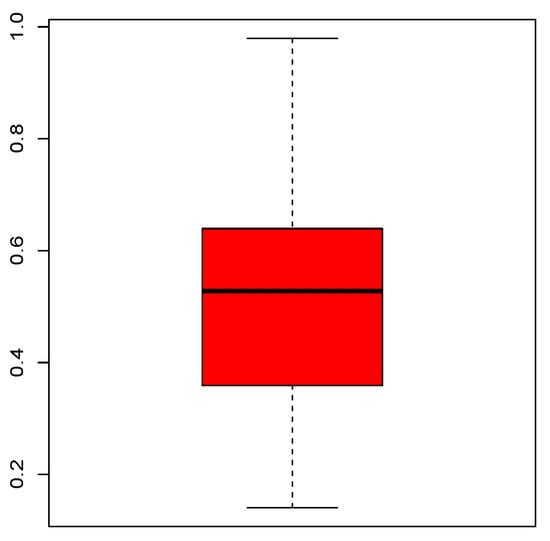
Figure 5.
Boxplot for the trade share data set.
From Figure 5, we see that the data are rather right-skewed and almost symmetrical. There is no atypical value. Table 7 completes this basic analysis by showing the statistical summary.
Table 7.
Statistical summary for the trade share data set.
From Table 7, we can say that the trade share data are right-skewed and platykurtic or near platykurtic with a moderate standard deviation.
As a main statistical work, we analyze this data set via a fitting approach. In this regard, we compare the fit of the proposed UG/G model and those of the Kumaraswamy (Kw), beta (Beta), UR (recalling that it refers to the unit Rayleigh distribution by [10]), Topp-Leone (Topp), power (Power), and Transmuted (TM) models. These competitive models are defined by specific cdfs, which are recalled below.
- Kw distribution:for , and for , with .
- Beta distribution:with , for , and for , with .
- UR distribution:for , and for , with .
- Topp distribution:for , and for , with .
- Power distribution:for , and for , with .
- TM distribution:for , and for , with .
Table 8 shows the MLEs of the model parameters, together with their SEs.
Table 8.
Estimates (MLEs and SEs under parentheses) associated to the model parameters for the trade share data set.
In order to compare fitted models, we employ the classic AIC, W, A, KS, KS (p-value) measures, which correspond to the Akaike, Anderson-Darling, Kolmogorov–Smirnov measures, with the p-value relating to the Kolmogorov–Smirnov test, respectively. Table 9 contains their values for the trade share data set and the considered models.
Table 9.
AIC, W, A, KS, and KS (p-value) values for the trade share data set.
According to Table 9, the UG/G model has the smallest values for the AIC, W, A, KS measures, and the largest value for the KS (p-value), which is equal to , so nearly equal to 1. As a result of these criteria and the trade share data set, we can declare that it is the best fit among the models studied.
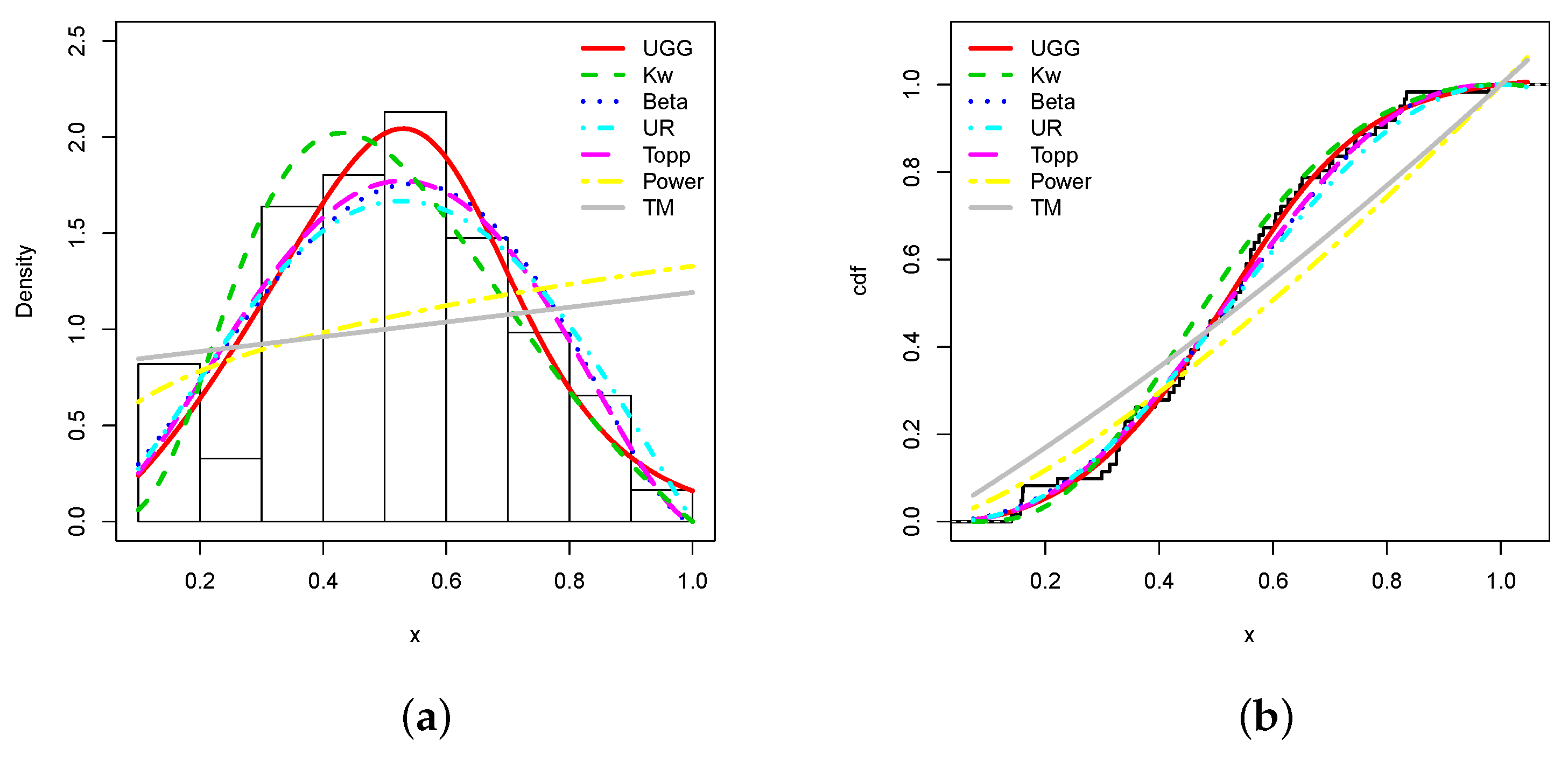
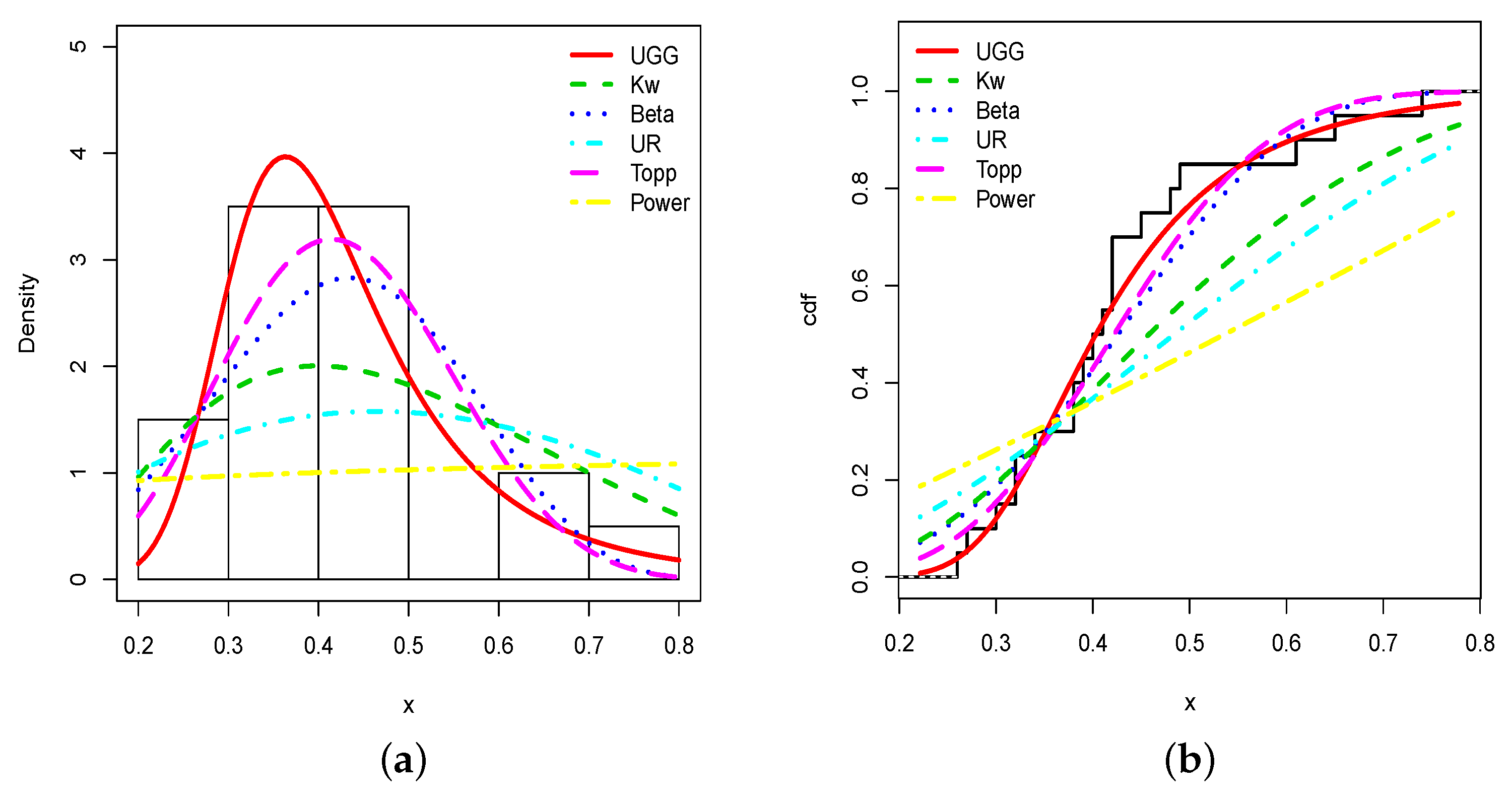
This superiority in fitting is visualized in Figure 6.
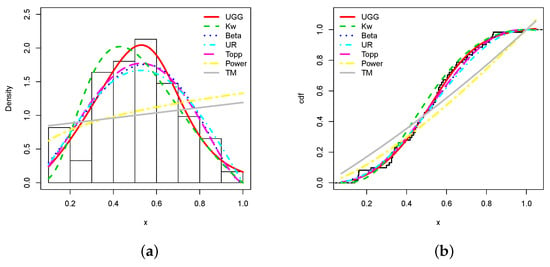
Figure 6.
Plots of the (a) estimated pdfs and (b) estimated cdfs of the considered models and the trade share data set.
From Figure 6, we see that the fits of the estimated pdf and cdf of the UG/G model are the best. In particular, the estimated pdf shapes the global form of the histogram well. Furthermore, the top of the histogram has been captured well. The estimated UG/G model contains most of the information underlying the data.
5.2. Application 2
The second data set is extracted from [22] and refers to 20 observations of the Susquehanna River’s maximum flood level located at Harrisburg, Pennsylvania. The unit is a million cubic feet per second. The precise values are: 0.26, 0.27, 0.30, 0.32, 0.32, 0.34, 0.38, 0.38, 0.39, 0.40, 0.41, 0.42, 0.42, 0.42, 0.45, 0.48, 0.49, 0.61, 0.65, and 0.74.
These data are analyzed using the same methodology as in the previous application. To begin, Figure 7 depicts the elementary statistical properties of the flood level data set using a boxplot.
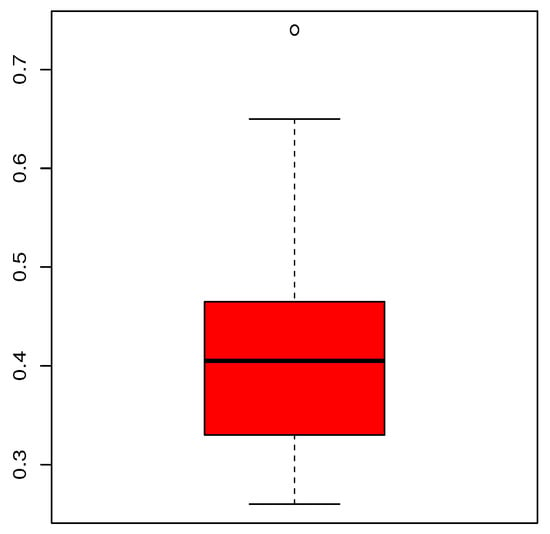
Figure 7.
Boxplot for the flood level data set.
From Figure 7, we see that the data are rather right-skewed. One atypical value is identified; it is , but its presence in the data set remains justified in practice. The statistical summary for the flood level data set is shown in Table 10.
Table 10.
Statistical summary for the flood level data set.
The parameter estimates, as well as their related SEs, are shown in Table 11.
Table 11.
Estimates (MLEs and SEs under parentheses) associated to the model parameters for the flood level data set.
Table 12 shows the values for the AIC, W, A, KS, and KS (p-value) of the flood level data set and the considered models.
Table 12.
AIC, W, A, KS, and KS (p-value) values for the flood level data set.
According to Table 12, the UG/G model has the smallest values for the AIC, W, A, and KS measures and the largest value for the KS (p-value), which is equal to . As a result of these facts, we may conclude that it has the best fit of all the models studied. It is worth mentioning that the TM model was left out of the competition due to its poor fit.
This superiority in fitting is visualized in Figure 6.
The estimated pdf and cdf fits of the UG/G model are the best, as shown in Figure 8. The estimated pdf, in particular, determines the overall shape of the histogram, as well as a nice capture of the top of the histogram and its right skewed portion.
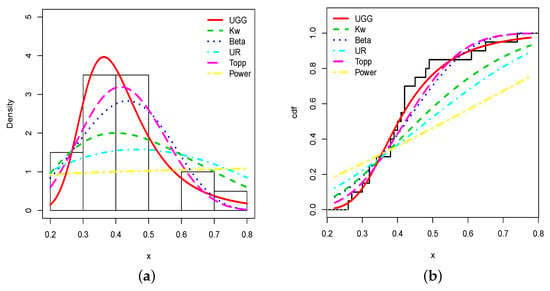
Figure 8.
Plots of the (a) estimated pdfs and (b) estimated cdfs of the considered models and the flood level data set.
5.3. Complementary Analysis
Here, we provide some complementary analysis to the trade share and flood level data sets via the UG/G model. To begin, Table 13 gives the estimated values for the unknown parameters , , S, and K of the UG/G distribution.
Table 13.
Estimates moment measures for the two data sets.
If we compare Table 7, Table 10 and Table 13, we see very similar results, confirming that the UG/G model can efficiently estimate these moment measures.
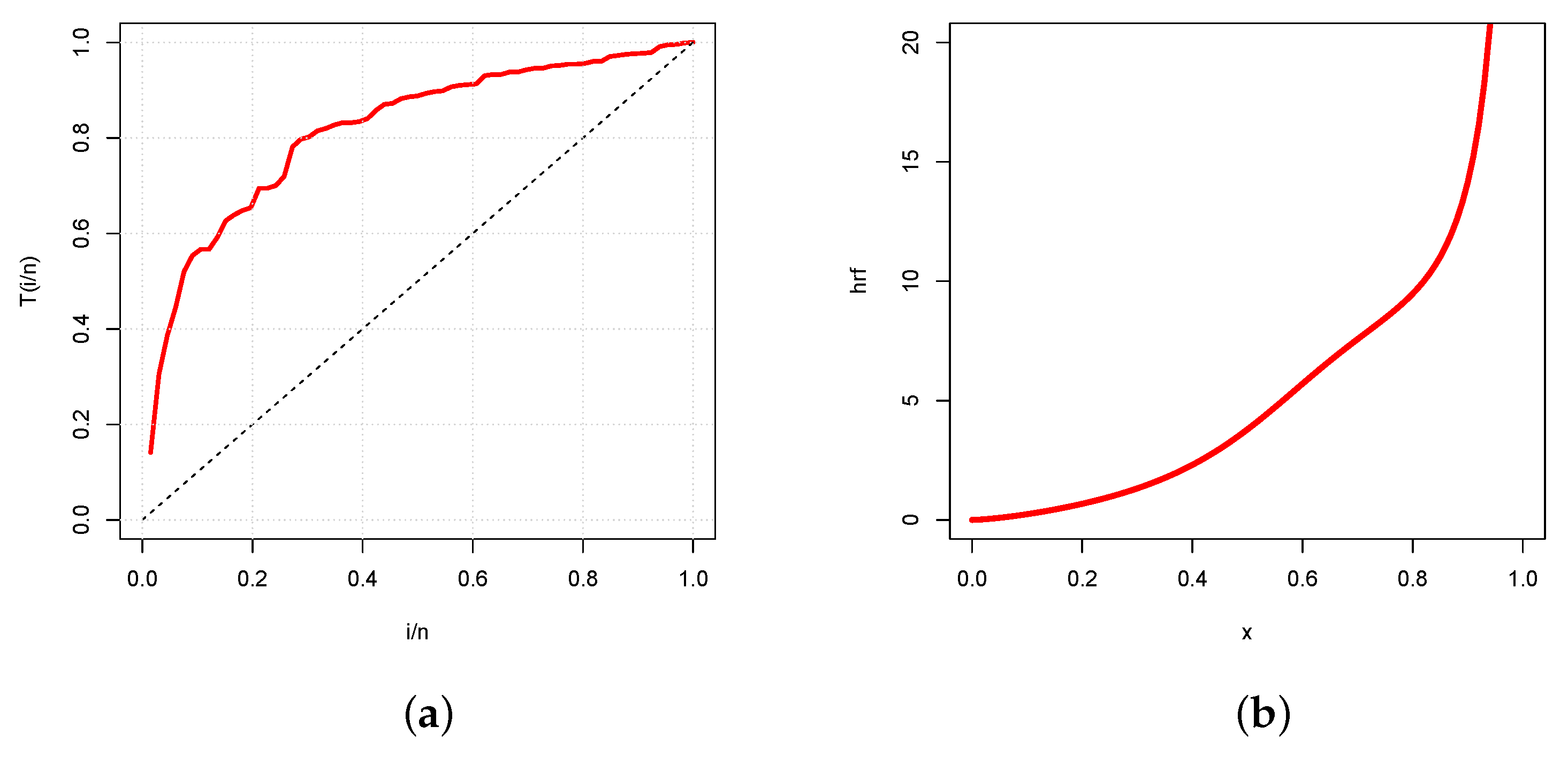
Now, we are conducting an hrf analysis. The total time test (TTT) plot is a useful graphical tool for determining whether or not data may be applied to a certain distribution through the underlying hrf. It has been elaborated by [23]. Figure 9 presents the TTT plot and the estimated hrf of the UG/G model.
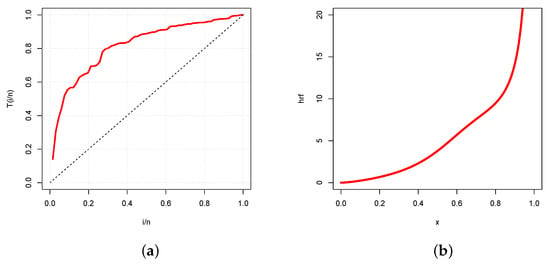
Figure 9.
Plots of the (a) TTT plot and (b) estimated hrf of the UG/G model for the trade share data set.
In Figure 9a, the TTT plot indicates an increasing hrf, which is immediately confirmed in Figure 9b by the plot of the estimated hrf of the UG/G model.
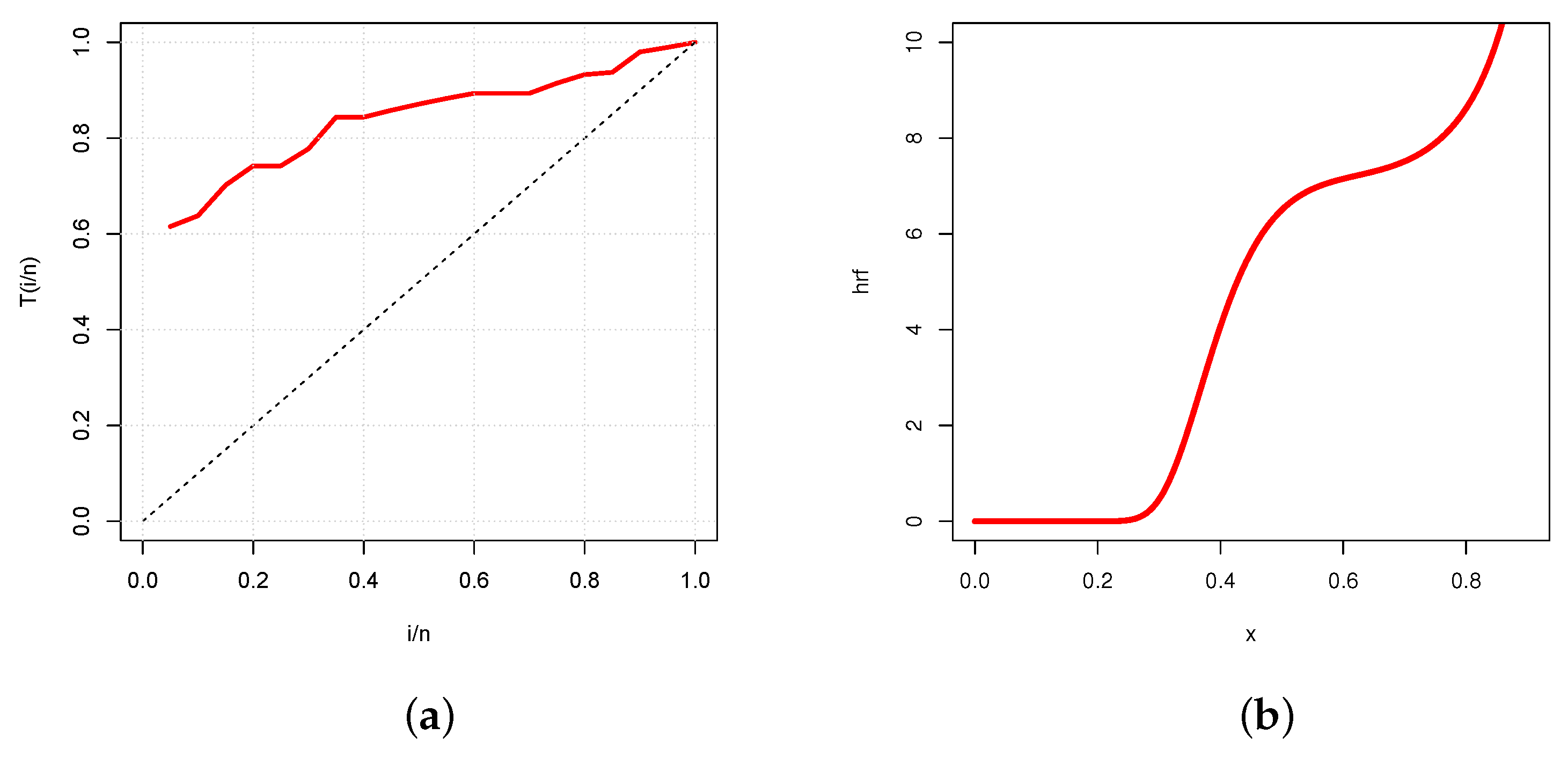
Again, the TTT plot in Figure 10a reveals an increasing hrf with diverse convex properties, which is immediately corroborated in Figure 10b by the plot of the estimated hrf of the UG/G model.
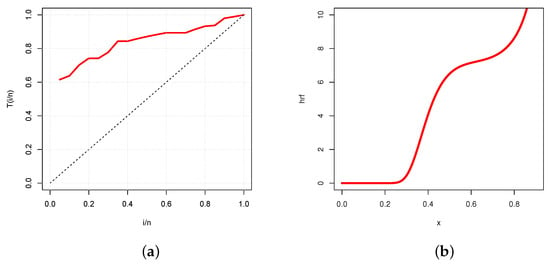
Figure 10.
Plots of the (a) TTT plot and (b) estimated hrf of the UG/G model for the flood level data set.
This new study verifies the use of the UG/G model in the analysis of the data sets in question.
6. Conclusions
This work has provided a new option for unit distribution based on the inverse-exponential scheme and the gamma/Gompertz distribution. The basic aim was to translate the relevant flexibility of the gamma/Gompertz distribution to the unit interval. The unit gamma/Gompertz distribution is thus created. It can also be viewed as a natural extension of the power distribution, and the unit version of the Marshall–Olkin extended power distribution. As the main motivation, the proposed distribution has numerous advantages over referenced unit distributions in terms of flexibility and modeling capacities. Among them, its probability density function is shown to be increasing, decreasing, “increasing-decreasing”, and “decreasing-increasing” with a tuning asymmetry, and the hazard rate function has a monotonically increasing, decreasing, or constant form. Significant stochastic ordering, moments, and quantiles results have been demonstrated. In addition, a part has been devoted to the reliability coefficient with discussion on its inferential aspect. The new strategy is also applied practically with the development of the maximum likelihood method and two applications employing real data sets. The obtained results highlight the importance of the novel model. Future research in this direction will include, among other things, the development of quantile regression models and the construction of various dependence structures based on copulas.
Author Contributions
Methodology, R.A.R.B., F.J., C.C. and M.E. All authors have read and agreed to the published version of the manuscript.
Funding
This work was funded by the Deanship of Scientific Research (DSR), King AbdulAziz University, Jeddah, under grant No. (D-332-150-1442).
Institutional Review Board Statement
Not applicable.
Informed Consent Statement
Not applicable.
Data Availability Statement
The datasets used in this paper are provided within the main body of the manuscript.
Acknowledgments
We would like to thank the two reviewers for their time and effort in assisting us in improving our manuscript. In addition, the authors gratefully acknowledge the DSR technical and financial support.
Conflicts of Interest
The authors declare no conflict of interest.
References
- Aitchison, J. The statistical analysis of compositional data. J. R. Stat. Soc. Ser. B (Methodol.) 1982, 44, 139–177. [Google Scholar] [CrossRef]
- Consul, P.C.; Jain, G.C. On the log-gamma distribution and its properties. Stat. Pap. 1971, 12, 100–106. [Google Scholar] [CrossRef]
- Gómez-Déniz, E.; Sordo, M.A.; Calderín-Ojeda, E. The log-Lindley distribution as an alternative to the beta regression model with applications in insurance. Insur. Math. Econ. 2014, 54, 49–57. [Google Scholar] [CrossRef]
- Mazucheli, J.; Menezes, A.F.B.; Ghitany, M.E. The unit-Weibull distribution and associated inference. J. Appl. Probab. Stat. 2018, 13, 1–22. [Google Scholar]
- Mazucheli, J.; Menezes, A.F.B.; Fernandes, L.B.; De Oliveira, R.P.; Ghitany, M.E. The unit-Weibull distribution as an alternative to the Kumaraswamy distribution for the modeling of quantiles conditional on covariates. J. Appl. Stat. 2020, 47, 954–974. [Google Scholar] [CrossRef]
- Mazucheli, J.; Menezes, A.F.B.; Dey, S. Unit-Gompertz Distrib. Applications. Statistica 2019, 79, 25–43. [Google Scholar]
- Korkmaz, M.Ç.; Chesneau, C. On the unit Burr-XII distribution with the quantile regression modeling and applications. Comput. Appl. Math. 2021, 40, 29. [Google Scholar] [CrossRef]
- Altun, E. The log-weighted exponential regression model: Alternative to the beta regression model. Commun. Stat.-Theory Methods 2021, 50, 2306–2321. [Google Scholar] [CrossRef]
- Altun, E.; Hamedani, G.G. The log-xgamma distribution with inference and application. J. De La Société Française De Stat. 2018, 159, 40–55. [Google Scholar]
- Bantan, R.A.R.; Chesneau, C.; Jamal, F.; Elgarhy, M.; Tahir, M.H.; Aqib, A.; Zubair, M.; Anam, S. Some new facts about the unit-Rayleigh distribution with applications. Mathematics 2020, 8, 1954. [Google Scholar] [CrossRef]
- Bemmaor, A.C.; Glady, N. Modeling purchasing behavior with sudden “death”: A flexible customer lifetime model. Manag. Sci. 2012, 58, 1012–1021. [Google Scholar] [CrossRef]
- Afshar-Nadjafi, B. An iterated local search algorithm for estimating the parameters of the gamma/Gompertz distribution. Model. Simul. Eng. 2014, 2014, 629693. [Google Scholar] [CrossRef] [Green Version]
- Okagbue, H.I.; Adamu, M.O.; Owoloko, E.A.; Opanuga, A.A. Classes of ordinary differential equations obtained for the probability functions of Gompertz and gamma Gompertz distributions. In Proceedings of the World Congress on Engineering and Computer Science 2017, San Francisco, CA, USA, 25–27 October 2017; pp. 405–411. [Google Scholar]
- AzZwideen, R.; Al-Zou’bi, L.M. The transmuted gamma-Gompertz distribution. Int. J. Res.-Granthaalayah 2020, 8, 236–248. [Google Scholar] [CrossRef]
- Okorie, I.E.; AKpanta, A.C.; Ohakwe, J. Marshall-Olkin extended power function distribution. Eur. J. Stat. Probab. 2017, 5, 16–29. [Google Scholar]
- Shaked, M.; Shanthikumar, J.G. Stochastic Orders; Wiley: New York, NY, USA, 2007. [Google Scholar]
- Gilchrist, W. Statistical Modelling with Quantile Functions; CRC Press: Abingdon, UK, 2000. [Google Scholar]
- Kotz, S.; Lumelskii, Y.; Pensky, M. The Stress-Strength Model and Its Generalizations: Theory and Applications; World Scientific: Singapore, 2003. [Google Scholar]
- Casella, G.; Berger, R.L. Statistical Inference; Brooks/Cole Publishing Company: Bel Air, CA, USA, 1990. [Google Scholar]
- R Core Team. R: A Language and Environment for Statistical Computing; R Foundation for Statistical Computing: Vienna, Austria, 2013; Available online: http://www.R-project.org/ (accessed on 20 February 2021).
- Stock, J.H.; Watson, M.W. Introduction to Econometrics, 2nd ed.; Addison Wesley: Boston, MA, USA, 2007; Available online: https://rdrr.io/cran/AER/man/GrowthSW.html (accessed on 20 June 2020).
- Dumonceaux, R.; Antle, C.E. Discrimination between the Log-Normal and the Weibull distributions. Technometrics 1973, 15, 923–926. [Google Scholar] [CrossRef]
- Aarset, M.V. How to identify bathtub hazard rate. IEEE Trans. Reliab. 1987, 36, 106–108. [Google Scholar] [CrossRef]
Publisher’s Note: MDPI stays neutral with regard to jurisdictional claims in published maps and institutional affiliations. |
© 2021 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).