1. Introduction
As the size and complexity of industrial systems increases, there is a need to accurately measure most process variables. Unfortunately, not all variables can be accurately measured using online hard sensors. For certain variables, such as concentration or density, the only accurate measurements can be obtained by manually taking samples and analyzing them in a laboratory. One solution to this problem is the development of soft sensors, which take the easy-to-measure variables and create models to predict the hard-to-measure variables [
1].
All soft sensor systems consist of a process model that takes the easy-to-measure variables and provides an estimate of the hard-to-measure variables. These models can be constructed using methods ranging from linear regression to principal component analysis and support vector machines. Although the main focus has been on the development of the soft sensor models [
2,
3,
4,
5], advanced soft sensor systems have also a bias update term that can take any slowly sampled information to update the soft sensor prediction [
1]. This bias update term is normally designed as some function of the difference between the predicted and measured values [
6]. Of note, it should be mentioned that the measured values are often sampled very slowly and with considerable time delay. This means that during the points at which there are no updates, the previously available bias value is used. When such a system is properly designed, it can provide good tracking of the process, i.e., the predicted and measured values are close to each other.
Recently, it has been suggested that instead of only using the available slowly sampled data for updating the bias term, it should be possible to also model the historical errors and use them to predict the future errors [
7]. It has been shown that such an approach can improve the overall performance of the soft sensor system. However, there still remain issues with how best to model and implement this predictive bias update term. Furthermore, there are issues with incorporating time delays into this approach since they will greatly increase the size of the required search space.
Therefore, this paper will examine the development of a predictive bias update term for a nonlinear system using dimension reduction. The proposed approach will be tested using data from an industrial reactive distillation column that produces methyl tert-butyl ether (MTBE).
2. Background
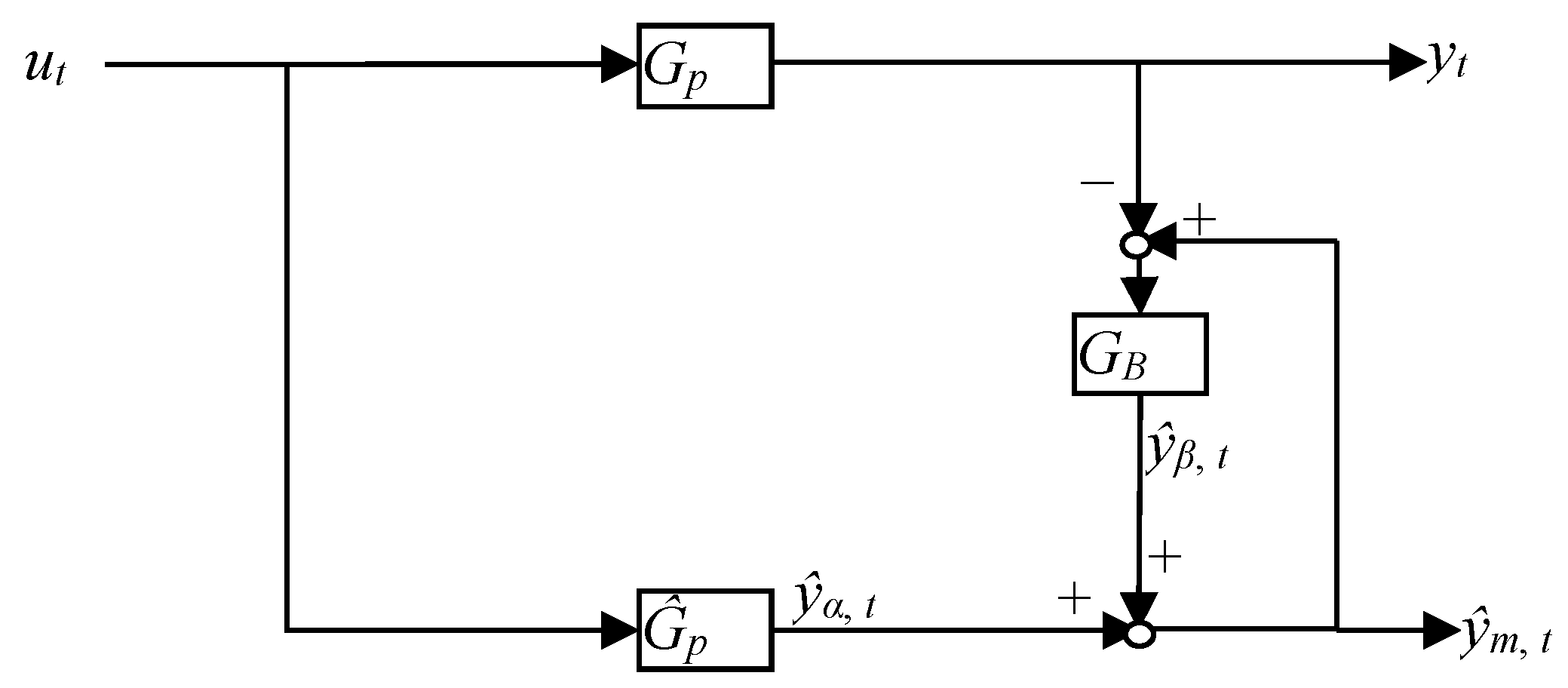
Consider the soft sensor system shown in
Figure 1, where
ut is the input,
yt is the measured (true) output,
the predicted soft sensor value,
and
are intermediate soft sensor values,
Gp is the true process,
is the soft sensor process model, and
GB is the bias update term. It can be noted that purpose of the bias update term is to take the information from the measured values and correct the output of the soft sensor system. This comes primarily from the unknown disturbances and the inherent plant-model mismatch.
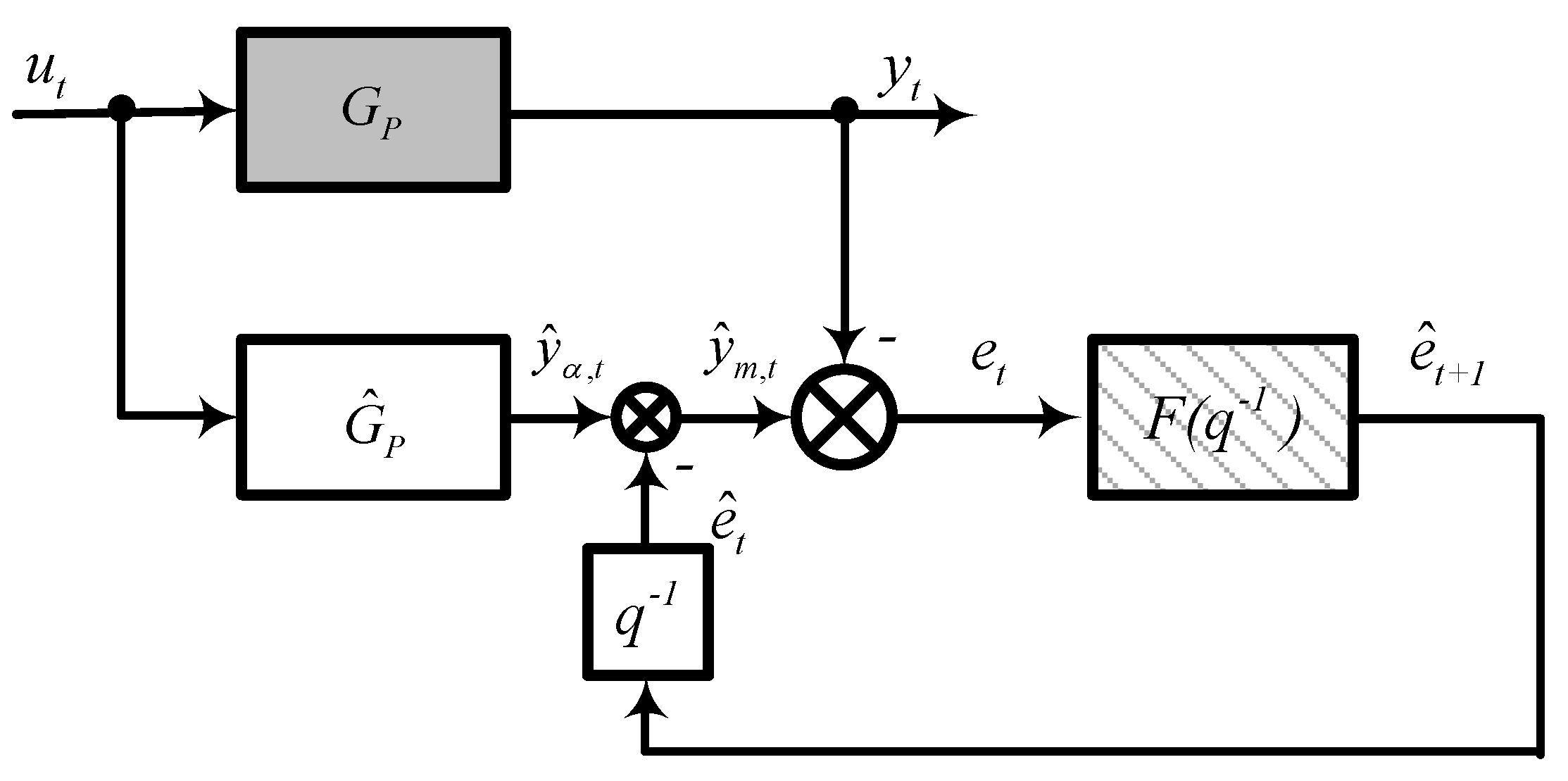
Another approach to this problem is to re-arrange the bias update term so that it contains a predictive model that can predict the errors between the measured and predicted values. This re-arrangement is shown in
Figure 2, where the predicted value from the soft sensor is corrected based on the modeled errors of the system. The question becomes how to design this model so that the best predictions can be obtained.
For prediction of time series, the Box-Jenkins methodology is traditionally used, according to which the time series model is found in the class of autoregressive-moving average (ARMA) models, i.e., is considered a rational algebraic function of the backward shift operator. The flexibility of the ARMA class makes it possible to find parsimonious models, i.e., the adequacy of the evaluated model is achieved with a small number of estimated parameters. Since this property is especially important for empirical models, the Box-Jenkins methodology is widely used to solve various practical problems. This approach is adopted in this paper.
In industrial processes, where it is desired to implement the model on programmable logic control (PLC) units, the complexity of the model
can be an issue. Therefore, this paper will consider a simple model for
of the form
where
b are the parameters to be estimated and
xt is the input(s). Model (1) can be improved by taking into account possible delays of the output variables relative to inputs. Consider the following model for a multi-output soft sensor
where
t = 1, 2, …,
n;
m = 1, 2, 3 (the number of outputs
m is given by the industrial production team and reflecting the key quality indices of MTBE product). Vector
bm = (
bm, 1,
bm, 2, …,
bm, 10) is a row vector of unknown coefficients;
τm = (
τm, 1,
τm, 2, …,
τm, 10) is a row vector of unknown time delays;
um (
t,
τm) = (
ut, m, 1,
ut, m, 2, …,
ut, m, 10)
T;
ut, m, k is the measurement of the
xk value at time
t −
τm, k with
k = 1, 2, …, 10. Please note that it has been assumed here that the maximal time delay is 10 samples and justified from the industrial process dynamics point of view. However, it can easily be extended to arbitrary values.
Solving model (2) by minimizing the mean squared error (MSE) gives an estimate for the unknown parameters
and
. The MSE depends not only on the coefficients
bm, but also on the delays
τm, i.e.,
Please note that if
, than
Furthermore, the estimates
are found using standard regression analysis which gives
where
Ym is the
m-th column of the matrix
Y;
Um is a matrix with dimension
n × 10, whose
t-th row is the row
um (
t, τ
m)
T.
Since all variables are measured at discrete moments in time, the gradient descent methods cannot be directly applied to minimize the objective function for the argument τm. However, this difficulty can be avoided by calculating Dem for any values of the elements of the vector τm by interpolating between the nearby nodes of the discrete grid. Interpolation with a large search space dimension is a difficult problem. Among the various characteristics of the algorithms used, such properties as visibility and relative simplicity come to the fore. Therefore, in this situation, the most preferable is the polynomial interpolation.
2.1. Error Modeling
If the
et, m error were known at time
t − 1, then using Equation (2), it would be possible to predict the
yt, m variable with absolute accuracy. Unfortunately, the
et, m error is not known in advance, but it can be predicted using any statistical patterns found in the sequence
e1, m,
e2, m, …. This error prediction can be used as a correction to model (2) as shown in
Figure 2, therefore improving the prediction accuracy of the
yt,m output variable. To evaluate a predictive model for the sequence
e1, m,
e2, m …, let us consider the class of ARMA models. Let us introduce the predicted process as the output of an invertible linear filter, called a shaping filter, driven by white noise, i.e., a process with a constant spectral density. In this case, the transfer function of the shaping filter is considered a rational algebraic function of the backward shift operator, i.e.,
where
εt and
et are values of the input and output processes of the shaping filter at time
t;
Nn is the order of the moving average;
Nd is the order of the autoregressive component;
Hl,
Gk are constants (generally speaking, complex-valued); and
is the backshift operator. The stationarity and invertibility conditions, which are necessary to predict the
et process, are [
8]
The flexibility of the ARMA class provides the possibility of finding parsimonious models, i.e., the adequacy of the constructed model is achieved with a relatively small number of estimated parameters. Since this property is especially important for empirical models, the models with the structure given in Equation (7) and their variants are widely used for solving practical problems.
The filter for predicting the
et process can be found using the prediction error method (PEM) [
9]. Expanding the brackets in Equation (7) gives
where
θl and
ηk are the model parameters. It is assumed that the polynomials in the numerator and denominator have no common roots, since otherwise it would be possible to reduce the common multipliers in the numerator and denominator of Equation (7).
The PEM function finds the parameter values that minimize the predictive MSE of the
et process for given polynomial orders (
Nn,
Nd) and the initial estimates of the parameters
θl and
ηk. It is possible to choose suitable orders of the polynomials based on sample estimations of the spectral density of the considered process. Recall that the frequency response of the shaping filter is the value of Equation (7) on a circle of unit radius centered on the origin and the spectral density
S(
ω) of the output process
et is equal to the product of the variance of the input process and the square of the frequency response modulus, i.e., [
10]
where
is the variance of random process
εt and
Hl and
Gk are the complex conjugates of the constants
Hl and
Gk. Furthermore, since we desire that our filter be invertible, it follows that for the model
the
et process is invertible if the absolute values of all the
Hl constants are less than one. Similarly, if the absolute values of all the
Gk constants is less than one, then the
et process is stationary [
8]. Thus, although multiple processes can have the same spectral density, there is only one that is both stationary and invertible.
Once the general model has been obtained, we can rewrite it as an infinite impulse response model, i.e.,
where
ψ is an impulse response coefficient. Since we know that the general model converges [
8], it follows that we only need a finite number of terms in Equation (12). Furthermore, we note that
which implies that for any positive
i the random variables
εt and
et−i are uncorrelated (since the process
εt is white noise). Therefore, successively multiplying both sides of Equation (12) by the values of the corresponding process at delays
i and taking expectations, we obtain equations for finding the initial estimates of the parameters that involve the covariances of the errors for different lags [
10]. Obviously, since the true covariances are not known, they will need to be replaced by the sample estimates. This method of estimating the coefficients does not lead to too large error as long as the absolute values of the parameters of model (7) are not too close to the boundary of unit circle centered on the origin. Thus, it is possible to design the required filter.
2.2. Filter Design
Let
et = (
et, 1,
et, 2, …,
et, N)
T be an
N-dimensional stationary process of the soft sensor’s errors whose shaping filter transfer matrix is
F0(
q−1), i.e
.,
where
q−1 is the backshift operator;
εt = (
εt, 1,
εt, 2, …,
εt, N)
T is an
N-dimensional vector of white noise; and
F0(
q−1) = [
fkm(
q−1)] is an
N N matrix function, whose entries denoted as
fkm(
q−1) are the rational transfer function from
εt,m to
et, k. Thus, it is desired to construct the filter that will predict
et+1 given the past values.
Let
P(
q−1) be the desired one-step ahead predictor transfer matrix,
=
P(
q−1)
et the prediction of the vector
et+1 at time
t, and
=
et+1 − the error of the prediction obtained with the aid of the filter
P(
q−1). Then
where
IN is identity matrix of order
N. Consequently, the filter in the square brackets transforms the initial series into the prediction error series. If the random vector
includes components correlated with those of the vector
at some
j > 0, we can predict the errors
using the known previous errors. Using those predictions as corrections to the
that were obtained, we could improve the accuracy of the predictions. Hence, in order to maximize the predictor accuracy, we must find a
P(
q−1) such that the errors
are uncorrelated with the errors
at any
j > 0 with some nonzero correlation between the components of
(i.e., at
j = 0) being admissible. In other words, the time series
must be
N-dimensional white noise. Consequently,
IN −
q−1P(
q−1) =
F0−1(
q−1), from which it follows that
P(
q−1) =
q[
IN − F0−1(
q−1)].
Thus, the predictor transfer matrix
P(
q−1) can be expressed through the transfer matrix of the shaping filter
F0(
q−1). The matrix
F0(
q−1) can be found from
where
G(
q−1) = [
gkm(
q−1)],
gkm(
q−1) is the
q-transform of the statistical estimate of the cross-covariance function of the time series
et, k and
et, m (in particular, when
m =
k,
gmm is a
q-transform of the sample covariance function, i.e., the autocovariance generating function (AGF) of the time series
etm).
The algorithm for finding
F0(
q−1) is simplified by decomposing it into
N stages. At the
kth stage, a shaping filter
Fk(
q−1) of the
k-dimensional process (
et, 1,
et, 2, …,
et, k)
T is found. At this stage, the filter
Fk−1(
q−1), found at the (
k−1)th stage, is used in order to transform the matrix
Gk(
q−1) =
Fk(
q−1)
FkT(
q) so that its transform contains nonzero elements in only one line, one column, and on the main diagonal. This technique substantially simplifies the procedure of spectral factorization (finding the matrix function
Fk(
q−1)) [
11].
The proposed approach allows us to identify the vector time series transfer matrix without resorting to a complicated phase state representation. This advantage is used to obtain an adequate model with relatively few estimated parameters for the initial time series shaping filter F0(q−1). Simultaneously, the model for the transfer matrix of the inverse filter F0−1(q−1), which transforms the initial time series into the white noise, is also found.
The algorithm for constructing both the shaping filter
F0(
q−1) and its inverse
F0−1(
q−1) is described in [
11]. Based on this algorithm, the sequence of prediction errors
should be
N-dimensional white noise. However, since in practice, the true characteristics of the original process are not known, but only their estimates, containing inevitable statistical errors, in reality, the properties of the sequence
can be significantly different from the properties of white noise. Thus, to verify the optimality of the resulting model
P(
q−1) of the predictive filter, a criterion is needed to test the hypothesis that the process
is
N-dimensional white noise. To construct such a criterion, we can transform the process
in such a way that its spectral density matrix is diagonal. Such a transformation is achieved by means of a rotation of axes in the
N-dimensional variable space
[
12]. Since the variances of these variables can be made equal to each other by normalization, without loss of generality, we suppose that spectral density matrix of the noise
is an
N × N identity matrix
IN.
Consider a univariate sequence
ξk =
, where
k =
jN +
m. Please note that each pair couple (
j,
m) determines one
k and each
k determines one pair couple (
j,
m). Consequently,
is multivariate white noise if and only if
ξk is univariate white noise. It is known that the spectral density of univariate white noise is constant [
8,
13]. Thus, testing the hypothesis that
is multivariate white noise is reduced to testing the hypothesis on the constancy of the spectral density of a univariate sequence. This hypothesis can be tested using Kolmogorov’s criterion [
14].
Please note that only a time series containing prediction errors is used as the initial information for constructing a predictor with the proposed approach. Information about the model with which the predictions were obtained is not used. Therefore, this approach is applicable to any predictive model that involves errors, regardless of the specific properties of the model used.
2.3. Summary of the Proposed Approach
Thus, the proposed procedure for developing the model can be summarized as follows:
Step 1: Create an initial sample ut, yt, t = 1, 2, …, K. If the plant is already functioning then the initial sample consists of the historical values of ut, yt. Otherwise, the initial sample is forming during the trial period of the plant. The initial sample is divided into training and testing datasets.
Step 2: Based on the data included in the training sample, the coefficients and delays of the model given by Equation (2) are estimated via solving optimization problem (4).
Step 3: Based on the data included in the training sample, the errors for the model and the corresponding sample spectrum of errors are calculated.
Step 4: Based on the sample spectrum, the order of the ARMA model is selected in order to predict the unknown future error given the known current and past errors.
Step 5: The least squares method is used to find the values of the ARMA model parameters.
Step 6: The ARMA model obtained is used as the predictive filter
F(
q−1) in the feedback loop of the compensator (bias update term) as shown in
Figure 2.
Step 7: If the resulting soft sensor improves the accuracy of the prediction for the test sample then it can be recommended for practical use.
Please note that the obtained predictive filter model can be recommended for further use for the same plant on the data of which it was built. As for the approach, it will certainly be successful if the sequence of errors of the plant is a stationary (or close to it) process. In addition, the class of successful applicability of this approach can be extended to those plants, for whose errors it is possible to find an invertible transformation that brings the sequence of errors to a stationary process. The quality of the developed model should be checked on a test sample that was not used at the stage of the model training.
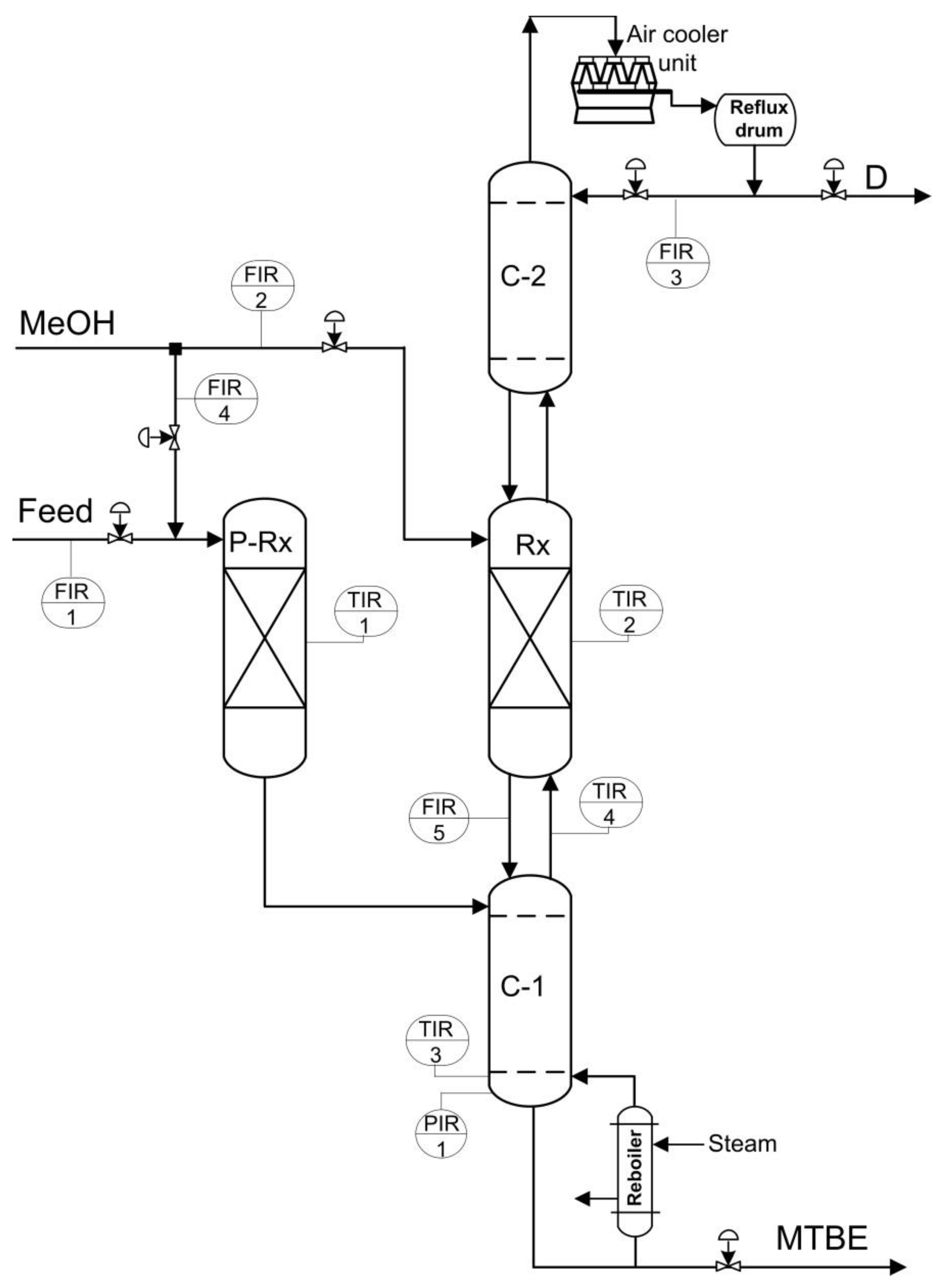
3. Industrial Application of the Proposed Method
Industrial methyl tert-butyl ether (MTBE) production occurs in a reactive distillation unit, as shown in
Figure 3. The feed containing isobutylene and methanol (MeOH) enters the column. The distillate (D) is a lean butane-butylene fraction with a certain amount of MeOH. The raffinate is the heavy product MTBE that is withdrawn from the bottom part of the column.
Table 1 shows the main process variables for the industrial unit. The goal is to develop a soft sensor for the prediction of the concentrations of methyl sec-butyl ether (MSBE), MeOH, and the sum of dimers and trimers of isobutylene (DIME) in the bottom product MTBE.
The measured values of output
ym and input
xk variables at the time moment
t are denoted as
ytm,
xtk;
m = 1, 2, 3;
k = 1, 2, …, 10; and
t = 1, 2, …,
n. The existing measurements may be used for development of a predictive model of the form
where
yt = (
yt, 1,
yt, 2,
yt, 3)
T;
xt = (
xt, 1,
xt, 2, …,
xt, 10)
T;
b is a matrix of the model parameters [
bmk] of dimension 3 × 10;
b0 = (
b1,
b2,
b3)
T is a vector of the constant biases;
et = (
et, 1,
et, 2,
et, 3)
T is a vector of the residuals, and the superscript
T denotes the transpose. Since Equation (17) can be rewritten as
where
,
, then expectations of all the elements of vectors
yt,
xt, and
et, as well as biases vector
b0, may be considered to be equal to zero without loss of generality.
Although the elements of matrix
b are unknown, they are easily estimated using the ordinary least squares (OLS) method, which gives [
10]
where
X = [
xtk];
Y = [
ytm];
m = 1, 2, 3;
k = 1, 2, …, 10; and
t = 1, 2, …,
n.
For the training sample containing
n = 400 measurements, the following estimates were obtained:
The estimated MSE vector for the model (17) is (0.0094 0.0095 0.0021)T, while the vector of sample estimates of variances of the output variables is (0.0321 0.0184 0.0047)T.
Let
be a sample estimate of the coefficient of determination, i.e., the estimate of a fraction of variance of the dependent variable
ym explained by model (18), i.e.,
where
Dm is a sample estimate of the variance of the output variable
ym,
De, m is the mean squared value of the
et, m errors, and
m = 1, 2, 3. This gives
= 0.7061,
= 0.4822, and
= 0.5467.
Assuming a sampling time of one hour, the estimates of the delay vector
for predicting the output variable
y1 is
and the estimate of the coefficient vector is equal to
with
De, 1(
,
) = 0.0091.
Similarly, for variables
y2 and
y3, we obtain
The sample estimate of the coefficient of determination to predict the output variable ym denoted by is = 0.7160; = 0.5200; = 0.5726.
The effect of delay accounting was evaluated on a test sample containing 167 measurements. As a result, the MSE of the predictions of output variables y1, y2 and y3 decreased by 23%, 10%, and 3%, respectively.
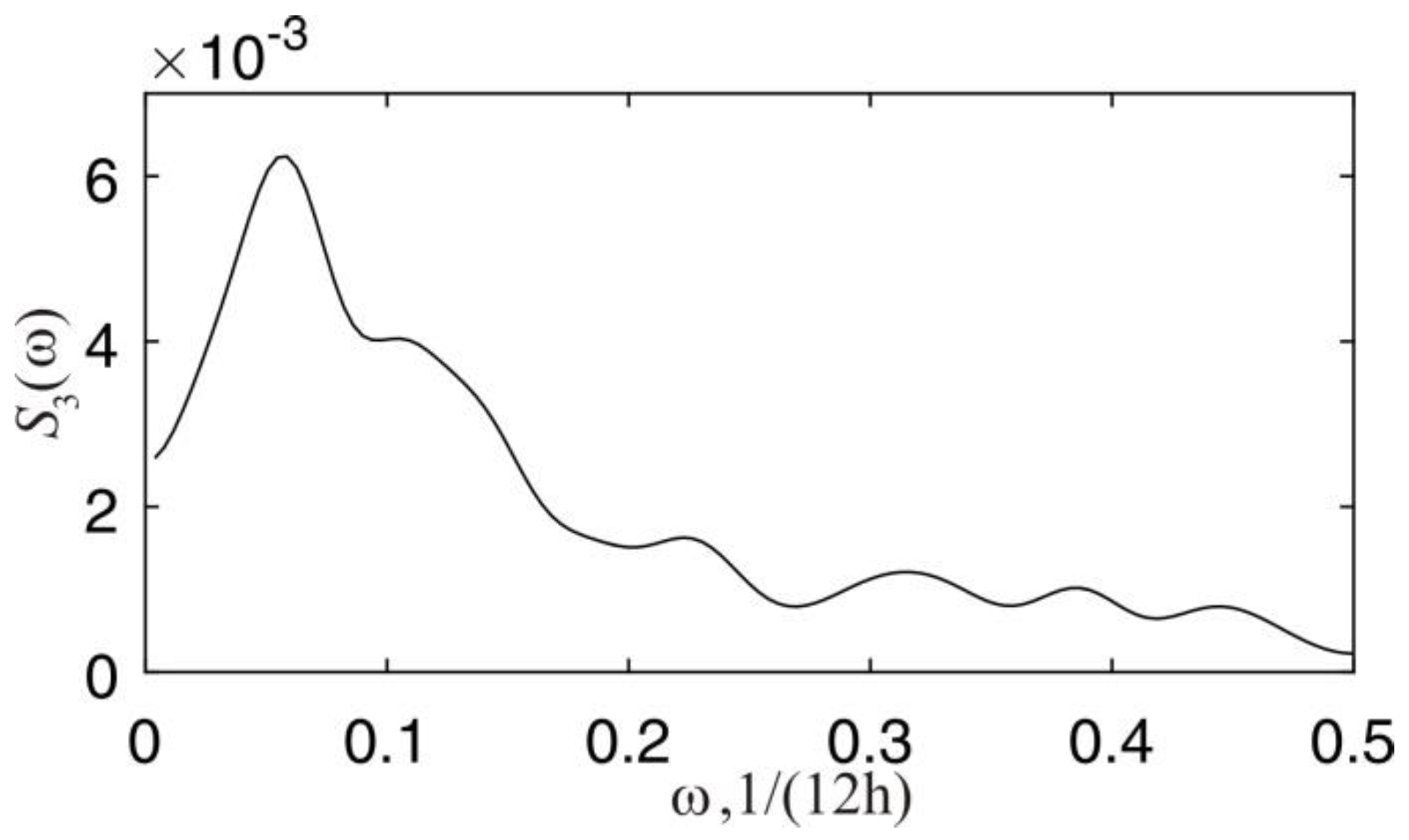
Now, let us consider modeling the error term. From the spectral density of the errors for
et, 1 and
et, 3 shown in
Figure 4 and
Figure 5, it can be seen that the maximum within the interval [0, 0.5] Hz indicates the presence in the denominator of the spectral density function
S(
ω) a factor (1 −
Ge−jω) with a complex-valued constant
G. Since the sampling time is equal to 12 h, the frequency unit 1/(12 h) is used instead of Hz. However, for the practical application of the filter given by Equation (9), it is necessary that all the coefficients be real [
8]. Therefore, the denominator of density
S(
ω) must contain a factor (1 −
e−jω) along with a factor (1 −
Ge−jω). If the frequency response models for
et, 1 and
et, 3 processes are limited to these two factors (assuming the numerator is equal to one), then the corresponding spectral density of the second-order autoregressive process approximates well the sample estimates of the spectrum of
et, 1 and
et, 3 processes at different values of
G. However, the insufficiently rapid decrease of the spectral density in the high-frequency region justifies the inclusion in the denominator of the model another multiplier with a real value of the constant
G.
In
Figure 6, which shows the spectral density for the
et, 2 errors, the sample spectrum of this time series resembles the spectrum of a first-order autoregressive process [
15,
16,
17]. However, we note that the stochastic process is not uniquely determined by its spectral density [
8]. Therefore, as previously mentioned, we need to include two additional constraints that the resulting model be invertible and realizable. This will ensure that we have a unique model.
Based on the theoretical properties of the process, the error models are
where
η are the parameters to be determined. These parameters can be found using the approach presented in
Section 2.2 by multiplying the finite impulse response model by the delayed errors and taking the expectations. For example, for
e1, this gives
where
γi = cov(
et1,
e(t−i)1) =
γ−i.
For the process et, 1, the estimates of the coefficients η11, η21 and η31 are, respectively, equal to 0.4131, −0.0093, and −0.0528. These values were used as the initial guesses passed to the PEM function. As a result of calculations, the model parameters were found to be: η11 = 0.4175, η21 = 0.03234, η31 = −0.07026. The initial value of coefficient η12 is 0.3748 and its final value is η12 = 0.3758.
Similarly, using Equation (22), the initial guesses were η13 = 0.5142, η23 = −0.0507, and η33 = −0.0207 to give final values of η13 = 0.5151, η23 = −0.02676, and η33 = −0.03246.
The performance of predictive filter models obtained from the analysis of the training dataset is validated using the testing sample.
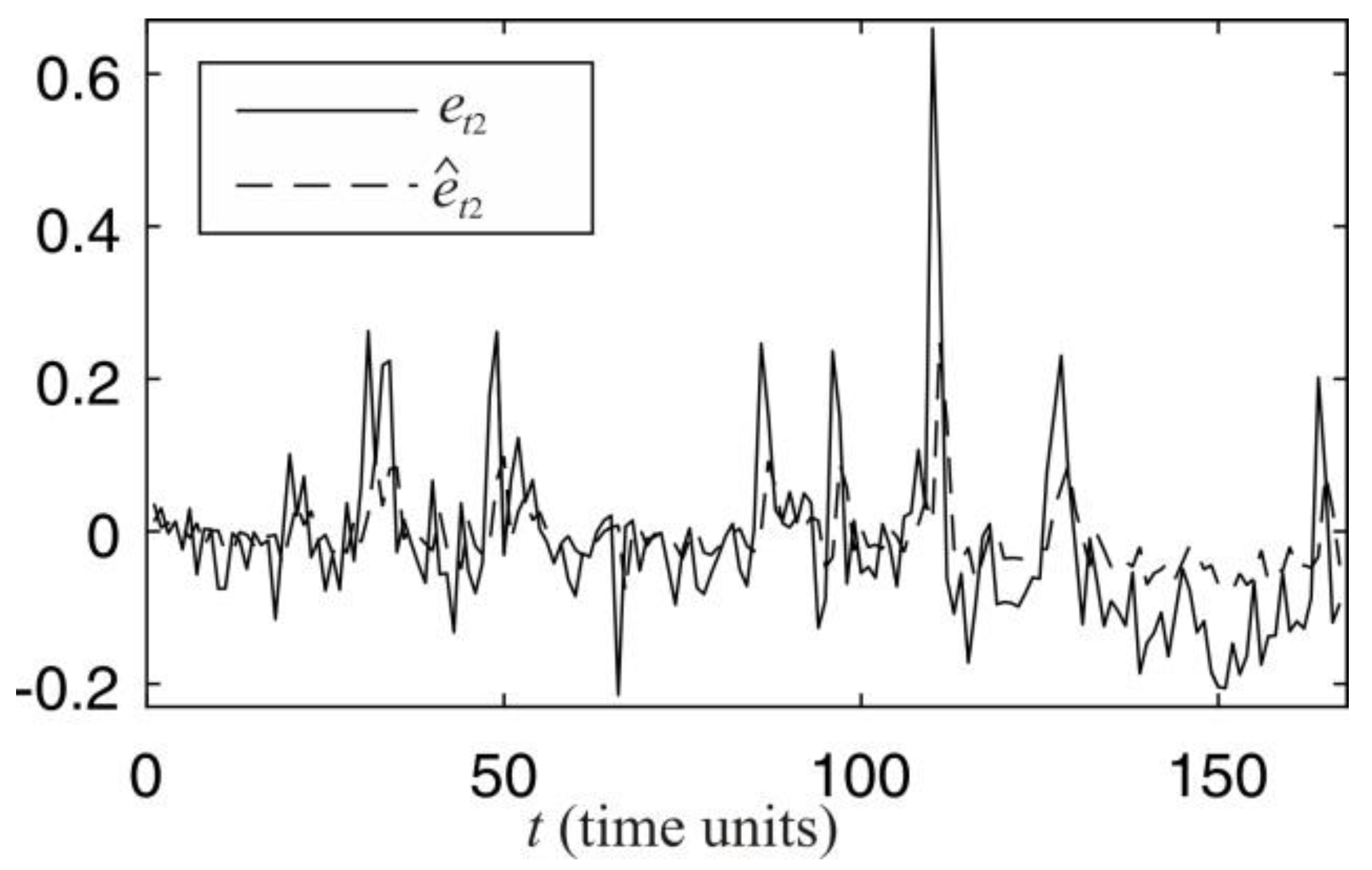
Figure 7,
Figure 8 and
Figure 9 compare the predictions against the true values, where the solid line shows the true
et, m errors and the dashed line their predicted values for
m = 1, 2, and 3. At the time point
t on the
x-axis, the corresponding error
et, m and the predicted error
computed at
t − 1.
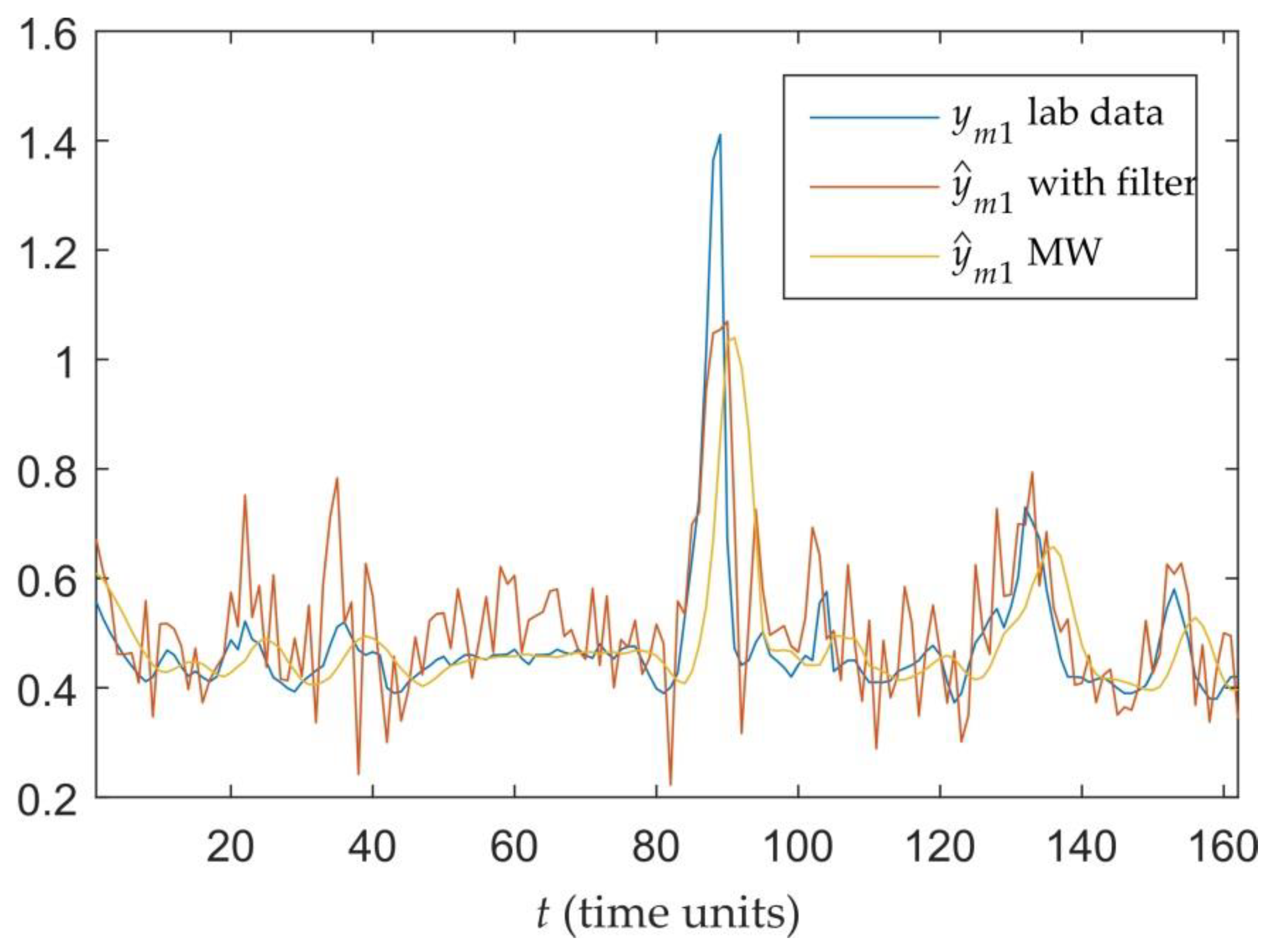
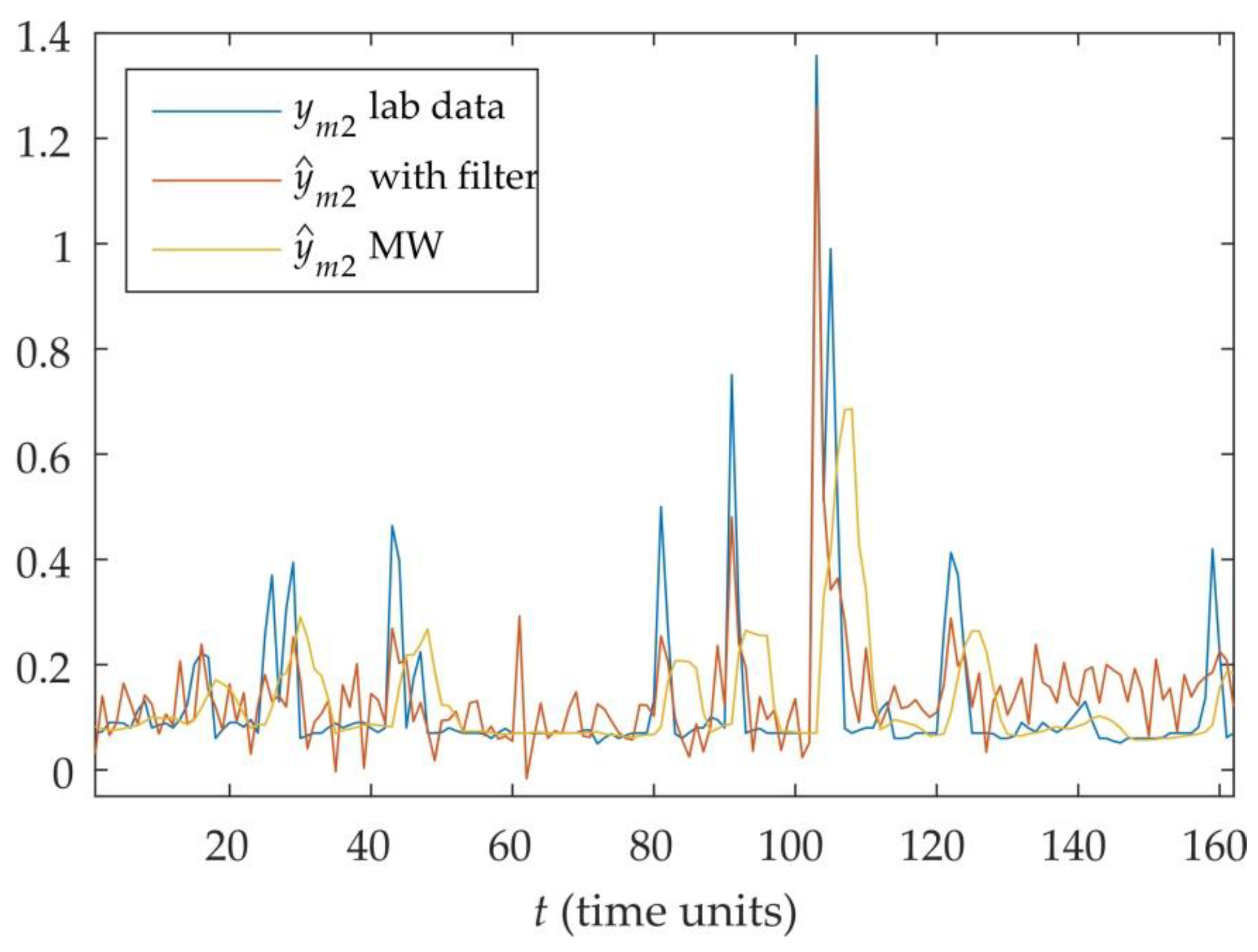
Figure 10,
Figure 11 and
Figure 12 compare the performance of the soft sensors with the proposed filter for error prediction and a traditional method, in which adaptive bias term is calculated based on the moving window (MW) approach [
18]. It can be seen that the filter provides better tracking of the process values, therefore improving the accuracy of the overall soft sensor system reducing the MSE of the output variables
y1,
y2, and
y3 by 32%, 67%, and 9.5%, respectively.





 —plant,
—plant,  —predictive model.
—predictive model.











{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}