2.1. Extraction of Hierarchical Type Information
The fact that the same entity has different meanings at different levels of a scenario is important for the learning of representations in the KG. However, most previous research pays less attention to the rich information located in hierarchical types of entities.
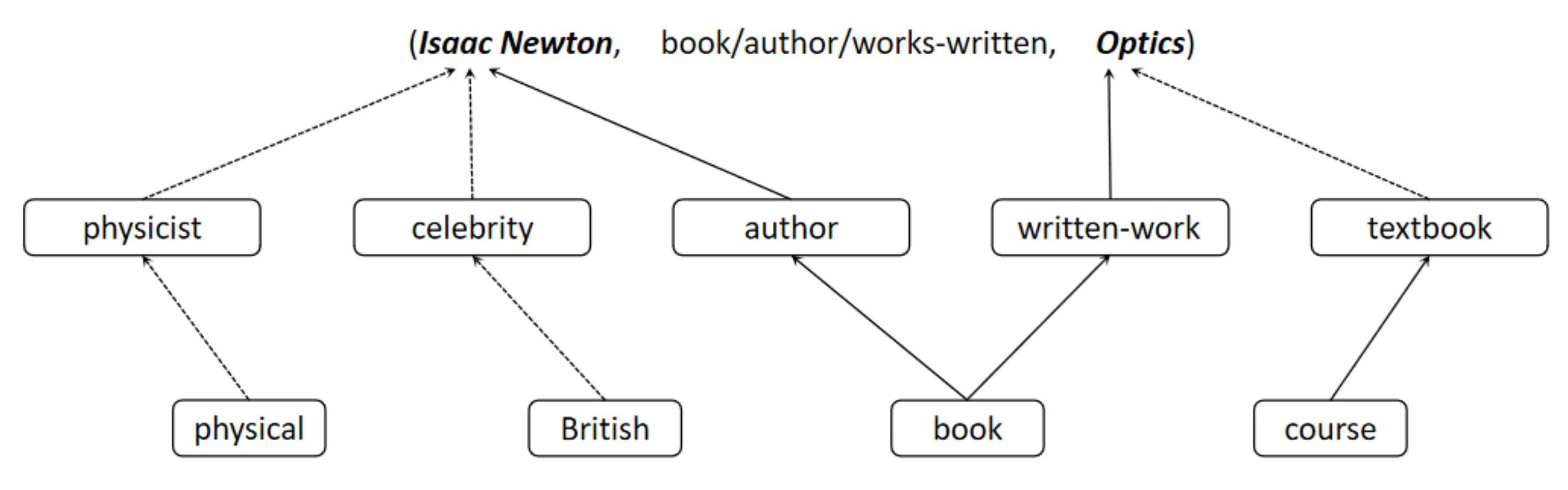
Figure 1 shows a triple instance;
Isaac Newton has a variety of types (e.g., book/author, physical/physicist, and British/celebrity). It is, therefore, reasonable to believe that each entity should be represented differently in different scenarios, as a reflection of itself from different perspectives. Take the example of a hierarchy type
g with
m layers, where
is the
ith sub-type of
g. Each sub-type
has only one parent sub-type
, while the most precise sub-type is the first layer, and the most general sub-type is the last. Going through the hierarchy from the bottom-up, we can obtain a representation of the hierarchical type as
. We assign the type-specific projection matrix
to each type
g, and the head
h and tail
t of this relation are then represented in the projection under the particular types as
and
, respectively. The energy function is defined as follows:
in which
and
are different projection matrices for
h and
t, respectively.
2.1.1. Type Encoder
We use a general form of type encoder to encode hierarchical type information into the representation learning. In the general form of a KG, most entities have more than one type, so the projection matrix
for entity
e is a weighted sum of all type matrices:
where
n is the number of types entity that
e has,
is the weight for
,
is the
ith type that
e belongs to, and
represents the projection matrix of
. The weights can be set according to statistical characteristics, such as type frequency. With this operation, all projection matrices of entity
e are the same in different scenes.
In practice, however, the importance of entity attributes varies in different scenarios. Therefore, we have improved the type encoder, and the projection matrix
in a specific triple will be:
where
. Similarly, the projection matrix
of the entity at the tail position can be obtained.
2.1.2. Hierarchical Encoder
As mentioned earlier, we consider the type information of entities to be hierarchical, so a recursive hierarchical encoder is used. During the projection process, entities (e.g., Isaac Newton) will be first mapped to the more general sub-type space (e.g., physical) and then be sequentially mapped to the more precise sub-type space (e.g., physical/physicist). The mathematical formula is:
where
is the projection matrix for type
g,
is the projection matrix of the
ith sub-type
, and
m is the number of layers for type
g.
2.2. Extraction of Logic Rules Information
To enable our model to provide more semantic information, we have further fused paths and logic rules information. First, we mine the rules with their confidence levels
from the KG. The higher the confidence level of the rule, the higher the probability that it holds. Second, we restrict the maximum length of rules to 2. Thus, rules are classified into two categories according to their length, as follows. (1)
: A rule set of length 1 is called
, which associates two relations in the rule body and rule head. (2)
: A rule set of length 2 is denoted
and it can be used to compose paths.
Figure 2 provides specific examples.
We use PTransE to implement the path extraction process, where the reliability of each path
p is denoted as
between pairs of entities
.
Table 1 lists the modes for
. Obviously, it is crucial that, in the rule
, which constitutes the path, sequential paths are formed by the atoms of each rule body. Therefore, we encode the eight rules to facilitate the formation of a valid path set
for the entity pair
. Taking the original rule
, for instance, we first convert the atom
into
, and then exchange two atoms in the rule body to obtain a chain rule
, which could be further abbreviated as
.
In order to make full use of the encoded rules, we should traverse the paths and iteratively perform the composition operation at the semantic level until the rules cannot combine any relations. In the actual path synthesis process, consider the optimal case in which all relations in the path can be synthesized iteratively by the rule and eventually joined together as a single relation between pairs of entities. In addition, when the path can match multiple rules at the same time, we choose the rule with a high confidence level to form the path. This leads to the path embedding of the path p.
When rule holds, relation may have more semantic similarity to its directly implicated relation . We, therefore, encode rules of the form of representation learning, as . During training, embedding representing pairs of relations that appear simultaneously in rule are considered closer than embedding of two relations that do not match any rule.
2.3. Integration of Information
For each triple
, we define three energy functions that model correlations for direct triples and hierarchical type methods, path pairs using rule
, and relationship pairs using rule
:
where
measures the effectiveness of type information.
denotes the energy function evaluating the similarity between path
p and relation
r, and
denotes the set of confidence levels corresponding to all rules in rule
employed in the composition of path
p.
is an energy function that represents the similarity between a relation
r and another relation
. If the relations contained in the relation
are re-defined using rule
, it should be assigned a smaller fraction.
2.4. Loss Function and Optimization
We formalize the loss function as a margin-based score function targeting negative sample sampling:
where
T represents a set that contains all the positive triples observed in KG.
is the negative sampling set of
T,
is the set of all relations deduced from
r on the basis of rule
, and
is any one of the relations in
.
is the set of all paths connecting entity pair
, of which
p is a path.
,
, and
correspond to marginal-based loss functions for the triple
of entity hierarchical types, path pairs
, and relationship pairs
:
where
,
, and
are hyper-parameters;
denotes the confidence level of associations
r and
.
Since there are no explicit negative triples in KGs, the entities or relationships in the training triples are randomly replaced by any other entity in
E. Moreover, the new triples after replacements will not be considered as negative samples if they are already in
T. In addition, the negative triples sampling rule is expressed as follows:
For optimization, mini-batch stochastic gradient descent (SGD) is used to minimize the loss function. The projection matrix set W could be initialized randomly or by identity matrix. In addition, the embeddings of entities and relations could be either initialized randomly or be pre-trained by existing translation-based models, such as TransE.





{kind=link}
{kind=link}