1. Introduction
In this paper we illustrate the use of the integrated nested Laplace approximation [
1] to fit spatial econometrics models. Interest in the Bayesian analysis of regression models with spatial dependence has existed since spatial econometrics came into being in the late 1970s. Hepple [
2] and Anselin [
3] point to key benefits, such as being able to make exact, finite-sample inferences in models in which only large-sample, asymptotic inferences would be feasible, and in the examination of model robustness to specification error [
2] (p. 180). Anselin [
4] (pp. 88–91) extends this discussion, but admits that Bayesian approaches had not at that time been applied often in spatial econometrics. Hepple [
5,
6] continued to follow up topics within Bayesian estimation, including Bayesian model choice [
7]. No software was available until the Spatial Econometrics Library was made available within the Econometrics Toolbox for Matlab, based on LeSage [
8,
9] (see
http://www.spatial-econometrics.com/, accessed on 20 August 2021).
LeSage and Pace [
10] provide a summary of spatial econometrics models and their applications. For Bayesian inference, they used Markov chain Monte Carlo (MCMC) algorithms to estimate the posterior distributions of the model parameters. These techniques give a feasible way of fitting Bayesian models, but can be computationally intensive. In addition, while the Matlab MCMC implementation does provide user access to change prior values from their defaults, the time required to check non-default settings may be considerable.
Bivand et al. [
11,
12] describe how to use the integrated nested Laplace approximation (INLA) [
1] to fit some spatial econometrics models. They focus on some models based on spatial autoregressive specifications on the response and the error terms often used in spatial econometrics. Because of the lack of an implementation of these models within the
R-INLA software at that time, Bivand et al. [
11,
12] fit many different models conditioning on values of the spatial autocorrelation parameter. These conditional models can be fitted with
R-INLA and they are later combined using Bayesian model averaging (BMA) [
13] to obtain the posterior marginals of the parameters of the desired model. The authors of [
14] discuss different approaches to fit spatial econometrics with INLA and how to perform multivariate inference on the output. Similarly, [
15] exploit Bayesian model averaging to fit spatial econometrics models with INLA.
INLA is based on approximating the posterior marginal distributions of the model parameters by means of different Laplace approximations. This provides a numerically fast method to fit models that can be applied to a wide range of research topics. INLA is restricted to models whose latent effects are Gaussian Markov random fields, but this class of models includes many models used in practice in a range of disciplines.
In this paper, we describe the implementation of a new latent class, that we will call slm, within R-INLA that facilitates fitting spatial econometrics models. This provides an alternative to fitting some of the models in the Spatial Econometrics Library. In addition, this creates a faster approach for Bayesian inference when only marginal inference on the model parameters is required.
This new approach will make fitting a wide range of spatial econometrics models very easy through the R-INLA package. A flexible specification of these models will allow the inclusion of smooth terms to explore non-linear relationships between variables. The new latent effects for spatial econometrics can be combined with other latent effects to fit more complex models. Furthermore, models will be fitted faster than with traditional MCMC, so a larger number of models can be explored and different model selection techniques can be used.
This paper has the following structure. After providing background descriptions of some spatial econometrics models and the integrated nested Laplace approximation, we introduce the new
slm latent model in
Section 3. A summary on the use of different likelihoods is included in
Section 4. The computation of the impacts is laid out in
Section 5.
Section 6.1 describes some applications on model selection and
Section 6.2 deals with other issues in Bayesian inference. Examples are included in
Section 7, using the well-known Boston house price data set and the Katrina business re-opening data set, and a final discussion is given in
Section 8.
2. Background
2.1. Spatial Econometrics Models
In this section, we summarise some of the spatial econometrics models that we will use throughout this paper. For a review on spatial econometrics models, see Anselin [
16]. We will follow the notation used in Bivand et al. [
11], which is in turn derived from Anselin [
4] and LeSage and Pace [
10], LeSage and Pace [
17].
We will assume that we have a vector
y of observations from
n different regions. The adjacency structure of these regions is available in a matrix
W, which may be defined in different ways. Unless otherwise stated, we will use standard binary matrices to denote adjacency between regions, with standardised rows. This is helpful in offering known bounds for the spatial autocorrelation parameters (see, for details, [
18]). Additionally, we will assume that the
p covariates available are in a design matrix
X, which will be used to construct regression models. Pace et al. [
19] have pointed out challenges involved in estimating models of this kind that we intend to address in further research.
The first model that we will describe is the spatial error model (SEM) which is based on a spatial autoregressive error term:
Here, is the spatial autocorrelation parameter associated with the error term. This measures how strong spatial dependence is. is the vector of coefficients of the covariates in the model. The error term e is supposed to follow a multivariate normal distribution with zero mean and diagonal variance–covariance matrix . is a global variance parameter while is the identity matrix of dimensions .
Alternatively, we can consider an autoregressive model on the response (spatial lag model, SLM):
is now the spatial autocorrelation parameter associated with the autocorrelated term on the response.
Next, a third model that is widely used in spatial econometrics is the spatial Durbin model (SDM):
is a vector of coefficients for the spatially lagged covariates, shown as matrix
.
A variation of this model is the spatial Durbin error model (SDEM), in which the error is autoregressive:
Here, M is an adjacency matrix for the error term that may be different from W.
All these models can be rewritten so that the response
y only appears on the left hand side. The SEM can also be written as
the SLM is equivalent to
the SDM is
with
, the new matrix of covariates with the original, and the lagged covariates and
, the associated vector of coefficients. Finally, the SDEM can be written as
For completeness, we will include a simplified model without spatial autocorrelation parameters and lagged variables (spatially lagged
X model, SLX):
These are a set of standard models in spatial econometrics, focussing on three key issues: spatially autocorrelated errors, spatially autocorrelated responses and spatially lagged covariates. More complex models can be built from these three standard models; the main difference is that those models incorporate more than one spatial autocorrelation parameter.
2.2. The Integrated Nested Laplace Approximation
Bayesian inference on hierarchical models has often relied on the use of computational methods among which Markov chain Monte Carlo is the most widely used. In principle, MCMC has the advantage of being able to handle a large number of models, but it has it drawbacks, such as slow convergence of the Markov chains and the difficulty of obtaining sampling distributions for complex models.
Rue et al. [
1] have developed an approximate method to estimate the marginal distributions of the parameters in a Bayesian model. In particular, they focus on the family of latent Gaussian Markov random fields models. We describe here how this new methodology has been developed, but we refer the reader to the original paper for details.
First of all, a vector of n observed values are assumed to be distributed according to one of the distributions in the exponential family, with mean . Observed covariates and a linear predictor on them (possibly plus random effects) may be linked to the mean by using an appropriate transformation (i.e., a link function). Hence, this linear predictor may be made of a fixed term on the covariates plus random effects and other non-linear terms.
The distribution of
will depend on a number of hyperparameters
. The vector
of latent effects forms a Gaussian Markov random field with precision matrix
, where
is a vector of hyperparameters. The hyperparameters can be represented in a unique vector
. It should be noted that observations
are independent given the values of the latent effects
and the hyperparameters
. This can be written as
Here, represents the linear predictor and is a vector of indices over . If there are missing values in , these indices will not be included in .
The posterior distribution of the latent effects
and the vector of hyperparameters
can be written as
INLA will not try to estimate the joint distribution but the marginal distribution of single latent effects and hyperparameters, i.e., and . Indices j and k will move in a different range depending on the number of latent variables and hyperparameters.
INLA will first compute an approximation to
,
, that will be used later to compute an approximation to
. This can be done because
Hence, an approximation can be developed as follows:
Here,
are values of the ensemble of hyperparameters in a grid, with associated weights
.
is an approximation to
and this is thoroughly addressed in Rue et al. [
1]. They comment on the use of a Gaussian approximation and others based on repeated Laplace approximations and explore the error of the approximation.
This methodology is implemented in the R-INLA package. It allows for easy access to many different types of likelihoods, latent models and priors for model fitting. However, this list is by no means exhaustive and there are many latent effects that have not been implemented yet. This is the reason why we describe a newly implemented slm latent effect that has many applications in spatial econometrics.
3. The slm Latent Model in R-INLA
Although the INLA methodology covers a wide range of models, latent models need to be implemented in compiled code in the INLA software to be able to fit the models described earlier in this paper. Hence, the newly implemented
slm latent model fills the gap for spatial econometrics models. This new latent model implements the following expression as a random effect that can be included in the linear predictor:
Here, is a vector of n random effects, is the identity matrix of dimension , is a spatial autocorrelation parameter (that we will discuss later), W is a weight matrix, X a matrix of covariates with coefficients and is a vector of independent Gaussian errors with zero mean and precision .
In this latent model, we need to assign prior distributions to the vector of coefficients , spatial autocorrelation parameter and precision of the error term . By default, takes a multivariate Gaussian distribution with zero mean and precision matrix Q (which must be specified); takes a Gaussian prior with zero mean and precision 10 and takes a log-gamma prior with parameters 1 and . Other priors can be assigned to these hyperparameters following standard R-INLA procedures.
Note that, as described in
Section 2.1, spatial econometrics models can be derived from this implementation. In particular, the SEM is a particular case of Equation (
14) with
. The SLM can be fitted with no modification and the SDM can be implemented using a matrix of covariates made of the original covariates plus the lagged covariates.
The SDEM simply takes two terms, a standard linear term on the covariates (and lagged covariates), plus a slm effect with . Finally, the SLX model can be fitted using a standard linear regression on the covariates and lagged covariates and typical i.i.d. random effects.
Implementation
We will describe here the implementation of the new
slm latent class. For a Gaussian response (and similarly for non-Gaussian likelihoods), the model can be written as
It can be rewritten using
, so that with observations
y, we then have
where
e is a tiny error that is introduced to fit the model. This is the error present in a Gaussian distribution and will not appear if another likelihood is used.
By re-writing the
slm as
in this way, we define it so that it suits the
f()-component in the
R-INLA framework. Given this, we note that the
slm is a Markov model with a sparse precision matrix, and so conforms to the INLA framework. We provide an introduction to the interface in the
R-INLA package in
Appendix A and a detailed proof in
Appendix B, and we show here the main results.
The mean and precision of (
given the hyperparameters
and
are given by
Note that this precision matrix is highly sparse and symmetric. Efficient computation using this new latent effect can be carried out using the GMRF library, as described in Rue and Held [
20].
The full model can then be derived conditioning on different parameters. Hence, the joint distribution of
,
,
and
can be written as
is a Gaussian distribution with mean and precision shown in Equations (
15) and (
16), respectively. The prior distribution of
is Gaussian with zero mean and known precision matrix
Q. This matrix is often taken diagonal to assume that the coefficients are independent a priori. In addition, it may be worth re-scaling the covariates in
X to avoid numerical problems. Including lagged covariates may lead to further numerical instability as they may be highly correlated with the original covariates.
It is internally assumed that
is between 0 and 1 so that a Gaussian prior is assigned to
. When computing
,
is re-scaled to be in a range of appropriate values (see details in the description of the R interface in
Appendix A).
The simulation study provided in one of the Appendices shows that the implementation works well in practice. A more thorough simulation study could be provided but this is out of the scope of this paper. Furthermore, the results presented in the examples in
Section 7 also support the assertion that the new
slm latent effect provides good estimates of the model parameters.
4. Using Different Likelihoods
4.1. Binary Response
The models described in
Section 2.1 assume a Gaussian response but other distributions can be used for the response. Le Sage et al. [
21] consider a binary outcome when studying the probability of re-opening a business in New Orleans in the aftermath of Hurricane Katrina. Binary outcome
is modelled using a latent Gaussian variable
as follows:
is the net profit, so if it is equal or higher than zero, the business will re-open.
is assumed to be a Gaussian variable that can be modelled using the spatial econometrics models described in
Section 2.1. Note that in this case the variance of the error term is set to 1 to avoid identifiability problems [
11,
21].
Several authors have assessed different methods for the estimation of spatial probit models. Billé [
22] has compared the methods of maximum likelihood (ML) and generalised method of moments using a Monte Carlo study and proposed alternatives to avoid the inversion of
when fitting the models. Calabrese and Elkink [
23] compared a larger number of estimation methods for spatial probit models, including MCMC algorithms, to estimate the spatial autocorrelation parameter and provide a study on the predictive quality of each method.
Instead of using a “broken-stick” function such as the one shown in Equation (
17),
R-INLA relies on standard logit and probit links, among others. In our examples, the spatial probit is based on using a (continuous) probit link function instead of the one shown in Equation (
17). Hence, differences in some results can be expected.
4.2. Other Likelihoods
R-INLA provides a number of likelihoods that can be used when defining a model, so that an
slm latent effect is included in the linear predictor. However, attention should be paid so that the resulting model makes sense. A particular problem of interest is whether all parameters in the model are identifiable. For example, if the spatial probit model is used,
must be set to one so that
can be properly estimated [
10]. Using other highly parameterised likelihoods (such as, for example, zero-inflated models) obliges the analyst to pay attention to details to ensure that output makes sense.
4.3. Additional Effects
R-INLA makes it possible to include additional effects in the linear predictor. All models presented to date assume a spatial structure on the error terms. As for Besag et al. [
24], it is possible to consider a model in which there are two different random effects: one spatial with an autocorrelated structured defined by the
slm latent class plus unstructured random effects. For example, the SLM can be extended as follows:
Note that the random effect u can have different structures.
Furthermore, other effects than linear can be explored for the covariates, as R-INLA includes different types of smoothers, such as first and second order random walks.
5. Computation of the Impacts
Impacts are related to how changes in the covariates in one area will affect the response in other areas, and there are different types of
impacts to measure these effects. As LeSage and Pace, in Section 2.7 of [
10], explain, impacts appear because a change in the value of a covariate in a region will affect not only the region itself (direct impact) but also other regions indirectly (indirect impact).
For the linear models presented in
Section 2.1, impacts per covariate
r can be defined as
with
being the
r-th covariate. This will measure the change in the response observed in area
i when covariate
r is changed in area
j. For the spatial probit models, the impacts are defined as [
21]:
In both cases, the impacts will produce an matrix of impacts for each covariate. The values on the diagonal of this matrix are called direct impacts, as they measure the change in the response when the covariate is changed in the same area (i.e., the value of covariate r in area i is changed). In order to give an overall measure of the direct impacts, its average is often computed and it is called average direct impact.
Similarly, indirect impacts are defined as the off-diagonal elements of , and they measure the change in the response in one area when changes in covariate r happen in any other area. A global measure of the indirect impacts is the sum of all off-diagonal elements divided by n, which is called the average indirect impact.
Finally, the average total impact is defined as the sum of direct and indirect impacts. This gives an overall measure of how the response is affected when changes occur in a covariate in any area.
Bivand et al. [
11] summarise the form of the impacts for different models and provide some ideas on how to compute the different average impacts with
R-INLA and BMA. For a Gaussian response, the impacts matrix for the SEM is simply a diagonal matrix with coefficient
in it, i.e.,
. For the SDM, the impacts matrix is
The impact matrix for the SLM is the same as in Equation (
21) with
, i.e., the coefficients of the lag covariates are not considered.
In addition, the impacts matrix for the SDEM is
Finally, the SLX model shares the same impacts matrix as the SDEM; in both cases, the average impacts are the coefficients (direct) and (indirect), for which inferences are readily available.
In the case of the spatial probit, the impacts matrices are similar but they need to be premultiplied by a diagonal matrix
, which is an
diagonal matrix with entries
, where
is the standard Gaussian distribution evaluated at the expected value of the linear predictor of observation
i. For example, for the spatial probit SDM, this is:
where
is defined as
The impacts matrix for other spatial probit models can be derived in a similar way.
Approximation of the Impacts
Average direct, indirect and total impacts can be computed by summing over the required elements in the impacts matrix (and dividing by n). In a few simple cases, such as the SEM, SDEM and SLX model, the impacts can be computed with R-INLA as the impacts are a linear combination of the covariate coefficients. In general, the impacts cannot be computed directly with R-INLA as they are a function on several parameters and INLA only provides marginal inference.
From a general point of view, the average impacts can be regarded as the computation of a function that involves two or three parameters in the model. Hence, multivariate posterior inference is required to obtain estimates of the impacts. We will try to approximate the posterior marginal of the average impacts the best we can by sampling from the approximate joint posterior (see below).
Let us consider the Gaussian case first. For the SEM, the average direct impact for covariate r is simply the posterior marginal of coefficient . Therefore, this is a trivial case and inference is exact. Average indirect impacts are equal to zero, which makes the average total impact equal to the average direct impact, i.e., .
For the SDM, the average total impact is
Note how this is the product of two terms, one on
and the other one on
. In order to estimate the posterior distribution of the average total impacts, samples from the approximate joint posterior of the parameters involved can be drawn from the fitted INLA model using the
inla.posterior.sample function from Chapter 2 of [
25].
Regarding the average direct impact for the SDM, this is
Again, this expression is a non-linear term that involves several parameters and its posterior distribution can be approximated by sampling from the approximate posterior distribution obtained with INLA.
For the SDEM and SLX model, the distribution of the average total impact is the marginal distribution of
, whilst the associated direct impact is given by
Hence, inference on the impacts is exact for the SDEM and SLX model.
In the case of the spatial probit, the average total impacts are as before but multiplied by
The average direct impact is the trace of
, which now takes a more complex form as it involves
, divided by
n. For example, for the SDM it is
The posterior distribution of the impacts will be approximated using sampling from INLA, as stated above.
6. Further Topics
6.1. Some Applications in Spatial Econometrics
LeSage and Pace [
10] not only describe how to fit Bayesian spatial econometrics models using MCMC but also discuss how to take advantage of the Bayesian approach to tackle a number of other issues. In this section, we discuss other applications when dealing with spatial econometrics models.
6.1.1. Model Selection
R-INLA reports the marginal likelihood of the fitted model
, i.e.,
, which can be used for model selection, as described in Section 6.3 of [
10] and Bivand et al. [
11]. For example, if we have a set of
m fitted models
with marginal likelihoods
, we may select the model with the highest marginal likelihood as the “best” model.
Following a fully Bayesian approach, we could compute the posterior probability of each model by taking a set of prior model probabilities
and combining them with the marginal likelihoods using Bayes’s rule:
If all models are thought to be equally likely a priori, then the priors are taken as
, so that the posterior probabilities are obtained by re-scaling the marginal likelihoods to sum up to one:
This model selection approach can be applied to models with very different structures. They could be models with different spatial structures, different latent effects or based on different sets of covariates. In
Section 7, we show an example based on comparing models with different spatial structures in the second example on the Katrina business data.
In addition,
R-INLA implements a number of criteria for model selection, such as the deviance information criterion (DIC) [
26] and conditional predictive ordinate (CPO) [
27]. These criteria can be used to compare different models and perform model selection as well.
6.1.2. Variable Selection
As a particular application of model selection, we will discuss here how to deal with variable selection. In this case, models differ in the covariates that are included as fixed effects. The number of possible models that appear is usually very large. For example, 20 covariates will produce
possible models, i.e., more than 1 million models to be fitted. As stated before, posterior probabilities for each model can be computed using the marginal likelihood as in Equation (
31). In principle, given that
R-INLA fits models very quickly and that a large number of models can be fitted in parallel on a cluster of computers, it would be feasible to fit all possible models.
As an alternative approach, stepwise regression can be performed based on any of the model selection criteria available. In particular, the DIC provides a feasible way of performing variable selection. This can be included in a step-wise variable selection procedure which will not explore all possible models but can lead to a sub-optimal model.
6.1.3. Model Averaging
Sometimes, an averaged model may be obtained from other fitted models. We have already pointed out how Bivand et al. [
11] used Bayesian model averaging to fit spatial econometrics models using other models with simpler random effects. The authors of [
15] describe the use of Bayesian model averaging with INLA and how to fit spatial econometrics models with two spatial autoregression parameters. This approach can be employed to fit highly parameterised models with INLA.
However, a BMA approach can also be used to combine different models for other purposes. For example, when the adjacency matrix is unknown, we may fit different models using slightly different adjacency matrices. LeSage and Pace [
10] discuss BMA in the context of spatial econometrics. In
Section 7, we have considered this in the second example on the Katrina business data where different spatial structures are considered using a nearest neighbour algorithm.
6.2. Other Issues in Bayesian Inference
So far, we have reviewed some existing and widely used spatial econometrics models, and how these models can be fitted using INLA and its associated software R-INLA. Now, we will focus on other general problems that can be tackled using this new approach.
6.2.1. Linear Combinations and Linear Constraints on the Parameters
R-INLA allows the computation of posterior marginals of linear combinations on the latent effects. This can be very useful to compute some derived quantities from the fitted models, such as some of the impacts described in
Section 5.
Furthermore, R-INLA allows the user to define linear constraints on any of the latent parameters and other quantities, including the linear predictor. This is useful, for example, to produce benchmarked estimates, i.e., model-based estimates obtained at an aggregation level that must match a particular value at a different aggregation level.
6.2.2. Prediction of Missing Values in the Response
Missing values often appear in spatial econometrics because actual data have not been gathered for some regions or the respondent was not available at the time of the interview. Sometimes, missing data appear because of the way surveys are designed as the sample is taken to be representative of the whole population under study and many small areas may not be sampled at all. Missing values may also appear in the covariates, but we will only consider here the case of missing values in the response.
With R-INLA, a posterior marginal distribution will be obtained and inference and predictions on the missing responses can be made from this. Note that this is a prediction only and that uncertainty about the missing values will not influence the parameter estimates.
The case of missing values in the covariates is more complex. First of all, we will need to define a reasonable imputation model and, secondly, the missing values and the parameters in the new imputation model will be treated as hyperparameters in our approach, increasing the number of hyperparameters and making a computational solution infeasible.
6.2.3. Choice of the Priors
LeSage and Pace [
10] briefly discuss the choice of different priors for the parameters in the model, and they stress the importance of having vague priors. For the spatial autocorrelation parameter, they propose a uniform distribution in the range of this parameter. A normal prior with zero mean and large variance is used for
. A gamma prior with small mean and large variance is proposed for the variance
. However wise these choices may seem, it is not clear how these priors will impact on the results.
Because of the way different models in the Spatial Econometrics Toolbox are implemented, it is difficult to assess the impact of the priors, as using different priors will require re-thinking how the MCMC sampling is carried out. New conditional distributions need to be worked out and implemented.
R-INLA provides a simple interface with some predefined priors that can be easily used. Other priors can be defined by using a convenient language and plugged into the
R-INLA software. Hence, it is easier and faster to assess the impact of different priors. See Chapter 5 in [
25] for a general discussion on the use of priors with
R-INLA.
For example, Gelman [
28] has suggested that gamma priors for the variances were not adequate for the variance parameter in Gaussian models as they were too informative. Instead, they have proposed the use of a half-Cauchy distribution. A model with this prior can be easily implemented by defining the half-Cauchy prior and passing it to
R-INLA.
7. Examples
7.1. Boston Housing Data
Harrison and Rubinfeld [
29] studied the median value of owner-occupied houses in the Boston area using 13 covariates. Note that the median value has been censored at USD 50,000 and that we omit tracts that are censored, leaving 490 observations [
30]. The spatial adjacency that we will consider is for census tract contiguities.
Bivand et al. [
11] use INLA and Bayesian model averaging to fit SEMs, SLMs and SDMs to this data set (but including all 506 tracts and using a different representation of adjacency). Here, we will use the new
slm latent model for
R-INLA to fit the same models. In principle, we should obtain similar results and we will benefit from all the other built-in features in
R-INLA (such as summary statistics, model selection criteria, prediction, etc.).
First of all, we have fitted the five models described in
Section 2.1. Point estimates of the fixed effects are summarised in
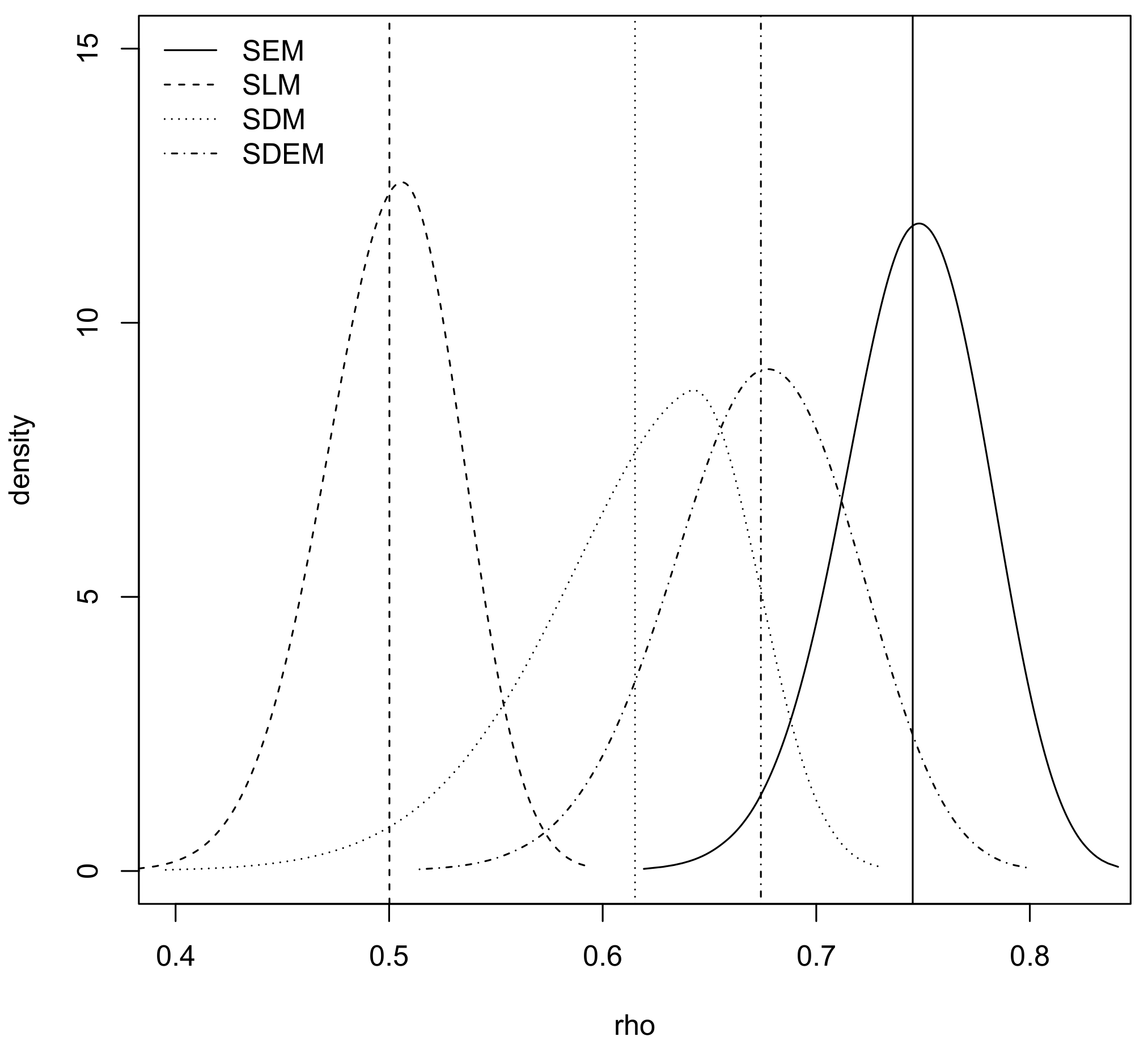
Table 1. In addition, the posterior marginal of the spatial autocorrelation parameters are displayed in
Figure 1, including posterior means. Note that these values are not the ones reported in the
R-INLA output and that we have re-scaled them as explained in
Section 3. In this case, the range used for the spatial autocorrelation parameter is
. This will make the summary statistics for
directly comparable to those reported in Bivand et al. [
11].
In general, all our results match theirs, as expected. However, the new
slm latent effects make fitting these models with
R-INLA simpler. Finally,
Figure 2 shows a map of the values of the
slm latent effects for the SEM and SDEM.
Note that in order to fit the model, we have set the variance of the Gaussian likelihood to a fixed and tiny value (by setting the log-precision to 15) because this error term does not appear in the different spatial econometrics model fits. A side effect of this is that the DIC will be the same for all models (and it cannot be used for model comparison) and that the fitted values will also have a tiny variance. The fitted values could be computed in the right way by adding extra observations with missing values (i.e., NA) in the response; this observation will not be used for model fitting and the fitted values will now account for the required uncertainty.
7.1.1. Smoothing Covariates
So far, we have considered the squared values of NOX in our models but the relationship between this covariate and the response may take other forms. In
Section 4.3, we have discussed how
R-INLA implements some latent effects to smooth covariates (see, for example, Chapter 9 of [
25]). One of them is the second order random walk that we have used here to smooth the values of nitric oxide concentration (parts per 10 million), which is covariate NOX. This smoother needs to be included additively in all the other effects, so it is only readily available for the SEM, SDEM and SLX model. This latent model has only one hyperparameter, which is its precision. In order to avoid overfitting and force the random walk to produce a smooth function, a gamma prior with mean 2000 and variance 10 has been used for the precision in all models, so that the level of smoothing can be compared. The results are shown in
Figure 3.
SEM and SDEM show a similar linear effect, which is consistent with the findings in Harrison and Rubinfeld [
29]. The SLX model seems to provide similar estimates of this effect but with considerably narrower credible intervals. As no spatial random effects are included in this model, we believe that the smoother on NOX is picking up residual spatial effects.
7.1.2. Impacts
Average direct, indirect and total impacts have been computed for the models fitted to the Boston housing data set. In addition, for the SLM and SDM, we have also fitted the models using maximum likelihood and computed their impacts for purposes of comparison. Average direct impacts, average total impacts and average indirect impacts are provided in the
Supplementary Materials. Impacts are very similar between ML and Bayesian estimation for the models where we have computed them using functions in the
spdep package.
Inference on the different impacts is based on their respective posterior marginal distributions provided by
R-INLA. In addition to the posterior means, other statistics can be obtained, such as standard deviation, quantiles and credible intervals. These posterior marginal distributions can also be compared to assess how different models produce different impacts.
Figure 4 shows the total impacts for NOX-squared under five different models. Given that for SLM and SDM we were using an approximation, we have included, with a thicker line, the distribution of the total impacts obtained with the Matlab code in the Spatial Econometrics Toolbox for these two models. The results clearly show that our approximation is very close to the results based on MCMC. Furthermore, we have checked that similar accuracy is obtained for all the covariates included in the model.
7.1.3. Prediction of Missing Values
As stated in
Section 6.2.2, INLA and
R-INLA can provide predictions of missing values in the response. We will use this feature to provide predictions of the 16 tracts with censored observations of the median values, treated as missing values. This will allow us to use the complete adjacency structure and to borrow information from neighbouring areas to provide better predictions.
With
R-INLA, this is as simple as setting the censored values in the response to
NA. We will obtain a predictive distribution for the missing values so that inference can be made from them. We have represented the five marginal distributions obtained with the models in
Figure 5 for six selected areas. The vertical line shows where the censoring cuts in.
Areas 13 to 17 seem to have predicted values well below the cut-off point. These areas are located in the city centre, where house prices are likely to be higher than average and that is why our model does not predict well there. Furthermore, the predicted values of the remaining 11 areas with missing values have a similar behaviour as in Area 312 (included in
Figure 5), that is, the cut-off point is close to the median of the predicted values.
Furthermore, in the
Supplementary Materials, we show the posterior means of the
slm latent effects for the SEM and SDEM in the same way as in
Figure 2 for the incomplete data set. The main difference is that the new maps include predictions for the areas with the censored observations but the estimates in the common tracts are similar.
7.2. Business Opening after Katrina
LeSage et al. [
21] studied the probabilities of re-opening a business in New Orleans in the aftermath of hurricane Katrina. They used a spatial probit, like the one described in Equation (
17). Here, we reproduce the analysis with a continuous link function (i.e., a probit function) and the new
slm latent model, similarly as in Bivand et al. [
11].
7.2.1. Standard Models
Table 2 shows point estimates (posterior means) of the fixed effects for the five of the models discussed in
Section 2.1.
Furthermore,
Figure 6 shows the marginal distribution of the spatial autocorrelation parameters of four different spatial econometrics models for INLA and MCMC. For the INLA models, the values of the spatial autocorrelation parameters have been properly re-scaled to fit in the correct range and not constrained to the
interval. In this example,
could be from
to 1, but we have only considered it to be in the
so that a fair comparison with MCMC can be made. INLA estimates for both fixed and spatial autocorrelation estimates are very similar to those reported by Bivand et al. [
11]. The posterior mean of the spatial autocorrelation for the SDM differs but this may be because Bivand et al. [
11] constrained
to be in the (0,1) interval. The SDM seems to have a weaker residual spatial correlation, probably because the inclusion of the lagged covariates reduces the autocorrelation in the response.
Regarding INLA and MCMC estimates, although the marginals are close for the SLM, they are a bit further away for all the other three models presented in
Figure 6. The posterior modes are close but these differences may be due to the fact that two different link functions are used as the MCMC implementation which defines a latent continuous variable
so that the response is 1 when
is non-negative and 0 otherwise. This makes the models fit with INLA and MCMC differently in practice. The results obtained in the simulation study included in the
Appendix A and
Appendix B also support the assertion that the differences are due to the different link functions.
7.2.2. Exploring the Number of Neighbours
LeSage et al. [
21] used a nearest neighbours method to obtain an adjacency matrix for the businesses in the data set. In addition, they explored the optimal number of nearest neighbours by fitting the model using different numbers of nearest neighbours and using the model with the lowest DIC [
26] as the one with the optimal number of neighbours. For the 3-month horizon model, they compared a window of 8–14 neighbours, probably because of the computational burden of MCMC, which they used to fit their models.
The newly available
slm in
R-INLA makes exploring the optimal number of neighbours faster and simpler. We have increased the number of neighbours considered, between 5 and 35, and fitted the SLM using different adjacency matrices. These adjacency matrices have been created using the nearest neighbour algorithm with different values of the number of neighbours.
Figure 7 shows how the optimal number of neighbours seems to be 22 according to both the DIC and the posterior probability (as explained in
Section 6.1) criteria. However, we believe that this should be used as a guide to set the number of neighbours as there may be other factors to take into account. In particular, a nearest neighbour approach may consider as neighbours businesses that are in different parts of the city, particularly if the number of nearest neighbours is allowed to be high.
When computing the posterior probability, the prior probability of each model is taken so that
, and there is no prior preference on the number of neighbours. If we decide to favour adjacencies based on a small number of neighbours, we may use a more informative prior. For example, we could take
so that neighbourhoods with a smaller number of neighbours are preferred.
Figure 7 shows the prior and posterior probability for different values of the number of neighbours. Now, it can be seen how our prior information produces different posterior probabilities, with an optimal number of neighbours of 8.
Finally, it is also possible to average over the ensemble of models using Bayesian model averaging. This will produce a fitted model that takes into account all the adjacency structures, weighted according to their marginal likelihoods.
Table 3 shows the estimates of the fixed effects for the model with the highest posterior probability according to a uniform prior (
) and an informative prior (
), and the estimates obtained by averaging over all the fitted models. These models should take into account the uncertainty about the number of neighbours and can provide different estimates of the fixed effects. As it happens, the posterior means and standard deviations are slightly different, but we can observe higher differences in the case of an informative prior.
7.2.3. Impacts
We have followed the method described in
Section 5 to approximate the impacts for the models fitted to the Katrina data set. In this case, we do not have any model fitted using ML with which to compare. The implementation of the spatial probit in the Spatial Econometrics Toolbox is for a different link, so our results cannot be directly compared to MCMC, as reported by LeSage et al. [
21]. Direct impacts are shown in
Table 4, whilst total and indirect impacts are available in the
Supplementary Materials.
Inference on the impacts relies on sampling from the approximation to the joint posterior distribution which is then used to compute the impacts and estimate their posterior distributions, as we have already seen in the Boston housing data example.
Figure 8 shows the estimates of the average total impacts for flood depth for four models. With a thicker line, we have included the posterior marginal of the impacts computed using the output from MCMC using the
spatialprobit package. As previously stated, MCMC results can be roughly compared to our SLM estimates but keeping in mind that different link functions have been used and that differences may appear. In this case, the quality of our approximations differs with the models. We have found similar accuracy for all the other variables, which means that our approximation appears to be acceptable.
Note that the impacts estimated with INLA and MCMC are close regardless of the estimates of the spatial autocorrelation parameters shown in
Figure 6. We believe that this is because the impacts themselves build on the fitted model parameter values rather than the posterior distributions, which only enter into simulations to obtain the distributions of the impacts.
8. Discussion and Final Remarks
In this paper, we have described how the analysis of spatial econometrics data requires the use of very specific models and how the integrated nested Laplace approximation offers an alternative to model fitting. Instead of resorting to MCMC methods, INLA aims at providing approximate inference on the marginal distribution of the model parameters. This methodology is implemented in the R package R-INLA, which includes a particular latent effect called slm which can be used to fit many spatial econometrics models.
We have also shown how impacts can be approximated when models are fitted with R-INLA. As this requires multivariate posterior inference, the estimation of the impacts is achieved by sampling from the approximation to the joint posterior of the required coefficients and spatial autocorrelation parameter and computing the impacts using these samples. It is worth noting that these samples are independent, so fewer samples are required for inference than with typical MCMC algorithms.
It should be noted that there are several advantages of using INLA and
R-INLA. Not only are model specification and fitting very easy using R but also the computational speed allows us to explore a large number of models. When the model is not available within the range of latent models available in
R-INLA, it is often possible to fit conditional models, on one or two model parameters, and then obtain the desired model by averaging over these models. Furthermore, other important topics in Bayesian inference, such as prediction of missing responses, model selection and variable selection, can be tackled with INLA. Several authors (see, for example, [
31,
32]) have assessed the accuracy of INLA (as compared to MCMC) for a wide range of models, so we believe that this will also be the case for the spatial econometrics models presented herein.
In the future, we expect to explore how to increase the number of spatial econometrics models available in R-INLA and how to extend them. In particular, we find that there is interesting work to do on models with more than one spatial term, spatio-temporal models, the analysis of panel data and how to account for measurement error in covariates, for example.












{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}