1. Introduction
In mathematics, just as in other scientific disciplines, there is a shift from theoretical mathematics to mathematics which would be applicable in practice. Such mathematics knowledge includes the field of statistics and probability. The theory of probability is a relatively young mathematical discipline whose axiomatic construction was built by Russian mathematician Kolmogorov in 1933 [
1]. For the first time in history, the basic concepts of probability theory were defined precisely but simply. A random event was defined as a subset of a space, a random variable as a measurable function, and its mean value as an integral (abstract Lebesgue integral). Like the Kolmogorov theory of probability in the first half of the 20th century, the Zadeh fuzzy set played an important role in the second half of the 20th century [
2,
3,
4,
5]. Zadeh’s concept of a fuzzy set was generalized by Atanassov. In May 1983 it turned out that the new sets allow the definition of operators which are, in a sense, analogous to the modal ones (in the case of ordinary fuzzy sets such operators are meaningless, since they reduce to identity). It was then that the author realized that he had found a promising direction of research and published the results in [
6]. Atanassov defined Intuitionistic Fuzzy sets (IF sets) and described them in terms of membership value, non-membership value and hesitation margin [
7,
8]. An IF set is a pair of functions
where function
is called the membership function and function
is called the non-membership function, in force that
. Many writers have attempted to prove some known assertions from the classical probability theory in the theory of IF sets [
9,
10,
11,
12] and apply known statistical methods in these sets.
In 2010, Bujnowski P., Kacprzyk J., and Szmidt E. [
13] defined a correlation coefficient (more in
Section 3) and presented novel-approach dimensionality reduction data sets through Principal Component Analysis on IF sets [
14]. For this article, we saw the practical use of IF sets to solve the problem of the reduction of dimensionality data sets. Therefore, it motivated us to continue this idea.
One of the main problems in data analysis is to reduce the number of variables while maintaining the maximum information that the data carries. Among the most-used methods to reduce the dimension of data are Principal Component Analysis (PCA) and Factor Analysis (FA) (more in
Section 2). The source data from an IF set accurately reflect the nature of the component under investigation. In the classical case of the use of methods PCA and FA, we examine the sample only from a one-sided view. In the case of data from an IF set, the sample is examined from two views: membership function and non-membership function. Alternatively, we can talk about up to three views if we include the degree of uncertainty of the IF set of a given data sample. The degree of uncertainty can be defined for each IF set in
by the formula
while
for each
[
15].
Based on the above, an IF set better describes the character of the studied compounds. The paper aims to show the use of data from an IF set to address a specific example for known methods used to reduce the dimensions of the data set. The comparison of methods with classical theory and the comparison of methods with each other are used to reduce the dimensions of the data set. The rest of the paper is organized as follows:
Section 2 contains the methods’ description.
Section 3 defines the correlation between IF sets.
Section 4 contains the specific example of the use of Principal Component Analysis and Factor Analysis methods.
Section 5 contains the conclusion, a comparison of methods and a discussion.
2. Methods’ Description
Principal Component Analysis (PCA) was introduced in 1901 by Karl Pearson [
16]. The method aims to transform the input multi-dimensional data so that the output data of the most important linear directions is obtained, with the least significant directions being ignored. Thus, we extract the characteristic directions (characters) from the original data and at the same time reduce the data dimension. The method is one of the basic methods of data compression—original
variables can be represented by a smaller number
of variables while explaining a sufficiently large part of the variability of the original data set. The system of new variables (the so-called main components) consists of a linear combination of the original variables. The first main component describes the largest part of the variability of the original data set. The other major components contribute to the overall variance, always with a smaller proportion. All pairs of main components are perpendicular to each other [
17]).
The basic steps of the PCA include the construction of a correlation matrix from source data, the calculation of eigenvalues of the correlation matrix, the alignment from the largest , the calculation of eigenvectors of the correlation matrix corresponding to its eigenvalues , the calculation of the variability of the original data , the determination of the number of main components sufficient to represent the original variables based on variability and the transfer of the original data to a new base. The number of major components (MC) is determined either by our consideration of the need to maintain information (eigenvalues, which explain e.g., 90% of variability). By Kaiser’s Rule using those MC whose eigenvalue is greater than the average of all eigenvalues (with standard data, the average is 1, i.e., taking the MC, whose eigenvalue is greater than 1), we use MC, which together account for at least 70% of the total variance, or based on a graphical display, the so-called Screen Plot chart, where we find a turning point in this chart and take MC into account for this turning point.
Factor Analysis (FA) was introduced in 1904 by Charles Edward Spearman and described in 1995 by Bartholomew D. J. [
18]. This method allows new variables to be created from a set of original variables. It allows you to find hidden (latent) causes that are a source of data variability. With latent variables, it is possible to reduce the number of variables while keeping the maximum amount of information, and to establish a link between observable causes and new variables (factors). If we assume that input variables are correlated, then the same amount of information can be described by fewer variables. In the resulting solution, each original variable should be correlated with as few factors as possible, and the number of factors should be minimal. The factor saturations reflect the influence of the
th common factor on the
th random variable. Several methods are used to estimate factor saturation, so-called factor extraction methods. In our paper, we used the method of the main components. Other known methods include the maximum plausibility method or the least-squares method.
The number of common factors can be determined either by the eigenvalue criterion (the so-called Kaiser’s Rule), when factors which have their eigenvalues
are considered significant. The reliability of this rule depends on the number of input variables (if the number of variables is between 20 and 50, the rule is reliable, if the number is less than 20, there is an erroneous tendency to determine a smaller number of factors, and if the number is greater than 50, this leads to a false determination of a large number of factors) and the criterion of the percentage of explained variability when common factors should explain as much as possible the total variability. Alternatively, it depends on the Screen Plot chart of eigenvalues (it is recommended that several factors be used; they are located in front of the turning point on the chart). The basic steps of FA are the selection of input data (assumption of correlation), the determination of the common factors, the estimation of parameters (if the communality is less than 0.5, it is appropriate to exclude the given indicator from the analysis), the rotation of factors (Varimax Method—orthogonal rotation) and the factor matrix (factor saturation matrix). High factor saturation means that the factor significantly influences the indicator. Those factors whose absolute value is greater than 0.3 are considered to be statistically significant, medium significant factors are those with an absolute value greater than 0.4, and very significant factors are those with an absolute value greater than 0.5 [
17]. The main idea of the methods is to reduce the number of variables (reduce the dimension of the data file) while maintaining the highest variability of the original data. For both methods we need the construction of a correlation matrix from source data. Therefore, we need to define the correlation coefficient for IF sets.
4. Use of PCA and FA Methods
We have selected the 20 most sold car brands for 2020 (we tracked sales for a period of 12 months). The data come from our own survey, in which we asked car dealers in two cities (Nitra and Žilina, Slovak Republic) about the best-selling car brands in 2020. There were 20 brands listed and 5 criteria were assessed (the criteria were not specifically selected, they were created on the basis of most common questions that buyers ask when buying a car): A—power, B—equipment, C—price, D—driving properties, E—consumption. Each criterion was evaluated twice: the percentage the criterion is met for each participant and the percentage the criterion is not met. The results are in
Table 1 below.
Data A, B, C, D and E from
Table 1 are assigned the competence and incompetence functions. Since the values in
Table 1 are expressed as percentages, we can easily assign the competence function of the values in the “met” column and the incompetence function to the values in the “not met” column, provided
that a
for A, B, C, D, and E. Then these values are IF data. From the relationship (1.1) we calculate the degree of uncertainty for A, B, C, D, and E (
Table 2).
First, we will conduct the Principal Component Analysis. We start by calculating the values of the correlation matrices from the values of the input variables of the competence function
, the incompetence function
and the degree of uncertainty
. We calculate the values of the correlation matrices from Equations (1.3)–(1.5).
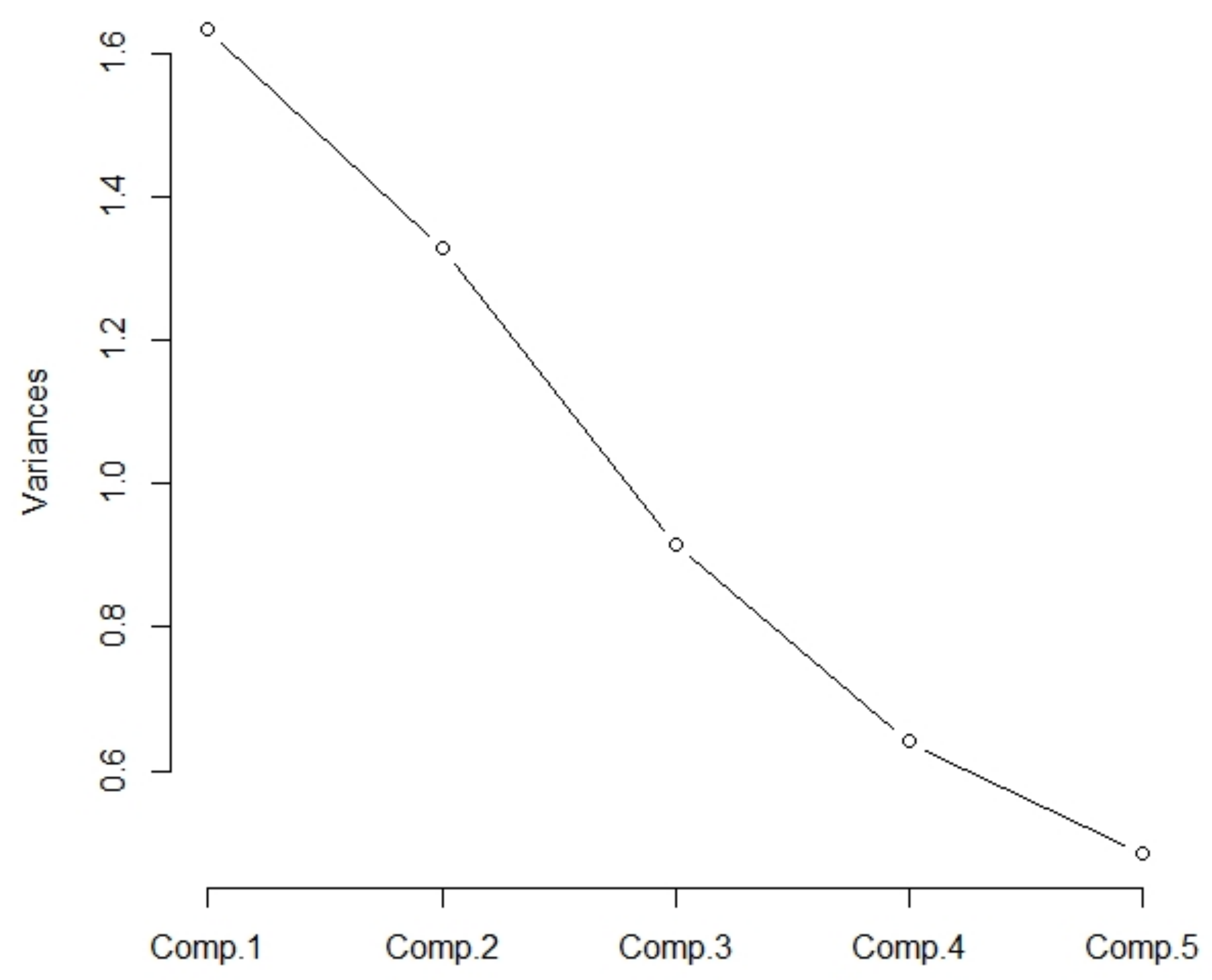
The eigenvalues of the correlation matrix
are:
1.6328865,
1.3278224,
0.9150624,
0.6406398,
0.4835889. The variability of the input variables (sum of the elements on the main diagonal = sum of the eigenvalues of the correlation matrix) is
5. The eigenvalues are displayed on the charts (
Figure 1,
Table 3). From the graph, we can see that the turning point is behind the third component. Additionally, according to Kaiser’s Rule, the first two components are considered.
In the row “Standard deviation”, there are the values of the main components, hence . In the row “Proportions of Variance”, there are the shares of variability . And in the row “Cumulative Proportion”, there are the cumulative shares of variability. We can see that the first two components meet 77.52% of the input data variability.
We will do the same for the values of the incompetence function input variables and the degree of uncertainty.
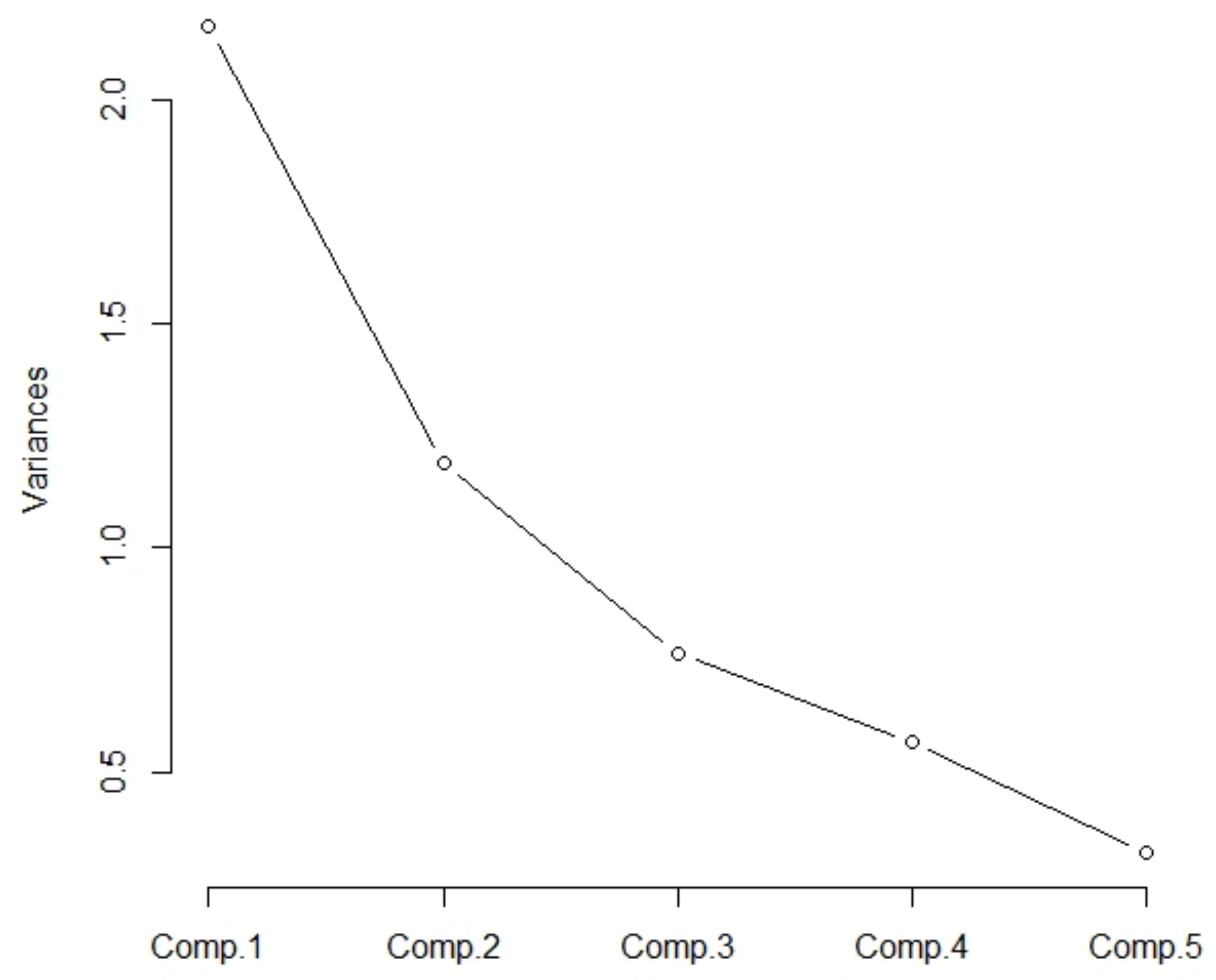
The eigenvalues of the correlation matrix
are
2.1645080,
1.1884539,
0.7637763,
0.5663754,
0.3168864. The variability of the input variables is
. The eigenvalues are displayed on the charts (
Figure 2,
Table 4). According to the graph, the turning point could be located after the second component. Both the first two components are considered from the graph and the Kaiser Rule.
The first two components meet 67.06% of the input data variability, which is insufficient. The first three components meet 82.33% of the input data variability, which is permissible.
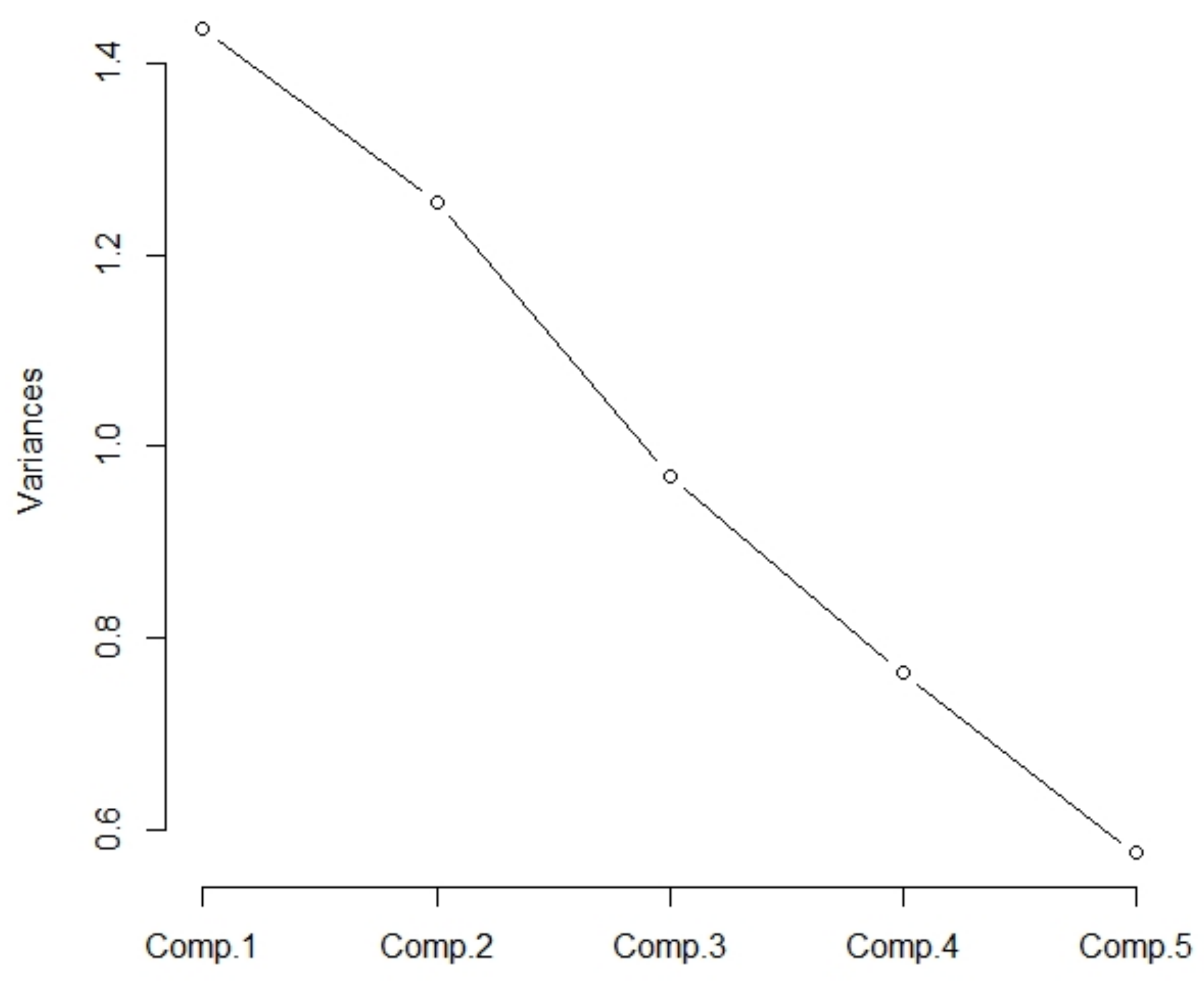
The eigenvalues of the correlation matrix
are
1.4352248,
1.2553099,
0.9695103,
0.7644114,
0.5755435. The variability of the input variables is
. The eigenvalues are displayed on the charts (
Figure 3,
Table 5). The turning point would be located behind the second component according to the graph. According to Kaiser’s Rule, the first two components are considered.
The first two components meet 53.81% of the input data variability, which is insufficient. The first three components meet 73.2% of the input data variability, which is permissible.
Now we calculate the correlation matrix R for the complete correlation of components according to (1.2).
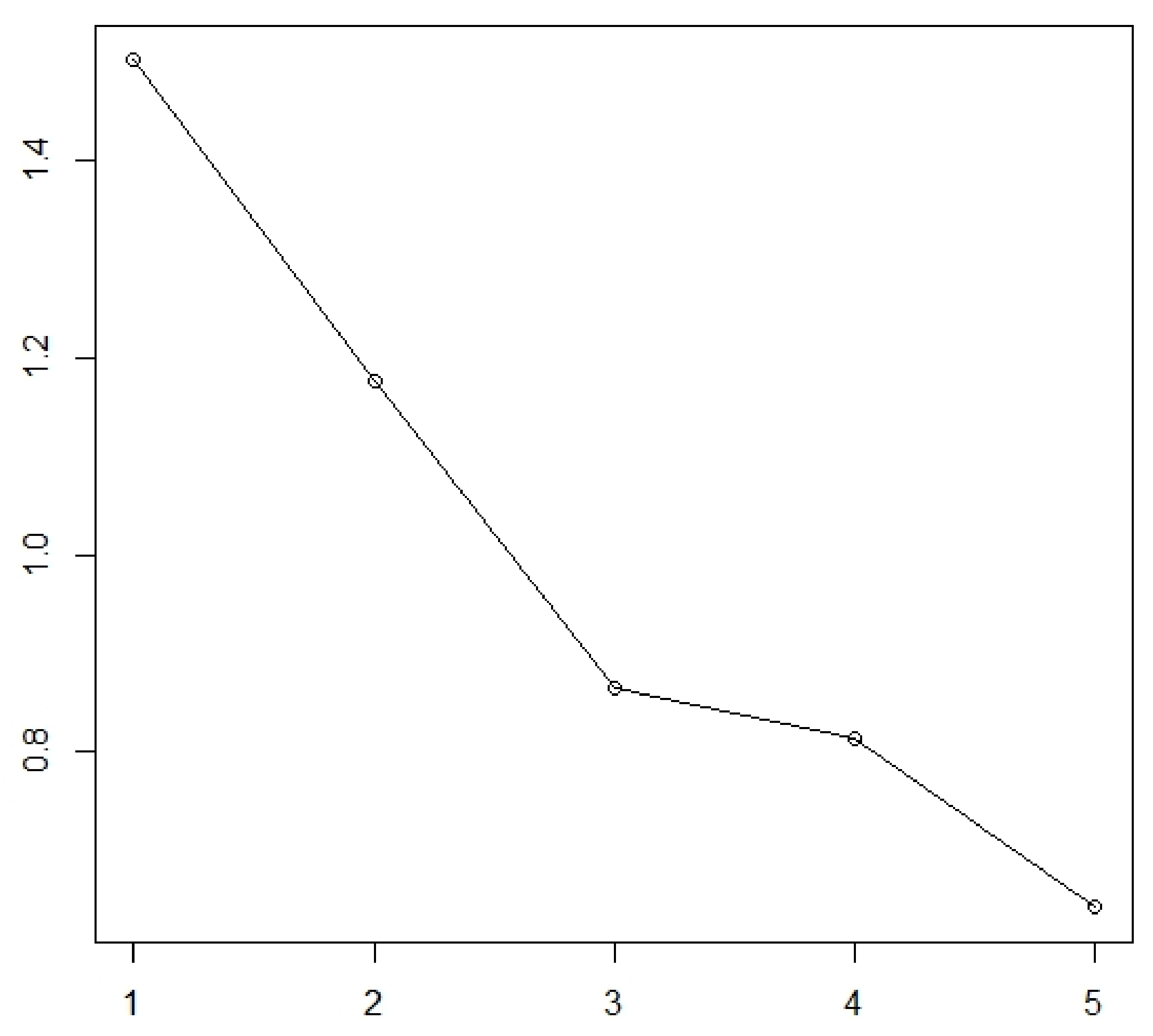
The eigenvalues of the correlation matrix R are
1.5023867,
1.1774258,
0.8652105,
0.8134299,
0.6415472. We will display them on the chart (
Figure 4).
From the graph, it is visible that the turning point is located behind the third component. According to Kaiser’s Rule, the first two components which are considered meet 53.6% of the input data variability, which is insufficient. Therefore, we will consider the first three components that meet the 70.9% of input data variability, which is sufficient.
From the results received so far, we can determine the number of main components at 3. The results of the overall correlation also enable a reduction in the dimension from five to three, i.e., the original 5 components can be replaced by three main components while maintaining 70.9% of the original data variability.
We mark the eigenvectors of the covariance matrix
as
. Similarly, we mark our eigenvector of the covariance matrix
as
and the eigenvectors of the covariance matrix
for
. The results of PCA are summarized in
Table 6. The columns in the table represent the first three eigenvectors of the covariance matrices
,
,
. The main components are obtained by multiplying the eigenvectors with the original data.
In this way, we will gain a reduction in the dimension of the original data from five to three.
We will also address the cases of Factor Analysis based on the PCA method. Input data are shown in
Table 2. The correlation matrices and their eigenvalues are calculated in the previous instance of the PCA method. As the number of input variables is 20, we are offered at least two criteria to determine the number of factors. The eigenvalue criterion determines for us two important factors (we can see this with eigenvalues of the correlation matrices
,
,
; only the first two values are greater than 1 in any case).
From the chart of eigenvalues,
Figure 1, we can see that the turning point is behind the third component. From the graphs
Figure 2 and
Figure 3, we can see that the turning point is at the second component in both cases. Let us have a look at the variability of the data. If two factors are considered, data variability is very low in all cases. At three components, data variability is greater than 70%, so it is sufficient. Hence, we will further consider three factors. We will first solve the case of Factor Analysis (hereinafter FA) for the input data of the competence functions
. The first three factors represent 77.52% of the input data variability. We perform the FA using the R program (
Table 7), and we use the
Varimax method to rotate the factors.
At the output, we have a calculated matrix of factor saturation after rotations (columns RC1-RC3). In column h2, there are values of the communalities. We can see that the first factor (the first column of RC1) is highly saturated in the second and fourth variables. The second factor (column RC2) is highly saturated in the fifth variable. The third factor (column RC3) is highly saturated in the first variable. In the third variable, saturation is not high enough for either factor. The values of communalities are sufficiently high, so we can consider presenting the original five variables with three variables.
Let us try to exclude the third variable from the original data and repeat the FA (
Table 8) without this variable. In this case, the first three factors represent 86.05% of the variability.
From the output, we can see that the factor saturation matrix is factorially clean because it has high factor saturation with just one factor. The values of communalities are sufficiently high. It is confirmed that we can use three factors instead of the original five variables.
Next, we address the case of FA (
Table 9) for input data of incompetence functions
. The first three factors represent 82.33% of the variability of the input data.
We can see that the values of communalities are sufficiently high. In the first four variables, the matrix has high factor saturation with just one factor, but the fifth variable is highly saturated with a second factor. Additionally, the first factor, where saturation is greater than 0.4, is statistically significant.
We will try to exclude one variable. Let us delete the third variable as in the previous case. In this case, the first three factors represent 92.04% of the variability (
Table 10).
The factor saturation matrix is factorially clean. The values of communalities are sufficiently high. It is confirmed that we can use three factors instead of the original five variables.
We will still solve the case of FA (
Table 11) for input data of degree of uncertainty
. The first three factors represent 73.2% of the variability of the input data.
We can see that the values of communalities are sufficiently high. The matrix is not completely factorially clean. We will, therefore, try to exclude the third variable, as in the previous cases. Then, the first three factors represent 82.06% of the input data variability (
Table 12).
The factor saturation matrix is factorially clean. The values of communalities are sufficiently high. It is confirmed that we can use three factors instead of the original five variables.
In this way, we will gain a reduction in the dimension of the original data from five to three.
5. Conclusions, Comparison of Methods
The aim of our work was to extend the use of IF sets in probability theory and statistics and to verify the behavior of IF data in solving the problem of multidimensional data analysis. We dealt with the issue of reducing the size of the data file while maintaining sufficient variability of the data (that is, to preserve sufficient information that the data carries). We applied the methods to the IF sets and then interpreted them on a specific example from common practice. In our example, we have described in detail the behavior of the given methods on IF sets in three directions through membership function, non-membership function and hesitation margin.
If we examine the data from three perspectives (membership function, non-membership function and hesitation margin) using the PCA method and Kaiser’s Rule, we are able to reduce the dimension of the data from five to two. With such a reduction, the variability is too low. We achieve the sufficient variability when reducing the dimension from five to three, which we also confirmed by the FA method. Thus, both methods allow the dimension of the original data set to be reduced from five to three while maintaining sufficient variability of the original data.
Similarly, in the classical case when using the PCA and FA methods, a reduction of the dimension from five to three is permissible. In this case, the variability of the data is lower, i.e., it retains less information of the original data. Thus, we can say that based on the solved example, we came to the following conclusion: The proposed reduction of data dimension by PCA and FA methods is the same in the classical case as in the use of data from IF sets, but when examining data from IF sets in three directions, a higher variability of data remains.
In this paper, we presented a new approach in solving PCA and FA methods using three data perspectives from IF sets (membership function, non-membership function and hesitation margin), which better describe the sample and maintain higher data variability when reducing the dimension.









{kind=link}
{kind=link}
{kind=link}
{kind=link}