1. Introduction
Many questions originating from the classical works of P. L. Chebyshev and A. A. Markov on approximation methods are of significant theoretical and great practical importance. The generalized Markov moment problem is closely related to problems of geometry, algebra, and function theory. From this point of view, it is possible to study not only tasks of the Petersburg mathematical school “on the limiting values of integrals”, but also problems of the theory of approximation, interpolation and extrapolation in various classes of functions [
1].
It is also interesting that not only the main theorems and statements and the accompanying auxiliary and preparatory results help solve applied problems. It turned out to be possible to use some of them to solve modern artificial intelligence problems, such as machine-learning methods. Today, several types of machine learning are known: supervised, semi-supervised, unsupervised, and reinforcement learning. Unsupervised learning is a type of machine learning that makes decisions or searches for patterns in a set of unlabeled data. He is designed to solve three types of problems: clustering, dimensionality reduction, and anomaly detection.
Cluster analysis is a multivariate statistical procedure for training a set of labels on a sample of unlabeled data. The range of applications of cluster analysis is extensive: it is used in archeology, medicine, psychology, chemistry, biology, public administration, philology, anthropology, marketing, sociology, geology, and other disciplines. However, the universality of application has led to the emergence of many conflicting terms, methods, and approaches. This universality complicates the unambiguous use and consistent interpretation of cluster analysis. There are many clustering algorithms, and it is difficult to say which one will be the most adequate for a given dataset.
Hierarchical methods form a tree-like structure of cluster formation, which is commonly called a dendrogram. New clusters are formed from the previously formed clusters [
2,
3]. Another approach to solving the clustering problem in Euclidean space is based on the estimation of the distribution density of the elements of the sample population, for example, the methods DBSCAN [
4] and OPTICS [
5,
6]. Splitting methods break objects into a priori a given number of clusters. They are used to optimize the similarity function of objective criteria, for example, when distance is the main parameter. The most famous of these algorithms is the K-means method [
2,
3]. Grid-based methods form the data space as a finite number of cells that form a grid-like structure. All clustering operations performed on these grids are independent of the number of data [
7].
In statistics, machine learning, and information theory, dimensionality reduction is the transformation of data, which reduces the number of variables by deriving the principal variables. Dimensionality reduction of the data removes redundant or highly correlated features and reduces the amount of noise in the data. This transformation of data allows simpler mathematical models that are easier and more transparent to interpret. In practice, the following methods are commonly used for dimensionality reduction: Principal Component Analysis, Uniform Manifold Approximation and Projection, Discriminant Analysis, and Autoencoders [
8,
9].
The task of anomaly detection is to identify data significantly different from the typical elements of some set. Anomalies are also referred to as outliers, novelties, noise, deviations, and exceptions [
10,
11]. In particular, in the context of network intrusion detection, objects of interest are often not rare objects but unexpected bursts of activity. This pattern does not follow the general statistical definition of an outlier as a rare object, and many outlier detection methods (in particular, uncontrolled methods) do not work with such data [
12].
Sometimes we can consider anomaly detection by unsupervised machine-learning methods as a sequential statistical analysis of monotone trajectories of a discrete quasi-deterministic process . For example, solving cluster analysis problems, solid mechanics problems, molecular biology, switched systems, etc.
The main idea of the approach proposed in this article has a pioneering character and is as follows. If a quasi-deterministic process with monotone trajectories is studied, then the moment of the change in the character of their increase from linear to nonlinear type may coincide with a qualitative change . Analytically, this moment can be determined by comparing the squared error of the linear approximation of the trajectory with the squared errors of the nonlinear approximation of the same trajectory. The difference in such errors is a quadratic form. This quadratic form changes the sign at the point if the point is of qualitative change of the trajectory . The coefficients of the approximating functions are sought using the least-squares method by of the , from the left semi-neighborhood of the point .
It is noteworthy that in our study, we use a whole set of mathematical concepts bearing the name of the outstanding Russian scientist A. A. Markov. In addition to the constructions accompanying the generalized problem of Markov moments, this is a Markov decision process, a Markov moment in time in the theory of random processes, and a Markov chain with memory.
2. Quasi-Deterministic Processes, Markov Moments and Markov Decision Process
Let
be a finite subset of the sequence of natural numbers. The family
of random variables
, given on the probability space
is called a discrete random process [
13,
14]. Each random variable
generates an
-algebra, which we will denote by as
[
15]. The
-algebra generated by the random process
is the minimal
-algebra containing all,
i.e.,
If we fix a time, t then obtain a random variable . If we fix a random event , then obtain a trajectory of the random process , which is a random sequence .
Random processes can be divided into two classes: quasi-deterministic processes and non-deterministic processes. We will consider only quasi-deterministic processes with monotonic trajectories. A random process
is called quasi-deterministic if all sequences
are functions of time of a given form, but each of them depends on a random parameter
. In general,
can be a randomly selected number, a random vector, a random sequence, or a random function. The main property of any quasi-deterministic process is that each random event
corresponds to only one trajectory
of the random process
[
16].
2.1. Markov Stopping Time
We will consider the binary problem of testing the statistical hypotheses and . The null hypothesis —the sequence increases linearly, and the alternative hypothesis —the sequence increases nonlinearly.
To test a statistical hypothesis, it will be necessary to construct a criterion allowing it to be accepted or rejected. Statistical criteria are based on a random set
X. Two variants are possible; in the first, the sample
X is extracted from the
n -dimensional Euclidean space
at once, i.e., it has a fixed volume. The second, when the sample
X is generated over a period of time, and its size is a random variable [
17]. A combined case is possible when
X is extracted from
at once, and then its variable size subsample is studied, which is formed by mapping
X into itself. In the last two cases, one speaks of sequential statistical analysis and sequential statistical test [
18,
19].
Decision-making at a certain moment of time can be based only on the known values of the discrete process
. If we use a formal approach, then the events under study should be measurable in a non-decreasing sequence of
-algebras
generated by the process
[
20]. On the probability space,
such a sequence is considered to be a family of
-algebras
and is called a filtration if for
. The map
is called the Markov moment with respect to the filtration
, if for
is the preimage of the set
. If moreover
, then
is called the Markov stopping time [
21].
For example, a random event
belongs to
from the previously introduced probability space
. If this random event
is the extraction of a finite set
X from the
n-dimensional Euclidean space,
then any point
can belong to the set
X. By definition, the
-algebra from the
contains all
. In addition, this
-algebra contains any finite set
X from the space
, all possible countable unions of such sets and complements to hims. We denote this system of sets as
. The same reasoning is valid for any
-algebra
, therefore
These
-algebra
will be filtration for
[
22,
23].
If a random event is the extraction of a countable set X from the n-dimensional Euclidean space , then the filtration for will again be the -algebra . If the event is some random function , then the filtration for is Borel’s -algebra .
In all these cases, the Markov stopping time is the minimum value at which the null hypothesis is rejected— (the trajectory of the quasi-determinate process increases linearly) and an alternative hypothesis is accepted— (the trajectory of the quasi-determinate process increases nonlinearly).
2.2. Approximation-Estimation Tests
To test the statistical hypotheses
and
, we use the approximation-estimation tests [
24,
25]. We will construct quadratic forms of approximation-estimation tests as the difference between the quadratic error of the linear approximation of the numerical sequence
and the quadratic error of the nonlinear approximation of
in various classes of nonlinear functions.
Let us use the concept of an approximating function. Ordered pairs
are the knots of approximation for the numerical sequence
where
i is a natural argument,
is the corresponding value of the sequence
. We will be called
the natural knot of approximation [
24,
25].
The segment of the real axis , on which the knots are located, will be called the “current interval of approximation”.
Let a real function
belong to class
Y. The function
approximates a numerical sequence
by the least-squares method if
There is always such the minimum since is a positive definite quadratic form.
The quadratic error of approximation of the numerical sequence
by an arbitrary nonlinear function
is equal to the sum of the squares of the differences
and
at the knots
for the corresponding values of the natural argument.
The quadratic error of
linear approximation with respect to the same knots is equal to:
If in our reasoning, the specific number of approximation knots does not play a role, then the quadratic errors will be denoted by
and
. These errors calculate from Formulas (
3) and (
4) respectively.
Let us introduce the notation: .
We assume by definition that the increase in the numerical sequence along the knots is linear if . Otherwise, the increase in has a nonlinear character. If , then the point is called “critical”.
When constructing quadratic forms of approximation-estimation tests, can use a technique that facilitates calculations. The values of
can be taken at the points,
assuming that
. This condition can be easily achieved at any approximation step using the transformation:
It is possible to construct several approximation-estimation tests, for example, logarithmic, parabolic, exponential, etc. In the general case, the approximation-estimation test can be formulated as follows.
Let
. We will say that at the left semi-neighborhood of the point
k (between points
and
k) is the character of the increase of the sequence
has changed from linear to nonlinear, if the following conditions hold: for the knots
is true
, and for the knots
is true
. If we use terms of sequential statistical analysis, then the Markov stopping time for a quasi-deterministic process
, with a random parameter
and a monotonically increasing trajectory
is
where in the null hypothesis
is rejected, and the alternative hypothesis
is accepted.
2.3. Markov Decision Process
Let us move to decisions by unsupervised machine-learning methods. We will use the formal apparatus Markov decision process (MDP) for this. MDP is a discrete-time stochastic control process. It is used to make decisions in situations where the results are partly random and partly under the control of the decision-maker [
26,
27]. The MDP is in some state
s at every moment, and the decision-maker can choose any action
a available in the state
s. In response, the MDP randomly transitions to the new state
at the next time step and gives the decision-maker a reward
.
The probability of the process entering the new state depends on the action chosen. This probability is given by the function of transition to a new state . Thus, the next state of depends on the current state of s and the action of the decision-maker, a. Therefore, we can say that the next state does not depend on all previous states and actions, i.e., MDP satisfies the Markov property.
Markov’s decision-making processes are generalizations of Markov chains; the difference lies in adding actions and rewards.
Formally, the MDP is an ordered set of four elements , where:
S—set of states (state space),
—set of actions (action space) available from the state s,
—the probability that the action a in state s and at time t will lead to state at time ,
—reward received after executing action a and transition from state s to state .
The goal of the Markov decision process is to build a “good strategy“ for the decision-maker. This strategy is made to maximize some cumulative random reward function.
The MDP for quasi-deterministic random processes with monotone trajectories degenerates into a special case when all states S are linearly ordered into a sequence of a given form , i.e., for each state S there is only one action, the transition from to, with the probability either 0 or 1. Rewards also take two values, which, by definition, will be considered equal to either 0 or 1. When using approximation-estimation tests, the decision on the amount of remuneration is based on the Markov stopping time, for determining which are used , from the left semi-neighborhood of the point .
By definition, a Markov chain with memory of order
k is a process that satisfies the condition:
where
, i.e., the future state depends on
k the past states and the set
is such that
has the Markov property [
28,
29].
In the case of using approximation-estimation tests, the formation of a new set of points , from the left semi-neighborhood points , can be considered to be some random event , and it will correspond to a certain value of the quadratic form of the approximation-estimation test, which we denote as .
Consider a sequence of random events: with a two-element set of outcomes , where outcome C is the event and B—event . Since the probability of occurrence of either C or B depends only on the set , then the sequence of random events is a Markov chain with memory of order k. Consequently, the MDP, based on approximation-estimation tests for quasi-deterministic random processes with monotone trajectories, can be considered a Markov chain with memory of order k. In this case, decisions are made at the expense of the Markov stopping time, and, by definition, the decision-maker receives a maximum remuneration equal to 1.
3. Parabolic Approximation-Estimation Tests
We will distinguish between the complete parabolic approximation in the class of functions
, and incomplete parabolic approximation in the class of functions
. Let us denote the quadratic error of the complete parabolic approximation over
k knots
as
In addition, let us denote the quadratic error of incomplete parabolic approximation for the same knots as
It is known that a complete parabolic approximation is always no worse than a linear one, i.e., the inequality is true . If we consider the incomplete parabolic approximation, then it is always no better than the complete parabolic approximation, i.e., the inequality holds.
When comparing and three cases are possible:
3.1. Quadratic Errors of Linear Approximation of Natural Knots
The least-squares method will be using for calculating the coefficients
of the function of two variables
We calculate the partial derivatives of this function
and we are solving the corresponding system of linear equations.
According to Cramer’s rule,
where
then
We use Formulas (
4) and (
15), to explicitly write down linear approximating functions over natural knots. Let us calculate the square-law errors for three, four, five, six, and seven natural knots.
For natural knots,
the linear approximating function has the form:
Similarly for knots
For knots
For knots
And for knots
3.2. Quadratic Forms of Parabolic Approximation-Estimation Tests
The least-squares method will be using for calculating the coefficients
of the function of two variables
Let us calculate the partial derivatives:
and solve the system of two linear equations for the unknowns
We use Formulas (
9), (
26) and (
27), and write incomplete parabolic (without linear term) approximating functions for natural knots. Let us calculate the quadratic errors for them, and then, taking into account the corresponding errors of the linear approximation (Formulas (
17)–(
21)), write quadratic forms for the parabolic approximation-estimation tests
for three, four, five, six and seven knots.
For knots
obtain
Likewise for knots
For knots
For knots
And for knots
In the general case, the parabolic approximation-estimation test has the form:
If the inequality
holds for natural knots
, but for knots
, holds
, then we can say that near the point
the character of the increase
changed from linear to parabolic [
24,
25], i.e., under the condition
the null hypothesis
is rejected, the alternative hypothesis
is accepted, and the Markov stopping time for the parabolic approximation-estimation test will be
It is important to note that in all cases, the point is an “upper estimate” for the corresponding critical value of the monotonically increasing numerical sequence .
3.3. Solution of Inverse Problem and Remark on Finite Differences
Of particular interest is the solution of the “inverse problem”. Specifically, let the values of the sequence at the knots be known, and it is required to determine at what value in the knot we can say that the character of the increase of the has changed from linear to parabolic. In other words, it is necessary to calculate at what numerical value the point will become critical.
Let us solve this problem for the knots .
Equated to zero the quadratic form
, and replace
by
x obtain the quadratic equation
for which
Considering that
and
we will obtain
Now we can answer the frequently asked questions. First, “Why can’t we limit ourselves to a simple comparison of finite differences?” Here we mean that when passing to a parabolic increase, the finite difference is greater than the previous finite difference , i.e., . The following second question arises: “What is equal K at the critical value of ”?
Let us look at an example that answers these questions.
We will use Formula (
43) to determine the critical value wheat the knot
if known knots
.
First, let
0.1,
0.2. Then, by Formula (
43)
0.381128. Let us calculate the ratio of finite differences for the obtained critical value
and obtain that
1.8112. The value
1.8113 corresponds to “already” parabolic increase, and the ratio of finite differences
1.8111 is to a linear change in the sequence
.
For knots
1.1,
2.3 by Formula (
43)
4.32486, the quotient
1.687385. In addition, finally for
0.1,
0.3 by Formula (
43)
0.513579, the quotient
1.06785.
Thus, for three different sets of knots
and the critical value at the point
, were received different the ratio of the first order finite differences. Consequently, the comparison of finite differences of elements of the sequence
cannot be used to obtain a criterion determining the point of change of character of increase for the
[
25].
4. Approximation-Estimation Tests with Irrational Coefficients
Let us construct approximation-estimation tests for four classes of nonlinear functions: of exponential—, of logarithms—, of arctangents—, and of square-roots .
In the general case, for all these functions, the coefficients of the corresponding quadratic forms are irrational numbers. Therefore, in contrast to parabolic approximation-estimation tests, these coefficients can be calculated only approximately.
It is easy to see that all four approximating functions have the same structure concerning unknown coefficients and : . Using the least-squares method, we will calculate these coefficients.
Let us find the local minimum of a function of two variables
First, we will calculate the partial derivatives of the function
and equate them to zero.
Then we solve the system of linear equations for the unknowns
and
We will construct the approximation-estimation tests by three, four, and five natural knots for exponentials, logarithms, argtangentials functions, and square-roots.
4.1. Exponential Approximation-Estimation Tests
The quadratic approximation error by natural knots in the class of exponential functions
is
When we use Formulas (
48) and (
49) and we obtain:
In generalized, the exponential approximation-estimation test has the form:
If for knots
is valid
, and for knots
the inequality
, then the character of growth of
changed from linear to exponential, i.e., in this case, the null hypothesis
is rejected, the alternative hypothesis
is accepted. Then the Markov stopping time for the exponential approximation-estimation test will be
Similar to the construction of parabolic approximation-estimation tests, we will calculate the coefficients of quadratic forms for exponential, logarithmic, arctangential, and square-root tests.
For an exponential test by three knots:
we obtain:
For knots
And for knots
4.2. Logarithmic Approximation-Estimation Tests
The quadratic approximation error by natural knots in the class of logarithm functions
is
When we use Formulas (
48) and (
49) and we obtain:
In generalized, the logarithmic approximation-estimation test has the form:
If for knots
the inequality
is valid, and for knots
the inequality
, then the character of growth of
changed from linear to logarithmic. When this condition is met, the null hypothesis
is rejected, the alternative hypothesis
is accepted, and the Markov stopping time for the logarithmic approximation-estimation test will be
For knots:
we obtain
For knots:
And for knots:
4.3. Arctangential Approximation-Estimation Tests
The quadratic approximation error by natural knots in the class of arctangential functions
is
When we use Formulas (
48) and (
49) and we obtain:
In generalized, the arctangential approximation-estimation test has the form:
If for knots
the inequality
is valid, and for knots
the inequality
, then the character of growth of
has changed from linear to arctangential. When this condition is met, the null hypothesis
is rejected, the alternative hypothesis
is accepted, and the Markov stopping time for the arctangential approximation-estimation test will be
For knots:
we obtain
For knots:
And for knots:
4.4. Square-Root Approximation-Estimation Tests
The quadratic approximation error by natural knots in the class of square-roots functions
is
When we use Formulas (
48) and (
49) and we obtain:
In generalized, the square-root approximation-estimation test has the form:
If for knots
the inequality
is valid, and for knots
the inequality
, then character of growth of
has changed from linear to parabolic of degrees the half. When this condition is met, the null hypothesis
is rejected, the alternative hypothesis
is accepted, and the Markov stopping time for the square-root approximation-estimation test will be
For knots:
we obtain
For knots:
And for knots:
5. Integral-Estimation Tests
Let us consider a generalization of the approximation-estimation tests for the continuous case. We will consider continuous and non-decreasing functions on the segment . The class of such functions will be denoted by M, i.e., .
Let us study the problem of classifying by the character of their increase on the segment . We will choose the following etalons for such a classification by analogy with the approximation-estimation tests: linear functions —, parabolic functions—, exponential functions—, logarithmic functions—, arctangent functions— and square-roots—.
All these functions are equal to zero at the point 0. Any function
can be changed using the transformation
so that it also satisfies the condition
. Additionally, we accept the agreement that undefined coefficients for etalon functions must satisfy the condition
and then:
The purpose of classification will be to determine the nature of the increase in
. We note that the integral characteristic of the speed is the distance traveled. Therefore, if being compared to two speeds, then the criterion could be the difference in the distance traveled. Based on this, we will define the criterion comparison rate of change of two functions
as an integral
The geometric meaning of this criterion is that estimates the area of a flat closed region bounded by the continuous curves and .
Let us introduce the notation
and by definition, we say that the continuous function
“almost linearly” increases on the segment
if the inequality is true:
, where index
, otherwise, the change in
will be considered nonlinear.
To determine the point at which the linear increase of
becomes nonlinear, it is necessary to compare this function with the etalons
,
, where
. We will calculate two integrals with variable upper limit:
Then the solution to the equation
with respect to the unknown
x is the “critical point”
b, at which the linear increase of
changes to nonlinear.
5.1. Tangential Test for a Discrete Case
We will consider a simple computational experiment will be called the tangential test. We use as a model function. As is known, in a neighborhood of zero . When the argument t tends to on the left, the function is infinitely large and approaches the vertical asymptote . Therefore, on the interval there must be a point to the left of which the ascending is closer to linear, and to the right of it, the function is more precisely approximated by a parabola. According to a previous convention, such a point is called the critical value of the argument.
Table 1 (adapted from [
25]) shows the results of the tangential test for the approximation-estimation tests by three, four, five, six, and seven approximation knots; the values of the
were calculated by Formulas (
30)–(
38). It is important to note that the character of an increase in any variable does not depend on the scale. Therefore, before using the indicated formulas, the corresponding similarity transformation was performed so that the discreteness step becomes one.
In the left column of the table, the initial (before similarity transformation) value of the discreteness step is indicated, in the following columns, the value of the minimum upper estimate for the critical value of the argument for three, four, five, six, and seven knots of approximation, respectively.
It is easy to see that as the discreteness step decreases, the critical point shifts to the right, closer to the vertical asymptote. At the same time, with an increase in the number of approximation knots, the critical point at the same discreteness step shifts to the left.
Let us pay attention to the following fact: sometimes, when the discreteness step decreases, monotonically of the increase in the minimum upper bound for the critical value of the argument is violated. The explanation for this phenomenon is simple: for example, for seven points with a discreteness step of
, the critical value of the argument for
lies in the interval
. When the discreteness step decreases to
, such a point, although it shifts to the right, is within the interval
[
25].
5.2. Tangential Test for a Continuous Case
We will be based on the results of the discrete tangential test. We can assume that as the number of approximation knots increases, the upper bound for the critical value of the function argument will tend to the minimum value. Integral-estimation tests generalize approximation-estimation tests in the continuous case. It can be assumed that they are corresponding to an infinite number of approximation knots. For the parabolic approximation-estimation tests, it was shown that the minimum upper estimate for the critical point is equal to . Let us solve the same problem using the integral-estimation test and compare the results.
Let us solve the same problem using the integral-estimation test, comparing with etalons functions and .
We will be to consider two integrals with the variable upper limit:
Let us calculate
as a function of
x.
For
the function
can be expanded in a power series [
30]:
where
are Bernoulli numbers, then
The solution to Equation (
98) will be the critical point at which the “almost linear” increase in
changes to “almost parabolic”. Using (
94) for expressions of undefined coefficients
a,
b and Formulas (
104) and (
108) we obtain the transcendental equation:
with a unique solution
(
Figure 1).
From which it follows that on the segment the function increases “almost linearly”, and to the right, its growth becomes nonlinear. Thus, the determination of the critical growth point for using the integral-estimation test qualitatively coincides with the solution of the same problem using the approximation-estimation test, but the integral-estimation test gives a more minimum estimate.
6. Discussion
When applied problems to solve, discrete quasi-deterministic random processes with monotonically increasing trajectories are encountered quite often. For example, these are sequences of minimum distances at clustering by agglomerative methods, deformation diagrams of various materials, experimental creep curves, fluorescence accumulation curves for a real-time polymerase chain reaction, the dependence of network activity on generalized time (milliseconds, iterations, time to live, etc.) during DoS and DDoS attacks.
6.1. Analytical Generalization of the “Elbow Method” Heuristic
One of the main problems at the cluster analysis is the determination of the preferred number of clusters. Finding the moment of completion of the process itself is associated with the solution of this issue [
31,
32]. Usually, the decision on the number of clusters is made during the process of clustering, but sometimes before it starts (for example, when using the
k-means method) [
2,
3].
At present, the problem of determining the number of clusters is open. For instance, Baxter and Everitt argue that the approach to establish the true number of clusters is to use subjective criteria based on expert judgment [
3,
33]. Nevertheless, cluster analysis remains one of the main methods of preliminary typology [
34], and this necessitates the derivation of formal criteria for completing the clustering process and the rules for calculating the number of clusters.
In the overwhelming majority of modern works devoted to studying and solving these problems, the authors consider not general but various exceptional cases of clustering. We can highlight the article [
35], which describes an algorithm based on finding and evaluating jumps of the so-called index functions. Developing the ideas presented in [
35], it was proposed to use randomized algorithms for approximation of jumps of index functions [
36] to find the number of clusters.
Quite often, the determination of the number of clusters during the execution of the hierarchical agglomerative clustering process is based on a visual analysis of dendrograms [
37,
38]. However, this approach is heuristic, but heuristic methods are based on some plausible assumptions and not on rigorous mathematical inferences.
Another heuristic approach to determining the preferred number of clusters under hierarchical agglomerative clustering is called the “elbow method” [
39]. The main idea of this heuristic is that if the graph of some variable describing the clustering process resembles a hand, then the “elbow” (the point of the sharp bend in the graph) is a good indicator that we received of the preferred number of clusters. From a formal point of view, if a value increased linearly, its increase became nonlinear at the “elbow” point.
For the “elbow method” application, can be used the sequence of minimum distances between the elements of the set
X. This sequence linearly ordered with respect to numeric values:
. In Euclidean spaces, when clusters merge, there should be a sharp jump in the numerical value of the minimum distance, which is the moment of completion of the clustering process. In
Figure 2 shows a graph of the sequence of minimum distances for the model set
X. The figure shows that this jump (point
) is better approximated not by a linear function, but of a parabolic or exponential. Moreover, this point is the “elbow” of the graph.
Clustering study as a quasi-deterministic process, as its trajectories, one can consider monotonically changing numerical characteristics, including the sequence of minimum distances, where time is the iteration number of the agglomerative process. To construct statistical criteria for completing the clustering process, one can use quadratic forms of approximation-evaluative criteria, which are an analytical generalization of the heuristic of the “elbow method”. It is essential to emphasize that determining the number of clusters with their help is based not on heuristic conclusions but sequential statistical analysis.
Several clusters automatic determination is an urgent problem in many cases of preliminary typologization of empirical data. For example, in cytometric blood analysis [
40], in automatic analysis of texts [
41] both on topics [
23,
42], and by emotional coloring [
43], as well in all other cases when the number of clusters is a priori unknown.
6.2. Limits of Application of Hooke’s Law
The main requirement for any structure is that it has strength, rigidity, and stability. The calculations of these parameters are based on experimental data and assumptions made within disciplines such as structural mechanics, the strength of materials, and elasticity theory.
The main goal of studying the properties of materials under the influence of external forces is to describe the relationship between stresses and strain. Sometimes strains are determined by stresses, and sometimes, conversely, stresses are determined by strain. The elastic deformation is described by Hooke’s law, which states that the stress is proportional to the strain, i.e., the relationship between them is linear [
44,
45].
Elastic deformation study is critical primarily since it is with it that any deformation process begins: plastic deformation, highly elastic deformation, or brittle fracture. The behavior in the elastic region is of great practical importance both for the brittle states of solids and for the plastic states of materials, for which elastic deformation has a significant effect on the development of inelastic processes.
The elastic properties of a solid are related to the nature of the adhesion forces, intermolecular bonds, etc. The nature of the interatomic forces indicates that Hooke’s law is approximate, and the directly proportional relationship between stresses and deformations is an idealized scientific abstraction. However, it has been shown experimentally that Hooke’s law is observed with sufficient accuracy for most materials, but only within certain limits. If the relationship between stresses and strains becomes nonlinear, then Hooke’s law becomes inapplicable [
46].
The currently used graphical methods for determining the boundaries of the elastic zone using the stress strain curve are rather primitive. They are intended for a situation where stress is a function of deformation in the one-dimensional case [
47]. Then the transition from elastic to plastic state is characterized by a change in the type of stress increase from linear to logarithmic or arctangential (
Figure 3) [
48].
However, cases where, on the contrary, stress is a function of deformation are also of great importance. Then the transition from elastic to plastic state is characterized by a change in the type of deformation growth from linear to parabolic or exponential (
Figure 4) [
49].
Various types of approximation-estimation tests can be used to determine the scope of Hooke’s law [
22].
6.3. Singular Points of the Creep (Cold Flow) Curve
As a rule, creep (cold flow) is slow, occurring in time, deformation of a solid under the influence of a constant load. Cold flow is described by the so-called “creep curve”, which depends on deformation on time at constant temperature and force. Creep mechanisms depend both on the type of material and on the conditions under which it occurs. Its physical mechanism is predominantly of a diffusion nature, which makes it different from plastic deformation, which is associated with fast sliding along the atomic planes of grains of the polycrystal [
50].
The creep curve is conventionally divided into three sections (stages). The first stage is a section of unsteady creep when the creep rate slows down. The second stage is a section of steady-state creep when deformation occurs at a constant rate. The third stage is an area of accelerated creep. Creep curves have the same form (
Figure 5) for a wide range of materials: metals, alloys, semiconductors, polymers, ice, etc.
In the first stage of creep, the initial velocity, given by the instantaneous initial deformation, gradually decreases to a particular minimum value. At the second stage, creep occurs at a constant speed [
50]. This piece of the curve can be compared to a graph of the locus of points, in which the relationship between the abscissa and the ordinate is first linear, then logarithmic, and then linear again.
We will call the moment of change in the nature of the increase in deformation from linear to logarithmic—“the first singular point of the creep curve”.
At the third stage, the growth of deformation occurs at an increasing rate and ends with the destruction of the material. The transition from the second stage to the third is characterized by a change in the rate of increase in deformation from linear to parabolic, or exponential [
50].
We will call the moment of change in the nature of the increase in deformation from linear to parabolic or exponential—“the second singular point of the creep curve”.
Methods of analytical determination of singular points of the creep curve can be of practical and theoretical interest in both physical and computational experiments. A possible approach to solving this problem can be the use of approximation-estimation tests.
6.4. Characteristic Points for the Curves of the Real-Time PCR
Real-time polymerase chain reaction (real-time PCR, qPCR), based on the PCR method [
51], allows you to determine the presence of the target nucleotide sequence in the sample and measure the number of its copies. The amount of amplified DNA is measured after each cycle of amplification using fluorescent labels. Evaluation can be quantitative (measuring the number of copies of the template) and relative (measuring relative to the introduced DNA or additional calibration genes). For real-time PCR, the amount of product formed is monitored during the reaction by monitoring the fluorescence of the dyes introduced into the reaction. The number of fluorophores is proportional to the amount of the resulting DNA product. Assuming a specific amplification efficiency, which is usually close to doubling the number of molecules per amplification cycle, it is possible to calculate the number of DNA molecules initially present in the sample. Thanks to highly efficient detection chemistry, sensitive instrumentation, and optimized analysis methods, DNA molecules can be quantified with unprecedented precision [
52].
The fluorescence accumulation curve (fluorescence graph) for real-time PCR has a characteristic form (
Figure 6); it consists of a baseline, an exponential phase, and a plateau phase [
53].
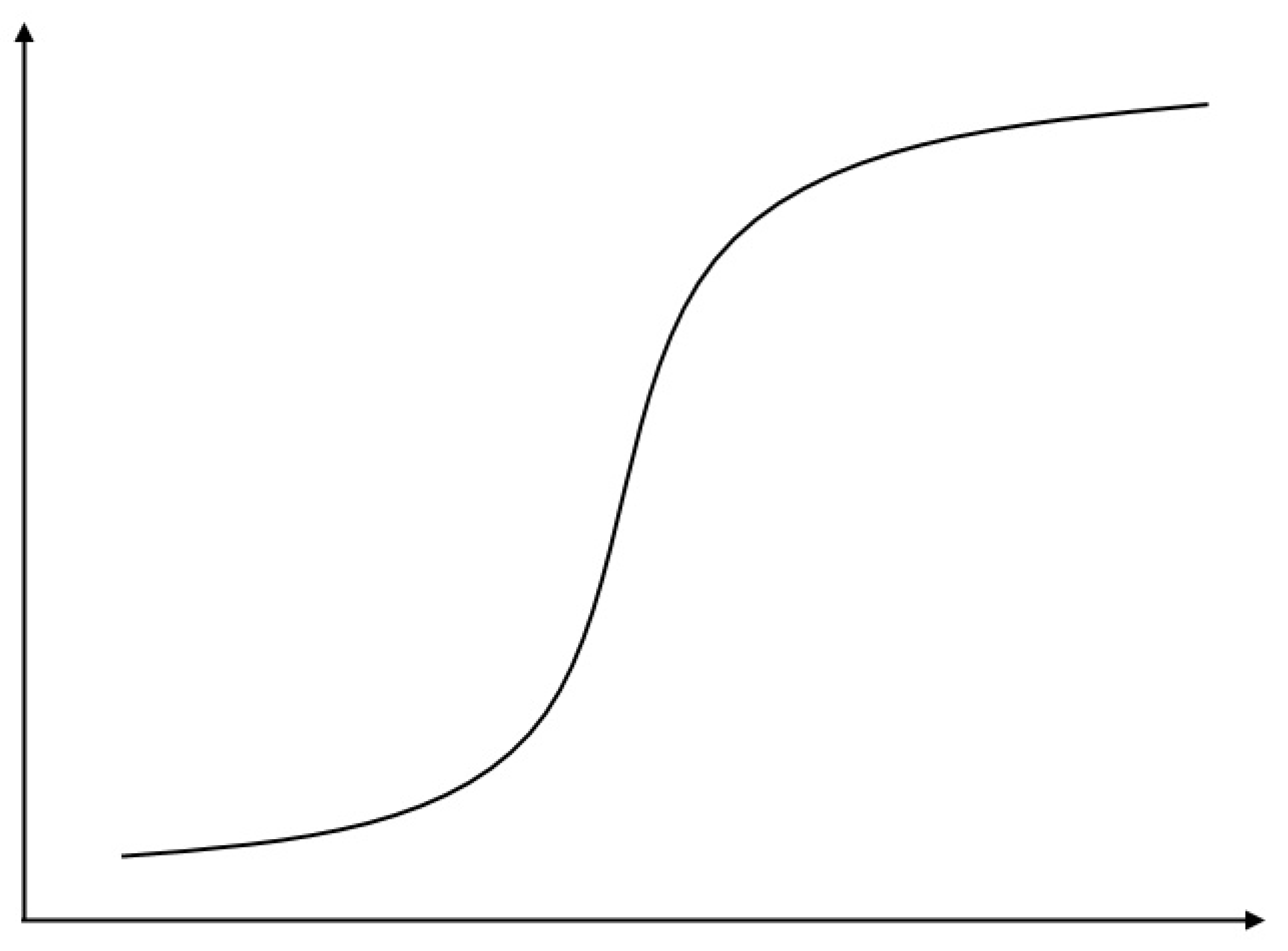
For initial cycles, when the fluorescent signal is below the value that the instrument can register, the amplification graph slowly increases as a linear function. Then, as the product accumulates, the signal increases exponentially and then reaches a plateau, similar to an arctangent. The plateau is due to the lack of one or another component of the reaction. In a standard real-time PCR reaction, all samples will plateau and reach approximately the same signal level. On the other hand, in the exponential phase, differences in the growth rate of the amount of product can be traced. Differences in the initial number of molecules affect the number of cycles required to raise the fluorescence level above the noise level.
There are many mathematical models describing the fluorescence graph for real-time PCR [
54,
55]. In some cases, theoretical and practical interest is not a heuristic inference, but a formal determination of the moments of transition of the fluorescence accumulation curve from linear growth to exponential growth, and then, reaching the plateau [
56,
57].
6.5. Switched Systems
Continuous dynamics and discrete events interconnect many systems encountered in practice. Systems in which these two types of dynamics coexist and interact are usually called hybrid systems. Their study entails interesting theoretical problems that are important for solving many applied problems. Due to its interdisciplinary nature, this field attracts the attention of a wide range of scientists. Researchers with experience and interest in continuous-time systems and control theory are primarily interested in the properties of continuous dynamics, such as Lyapunov stability. At the same time, it is necessary to study the discrete behavior of such systems. To describe the specifics of discrete dynamics, it is helpful to analyze a more general situation that contains a specific model as a particular case. We can is done this by considering systems with continuous-time and discrete switching events from a particular class. Such systems are called switched systems and are considered higher-level abstractions than hybrid systems. It should be borne in mind that such systems often demonstrate non-trivial switching behavior and, thus, go beyond the traditional control theory [
58].
For example, we can consider the security issues on the Internet of Things (IoT), which connects devices and users without limiting time and place. Latency, availability, and reliability are critical metrics for the efficient use of IoT data and services. IoT devices equipped with embedded controllers are often targeted by denial-of-service attacks. Denial-of-service (DoS) attacks and Distributed Denial-of-Service (DDoS) attacks are the most common attacks on the Internet of Things [
59]. They can take many forms and are defined as attacks that can undermine the network’s ability to perform its function. During DoS and DDoS attacks, several “malicious” computer systems “flood” the selected server with a huge volume of concurrent requests and cause a denial of service for users and devices on the network [
60].
In these cases, the system must change “its behavior” depending on the situation and use specialized hardware and software methods to deal with them. A possible approach, in this case, would be to use machine-learning methods in the IoT [
61]. The fact is that random functions, which are mappings between the generalized time and the amount of information (the number of requests), at the beginning of the attacks change the character of their increase from linear to nonlinear form, as a rule—exponential (
Figure 7). Approximation-estimation tests can be used to definition Markov stopping time corresponding to a change in strategy in response to an attack or overload.
The flexibility of the set of approximation-estimation tests allows them to make decisions on changing the control strategy based on any available metric. Network congestion control can be thought of as a switching system [
62,
63]. In this case, the primary mechanism for congestion avoidance is to determine the available system bandwidth. If the network is overloaded, it is necessary to automatically switch to emergency mode with a decrease in unacknowledged packets.
One of the most critical aspects of the considered tools is that the decision to change the strategy is made based on data on changes in the nature of network activity and not based on overcoming specific fixed load values. This allows these algorithms to be applied without additional configuration on systems of any size.
7. Conclusions
At the end of the article, it should be noted that modern computers do not learn anything. Typical machine learning boils down to finding and using “mathematical formulas” that produce the desired results when applied to a set of inputs. Just as artificial intelligence is not intelligence, machine learning is not learning. The term was coined for marketing reasons; in the 1960s, IBM used it to attract customers and talents [
64]. Nevertheless, the term machine learning has gained worldwide acceptance and is understood as the theory and practice of creating hardware and software that can perform practical actions without direct human intervention.
The practical application of approximation-estimation tests for solid mechanics, molecular biology, and switching systems can be attributed to a particular case of detecting anomalies. The same applies to their use in cluster analysis; the definition of “elbow” on the graph identifies an anomaly. Specific implementations of the proposed formulas and algorithms and an assessment of their computational complexity are beyond the scope of this article, but there are no prerequisites to believe that this aspect will cause significant difficulties in implementation. Moreover, the implementation of algorithms using approximation-estimation tests is possible in both hardware and software.
Approximation-estimation tests and integral-estimation tests open up new purely mathematical problems. For example, we can be studying their extreme properties. Approximation-estimation tests let obtain an upper bound for the critical point of the transition of the trajectory of a quasi-deterministic process from linear to nonlinear growth. Moreover, if the trajectory is convex, then an increase in the approximation knots shifts this upper bound to the left. Integral and differential calculus tools provide more accurate results than discrete methods. Therefore, it can be assumed that integral-estimation tests allow one to obtain more accurate estimates for critical points of monotonic trajectories than approximation-estimation tests. The next problem, by the way, is related to the previous one. Behavior study of approximation-estimation tests and integral-estimation tests if an increasing variable has not one inflection point, such as a sigmoid or a logit, but a countable set of such points, etc.
And in the end, for the sake of fairness, it should still be noted that integral-estimation tests are primarily of academic interest since practical implementation in digital technologies is possible mainly for discrete solutions.










{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}