
Optimized Task Group Aggregation-Based Overflow Handling on Fog Computing Environment Using Neural Computing


 , ,
, ,  and
and 
Abstract
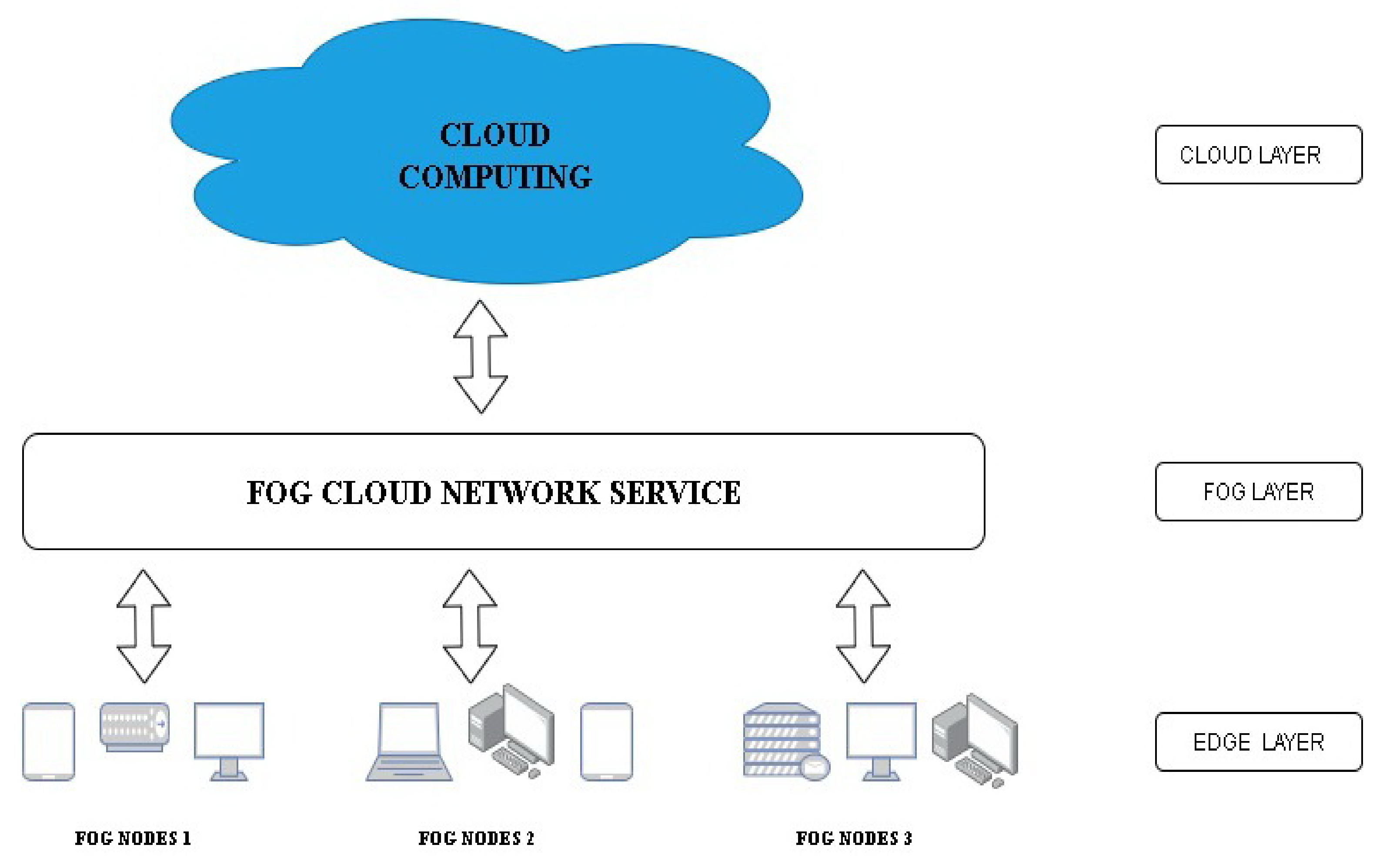
:1. Introduction
- To address the overflow problem on fog servers or virtual machines, we provide an ANN-oriented overflow management model with a TGA method for a fog computing environment;
- TGA with ABC is used as a classifier to detect overflow problems in ANN;
- The suggested fog computing overflow control model is tested by comparison to the current state-of-the-art virtual machine efficiency for resource scheduling average success rate, average task completion success rate, and virtual machine response time.
2. Related Work
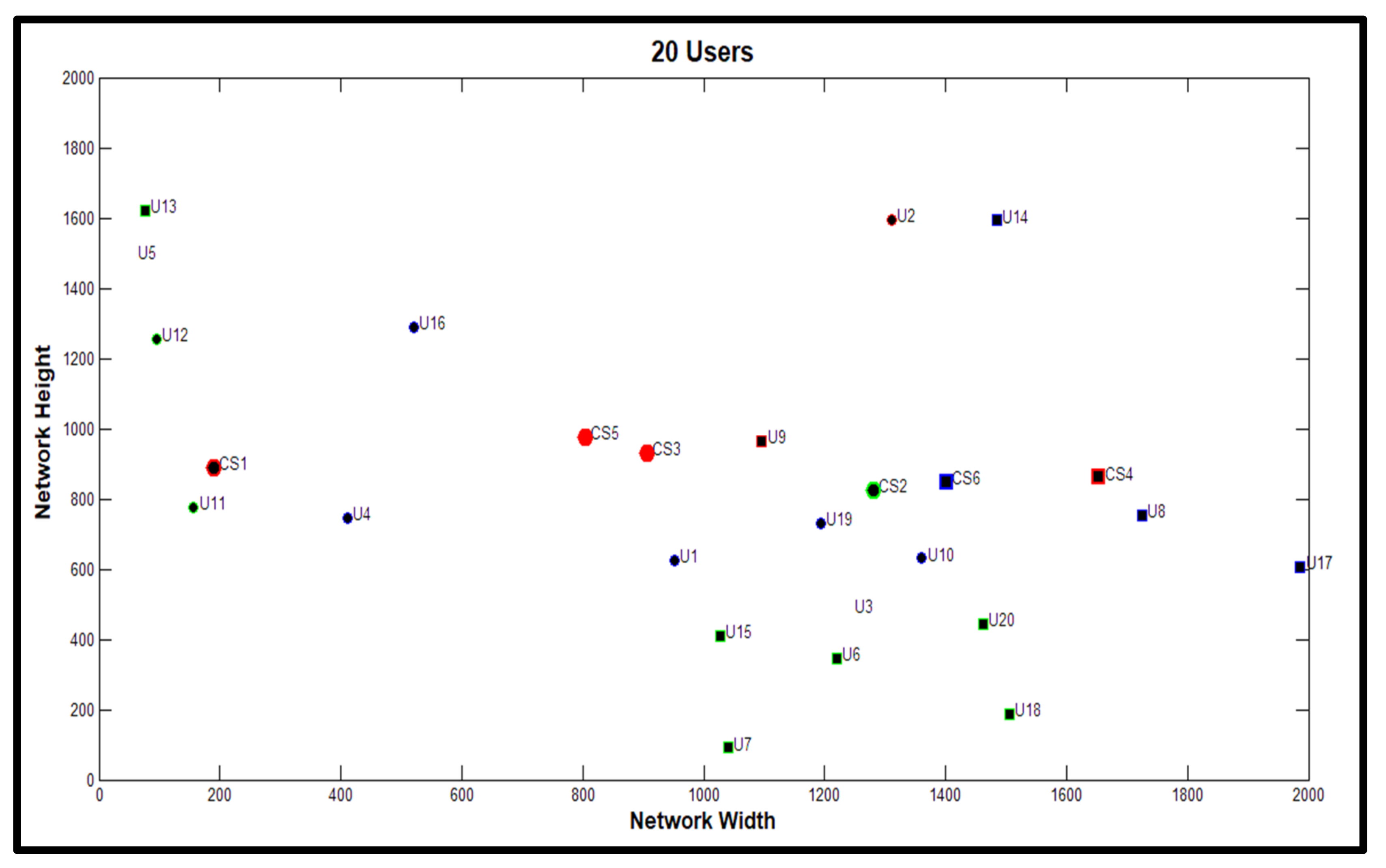
3. Method of Model
| Algorithm 1. Algorithm of TGA (Task Group Aggregation) |
| Input: U→Number users |
| C→Number of servers |
| Output: AS→List of Allocated Server |
| Start |
| Define RTF = [sCPUsMemsBW]//Assign the RTF (Resource Threshold Factor) using the basic parameters of servers like their CPU, RAM, and bandwidth |
| For each U |
| TimInt = random//Requests at Time Interval |
| DemR= max([uCPUuMemuBW])//user demand for resources |
| UtilRate= DemR×TimInt//Resource Utilization Rate |
| If max (UtilRate)<=max (RTF) |
| AvgPTimeSer(i)=DemR(i)/(1- |
| UtilRate(i))AvgPTimeAllSer(i)=(AvgPTimeSer(i)×TimInt(i))/(TimInt(i)) |
| AS-LIST =ceil(cServer × rand) |
| End—If |
| End—For |
| Return: AS-List as a list of allocated servers |
| End—Algorithm |
| Algorithm 2. Algorithm of ABC (Artificial Bee Colony) with Fitness Function |
| Input: AS→ List of Allocated Server |
| f (fit)→Fitness Function of ABC |
| Output: OAS→Optimized List of Allocated Server |
| Start |
| Initialize ABC algorithm with operators and parameter—Iterations (ITR) |
| – Bee Size (S) |
| – Lower Bound (LB)> |
| – Upper Bound (UB) |
| – Number of Variables (Nvar) |
| Calculate Size of AS, SZ = Size (AS) |
| Define Fitness function, f (fit) |
| For each ITR & SZ |
| //Select one by on VMs from allocated serves list |
| //Threshold |
| = fitness function//which is define above |
| End—For |
| For each CserverProp |
| OAS = Count (find (AS == CserverProp)) |
| End—For |
| Return: OAS→Optimized List of Allocated Server |
| End—Algorithm |
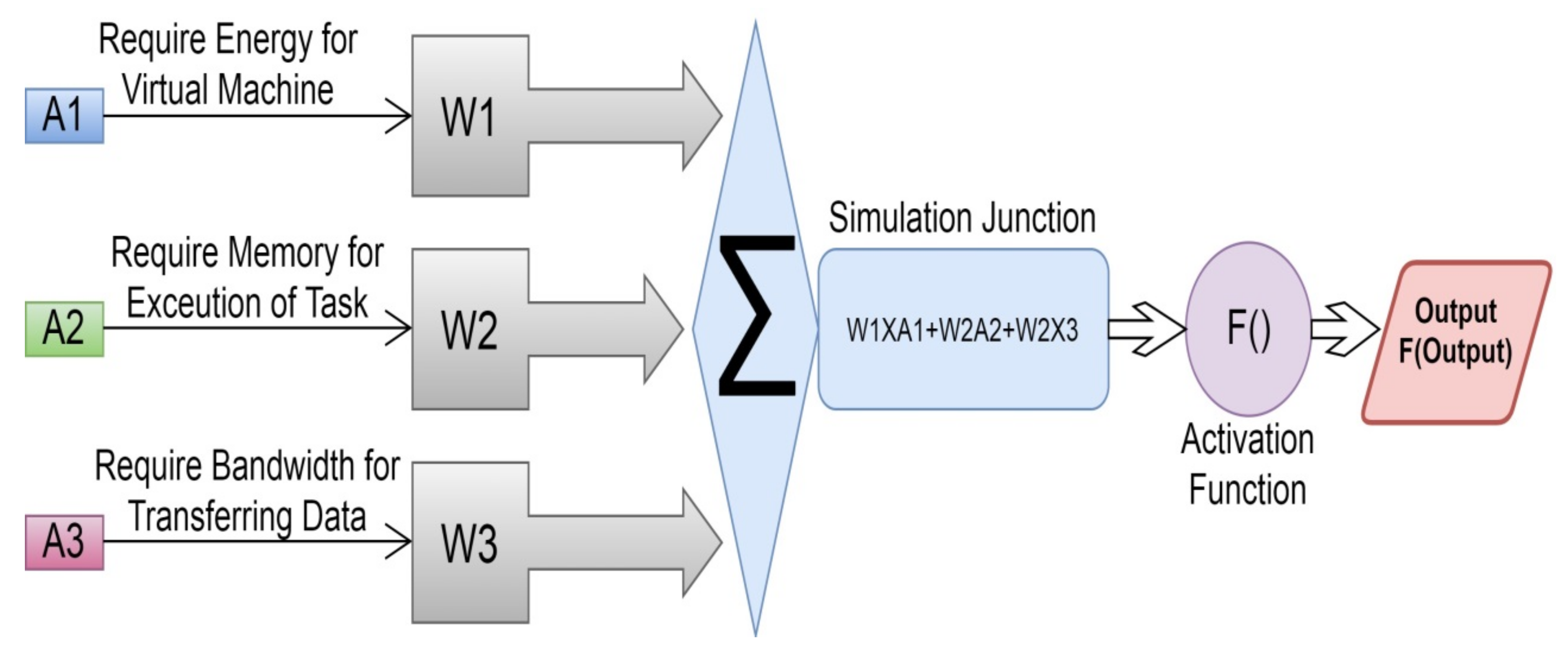
| Algorithm 3. Algorithm of ANN for Overflow Handling (Artificial Neural Network) with TGA |
| Input: OAS→Optimized List of Allocated Server |
| T-Data→VM properties as training data |
| TR→No. of VMs as a target in OAS |
| N→Neurons |
| Output: VAS→ValidList of Allocated Server |
| Start |
| For each cServer |
| If OAS (individual)>Average (OAS) |
| T-Data= [sCPUsMemsBW] |
| Targetc [] |
| End—If |
| End—For |
| Foreach T-Data |
| IfsCPU(Individual)>= Average(sCPU) |
| Target (1)= 1 |
| Else ifsCPU(Individual)<minimum (sCPU)) |
| Target (2)= 1 |
| Else |
| Target (3) =1 |
| End—If |
| End—For |
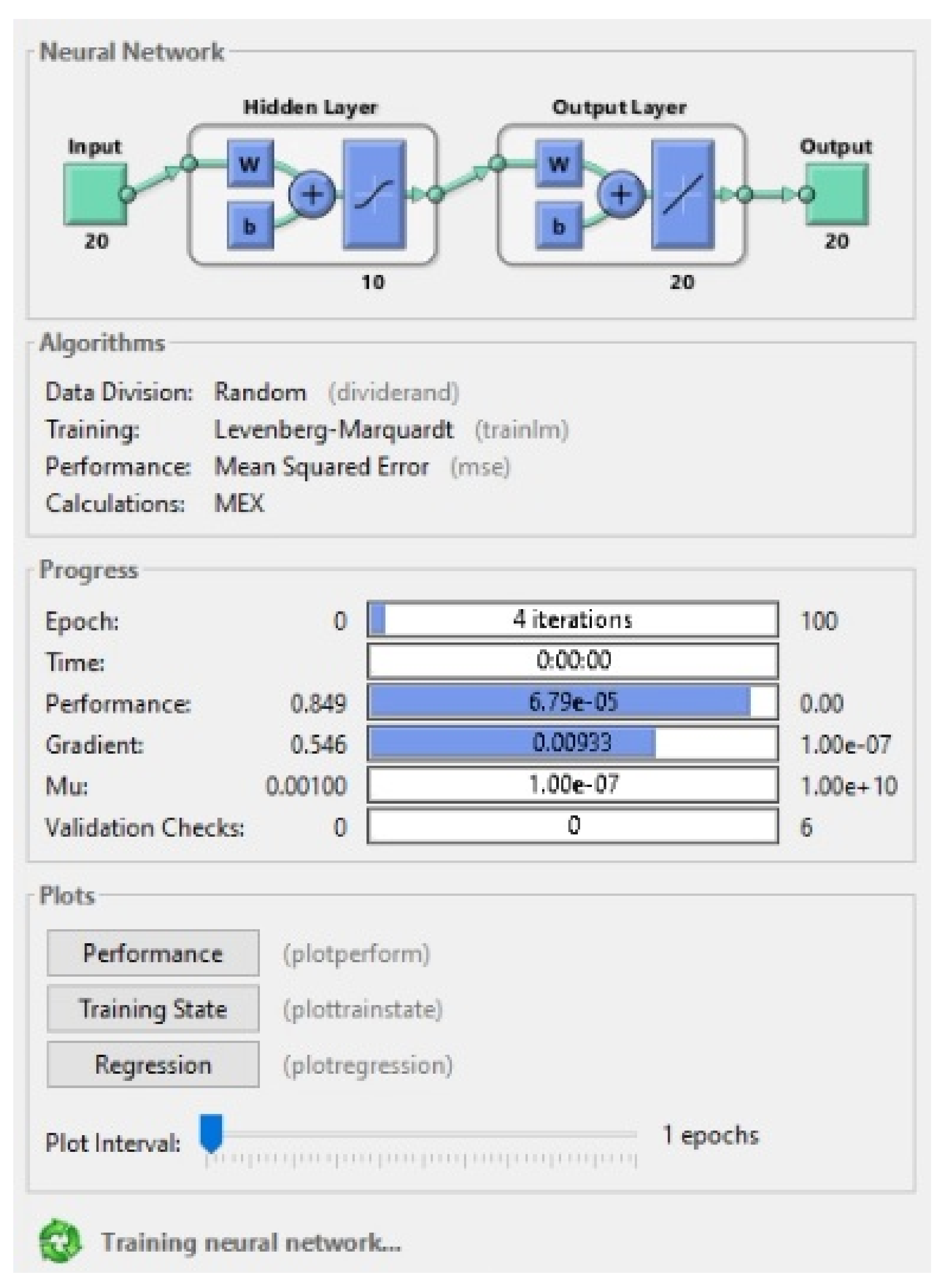
| Call and set the ANN |
| Set, Fog-Net = Newff (T-Data, TR, N) |
| Fog-NetEpoch = 1000 |
| Fog-Net Training Data Ratio = 70% |
| Fog-Net Testing Data Ratio = 15% |
| Fog-NetValidation Data Ratio = 15% |
| Fog-Net = Train (Fog-Net, T-Data, TR) |
| Properties Current VM in OAS = VMC |
| VM Characteristics = simulate (Fog-Net, VMC) |
| If VM Characteristics is valid and not overloaded |
| VAS = Validated |
| Else |
| VAS = Maybe under or overloaded |
| End |
| Return: VAS as the list of valid allocated server |
| End—Algorithm |
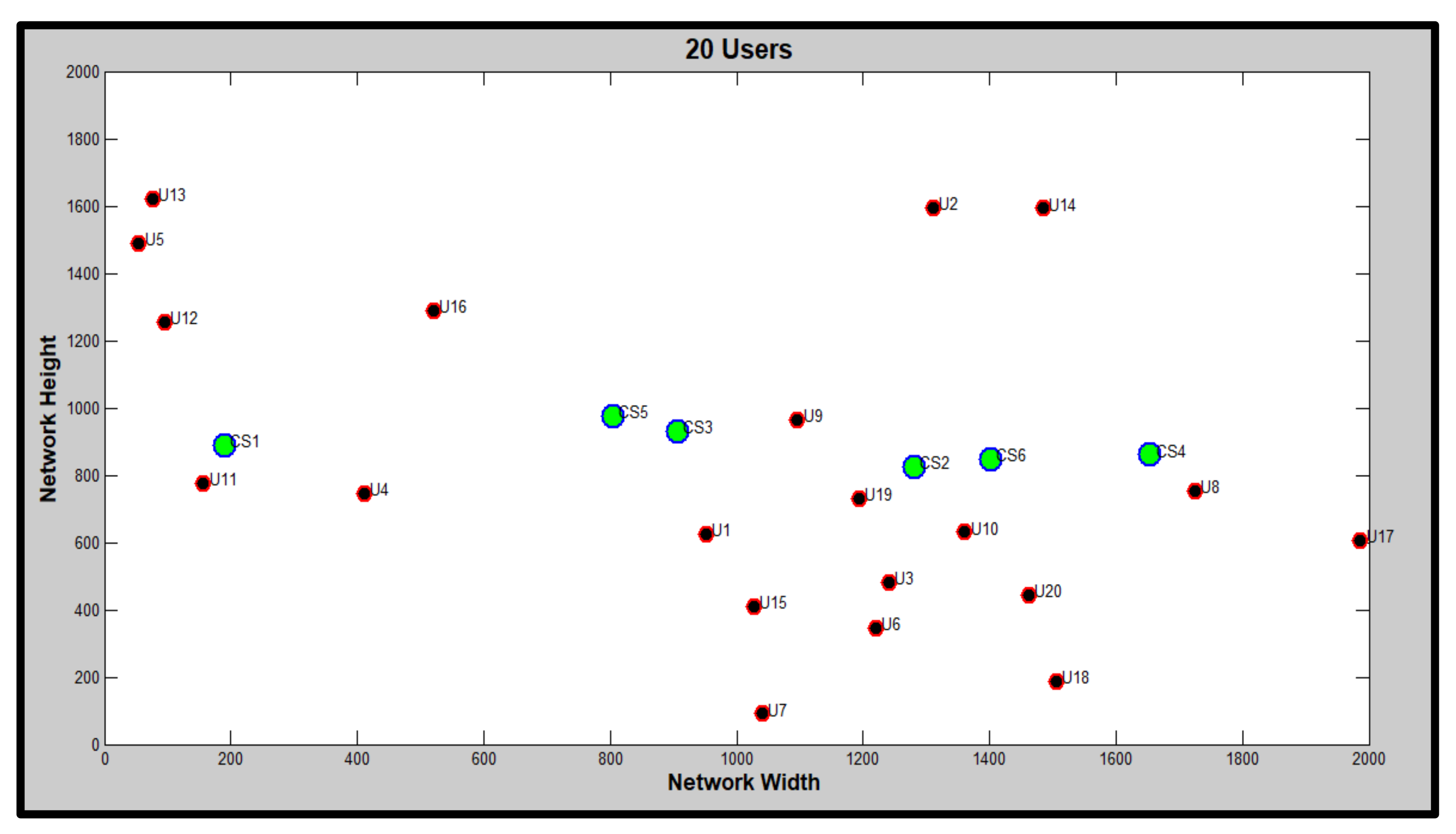
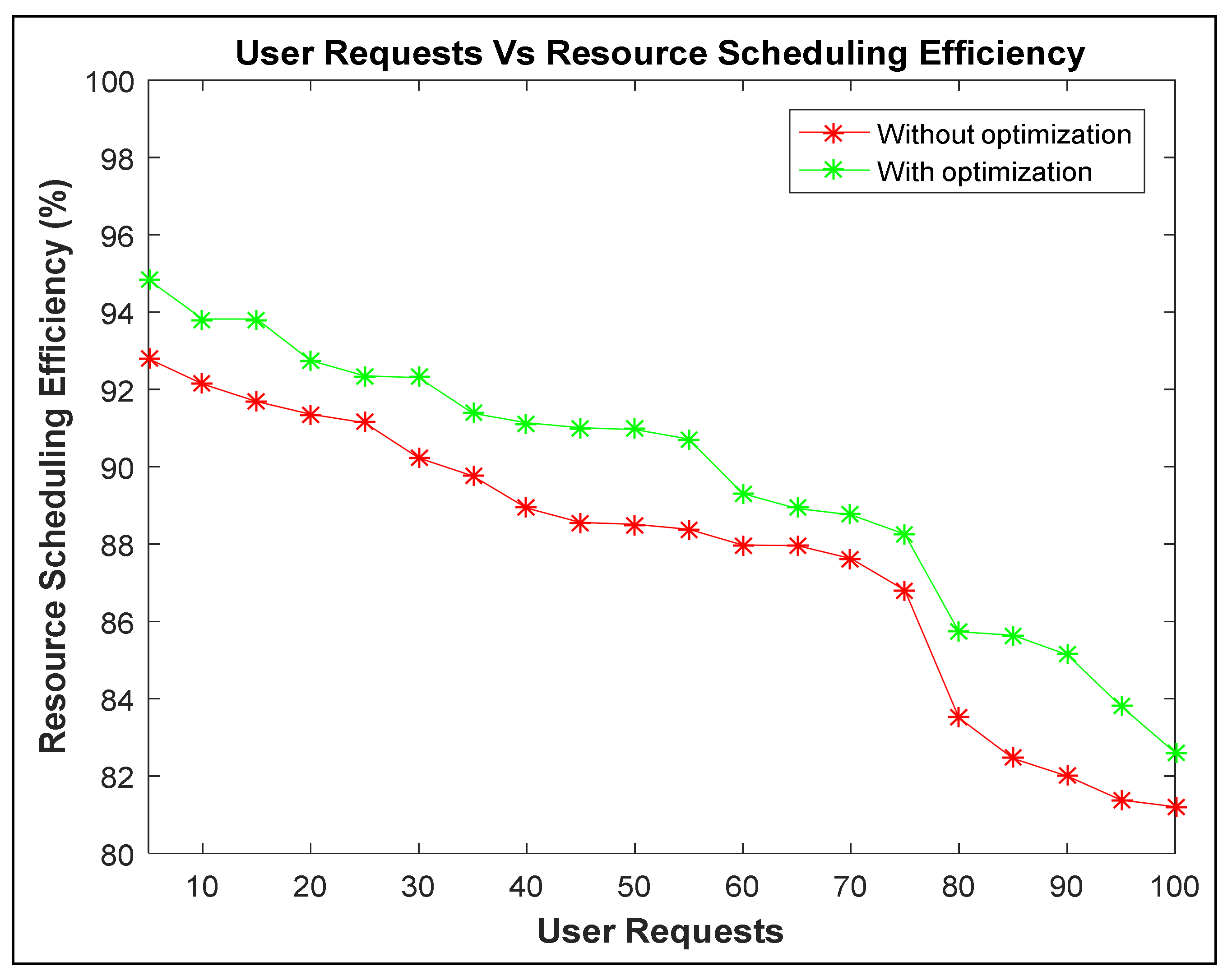
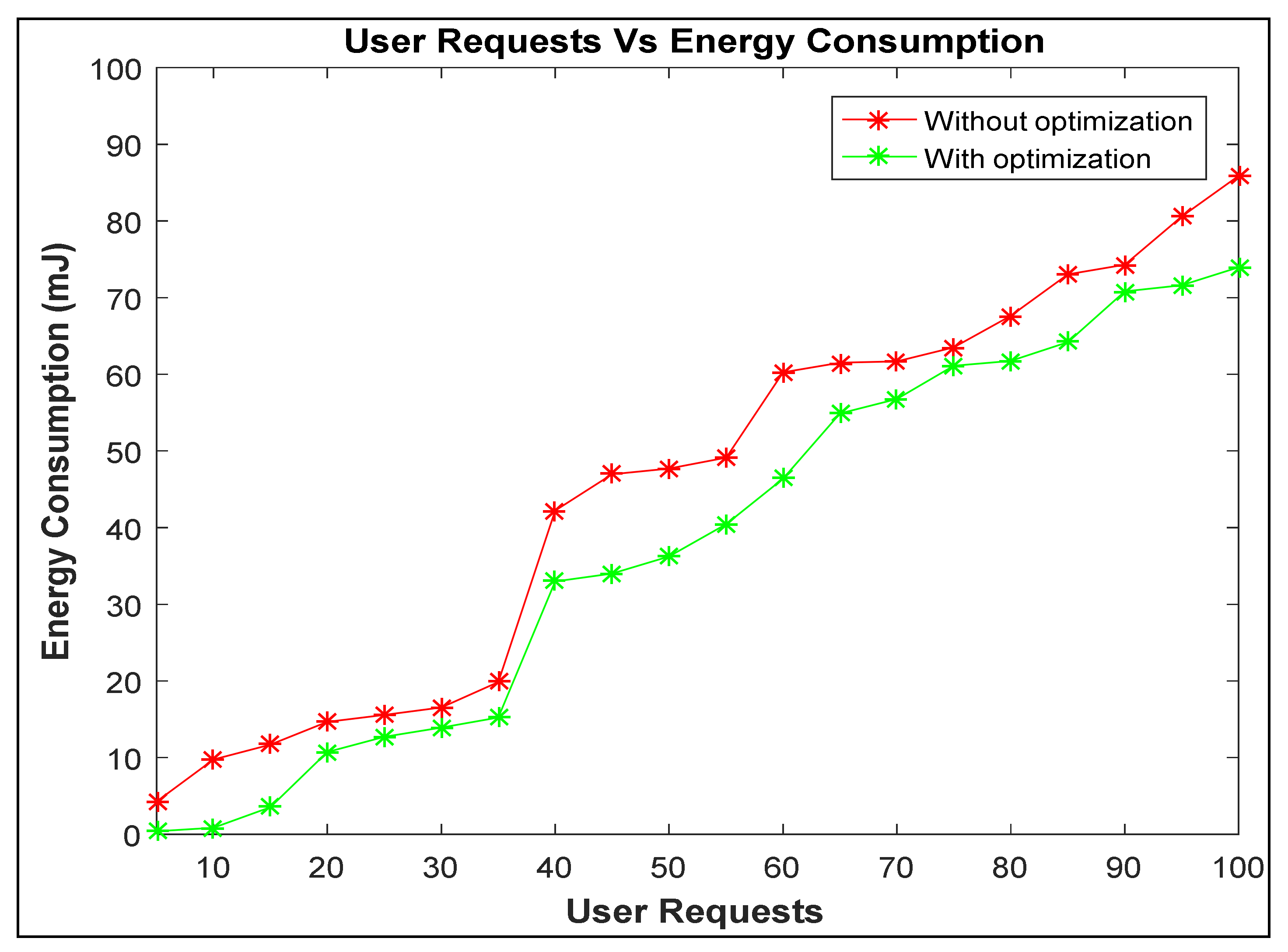
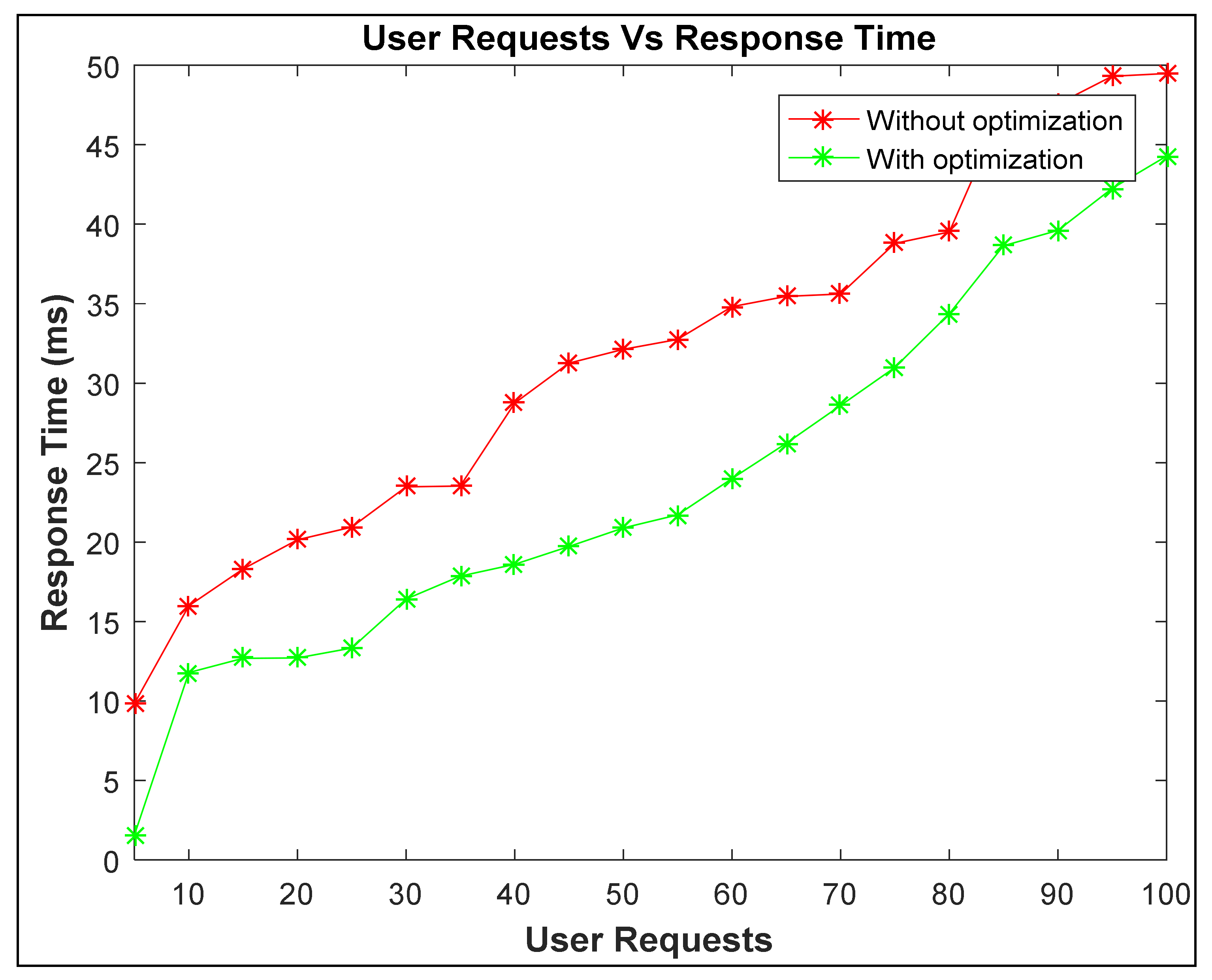
4. Results and Discussion
5. Conclusions
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Data Availability Statement
Conflicts of Interest
References
- Zhao, J.; Yang, K.; Wei, X.; Ding, Y.; Hu, L.; Xu, G. A heuristic clustering-based task deployment approach for load balancing using Bayes theorem in cloud environment. IEEE Trans. Parallel Distrib. Syst. 2015, 27, 305–316. [Google Scholar] [CrossRef]
- El Amrani, C.; Gibet Tani, H. Smarter round robin scheduling algorithm for cloud computing and big data. J. Data Min. Digit. Humanit. 2018, 2016, 1–8. [Google Scholar]
- Porkodi, V.; Singh, A.R.; Sait, A.R.W.; Shankar, K.; Yang, E.; Seo, C.; Joshi, G.P. Resource Provisioning for Cyber–Physical–Social System in Cloud-Fog-Edge Computing Using Optimal Flower Pollination Algorithm. IEEE Access 2020, 8, 105311–105319. [Google Scholar] [CrossRef]
- Rahmani, A.M.; Gia, T.N.; Negash, B.; Anzanpour, A.; Azimi, I.; Jiang, M.; Liljeberg, P. Exploiting smart e-Health gateways at the edge of healthcare Internet-of-Things: A fog computing approach. Future Gener. Comput. Syst. 2018, 78, 641–658. [Google Scholar] [CrossRef]
- Verma, D.; Rana, S. Deep learning based load balancing using multidimensional queuing load optimization algorithm for cloud environment. Int. J. Eng. Sci. Res. Technol. 2020, 9, 156–167. [Google Scholar]
- Ashouraei, M.; Khezr, S.N.; Benlamri, R.; Navimipour, N.J. A New SLA-Aware Load Balancing Method in the Cloud Using an Improved Parallel Task Scheduling Algorithm. In Proceedings of the 2018 IEEE 6th International Conference on Future Internet of Things and Cloud (FiCloud), Barcelona, Spain, 6–8 August 2018; pp. 71–76. [Google Scholar]
- Belgaum, M.R.; Soomro, S.; Alansari, Z.; Alam, M. Cloud service ranking using checkpoint-based load balancing in real-time scheduling of cloud computing. In Progress in Advanced Computing and Intelligent Engineering; Springer: Singapore, 2018; pp. 667–676. [Google Scholar]
- Priya, V.; Kumar, C.S.; Kannan, R. Resource scheduling algorithm with load balancing for cloud service provisioning. Appl. Soft Comput. 2019, 76, 416–424. [Google Scholar] [CrossRef]
- Guo, S.; Liu, J.; Yang, Y.; Xiao, B.; Li, Z. Energy-Efficient Dynamic Computation Offloading and Cooperative Task Scheduling in Mobile Cloud Computing. IEEE Trans. Mob. Comput. 2019, 18, 319–333. [Google Scholar] [CrossRef]
- Mukherjee, A.; Roy, D.G.; De, D. Mobility-aware task delegation model in mobile cloud computing. J. Supercomput. 2019, 75, 314–339. [Google Scholar] [CrossRef]
- Zhou, B.; Dastjerdi, A.V.; Calheiros, R.; Srirama, S.N.; Buyya, R. mCloud: A Context-Aware Offloading Framework for Heterogeneous Mobile Cloud. IEEE Trans. Serv. Comput. 2017, 10, 797–810. [Google Scholar] [CrossRef]
- Hung, T.C.; Hieu, L.N.; Hy, P.T.; Phi, N.X. MMSIA: Improved max-min scheduling algorithm for load balancing on cloud computing. In Proceedings of the 3rd International Conference on Machine Learning and Soft Computing, Dalat, Vietnam, 25–28 January 2019; pp. 60–64. [Google Scholar]
- Mishra, S.K.; Sahoo, B.; Parida, P.P. Load balancing in cloud computing: A big picture. J. King Saud Univ. Comput. Inf. Sci. 2020, 32, 149–158. [Google Scholar] [CrossRef]
- Atlam, H.F.; Walters, R.J.; Wills, G.B. Fog Computing and the Internet of Things: A Review. Big Data Cogn. Comput. 2018, 2, 10. [Google Scholar] [CrossRef] [Green Version]
- Subhulakshmi, R.; Suryagandhi, S.; Mathubala, R.; Sumathi, P. An evaluation on Cloud Computing Research Challenges and Its Novel Tools. Int. J. Adv. Res. Basic Eng. Sci. Technol. 2016, 2, 69–76. [Google Scholar]
- Rashid, A.; Chaturvedi, A. Cloud computing characteristics and services: A brief review. Int. J. Comput. Sci. Eng. 2019, 7, 421–426. [Google Scholar] [CrossRef]
- Kumar, P.; Kumar, R.; Gupta, G.P.; Tripathi, R. A Distributed framework for detecting DDoS attacks in smart contract-based Blockchain-IoT Systems by leveraging Fog computing. Trans. Emerg. Telecommun. Technol. 2021, 32, 4112. [Google Scholar] [CrossRef]
- Kumar, P.; Gupta, G.P.; Tripathi, R. An ensemble learning and fog-cloud architecture-driven cyber-attack detection framework for IoMT networks. Comput. Commun. 2021, 166, 110–124. [Google Scholar] [CrossRef]
- Mutlag, A.A.; Ghani, M.K.A.; Arunkumar, N.; Mohammed, M.A.; Mohd, O. Enabling technologies for fog computing in healthcare IoT systems. Futur. Gener. Comput. Syst. 2019, 90, 62–78. [Google Scholar] [CrossRef]
- Bonomi, F.; Milito, R.; Natarajan, P.; Zhu, J. Fog computing: A platform for internet of things and analytics. In Big Data and Internet of Things: A Roadmap for Smart Environments; Springer: Cham, Switzerland, 2014; pp. 169–186. [Google Scholar]
- Kumar, D.P.; Amgoth, T.; Annavarapu, C.S.R. Machine learning algorithms for wireless sensor networks: A survey. Inf. Fusion 2019, 49, 1–25. [Google Scholar] [CrossRef]
- Moustafa, N. A systemic iot-fog-cloud architecture for big-data analytics and cyber security systems: A review of fog computing. arXiv 2019, arXiv:1906.01055. [Google Scholar]
- Hsu, C.-H.; Hong, H.-J.; Elgamal, T.; Nahrstedt, K.; Venkatasubramanian, N. Multimedia fog computing: Minions in the cloud and crowd. In Frontiers of Multimedia Research; ACM Press: New York, NY, USA, 2017; pp. 255–286. [Google Scholar]
- Sufyan, F.; Banerjee, A. Computation Offloading for Smart Devices in Fog-Cloud Queuing System. IETE J. Res. 2021, 1–13. [Google Scholar] [CrossRef]
- Farzai, S.; Shirvani, M.H.; Rabbani, M. Multi-objective communication-aware optimization for virtual machine placement in cloud datacenters. Sustain. Comput. Informatics Syst. 2020, 28, 100374. [Google Scholar] [CrossRef]
- Arri, H.S.; Ramandeep, S. Energy Optimization-based Optimal Trade-off Scheme for Job Scheduling in Fog Computing. In Proceedings of the 8th International Conference on Computing for Sustainable Global Development, New Delhi, India, 17–19 March 2021. [Google Scholar]













{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
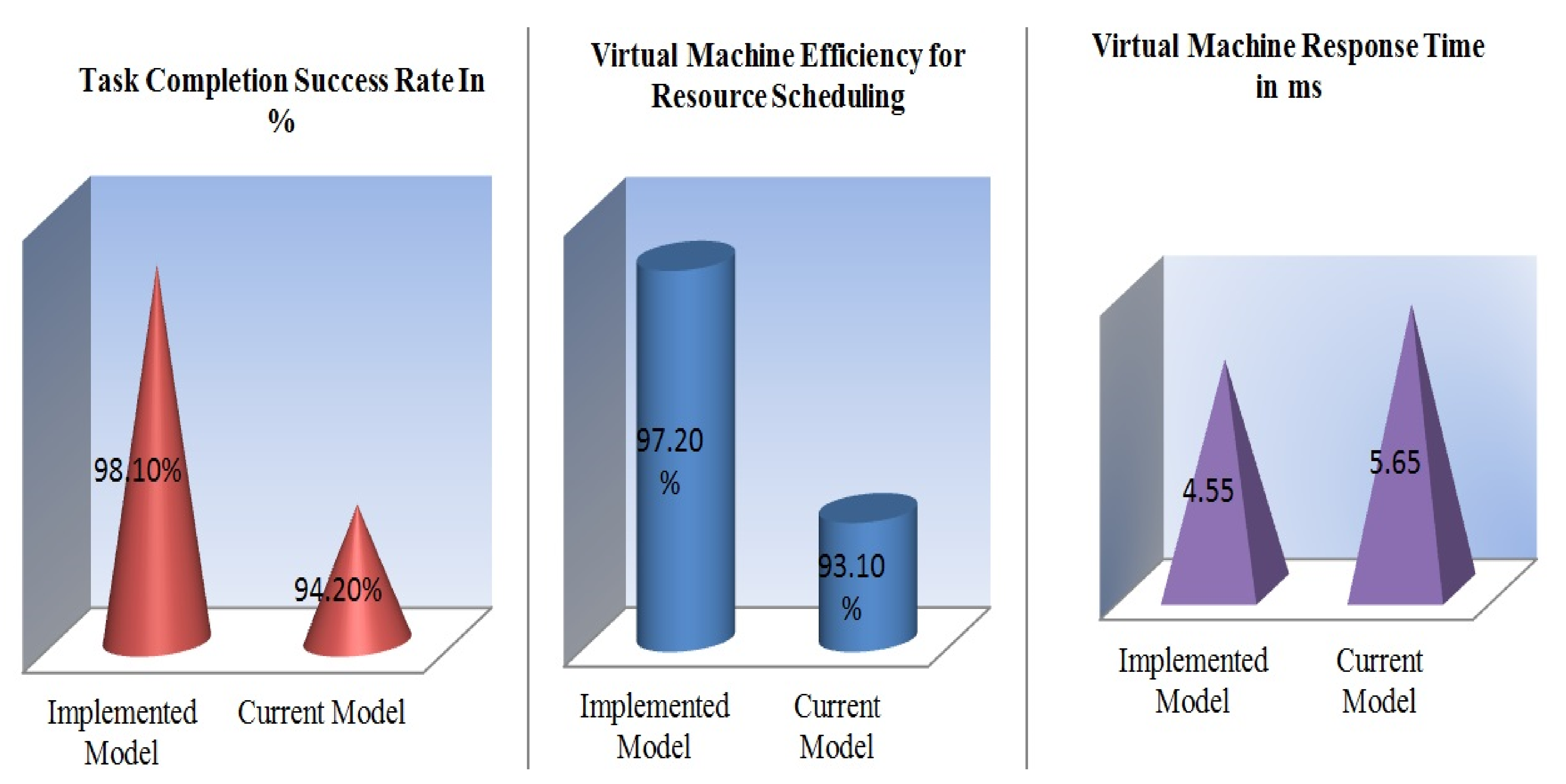
| Parameters | Current/Existing Model [26] | Implemented/Proposed Model | Advantage and Disadvantage of Proposed Model |
|---|---|---|---|
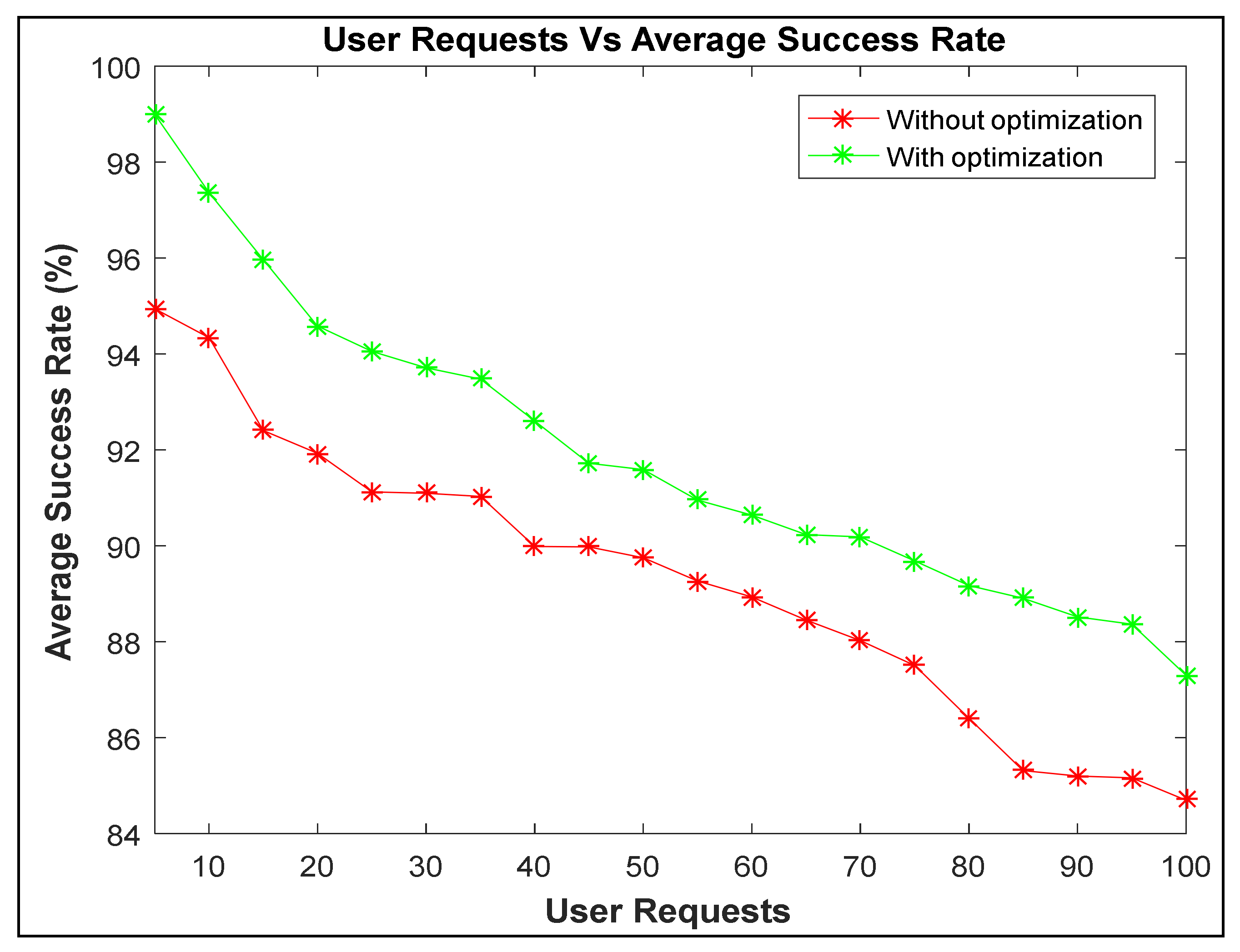
| Virtual Machine Efficiency For Resource Scheduling | In the existing models, average of resource scheduling is 93.10%. | In the proposed model, average of resource scheduling is 97.20%. | The success rate of resource scheduling is increased because more new tasks will be allocated to the virtual machines as per energy consumption. However, this work can be extended by considering the concept of clustering mechanism with optimization technique to find out the over- and underloaded VMs so that we can manage the task allocation properly. |
| Average Task Completion Success Rate | In the existing models, the average success rate is 94.20. | The proposed models’ average success rate is 98.10%. | The proposed scheme achieved a far better result than the other existing work based on the job completion time. It mitigates the job scheduling problem in the fog computing environment. Additionally, it gratifies the service requests of operators based on the optimal tradeoff scheme. However, the energy consumption is still massive for a cost-effective prototype. |
| Virtual Machine Response time | In the existing model, average response time is 5.65 ms. | In the proposed model, average response time is 4.55 ms. | The issue of resource scheduling and task overflow handling in fog computing can be handled by reducing response time and balancing the load on servers. This provides the optimal tradeoff scheme between user and operator. |
Publisher’s Note: MDPI stays neutral with regard to jurisdictional claims in published maps and institutional affiliations. |
© 2021 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Arri, H.S.; Singh, R.; Jha, S.; Prashar, D.; Joshi, G.P.; Doo, I.C. Optimized Task Group Aggregation-Based Overflow Handling on Fog Computing Environment Using Neural Computing. Mathematics 2021, 9, 2522. https://doi.org/10.3390/math9192522
Arri HS, Singh R, Jha S, Prashar D, Joshi GP, Doo IC. Optimized Task Group Aggregation-Based Overflow Handling on Fog Computing Environment Using Neural Computing. Mathematics. 2021; 9(19):2522. https://doi.org/10.3390/math9192522
Chicago/Turabian StyleArri, Harwant Singh, Ramandeep Singh, Sudan Jha, Deepak Prashar, Gyanendra Prasad Joshi, and Ill Chul Doo. 2021. "Optimized Task Group Aggregation-Based Overflow Handling on Fog Computing Environment Using Neural Computing" Mathematics 9, no. 19: 2522. https://doi.org/10.3390/math9192522
APA StyleArri, H. S., Singh, R., Jha, S., Prashar, D., Joshi, G. P., & Doo, I. C. (2021). Optimized Task Group Aggregation-Based Overflow Handling on Fog Computing Environment Using Neural Computing. Mathematics, 9(19), 2522. https://doi.org/10.3390/math9192522