
A Novel Hybrid Approach: Instance Weighted Hidden Naive Bayes


Abstract
:1. Introduction
- We reviewed the related work about structure extension and found that there is almost no method that focuses on the hybrid paradigm which combines structure extension with instance weighting.
- We reviewed the related work about the existing instance weighting approaches and found that the Bayesian network in these researches is limited to NB.
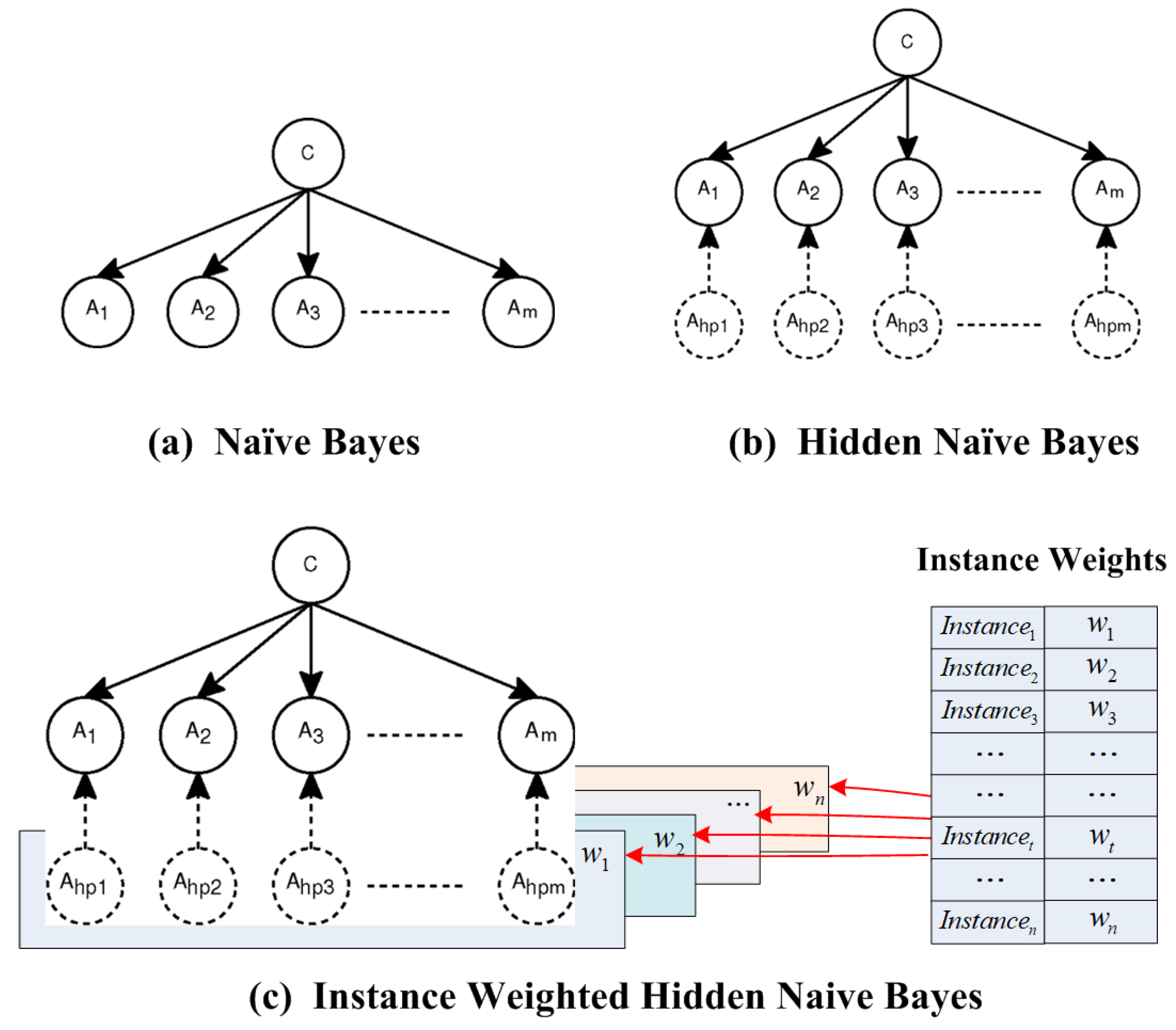
- The IWHNB approach is an improved approach which combines instance weighting with the improved HNB model into one uniform framework. It is a new paradigm to calculate discriminative instance weights for the structure extension model.
- Although some training time is spent to calculate the weight of each instance, the experimental results show that our proposed IWHNB approach is still simple and efficient. Meanwhile, the classification performance of the IWHNB approach is more satisfactory than its competitors.
2. Related Work
2.1. Structure Extension
2.2. Instance Weighting
3. Instance Weighted Hidden Naive Bayes
3.1. The Instance Weighted Hidden Naive Bayes Model
3.2. The Weight of Each Instance
| Algorithm 1 Instance Weighted Hidden Naive Bayes |
| Input: TD-a training dataset; a test instance x Output: the predicted class label of x
|
4. Experiments and Results
- According to results in Table 1, the averaged classification accuracy of IWHNB across all datasets is 86.37%. It is considerably higher than its competitors, such as NB (83.31%), HNB (85.86%), AVFWNB (84.21%), AIWNB (84.94%), AODE (85.68%) and TAN (84.95%). This suggests that our proposed IWHNB approach is effective.
- IWHNB obtains the most satisfactory experimental results in accuracy. IWHNB outperforms NB (17 wins, 18 ties and 1 loss), HNB (9 wins, 27 ties and 0 losses), AVFWNB (13 wins, 21 ties and 2 losses), AIWNB (8 wins, 25 ties and 3 losses), AODE (6 wins, 30 ties and 0 losses) and TAN (9 wins, 25 ties and 2 losses).
- The summary and ranking test results show that IWHNB is overall the best across all datasets (62 wins and 8 losses). The descending sort across all datasets is IWHNB, HNB, AIWNB, AODE, TAN, AVFWNB and NB.
- Compared with HNB, IWHNB considerably improves the classification accuracy (nine wins and zero losses). This suggests that this improved hybrid approach which combines the improved HNB model with instance weighting improves the classification performance effectively.
- 1
- According to results in Table 4, the averaged elapsed training time of IWHNB is 13.15 milliseconds, which is a little bigger than that of HNB (12.56 milliseconds). Therefore, our proposed IWHNB approach maintains the computational simplicity that characterizes HNB. It is a simple, efficient and effective approach.
- 2
- Compared with TAN, IWHNB has the lower time complexity. The averaged elapsed training time of IWHNB is smaller than that of TAN (15.84 milliseconds). It reduces the elapsed training time on 8 datasets, and loses on 0 datasets.
- 3

{kind=link}
| Dataset | IWHNB | NB | HNB | AVFWNB | AIWNB | AODE | TAN | ||||||||||||||||||||
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| anneal | 19.42 | ± | 12.25 | 0.45 | ± | 0.88 | • | 13.28 | ± | 6.04 | • | 0.93 | ± | 1.37 | • | 6.20 | ± | 4.53 | • | 7.84 | ± | 1.64 | • | 17.18 | ± | 7.88 | |
| anneal.ORIG | 16.80 | ± | 3.95 | 0.25 | ± | 0.44 | • | 12.32 | ± | 1.79 | • | 0.36 | ± | 0.50 | • | 4.20 | ± | 0.65 | • | 6.95 | ± | 1.00 | • | 14.19 | ± | 1.10 | |
| audiology | 63.53 | ± | 18.79 | 0.13 | ± | 0.34 | • | 57.39 | ± | 4.66 | 0.24 | ± | 0.43 | • | 6.53 | ± | 1.38 | • | 7.12 | ± | 1.20 | • | 95.49 | ± | 9.07 | ∘ | |
| autos | 4.65 | ± | 1.25 | 0.03 | ± | 0.17 | • | 4.35 | ± | 0.63 | 0.09 | ± | 0.29 | • | 1.15 | ± | 0.41 | • | 0.86 | ± | 0.43 | • | 4.89 | ± | 0.65 | ||
| balance-scale | 0.18 | ± | 0.39 | 0.06 | ± | 0.42 | 0.08 | ± | 0.27 | 0.07 | ± | 0.26 | 0.17 | ± | 0.40 | 0.05 | ± | 0.22 | 0.18 | ± | 0.46 | ||||||
| breast-cancer | 0.52 | ± | 0.70 | 0.02 | ± | 0.14 | • | 0.40 | ± | 0.49 | 0.01 | ± | 0.10 | • | 0.27 | ± | 0.45 | 0.16 | ± | 0.37 | 0.38 | ± | 0.55 | ||||
| breast-w | 0.62 | ± | 0.49 | 0.03 | ± | 0.17 | • | 0.48 | ± | 0.50 | 0.04 | ± | 0.20 | • | 0.48 | ± | 0.52 | 0.30 | ± | 0.48 | 0.59 | ± | 0.49 | ||||
| colic | 1.95 | ± | 0.50 | 0.09 | ± | 0.29 | • | 1.77 | ± | 0.49 | 0.13 | ± | 0.34 | • | 0.83 | ± | 0.40 | • | 0.98 | ± | 0.38 | • | 2.34 | ± | 0.52 | ||
| colic.ORIG | 3.77 | ± | 1.20 | 0.09 | ± | 0.29 | • | 3.28 | ± | 0.53 | 0.13 | ± | 0.34 | • | 1.54 | ± | 0.54 | • | 1.44 | ± | 0.62 | • | 4.05 | ± | 0.87 | ||
| credit-a | 1.83 | ± | 0.88 | 0.05 | ± | 0.22 | • | 1.34 | ± | 0.50 | 0.18 | ± | 0.39 | • | 0.78 | ± | 0.44 | • | 0.87 | ± | 0.46 | • | 1.59 | ± | 0.73 | ||
| credit-g | 3.00 | ± | 0.59 | 0.15 | ± | 0.36 | • | 3.12 | ± | 0.59 | 0.26 | ± | 0.44 | • | 1.66 | ± | 0.81 | • | 2.17 | ± | 0.45 | • | 3.42 | ± | 0.81 | ||
| diabetes | 0.48 | ± | 0.50 | 0.09 | ± | 0.29 | • | 0.36 | ± | 0.48 | 0.09 | ± | 0.29 | 0.37 | ± | 0.49 | 0.31 | ± | 0.46 | 0.40 | ± | 0.55 | |||||
| glass | 0.42 | ± | 0.50 | 0.00 | ± | 0.00 | • | 0.38 | ± | 0.49 | 0.02 | ± | 0.14 | • | 0.13 | ± | 0.34 | 0.07 | ± | 0.26 | 0.44 | ± | 0.52 | ||||
| heart-c | 0.70 | ± | 0.61 | 0.10 | ± | 0.30 | • | 0.68 | ± | 0.49 | 0.04 | ± | 0.20 | • | 0.29 | ± | 0.46 | 0.23 | ± | 0.42 | 0.90 | ± | 0.61 | ||||
| heart-h | 0.63 | ± | 0.49 | 0.07 | ± | 0.26 | • | 0.68 | ± | 0.49 | 0.03 | ± | 0.17 | • | 0.31 | ± | 0.46 | 0.27 | ± | 0.47 | 0.71 | ± | 0.56 | ||||
| heart-statlog | 0.60 | ± | 0.51 | 0.05 | ± | 0.22 | • | 0.37 | ± | 0.51 | 0.03 | ± | 0.17 | • | 0.29 | ± | 0.46 | 0.28 | ± | 0.45 | 0.43 | ± | 0.54 | ||||
| hepatitis | 0.81 | ± | 0.51 | 0.06 | ± | 0.24 | • | 0.72 | ± | 0.51 | 0.03 | ± | 0.17 | • | 0.35 | ± | 0.48 | 0.39 | ± | 0.49 | 0.95 | ± | 0.39 | ||||
| hypothyroid | 19.24 | ± | 1.92 | 1.16 | ± | 0.60 | • | 18.46 | ± | 1.46 | 1.90 | ± | 0.70 | • | 10.27 | ± | 1.63 | • | 17.96 | ± | 3.36 | 21.08 | ± | 2.44 | |||
| ionosphere | 5.20 | ± | 0.77 | 0.06 | ± | 0.24 | • | 5.26 | ± | 0.63 | 0.09 | ± | 0.29 | • | 2.36 | ± | 0.50 | • | 2.78 | ± | 1.38 | • | 7.79 | ± | 1.23 | ∘ | |
| iris | 0.03 | ± | 0.17 | 0.00 | ± | 0.00 | 0.05 | ± | 0.22 | 0.04 | ± | 0.20 | 0.05 | ± | 0.22 | 0.05 | ± | 0.22 | 0.05 | ± | 0.22 | ||||||
| kr-vs-kp | 27.11 | ± | 5.29 | 1.33 | ± | 0.64 | • | 23.27 | ± | 1.22 | • | 1.71 | ± | 0.71 | • | 23.76 | ± | 23.79 | 23.15 | ± | 4.53 | 30.78 | ± | 5.71 | |||
| labor | 0.51 | ± | 0.85 | 0.00 | ± | 0.00 | 0.38 | ± | 0.51 | 0.02 | ± | 0.14 | 0.18 | ± | 0.39 | 0.05 | ± | 0.22 | 0.52 | ± | 0.56 | ||||||
| letter | 81.00 | ± | 21.55 | 4.51 | ± | 0.86 | • | 72.44 | ± | 8.74 | 9.73 | ± | 1.05 | • | 74.51 | ± | 36.78 | 66.65 | ± | 23.94 | 79.07 | ± | 13.71 | ||||
| lymphography | 1.16 | ± | 0.72 | 0.02 | ± | 0.14 | • | 1.15 | ± | 0.67 | 0.04 | ± | 0.20 | • | 0.47 | ± | 0.50 | • | 0.26 | ± | 0.44 | • | 1.18 | ± | 0.67 | ||
| mushroom | 24.98 | ± | 3.41 | 1.85 | ± | 1.37 | • | 24.47 | ± | 1.47 | 4.26 | ± | 0.79 | • | 25.80 | ± | 4.66 | 25.55 | ± | 3.54 | 27.06 | ± | 3.80 | ||||
| primary-tumor | 3.28 | ± | 0.57 | 0.06 | ± | 0.24 | • | 3.57 | ± | 0.76 | 0.09 | ± | 0.29 | • | 0.91 | ± | 0.47 | • | 0.58 | ± | 0.50 | • | 3.76 | ± | 1.68 | ||
| segment | 11.00 | ± | 1.36 | 0.42 | ± | 0.52 | • | 12.32 | ± | 1.52 | 0.78 | ± | 0.50 | • | 7.52 | ± | 1.49 | • | 6.87 | ± | 1.19 | • | 13.28 | ± | 1.78 | ∘ | |
| sick | 18.14 | ± | 1.98 | 1.04 | ± | 0.53 | • | 17.77 | ± | 1.64 | 1.85 | ± | 0.59 | • | 11.92 | ± | 2.79 | • | 16.74 | ± | 1.54 | 22.35 | ± | 5.21 | ∘ | ||
| sonar | 7.16 | ± | 0.85 | 0.07 | ± | 0.26 | • | 7.76 | ± | 1.40 | 0.18 | ± | 0.39 | • | 2.24 | ± | 0.51 | • | 4.17 | ± | 1.09 | • | 29.32 | ± | 3.92 | ∘ | |
| soybean | 17.57 | ± | 2.01 | 0.30 | ± | 0.46 | • | 17.80 | ± | 1.84 | 0.53 | ± | 0.50 | • | 4.85 | ± | 1.86 | • | 5.59 | ± | 1.54 | • | 20.50 | ± | 2.12 | ∘ | |
| splice | 81.68 | ± | 7.16 | 1.79 | ± | 0.67 | • | 89.51 | ± | 4.19 | ∘ | 3.14 | ± | 0.75 | • | 63.97 | ± | 8.34 | • | 80.66 | ± | 11.04 | 101.74 | ± | 11.40 | ∘ | |
| vehicle | 2.95 | ± | 0.58 | 0.13 | ± | 0.37 | • | 2.87 | ± | 0.51 | 0.25 | ± | 0.44 | • | 1.45 | ± | 0.52 | • | 1.63 | ± | 0.60 | • | 3.09 | ± | 0.64 | ||
| vote | 0.92 | ± | 0.34 | 0.07 | ± | 0.26 | • | 0.90 | ± | 0.46 | 0.11 | ± | 0.31 | • | 0.52 | ± | 0.54 | 0.64 | ± | 0.54 | 1.00 | ± | 0.45 | ||||
| vowel | 2.86 | ± | 0.59 | 0.15 | ± | 0.36 | • | 3.04 | ± | 0.63 | 0.23 | ± | 0.42 | • | 1.14 | ± | 0.40 | • | 1.11 | ± | 0.31 | • | 2.93 | ± | 0.57 | ||
| waveform-5000 | 47.56 | ± | 2.10 | 1.61 | ± | 0.58 | • | 49.06 | ± | 2.40 | 3.05 | ± | 0.85 | • | 29.01 | ± | 1.84 | • | 46.70 | ± | 4.64 | 55.69 | ± | 2.93 | ∘ | ||
| zoo | 0.98 | ± | 0.38 | 0.00 | ± | 0.00 | • | 1.01 | ± | 0.33 | 0.08 | ± | 0.27 | • | 0.19 | ± | 0.39 | • | 0.21 | ± | 0.43 | • | 1.03 | ± | 0.36 | ||
| Average | 13.15 | 0.45 | 12.56 | 0.85 | 7.96 | 9.21 | 15.84 | ||||||||||||||||||||
| W/T/L | - | 0/3/33 | 1/32/3 | 0/4/32 | 0/15/21 | 0/19/17 | 8/28/0 | ||||||||||||||||||||
| Algorithm | IWHNB | NB | HNB | AVFWNB | AIWNB | AODE | TAN |
|---|---|---|---|---|---|---|---|
| IWHNB | - | 0 (0) | 12 (1) | 1 (0) | 2 (0) | 2 (0) | 27 (8) |
| NB | 36 (33) | - | 36 (32) | 30 (6) | 36 (25) | 35 (23) | 36 (31) |
| HNB | 24 (3) | 0 (0) | - | 0 (0) | 5 (0) | 1 (0) | 33 (13) |
| AVFWNB | 35 (32) | 5 (0) | 36 (31) | - | 36 (24) | 35 (23) | 36 (32) |
| AIWNB | 34 (21) | 0 (0) | 29 (21) | 0 (0) | - | 17 (6) | 35 (24) |
| AODE | 34 (17) | 1 (0) | 34 (18) | 1 (0) | 18 (0) | - | 35 (25) |
| TAN | 8 (0) | 0 (0) | 2 (0) | 0 (0) | 0 (0) | 0 (0) | - |
| Algorithm | Losses-Wins | Losses | Wins |
|---|---|---|---|
| TAN | 133 | 133 | 0 |
| IWHNB | 97 | 106 | 9 |
| HNB | 87 | 103 | 16 |
| AODE | −8 | 52 | 60 |
| AIWNB | −23 | 49 | 72 |
| AVFWNB | −136 | 6 | 142 |
| NB | −150 | 0 | 150 |
5. Conclusions and Future Work
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Data Availability Statement
Conflicts of Interest
Abbreviations
| NB | Naive Bayes |
| HNB | Hidden NB |
| AVFWNB | Attribute Value Frequency Weighted NB |
| AIWNB | Attribute and Instance Weighted NB |
| AODE | Aggregating One-Dependence Estimators |
| TAN | Tree-augmented NB |
| IWHNB | Instance Weighted HNB |
| BN | Bayesian Network |
| WAODE | Weighted Average of One-Dependence Estimators |
| UCI | University of California, Irvine |
| WEKA | Waikato Environment for Knowledge Analysis |
| MDL | Minimum Description Length |
| NP | Non-deterministic Polynomial |
References
- Zhang, Y.; Wu, J.; Zhou, C.; Cai, Z. Instance cloned extreme learning machine. Pattern Recognit. 2017, 68, 52–65. [Google Scholar] [CrossRef]
- Yu, L.; Jiang, L.; Wang, D.; Zhang, L. Attribute Value Weighted Average of One-Dependence Estimators. Entropy 2017, 19, 501. [Google Scholar] [CrossRef] [Green Version]
- Wu, J.; Cai, Z.; Zhu, X. Self-adaptive probability estimation for Naive Bayes classification. In Proceedings of the International Joint Conference on Neural Networks, Dallas, TX, USA, 4–9 August 2013. [Google Scholar]
- Qiu, C.; Jiang, L.; Li, C. Not always simple classification: Learning superparent for class probability estimation. Expert Syst. Appl. 2015, 42, 5433–5440. [Google Scholar] [CrossRef]
- Jiang, L.; Wang, S.; Li, C.; Zhang, L. Structure extended multinomial naive Bayes. Inf. Sci. 2016, 329, 346–356. [Google Scholar] [CrossRef]
- Yu, L.; Gan, S.; Chen, Y.; He, M. Correlation-Based Weight Adjusted Naive Bayes. IEEE Access 2020, 8, 51377–51387. [Google Scholar] [CrossRef]
- Jiang, L.; Li, C.; Cai, Z. Learning decision tree for ranking. Knowl. Inf. Syst. 2009, 20, 123–135. [Google Scholar] [CrossRef]
- Bai, Y.; Wang, H.; Wu, J.; Zhang, Y.; Jiang, J.; Long, G. Evolutionary lazy learning for Naive Bayes classification. In Proceedings of the 2016 International Joint Conference on Neural Networks (IJCNN), Vancouver, BC, Canada, 24–29 July 2016; pp. 3124–3129. [Google Scholar]
- Bermejo, P.; Gámez, J.A.; Puerta, J.M. Speeding up incremental wrapper feature subset selection with Naive Bayes classifier. Knowl.-Based Syst. 2014, 55, 140–147. [Google Scholar] [CrossRef]
- Hall, M. A decision tree-based attribute weighting filter for naive Bayes. Knowl.-Based Syst. 2007, 20, 120–126. [Google Scholar] [CrossRef] [Green Version]
- Webb, G.I.; Boughton, J.R.; Fei, Z.; Ting, K.; Salem, H. Learning by extrapolation from marginal to full-multivariate probability distributions: Decreasingly naive Bayesian classification. Mach. Learn. 2012, 86, 233–272. [Google Scholar] [CrossRef] [Green Version]
- Webb, G.I.; Boughton, J.R.; Wang, Z. Not so naive Bayes: Aggregating one-dependence estimators. Mach. Learn. 2005, 58, 5–24. [Google Scholar] [CrossRef] [Green Version]
- Yang, Y.; Webb, G.; Korb, K.; Boughton, J.; Ting, K. To Select or To Weigh: A Comparative Study of Linear Combination Schemes for SuperParent-One-Dependence Estimators. IEEE Trans. Knowl. Data Eng. 2007, 9, 1652–1665. [Google Scholar] [CrossRef] [Green Version]
- Friedman, N.; Geiger, D.; Goldszmidt, M. Bayesian network classifiers. Mach. Learn. 1997, 29, 131–163. [Google Scholar] [CrossRef] [Green Version]
- Jiang, L.; Wang, D.; Cai, Z. Discriminatively weighted naive bayes and its application in text classification. Int. J. Artif. Intell. Tools 2012, 21, 1250007. [Google Scholar] [CrossRef]
- Jiang, L.; Guo, Y. Learning Lazy Naive Bayesian Classifiers for Ranking. In Proceedings of the 17th IEEE International Conference on Tools with Artificial Intelligence, Hong Kong, China, 14–16 November 2005; pp. 412–416. [Google Scholar]
- Jiang, L.; Cai, Z.; Wang, D. Improving Naive Bayes for Classification. Int. J. Comput. Appl. 2010, 32, 328–332. [Google Scholar] [CrossRef]
- Xu, W.; Jiang, L.; Yu, L. An attribute value frequency-based instance weighting filter for naive Bayes. J. Exp. Theor. Artif. Intell. 2019, 31, 225–236. [Google Scholar] [CrossRef]
- Kohavi, R. Scaling Up the Accuracy of Naive-Bayes Classifer: A Decision-Tree Hybrid. In Proceedings of the Second International Conference on Knowledge Discovery and Data Mining; AAAI Press: Portland, ON, USA, 1996; pp. 202–207. [Google Scholar]
- Xie, Z.; Hsu, W.; Liu, Z.; Lee, M. A Selective Neighborhood Based Naive Bayes for Lazy Learning. In Proceedings of the Sixth Pacific Asia Conference on KDD; Springer: Berlin/Heidelberg, Germany, 2002; pp. 104–114. [Google Scholar]
- Frank, E.; Hall, M.; Pfahringer, B. Locally Weighted Naive Bayes. In Proceedings of the Nineteenth Conference on Uncertainty in Artificial Intelligence; Morgan Kaufmann Publishers Inc.: San Francisco, CA, USA, 2003; pp. 249–256. [Google Scholar]
- Lee, C.H.; Gutierrez, F.; Dou, D. Calculating feature weights in naive bayes with kullback-leibler measure. In Proceedings of the 11th International Conference on Data Mining, Vancouver, BC, Canada, 11–14 December 2011; pp. 1146–1151. [Google Scholar]
- Jiang, L.; Zhang, L.; Li, C.; Wu, J. A Correlation-Based Feature Weighting Filter for Naive Bayes. IEEE Trans. Knowl. Data Eng. 2019, 31, 201–213. [Google Scholar] [CrossRef]
- Zhang, H.; Jiang, L.; Yu, L. Class-specific Attribute Value Weighting for Naive Bayes. Inf. Sci. 2020, 508, 260–274. [Google Scholar] [CrossRef]
- Zaidi, N.A.; Cerquides, J.; Carman, M.J.; Webb, G.I. Alleviating naive Bayes attribute independence assumption by attribute weighting. J. Mach. Learn. Res. 2013, 14, 1947–1988. [Google Scholar]
- Jiang, L.; Li, C.; Wang, S.; Zhang, L. Deep feature weighting for naive Bayes and its application to text classification. Eng. Appl. Artif. Intell. 2016, 52, 26–39. [Google Scholar] [CrossRef]
- Langley, P.; Sage, S. Induction of selective Bayesian classifiers. In Proceedings of the Tenth International Conference on Uncertainty in Artificial Intelligence; Morgan Kaufmann: San Francisco, CA, USA, 1994; pp. 339–406. [Google Scholar]
- Jiang, L.; Cai, Z.; Zhang, H.; Wang, D. Not so greedy: Randomly Selected Naive Bayes. Expert Syst. Appl. 2012, 39, 11022–11028. [Google Scholar] [CrossRef]
- Jiang, L.; Zhang, H.; Cai, Z.; Su, J. Evolutional naive bayes. In Proceedings of the 2005 International Symposium on Intelligent Computation and Its Application, Wuhan, China, 22–24 October 2005; pp. 344–350. [Google Scholar]
- Chen, S.; Webb, G.; Liu, L.; Ma, X. A novel selective naïve Bayes algorithm. Knowl.-Based Syst. 2020, 192, 105361. [Google Scholar] [CrossRef]
- Xiang, Z.; Kang, D. Attribute weighting for averaged one-dependence estimators. Appl. Intell. 2017, 46, 616–629. [Google Scholar] [CrossRef]
- Yu, L.; Jiang, L.; Wang, D.; Zhang, L. Toward naive Bayes with attribute value weighting. Neural Comput. Appl. 2019, 31, 5699–5713. [Google Scholar] [CrossRef]
- Jiang, L.; Zhang, H.; Cai, Z. A novel Bayes model: Hidden naive Bayes. IEEE Trans. Knowl. Data Eng. 2009, 21, 1361–1371. [Google Scholar] [CrossRef]
- Jiang, L.; Zhang, H.; Cai, Z.; Wang, D. Weighted average of one-dependence estimators. J. Exp. Theor. Artif. Intell. 2012, 24, 219–230. [Google Scholar] [CrossRef]
- Zhang, H.; Jiang, L.; Yu, L. Attribute and instance weighted naive Bayes. Pattern Recognit. 2021, 111, 107674. [Google Scholar] [CrossRef]
- Langley, P.; Iba, W.; Thompson, K. An Analysis of Bayesian Classifiers. In Proceedings of the 10th National Conference on Artificial Intelligence, San Jose, CA, USA, 12–16 July 1992; pp. 223–228. [Google Scholar]
- Frank, A.; Asuncion, A. UCI Machine Learning Repository; University of California: Irvine, CA, USA, 2010. [Google Scholar]
- Witten, I.H.; Frank, E.; Hall, M.A. Data Mining: Practical Machine Learning Tools and Techniques, 3rd ed.; Morgan Kaufmann: San Francisco, CA, USA, 2011. [Google Scholar]
- Fayyad, U.M.; Irani, K.B. Multi-interval discretization of continuous-valued attributes for classification learning. In Proceedings of the 13th International Joint Conference on Articial Intelligence, Chambéry, France, 28 August–3 September 1993; pp. 1022–1027. [Google Scholar]
- Nadeau, C.; Bengio, Y. Inference for the Generalization Error. Mach. Learn. 2003, 52, 239–281. [Google Scholar] [CrossRef] [Green Version]
- Jiang, L.; Zhang, L.; Yu, L.; Wang, D. Class-specific attribute weighted naive Bayes. Pattern Recognit. 2019, 88, 321–330. [Google Scholar] [CrossRef]

| Dataset | IWHNB | NB | HNB | AVFWNB | AIWNB | AODE | TAN | ||||||||||||||||||||
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| anneal | 98.31 | ± | 1.29 | 96.13 | ± | 2.16 | • | 98.33 | ± | 1.22 | 98.62 | ± | 1.15 | 98.94 | ± | 1.05 | 98.01 | ± | 1.39 | 98.61 | ± | 1.02 | |||||
| anneal.ORIG | 94.65 | ± | 2.24 | 92.66 | ± | 2.72 | • | 95.29 | ± | 2.04 | 93.32 | ± | 2.65 | • | 95.06 | ± | 2.23 | 93.35 | ± | 2.53 | 94.55 | ± | 2.10 | ||||
| audiology | 78.17 | ± | 7.15 | 71.40 | ± | 6.37 | • | 69.04 | ± | 5.83 | • | 78.58 | ± | 8.44 | 83.93 | ± | 7.00 | ∘ | 71.66 | ± | 6.42 | • | 65.35 | ± | 6.84 | • | |
| autos | 85.56 | ± | 7.93 | 72.30 | ± | 10.31 | • | 82.17 | ± | 8.60 | 77.27 | ± | 9.43 | • | 78.04 | ± | 9.02 | • | 80.74 | ± | 8.68 | 80.85 | ± | 8.99 | • | ||
| balance-scale | 69.05 | ± | 3.74 | 71.08 | ± | 4.29 | ∘ | 69.05 | ± | 3.75 | 71.10 | ± | 4.30 | ∘ | 73.75 | ± | 4.22 | ∘ | 69.34 | ± | 3.82 | 70.75 | ± | 3.99 | ∘ | ||
| breast-cancer | 70.47 | ± | 6.29 | 72.94 | ± | 7.71 | 73.09 | ± | 6.11 | 71.41 | ± | 7.98 | 71.90 | ± | 7.55 | 72.53 | ± | 7.15 | 69.53 | ± | 7.13 | ||||||
| breast-w | 96.30 | ± | 1.94 | 97.25 | ± | 1.79 | 96.32 | ± | 2.01 | 97.48 | ± | 1.68 | ∘ | 97.17 | ± | 1.68 | 96.97 | ± | 1.87 | 96.27 | ± | 2.08 | |||||
| colic | 81.20 | ± | 6.00 | 81.39 | ± | 5.74 | 82.09 | ± | 5.86 | 81.47 | ± | 5.86 | 83.45 | ± | 5.45 | 82.64 | ± | 5.83 | 81.00 | ± | 5.86 | ||||||
| colic.ORIG | 74.23 | ± | 6.52 | 73.62 | ± | 6.83 | 74.06 | ± | 5.79 | 72.91 | ± | 6.34 | 73.87 | ± | 6.40 | 74.62 | ± | 6.51 | 68.31 | ± | 6.04 | • | |||||
| credit-a | 85.23 | ± | 3.82 | 86.25 | ± | 4.01 | 85.91 | ± | 3.70 | 86.23 | ± | 3.85 | 87.03 | ± | 3.83 | 86.71 | ± | 3.82 | 85.39 | ± | 3.81 | ||||||
| credit-g | 75.85 | ± | 3.69 | 75.43 | ± | 3.84 | 76.12 | ± | 3.72 | 75.38 | ± | 3.90 | 75.81 | ± | 3.60 | 76.50 | ± | 3.89 | 73.54 | ± | 4.16 | • | |||||
| diabetes | 76.75 | ± | 4.20 | 77.85 | ± | 4.67 | 76.81 | ± | 4.11 | 77.89 | ± | 4.66 | 77.87 | ± | 4.86 | 78.07 | ± | 4.56 | 78.70 | ± | 4.29 | ∘ | |||||
| glass | 77.70 | ± | 8.98 | 74.39 | ± | 7.95 | 77.80 | ± | 8.40 | 76.25 | ± | 8.07 | 74.02 | ± | 8.41 | 76.08 | ± | 8.07 | 76.23 | ± | 8.87 | ||||||
| heart-c | 81.52 | ± | 7.12 | 83.60 | ± | 6.42 | 82.31 | ± | 6.81 | 83.04 | ± | 6.68 | 82.71 | ± | 6.61 | 83.20 | ± | 6.20 | 81.62 | ± | 7.50 | ||||||
| heart-h | 84.56 | ± | 6.05 | 84.46 | ± | 5.92 | 84.87 | ± | 6.03 | 84.90 | ± | 5.68 | 84.29 | ± | 5.85 | 84.43 | ± | 5.92 | 84.05 | ± | 6.66 | ||||||
| heart-statlog | 82.33 | ± | 6.59 | 83.74 | ± | 6.25 | 82.33 | ± | 6.55 | 83.78 | ± | 6.29 | 83.22 | ± | 6.61 | 83.33 | ± | 6.61 | 82.44 | ± | 6.48 | ||||||
| hepatitis | 87.38 | ± | 8.43 | 84.22 | ± | 9.41 | 88.26 | ± | 7.28 | 85.38 | ± | 9.00 | 85.75 | ± | 8.97 | 84.98 | ± | 9.26 | 86.01 | ± | 8.25 | ||||||
| hypothyroid | 99.32 | ± | 0.40 | 98.48 | ± | 0.59 | • | 98.95 | ± | 0.48 | • | 98.98 | ± | 0.48 | • | 99.07 | ± | 0.48 | 98.76 | ± | 0.54 | • | 99.15 | ± | 0.44 | ||
| ionosphere | 93.96 | ± | 3.65 | 90.77 | ± | 4.76 | • | 91.82 | ± | 4.33 | • | 91.94 | ± | 4.09 | 92.40 | ± | 4.13 | 92.79 | ± | 4.26 | 92.25 | ± | 4.33 | ||||
| iris | 93.27 | ± | 5.72 | 94.47 | ± | 5.61 | 93.80 | ± | 5.86 | 94.40 | ± | 5.50 | 94.40 | ± | 5.50 | 93.20 | ± | 5.76 | 94.20 | ± | 5.74 | ||||||
| kr-vs-kp | 92.70 | ± | 1.37 | 87.79 | ± | 1.91 | • | 92.36 | ± | 1.30 | • | 88.18 | ± | 1.86 | • | 93.73 | ± | 1.28 | ∘ | 91.01 | ± | 1.67 | • | 92.88 | ± | 1.49 | |
| labor | 95.90 | ± | 9.21 | 93.13 | ± | 10.56 | 94.87 | ± | 9.82 | 94.33 | ± | 10.13 | 94.33 | ± | 9.30 | 94.70 | ± | 9.15 | 92.47 | ± | 10.89 | ||||||
| letter | 90.17 | ± | 0.62 | 74.00 | ± | 0.88 | • | 88.20 | ± | 0.66 | • | 75.07 | ± | 0.84 | • | 75.56 | ± | 0.89 | • | 88.76 | ± | 0.70 | • | 85.49 | ± | 0.76 | • |
| lymphography | 85.89 | ± | 8.02 | 84.97 | ± | 8.30 | 85.84 | ± | 8.86 | 85.49 | ± | 7.83 | 84.68 | ± | 7.99 | 86.98 | ± | 8.32 | 85.30 | ± | 8.79 | ||||||
| mushroom | 99.96 | ± | 0.06 | 95.52 | ± | 0.78 | • | 99.94 | ± | 0.10 | 99.12 | ± | 0.31 | • | 99.53 | ± | 0.23 | • | 99.95 | ± | 0.07 | 99.99 | ± | 0.04 | |||
| primary-tumor | 46.14 | ± | 6.17 | 47.20 | ± | 6.02 | 47.66 | ± | 6.21 | 45.85 | ± | 6.53 | 47.76 | ± | 5.25 | 47.67 | ± | 6.30 | 44.77 | ± | 6.84 | ||||||
| segment | 96.87 | ± | 1.07 | 91.71 | ± | 1.68 | • | 95.88 | ± | 1.19 | • | 93.69 | ± | 1.41 | • | 94.16 | ± | 1.38 | • | 95.77 | ± | 1.23 | • | 95.58 | ± | 1.32 | • |
| sick | 97.52 | ± | 0.76 | 97.10 | ± | 0.84 | • | 97.56 | ± | 0.74 | 97.02 | ± | 0.86 | • | 97.33 | ± | 0.85 | 97.39 | ± | 0.79 | 97.40 | ± | 0.76 | ||||
| sonar | 84.63 | ± | 7.72 | 85.16 | ± | 7.52 | 84.63 | ± | 7.34 | 84.49 | ± | 7.79 | 82.23 | ± | 8.65 | 86.60 | ± | 6.91 | 84.45 | ± | 8.31 | ||||||
| soybean | 94.61 | ± | 2.18 | 92.20 | ± | 3.23 | • | 93.88 | ± | 2.47 | 94.52 | ± | 2.36 | 94.74 | ± | 2.19 | 93.28 | ± | 2.84 | 94.98 | ± | 2.38 | |||||
| splice | 96.24 | ± | 1.00 | 95.42 | ± | 1.14 | • | 95.84 | ± | 1.10 | • | 95.61 | ± | 1.11 | • | 96.21 | ± | 0.99 | 96.12 | ± | 1.00 | 94.95 | ± | 1.18 | • | ||
| vehicle | 73.70 | ± | 3.41 | 62.52 | ± | 3.81 | • | 72.37 | ± | 3.35 | • | 63.36 | ± | 3.87 | • | 63.59 | ± | 3.92 | • | 72.31 | ± | 3.62 | 73.39 | ± | 3.26 | ||
| vote | 94.39 | ± | 3.21 | 90.21 | ± | 3.95 | • | 94.43 | ± | 3.18 | 90.25 | ± | 3.95 | • | 92.18 | ± | 3.76 | • | 94.52 | ± | 3.19 | 94.43 | ± | 3.34 | |||
| vowel | 90.32 | ± | 2.71 | 65.23 | ± | 4.53 | • | 85.12 | ± | 3.65 | • | 67.46 | ± | 4.62 | • | 69.98 | ± | 4.11 | • | 80.87 | ± | 3.82 | • | 86.09 | ± | 3.91 | • |
| waveform-5000 | 86.24 | ± | 1.45 | 80.72 | ± | 1.50 | • | 86.21 | ± | 1.44 | 80.65 | ± | 1.46 | • | 82.98 | ± | 1.37 | • | 86.03 | ± | 1.56 | 82.22 | ± | 1.71 | • | ||
| zoo | 98.33 | ± | 3.72 | 93.98 | ± | 7.14 | 97.73 | ± | 4.64 | 96.05 | ± | 5.60 | 96.05 | ± | 5.60 | 94.66 | ± | 6.38 | 95.15 | ± | 6.68 | ||||||
| Average | 86.37 | 83.31 | 85.86 | 84.21 | 84.94 | 85.68 | 84.95 | ||||||||||||||||||||
| W/T/L | - | 17/18/1 | 9/27/0 | 13/21/2 | 8/25/3 | 6/30/0 | 9/25/2 | ||||||||||||||||||||
| Algorithm | IWHNB | NB | HNB | AVFWNB | AIWNB | AODE | TAN |
|---|---|---|---|---|---|---|---|
| IWHNB | - | 11 (1) | 17 (0) | 12 (2) | 15 (3) | 14 (0) | 11 (2) |
| NB | 25 (17) | - | 27 (16) | 26 (11) | 27 (15) | 29 (13) | 20 (13) |
| HNB | 18 (9) | 9 (1) | - | 13 (3) | 16 (4) | 18 (1) | 12 (2) |
| AVFWNB | 24 (13) | 10 (0) | 23 (11) | - | 25 (10) | 24 (10) | 16 (8) |
| AIWNB | 21 (8) | 9 (0) | 20 (7) | 8 (0) | - | 21 (8) | 15 (6) |
| AODE | 22 (6) | 7 (1) | 18 (3) | 12 (3) | 15 (7) | - | 16 (4) |
| TAN | 25 (9) | 16 (2) | 24 (5) | 20 (2) | 21 (5) | 20 (6) | - |
| Algorithm | Wins-Losses | Wins | Losses |
|---|---|---|---|
| IWHNB | 54 | 62 | 8 |
| HNB | 22 | 42 | 20 |
| AIWNB | 15 | 44 | 29 |
| AODE | 14 | 38 | 24 |
| TAN | 6 | 35 | 29 |
| AVFWNB | −31 | 21 | 52 |
| NB | −80 | 5 | 85 |
Publisher’s Note: MDPI stays neutral with regard to jurisdictional claims in published maps and institutional affiliations. |
© 2021 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Yu, L.; Gan, S.; Chen, Y.; Luo, D. A Novel Hybrid Approach: Instance Weighted Hidden Naive Bayes. Mathematics 2021, 9, 2982. https://doi.org/10.3390/math9222982
Yu L, Gan S, Chen Y, Luo D. A Novel Hybrid Approach: Instance Weighted Hidden Naive Bayes. Mathematics. 2021; 9(22):2982. https://doi.org/10.3390/math9222982
Chicago/Turabian StyleYu, Liangjun, Shengfeng Gan, Yu Chen, and Dechun Luo. 2021. "A Novel Hybrid Approach: Instance Weighted Hidden Naive Bayes" Mathematics 9, no. 22: 2982. https://doi.org/10.3390/math9222982
APA StyleYu, L., Gan, S., Chen, Y., & Luo, D. (2021). A Novel Hybrid Approach: Instance Weighted Hidden Naive Bayes. Mathematics, 9(22), 2982. https://doi.org/10.3390/math9222982