1. Introduction
Time series classification (TSC) is a hot topic with applications in many fields, including economics, finance, environmental sciences, medicine, physics, speech recognition and multimedia, among many others. Given a set of univariate (UTS) or multivariate (MTS) time series with class labels, the target is to train an algorithm to predict the class of unlabelled time series. Unlike UTS, MTS involve a number of variables or dimensions which should be jointly considered to extract information about its right class label. Although many algorithms have been developed in the last few years for univariate time series classification (UTSC), multivariate time series classification (MTSC) has received much less attention (a review on the topic of feature-based MTSC can be seen in [
1]). However, the increasing amount of data that are generated every day by sensors and Internet of Things (IoT) devices makes totally pivotal the development of fast and accurate MTSC algorithms. For instance, it is common for doctors to decide whether or not a patient is likely to suffer a myocardial infarction based on multivariate ECG data. The availability of MTSC approaches capable of tackling this task in an automated manner could free healthcare professionals from individually examining each ECG, resulting in increased efficiency. Similar examples can be extracted from different application fields. In [
2], a comprehensive overview on MTSC, including current advances, future prospects, important references and several application areas, is provided.
One of the first approaches for MTSC was introduced in the early work [
3]. Each MTS is characterised by means of a set of spectral matrices and then a classifier based on measures of divergence between the corresponding sets is proposed. By nature, this approach is aimed at classifying MTS according to the underlying multivariate process. However, in [
3], the procedure is only assessed with a real dataset of MTS coming either from earthquakes or explosions without reporting the results of its behaviour for different generating models.
Some approaches for MTSC based on dimensionality reduction techniques were introduced in the last decade [
4,
5,
6]. In [
4,
5], two different procedures of feature selection for MTS using the singular value decomposition (SVD) were proposed. The first approach considers the first singular vector, whereas the second one considers the first two dominating singular vectors weighted by their associated singular values. The correlations between dimensions are taken into account in both cases, but the class labels are ignored when the feature extraction is performed. To address this issue, Weng and Xen [
6] proposed to classify MTS by using locality preserving projections (LPP). The method consists of two steps. First, feature extraction is carried out by using one of the approaches in [
4] or [
5]. Second, the feature vectors are projected in a lower dimensional space in a way that MTS sharing the same class label are close to each other. In the reported simulation study, Weng and Xen [
6] also considered the two-dimensional singular value decomposition (2dSVD) for MTSC, which was introduced in [
7] as an extension of the classical SVD to sets of 2D objects, as matrices.
A classical technique to perform TSC is based on the dynamic time warping (DTW) distance along with the one nearest neighbour (1NN) classifier (see, e.g., [
8,
9]). Two main extensions of this distance are frequently used in MTSC tasks [
10]. Furthermore, multivariate DTW has been used along with other distances to develop some sophisticated MTSC procedures. In this regard, Mei et al. [
11] proposed an approach considering DTW and the Mahalanobis distance. Bankó and Abonyi [
12] presented a novel algorithm called correlation based dynamic time warping where DTW and PCA-based similarity measures are combined so that the correlation between dimensions is taken into consideration in the classification procedure. Górecki and Luczak [
13] introduced a method called derivative dynamic time warping where the distance between two MTS is defined as a convex combination of the multivariate DTW distances between them and between their derivatives. A hyperparameter
chosen in the learning phase (by leave-one-out cross-validation) determines the weight of each individual distance and the 1NN rule is used to classify new observations. The procedure is shown to improve the results achieved by DTW in some datasets. Due to their generally great performance on classifying MTS, the multivariate extensions of DTW distance with the 1NN classifier are usually considered as a benchmark when a new MTS classification approach is introduced [
11,
14,
15,
16]. Indeed, in [
14], where an extensive analysis of some of the most promising approaches for MTSC is performed, the authors conclude that:
The standard TSC benchmark, DTW, is still hard to beat and competitive with more recently proposed alternatives.
Approaches based on word extraction and symbolic representations have also been constructed for MTSC. Schäfer and Leser [
16] proposed WEASEL+MUSE, which builds a multivariate feature vector, first using a sliding window approach applied to each UTS constituting the MTS and then extracting the discrete features by window and dimension. Next, the feature vector is utilised in a traditional classifier. WEASEL+MUSE is based on the WEASEL classifier that the same authors proposed for UTS relying on a similar idea [
17]. Baydogan and Runger [
18] introduced a classifier based on a new symbolic representation, called SMTS, where all the dimensions are simultaneously considered. The procedure builds on the application of two random forests, one for variable selection and the other for the classification task.
The well-known idea of ensemble learning has also played a central role in MTSC in recent years. The most successful method considering this approach is the Hierarchical Vote Collective of Transformation-based Ensembles, so-called HIVE-COTE, which combines classifiers based on five types of discriminatory features. Although it was originally designed for UTSC [
19], a multivariate extension can easily be developed by building each component as an independent ensemble [
14]. Multivariate HIVE-COTE is, on average, one of the best performing algorithms when dealing with the datasets contained in the University of East Anglia (UEA) multivariate time series classification archive [
20].
Deep learning algorithms have also been applied to MTSC during the last few years. Karim et al. [
15] proposed a long short-term memory fully convolutional network (LSTM-FCN) to perform the classification task. This work is an extension of a previous work where a fully convolutional with long short-term memory recurrent neural network is introduced to perform UTSC [
21]. The results given in [
15] indicate that the LSTM-FCN beats the state of the art in many of the considered datasets. However, it is worth mentioning that these results differ from the ones reported in [
14], where LSTM-FCN was tested in some of the same datasets. As it is stated there:
The deep learning algorithms have been disappointing in these experiments. They have a tendency to occasionally completely fail. No doubt these will be improved over time, but, as yet, they are not consistently state-of-the-art. This casts doubt on the ability of the current deep learning techniques to solve MTSC problems. Liu, Hsaio and Tu [
22] designed a methodology for MTSC relying on convolutional neural networks (CNN). The approach is based on a tensor scheme along with an innovative deep learning architecture considering multivariate and lag-feature characteristics. Fan, Shrestha and Qiu [
23] presented a technique to classify spatial temporal patterns which employs spiking neural networks (SNN). The method is evaluated in some MTS datasets, achieving a performance comparable to deep neural networks.
There also exists some methods based solely on statistical feature extraction and then on feeding a traditional classifier with the extracted features. For example, Zagorecki [
24] developed a generic method which extracts many statistical quantities from a given MTS. The majority of those are derived from each UTS individually, but the approach also considers the cross-correlation between each pair of UTS, thus accounting for the relationship between dimensions. This method was the runner-up in the 2015 AAIA Data Mining Competition [
25], in which 80 participant teams took part, thus proving itself as a powerful approach.
The above-mentioned MTSC methods are fairly general in the sense that they are presented to be applied to an arbitrary MTS dataset. A few other proposed approaches are domain-specific. In [
26], an approach particularly designed to classify multivariate ECG data is provided. The method performs feature extraction via the maximum overlap discrete wavelet transform (MODWT), and the features are then used to feed a linear or quadratic discriminant analysis classifier. The approach is shown to compare favourably with other techniques for classifying ECG signals. Formisano, De Martino and Valente [
27] designed a straightforward approach to classify multivariate functional magnetic resonance imaging (fMRI) signals involving two steps: feature selection based on raw fMRI data through recursive feature elimination, and application of a support vector machine considering the selected features. Seto, Zhang and Zhou [
28] presented a technique for classifying MTS from human activity recognition. It first builds a paragon for each class by using cluster analysis in the training data. Then, feature extraction is performed via DTW and a classifier, such as the support vector machine, is applied.
Aside from [
3,
26], all the mentioned approaches address the MTSC task from a shape-based point of view, in the sense that they assume that MTS in different classes are mainly characterised by different geometric profiles. It seems surprising that, in the last 20 years, almost nobody has proposed a procedure for classifying MTS in a setting where the different categories are associated with distinct underlying generating processes. Furthermore, although the approaches in [
3,
26] should be able to distinguish between generating processes, their performance is only illustrated with real datasets in those works. Thus, their effectiveness under different dependence structures between classes has not been examined. To the best of our knowledge, none of the existing MTSC approaches have been evaluated in a scenario with different multivariate generating processes. However, such a situation is not uncommon. For instance, it is well known that the MTS of daily returns of different pairs of sector indexes can be modelled by means of multivariate generalized autoregressive conditional heteroscedasticity (MGARCH) models with different coefficients [
29]. Furthermore, multivariate electroencephalogram (EEG) signals collected from a group of subjects have been shown to follow vector autoregressive moving average (VARMA) models whose coefficients depend on the specific mental task that the subject is performing [
30].
In addition, due to the lack of methods addressing the MTSC task from the previously stated point of view, it remains uncertain if a classifier of this nature would do a good job when dealing with the real datasets most commonly considered in MTSC, for example, the ones included in the UEA multivariate time series classification archive. The archive consists of 30 MTS datasets covering a wide range of cases, dimensions and series lengths. Some approaches such as multivariate DTW, WEASEL + MUSE and HIVE-COTE have been tested with these datasets, showing a great performance. However, it remains totally unanswered if the different classes in these datasets, or at least in some of them, can be described by means of the underlying dependence structures in addition to the shapes. If so, the implications of this fact would be profound, as it would encourage researchers to take into account dependence measures when coping with a MTSC task.
The first contribution of this paper is to introduce a novel approach for classifying MTS aimed at discriminating between underlying generating processes. The proposed classifier is based on the quantile cross-spectral density (QCD) and the maximum overlap discrete wavelet transform (MODWT). Both spectral tools are utilised to extract suitable features, which are then used to feed a random forest classifier. Consideration of QCD and MODWT is motivated by our previous work [
31], where they separately proved their usefulness in MTS clustering, exhibiting a high discriminatory power. Unlike other conventional spectral features, quantile cross-spectral densities examine the dependence between the components in quantiles, thus allowing us to simultaneously characterise cross-sectional and serial dependence, exhibiting robustness to outliers and heavy tails and capturing changes in the conditional shape (skewness, kurtosis). On the other hand, the wavelet features are useful to distinguish between signals with spectra changing over time and hence particularly suitable to deal with nonstationary processes. Therefore, both feature types provide a valuable picture of the underlying dynamic structures and report complementary information so that their combined use is expected to increase the classification accuracy. Our approach avoids the need to analyse and model each single MTS, which is computationally expensive and far from being the actual goal. The second contribution of this work is to show how the proposed methodology can be successfully applied to discriminate between ECG signals of healthy subjects and those with myocardial infarction condition, which is an active and important research topic. Finally, the third contribution is to show the excellent results reached by the proposed approach in some classical MTS datasets despite lacking shape-based information.
The remainder of this paper is organised as follows. In
Section 2, we present the proposed classifier along with some related theoretical background and a toy example illustrating its usefulness.
Section 3 shows an extensive assessment of the proposed approach via a simulation study covering a broad variety of scenarios. The corresponding classes are represented by means of different stationary processes. The proposed classifier is compared with some competitive alternatives reported in the literature. In
Section 4, the classifier is evaluated in nonstationary settings. The effectiveness of the method and its competitors when varying the amount of training data and the series length is reported in
Section 5. The computation times of the analysed procedures are discussed through
Section 6.
Section 7 illustrates the application of the proposed methodology to a classical dataset containing ECG data. In
Section 8, the classification method is applied to some datasets in the UEA archive. Some concluding remarks and future work are provided in
Section 9.
2. A Combined Feature-Based Approach for Multivariate Time Series Classification
In this section, we present Fast Forest of Flexible Features (F4), the proposed approach for classifying MTS. After some brief comments on the considered features and some theoretical background, the classifier F4 is introduced and a motivating example is used to highlight the advantages of combining the selected features.
2.1. Combining Two Types of Features
F4 is based on a combination of two types of features. In [
31], we proposed a dissimilarity measure based on QCD to perform clustering of MTS, so-called
. In an extensive simulation study where a range of state-of-the-art dissimilarities were compared,
turned out to be the average best-performing measure, showing robustness against the generating mechanism and exhibiting low computation times. On the other hand, a dissimilarity based on multiple-scale wavelet variances and wavelet correlations, so-called
[
32] also worked very well in the majority of scenarios simulated in [
31], besides being the most efficient. Both
and
are simply Euclidean distances between extracted features and their high capability to discern between generating processes in an unsupervised learning context suggests great performance when facing supervised classification tasks. Furthermore, given their different nature, it is expected that a classifier considering both types of features significantly improves the behaviour of classifiers based on only one of these features. Whereas
focuses on capturing the dependence structure at different pairs of quantile levels,
relies on decomposing a signal into a set of mutually orthogonal wavelet basis functions. Both features complement each other, with
well suited to detect different dependence structures in parts of the joint distribution (which remain hidden for standard spectral measures), and
relying on a time-frequency analysis which allows us to capture differences in times where the changes occur, and hence particularly useful to deal with series exhibiting long-range dependence and nonstationarity.
2.2. Background
Some background knowledge of QCD and MODWT is provided below.
2.2.1. The Quantile Cross-Spectral Density
Following [
31], let
be a
d-variate real-valued strictly stationary stochastic process. Denote by
the marginal distribution function of
,
, and by
,
, the corresponding quantile function. Fixed
and an arbitrary couple of quantile levels
, consider the cross-covariance of the indicator functions
and
given by
for
. Taking
, the function
, with
, so-called quantile autocovariance function of lag
l, generalises the traditional autocovariance function.
In the case of the multivariate process
, we can consider the
matrix
which jointly provides information about both the cross-dependence (when
) and the serial dependence (because the lag
l is considered). To obtain a much richer picture of the underlying dependence structure,
can be computed over a range of prefixed values of
L lags,
, and
r quantile levels,
, thus having available the set of matrices
In the same way as the spectral density is the representation in the frequency domain of the autocovariance function, the spectral counterpart for the cross-covariances
can be introduced. Under suitable summability conditions (mixing conditions), the Fourier transform of the cross-covariances is well defined and QCD is given by
for
,
and
. Note that
is complex-valued so that it can be represented in terms of its real and imaginary parts, which will be denoted by
and
, respectively. The quantity
is known as quantile cospectrum of
and
, whereas the quantity
is called quantile quadrature spectrum of
and
.
Proceeding as in (
3), QCD can be evaluated on a range of frequencies
and of quantile levels
for every couple of components in order to obtain a complete representation of the process, i.e., consider the set of matrices
where
denotes the
matrix in
Representing
through
, a complete information on the general dependence structure of the process is available. As the true QCD is unknown, estimates of this quantity must be obtained. A consistent estimator of
is given by the so-called smoothed CCR-periodogram,
(see Equation (
10) in [
31]). Consistency and asymptotic performance of this estimator are established in Theorem S4.1 of [
33].
This way, the set of complex-valued matrices
in (
5) characterising the underlying process can be estimated by
where
is the matrix
2.2.2. The Maximum Overlap Discrete Wavelet Transform
Following [
32], we give some background of MODWT. The discrete wavelet transform (DWT) is a orthonormal transform which re-expresses a univariate time series of length
T in terms of coefficients that are associated with a particular time and dyadic scale as well as one or more scaling coefficients. A dyadic scale is of the form
, where
, and
J is the maximum allowable number of scales. Provided
, the number of coefficients at the
j-th scale is
. Generally, the wavelet coefficients at scale
are associated with frequencies in the interval
. Thus, large time scales give more low-frequency information, while small time scales give more high-frequency information. A UTS
can be recovered from its DWT by a multiresolution analysis (MRA), which is expressed as:
where
is the series of inverse of the series of wavelet coefficients at scale
j, called wavelet detail, and
is the smooth series, which is the inverse of the series of scaling coefficients.
The MODWT is a variation of the DWT. Under the MODWT, the number of resulting wavelet coefficients is the same as the length of the original series. The MODWT decomposition retains all of the possible times at each time scale, thus overcoming the lack of time invariance of the DWT. The MODWT can also be used to define a multiresolution analysis of a given time series. In contrast to the DWT, the MODWT details and smooths are associated with zero phase filters making it easy to line up features in a MRA with the original time series more meaningfully.
Let
,
, be a
j-level wavelet filter of length
associated with scale
. Let
be a discrete parameter stochastic process. Let
be the stochastic process by filtering
with the MODWT wavelet filter
. If it exists and is finite, the time independent variance at scale
is defined as
and the equality
holds. For more details, we refer the reader to [
34].
Given a time series
, which is a realisation of the stochastic process
, an unbiased estimator of
can be obtained by means of
where
are MODWT coefficients associated with the time series
and
are the number of wavelet coefficients excluding the boundary coefficients that are affected by the circular assumption of the wavelet filter. Let
and
be two appropriate stochastic processes with MODWT coefficients
and
, respectively, the wavelet covariance can be defined as
which gives a scale-based decomposition of the covariance between
and
, i.e.,
. Similarly, the wavelet correlation at scale
is defined as
where
and
are the wavelet variances of
and
, respectively. For two time series
and
, which are realisations of
and
, respectively, the estimator of
is obtained by replacing
,
and
by their estimators. Thus, by considering unbiased estimators
,
and
we obtain:
2.3. The Proposed Classifier
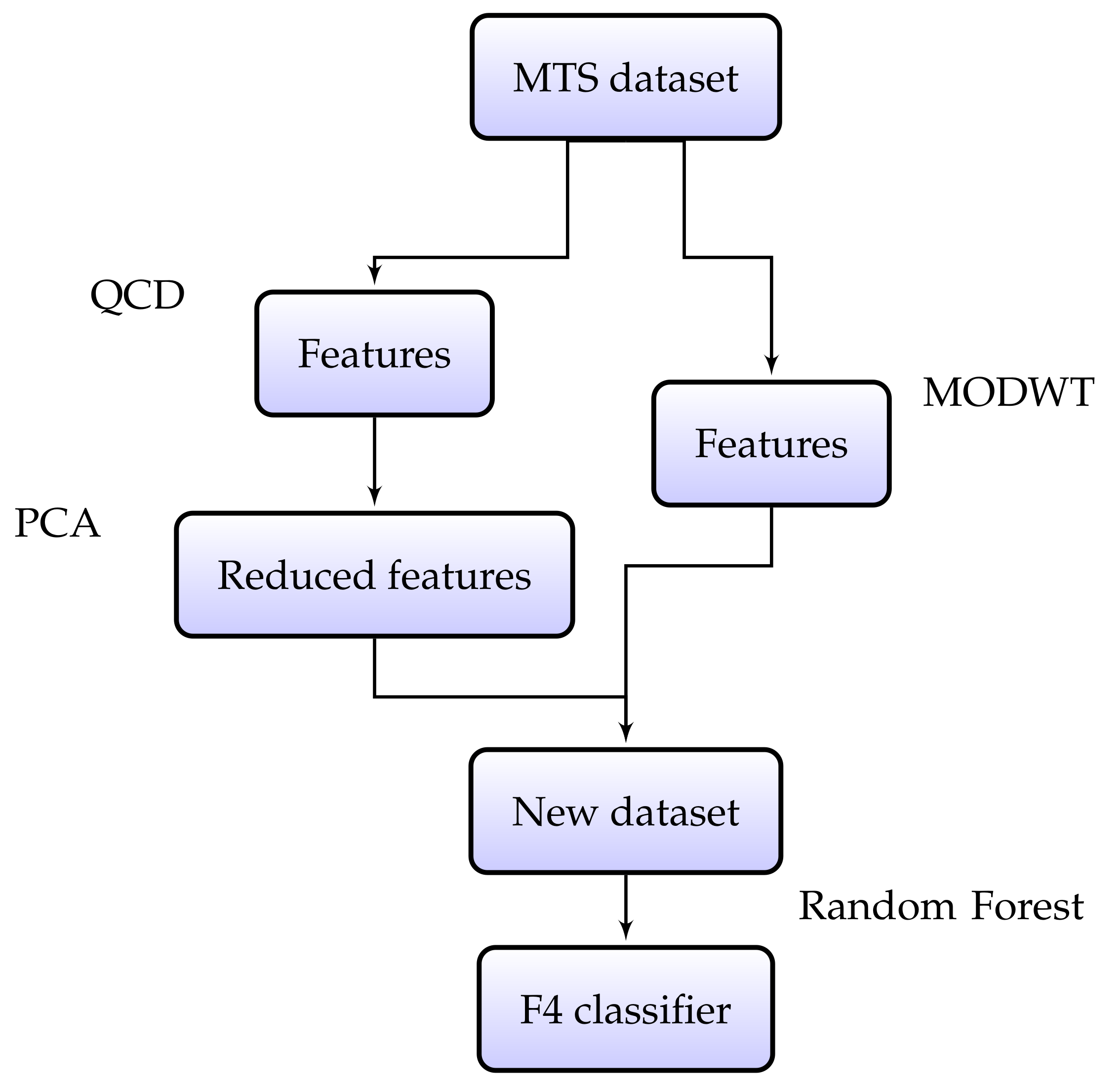
F4 consists of two main steps, namely (i) a feature extraction step and (ii) a classification step based on the extracted features. In the first step, each MTS in the original labelled sample is characterised by a vector of specific features as described below.
QCD-based features. Estimates of QCD are obtained via the smoothed CCR-periodogram
for each pair of UTS by considering the set of quantile levels
and the Fourier frequencies
. Then, each series is characterised by a vector consisting of the concatenation of the real and imaginary parts of all the elements in the set
,
, such as described in
Section 2.3 of our previous work [
31]. The classical principal component analysis (PCA) transformation is applied to the new dataset and the first ⌊
⌋ principal components are retained, ⌊
p⌋ being the number of principal components and · denoting the floor function. Our analyses have shown that the discriminatory power of the QCD-based features significantly improves when PCA is performed. In addition, the rate 0.12 has shown to give good results in a wide variety of situations. Apart from improving the classification performance, this dimensionality reduction step significantly reduces the runtime of F4.
MODWT-based features. Estimates of wavelet variances for each UTS and of wavelet correlations between each pair of UTS are extracted in a number of scales via the MODWT by considering (
10) and (
12), respectively. This requires choosing a wavelet filter of a given length and the number of scales. In [
31], we concluded that the wavelet filter of length 4 of the Daubechies family, DB4, along with the maximum allowable number of scales were the choices that led to the best average results in terms of clustering quality indexes. Thus, we decided to use these hyperparameters in F4 to perform supervised classification.
After the feature extraction stage, each MTS is replaced by a vector obtained by stacking the two individual vectors associated with each type of features. The new dataset is used as input to the random forest [
35], thus concluding the classification process. Indeed, a different classifier can be selected. In fact, our extensive numerical study also analysed the performance of the gradient boosting machine [
36] and different types of support vector machines. The support vector machines showed significantly worse performance than the tree-based classifiers in the majority of situations. The gradient boosting machine and the random forest obtained similar results, but the hyperparameter tuning stage is easier to carry out in the latter. In addition, the computation times were substantially lower for the random forest than for the gradient boosting machine. According with these arguments, the random forest was the classifier selected for F4.
It is worth remarking that F4 does not consider the fine-tuning of the hyperparameters involved in the feature extraction stage, namely the quantile levels, the number of selected principal components, the wavelet filter and the number of scales. Of course one could look for an optimal set of hyperparameters, for instance, via cross-validation and grid search, but this would substantially increase the computation time of F4.
Figure 1 shows a flowchart of F4 classifier.
2.4. Effectiveness of Combining Both Feature Types: An Illustrative Example
Consider a supervised classification problem consisting of three classes, each one of them defined by a linear, nonlinear and conditional heteroskedastic bivariate process, which are given below.
Class 3. Let
, denoting ⊺ the transpose operator. The data-generating process consists of two Gaussian GARCH models
In the three cases, the vector is an i.i.d. vector error process following a bivariate normal distribution with zero mean. The variance of and is 1. The covariance between and is 0 in Classes 1 and 2 and 0.5 in Class 3.
We simulated 50 realisations of length
from each class, which were randomly divided into equal sized training and testing sets to assess the performance of classifier F4. The classification was also carried out considering each kind of features separately. The average accuracies based on 400 trials of the simulation mechanism are given in
Table 1.
Even though the series length is substantially small, the classifiers based only on a feature type (QCD or MODWT) performed significantly better than a naive classifier (which here has an expected accuracy of 0.33). However, the combined classifier F4 led to a higher average score than the individual approaches. With the aim of rigorously confirming the superiority of F4, we performed Wilcoxon–Mann–Whitney tests. The 400 accuracy values obtained by F4 were compared either with the values attained by the QCD-based classifier or the MODWT-based classifier. In both cases, the alternative hypothesis stated that F4 achieves higher accuracy than the single classifier with a probability greater than 0.5. Both p-values were less than , thus indicating rejection of the null hypothesis.
Table 2 shows the average confusion matrices based on the 400 trials for QCD, MODWT and F4, respectively. Therefore, the quantities at each matrix add up to 75, the size of the test set. The diagonal elements are related to correct classifications, whereas the off-diagonal elements correspond to the different types of errors. All diagonal elements in the matrix obtained with F4 are greater than the corresponding ones in the other two matrices, thus indicating that F4 performed better than the individual classifiers with regards to the three classes. The greatest improvement occurred in Class 2, associated with the nonlinear MTS. An interesting aspect is that both individual classifiers are prone to different kinds of errors. For example, the QCD-based classifier is more likely to predict Class 3 from a series coming from Class 2, or to predict Class 2 for a series pertaining to Class 3. On the other hand, the MODWT-based classifier is more likely to anticipate Class 1 for an MTS coming from Class 2, or to predict Class 3 for an MTS belonging to Class 1.
It can be deduced from the previous remarks that, in this example, both single classifiers are able to extract from the data complementary information. Thus, the joint use of features extracted via QCD and via MODWT seems a reasonable choice in order to obtain improved performance in an MTSC problem.
8. Application to Some UEA Datasets
We now apply F4 to some datasets in the UEA multivariate time series classification archive. Training and testing sets are given in the archive for each dataset, thus allowing to perform a rigorous assessment of new MTSC algorithms. Notice that our goal here is not running F4 in each and every dataset and comparing the results with those that are state of the art. This would be unfair for F4, as it does not contain any shape or level-based information, such as the mean or the maximal or minimal values of each UTS constituting the given MTS, which are known to be proper discriminative features for the datasets in the archive (a simple graphical analysis of some MTS confirms this fact). Instead, we want to show how F4, which is mainly aimed at discriminating between generating processes, can also obtain good results when dealing with some real-life classification problems in which each class is characterised by a different geometric profile.
The considered datasets are summarised in
Table 8. They cover a broad variety of dimensions, series lengths and numbers of classes, thus constituting a heterogeneous subset of the UEA archive. Each dataset in
Table 8 pertains to a different problem. For instance, the data in RacketSports were created from university students playing badminton or squash while wearing a smart watch, the problem being to identify the sport and the stroke of each player. A summary of the corresponding problems can be seen in [
20].
The F4 algorithm, along with its competitors, was used to perform MTSC in the six considered datasets. We maintained the same setting considered throughout the work. Accuracies obtained in the test set are given in
Table 9. F4 got the best average results in these challenging scenarios, showing its huge versatility. It clearly beat KST and 2dSVD, and reaped better results than ZK and DTW in four out of the six datasets.
As a matter of fact, F4 attained perfect results with the datasets containing series of large length (Cricket, Epilepsy and Basic Motions), and worse results with the datasets containing series of short length (Libras and RacketSports). The exception to this fact was the dataset Handwriting. F4 achieved the worst results in this dataset. However, this could be due to the large number of existing classes (26), which makes the classification task in Handwriting particularly challenging. The previous insights are not surprising, since a larger value of the series length implies a more accurate estimate of QCD and the wavelet quantities. This suggests that F4 could be particularly useful when dealing with datasets containing long MTS.
9. Conclusions and Future Work
Given the massive amount of data that are generated everyday, TSC has become a topic of paramount importance. MTSC is a more challenging task than UTSC given the high dimensionality of MTS objects. Classification of MTS should take into account the relationships between dimensions. Whereas most of the approaches for MTSC are based on considering that the different classes are described by means of unequal geometric profiles, only a few authors have tackled the classification task from a point of view of multivariate generating processes. The first contribution of this paper was addressing that issue by proposing F4, a versatile, effective and efficient classifier for MTSC. F4 consists of two steps: feature extraction via QCD and MODWT, and feeding a traditional random forest classifier with the extracted features. F4 was tested in a wide variety of simulated scenarios, including stationary and nonstationary settings. In all of the considered cases, F4 led to very good results, comparing favourably with some powerful classifiers proposed in the literature.
The great performance of F4 when dealing with nonstationary MTS called for its evaluation in some real datasets, which are usually comprised of nonstationary series. Particularly, the UEA multivariate time series classification archive provided a good starting point. Actually, we were sceptical about F4 performing well in these datasets. Furthermore, we did not suspect that F4 would be able to beat ZK and DTW in some of them. The classes in these datasets are often characterised by changes in level and other shape patterns, and neither of them are taken into consideration by F4, which is mainly based on the dependence structure within and between MTS dimensions. Thus, another contribution of this work was to show that even in an MTSC problem calling for a shape-based classifier, a dependence-based classifier could be helpful.
Finally, F4 was also used to solve a classical problem in medicine: classifying ECG signals of MI and healthy patients. The approach was successful in discriminating between both types of signals in a well-known ECG dataset.
There are two main ways through which this work could be further developed. First, an extension of F4 considering the inclusion of geometric features could be constructed. This way, classification performance is likely to improve substantially, at least when coping with datasets such as the ones in the UEA archive. Indeed, we have already obtained promising preliminary results by considering this approach. Second, it would be interesting to design an even computationally cheaper version of F4 to properly cope with situations in which the number of dimensions becomes considerably large. Both approaches will be properly addressed in upcoming months.










{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}