Abstract
This paper proposes an effective extended reweighted minimization algorithm (ERMA) to solve the basis pursuit problem in compressed sensing, where , . The fast algorithm is based on linearized Bregman iteration with soft thresholding operator and generalized inverse iteration. At the same time, it also combines the iterative reweighted strategy that is used to solve problem, with the weight . Numerical experiments show that this minimization persistently performs better than other methods. Especially when , the restored signal by the algorithm has the highest signal to noise ratio. Additionally, this approach has no effect on workload or calculation time when matrix A is ill-conditioned.
1. Introduction
Image restoration is a fundamental problem in image processing. In particular, image deblurring has great application for facial alignment, remote sensing, medical image processing, camera equipment, compression transmission, and so on [1,2,3].
Let be an original signal with nonzero components ( is called —sparse signal or vector) and be the linear measurements with the form for some ,. Then, the compressed sensing problem can be represented as (1), where is the number of nonzero elements of vector .
The main purpose of compressive sensing is to recover the sparse signal from the inaccurate linear measurements. Namely, we shall identify valid algorithms for efficiently solving the indeterminate linear system.
Unfortunately, the minimization problem (1) is nonconvex and generally cannot be solved fast and efficiently. A common alternative is to consider the convex-relaxation of (1), i.e., basis pursuit problem [4,5]. The solution of the linear equations may not exist, and measurement may contain noise in certain applications. Thus, under such occasions we need to compute its least square solution.
There has been a recent flurry of study in compressive sensing, which entails resolving problems (2). Candes et al. [6,7], Donoho [8,9], and others were the driving force behind this, as detailed in [6,7,8,10,11,12,13,14,15,16,17,18]. The theory of compressed sensing assures that solving (2) under specific restrictions on the dense matrix and the sparsity of will yield the sparsest solution of . However, there are no universal linear programming strategies for handling this problem. As a result, [6] presents a soft threshold linearized Bregman iteration, and [9,14,19,20,21] investigates its associated convergence. Unfortunately, only is surjective. Cai et al. then studied linearized Bregman iteration with soft threshold where is any matrix and its property in [19,22]. In [23], Qiao et.al proposed a simplified iterative formula that combines original linearized Bregman iteration together with iterative formula for generalized inverse of matrix ,, and soft threshold. In [24,25], Liu et al. proposed efficient non-convex total variation with differential shrink operator.
On the basis of this, Qiao et.al proposed Chaotic Iteration for compressed sensing and image deblurring in [26,27]. Chaotic Iteration not only possesses all merits of linearized Bregman iterative method, but also accelerates the computing speed. Subsequently, we were inspired by the reweighted idea in [27,28,29] and proposed the reweighted ℓ1 minimization algorithm with -inverse function (RMA-IF) based on Chaotic Iteration in [27]. We are interested in the fact that the restored effect of RMA-IF is better than Chaotic Iteration without increasing the computing time. Unfortunately, in [27], we only discussed the case that the weight coefficient is a usual inverse function. It did not involve the general weight coefficients and any theoretical results of the corresponding algorithms. This is exactly what this paper does.
In addition, it was also shown in [23] that exact reconstruction can be achieved by a nonconvex variant of basis pursuit with fewer measurements. Precisely, the norm is replaced by the quasi-norm.
where , .
However, the quasi-norm is nonconvex for , and minimization is generally NP-hard problem. Instead of directly minimizing the quasi-norm, which most likely ends up with one of its numerous local minimizers, these algorithms [30,31] solve a series of smoothed subproblems. Specifically, [32] solves reweighted subproblems: given an existing iterate , the algorithm generates a new iterate by minimizing with weights . In [33], Xiu et al. illustrated the reweighted algorithm in order to solve the variational model . On the other hand, the works in [34,35,36] solve reweighted subproblems: at each iteration, they approximate by with weights . To recover a sparse vector u from , these algorithms need to vary , starting at a large value and gradually reducing it. Empirical results show that the sparsity of the signal can be enhanced by the reweighted coefficients in the algorithm, so that the algorithm can recover the signal quickly. The reweighted or algorithms require much less measurements than convex minimization to recover vectors with entries in decaying magnitudes, and in compressed sensing, this measurement reduction corresponds to savings in sensing time and cost.
In this paper, we propose a reweighted minimization algorithm for the basis pursuit problem (2) in compressed sensing. The algorithm is based on Chaotic Iteration [23] and iterative reweighted strategy that is used to solve the problem. In particular, we chose the weight coefficient that given in papers [31,32,34,35,36,37] and let parameter ,1 in numerical experiment [38].
The rest of the paper is organized as follows. The available strategies for tackling the confined problem (2) are summarized in Section 2. The reweighted minimization algorithm is described, and convergence behavior is also analyzed in Section 3. In Section 4, the numerical results are shown. Finally, in Section 5, we draw some conclusions.
2. Preliminaries
2.1. Linearized Bregman Iteration
In [22], Cai et al. extended linearized Bregman iteration to
where is a known measurement, and ; is Moore–Penrose generalized inverse matrix of any , and
is the soft thresholding operator [6] with
Theorem 1.
[39] Let , , be an arbitrary matrix. Then, the sequencegenerated by (4) with converges to the unique solution of
Furthermore, when , the limit of tends to the solution of
that has a minimal norm among all the solution of (8).
2.2. Chaotic Iteration
In [20], we noted that the computation of involving decomposition of singular value for algorithm (4) needs matrix product, so the computational costs are relatively large. In fact, we just need to compute in (4). In [26], replacing SVD by iterative computation of , we obtained Chaotic Iteration. Because the algorithm only needs to calculate the product of matrix and vector, the computing speed is improved without reducing the accuracy.
Chaotic Iteration:
where , , and , and .
Theorem 2.
[26] Let , , be an arbitrary matrix. Assuming the initial value, then the sequencegenerated by (9) with converges to the unique solution of (7). Furthermore, when , the limit of tends to the solution of (8), which has a minimal norm among all the solution of (8).
2.3. Reweighted Minimization Algorithm with -Inverse Function Iteration
In order to further improve the chaotic iteration, we combined it with the reweighted strategy in [27]. As a preliminary idea, we chose the usual inverse function as the weight coefficient.
RMA-IF:
where , and , and
is the weighted soft thresholding operator with
3. Reweighted Minimization Algorithm
Consider the weighted minimization problem
where , are positive weights. Denoting as , then (13) can be rewritten as
Just like its unweighted counterpart (2), this convex problem can be recast as a linear program. The weighted minimization (14) can be viewed as relaxation of weighted minimization problem. Whenever the solution of (1) is unique, it is also the unique solution of weighted minimization problem, provided that the weights do not vanish. However, the corresponding relaxations (2) and (14) will have different solutions in general. Hence, one may think of the weights as free parameters in the convex relaxation, whose values if set wisely could improve the signal reconstruction.
In comparison to many algorithms that can be used to solve the problem (2), Chaotic Iteration is very effective [26]. Avoiding computing in algorithm (4), the algorithm can reduce the computational complexity and improve the computational efficiency. Thus, we adopt a proper reweight coefficient to this algorithm and obtain a new fast reweighted minimization algorithm.
where , , and is weighted soft thresholding operator, and is weighted function of .
There are many ways to update the weight coefficients , and ERMA uses the following schemes:
where avoids division by zero. In [28], weight coefficients (16) and (17) for , problem are discussed. We adopt iterative formula (16) and (17), when ,1. Obviously, these values of are representative. RMA-IF and Chaotic Iteration are special cases of ERMA with weight coefficients (16), respectively, when and .
In [27], we mentioned the weighted soft thresholding operator , and now we expand further discussed about it in the following.
Theorem 3.
.
Proof.
Let then,
Case 1:
- (a)
- If , and notice that then ; for this case, gets its minimum at point along direction , and the minimum is:
- (b)
- If , and notice that , again we have that decreases along direction :
Since , along direction , we have the knowledge that the minimizer of is .
Case 2:
- (a)
- If , since , increases along direction .
- (b)
- If , since , we have ; the minimizer of along direction is , and the corresponding minimum is:
Since , we can obtain the minimizer of at along direction .
Case 3:
- (a)
- If , since , increases along direction .
- (b)
- If , since , decreases along direction .when , the minimum of along direction is .
In conclusion, we have the weighted soft shrinkage operator (12), and the minimizer of the minimization problem is given by
Taking , we provide an analysis of the convergence behavior of ERMA. The main result is the following theorem. □
Theorem 4.
Let, andbe an arbitrary matrix. Assume the initial value , then the sequence generated by ERMA (), then for , and .
- (a)
- is a monotonically decreasing sequence and bounded below;
- (b)
- is asymptotically regular, such that ;
- (c)
- converges to , where is a limit point of function .
Proof.
Denote the k-th approximation of objective function as .
It is easy to see that
where .
- (a)
- On the basis of the above derivation, we can get
Since is a minimization of , then the first inequality is satisfied. Again, ; this implies , the last inequality holds. In additon, for all , . Therefore, is a monotonically decreasing sequence and bounded below.
- (b)
- From (28), we havesothus,
Sum of (31) form to , we have that
Therefore, the series is convergent and as .
- (c)
- Set , from (32), we obtain
Thus, the sequence is bounded and has a convergent subsequence . Obviously, . To prove , we only need to prove that for any convergent sequence
Let and . That is, there is a constant such that, for , we have . Moreover, because , there such that, for we have . Therefore,
This is contradictory to the regularity in (b). Therefore, converges to a fixed value , where . □
4. Numerical Result
In the basis pursuit problem (2), the constraint is underdetermined linear equations. We test ERMA with (16) () and (17) () when ,1 for the problem (2), respectively. Here, the quality of restoration is measured by the signal-to-noise ratio (SNR), structural similarity (SSIM), and mean squared error (MSE) defined by
where is restored signal and is original signal, and , and are the local means, standard deviations, and cross-covariance for images ,. Our code was written in MATLAB and run on a Windows PC with an Intel(R) Core (TM), , and memory. The MATLAB version was R2015b. The stochastic matrix , with by interior function in MATLAB. was defined as the number of nonzero elements of , and was maximum iteration number. Initial , was obtained according to each stochastic matrix . Set , = 1, , , where selection method of parameters , can also be referred to [31,32].
The original stochastic signals with parameters and reconstructed signals via ERMA with and when ,1, (4) based on (SVD) and Chaotic Iteration are shown in Figure 1, respectively. Moreover, the measurements signal is plotted in Figure 1, where , , is the standard deviation, and .
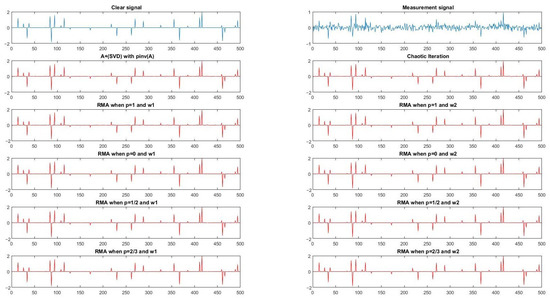
Figure 1.
(m, n) = (250, 500).
Subsequently, we chose of large size . Corresponding to stochastic signals, the signal reconstructed by Iterative Figure 1 with and when ,1, (4) based on (SVD) and Chaotic Iteration are displayed in Figure 2. The measurement signal is plotted in Figure 2, where . For two groups of parameters, we randomly chose some groups of different numerical experiments and listed the results in Table 1 and Table 2, respectively.
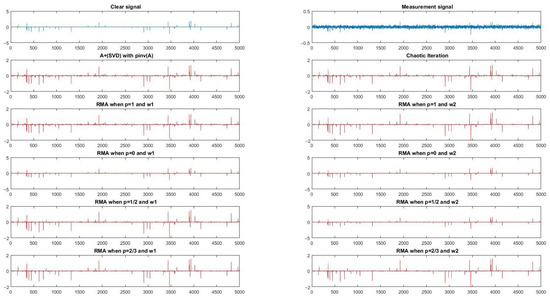
Figure 2.
(m, n) = (1000, 5000).

Table 1.
The comparison of ( ) = (250, 500, 200, 30).
Table 2.
The comparison of ( ) = (1000, 5000, 500, 50).
In Table 1 and Table 2, is and is initial SNR. Obviously, these condition numbers of were large and initial SNR were small. Thus, solving problem (2) is very difficult. Comparing these data in Table 1 and Table 2, we can see the restored signals effected by (4) based on (SVD) algorithm, Chaotic Iteration, ERMA with and , and ERMA with . When , the SNR of ERMA with was the largest among all these results. Although the running times of these algorithms for one-dimensional signal reconstruction were small, it still can be seen that the running time of Chaotic Iteration, ERMA with , and ERMA with were almost the same, and the time consumed by the (4) based on (SVD) algorithm was bigger than those consumed by the above three algorithms. This is because the formula of (4) involves computing the SVD decomposition, and the remaining algorithms just use matrix-vector product. Thus, as we can predict, the relationship of computing time was ERMA with ERMA with Chaotic Iteration < (4) based on (SVD) algorithm, and the relationship of SNR of all methods was ERMA with > ERMA with > Chaotic Iteration (4) based on (SVD) algorithm.
When the above several algorithms were applied to image deblurring, the reconstructed results for image convolved by a Gaussian kernel and for image convolved by disk kernel were found, as shown in Figure 3 and Figure 4, respectively. The first set of images was , which had a smaller scale and was not normal. The second set of images was , which was the common size. The choice of these two sizes of images illustrates the generality of our algorithm. We noticed that the ERMA algorithm had better performance than others. In Table 3 and Table 4, which listed results of Figure 3 and Figure 4, we discovered that the relationship of computing speed was ERMA Chaotic (SVD), that of SNR and SSIM was (SVD) ERMA () > ERMA()(RMA-IF) > Chaotic (ERMA ()), and that of MSE was (SVD) ERMA () ERMA() (RMA-IF) Chaotic (ERMA ()). Obviously, the parameter of in ERMA is a better choice than others. We had no doubt that we obtained the same conclusion for image blurring with signal reconstruction.

Figure 3.
Deblurring results of the Bregman iteration, Chaotic iteration and RMA with , , when ,1 for a 64 × 80 part of the sparse Words image convolved by a Gaussian kernel and contaminated by a Gaussian white noise of .

Figure 4.
Deblurring results of the Bregman iteration, Chaotic iteration, and RMA with , , when ,1 for a 256 × 256 image convolved by a disk kernel.
Table 3.
The comparison of Figure 3 deblurring results.
Table 4.
The comparison of Figure 4 deblurring results.
In fact, the complexity analysis included a comparison of the outcomes of several methods. was the same loop number as before. Thus, the workload of the algorithm (4) was divided into two parts. They are the workload of the and the loop of the (4). Because of the singular value decomposition including matrix multiplication and matrix and eigenvalue calculation, the workload was when computing and when . Because the loop only involved matrix and vector multiplication, the workplace of the (4) loop was . As a result, the algorithm’s overall burden was . The workload of the remaining algorithms was equal to . Obviously, , and the algorithm (4) had the most workload compared to the other three algorithms [23,26,27]. The calculation of the generalized inverse matrix was the main workload.
The comparison of the SNR, SSIM, and MSE data for all methods in Table 3 and Table 4 shows that ERMA outperformed other two methods and was a relatively good choice for our new algorithm, which was found to be more effective than the (SVD), Chaotic algorithm in [26], and RMA-IF (that is, ERMA with ) in [27], given the enhanced sparsity proposed in this work. Such a parameter group can improve the calculation efficiency and keep the effectiveness of image recovery.
5. Conclusions
We have proposed an effective reweighted minimization algorithm. The algorithm is based on the Chaotic Iteration and iterative reweighted strategy that is used to solve the problem. ERMA is competitive due to its restored effectiveness and smaller workload in comparison to its initial version. Numerically and theoretically, ERMA not only inherits all merits of Chaotic Iteration and linearized Bregman iteration, but also greatly improves the SNR, SSIM, and MSE. Importantly, ERMA still preserves stable results when is a very ill condition. Overall, ERMA remains as a good alternative when the condition of is unknown and the measurement signal contains error.
Author Contributions
Conceptualization, S.H., Y.C., T.Q.; methodology, T.Q.; validation, Y.C., T.Q.; formal analysis, S.H.; investigation, Y.C.; resources, S.H.; data curation, T.Q.; writing—original draft preparation, Y.C.; writing—review and editing, S.H.; supervision, S.H.; funding acquisition, S.H. All authors have read and agreed to the published version of the manuscript.
Funding
This research was funded by “National Key Research and Development Program, grant number 2018YFC1504402 and 2018YFC1504404”; “the Tian Yuan Special Funds of the National Natural Science Foundation of China, grant number 11626233”; and “the Fundamental Research Funds for the Central Universities, grant number 19CX02062A”.
Institutional Review Board Statement
Not applicable.
Informed Consent Statement
Not applicable.
Data Availability Statement
Not applicable.
Acknowledgments
We kindly thank the National Key Research and Development Program.
Conflicts of Interest
The authors declare no conflict of interest.
References
- Aspandi, D.; Martinez, O.; Sukno, F.; Binefa, X. Composite recurrent network with internal denoising for facial alignment in still and video images in the wild. Image Vis. Comput. 2021, 111, 104189. [Google Scholar] [CrossRef]
- Zhu, P.; Jiang, Z.; Zhang, J.; Zhang, Y.; Wu, P. Remote sensing image watermarking based on motion blur degeneration and restoration model. Optics 2021, 248, 168018. [Google Scholar] [CrossRef]
- Chaudhari, A.; Kulkarni, J. Adaptive Bayesian Filtering Based Restoration of MR Images. Biomed. Signal Process. Control. 2021, 68, 102620. [Google Scholar] [CrossRef]
- Chen, S.S.; Donoho, D.L.; Saunders, M.A. Atomic Decomposition by Basis Pursuit. SIAM Journal on Scientific Computing 1998, 43(1), 129–159. [Google Scholar] [CrossRef]
- Wang, Y.; Yang, J.; Yin, W.; Zhang, Y. A New Alternating Minimization Algorithm for Total Variation Image Reconstruction. SIAM J. Imag. Sci. 2008, 1, 248–272. [Google Scholar] [CrossRef]
- Tsaig, Y.; Donoho, D.L. Extensions of compressed sensing. Signal Process. 2006, 86, 549–571. [Google Scholar] [CrossRef]
- Candes, E.J.; Romberg, J. Errata for Quantitative Robust Uncertainty Principles and Optimally Sparse Decompositions. Math. Ann. 2007, 7, 529–531. [Google Scholar] [CrossRef][Green Version]
- Candes, E.J.; Romberg, J.; Tao, T. Robust uncertainty principles: Exact signal reconstruction from highly incomplete frequency information. IEEE Trans. Inf. Theory 2006, 52, 489–509. [Google Scholar] [CrossRef]
- Misra, G.D.; Donoho, D.L. Compressed Sensing. IEEE Trans. Inf. Theory 2006, 52, 1289–1306. [Google Scholar]
- Zhang, X.; Zhang, S.; Lin, J.; Sun, F.; Zhu, X.; Yang, Y.; Tong, X.; Yang, H. An Efficient Seismic Data Acquisition Based on Compressed Sensing Architecture With Generative Adversarial Networks. IEEE Access 2019, 7, 105948–105961. [Google Scholar] [CrossRef]
- Shi, L.; Qu, G.; Wang, Q. A Method of Reweighting the Sensing Matrix for Compressed Sensing. IEEE Access 2021, 9, 21425–21432. [Google Scholar] [CrossRef]
- Xu, S.; Yang, X.; Jiang, S. A fast nonlocally centralized sparse representation algorithm for image denoising. Signal Process. 2017, 131, 99–112. [Google Scholar] [CrossRef]
- Xie, J.; Liao, A.; Lei, Y. A new accelerated alternating minimization method for analysis sparse recovery. Signal Process. 2018, 145, 167–174. [Google Scholar] [CrossRef]
- Cai, J.-F.; Osher, S.; Shen, Z. Linearized Bregman iterations for compressed sensing. Math. Comput. 2009, 78, 1515–1536. [Google Scholar] [CrossRef]
- Cholamjiak, W.; Khan, S.A.; Yambangwai, D.; Kazmi, K.R. Strong Convergence Analysis of Common Variational Inclusion problems Involving an Inertial Parallel Monotone Hybrid Method for a Novel Application to Image Restoration. RACSAM 2020, 114, 99. [Google Scholar] [CrossRef]
- Cholamjiak, W.; Dutta, H.; Yambangwai, D. Image Restorations Using an Inertial Parallel Pybrid Algorithm with Armijo Linesearch for Nonmonotone Equilibrium Problems. Chaos Solitons Fractals 2021, 153, 111462. [Google Scholar] [CrossRef]
- Suantai, S.; Peeyada, P.; Yambangwai, D.; Cholamjiak, W. A Parallel-Viscosity-Type Subgradient Extragradient-Line Method for Finding the Common Solution of Variational Inequality Problems Applied to Image Restoration Problems. Mathematics 2020, 8, 248. [Google Scholar] [CrossRef]
- Yambangwai, D.; Khan, S.A.; Dutta, H.; Cholamjiak, W. Image Restoration by Advanced Parallel Inertial Forward–Backward Splitting Methods. Soft Comput. 2021, 25, 6029–6042. [Google Scholar] [CrossRef]
- Cai, J.F.; Shen, S.O. Convergence of the Linearized Bregman Iteration for ℓ1-norm Minimization. Math. Comput. 2009, 78, 2127–2136. [Google Scholar] [CrossRef]
- Amaral, G.; Calliari, F.; Lunglmayr, M. Profile-Splitting Linearized Bregman Iterations for Trend Break Detection Applications. Electronics 2020, 9, 423. [Google Scholar] [CrossRef]
- Osher, S.; Mao, Y.; Dong, B.; Yin, W. Fast Linearized Bregman Iteration for Compressive Sensing and Sparse Denoising: UCLA. Commun. Math. Sci. 2010, 8, 93–111. [Google Scholar]
- Cai, J.; Osher, S.; Shen, Z. Linearized Bregman Iterations for Frame-Based Image Deblurring. SIAM J. Imaging Sci. 2009, 2, 226–252. [Google Scholar] [CrossRef]
- Qiao, T.; Li, W.; Wu, B. A New Algorithm Based on Linearized Bregman Iteration with Generalized Inverse for Compressed Sensing. Circuits Syst. Signal Process. 2014, 33, 1527–1539. [Google Scholar] [CrossRef]
- Liu, J.; Ma, R.; Zeng, X.; Liu, W.; Wang, M.; Chen, H. An efficient non-convex total variation approach for image deblurring and denoising. Appl. Math. Comput. 2021, 397, 125977. [Google Scholar] [CrossRef]
- Liu, J.; Ni, A.; Ni, G. A nonconvex l1(l1−l2) model for image restoration with impulse noise. J. Comput. Appl. Math. 2020, 378, 112934. [Google Scholar] [CrossRef]
- Qiao, T.; Li, W.; Wu, B.; Wang, J. A chaotic iterative algorithm based on linearized Bregman iteration for image deblurring. Inf. Sci. 2014, 272, 198–208. [Google Scholar] [CrossRef]
- Qiao, T.; Wu, B.; Li, W.; Dong, A. A new reweighted l 1 minimization algorithm for image deblurring. J. Inequalities Appl. 2014, 2014, 238. [Google Scholar] [CrossRef]
- Rose, K. Deterministic annealing for clustering, compression, classification, regression, and related optimization problems. Proc. IEEE 1998, 86, 2210–2239. [Google Scholar] [CrossRef]
- Jin, D.; Yang, Y.; Ge, T.; Wu, D. A Fast Sparse Recovery Algorithm for Compressed Sensing Using Approximate l0 Norm and Modified Newton Method. Materials 2019, 12, 1227. [Google Scholar] [CrossRef]
- Materassi, D.; Innocenti, G.; Giarré, L.; Salapaka, M. Model Identification of a Network as Compressing Sensing. Syst. Control. Lett. 2013, 62, 664–672. [Google Scholar] [CrossRef]
- Zhou, F.; Wu, Y.; Dai, Y.; Wang, P. Detection of Small Target Using Schatten 1/2 Quasi-Norm Regularization with Reweighted Sparse Enhancement in Complex Infrared Scenes. Remote Sens. 2019, 11, 2058. [Google Scholar] [CrossRef]
- Zhu, H.; Xiao, Y.; Wu, S.-Y. Large sparse signal recovery by conjugate gradient algorithm based on smoothing technique. Comput. Math. Appl. 2013, 66, 24–32. [Google Scholar] [CrossRef]
- Xiu, X.; Kong, L.; Yan, H. Iterative Reweighted Methods for l1–lp Minimization. Comput. Optim. Appl. 2018, 70, 201–219. [Google Scholar] [CrossRef]
- Faris, H.; Mafarja, M.M.; Heidari, A.A.; Aljarah, I.; Al-Zoubi, A.; Mirjalili, S.; Fujita, H. An efficient binary Salp Swarm Algorithm with crossover scheme for feature selection problems. Knowl.-Based Syst. 2018, 154, 43–67. [Google Scholar] [CrossRef]
- Abdi, M.J. Comparison of Several Reweighted l1-Algorithms for Solving Cardinality Minimization Problems. Mathematics 2013, arXiv:1304.6655. [Google Scholar]
- Qiao, D.; Pang, G.K.H. An Iteratively Reweighted Least Square Algorithm for RSS-Based Sensor Network Localization; IEEE: Beijing, China, 2011; pp. 1085–1092. [Google Scholar]
- Daubechies, I.; DeVore, R.; Fornasier, M.; Güntürk, C.S. Iteratively reweighted least squares minimization for sparse recovery. Commun. Pure Appl. Math. 2010, 63, 1–38. [Google Scholar] [CrossRef]
- Cao, W.; Sun, J.; Xu, Z. Fast Image Deconvolution Using Closed-form Thresholding Formulas of Lq(q = 12, 23) Regularization. J. Vis. Commun. Image Represent. 2013, 24, 31–41. [Google Scholar] [CrossRef]
- Zhang, H.; Cheng, L.Z. A− Linear Bregman Iterative Algorithm. Comput. Math. 2010, 32, 97–104. [Google Scholar]




Publisher’s Note: MDPI stays neutral with regard to jurisdictional claims in published maps and institutional affiliations. |
© 2021 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).