1. Introduction
To ensure the seamless operation of intelligent transport systems (ITSes), it is required to process large amounts of monitoring information of various formats, purposes, and confidentiality levels in the real-time mode [
1,
2,
3]. General- and special-purpose computing machinery is essential to information processing. Computer hardware (CHW) can be speeded up in two ways. The first one is extensive, requiring continuously enhancing computational capacities and developing special-purpose CHW focused on a predefined scope of tasks. The second one is intensive, requiring a flexible adaptation of the CHW hardware to a certain task, particularly rejecting the classical, von Neumann’s, CHW common-bus architecture. Unlike the former, the latter way allows implementing devices with higher speeds than that for general-purpose CHW. Examples of special purpose computing devices that use field-programmable gate arrays (FPGAs) [
4] are given in [
5,
6]. Using high-speed CHW devices that allow implementing various algorithms of distributed data processing at different times is relevant in solving various ITS-related tasks, such as data processing in large databases [
7], analysis of discrete Markovian processes [
8,
9], nonlinear filtering of data [
10], etc.
To solve the above scope of problems, FPGAs [
4] can be used that include reconfigurable logical elements, i.e., lookup tables (LUTs(x)), D flip-flops, and input/output blocks (IOBs). In [
11,
12,
13], an approach is presented based on reducing the problem of processing data arrays (exemplified by maps) to implementing similar FPGA-based operations. Several studies [
14,
15,
16] show that the problem of implementing arbitrary maps of one set of elements into another set is reduced to the distributed computation of a group of nonlinear polynomial functions (polynomials, functions) of a given number of variables defined over a Galois field
of a certain power [
17]. A cooperative distributed FPGA-based computation method is proposed for the said polynomials. We obtained the estimates of hardware complexity for a group of polynomials by the number of reconfigurable FPGA elements. It is shown that the computations of elementary polynomials common for the functions from the set to be implemented considerably save the reconfigurable logical resources of FPGA. Due to the pipelined implementation of computing a group of functions based on similar IP-cores, estimates of operation delays of pipeline devices computing the set of polynomials on FPGA are weakly dependent on the number of variables at the input of these functions.
The article is contained three basic Sections: (1) Basic Terms and Definitions; (2) Hardware Complexity of Implementing a Group of Polynomials in the FPGA Architecture and (3) Discussion. In
Section 1, the concept of a polynomial of m variables and operations on elements of the Galois field is introduced in accordance with [
17]. Statements are made regarding the hardware and time complexity of the pipeline implementation of operations on elements of the Galois field in the FPGA architecture. The concept of a similar IP-core corresponding to FPGA architecture is introduced [
16]. According to [
14,
15,
16], the separate computation of a group of polynomials involves multiple recomputations of partial polynomial functions common to a group of polynomials. This significantly increases the complexity estimates by the number of such IP-cores.
Section 2 presents and theoretically supports representing a group of polynomials over a Galois field. Estimates of the complexity of the implementation of this group by the number of similar IP cores are calculated. The proportion of IP-cores required to calculate parts of elementary polynomial functions common to a group of polynomials is determined.
Section 3 defines the possibilities for using the proposed method to evaluate the characteristics of a group of polynomials (the number of variables and polynomials, the dimension of the Galois field) that are acceptable for implementation on a given FPGA-devices, both for existing and prospective.
2. Basic Terms and Definitions
Let us define a polynomial of m variables over a Galois field represented as
[
17]
By defining the values of an m-dimensional matrix of coefficients , . Symbol in (1) means the bitwise sum of elementary modulo-2 polynomials , .
A polynomial function of the form (1) is representable as a self-similar formula: , where is a function of variables defined according to (1).
Example 1. Let for (1)andthe elements ofbe representable in both exponentialand vectorforms equivalent to each other; the multiplication operation over the elements ofis defined as, and the addition operation is defined as the bitwise sum of elementary modulo-2 [
17].
The coefficients of this polynomial are given by a two-dimensional matrix . Then , and the values , , .
Let us consider a polynomial represented as (1) on FPGA. According to [
14], let us introduce the following statements:
Statement 1. k LUTs (x),, allow performing the following operations: raising to power i,, and multiplying two elements of; multiplying two elements ofby a constant, followed by addition; and bitwise modulo-2 sum operation for x elements of.
Statement 2. The basic element for implementing a polynomial represented as (1) on FPGA is an IP-core that includes k LUTs (x),, and k D flip-flops.
Statement 2 defines the hardware complexity of the basic element by the number of the programmable FPGA elements, i.e.,
k LUTs (
x) and
k D flip-flops, respectively. The pipelined operation delay time of a device implemented on these moduli does not depend on the number of variables of polynomial (1) and is defined by formula:
where
,
, and
are operation delay times of
D flip-flops, interconnections, and LUTs (
x) for a given FPGA, while
and
are the delay times of IOBs that function to information input/output within the package of a given FPGA, respectively. Delay time of interconnections,
, is computed for a given device using a particular computer-aided design system. Such as Vivado 2020.1 CAD system (Xilinx, Inc., San Jose, CA, USA), Quartus II (Intel, Inc., Santa Clara, CA, USA), etc.
For example, according to [
4], for FPGA Virtex UltraScale, device XCVU065, in formula (2) operation delay time
, is 2.36 ns.
and
are equal to approximately 0.42 ns and 0.66 ns. The value of the value
(
x = 6) is less than the values
and
. According to [
15,
18], the interconnections’ delay time does not exceed 70% of the total delay time of operation. As a result, according to (2), the upper bound of pipelined operation delay time of XCVU065 device is
ns.
Problem of implementing a broad class of digital CHW devices is reduced to the problem of implementing an arbitrary map of the elements of set
into set
. In [
15], it is shown that, in case of
,
, this map can be represented by
E polynomials of
m variables over Galois field represented as
.
3. Hardware Complexity of Implementing a Group of Polynomials in the FPGA Architecture
According to Statement 1, let us find the hardware complexity estimates of implementing a group of E polynomials represented as (1) of m variables over the field . Each of E polynomials represented as (1), generally speaking, is computed when using identical elementary polynomials. Let us introduce the following definitions of subsets of this set:
Definition 1. First subset of elementary polynomials, power, includes elementary polynomials that are not used in computing each of E polynomials, …,because of multiplying it by the zero coefficient of matrix, .
Definition 2. First subset of elementary polynomials is divided into non-overlapping subsets, power, including elementary polynomials of j variables, , .
Definition 3. Each of E subsets of elementary polynomials, power, that are not overlapped with the first subset include elementary polynomials that are not used in computingbecause of multiplying it by the zero coefficient of matrix, .
A method is proposed to compute the hardware complexity estimates for a group of E polynomials of m variables represented (1) in the FPGA architecture. The method includes three stages:
Stage 1. Computing common elementary polynomials, among which there are at most of m variables and at most of variables, .
Stage 2. Obtaining the values of the products of elementary polynomials and nonzero constants , .
Stage 3. Bitwise modulo-2 addition of values obtained at Stage 2.
Let us define the hardware complexity estimates for computing a group of
E polynomials represented as (1) in the FPGA architecture in using the basic elements, IP-cores, based on Statements 1 and 2. Due to the fact that the said IP-cores form a pipeline, operation delay time estimates do not practically depend on the number of variables
m of each of
E polynomials. The number of basic elements required at Stages 1, 2, and 3 is defined according to formulas:
Values of
and
,
,
, are defined in accordance with the definitions 1–3. The total number of IP cores required to compute a group of
E polynomials represented as (1) is:
Based on definitions 1–3 and the above true is the Theorem 1.
Theorem 1. Hardware complexity of computing a group of E polynomials represented as (1) of m variables overin the FPGA architecture by the number of IP-cores is calculated according to (3), the operation time delay was estimated according to (2), while the number of FPGA pins is defined as.
Let us analyze the hardware complexity estimates of implementing a group of polynomials in the FPGA architecture.
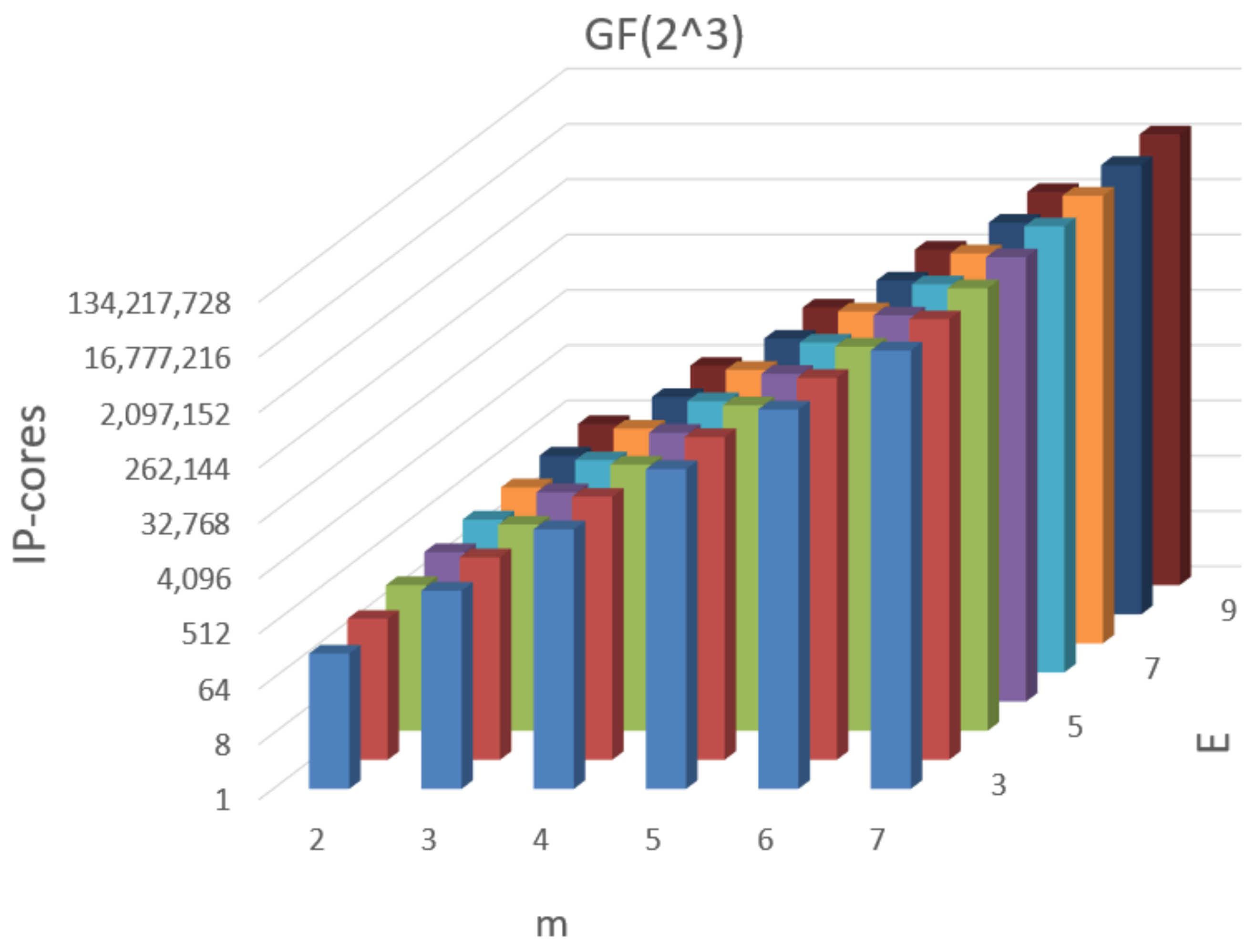
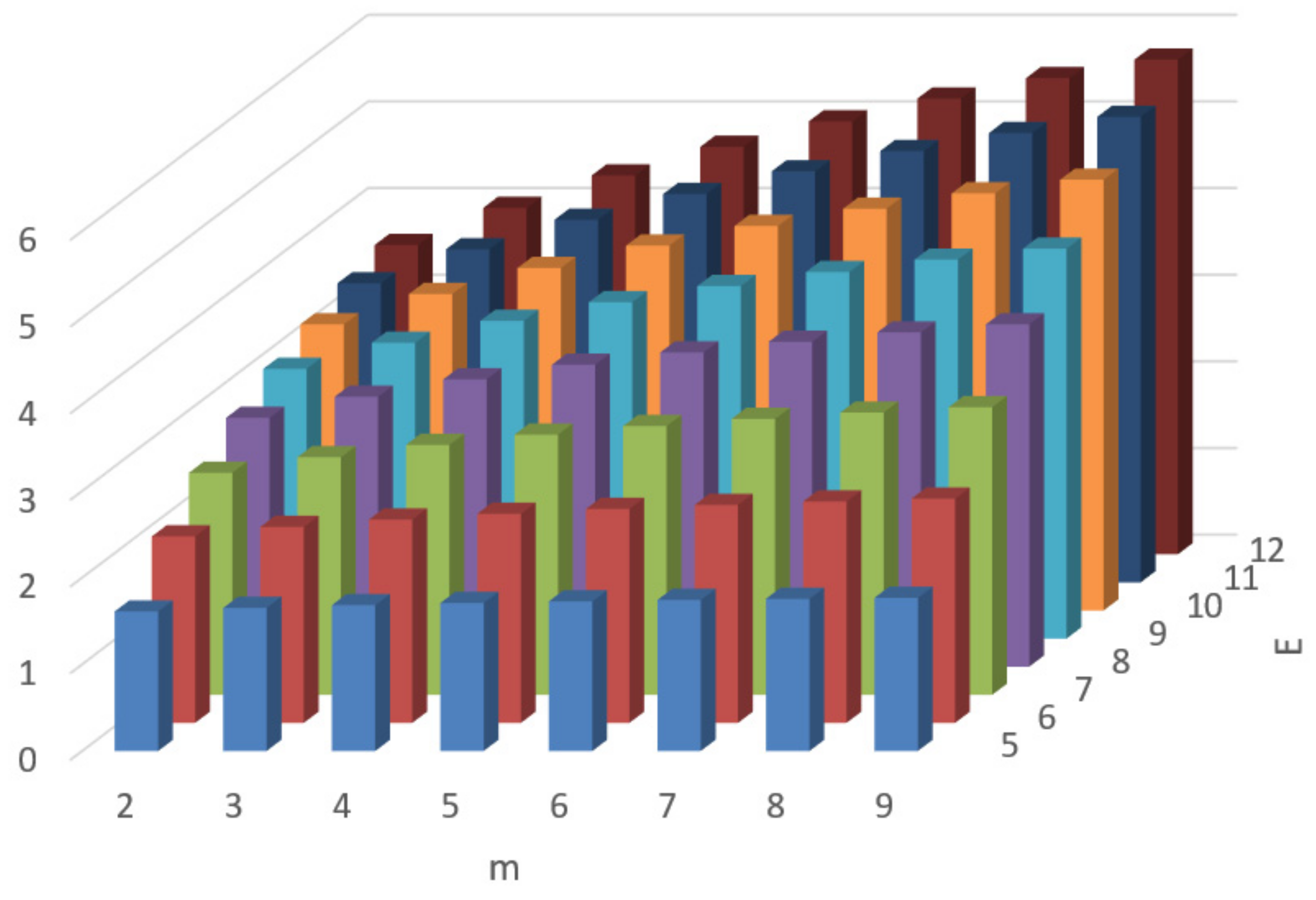
Figure 1 and
Figure 2 represent diagrams that show the dependency of the total number of IP-cores,
, for a group of polynomials represented as (1) over
and
, respectively, on the number of variables
m and on the power of a group of polynomials
E. According to the data given in
Figure 1, the spread of estimates of the number of IP-cores for a group of polynomials represented as (1) over
varies from 59 (
m = 2,
E = 5) to approximately
(
m = 9,
E = 12). For a group implemented over
(see
Figure 2) these estimates range from 163 (
m = 2,
E = 5) to approximately
(
m = 7,
E = 10). With the increase in the number of the variables of polynomials, an exponential increase in the estimate,
, is observed, while the growth of
E results in the practically linear increase in this estimate.
Of interest is also the contribution of the hardware complexity estimates for computing elementary polynomials common for each of
E functions of
to the total complexity estimate,
. According to diagrams shown in
Figure 3 and
Figure 4, linear growth of the
ratio is observed in increasing the number of variables. However, the higher the value of
E, the slower
grows. This observation is true for both
and
. This is explained by the fact that the number of IP-cores required for computing elementary polynomials increases exponentially with the linear increase in the number of variables
m.
The value
shows what effect will be in the case of the implementation of a group of
E polynomials according to the proposed method compared with the separate implementation of each of their
E polynomials over
and
. For
(see
Figure 3) the spread of values of magnitude
varies from 15.3% (
m = 2,
E = 5) to 42.8% (
m = 9,
E = 12). For
(see
Figure 3)—from 30.1% (
m = 2,
E = 5) to 46.8% (
m = 7,
E = 10).
According to [
15], implementing the given system from
E polynomials of
m variables over
on one FPGA microcircuit is allowed, provided that the following conditions are met:
where
,
, and
are the number of reconfigurable resources, LUTs(
x),
D flip-flops, and IOBs, respectively, required for implementing a group of
E polynomials of
m variables;
,
, and
are the number of similar resources available to the user within the given FPGA, while
,
, and
are the use factors of the said reconfigurable resources.
Example 2. Joint implementation of a group of two polynomials,and, having the structure given in Example 1, and given by the matrices of coefficientsand. The implementation of step 1 of the proposed method is represented in the form of a two-dimensional matrix:. Five elementary polynomials do not need to be calculated, since the coefficients for them and inand inare zero; according to the definition of 2,,,; for any value , therefore, it is not necessary to raise to the power of,. The result of stage 2 for each of the polynomialsandis represented as matrices:and, respectively, for which(see Definition 3). Stage 3 consists of the bitwise addition of elementary polynomials and constants represented in the specified matrices: 4. Discussion
What is the advantage of the proposed approach to the implementation of a group of polynomials over a Galois field? Let us return to formula (3). Suppose the elements of this group of
E polynomials are calculated separately. In that case, the hardware complexity will be defined as
, that is, the value of
will be increased by
E times. As a result, the assessment of the complexity
of the joint implementation of a group of
E polynomials over a Galois field in comparison with their separate implementation
will be reduced in time.
The value
is given for a group of
E polynomials over a Galois field
and
given
m and
E on
Figure 3 and
Figure 4, respectively. By analogy, the estimate (5) has a range of values for
from 1.61 (
m = 2,
E = 5) to 5.71 (
m = 9,
E = 12) and for
from 1.90 (
m = 2,
E = 3) to 5.68 (
m = 7,
E = 9). These estimates are shown in
Figure 5 and
Figure 6.
For example, let us consider the FPGA XC7V585T of the Virtex-7 family. This FPGA includes 585,720 LUTs (6), 728,400 D flip-flops, and 850 IOBs. Use factors of each of the reconfigurable elements specified are 0.5. According to Theorem 1, FPGA-based implementation of a group of E polynomials of m variables over requires IOBs, while that over requires IOBs. According to Statement 1, implementing each IP-core over the elements of requires two LUTs (6) and two D flip-flops, while implementing over requires three LUTs (6) and three D flip-flops each. According to inequality (4) and formula (3), it is possible to implement on one FPGA XC7V585T the groups of, at most:
Seven polynomials of seven variables over , which correspond with mapping set into set ;
51 polynomials of six variables over , which correspond with mapping set into set ; and
36 polynomials of four variables over , which correspond with mapping set into set .
In all the above cases of implementing the maps on FPGA XC7V585T, the limiting factor is the number of reconfigurable LUTs (6).
The proposed method allows us to estimate for a given group of E polynomials defined over and from m variables each the possibility of its implementation on a given FPGA-device. The degree of the field , , is determined with reference to the features of existing FPGA-devises that implement LUT(4) and LUT(6) (see. Statement 1). The proposed method allows us to perform a similar study for any FPGA, both for existing and prospective.
5. Conclusions
Using the method proposed, we obtained the hardware complexity estimates for the distributed computation of a group of E polynomials of m variables over field . Based on the above estimates, the values of E and m, can be defined. This group of polynomials can be implemented on an FPGA with the predefined characteristics by the number of reconfigurable elements available to the user. The method suits for estimating the hardware complexity of implementing a group of polynomials on both the existing and promising would-be FPGAs.
In arranging a pipeline, the average estimate of the operating delay of a device implementing the FPGA-based computation of a group of polynomials is weakly dependent on the power of a group of polynomials and on the number of their variables at the input. Due to the cooperative computing of polynomials from the group, the logical resources of FPGA are saved considerably. A relatively small set of elements, defined by input variables that are common for a group of polynomials, can be mapped in quite a large output set of values, the power of which exceeds considerably that of the input set.
The technique presented herein is a tool that allows the FPGA-based implementation of a frantic way to increase the data array processing speed in using the focused hardware basis. Due to reconfigurable elements available in the FPGA architecture, different maps of one set into another one can be implemented at different time intervals. This result is relevant in developing a hardware platform of intelligent transport systems, the role of which becomes increasingly important in the modern information society.



{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}