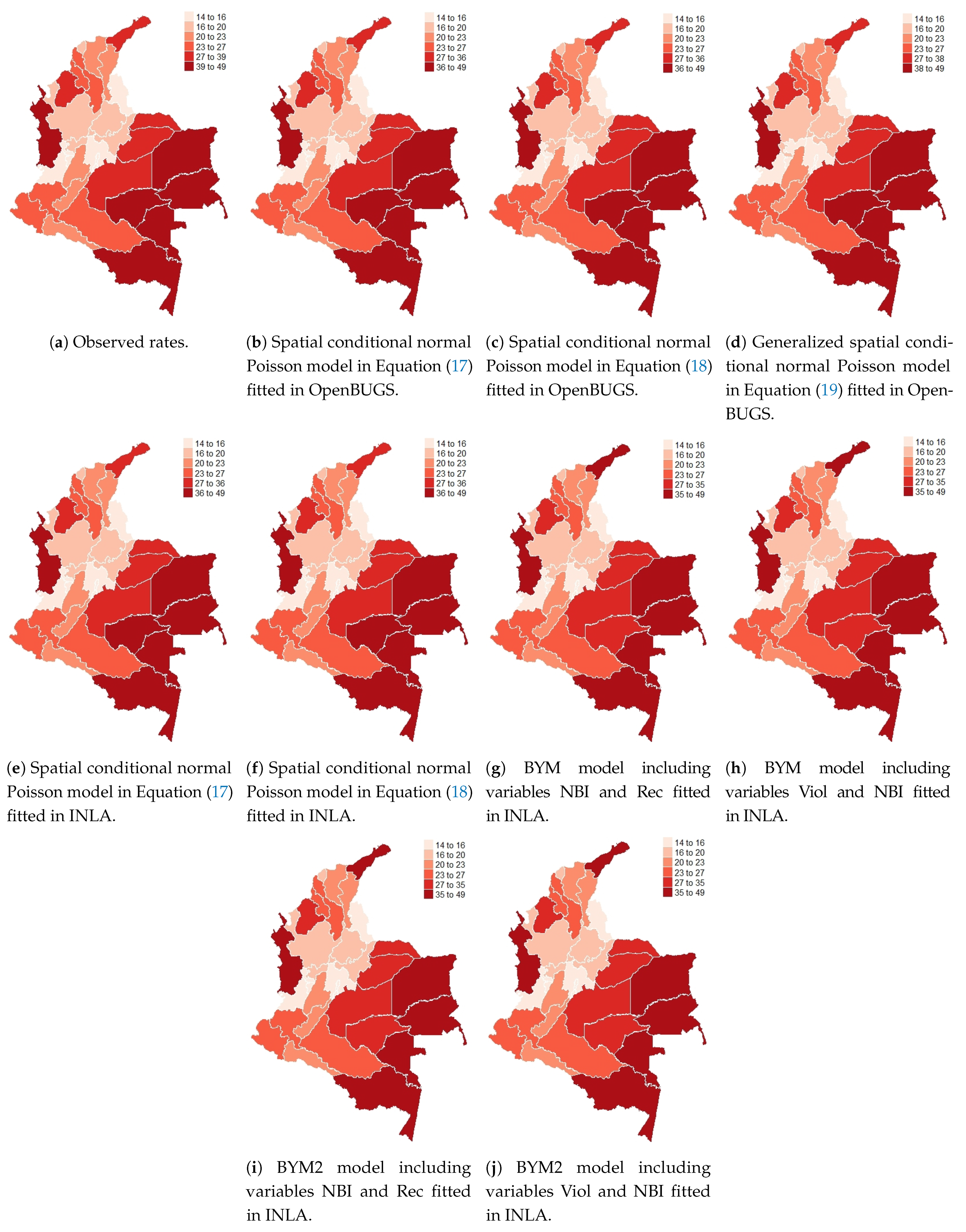
2.1. Spatial Conditional Overdispersion Models
Let us suppose that the random variables
, for
, represent counts with corresponding means
. The Poisson model generally assumes that
, with variance
, so that the variance is equal to the mean, a property that is known as equidispersion. In a generalized linear model, the mean of the distribution depends on the explanatory variables through the following regression model, known as linear predictor:
where
is a monotonic and differentiable link function,
is the
vector of explanatory variables for the
i-th observation and
is the
vector of unknown regression parameters that need to be estimated. For the Poisson regression model, the natural logarithm is often chosen as the link function; that is,
. Under these assumptions, overdispersion would occur when there is extra-Poisson variability in the data, so that
.
Two of the most common models used to accommodate overdispersion in count data for the case of response variables following a Poisson distribution are the normal Poisson and the negative binomial models. In the normal Poisson model, the overdispersion is corrected by the inclusion of a random effect, assumed to be normally distributed, in the linear predictor. In this way, the normal Poisson can be written as:
where
and
are as before, and
, for
. In this model,
, for
, follows a Poisson distribution with conditional mean
. Although the distribution of
does not have a closed form expression (see [
3]), when the variance
of the random effects is small enough, the random variables
, can be considered as mixed Poisson variables, with mean and variance that can be approximated by
and
(see [
31]). The dispersion parameter
allows for modeling the possible existing overdispersion and, in addition, it also captures the variability unexplained by the covariates. That is, since
, the variance is larger than that specified by the Poisson model, so that
. We believe it is important to mention that the condition that the variance
of the random effects should be small enough (see [
3] or [
31]) is satisfied in the relevant cases in the application of this model in
Section 3, so that the approximations mentioned above hold.
Another frequently used model to fit overdispersed count data is the standard negative binomial or NB2 model (see [
32]). One possible way to be able to generate this model is by considering a Poisson-gamma mixture. That is, if we assume that the random variables
, follow a Gamma distribution, such that
, with
a parameter that needs to be estimated, and that the random count variables
, conditioned on
and the random variables
follow a Poisson distribution with mean
, such that
, then the unconditional distribution of
can be derived in the following way [
32]:
which corresponds to the probability density for a negative binomial distributed count variable, so that
, with mean
and variance
. The dispersion parameter
allows for the modeling of the extra-Poisson variability because, since we have that
, then
. Therefore, and from the above, for the negative binomial regression model, the linear predictor is specified for the mean
, so that:
where
and
are as above.
One of the reasons for the existence of overdispersion in spatial data may be the possibly existing spatial correlation between the responses corresponding to the different adjacent locations. Hence, it can be assumed that a portion of the overdispersion can be explained by taking into account this spatial correlation. Thus, the spatial conditional overdispersion regression models proposed by Cepeda-Cuervo, Córdoba and Núñez-Antón [
22] assumed a specific spatial structure for the variable under study. That is, they assumed that
, for
, conditioned on the values in all of the neighbors of the
ith region, except for the
i-th region itself (i.e.,
), follows a conditional overdispersed distribution denoted by
, for
. In this distribution, the conditional mean follows a given regression structure that includes some covariates affecting the response variable, as well as its spatial lags, together with a spatial parameter that allows to account for the intensity of the spatial dependence that is present in the data. In the case where the conditional distribution follows one of the aforementioned models, this model leads to the spatial conditional Poisson, negative binomial and normal Poisson regression models, respectively.
The spatial distribution is commonly specified by means of a neighborhood structure, defined, for a sample of n regions, by an spatial weights matrix, denoted by , where its elements, , are the weights to be specifically used to model the strength of the dependence between the i-th and the j-th regions. These elements are given by the contiguity criteria chosen by the researcher, which can be based on the boundaries of the regions or on the distance from one spatial location to the others, or by any other alternative criteria previously proposed in the literature. It is commonly assumed that, , if region i is adjacent or a neighbor to region j, and , otherwise. First order contiguity can be specified, for example, when we use the criteria that regions i and j are neighbors if they share at least one point in their boundaries. Second order could also be considered if we extend the criteria by considering that i and j are neighbors if they share a common neighbor. This weights matrix is usually standardized by rows, so that, if region i is adjacent to region j, then , where is the number of neighbors region i has. Along these lines, if is the vector of observations for a response variable Y, then the spatial lag of Y is defined as the product of the vector corresponding to the ith row of the weights matrix , , and the vector ; that is, , a product representing the averaged values of the considered variable in the neighboring locations for the ith region. In this work, we only assume first order adjacency among regions and, in addition, that the spatial weights matrix is standardized by rows.
The spatial conditional Poisson model is specified by assuming that the conditional distribution of the variable under study follows a Poisson distribution, that is
, with conditional mean
, so that its corresponding regression model, where the previously described spatial association dependence is incorporated, can be specified as:
where
and
are as above,
is the parameter incorporating the first order spatial association,
is the
ith row of the
weight matrix
that represents the spatial neighborhood structure assumed in the model, and
is the vector of dimension
for the observed values for the response variable under study.
The spatial conditional normal Poisson model assumes that the distribution of the variable under study, conditioned on its neighbors excluding the
i-region itself,
, and the normally distributed random effect
, follows a Poisson distribution. That is,
, with conditional mean
, so that its corresponding regression model, where the previously described spatial association dependence is incorporated, can be specified as:
where
,
,
,
and
are as above.
In the same way, the spatial conditional negative binomial model can be also specified if we assume that the response variable under study, conditioned on
, follows a negative binomial distribution. That is,
, with conditional mean
, and with a regression structure given by Equation (
5).
We believe it is important to mention that, in the spatial conditional normal Poisson and the spatial conditional negative binomial models, a portion of the overdispersion that may have been generated by the possible existing spatial correlation in the data is considered to be incorporated into the model by using the specified neighborhood spatial structure, given by the product between the spatial weights matrix and the vector of responses (i.e., by incorporating spatial lags of the variable under study),
. The remaining unexplained overdispersion in the data will be modeled by means of the dispersion parameter
. However, we should note that these models assume a constant overdispersion, and there are cases where the dispersion in the data can vary among groups or observations. The generalized overdispersion models proposed by Quintero-Sarmiento, Cepeda-Cuervo and Núñez-Antón [
9] introduced Bayesian extensions of the standard overdispersion models, where regression structures are assumed both for the mean and for the dispersion parameter. Their model allowed for the dispersion to vary as a function of some explanatory variables, so that dispersion can vary for the different regions or observations in the study.
In this sense, generalized overdispersion models offer a reasonable and well justified proposal for fitting count data with overdispersion. However, for the case of spatial count data, they do not provide information or incorporate into the model the possible existing spatial dependence in the data set under study, which clearly motivates the inclusion of the spatial dependence structure in these models. Along these lines, the generalized spatial conditional overdispersion regression models [
22] assumed that the spatial count variable in their model,
, conditioned on the values in all of the neighbors of it, except for the
ith region itself (i.e.,
), follows an overdispersed conditional distribution
, with conditional mean and dispersion parameter following specific regression structures that include some covariates affecting the response variable and the spatial lags of the variable of interest.
If we now consider the case where
follows a Poisson distribution with mean
, and assume the normal Poisson model with mean structure given by Equation (
6), for the generalized spatial conditional normal Poisson model, we will have that the conditional mean and variance components in the random effect distribution will be specified by regression structures given by:
where
,
,
and
are as above, and
and
are the parameters that explain the spatial association in the mean and dispersion structures, respectively. In addition,
is the
vector of explanatory variables for the
ith observation and
is a vector of dimension
containing the unknown regression parameters that need to be estimated. The generalized spatial conditional negative binomial model can be specified in the same way, by assuming that
, conditioned on
, follows a negative binomial distribution, and assuming the following regression structures for both the conditional mean and dispersion parameter:
where
,
,
,
,
,
,
and
are as above.
2.2. Besag–York–Mollié (BYM) Model
The Besag–York–Mollié (BYM) model [
16] is a Bayesian Poisson hierarchical model widely used in the literature for fitting spatial count data, particularly in the field of disease mapping (see [
17]). It is an extension of the generalized linear Poisson model that includes both a spatial structured and an unstructured random effect in the regression model structure. If we let
represent counts for the
n different regions, the BYM model is specified by assuming that the variable under study follows a Poisson distribution with mean
, having a mean regression structure given by:
where
and
are as above,
is a normally distributed random effect, so that
, with
being an unknown variance parameter that needs to be estimated, and
is an intrinsic conditional autoregressive (CAR) [
16] distributed random effect, so that:
where
represents the set of values of all neighbors of the
ith region, except for the
ith region itself,
is the spatial weights matrix and
is an unknown variance parameter that needs to be estimated. Given that this model is able to account for spatial dependence and also for the extra-variability in the data set not explained by the covariates, it has a considerable potential to motivate and justify its use for the analysis of spatial count data. However, since it is only possible to obtain information from the data from the sum of the two random effects, but not from each of the individual components separately, its use in this specific context has been questioned because of the possible identifiability problems that it may present (see [
33]).
Some authors (e.g., Riebler, Sørbye, Simpson and Rue [
20]) have addressed the issue of identifiability. They proposed the BYM2 model, an extension of the BYM model that scales the spatial component and the unstructured component, so that the mean regression structure can be written as:
where the random effects
and
are as in the BYM model, but with a scaled variance approximately equal to one,
is an unknown precision parameter that captures the variance contribution from the sum of the two random effects, and
is a mixing parameter that controls for the variance contribution of the spatially structured component
, whereas the variance contribution of the unstructured random component
is explained by
. The main advantage of the BYM2 model is precisely the possibility that it offers to be able to separately capture the impact of the spatial dependence and the effect of the variability or the overdispersion present in the data. The priors for these hyperparameters are defined by means of the penalized complexity priors developed by Simpson, Rue, Riebler, Martins and Sørbye [
34]. The complexity prior for the parameter
can be specified by assuming the probability statement that
, and, for the parameter
, that
, with
U and
being fixed values that depend on the specific application under consideration. The use of these priors has been proved to be a suitable choice in Bayesian spatial models and, especially, for the BYM2 model, mainly due to the fact that they favor less complex models and allow for a clearer interpretation of the parameters (see [
35]).
2.3. Bayesian Estimation
As we have already mentioned above, models studied here will be estimated by using a Bayesian approach. That is, we assume that we have a sample of
n independent observations,
, for
from the variable
, and we wish to estimate a parameter
, we will consider it as a random variable and express our beliefs about this parameter via a prior distribution
. The information available in the data about
will be included in the likelihood function
, which is the joint distribution of the sample, so that, if
, given the parameter
, are independent and have a probability density function given by
, then
. In Bayesian inference, we use this information to update our knowledge using the Bayes theorem, thus, being able to obtain a posterior distribution for the parameter given the data,
. In the case of spatial conditional regression models, Cepeda-Cuervo, Córdoba and Núñez-Antón [
22] considered the variables
, conditioned on the assumed spatial neighborhood structure, following an overdispersion distribution such as the ones mentioned in
Section 2.1, and the parameter
, to be estimated, to be independent. Therefore, under these independence assumptions, the likelihood function can be obtained in the usual way and, therefore, the Bayesian inference process is valid.
In Bayesian analysis, vague or noninformative prior distributions for the parameters are usually specified in order to minimize the possible impact of prior information, compared to the likelihood of the data, on the posterior inference. For the regression coefficients of explanatory variables, typically normal prior distributions with zero mean and large variances are considered. In this case, we assume that
. In most software packages available for Bayesian inference approaches, the prior distribution for the variance component in the normal distribution is implemented on its inverse instead, which is usually labeled as the precision parameter (i.e.,
), so that
, if
is the variance component parameter. For this precision parameter several prior distributions have been proposed in the literature for Bayesian hierarchical models (see [
36]), the Gamma distribution being the most commonly used. In this way, it is assumed that
, with
and
being fixed and user-specified parameters. The choice of these values,
and
, is a crucial issue that needs to be addressed in a careful manner, mainly because inference can be sensitive to their selection, especially when the data set does not have a large number of observations available (see [
36]). Specific values of
for this prior distribution are often employed in many applications (see [
17]), so that
, which, given that its mean is equal to 1 and its variance equal to 1000, a large value, it can be considered as a vague prior. Alternative frequently used values that can be found in the literature are,
and
, in Vranckx, Neyens and Faes [
30],
,
in Best, Richardson and Thomson [
18],
and
in Carroll, Lawson, Faes, Kirby, Aregay and Watjou [
29],
in Cepeda-Cuervo, Córdoba and Núñez-Antón [
22], among others. Nevertheless, the choice of these parameters must be based on their adequacy to the specific application considered and its adverse effects on the posterior inference should be appropriately assessed and studied.
Following these guidelines, for our Bayesian analysis, we will assume noninformative prior distributions with zero mean and large variance for the regression parameters, as well as for the spatial lag parameters included in the proposed models. For the inverse of the dispersion parameters, , we will specify Gamma distributions with large variances, so that , with being a very small value. Estimation will be carried out in OpenBUGS, and also in R-INLA for some specific cases.
Model selection will be performed by using the Deviance Information Criterion (DIC) [
37] and the Watanabe-Akaike Information Criterion (WAIC) [
38], also known as the widely applicable information criterion, where the models with the lowest values for these criteria would be considered as the best fitting ones. On the one hand, the DIC is based on the posterior distribution of the deviance statistic, a measure of the model’s fit, and it is penalized by the effective number of parameters, which is a measure representing the complexity of the model. On the other hand, the WAIC is based on the logarithm of the pointwise posterior predictive density and receives a penalty specified by a different definition of the effective number of parameters. This criterion has become very popular in the last few years, since it is considered as a fully Bayesian approach (see [
23,
39]). Given that each of these two measures has its own advantages and drawbacks (see [
39]), we will include both of them in our analysis, since we believe the information provided by one can be complemented by the other. Moreover, besides these information criteria values, we will also take into account the predictive accuracy of the fitted models to select the best fitting ones by performing posterior predictive checks on each of the fitted models.














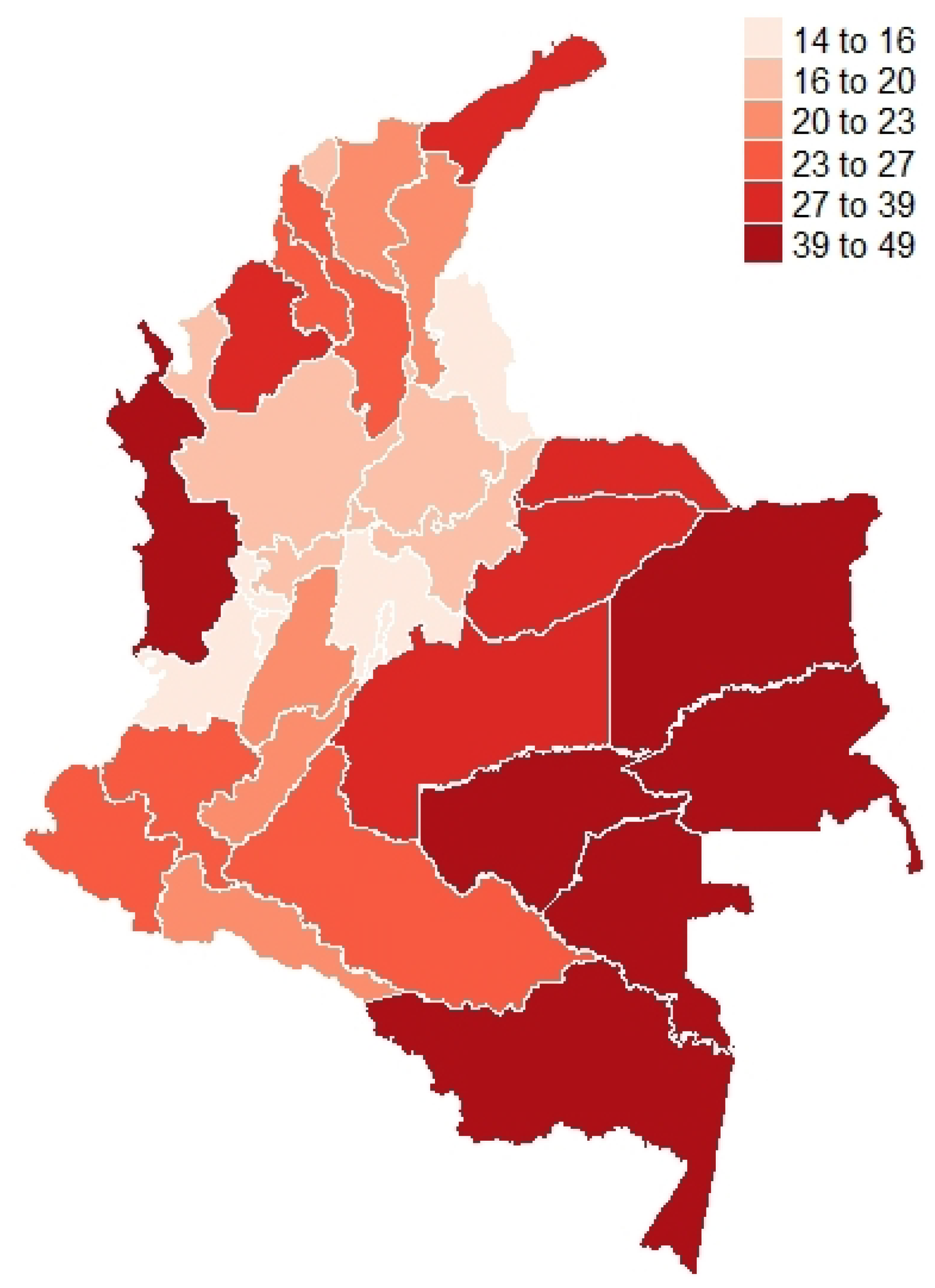{kind=link}
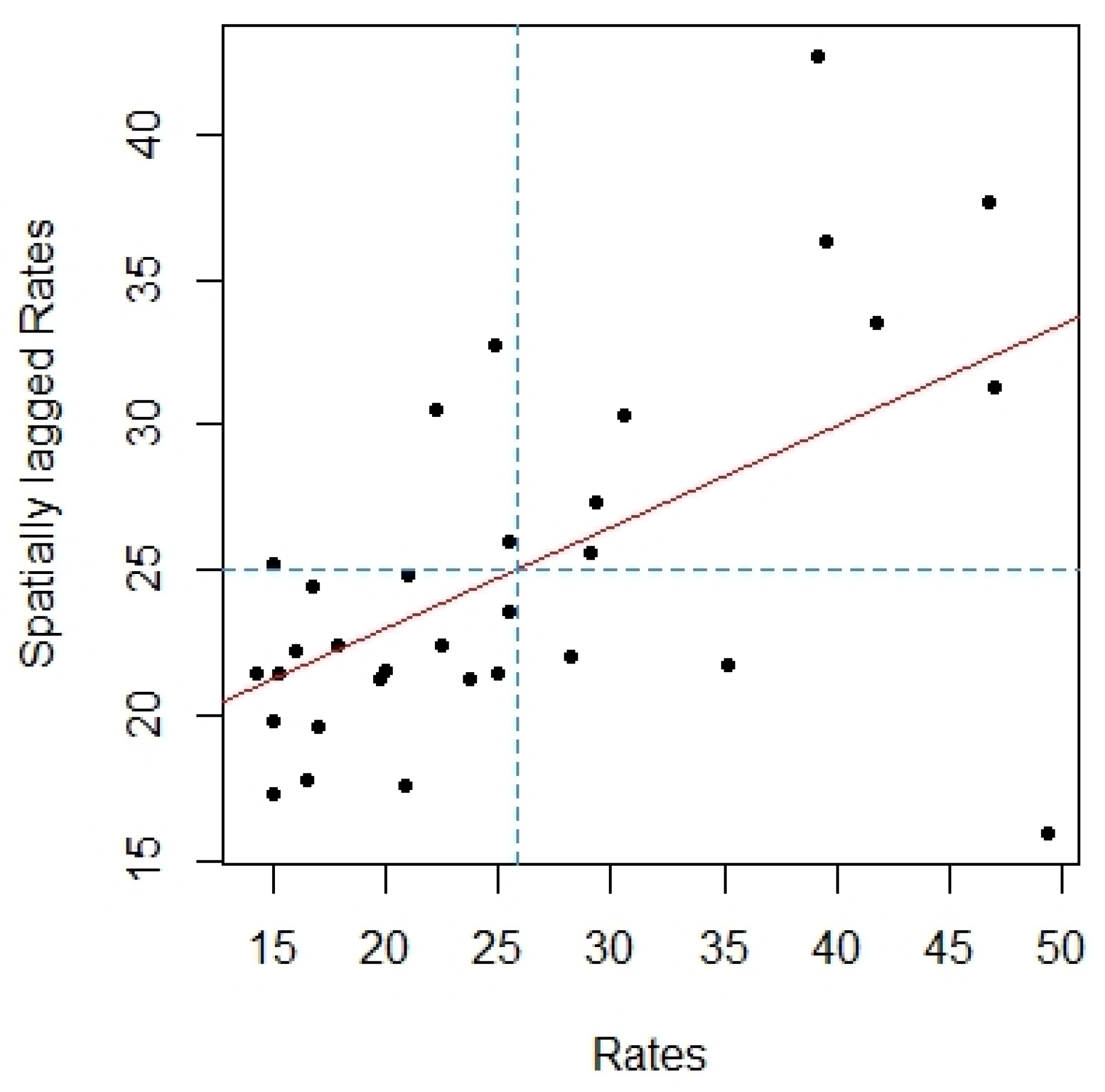{kind=link}
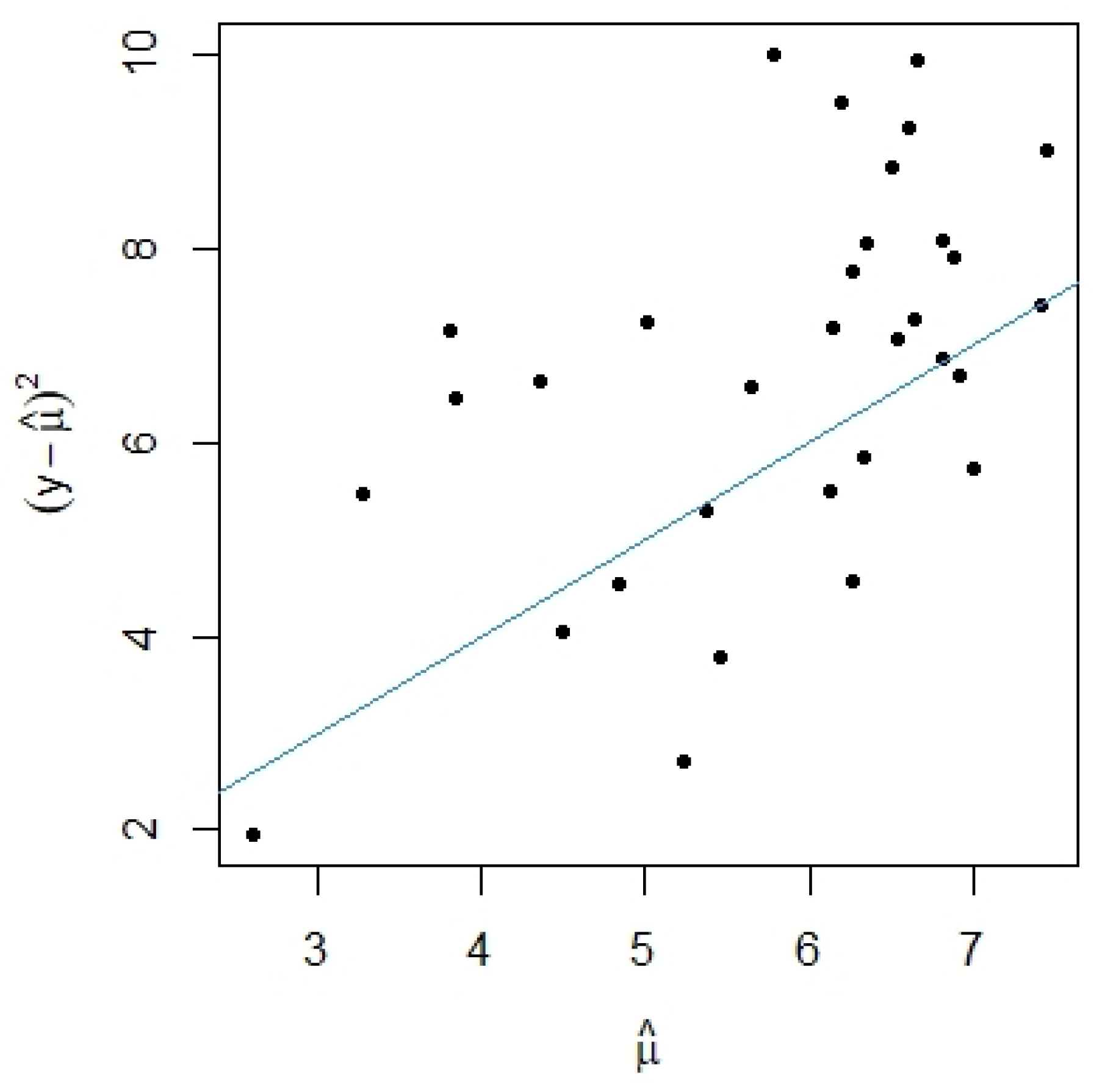{kind=link}
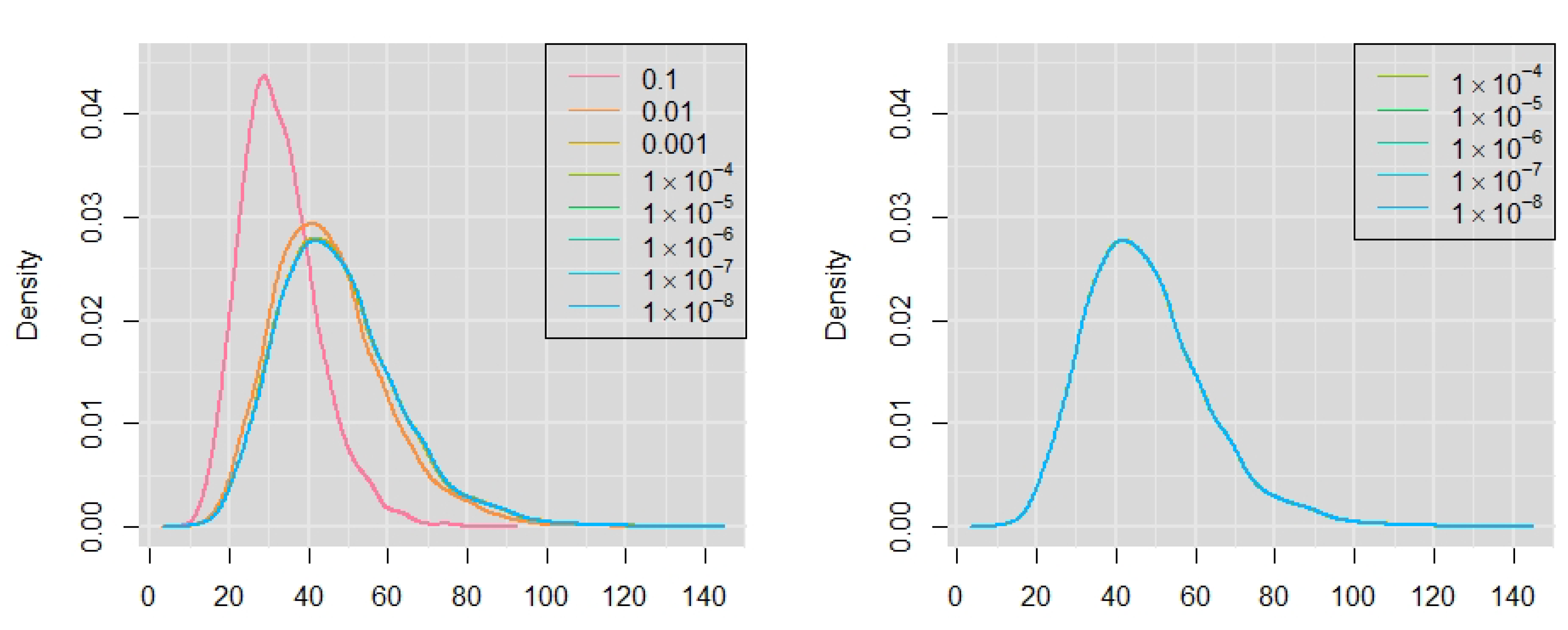{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}