
High-Precision Kriging Modeling Method Based on Hybrid Sampling Criteria


Abstract
:1. Introduction
2. Related Work
2.1. Kriging
2.2. AME
3. HKM-HS Method
3.1. Maximizing Mean Square Error (MMSE)
3.2. MC Criterion
3.3. Screening Method
3.4. Implementation of the HKM-HS Method
4. Numerical Experiment
4.1. Benchmark Function Test
4.2. Examples
4.2.1. Spring Design Problem
4.2.2. Ten-Bar Planar Truss Problem
5. House Heating
6. Conclusions
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Data Availability Statement
Conflicts of Interest
References
- Jensen, W.A. Response surface methodology: Process and product optimization using designed experiments. J. Qual. Technol. 2017, 49, 186. [Google Scholar] [CrossRef]
- Fan, Y.; Lu, W.; Miao, T.; Li, J.; Lin, J. Multiobjective optimization of the groundwater exploitation layout in coastal areas based on multiple surrogate models. Environ. Sci. Pollut. Res. Int. 2020, 27, 19561–19576. [Google Scholar] [CrossRef] [PubMed]
- Yan, C.; Shen, X.; Guo, F. An improved support vector regression using least squares method. Struct. Multidiscip. Optim. 2017, 57, 2431–2445. [Google Scholar] [CrossRef]
- Hamed, Y.; Alzahrani, A.I.; Mustaffa, Z.; Ismail, M.C.; Eng, K.K. Two steps hybrid calibration algorithm of support vector regression and K-nearest neighbors. Alex. Eng. J. 2020, 59, 1181–1190. [Google Scholar] [CrossRef]
- Fan, C.; Huang, Y.; Wang, Q. Sparsity-promoting polynomial response surface: A new surrogate model for response prediction. Adv. Eng. Softw. 2014, 77, 48–65. [Google Scholar] [CrossRef]
- Rashki, M.; Azarkish, H.; Rostamian, M.; Bahrpeyma, A. Classification correction of polynomial response surface methods for accurate reliability estimation. Struct. Saf. 2019, 81, 101869. [Google Scholar] [CrossRef]
- Dou, S.-q.; Li, J.-j.; Kang, F. Health diagnosis of concrete dams using hybrid FWA with RBF-based surrogate model. Water Sci. Eng. 2019, 12, 188–195. [Google Scholar] [CrossRef]
- Durantin, C.; Rouxel, J.; Désidéri, J.A.; Glière, A. Multifidelity surrogate modeling based on radial basis functions. Struct. Multidiscip. Optim. 2017, 56, 1061–1075. [Google Scholar] [CrossRef] [Green Version]
- Keshtegar, B.; Mert, C.; Kisi, O. Comparison of four heuristic regression techniques in solar radiation modeling: Kriging method vs RSM, MARS and M5 model tree. Renew. Sustain. Energy Rev. 2018, 81, 330–341. [Google Scholar] [CrossRef]
- Li, T.; Yang, X. An efficient uniform design for Kriging-based response surface method and its application. Comput. Geotech. 2019, 109, 12–22. [Google Scholar] [CrossRef]
- van Stein, B.; Wang, H.; Kowalczyk, W.; Emmerich, M.; Bäck, T. Cluster-based Kriging approximation algorithms for complexity reduction. Appl. Intell. 2019, 50, 778–791. [Google Scholar] [CrossRef] [Green Version]
- Namura, N.; Shimoyama, K.; Obayashi, S. Kriging surrogate model with coordinate transformation based on likelihood and gradient. J. Glob. Optim. 2017, 68, 827–849. [Google Scholar] [CrossRef]
- Craven, B.A.; Aycock, K.I.; Herbertson, L.H.; Malinauskas, R.A. A CFD-based Kriging surrogate modeling approach for predicting device-specific hemolysis power law coefficients in blood-contacting medical devices. Biomech. Model. Mechanobiol. 2019, 18, 1005–1030. [Google Scholar] [CrossRef] [PubMed]
- An, X.; Song, B.; Mao, Z.; Ma, C. Layout Optimization Design of Two Vortex Induced Piezoelectric Energy Converters (VIPECs) Using the Combined Kriging Surrogate Model and Particle Swarm Optimization Method. Energies 2018, 11, 2069. [Google Scholar] [CrossRef] [Green Version]
- Yu, J.; Wang, Z.; Chen, F.; Yu, J.; Wang, C. Kriging surrogate model applied in the mechanism study of tip leakage flow control in turbine cascade by multiple DBD plasma actuators. Aerosp. Sci. Technol. 2019, 85, 216–228. [Google Scholar] [CrossRef]
- Zeng, F.; Bu, J.; Yu, Y.; Bian, H.; Yang, L.; Zi, X. Optimum design of permanent magnet synchronous generator based on MaxPro sampling and kriging surrogate model. IEEJ Trans. Electr. Electron. Eng. 2020, 15, 278–290. [Google Scholar] [CrossRef]
- Palar, P.S.; Liem, R.P.; Zuhal, L.R.; Shimoyama, K. On the use of surrogate models in engineering design optimization and exploration: The key issues. In Proceedings of the Genetic and Evolutionary Computation Conference Companion, Prague, Czech Republic, 13–17 July 2019. [Google Scholar]
- Settles, B. Active Learning Literature Survey; University of Wisconsin-Madison Department of Computer Sciences: Madison, WI, USA, 2009. [Google Scholar]
- Jin, R.; Chen, W.; Sudjianto, A. On sequential sampling for global metamodeling in engineering design. In Proceedings of the ASME 2002 International Design Engineering Technical Conferences and Computers and Information in Engineering Conference, Montreal, QC, Canada, 29 September–2 October 2002. American Society of Mechanical Engineers Digital Collection. [Google Scholar]
- Liu, H.; Cai, J.; Ong, Y.-S. An adaptive sampling approach for kriging metamodeling by maximizing expected prediction error. Comput. Chem. Eng. 2017, 106, 171–182. [Google Scholar] [CrossRef]
- Liu, H.; Xu, S.; Ma, Y.; Chen, X.; Wang, X. An Adaptive Bayesian Sequential Sampling Approach for Global Metamodeling. J. Mech. Des. 2016, 138, 011404. [Google Scholar] [CrossRef]
- Sacks, J.; Welch, W.J.; Mitchell, T.J.; Wynn, H.P. Design and analysis of computer experiments. Stat. Sci. 1989, 4, 409–423. [Google Scholar] [CrossRef]
- Jiang, P.; Zhang, Y.; Zhou, Q.; Shao, X.; Hu, J.; Shu, L. An adaptive sampling strategy for Kriging metamodel based on Delaunay triangulation and TOPSIS. Appl. Intell. 2018, 48, 1644–1656. [Google Scholar] [CrossRef]
- Xu, J.; Dang, C. A novel fractional moments-based maximum entropy method for high-dimensional reliability analysis. Appl. Math. Model. 2019, 75, 749–768. [Google Scholar] [CrossRef]
- Zeng, W.; Sun, W.; Song, H.; Ren, T.; Sun, Y. A parallel adaptive sampling strategy to accelerate the sampling process during the modeling of a Kriging metamodel. J. Chin. Inst. Eng. 2019, 42, 676–689. [Google Scholar] [CrossRef]
- Wei, X.; Wu, Y.-Z.; Chen, L.-P. A new sequential optimal sampling method for radial basis functions. Appl. Math. Comput. 2012, 218, 9635–9646. [Google Scholar] [CrossRef]
- Cai, X.; Qiu, H.; Gao, L.; Yang, P.; Shao, X. A multi-point sampling method based on kriging for global optimization. Struct. Multidiscip. Optim. 2017, 56, 71–88. [Google Scholar] [CrossRef]
- Li, Y. A Kriging-based multi-point sequential sampling optimization method for complex black-box problem. Evol. Intell. 2020, 1–10. [Google Scholar] [CrossRef]
- Liu, B.; Xie, L. An Improved Structural Reliability Analysis Method Based on Local Approximation and Parallelization. Mathematics 2020, 8, 209. [Google Scholar] [CrossRef] [Green Version]
- Nielsen, H.B. Aspects of the Matlab Toolbox DACE; Technical University of Denmark: Kongens Lyngby, Denmark, 2002. [Google Scholar]
- Lophaven, S.; Nielsen, H.; Sondergaard, J.; Dace, A. A Matlab Kriging Toolbox; Technical Report, No. IMMTR-2002-12; Technical University of Denmark: Kongens Lyngby, Denmark, 2002. [Google Scholar]
- Rasmussen, C.E.; Williams, C.K.I. Gaussian Processes for Machine Learning; The MIT Press: Cambridge, MA, USA, 2005. [Google Scholar]
- Palar, P.S.; Shimoyama, K. Efficient global optimization with ensemble and selection of kernel functions for engineering design. Struct. Multidiscip. Optim. 2018, 59, 93–116. [Google Scholar] [CrossRef]
- Yuan, G.L.; Yu, T.; Du, J. Multi-Objective Optimal Load Distribution Based on Sub Goals Multiplication and Division in Power Plants. Appl. Mech. Mater. 2014, 494–495, 1715–1718. [Google Scholar] [CrossRef]
- Yun, Y.; Chuluunsukh, A.; Gen, M. Sustainable Closed-Loop Supply Chain Design Problem: A Hybrid Genetic Algorithm Approach. Mathematics 2020, 8, 84. [Google Scholar] [CrossRef] [Green Version]
- Schobi, R.; Sudret, B.; Wiart, J. Polynomial-chaos-based kriging. Int. J. Uncertain. Quantif. 2015, 5, 171–193. [Google Scholar] [CrossRef]
- Xiong, Y.; Chen, W.; Apley, D.; Ding, X. A non-stationary covariance-based Kriging method for metamodelling in engineering design. Int. J. Numer. Methods Eng. 2010, 71, 733–756. [Google Scholar] [CrossRef]
- Arora, J.S. Optimum Design with Excel Solver. In Introduction to Optimum Design; Academic Press: Cambridge, MA, USA, 2012; pp. 213–273. [Google Scholar]
- Sobieszczanski-Sobieski, J.; Barthelemy, J.-F.; Riley, K.M. Sensitivity of Optimum Solutions of Problem Parameters. AIAA J. 1982, 20, 1291–1299. [Google Scholar] [CrossRef] [Green Version]
- Schmit, L.A.; Farshi, B. Some Approximation Concepts for Structural Synthesis. AIAA J. 1974, 12, 692–699. [Google Scholar] [CrossRef]
- Fan, Y.; Zhao, X.; Li, J.; Li, G.; Myers, S.; Cheng, Y.; Badiei, A.; Yu, M.; Akhlaghi, Y.G.; Shittu, S.; et al. Economic and environmental analysis of a novel rural house heating and cooling system using a solar-assisted vapour injection heat pump. Appl. Energy 2020, 275, 115323. [Google Scholar] [CrossRef]
- Bezyan, B.; Zmeureanu, R. Machine Learning for Benchmarking Models of Heating Energy Demand of Houses in Northern Canada. Energies 2020, 13, 1158. [Google Scholar] [CrossRef] [Green Version]






















{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Exponential model | |
| Exponential Gaussian model | |
| Gaussian model | |
| Linear model | |
| Spherical model | |
| Cubic model | |
| Spline model | |
| Matérn model | |
| HKM-HS Method |
|---|
| Step 1. Generate initial design points. The LHD (Latin Hypercube Design) method is used to generate initial design point . Then, set the initial sample set to . Step 2. Determine the sample sets and . Estimate the expensive objective function of each initial sample point to obtain . Then, set to be the set of all . For one or two update points obtained by the infilling sampling criterion, their expensive function evaluation values can be determined. Then the update point and its function evaluation value are added to the sample sets and , respectively. If there is only one new sampling point, then ; if there are two new sampling points, then . Step 3. Build Kriging model. The Kriging model will be established by the new data sets and formed by Step 2, and the construction of Kriging is realized by DACE toolbox in MATLAB. Step 4. Infill sampling criteria. The new infilling sampling method has two criteria, one is MMSE and the other is the MC sampling strategy based on mean square error and correlation function. See Section 3.1 and Section 3.2 for details. The PSO algorithm of MATLAB is used to optimize the sampling criteria. The first candidate point is obtained by optimizing the MMSE function (Equation (12)) through PSO algorithm. The second candidate point is obtained by optimizing the function (Equation (14)) with PSO algorithm. Step 5. Determine new sampling point. First, two candidate sampling points and are generated with the new infilling sampling criteria. Then, one or two candidate sampling points are selected as new sampling points. See Section 3.3 for details. Step 6. Stopping criterion. The maximum number of function evaluations is set as . Determine the relationship between m and . If the number of sampling points is greater than , stop adding points and go to step 7. If the condition is not met, go back to step 2. Step 7. Stop. This is the output global approximate Kriging model. |
| Algorithm for HKM-HS |
|---|
| 1. Begin 2. X and : Use LHD to generate m initial sample points and perform expensive functional evaluation on them. 3. Update and : Add the new sample point to , and add to . 4. Update m: or . The Kriging is established with new sets X and . and : Optimize the MMSE function and function by PSO. 7. New sampling points: Screening method (Section 3.3). Return to line 3or elsestop if this is the end. 9. End |
| Function | Dimension | Expression |
|---|---|---|
| Alpine | 2 | |
| Bukin | 2 | |
| Gp | 2 | |
| Mccormick | 2 | |
| Schwefel | 2 | |
| sixHump | 2 |
| D | Type | Function | AKSM-MC | MSE | LHD | AME | ||||
|---|---|---|---|---|---|---|---|---|---|---|
| RMSE | RMSE | RMSE | RMSE | |||||||
| Mean | Std | Mean | Std | Mean | Std | Mean | Std | |||
| 3 | Fourth | Hartman3 | 0.0350 | 0.0025 | 0.0443 | 0.0044 | 0.0460 | 0.0033 | 0.0379 | 0.0079 |
| 4 | Fourth | Shekel | 0.0038 | 0.0006 | 0.0048 | 0.0010 | 0.0075 | 0.0019 | 0.0054 | 0.0008 |
| 5 | Third | Michalewicz | 0.0329 | 0.0020 | 0.0402 | 0.0036 | 0.0478 | 0.0028 | 0.0401 | 0.0028 |
| 6 | Fourth | Hartman6 | 0.0121 | 0.0024 | 0.0166 | 0.0030 | 0.0167 | 0.0018 | 0.0134 | 0.0041 |
| 8 | First | Levy | 6.5634 | 0.3191 | 6.7909 | 0.5061 | 3.1332 | 0.2700 | 3.1550 | 0.3943 |
| 9 | Second | DixonPrice | 3.15 × 104 | 2.09 × 103 | 4.65 × 104 | 3.98 × 103 | 1.64 × 104 | 3.12 × 103 | 1.17 × 104 | 1.42 × 103 |
| 10 | Third | Michalewicz10 | 0.0461 | 0.0025 | 0.0476 | 0.0047 | 0.0499 | 0.0028 | 0.0513 | 0.0018 |
| 10 | Second | Rosenbrock | 228.5093 | 9.0254 | 377.0992 | 21.4293 | 230.2005 | 9.0255 | 231.2139 | 22.2353 |
| 12 | First | Rastrigin | 0.5446 | 0.0215 | 0.7339 | 0.1015 | 0.6045 | 0.0215 | 0.6608 | 0.0537 |
| 16 | Fourth | F16 | 1.3398 | 0.1280 | 1.4068 | 0.4496 | 1.4281 | 0.4921 | 1.3414 | 0.0535 |
| HKM-HS | MMSE | LHD | AME | ||
|---|---|---|---|---|---|
| RMSE | Meanstd | 258.1106 15.7369 | 305.5048 17.8805 | 436.2186 43.3815 | 284.0081 34.8651 |
| HKM-HS | MMSE | LHD | AME | ||
|---|---|---|---|---|---|
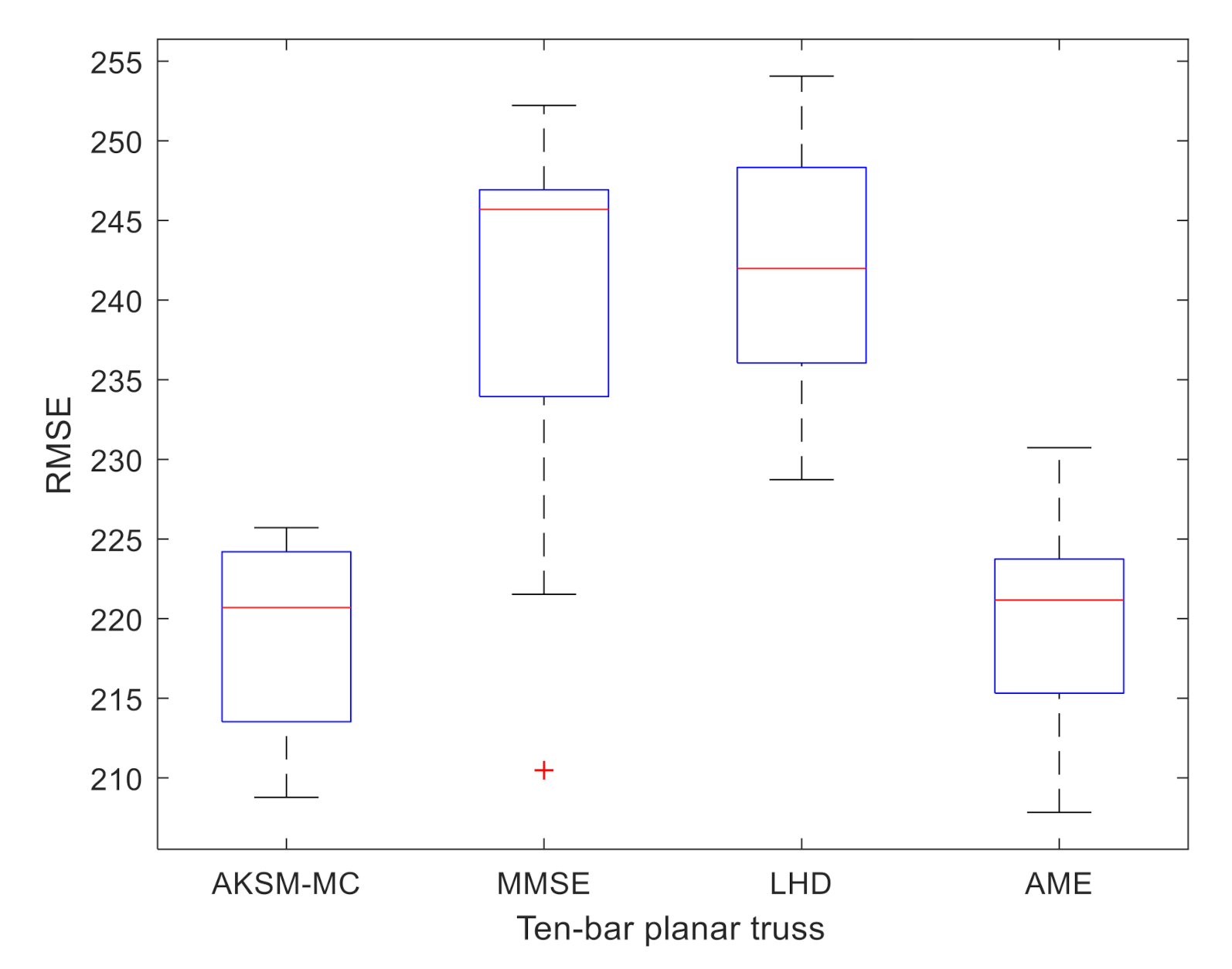
| RMSE | mean | 219.0163 | 238.4223 | 241.7911 | 219.7608 |
| std | 5.8617 | 12.7105 | 8.0089 | 6.5274 |
| HKM-HS | MMSE | LHD | AME | ||
|---|---|---|---|---|---|
| RMSE | mean | 0.5738 | 0.6028 | 0.6577 | 0.5866 |
| std | 0.0358 | 0.0418 | 0.0338 | 0.0505 |
Publisher’s Note: MDPI stays neutral with regard to jurisdictional claims in published maps and institutional affiliations. |
© 2021 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (http://creativecommons.org/licenses/by/4.0/).
Share and Cite
Shi, J.; Shen, J.; Li, Y. High-Precision Kriging Modeling Method Based on Hybrid Sampling Criteria. Mathematics 2021, 9, 536. https://doi.org/10.3390/math9050536
Shi J, Shen J, Li Y. High-Precision Kriging Modeling Method Based on Hybrid Sampling Criteria. Mathematics. 2021; 9(5):536. https://doi.org/10.3390/math9050536
Chicago/Turabian StyleShi, Junjun, Jingfang Shen, and Yaohui Li. 2021. "High-Precision Kriging Modeling Method Based on Hybrid Sampling Criteria" Mathematics 9, no. 5: 536. https://doi.org/10.3390/math9050536