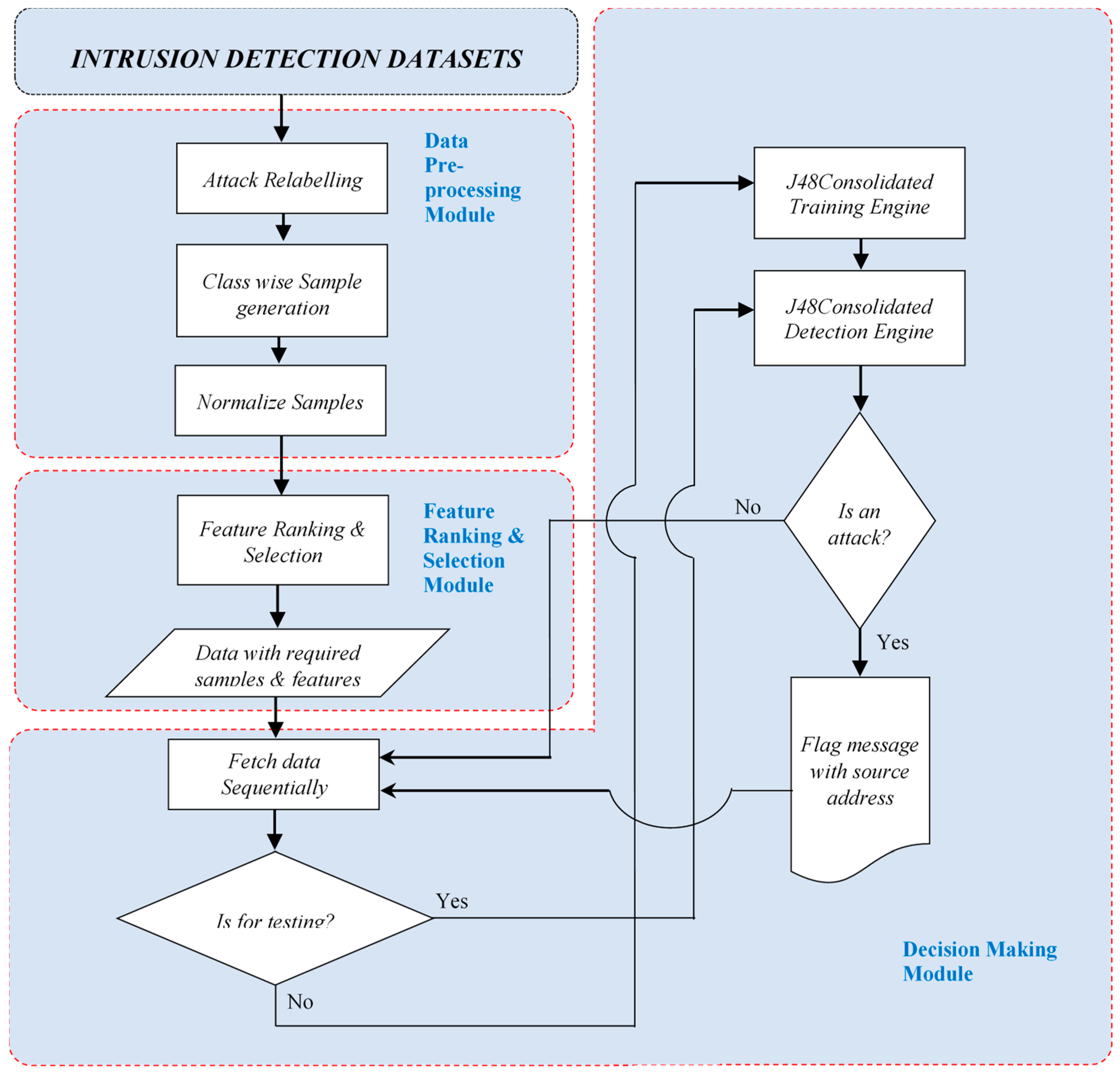
Data preprocessing starts with first removing duplicate and missing value instances of the dataset on which the system will be trained. Once the duplicate and missing values are removed, the related attack labels are merged with new class labels. By forming the new attack labels, it reduces the class imbalance issue significantly. A supervised sampling approach has been proposed to generate class-wise samples. Therefore, the class imbalance issue of the IDS datasets has been improved. A suitable normalizer has been applied to fix the dataset values in the range of 0 and 1.
In the feature selection phase, a suitable feature selector is deployed to retrieve the essential features by eliminating redundant features of the dataset. In the final stage, an intelligent C4.5 classifier is deployed, which resumes the training samples using CTC. The detailed procedure from dataset selection to intrusion detection is described as follows.
3.1. IDS Datasets
The preparation of data is critical for the training and testing of the IDS model. The candidate datasets NSLKDD [
34], ISCXIDS2012 [
35], CICIDS2017 [
36] provided by the Canadian Institute for Cybersecurity are the basis of the proposed IDS. On the one hand, the NSLKDD and CICIDS2017 datasets are multiclass and contain benign and multi-attack instances. On the other hand, the ISCXIDS2012 is a binary IDS dataset containing a mixture of benign and attack instances. These datasets’ features contain normal and the most recent frequent attacks resembling the real-world network environment. These datasets contain a considerable number of instances and feature sets, which is sufficient enough to be a bottleneck for any IDS. Therefore, these datasets can be considered reliable candidates for evaluating the proposed IDS architecture’s actual performance.
The system has been designed to select a required number of features with a reasonably small number of samples from these datasets for training and testing purposes. Before sampling and feature selection, the duplicate instances have been removed using Weka’s unsupervised RemoveDuplicates filter, and the unique instances are considered for feature selection and sampling. Furthermore, biases of the detector towards majority classes happen if the dataset is a high-class imbalance in nature. A reliable IDS detector must be prepared for such an adverse situation. The three datasets considered here are prone to high-class imbalance.
The prevalence ratio of normal labels and attack labels is 51.882% and 48.118%, respectively, for the NSLKDD dataset. Though the prevalence ratio seems to be convincing by just keeping normal instances on one side and attacking instances on the other side but observing the individual attack labels, the ratio seems discouraging. There is a considerable gap between majority class labels (Normal) and minority class labels (Spy, udpstorm, worm, SQL attack). This prevalence gap of attack labels makes the dataset imbalanced. By combining a few attack labels through forming a new label is possible to solve the imbalance issue.
In the ISCXIDS2012 dataset, data of normal and malicious instances are scattered in seven different XML files. The data from those XML files are merged into a single CSV file for analyzing the characteristics of the whole dataset. An XML file named “TestbedThuJun17-1Flows.xml” was found to be corrupted at the source during the extraction process. Therefore, it has been decided to drop that file from the analysis. The rest of the data files of the ISCXIDS2012 dataset are so large that the idea of excluding the file “TestbedThuJun17-1Flows.xml” had a negligible contribution to the entire set of data and hence will not affect the detection process. The ISCXIDS2012 is a high-class imbalanced dataset. The majority class (Normal) has a 96.98% prevalence rate. By considering this, the dataset directly may bias the detection model towards the majority class. Therefore, an efficient sampling technique is needed that can generate a balanced sample from this unbalanced dataset.
Finally, the most recent dataset, named CICIDS2017, is considered. The dataset contains a mixture of the most up-to-date attacks and normal data. The dataset claims to fulfill all the 11 criteria of an IDS described by Gharib et al. [
37]. By analyzing these IDS dataset design criteria, CICIDS2017 appears to be the most prominent dataset in evaluating the proposed IDS. Physically inspecting the dataset, it has been found that the dataset contains 3,119,345 records. Out of which, 288,602 instances have missing class labels, and 203 instances have missing values. Therefore, it has been decided to remove these outliers before conducting any further experiments. After removing 203 missing values and 288,602 missing class labels, a dataset is reduced to 2,830,540 distinct records. Furthermore, it is found that the dataset contains 15 attack labels and 83 features. It is also observed that there is a considerable class imbalance between the majority class and other classes. In this situation, if a detection model is created considering this CICIDS2017 dataset directly, then a false alarm might be generated for any incoming instance of attack class Heartbleed or Infiltration. Therefore, the dataset must be sampled in a balanced manner before training the IDS detector.
All the datasets NSLKDD, ISCXIDS2012, and CICIDS2017 are highly class imbalanced. Therefore, the challenge is to design a sampling model and detector, which can work efficiently on these imbalanced datasets.
3.2. Attack Relabeling
The class imbalance problem is widely cited in [
11,
38,
39], and its countermeasures have been addressed elaborately in [
40]. The problem of class imbalance lies more with the multiclass intrusion datasets. Numerous attack labels are found in a multiclass intrusion dataset that needs to be relabeled by merging two or more similar kinds of attacks either in terms of similar characteristics, features, or behaviors. Therefore, the NSLKDD and CICIDS2017 multiclass intrusion datasets have been considered to merge the respective minor class labels to form the new class information.
The NSLKDD dataset contains 39 types of attack and benign instances. The normal labels have more than 51% occurrence, whereas many attacks have a very low prevalence rate of 0.001%. Various similar attack labels of the NSLKDD dataset have been merged to generate new attack labels to reduce such imbalances. The selection of new attack labels has been considered per the guideline provided in [
41,
42]. The newly formed attack labels are presented as follows.
Denial of Service Attack (DoS): It is an attack in which the attacker makes some computing or memory resource too busy or too full to handle legitimate requests or denies legitimate users access to a machine. The NSLKDD dataset’s various attacks that fall within this category are apache2, back, land, mailbomb, neptune, pod, processtable, smurf, teardrop, udpstorm, and warezclient.
User to Root Attack (U2R): It is a class of exploit in which the attacker starts with access to a normal user account on the system (perhaps gained by sniffing passwords, a dictionary attack, or social engineering) and can exploit some vulnerability to gain root access to the system. U2R attacks of the NSLKDD dataset are buffer_overflow, httptunnel, loadmodule, perl, ps, rootkit, sqlattack, and xterm.
Remote to Local Attack (R2L): It occurs when an attacker who can send packets to a machine over a network but does not account on that machine exploits some vulnerability to gain local access as a user of that machine. The attacks that fall into this group are ftp_write, guess_passwd, imap, ftp_write, multihop, named, phf, sendmail, snmpgetattack, snmpguess, spy, warezmaster, worm, xlock, and xsnoop.
Probing Attack: It is an attempt to gather information about a network of computers for the apparent purpose of circumventing its security controls. Probing attacks are ipsweep, mscan, nmap, portsweep, saint, and satan.
Once the new attack labels are identified, the old labels are mapped to form new attack labels. The characteristics of new attack labels in the NSLKDD dataset with their prevalence rate are presented in
Table 1.
The imbalance ratio of newly created attack labels has been improved significantly as compared to the old attack labels. The prevalence rate of majority to minority class becomes 51.88:0.17, which is far better than earlier 51.88:0.001. Moreover, comparing the majority benign label (Normal) with other attack labels, it can be realized that the imbalance ratio has also been improved to a great extent.
Multiclass dataset CICIDS2017 has 15 different types of attack information. The normal label (Benign) has more than 83% occurrence, whereas many attacks have a very low prevalence rate of 0.00039%. To reduce such imbalances, various similar attack labels of this dataset have to be merged to generate new attack labels. The selection of new attack labels has been considered as per the guideline provided by the publisher of the CICIDS2017 dataset. The newly formed attack labels with their characteristics are presented in
Table 2.
The imbalance ratio of newly created attack labels has been improved significantly compared to the old attack labels of the CICIDS2017 dataset. The majority’s prevalence rate to minority class becomes 83.34%:0.001%, which is far better than earlier 83.34%: 0.00039%. Moreover, comparing the majority label (Normal) with other attack labels, it can be realized that the imbalance ratio has also been improved to a great extent.
3.3. Supervised Relative Random Sampling (SRRS)
The random sampling procedure is either a probability sampling or nonprobability in nature. In probability sampling, the probability of an object being included in the sample is defined by the researcher. On the other hand, there is no tactic of estimating the probability of an item being included in the sample in nonprobability sampling. Suppose the interest is to infer that a sample is in line with the original data’s finding. In that case, probability sampling is the better approach to consider. Random sampling is popularly known as a probability sampling mechanism [
43].
Random sampling ensures each item of the original item set stands a chance to be selected in the sample. The n samples are selected tuple-by-tuple from an original dataset of size
through random numbers between 1 and
. By signifying the dataset having
tuples as
—the focusing input and the desired samples as
—focusing output, and the random sampling procedure has been represented in Algorithm 1.
| Algorithm 1 Random Sampling |
![Mathematics 09 00751 i001]() |
In this algorithm, the sampling is done with replacement, i.e., each tuple has the same chance at each draw regardless of whether it has already been sampled or not. However, this kind of simple random sampling is purely unsupervised. In the case of a high-class imbalanced dataset, it does not guarantee a specific class label tuple will fall in the sample set. By observing the datasets considered here, especially the CICIDS2017 dataset, it is evident that the minority class contains only 36 tuples, whereas the primary class contains a vast volume of 2,359,087 tuples. In such a scenario, merely drawing a random sample will not help retrieve a balanced sample consisting of instances of all the class labels. Therefore, a specialized sampling mechanism needs to be developed, which should guarantee all class labels’ equal chances to participate in the sample space.
Keeping in view this requirement a supervised sampling technique has been designed that generates random samples for each class label of the dataset. Each instance of each class label has an equal priority and probability of participating in the sample space. The proposed sampling algorithm generates a sample of each class by assigning weight to each class label based on the frequency it holds. The number of random samples of a class label is generated according to the allocated weight at each iteration. The iteration continues until the desired samples of the specified size are generated. The allocated weight is relative and depends upon the frequency of the class label in the current sample set. The more the frequency, the less the weight allocated. This strategy has been imposed deliberately to give more weight to the class, having low frequency. The detailed step of the SRRS has been presented in Algorithm 2.
| Algorithm 2 Supervised Relative Random Sampling (SRRS) |
![Mathematics 09 00751 i002]() |
The main logic behind sample generation is generating class-wise random samples. The class-wise random sample is possible through
where,
= desired sample weight for class number
p,
= stepwise total instances for all classes. Once the desired weight is on hand, the random sampling algorithm (Algorithm 1) is called to get the required sample from each attack class instance. It should be noted that the sampling generation holds the principle
.
The proposed Supervised Relative Random Sampling (SRRS) has been validated using NSLKDD, ISCXIDS2012, and CICIDS2017 datasets through—
Class imbalance of a class is measured as the ratio of the number of instances of a class with the total number of instances of the dataset. On the other hand, the margin of sampling error is calculated through the Yamene formula as
where,
n = required sample size,
N = total number of instances in a dataset,
e = Margin of error. Simplifying the formulae, the margin of error
e is
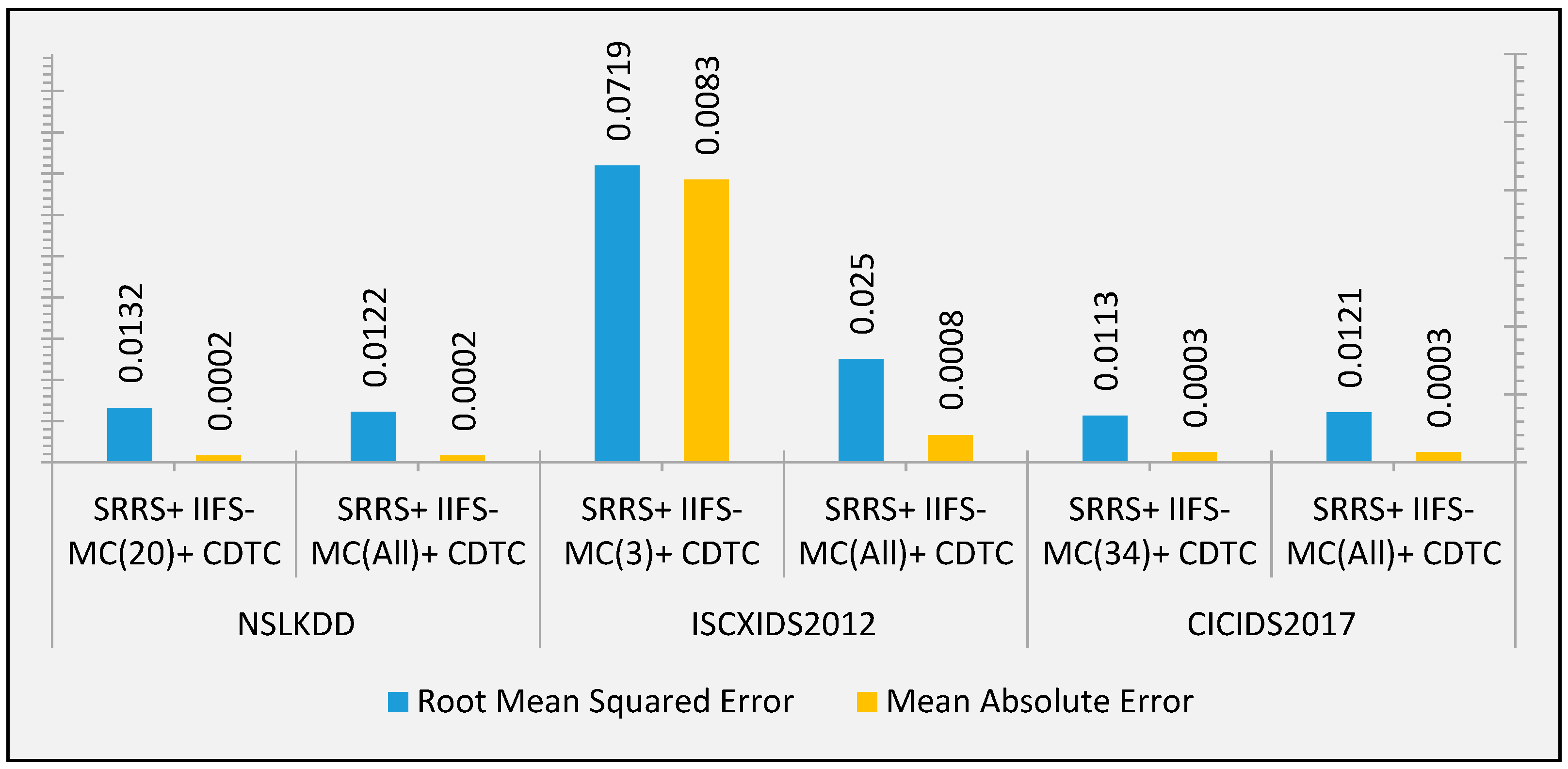
The SRRS algorithm performs consistently for all three datasets for varying sampling thresholds. The sampling thresholds considered here are 20,000, 60,000, and 100,000. In the case of the NSLKDD dataset for these sampling thresholds, SRRS generates 19,080, 56,032, and 87,312, respectively. This sample set leads to a very low sampling error of 0.007, 0.003, and 0.002, respectively. A similar kind of performance outcome is found for the ISCXIDS2012 and CICIDS2017 datasets.
Furthermore, considering class prevalence, it is found that the SRRS maintains a consistent prevalence ratio for all the attack labels. The improvement of prevalence (%) for all three datasets are summarized in
Table 6.
3.4. Feature Ranking and Selection using IIFS-MC
The principle of feature selection falls into three types [
44]. i.e., wrapper based, embedded and filter based. In wrapper-based feature selection, classifiers are used to generate feature subsets. Similarly, in embedded methods where feature selection is an inbuilt approach within the classifier, and the filter methods where properties of instances are analyzed to rank features followed by a feature subset selection. In the ranking phase, the reputation of each feature is evaluated through weight allocation [
45]. Moreover, in the subset selection phase, only those ranked features are selected for which a classifier shows the highest accuracy [
46,
47,
48,
49,
50,
51]. However, the features can also be chosen, ignoring ranks [
52]. In most cases, the subset selection procedure is supervised in nature.
There are several variations of filter-based feature selection mechanisms found in the literature. These feature selection mechanisms have their outcomes and limitations. The IFS is one of the recent unsupervised filter-based feature selection schemes that proved to be a magnificent feature selector over traditional popular schemes such as Fisher score [
52], Relief [
53], Mutual information (MI) [
49,
54], and Laplacian Score (LS) [
55]. As a filter-based algorithm, the feature selection process in IFS [
12] takes place in two steps. First, each feature of the underlying dataset is ranked in an unsupervised manner, and then the best m ranked features are selected through a cross-validation strategy. The distinguishing characteristic of IFS over other peer FS schemes is that all the features participate in estimating each feature’s weight. The idea is to construct an affinity graph from the feature set where the subset of features is realized as a path connecting them. The detailed steps of the IFS have been outlined in Algorithm 3.
| Algorithm 3 Infinite Feature Selection (IFS) |
![Mathematics 09 00751 i003]() |
For a generic distribution
,
x represents the random set of samples of the instance set
R, i.e.,
(where |
x| =
t). Now the target is to construct a fully connected graph
so that
V represents the set of vertices representing each feature of sample
x. The graph
G is nothing but an adjacency matrix
A, where
E represents the weighted edges through pairwise relation of the feature distribution. In other words, each element aij of matrix
, represents a pairwise energy term. Therefore, the element
can be represented as a weighted linear combination of two features
and
is
where,
| α | = | a loading coefficient ∈ [0, 1] |
| σij | = | max(σi, σj), where σi and σj are the standard deviation of fi and fj, respectively. |
| cij | = | 1 − Spearman(fi, fj) is the absolute Spearman’s rank correlation coefficient |
Once the matrix
A has been determined, the score of each feature can be estimated as:
where
denotes spectral radius and can be calculated as
Here, represent the eigenvalues of matrix A.
The authors found that there is considerable scope for improvement in the IFS algorithm. Equation (4) is the IFS algorithm’s heart, where the correlation matrix has been generated in an unsupervised manner. It should be noted that the correlation between the features of intraclass instances is close to each other. Similarly, the correlation between the features of inter-class distances hugely deviates. Therefore, analyzing features using a correlation matrix for each class will provide better insight than the overall correlation matrix of all the instances. Algorithm 3 can be used for each class of the sample and a weighted matrix should be prepared to contain weights of features of all the classes, where the total number of rows represents the number of classes and the columns represent the number of features, respectively. As a final step, the real weight of features can be realized by calculating each column of the weight matrix’s average. The improved version of IFS has been named IIFS-MC has been represented in Algorithm 4. The idea behind IIFS-MC is to calculate the weight of features based on the class information of instances. The class-wise feature weights improve classification accuracy to an impressive level.
As the class-wise weights of features have been calculated, therefore the complexity of this algorithm would be
is the number of samples,
is the number of initial features, and
is the number of classes.
| Algorithm 4 Improved Infinite Feature Selection for Multiclass classification (IIFS-MC) |
![Mathematics 09 00751 i004]() |
The proposed IIFS-MC analysis has been conducted similar to the guideline provided in [
12], where the mechanisms have been analyzed through a variety of datasets. Unfortunately, the analysis [
12] missed the standard intrusion detection datasets such as NSLKDD or CICIDS2017. Therefore, it has been decided to analyze the FS mechanisms through the most widely used NSLKDD, ISCXIDS2012, and CICIDS2017 datasets. In this regard, 5000 random samples of the NSLKDD dataset have been generated using the proposed Supervised Relative Random Sampling (SRRS) consisting of a mixture of normal and intrusion instances.
Furthermore, six popular supervised classifiers such as SVM, NB, Neural Network, Logistic Regression, C4.5, and Random Forest has been analyzed to judge the performance of the FS mechanisms discussed in this chapter along with the improved version of the infinite multiclass feature selection scheme. The classification accuracy of these supervised classifiers has been observed considering the varying size of features.
Table 7 reflects the performance of SVM on varying feature size. It can be seen that the accuracy of SVM improves with a change in feature size.
Using five features of NSLKDD, the SVM method shows the highest accuracy of 88.237% when the features are selected using IIFS-MC. Nevertheless, with the increase in feature size, the IFS magnificently improves the classifier’s accuracy, leading to an accuracy of 92.844%. However, IIFS-MC consistently shows significantly better accuracy for varying feature subsets among all other feature selection schemes.
A similar outcome has been observed for IIFS-MC when the classification has been conducted with NB. The adequate class information and class-wise feature weight calculation enable IIFS-MC to boost the accuracy of NB (
Table 8).
For Neural Network classification (
Table 9), IIFS-MC again performs better as compared to other FS schemes.
The IIFS-MC shows a distinct improvement over LSFS for almost all feature sizes. On the other hand, IIFS-MC shows distinctive accuracy only between 10–20 features. However, for all other feature sizes, both IFS and IIFS-MC produce a similar amount of accuracy. The logistic regression results FS schemes results are presented in
Table 10. Though the IIFS-MC scheme shows better accuracy as compared to other peer schemes, at the same time, IFS shows equivalent classification accuracy along with IIFS-MC. Similarly, Logistic Regression suffers from the original five features through MIFS. However, the situation becomes comfortable with an increase in feature size. Slowly, MIFS shows Logistic Regression’s performance at par with other FS schemes with 30 features in hand. The accuracy output of Logistic Regression for all the feature selectors has been presented in
Table 10.
Similarly, with all the ranked features in hand, the IFS, RelieF, and IIFS-MC show improved accuracy than that of the Fisher, MIFS, and LSFS schemes.
All the feature selection schemes show a close accuracy rate for Naïve Bayes and Function-based classifiers. However, the decision tree shows a distinct result and outperforms the other classifiers (
Table 11).
According to
Table 11, it is evident that IIFS-MC shows better accuracy for a little number of feature segments. However, with the increase in several features, the accuracy of C4.5 becomes close for all the feature selectors.
The Random Forest also reveals a similar accuracy rate for all the FS schemes except the Fisher score method. Random Forest’s accuracy improves with the Feature score, which was not visible earlier in the case of other decision trees (
Table 12).
Furthermore, up to the 20th feature, there was a close accuracy observed between IFS and IIFS-MC approaches. After the 20th feature to 30th, Random Forest’s accuracy deviates to a better position due to IIFS-MC. However, all the feature selectors show equivalent results while attaining the 37th feature of the NSLKDD dataset.
While analyzing the accuracy of supervised classifiers with various feature selection schemes, the following broad inferences have been observed.
- (i)
The improvised version of the IFS scheme ranks the features better to boost supervised classifiers’ accuracy to the maximum extent possible.
- (ii)
Moreover, it is observed that from the 20th feature onwards, the supervised classifiers show a similar accuracy as it is achieved with the whole set of features. Therefore, 20 features of the NSLKDD dataset are viable to achieve a similar accuracy level to the original feature set.
In this way, it has been observed that 20 ranked features of the NSLKDD dataset provide optimum detection results for a variety of supervised classifiers. Therefore out of all the ranked features of NSLKDD, the top 20 features are considered as feature subsets. All the ranked features of the NSL-KDD dataset have been outlined in
Table 13.
A similar kind of analysis on ISCXIDS2012 and CICIDS2017 datasets was also conducted, and the ranks of features for these two datasets are outlined in
Table 14 and
Table 15, respectively.
Similarly, observing the drifting of the accuracy of various classifiers similar to inference (ii), an attempt has been made to generate a feature subset of NSLKDD, ISCXIDS2012, and CICIDS2017 dataset, which will be taken into account to improve the performance of IDS detector in the subsequent stages of detection. The ideal feature subsets of IDS datasets are presented in
Table 16,
Table 17 and
Table 18.
It should be noted that, before the features ranking and subset selection process, all the identification attributes, such as Source and destination IP address, protocol name, system name, etc. have been removed from the dataset. This is because the feature selection technique used here is designed to work on numerical features only. Once the required numbers of features are selected, the training and testing data have been extracted from the samples. To achieve an unbiased experiment, both train and test data have been selected from the samples randomly in such a way that,
, where
represents the training and
represents the testing instances. In this case, 66% of the sample has been used for training, and 34% of the sample has been used for testing [
56,
57], the proposed detection model. The generated training and test samples that have been used to train and test the IDS detection engine are presented in
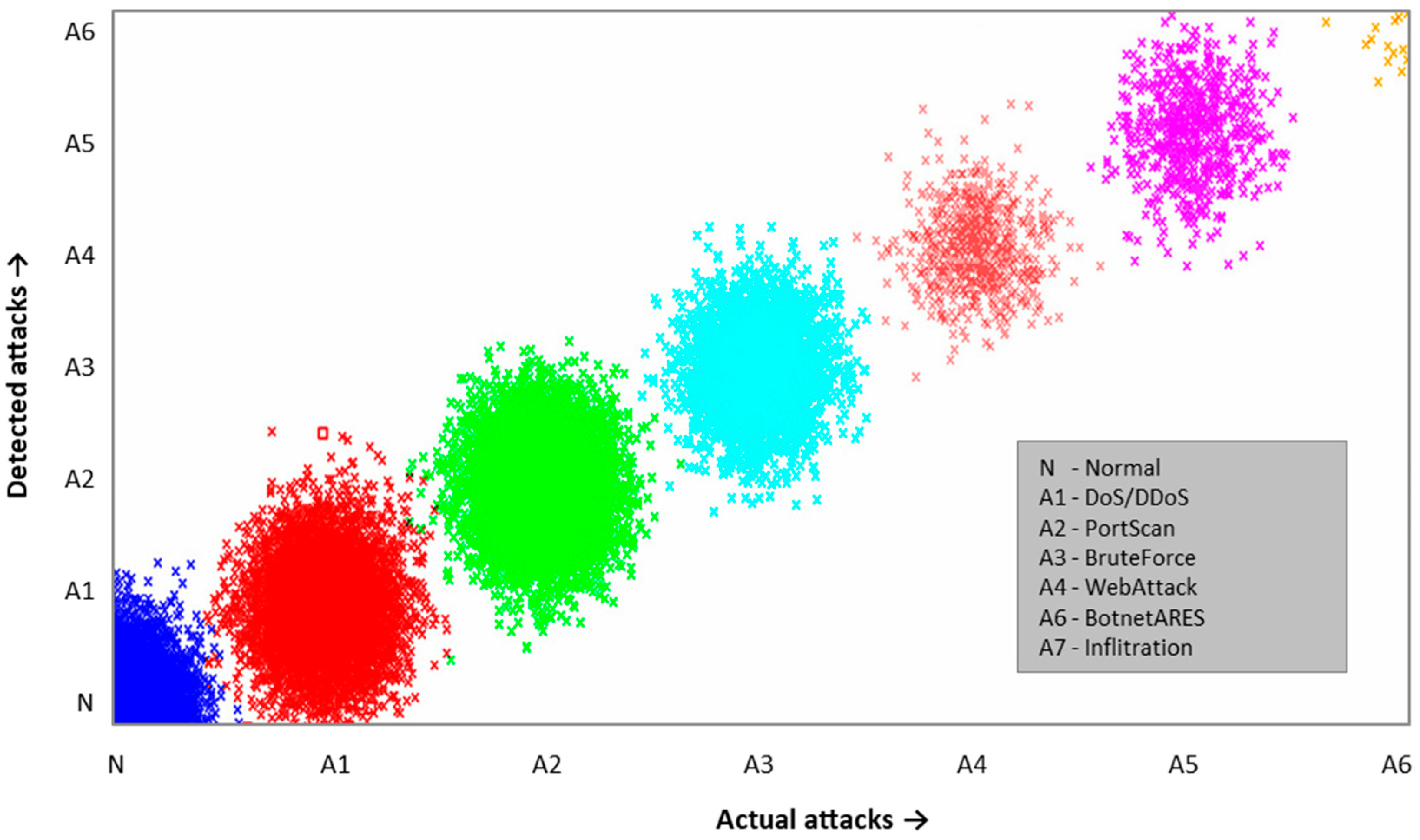
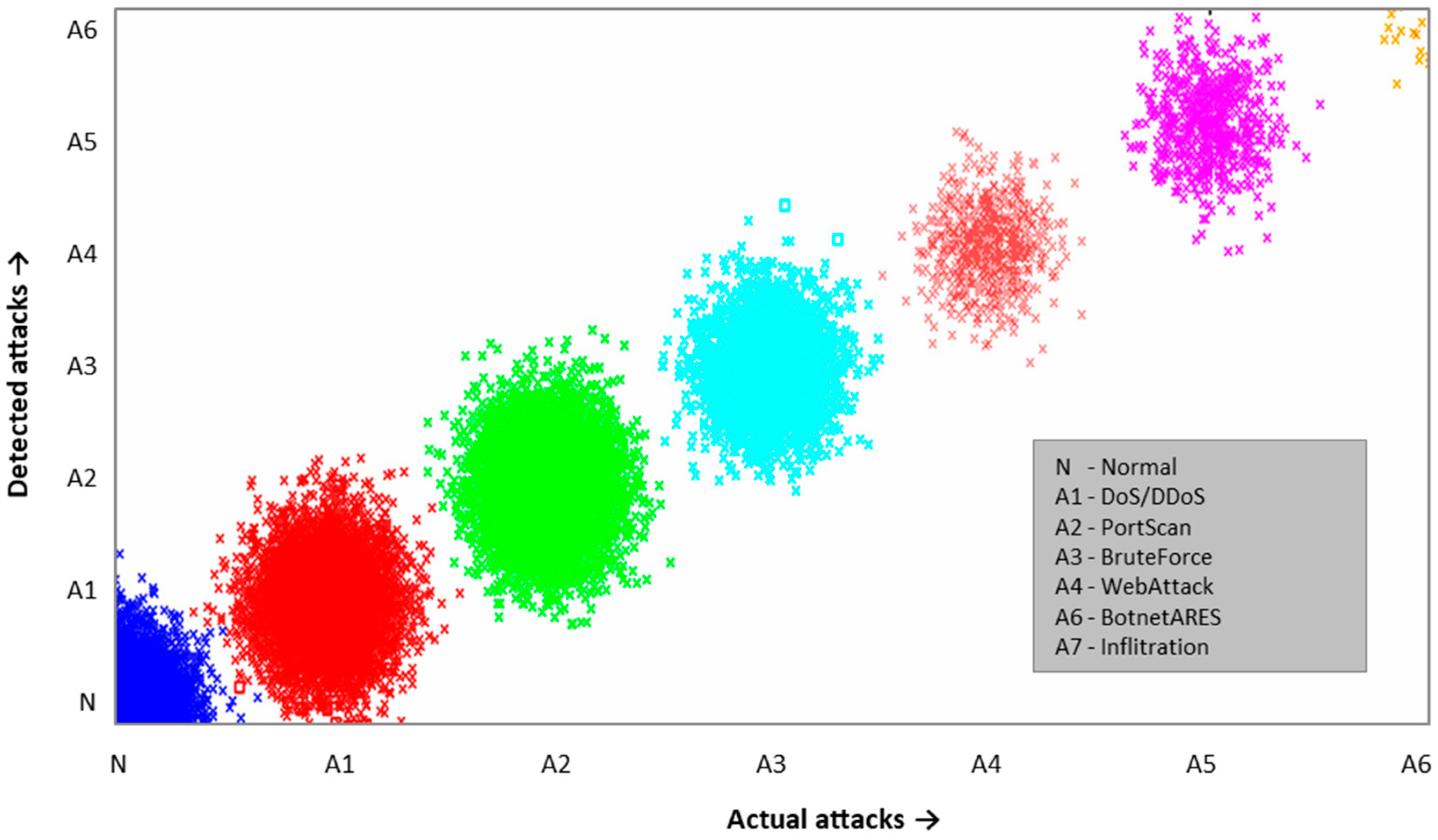
Table 19.


 ,
, 


















{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}