
Automatic Tempered Posterior Distributions for Bayesian Inversion Problems

 , , and
, , and
Abstract
:1. Introduction
2. Problem Statement
3. Key Observations and Proposed Approach
3.1. Split Inference
3.2. An Iterative Scheme
- 1
- Estimate by Monte Carlo (e.g., an IS scheme) by approximately maximizing .
- 2
- Compute
4. Automatic Tempering Adaptive Importance Sampling (ATAIS)
| Algorithm 1: ATAIS: AIS with automatic tempering. |
|
4.1. With a Generic Prior
5. Complete Bayesian Inference with ATAIS
6. Simulations
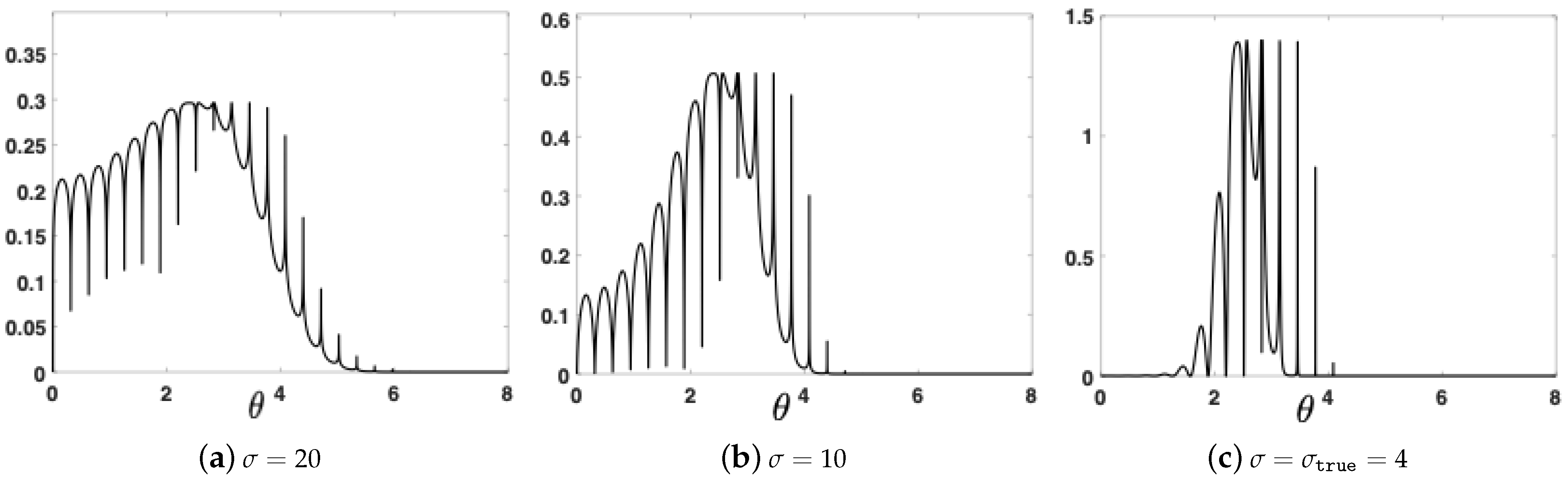
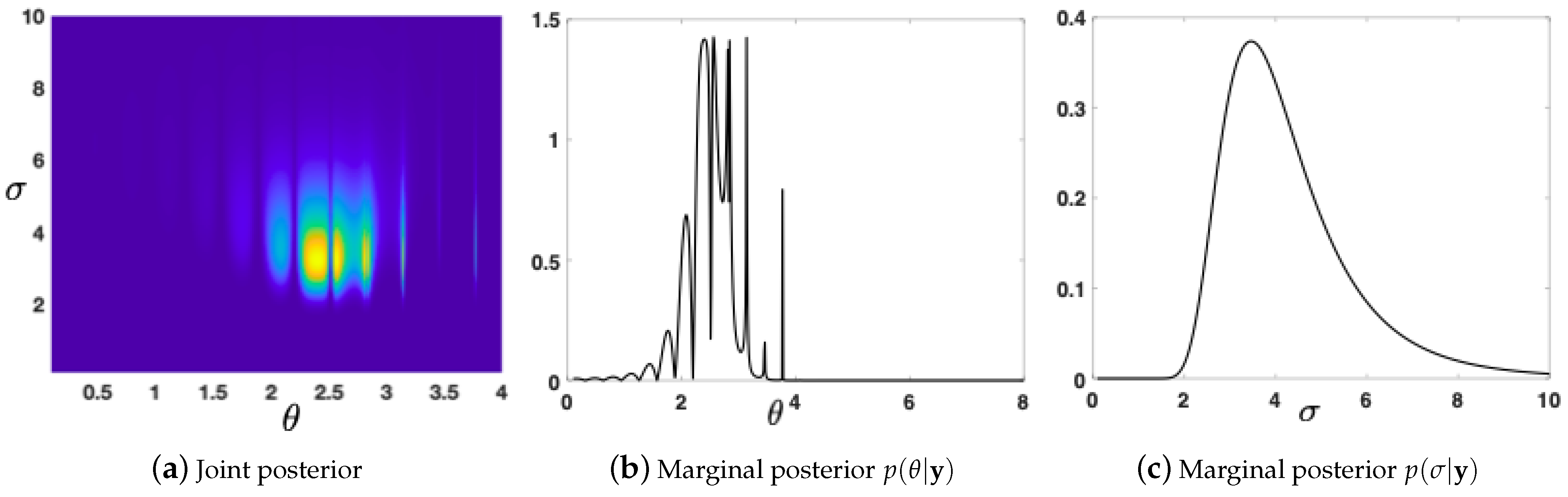
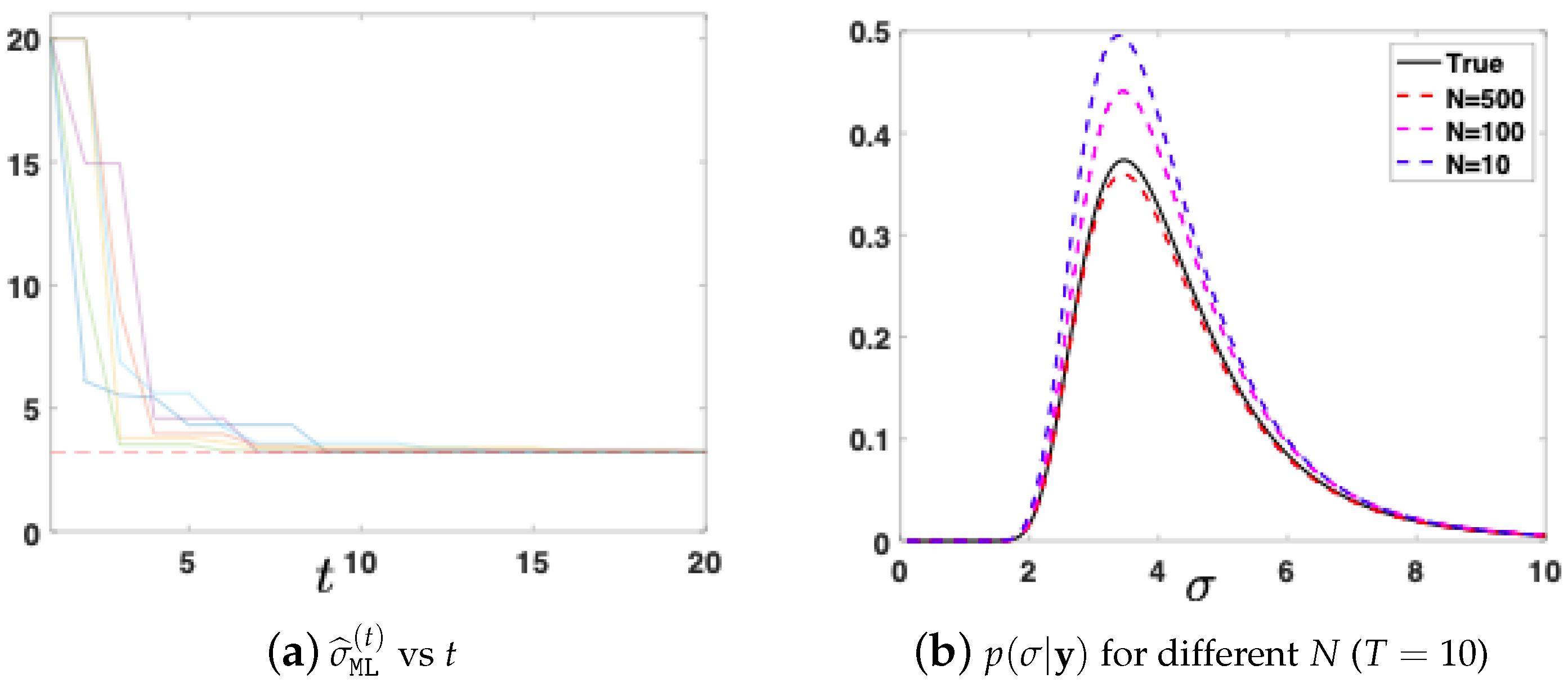
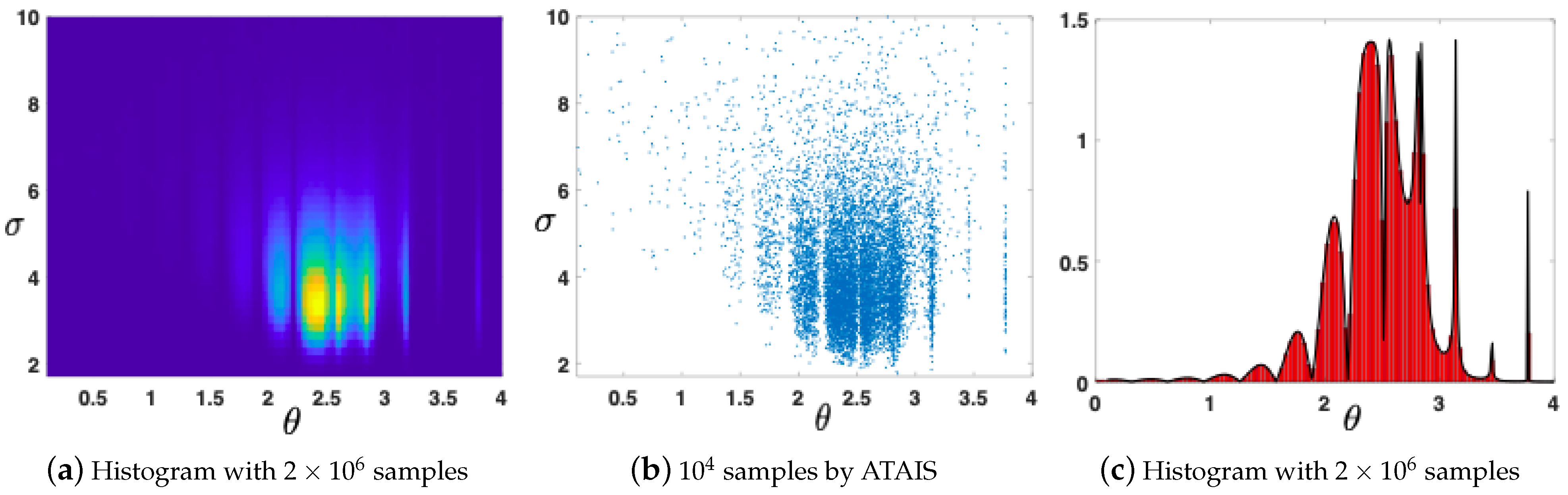
6.1. First Numerical Analysis
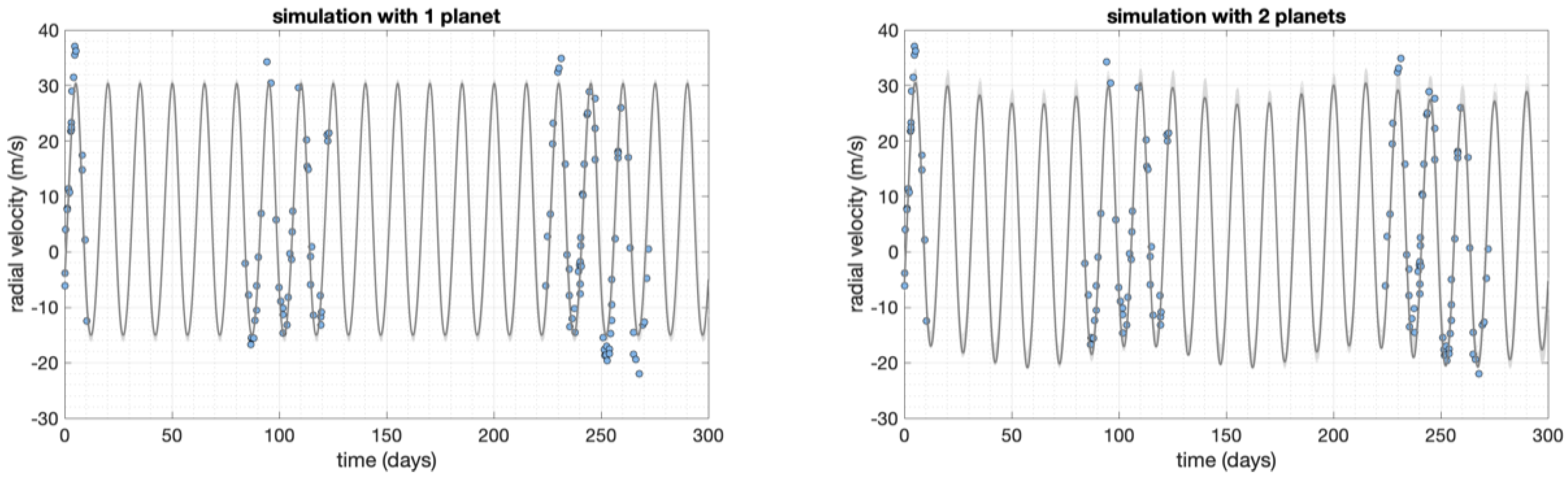
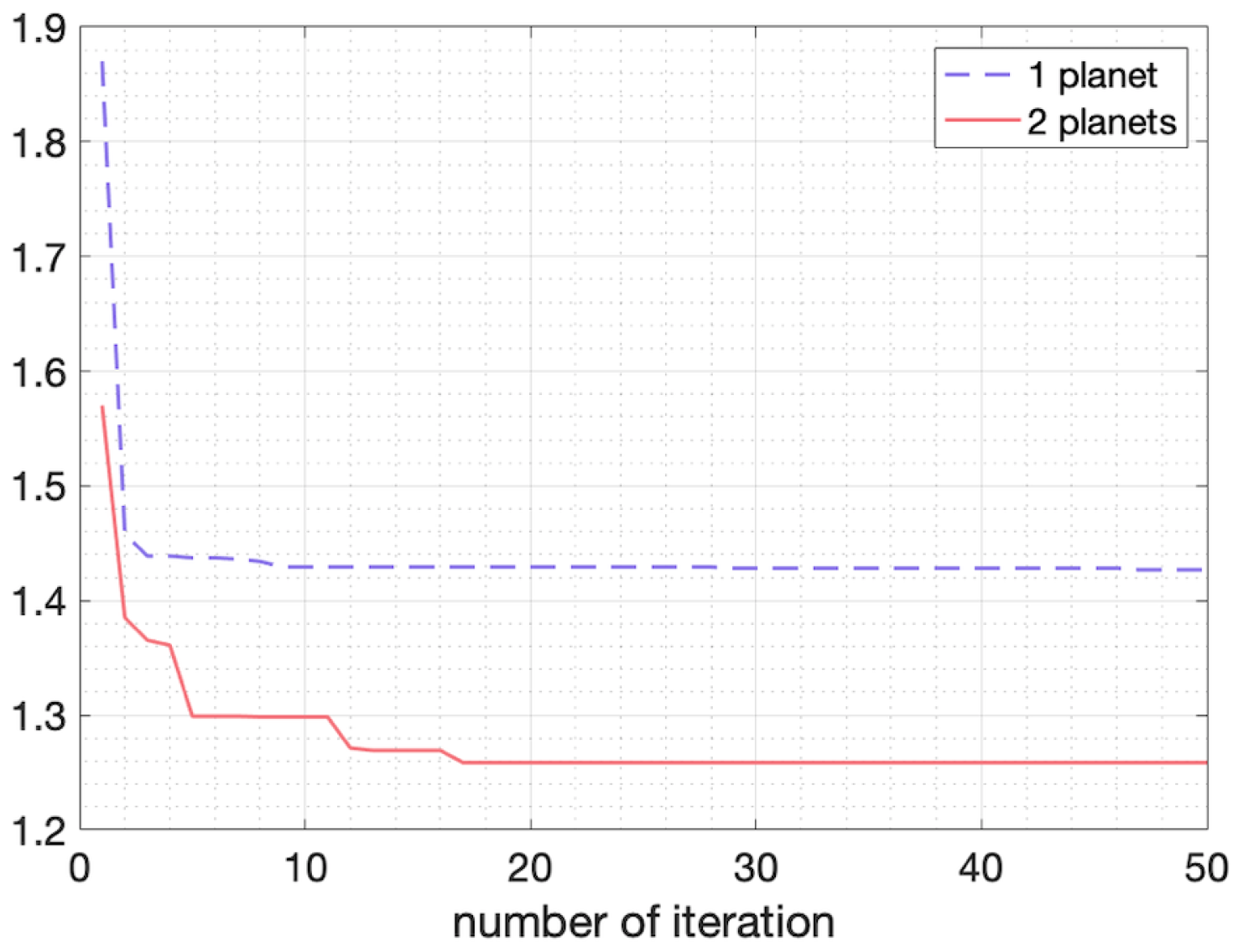
6.2. Radial Velocity Curves of Exoplanets and Binary Systems
7. Conclusions
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Data Availability Statement
Conflicts of Interest
Appendix A. On the Optimization of the Likelihood Function
References
- Fitzgerald, W.J. Markov chain Monte Carlo methods with applications to signal processing. Signal Process. 2001, 81, 3–18. [Google Scholar] [CrossRef]
- Andrieu, C.; de Freitas, N.; Doucet, A.; Jordan, M. An Introduction to MCMC for Machine Learning. Mach. Learn. 2003, 50, 5–43. [Google Scholar] [CrossRef] [Green Version]
- Martino, L.; Míguez, J. Generalized Rejection Sampling Schemes and Applications in Signal Processing. Signal Process. 2010, 90, 2981–2995. [Google Scholar] [CrossRef] [Green Version]
- Robert, C.P.; Casella, G. Monte Carlo Statistical Methods; Springer: New York, NY, USA, 2004. [Google Scholar]
- Liu, J.S. Monte Carlo Strategies in Scientific Computing; Springer: New York, NY, USA, 2004. [Google Scholar]
- Martino, L.; Luengo, D.; Miguez, J. Independent Random Sampling Methods; Springer: New York, NY, USA, 2018. [Google Scholar]
- Kirkpatrick, S., Jr.; Gelatt, C.D.; Vecchi, M.P. Optimization by Simulated Annealing. Science 1983, 220, 671–680. [Google Scholar] [CrossRef] [PubMed]
- Marinari, E.; Parisi, G. Simulated Tempering: A New Monte Carlo Scheme. Europhys. Lett. 1992, 19, 451–458. [Google Scholar] [CrossRef] [Green Version]
- Friel, N.; Pettitt, A.N. Marginal Likelihood Estimation via Power Posteriors. J. R. Stat. Soc. Ser. B Stat. Methodol. 2008, 70, 589–607. [Google Scholar] [CrossRef]
- Moral, P.D.; Doucet, A.; Jasra, A. Sequential Monte Carlo samplers. J. R. Stat. Soc. Ser. B Stat. Methodol. 2006, 68, 411–436. [Google Scholar] [CrossRef]
- Neal, R.M. Annealed importance sampling. Stat. Comput. 2001, 11, 125–139. [Google Scholar] [CrossRef]
- Llorente, F.; Martino, L.; Delgado, D.; Lopez-Santiago, J. Marginal likelihood computation for model selection and hypothesis testing: An extensive review. arXiv 2020, arXiv:2005.08334. [Google Scholar]
- Bugallo, M.F.; Martino, L.; Corander, J. Adaptive importance sampling in signal processing. Digit. Signal Process. 2015, 47, 36–49. [Google Scholar] [CrossRef] [Green Version]
- Rubin, D.B. Using the SIR algorithm to simulate posterior distributions. In Bayesian Statistics 3, Ads Bernardo, Degroot, Lindley, and Smith; Oxford University Press: Oxford, UK, 1988. [Google Scholar]
- Gelman, A.; Meng, X.L. Applied Bayesian Modeling and Causal Inference from Incomplete-Data Perspectives; John Wiley & Sons: New York, NY, USA, 2018. [Google Scholar]
- Gregory, P.C. Bayesian re-analysis of the Gliese 581 exoplanet system. Mon. Not. R. Astron. Soc. 2011, 415, 2523–2545. [Google Scholar] [CrossRef] [Green Version]
- Barros, S.C.C.; Brown, D.J.A.; Hébrard, G.; Gómez Maqueo Chew, Y.; Anderson, D.R.; Boumis, P.; Delrez, L.; Hay, K.L.; Lam, K.W.F.; Llama, J.; et al. WASP-113b and WASP-114b, two inflated hot Jupiters with contrasting densities. Astron. Astrophys. 2016, 593, A113. [Google Scholar] [CrossRef]
- Affer, L.; Damasso, M.; Micela, G.; Poretti, E.; Scand ariato, G.; Maldonado, J.; Lanza, A.F.; Covino, E.; Garrido Rubio, A.; González Hernández, J.I.; et al. HADES RV program with HARPS-N at the TNG. IX. A super-Earth around the M dwarf Gl 686. Astron. Astrophys. 2019, 622, A193. [Google Scholar] [CrossRef] [Green Version]
- Trifonov, T.; Stock, S.; Henning, T.; Reffert, S.; Kürster, M.; Lee, M.H.; Bitsch, B.; Butler, R.P.; Vogt, S.S. Two Jovian Planets around the Giant Star HD 202696: A Growing Population of Packed Massive Planetary Pairs around Massive Stars? Astron. J. 2019, 157, 93. [Google Scholar] [CrossRef] [Green Version]
- Press, W.H.; Teukolsky, S.A.; Vetterling, W.T.; Flannery, B.P. Numerical Recipes in C++: The Art of Scientific Computing; Springer: New York, NY, USA, 2002. [Google Scholar]
- Martino, L.; Elvira, V.; Luengo, D.; Corander, J. Layered Adaptive Importance Sampling. Stat. Comput. 2017, 27, 599–623. [Google Scholar] [CrossRef] [Green Version]
- Botev, Z.I.; Ecuyer, P.L.; Tuffin, B. Markov chain importance sampling with applications to rare event probability estimation. Stat. Comput. 2013, 23, 271–285. [Google Scholar] [CrossRef]







{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Expectation | Variance | MAP | |
|---|---|---|---|
| 2.48 | 0.11 | 2.56 | |
| 4.32 | 2.43 | 3.46 | |
| 2.46 | 0.18 | 2.56 |
| Value | Ground-Truths | ||||
|---|---|---|---|---|---|
| 0.0311 | 0.0098 | 0.0034 | 0.0024 | 2.48 | |
| 0.0474 | 0.0370 | 0.0298 | 0.0201 | 0.11 | |
| 0.0410 | 0.0337 | 0.0285 | 0.0127 | 2.56 | |
| 0.9233 | 0.0785 | 0.0097 | 0.0023 | 4.32 | |
| 6.1869 | 0.2640 | 0.0035 | 0.0010 | 2.43 | |
| 0.0056 | 0.0004 | 0.0001 | 3.46 | ||
| 3.23 | |||||
| Parameter | Planet 1 | Planet 2 |
|---|---|---|
| P | 15 d | 115 d |
| A | 25 m s | 5 m s |
| e | 0.1 | 0.0 |
| 0.61 rad | 0.17 rad | |
| 3 d | 24 d |
| Parameter | Planet 1 | Planet 2 | ||
|---|---|---|---|---|
| —Planet 2 | ||||
| P | 14.99 d | 0.18 | 110.39 d | 11.28 |
| K | 23.78 m s | 0.52 | 3.50 m s | 0.44 |
| e | 0.05 | 0.047 | 0.00 | 0.003 |
| 7.69 rad | 0.61 | 0.68 rad | 0.82 | |
| 6.8 d | 0.76 | 7.96 d | 20.31 | |
Publisher’s Note: MDPI stays neutral with regard to jurisdictional claims in published maps and institutional affiliations. |
© 2021 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Martino, L.; Llorente, F.; Curbelo, E.; López-Santiago, J.; Míguez, J. Automatic Tempered Posterior Distributions for Bayesian Inversion Problems. Mathematics 2021, 9, 784. https://doi.org/10.3390/math9070784
Martino L, Llorente F, Curbelo E, López-Santiago J, Míguez J. Automatic Tempered Posterior Distributions for Bayesian Inversion Problems. Mathematics. 2021; 9(7):784. https://doi.org/10.3390/math9070784
Chicago/Turabian StyleMartino, Luca, Fernando Llorente, Ernesto Curbelo, Javier López-Santiago, and Joaquín Míguez. 2021. "Automatic Tempered Posterior Distributions for Bayesian Inversion Problems" Mathematics 9, no. 7: 784. https://doi.org/10.3390/math9070784
APA StyleMartino, L., Llorente, F., Curbelo, E., López-Santiago, J., & Míguez, J. (2021). Automatic Tempered Posterior Distributions for Bayesian Inversion Problems. Mathematics, 9(7), 784. https://doi.org/10.3390/math9070784