1. Introduction
Many real-world applications pose different objectives (usually in conflict) to optimize [
1,
2,
3]. This leads to the proposal of a multi-objective optimization approach (MOOP—multi-objective optimization problem) [
4,
5,
6,
7]. In a posteriori multi-objective approach [
8], after the MOOP definition and the optimization stage, a set of Pareto optimal solutions [
9] is generated. The decision maker (DM) can then analyze, at the decision-making stage, the trade-off of the optimal alternatives for each design objective. This enables a better understanding of the problem and a better-informed final decision.
For the DM, it is useful to have a diverse set of solutions. Traditionally, diversity is sought in the objective space. However, obtaining a diverse set in the decision space also offers advantages [
10]: (1) it enables the DM to obtain different (even significantly different) alternatives before the final decision; (2) it helps speed up the search, improving exploration, and preventing premature convergence towards a non-global minimum. In addition, the best solutions are sometimes too sensitive to disturbances, or are not feasible in practice [
11,
12,
13,
14]. In this scenario, the multimodal solutions or the nearly optimal solution set (also called approximate or
-efficient solutions) plays a key role in enhancing the diversity of solutions. Two multimodal solutions are those that, being optimal, obtain the same performance. Nearly optimal solutions are those that have similar performance to optimal solutions. Generalizing, it can be considered that multimodal solutions are included in nearly optimal solutions. Nearly optimal solutions have been studied by many authors in the bibliography [
15,
16,
17,
18,
19], have similar performance to optimal solutions and can sometimes be more adequate according to DM preferences (for instance, more robust [
14]). Therefore, an additional challenge then arises: to obtain a set of solutions that, in addition to good performance in the design objectives, offer the greatest possible diversity.
However, considering all the nearly optimal solutions requires obtaining and analyzing a great number of alternatives and this causes two problems:
- 1
It slows down the optimization process. In evolutionary algorithms, an archive (a set to store solutions during the execution) is required. The computational cost of the optimization process largely depends on the archive size. This is because to check for the inclusion of a new candidate solution in the archive, it is necessary to check the dominance (or dominance) for each solution in the current archive. Many new candidate solutions are analyzed in an optimization process. Therefore, a large archive results in a significantly higher computational cost.
- 2
The decision stage is made more difficult. The designer must choose the final solution from a much larger number of alternatives.
Therefore, it is necessary to reduce the set of optimal solutions obtained by the designer. In the literature, there are different algorithms aimed at finding nearly optimal solutions in multi-objective optimization problems. The multimodal multi-objective evolutionary algorithms (MMEAs [
20]) are intended for multimodal optimization problems. Some of the MMEAs take into account nearly optimal solutions in the optimization process, but most of them do not provide these solutions to the DM. Furthermore, evolutionary algorithms with an unbounded external archive [
21] can also be interesting to analyze these solutions. These unbounded external archives can be analyzed to obtain the relevant nearly optimal solutions.
One of the crucial points in an evolutionary multi-objective optimization algorithm is the archiving strategy (or archiver). An archiving strategy is the strategy that selects and updates a solution set, called the archive, during the evolutionary process. Some archivers have been studied previously [
19,
22,
23,
24,
25,
26]. In this paper, we address the problem of discretization of the potentially useful alternatives. For this purpose, we compare different archiving strategies that aim to obtain the set of potentially useful nearly optimal solutions. An archiving strategy must take into account the decision space to ensure that the potentially useful nearly optimal solutions are not discarded.
For the comparison of the results in this real problem, we have chosen to embed the archiver in a basic evolutionary algorithm. First, to observe the impact of each archiver when incorporated into an evolutionary mechanism. In addition, second, because the computational cost associated with the objective functions of the real problem does not allow simulations on large numbers of points. Therefore, it is not feasible to test each archiver with a random or exhaustive search as has been done with the benchmarks.
These archivers have not been compared in the literature, so this work is useful for future designs of evolutionary algorithms that consider nearly optimal solutions or even to modify the archivers of the old evolutionary algorithms considering such solutions. Therefore, the purpose of the paper is: (1) to understand the properties of these archivers, (2) to provide an analysis for choosing one of these archivers and (3) to give ideas for designing new archivers. The design of these algorithms are currently open issues in this research area [
18,
20,
27].
This work is structured as follows. In
Section 2, a small state of the art on potentially useful nearly optimal solutions is introduced. In
Section 3 some basic multi-objective backgrounds are presented. In
Section 4, different archiving strategies to characterize the optimal and nearly optimal set are described. In
Section 5 the MOOPs and the archivers comparison procedure are presented. The results obtained on the archivers are shown in
Section 6. Finally, the conclusions are given in
Section 7.
2. State of the Art
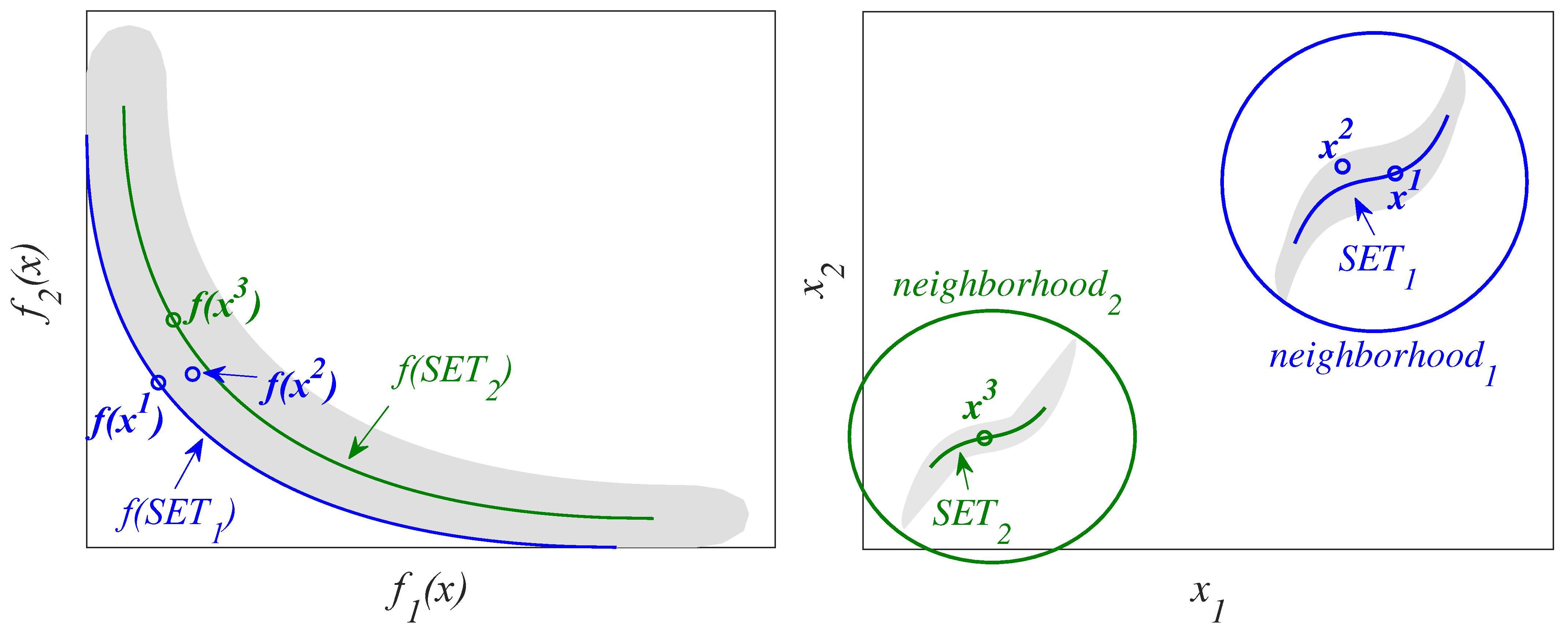
As discussed in the previous section, obtaining all nearly optimal solutions leads to problems. Considering only the most relevant solutions largely avoids the problems mentioned above. Not all nearly optimal solutions are equally useful to the DM. Therefore, if we manage to discard those that are less useful, we will reduce both mentioned problems. Let us see a graphic example to illustrate what we consider as potentially useful solutions. Suppose we have a MOOP with two design objectives and two decision variables (see
Figure 1). Three solutions
,
and
are selected.
is an optimal solution (member of the Pareto set), and it slightly dominates the nearly optimal solutions
and
.
and
are very similar alternatives in their parameters (both belong to
, the same area in the parameter space), while
is significantly different (it belongs to
). In this scenario,
does not provide new relevant information to the DM. This solution is similar to
but with a worse performance in design objectives. Predictably, both will have similar characteristics, therefore the DM will choose
since it obtains a better performance in the design objectives. However,
does provide useful new information to the DM because it has a similar performance to the optimal ones and is in a different neighborhood. The solutions in
could be, for example, not very robust or not feasible in practice. In this context,
(and the solutions in
) could be a potentially useful solution due to their significantly different characteristics. It is possible, and often common, for the DM to analyze in the decision stage additional indicators/objectives not included in the optimization phase. Thus, the DM can assume a small loss of performance in the design objectives in exchange for an improvement in a new feature not contemplated in the optimization process. This analysis can decide the final choice in one way or another. In short, including solutions of
increases the diversity with useful solutions and enables the DM to make a better-informed final decision.
Therefore, the potentially useful nearly optimal solutions are those nearly optimal alternatives that differ significantly in the parameter space [
28,
29,
30]. Thus, the new set must: (1) not neglect the diversity existing in the set of nearly optimal alternatives; (2) obtain the least number of solutions. To achieve both aims, it is necessary to employ an evolutionary algorithm that characterizes the set of solutions by means of a discretization which takes into account both the decision space and the objective space, simultaneously. A discretization that takes into account only the objective space can lead to the loss of significantly different nearly optimal alternatives in the decision space. This loss is a drawback because, as we have previously discussed, these alternatives are potentially useful. On the other hand, a discretization that takes into account only the decision space can lead to archives with a huge number of solutions [
19] and cause the two problems previously mentioned.
3. Background
A multi-objective optimization problem can be defined as follows:
where
is defined as a decision vector in the domain
and
:
is defined as the vector of objective functions
. A maximization problem can be converted into a minimization problem. For each objective to be maximized
will be performed. The domain
Q is defined by the set of constraints on
. For instance (but not limited to –any other constraints could be introduced in a general MOOP–):
where
and
are the lower and upper bounds of
components.
Consequently, the MOOP obtains a Pareto set (see Definition 2). This set has solutions non-dominated by any other solution (see Definition 1) in Q.
Definition 1 (Dominance [
31]).
A decision vector is dominated by another decision vector if for all and for at least one j, . This is denoted as . Definition 2.
(Pareto set ): is the set of solutions in Q that is non-dominated by any other solution in Q:
Definition 3.
(Pareto front ): given a set of Pareto optimal solutions , the Pareto front is defined as:
In any MOOP, there is a set of solutions with objective values close to the Pareto front. These solutions receive several names in the bibliography: nearly optimal, approximate, or -efficient solutions. To formalize the treatment of the nearly optimal solutions, the following definitions are used:
Definition 4.
(-dominance [32]): define as the maximum acceptable degradation. A decision vector is -dominated by another decision vector if for all and for at least one j, . This is denoted by . Definition 5.
(Set of nearly optimal solutions, [30]): is the set of solutions in Q which are not -dominated by another solution in Q: The sets defined and usually contain a great, or even infinite, number of solutions. Optimization algorithms try to characterize these sets using a discrete approximation and . In general, if such an approach has a limited set of solutions, the computational cost falls. However, the number of solutions must be sufficient to obtain a good characterization of these sets.
To compare the archiving strategies, it is useful to use a metric. Different metrics are used in the literature to measure the convergence of the outcome set. An example of these is the Hausdorff distance (
[
33,
34,
35] see Equation (
3)).
This metric is a measure of the distance between two sets. Therefore, can be used to measure convergence between the outcome set (or final archive) to the target set of a given MOOP (or archiving strategy). However, only penalizes the largest outlier of the candidate set. Thus, a high value of can indicate both that A is a bad approximation of H and that A is a good approximation but contains at least one outlier. The is used by the archiver .
To avoid this problem, a new indicator appears in the literature: the averaged Hausdorff distance
(the standard Hausdorff distance is recoverable from
by taking the limit
). This metric (with
) assigns a lower value to sets uniformly distributed throughout its domain.
is based on the known generational distance metrics (GD [
36] and represents how “far”
is from
), and inverted generational distance (IGD [
37] represents how “far”
is from
). However, these metrics are slightly modified in
(
and
, see Equation (
5)). This modification means that the larger archive sizes and finer discretizations of the target set do not automatically lead to better approximations under
[
34].
measures the diversity and convergence in the decision and objective spaces. In this work we use
with
(as in [
18,
38]) so that the influence of outliers is low.
where
where
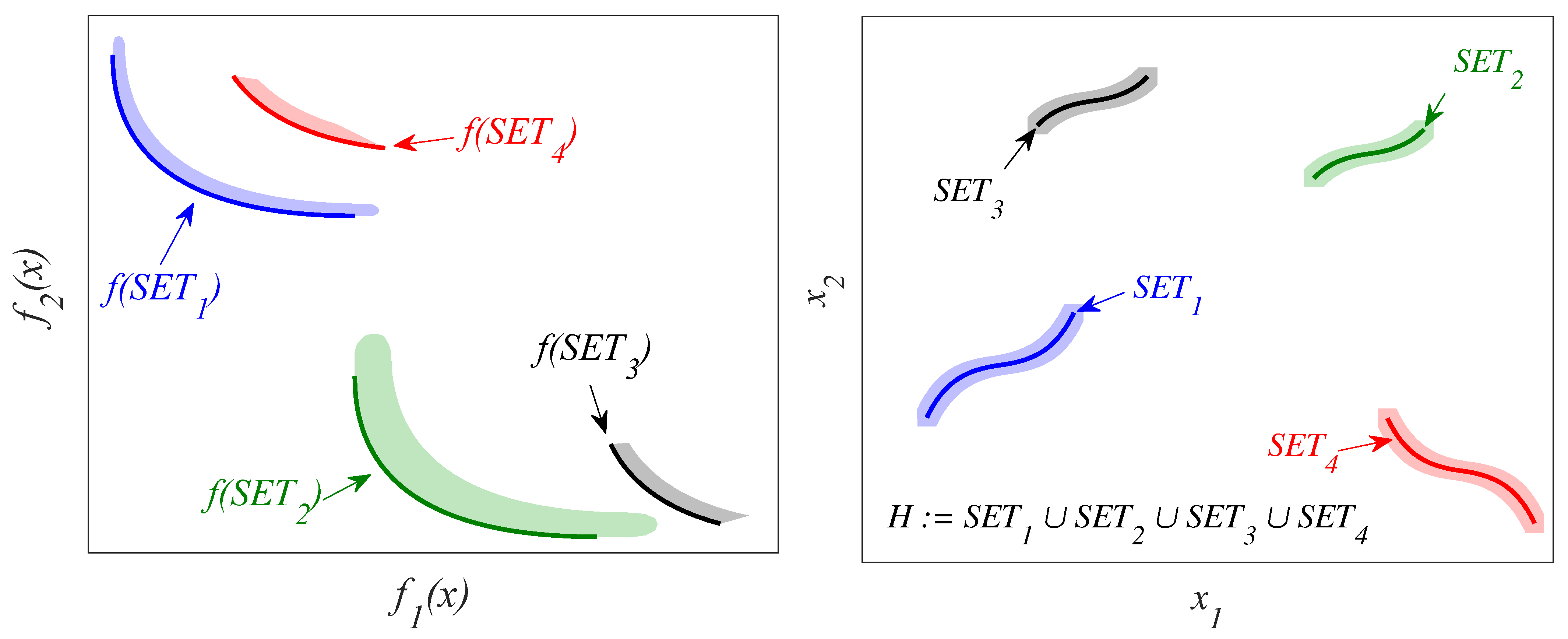
To use it is necessary to define the target set H with which to compare the final archive A obtained by the archivers. The target set is defined in the decision space (H) and it has its representation in the objective space (). The definition of H is possible on the benchmarks used in this work (where the global and local optimum are known), but this definition is not trivial. and archivers discard solutions similar in both spaces at the same time. However, - , unlike , discards dominated solutions in their neighborhood. looks for diversity in both spaces simultaneously. On the one hand, defining H as the optimal and nearly optimal solutions that are not similar in both spaces at the same time, would give the archive an advantage. If H is defined as the set of optimal and nearly optimal solutions non-dominated in their neighborhood, would be benefited. However, the archivers have a common goal: to obtain the solutions close to the optimals in the objective space but significantly different in the decision space (potentially useful solutions). Consequently, to be as “fair” as possible we must define H as the set that defines the common objective. Thus, the potentially useful solutions can be represented by the local Pareto set (see Definition 6).
Definition 6.
(Local Pareto set [5,39]): is the set of solutions in Q that is non-dominated by any another neighbor solution in Q (where n is a small positive number): Figure 2 shows an example of a MOOP with two design objectives and two decision variables. Sets
and
form the global Pareto set. Both sets, together with
and
form the local Pareto set (since the global Pareto set is also a local Pareto set). No solution of a local Pareto set is dominated by a neighboring solution. Furthermore, all the solutions neighboring the local Pareto set are dominated by a neighboring solution, and therefore they are not part of this set. This can be verified by the colored areas around the sets
,
,
and
. For example, solutions in the gray area, which are neighboring solutions to
, obtain a worse objective value than
. For this reason, the solutions of the gray area are dominated by neighboring solutions, and therefore are not part of the local Pareto set. Sets
and
provide the DM with alternatives potentially useful (significantly different to
and
), enabling the DM to make a more informed final decision. For this work, the
dominated solutions (solutions that are not in the set
) will not be considered to be local Pareto solutions (
H) because their degradation in performance is significant for the DM.
4. Description of the Compared Archivers
As already discussed above, nearly optimal solutions can be very useful. However, it is necessary to discretize this set in order to find a reduced set of solutions to avoid the problems associated with an excessive number of solutions. Furthermore, it is necessary not to neglect the potentially useful nearly optimal solutions, i.e., nearly optimal alternatives significantly different (in the decision space) to the optimal solutions. To achieve both purposes, it is essential to discretize the set of solutions taking into account the decision and objective spaces at the same time. In this section, three archivers that discretize the set in both spaces are described.
There are MMEAs and algorithms that consider nearly optimal solutions that offer these solutions:
-NSGA-II [
28],
-MOEA [
30], nevMOGA [
29], N
SGA [
18], DIOP [
10], 4D-Miner [
40,
41], MNCA [
42].
-NSGA-II [
28] was one of the first algorithms aimed at finding approximate (nearly optimal) solutions.
-NSGA-II uses the same classification strategy as the algorithm on which it is based, NSGA-II [
43], and therefore, the highest pressure of the population is taken toward the Pareto set. Thus, this may result in the neighborhoods with only nearly optimal solutions not being adequately explored [
30]. To avoid this problem, the algorithm
-MOEA [
30] is created. This algorithm was designed to avoid Pareto set bias. Nevertheless,
-MOEA does not take into account the location of solutions in the decision space.
-MOEA does not then guarantee that the potentially useful alternatives will not be discarded. To overcome this problem, the nevMOGA [
29] algorithm was designed. This algorithm seeks to ensure that the potentially useful alternatives are not discarded. DIOP [
10] is a set-based algorithm that can maintain dominated solutions. This algorithm simultaneously evolves two populations A and T. Population A approaches the Pareto front, and is not provided to the DM, while T is the target population that seeks to maximize diversity in the decision and objective spaces. MNCA [
42] is an evolutive algorithm that simultaneously evolves multiple subpopulations. In MNCA each subpopulation converges to a different set of non-dominated solutions. Finally, 4D-Miner [
40,
41] is an algorithm especially designed for functional brain imaging problems.
One of the crucial points in an evolutionary multi-objective optimization algorithm is the archiving strategy. The
-NSGA-II and
-MOEA algorithms share the
archiver. This archiver seeks to characterize all nearly optimal solutions without taking into account the decision space. In [
19], different archiving strategies are compared:
,
,
and
. On the one hand,
gets an excessive number of solutions. On the other hand,
,
do not discretize the decision and objective spaces simultaneously. Therefore, these archivers do not achieve the two purposes discussed above. The mentioned work concludes that archiver
is most practical use within stochastic search algorithms. Furthermore, this archiver is the only one of the archivers compared in this paper that discretizes the decision and objective spaces simultaneously [
27], a factor that we consider necessary to obtain potentially useful solutions. The archiver
has been employed in the recent N
SGA algorithm to maintain a well-distributed representation in the decision and objective spaces. For this reason, the present work compares the archiver
and not
,
and
.
The second archiver included in this comparison is the archiver of the nevMOGA algorithm (). This archiver characterizes the set of potentially useful solutions by discretizing both spaces simultaneously. Finally, the archiver of the DIOP algorithm () is also compared in this work. seeks to find the population that maximizes an indicator that measures diversity in the decision and objective spaces simultaneously. Therefore, a metric-based archiver is compared to the distance-based archivers and . The three archivers compared in this work seek to characterize the potentially useful solutions. The archiver of the MNCA algorithm has not been included in the comparison because it looks for non-dominated solutions. The archiver of the 4D-Miner algorithm has also not been included in the comparison because 4D-Miner is a very specific algorithm for functional brain imaging problems.
4.1.
is the proposed archiving strategy in [
19] (see Algorithm 1). As already mentioned, potentially useful solutions are those that obtain similar performance (in the design objectives) but differ significantly in their parameters (in the decision space). This archiver aims to maintain these solutions. This archiver uses, in addition to the parameter
(maximum degradation acceptable to the DM, see Definition 4), the parameters
and
. Two solutions are considered similar if their distance in the decision space is less than
. Therefore, the parameter
is the maximum distance, in the decision space, between two similar solutions. Two alternative solutions obtain a similar performance if their distance in the objective space is less than
. Therefore, the parameter
is the maximum distance between two solutions to be considered similar in the objectives space. Both parameters are measured using the Hausdorff distance [
34] (
, see Equation (
3)). The archive
A stores the set of obtained alternatives. A new solution
p from
P (new candidate solutions) will only be incorporated in
A if: (1)
p is a nearly optimal solution; and (2)
A does not contain any solution similar to
p, in the decision and objective spaces at the same time. If the new solution
p is stored in archive
A, the new set of optimal and nearly optimal solutions (
) belonging to archive
A is calculated. Thus, a solution
will be removed if: (1) it is not a nearly optimal solution (
); and (2) the distance to the set
fulfills the condition
.
| Algorithm 1 |
| Require: population P, archive |
| Ensure: update archive A |
- 1:
- 2:
for alldo - 3:
if and and then - 4:
- 5:
- 6:
for all \ do - 7:
if and then - 8:
\ {a} - 9:
end if - 10:
end if - 11:
end if - 12:
end if
|
The archiver
goes through all the set of candidate solutions
, and in the worst case, the algorithm compares them with all the solutions
. Thus, the complexity of the archiver is
[
44]. Also,
has a maximum number of solutions
[
19] which is given by:
where
is the maximum number of neighborhoods that the decision space can contain (based on
) and
is the maximum number of solutions that can exist in each neighborhood (based on
and
), and are defined as:
and
are the bounds in the decision space (
is included in
) and
and
are the bounds in the objective space of the set to discretize
. Also, it is assumed that any
is greater than
.
4.2.
is the archiving strategy used by the nevMOGA evolutionary algorithm [
29]. This archiver, just as
, aims to guarantee solutions that obtain similar performance to the optimals, but are significantly different in the decision space. The archiver
uses the same three parameters as
(
,
,
). However, there are differences in the definition of some parameters in this archiver with respect to
: (1)
is a vector that contains the maximum distances (in the decision space) between similar solutions for each dimension. Thus, two individuals
a and
b are similar if:
. (2)
is also a vector that contains the maximum distances (in the objective space) between solutions with similar performance for each dimension. Thus, two individuals
a and
b have a similar performance if:
.
The archiver will add a new candidate solution p to the archive A if the following conditions are met simultaneously: (1) p is a nearly optimal solution; (2) there is no similar solution to p (in the decision space) that dominates it; and (3) there is no similar solution to p in A in both spaces at the same time (if it exists, and p dominates it, it will be replaced). If a solution p is incorporated in the archive A, it will remove from A: (1) the similar individuals (in the parameter space) that are dominated by p and (2) the individuals dominated by p.
The complexity of the archiver
is equivalent to the complexity of
previously defined (
). Moreover,
has a maximum number of solutions
which is given by:
where
is the maximum number of neighborhoods that the decision space can contain (based on
) and
is the maximum number of solutions that can exist in each neighborhood (based on
and
), and are defined as:
where
,
and
and
are the bounds in the objective space of the set to discretize
.
The archive size with respect to the decision space is equivalent for the compared archivers ( and ). However, there is a difference between and (objective space). The archiver , unlike , discards nearly optimal solutions dominated by a similar solution in the decision space. Thus, in the worst case, will obtain the best solutions (non-dominated) in each neighborhood. These solutions will have a maximum number of alternatives depending on . However, , in the worst case, will obtain, in each neighborhood, in addition to the best solutions, additional solutions. These additional solutions are dominated by neighboring solutions, but are considered solutions with different performance (based on ). As a result, the archive of will have fewer solutions than the archive of . Therefore, we can deduce that the archiver has a lower computational cost than because its archive contains fewer solutions (the candidate solutions are compared with a smaller number of solutions).
4.3.
is the archiving strategy used by the DIOP evolutionary algorithm [
10]. This archiver seeks to obtain a diverse set of solutions (keeping solutions close to the Pareto set) in the decision and objective spaces.
has as inputs: an approximation to the Pareto front
F, the set of solutions to be analyzed
T, the size of the set target
, and
. This archiver selects
solutions from set
T. The goal is to find the population
A, with size
, to maximize
(see Equation (
13)).
is defined as the sum of the product between a metric and its respective weight.
where
and
are metrics that measure diversity in the objective and decision spaces respectively, and
is a distance metric defined as:
is an indicator that measures diversity and convergence to the Pareto front, and
is an indicator that measures diversity in the decision space. In this work, as in [
10],
and
were specified by the hypervolume indicator [
45] and the Solow–Polasky diversity measure [
46], respectively. An advantage of the archiver
is that you can directly and arbitrarily specify the archive size.
6. Results and Discussion
This section shows the results obtained on the two benchmarks and the real example previously introduced.
6.1. Benchmark 1 with Uniform Dispersion
The archivers are tested on 25 different input populations obtained by uniform dispersion.
Figure 7 shows the median results of archive
A on the benchmark 1 for both decision and objective spaces with respect to
in decision space. As can be seen, the archivers make a good approximation to the target set
H, characterizing the nine neighborhoods that compose it. However, there are differences between the sets found by the archivers. First, the
archiver obtains fewer solutions. The number of solutions
for the
is user-defined, but a smaller size makes
worse for both spaces. The archive
A obtained by
obtains a larger number of solutions.
The archiver obtains a better approximation to the Pareto front than the other archivers. This is because the weight has a high value, giving greater weight to the indicator that measures convergence and diversity for the Pareto front. The and archivers do not select a candidate solution p (even if p belongs to the Pareto set) if an alternative already exists in the current archive that is similar in both spaces (in , p is selected if it dominates the similar solution). These archivers could obtain a better approximation to the Pareto front by reducing the parameter (parameter with which the degree of similarity in the objective space is decided), but it probably also implies obtaining a greater number of solutions.
Regarding the local Pareto set, the archive obtains a better approximation in the comparison. and obtain solutions in all neighborhoods where nearly optimal solutions exist. However, these solutions are rarely located on the lines that define the local Pareto set.
Notice that and archivers obtain dominated solutions. In , it is possible that a solution in A that is no longer nearly optimal due to the apparition of a new candidate solution p. p may not be removed because it does not satisfy condition in the line 7 of Algorithm 1. In , a new candidate solution p can be added to the archive A through the condition of line 8 of Algorithm 3. In some cases, solutions that are not nearly optimal due to the appearance of p (by line 8 of Algorithm 3) are not eliminated. Therefore, the archive A obtained by both archivers may contain solutions that do not belong to the nearly optimal set.
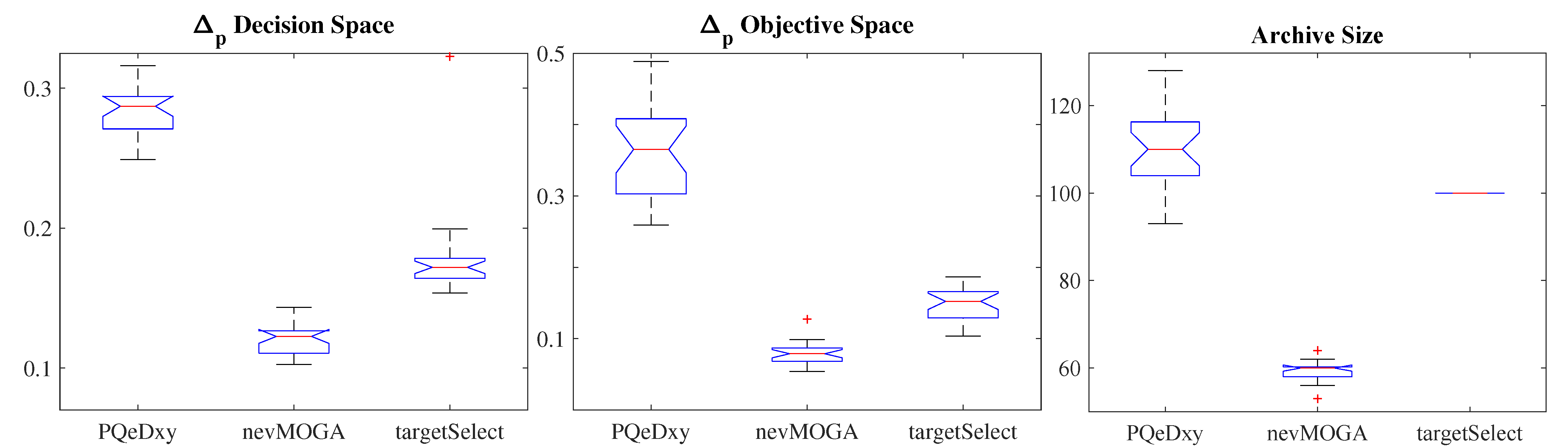
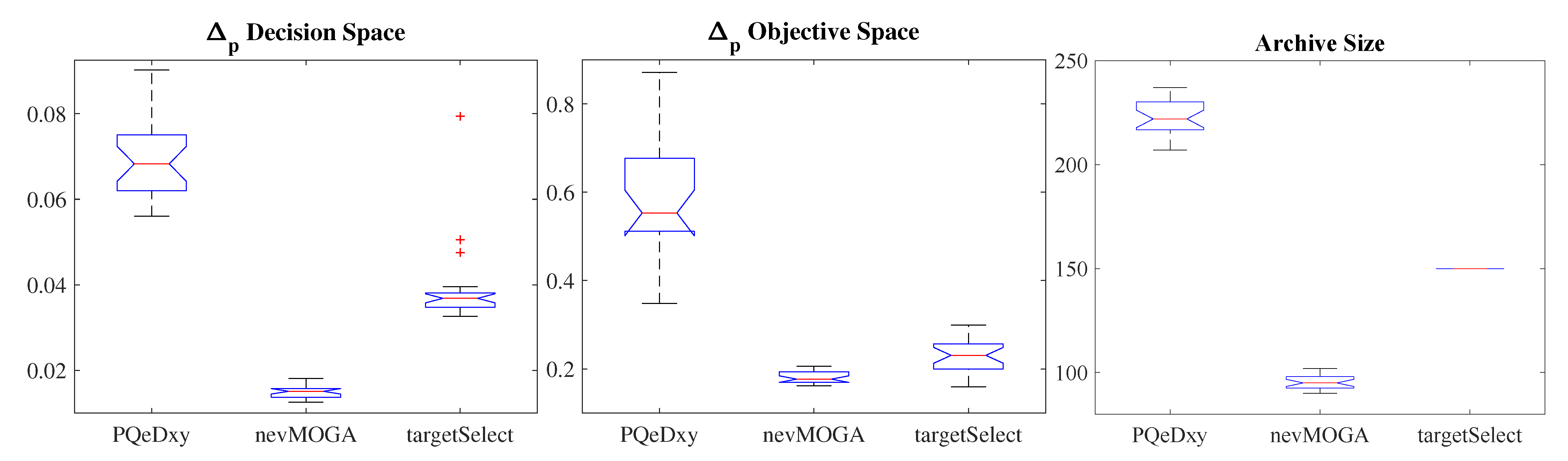
Figure 8 shows the boxplot of the indicators
,
and archive size for the 25 tests performed.
achieves a better approximation in the decision and objective spaces, and obtains fewer solutions.
also obtains a better approximation in both spaces with fewer solutions than
.
obtains greater variability among the 25 archives obtained. Therefore,
has achieved, in a better way, the two main objectives: not neglecting the diversity of solutions (locates all nine neighborhoods) and obtains a reduced number of solutions (simplifying the optimization and decision stages).
| Algorithm 3 |
| Require: population P, archive |
| Ensure: update archive A |
- 1:
- 2:
for alldo - 3:
if and and and and then - 4:
- 5:
if or and then - 6:
\ - 7:
end if - 8:
else if and and then - 9:
- 10:
end if - 11:
end if
|
6.2. Benchmark 1 with Random Dispersion
The archivers are tested on 25 different input populations obtained by random dispersion.
Figure 9 shows the archive
A, with median result for
. The archivers characterize the nine neighborhoods that form the target set
H. The archive
A obtained by
has a smaller number of solutions. Decreasing the number of solutions
for the archive
makes
worse in both spaces. Comparing
Figure 7 and
Figure 9,
in random dispersion produces a worse approximation of the Pareto front than in uniform search. This is for two reasons: (1) the lower value of the weight
(lower weight of the metric
, which measures convergence in Pareto front); (2) the initial population has been obtained in a random way (meaning certain areas have not been adequately explored).
Figure 10 shows the boxplot, of the 25 archives obtained in the tests.
obtains better results in both spaces, also obtaining a smaller number of solutions. On the benchmark 1, the approximations obtained by the archivers in a random dispersion are slightly worse than in a uniform dispersion.
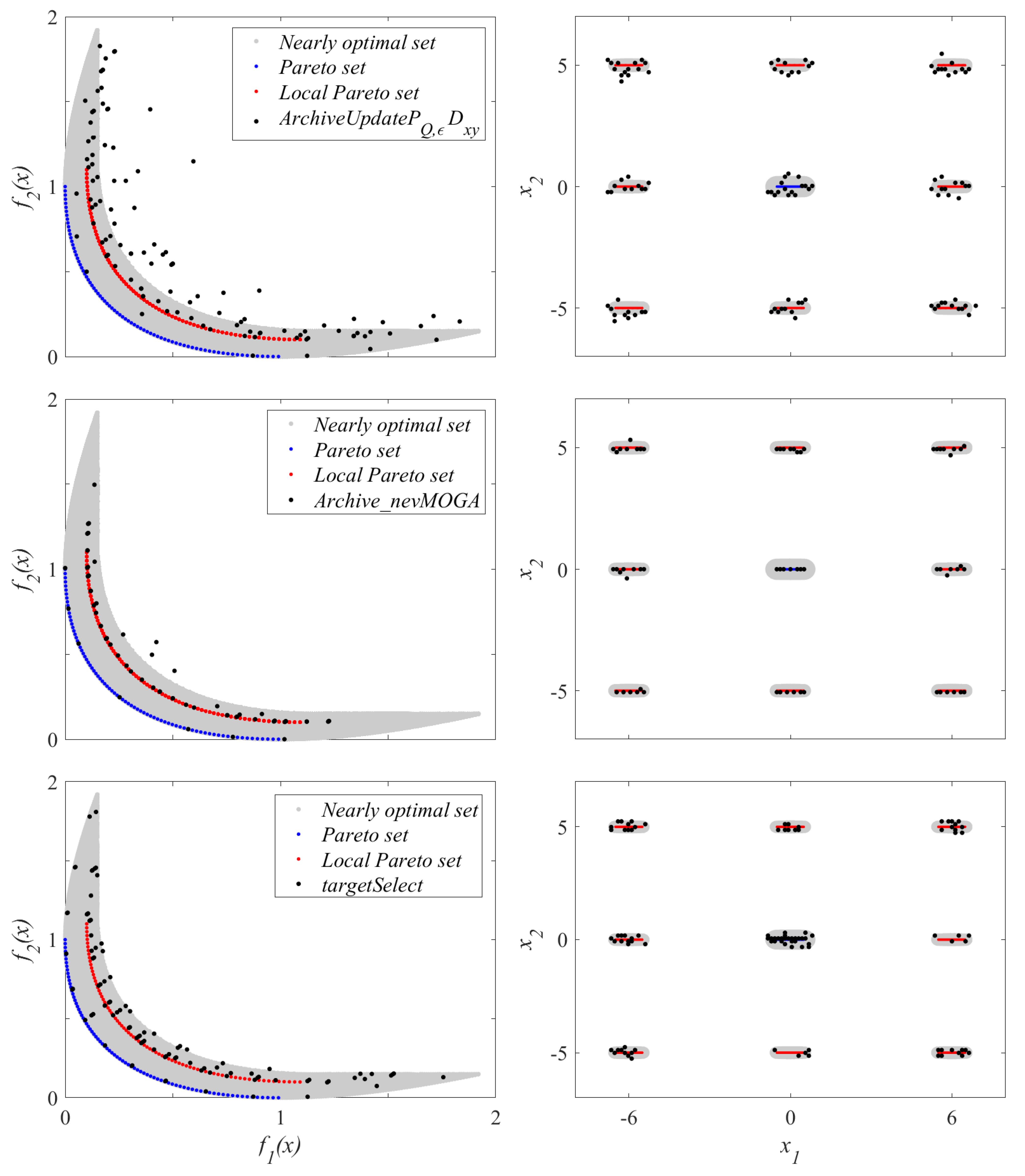
6.3. Benchmark 2 with Uniform Dispersion
The archive
A, with the median result (in the decision space), for each archiver is shown in
Figure 11. The archivers locate the neighborhoods where nearly optimal solutions are found. The archive of
again obtains fewer solutions. Keep in mind that decreasing
for
causes a considerable increase in the variability of the results obtained
for the 25 tests.
obtains a better approximation to the Pareto front due to the high value of the weight
. However,
obtains solutions closer to the local Pareto set. This is because
seeks to achieve the greatest diversity in the decision space (through
) without taking into account whether these solutions are worse than a close solution (if they are not optimal).
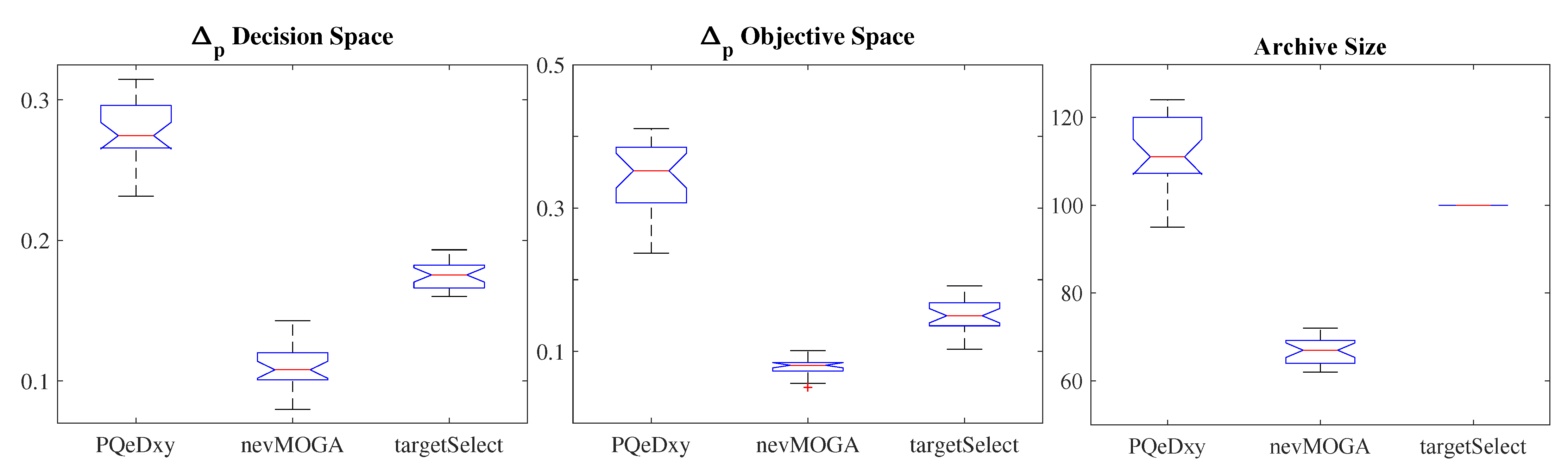
Figure 12 shows the boxplot, of the 25 archives obtained for the archivers, for the indicator
in the decision and objective spaces and the archive size. Regarding the decision space,
obtains a better approximation to the target set than its competitors. Regarding the objective space,
and
obtain a similar minimum value. However,
obtains worse variability. Therefore, as occurred with benchmark 1, the archiver
achieves a better approximation in both spaces and obtains a smaller number of solutions.
6.4. Benchmark 2 with Random Dispersion
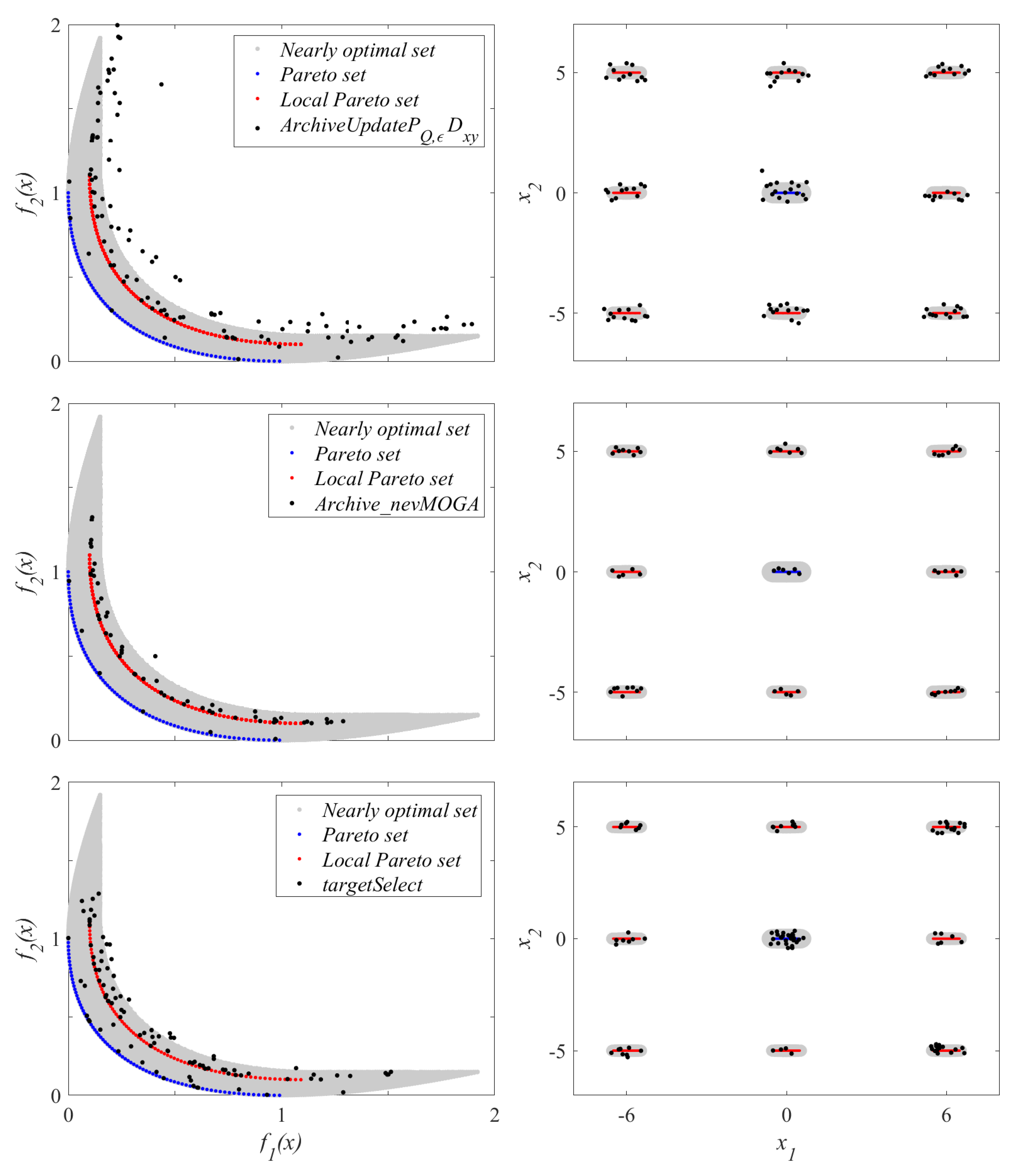
Figure 13 shows the archive
A, which obtains a median result for
for the archivers. Again, the archiver
obtains significantly fewer solutions while also obtaining a better characterization of the target set
H.
Figure 14 shows the boxplot of the archivers. The archiver
obtains a better value of
in both spaces. Regarding the objective space,
obtains results similar to
but worse variability. The archiver
obtains fewer solutions, which simplifies the optimization and decision stages. Using the random search,
and
perform slightly worse than the uniform search.
obtains slightly better results than the uniform search.
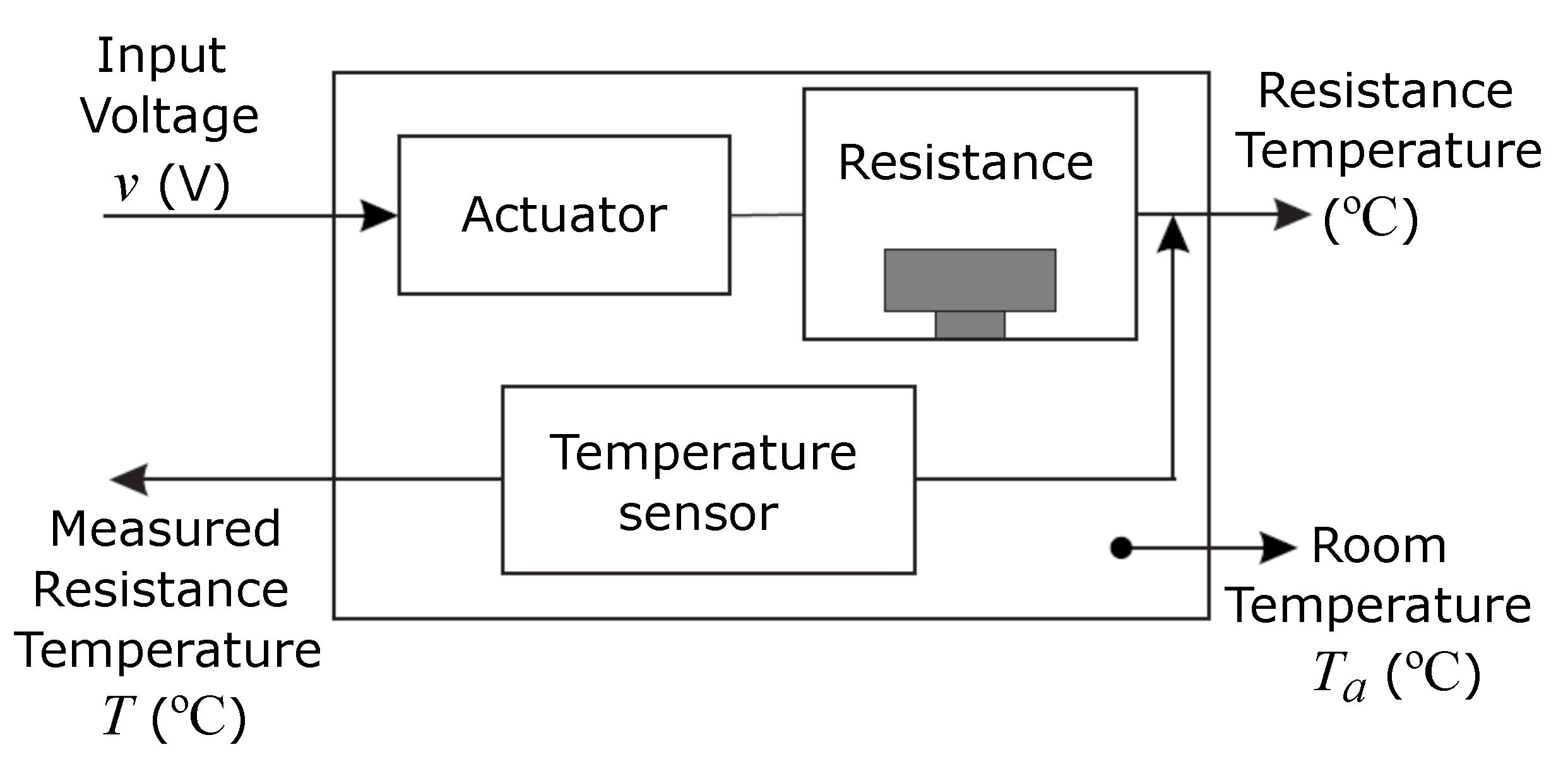
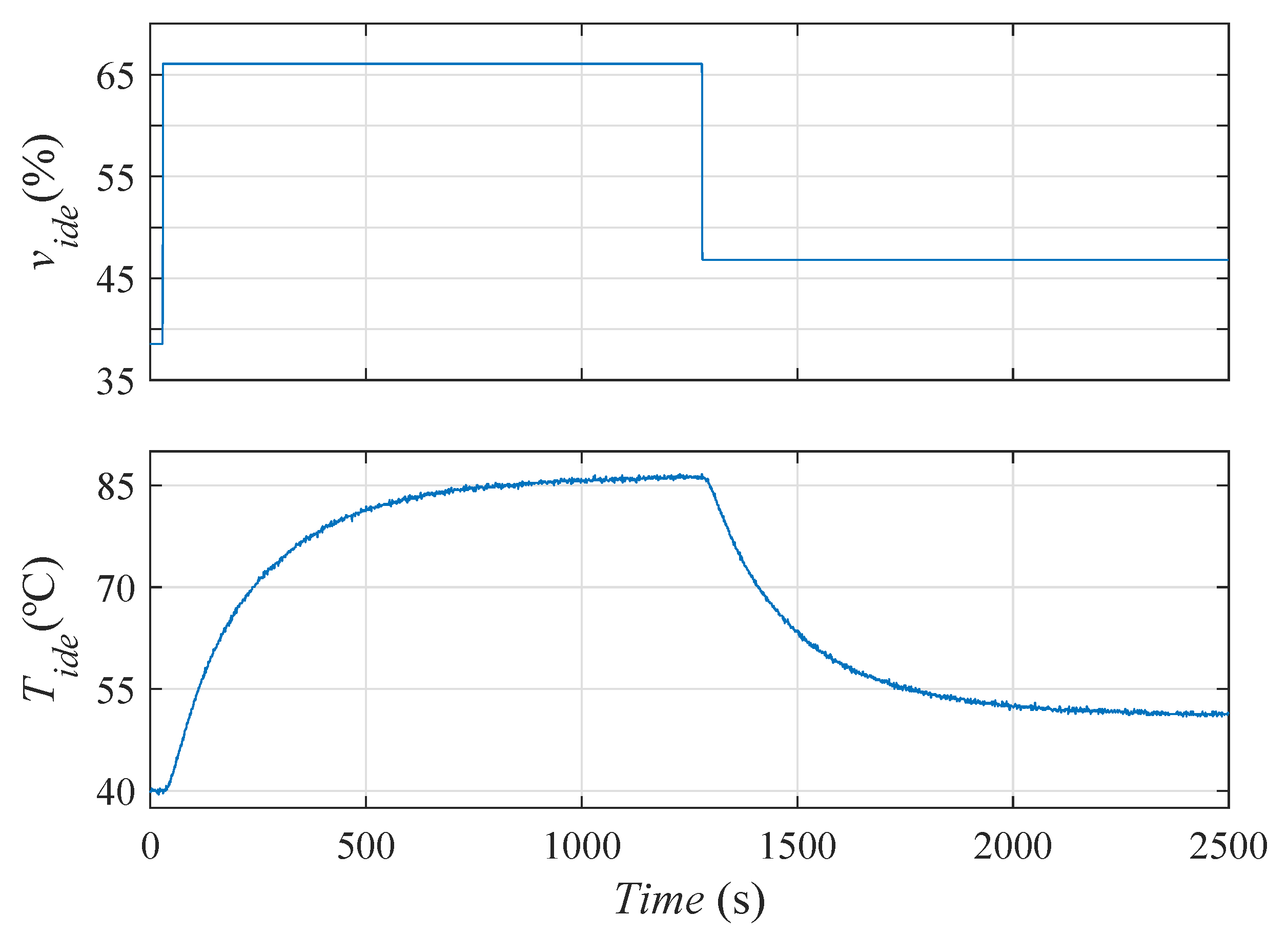
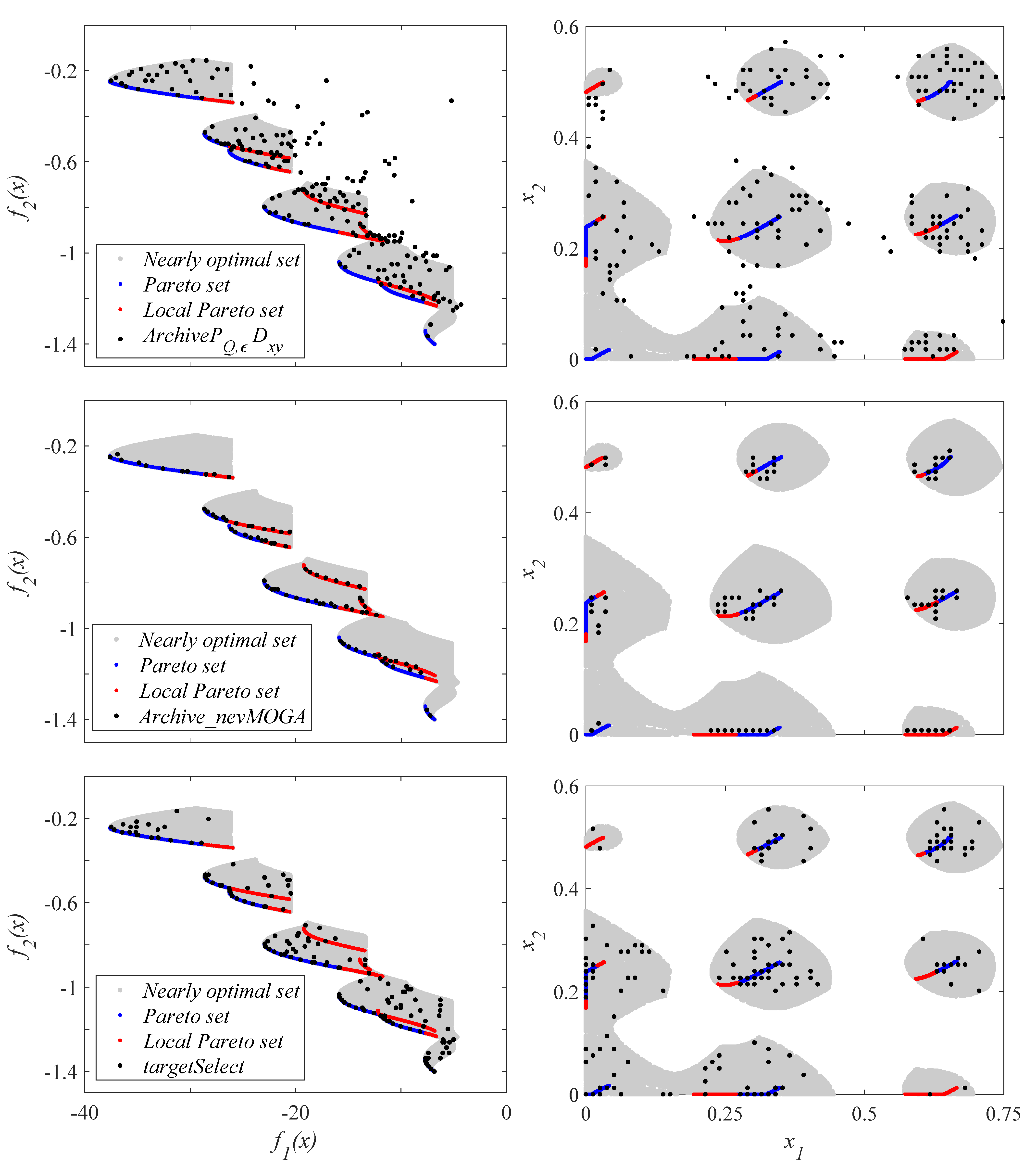
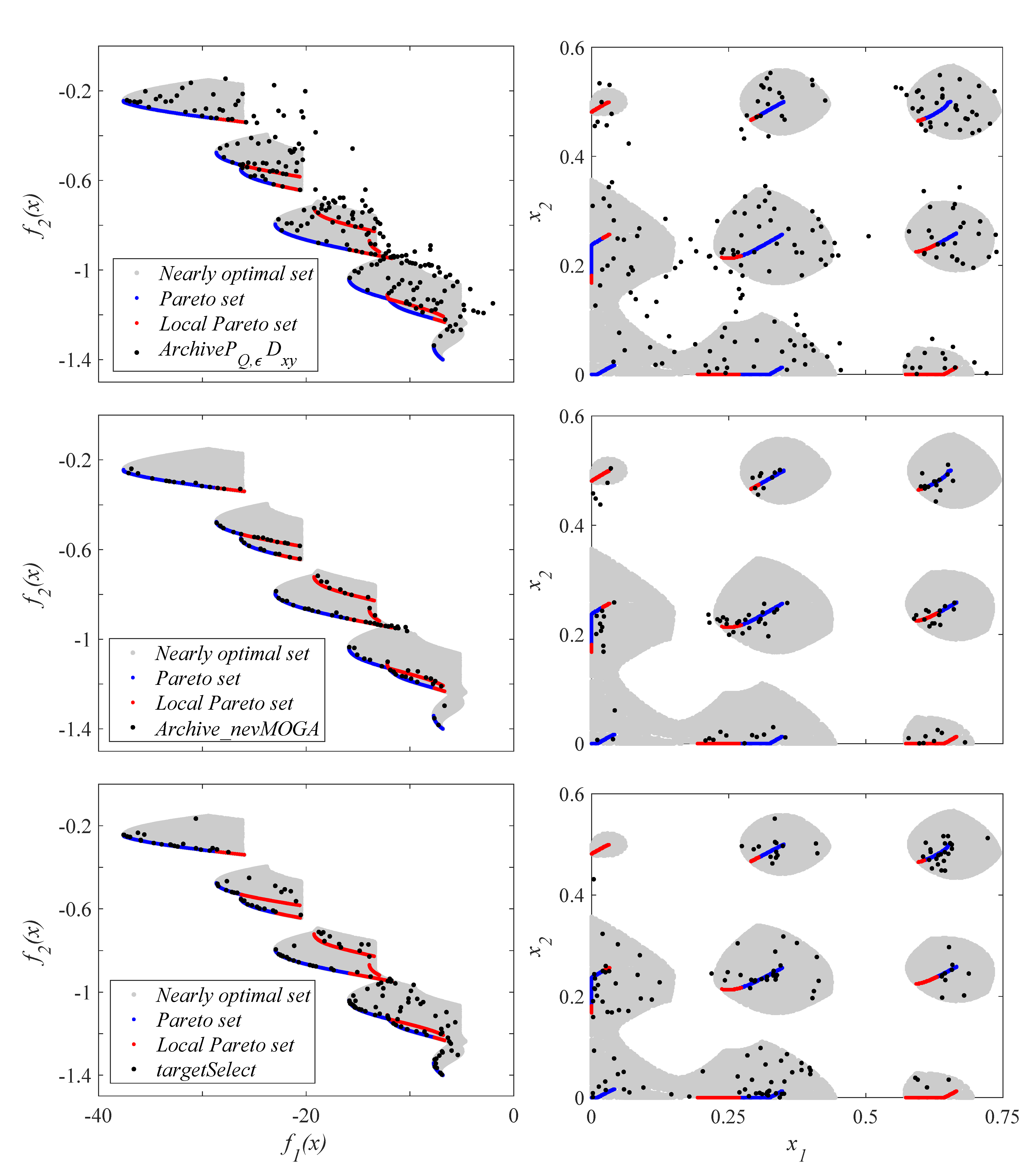
6.5. Identification of a Thermal System
Figure 15 shows the final archive
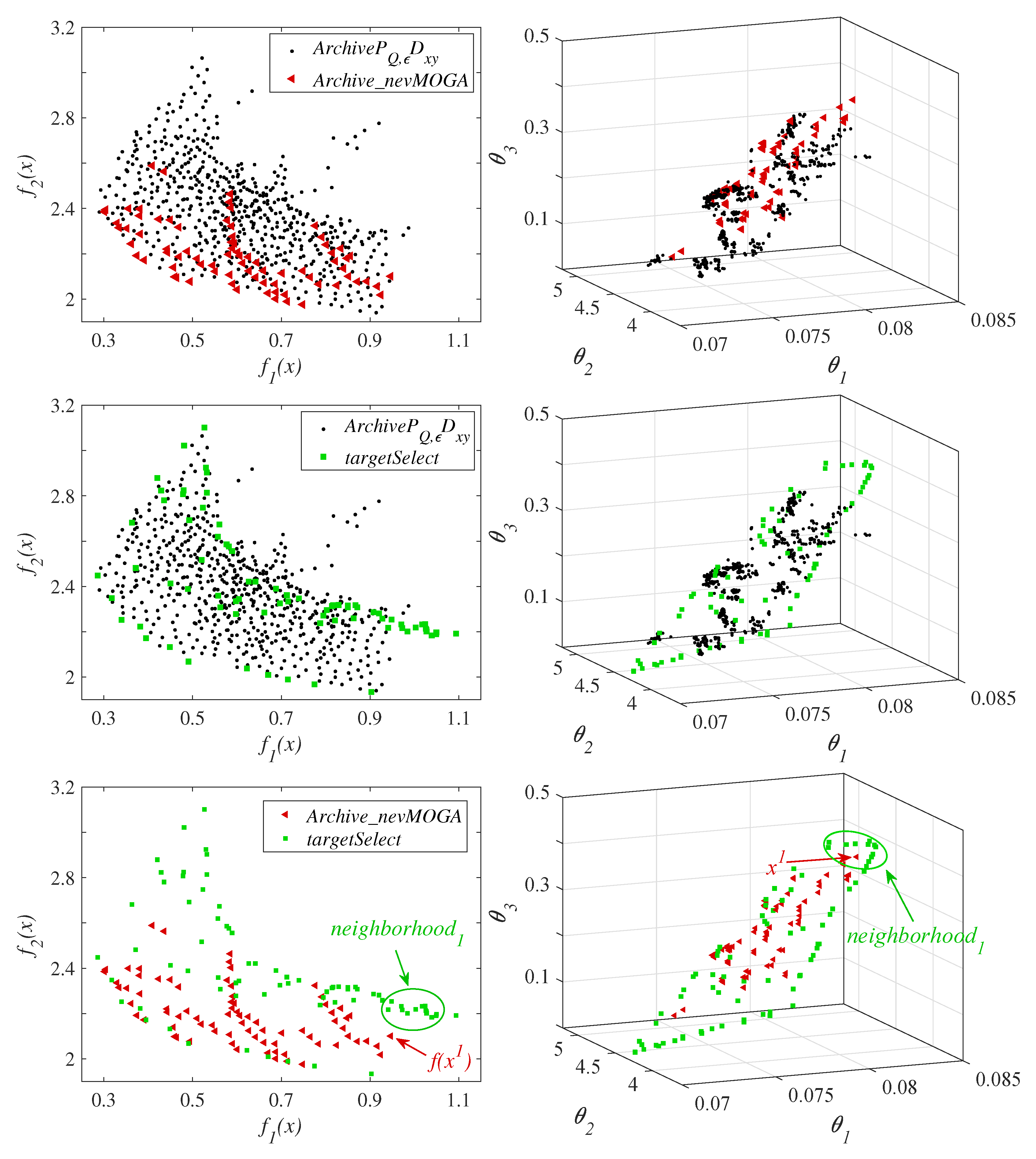
A obtained when using the three archivers inside a compared basic optimization algorithm. In this example, the obtained archives are compared by pairs to better observe the differences between them.
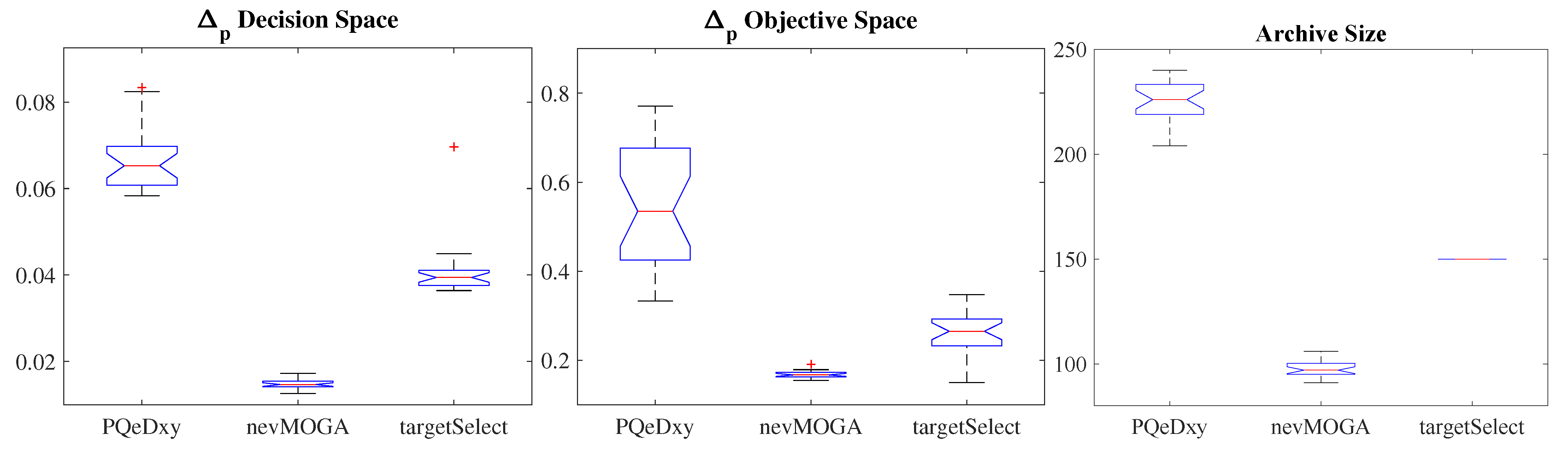
The three archivers obtain diversity in the decision space, and convergence in the Pareto front. The first thing that stands out is the large number of solutions (610 solutions) obtained by the archive . This high number of solutions complicates the optimization and decision phases. For each iteration, the newly generated solutions must be compared with the solutions in the current file . Therefore, many solutions in the file implies a higher computational cost. In addition, a high number of solutions makes the final decision of the DM more difficult. This large number of solutions can be reduced by increasing the parameters and . However, this increase also implies a worse discretization in both spaces. obtains a worse approximation to the Pareto front.
The results show more similarities with respect to the other two archivers. Archiver obtains 78 solutions. To compare under similar conditions, we set the size of the file obtained by to 78 solutions (). In this way, both archivers obtain the same number of solutions. The set of solutions found by both archivers are different. With respect to the Pareto front, both archivers achieve a good approximation in the range . However, does not get solutions in the range of the Pareto front. Therefore, in this example, gets a little more diversity in the Pareto front.
focuses on obtaining, in addition to a good convergence in the Pareto front, the greatest diversity in the decision space (using
, see
Section 4.3). However, solutions that provide greater diversity may be worse than neighboring solutions. For example,
Figure 15 shows the solution
obtained by
. This solution has similar parameters to the
solutions (see decision space).
performs better (
) than all the
solutions obtained by
. Therefore,
would eliminate all these solutions (dominated in its neighborhood by
).
maintains them because they increase the diversity in the decision space. This happens repeatedly in this MOOP. For this reason,
obtains nearly optimal solutions farther from the Pareto front than obtained by
. These solutions are in the contour/ends of the plane that form the optimal and nearly optimal solutions in the decision space, and therefore, they obtain a better diversity under the
indicator.
could find solutions closer to the contour/ends of the plane formed in the decision space (as is the case with
) by reducing the parameter
, although this would imply obtaining a larger number of solutions. Therefore, depending on the needs or preferences of the DM, the use of one archiver or another may be more appropriate. This archiver can be embedded in most of the multi-objective algorithms available.
,
and
archivers are currently built into the algorithms N
SGA,
and
respectively.
7. Conclusions
In this paper, the characterization of nearly optimal solutions potentially useful in a MOOP has been addressed. In this type of problem, in practice, the DM may wish to obtain nearly optimal solutions, since they can play a relevant role in the decision-making stage. However, an adequate approximation to this set is necessary to avoid an excessive number of alternatives that could hinder the optimization and decision-making stages. Not all nearly optimal solutions provide the same useful information to the DM. To reduce the number of solutions to be analyzed, we consider potentially useful solutions (in addition to the optimals) that are close to the optimals in objective space—but which differ significantly in the decision space. To adequately characterize this set, it is necessary to discretize the nearly optimal solutions by analyzing the decision and objective spaces simultaneously.
This article compares different archiving strategies that perform this task:
-
,
and
. The main objective of the archivers is to obtain potentially useful solutions. This analysis is of great help to designers of evolutionary algorithms who wish to obtain such solutions. In this way, designers will have more information to choose their archivers based on their preferences.
and
are two distance-based archivers. Both archivers simultaneously discard solutions that are similar in decision and objective spaces. However,
, in contrast to
, discards solutions dominated by a neighboring solution in the decision space.
is an archive based on an indicator that measures the diversity in both spaces simultaneously.
, unlike the other archivers, can directly and arbitrarily specify the archive size. This can be an advantage. The archivers are evaluated using two benchmarks. They obtain a good approximation to the set of potentially useful solutions, characterizing the diversity existing in the set of nearly optimal solutions. As discussed in [
19], the
archiver is more practical than other archivers in the literature. However, this archiver, as demonstrated in this paper, obtains significantly more solutions than its competitors in this paper. This can make the optimization and decision phase more difficult. In addition,
obtains a better approximation to the target set
H under the averaged Hausdorff distance
. In addition,
obtains a smaller number of solutions, which speeds up the optimization process and facilitates the decision-making stage. However, fewer solutions can also decrease diversity (which can lead to degraded global search capabilities).
Finally, the compared archivers are analyzed on a real engineering example. This real example is the identification of a thermal system. To carry out this analysis, a generic multi-objective optimization algorithm is used, in which it is possible to select different archivers. This enables a more realistic comparison of the impact of the archivers on the entire optimization process.
The three archivers obtain the existing diversity in the set of optimal and nearly optimal solutions. In this last example, we can see how the archive obtained by obtains a very high number of solutions, complicating the optimization and decision stages. and obtain the same number of solutions. Both archivers obtain an adequate Pareto front. However, gets more diversity on the Pareto front. The main difference between the two archivers is in the set of nearly optimal solutions. On the one hand, obtains solutions closer to the Pareto front, but significantly different in the decision space. On the other hand, obtains the solutions that provide the greatest diversity in the decision space, even though these solutions are farther away from the Pareto front, and therefore, offer significantly worse performance.
Finally, this analysis suggests two possible future lines of research: (1) design of new evolutionary algorithms, which characterize the nearly optimal solutions, using some of the archivers compared in this work and (2) design of new archivers that improve the current ones. For example, the clustering techniques could improve the archivers compared in this work. These techniques, not analyzed in this work, allow the location of new neighborhoods, allowing their exploration and evaluation. In this way, the optimization process could be improved.




















{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}