
Uncertainty Ordinal Multi-Instance Learning for Breast Cancer Diagnosis


Abstract
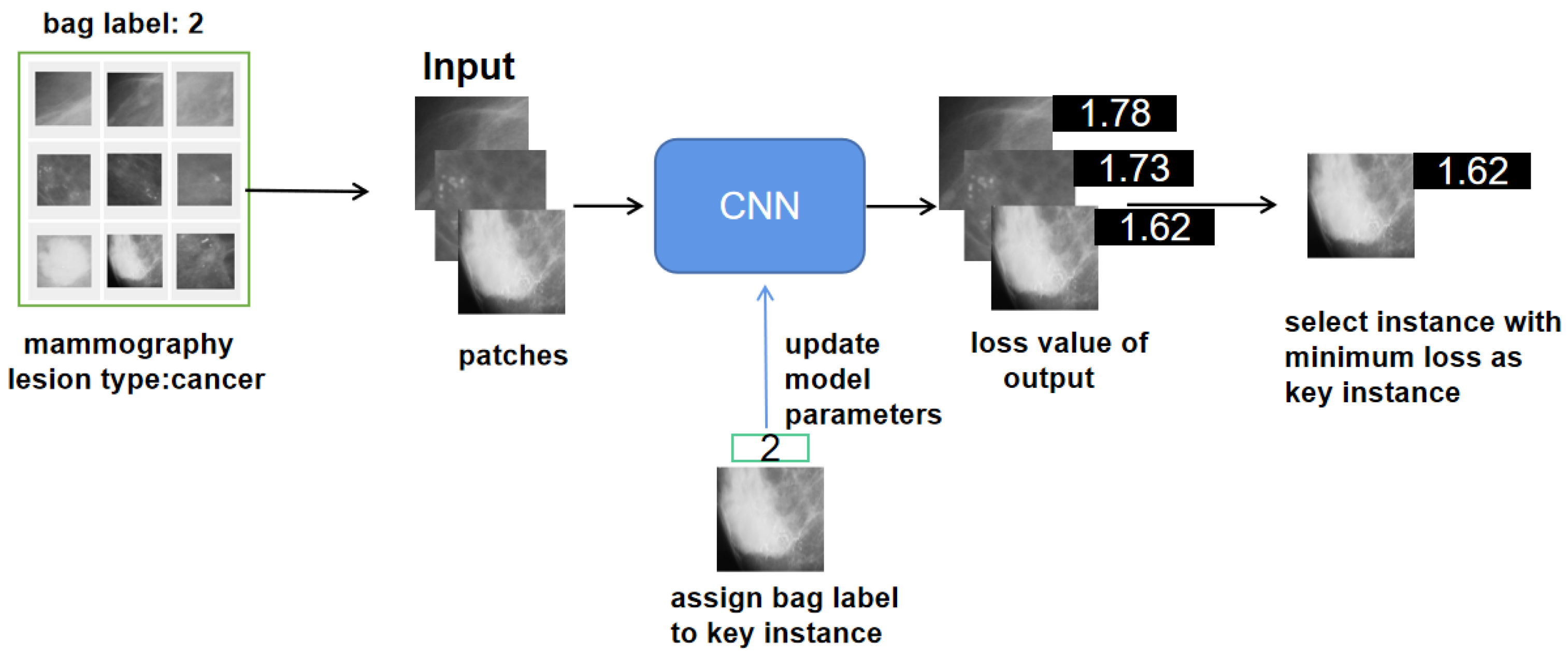
:1. Introduction
- We select a key instance as a positive instance of the bags and send the key instance, which has a bag label, to the network for training. The instances selected from the bag at each iteration are uncertain but incur minimal loss.
- We employ ordinal minimum uncertainty loss to take advantage of the ordered information in classes.
- We carry out experiments on a DDSM dataset to evaluate the OMIL method. The experimental results demonstrate that our OMIL approach achieves better performance than the existing OMIL method.
2. Related Works
2.1. Key Instance
2.2. Multiple Instance Learning
2.3. Ordinal Classification
3. Proposed Approach
3.1. Problem Formalization of OMIL
3.2. Model
4. Experiments
4.1. Datasets
4.2. Experimental Setup
4.3. Empirical Results of OMIL
5. Ablation Study and Discussion
6. Conclusions
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Data Availability Statement
Conflicts of Interest
References
- Elmoufidi, A. Deep Multiple Instance Learning for Automatic Breast Cancer Assessment Using Digital Mammography. IEEE Trans. Instrum. Meas. 2022, 71, 4503813. [Google Scholar] [CrossRef]
- Elmoufidi, A.; El Fahssi, K.; Jai-andaloussi, S.; Sekkaki, A.; Gwenole, Q.; Lamard, M. Anomaly Classification in Digital Mammography Based on Multiple-Instance Learning. IET Image Process. 2018, 12, 320–328. [Google Scholar] [CrossRef]
- Sánchez de la Rosa, R.; Lamard, M.; Cazuguel, G.; Coatrieux, G.; Cozic, M.; Quellec, G. Multiple-Instance Learning for Breast Cancer Detection in Mammograms. In Proceedings of the 2015 37th Annual International Conference of the IEEE Engineering in Medicine and Biology Society (EMBC), Milan, Italy, 25–29 August 2015; pp. 7055–7058. [Google Scholar]
- Wei, X.-S.; Ye, H.-J.; Mu, X.; Wu, J.; Shen, C.; Zhou, Z.-H. Multiple Instance Learning with Emerging Novel Class. IEEE Trans. Knowl. Data Eng. 2019, 33, 2109–2120. [Google Scholar] [CrossRef]
- Zhou, Z.-H.; Zhang, M.-L.; Huang, S.-J.; Li, Y.-F. Multi-Instance Multi-Label Learning. Artif. Intell. 2012, 176, 2291–2320. [Google Scholar] [CrossRef] [Green Version]
- Zhou, Z.-H. Multi-Instance Learning: A Survey; Technical Report; Department of Computer Science & Technology, Nanjing University: Nanjing, China, 2004. [Google Scholar]
- Bilen, H.; Vedaldi, A. Weakly Supervised Deep Detection Networks. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition (CVPR), Las Vegas, NV, USA, 27–30 June 2016; pp. 2846–2854. [Google Scholar] [CrossRef]
- Campanella, G.; Hanna, M.G.; Geneslaw, L.; Miraflor, A.; Werneck Krauss Silva, V.; Busam, K.J.; Brogi, E.; Reuter, V.E.; Klimstra, D.S.; Fuchs, T.J. Clinical-Grade Computational Pathology Using Weakly Supervised Deep Learning on Whole Slide Images. Nat. Med. 2019, 25, 1301–1309. [Google Scholar] [CrossRef] [PubMed]
- Kim, J.; Kim, H.J.; Kim, C.; Lee, J.H.; Kim, K.W.; Park, Y.M.; Kim, H.W.; Ki, S.Y.; Kim, Y.M.; Kim, W.H. Weakly-Supervised Deep Learning for Ultrasound Diagnosis of Breast Cancer. Sci. Rep. 2021, 11, 24382. [Google Scholar] [CrossRef] [PubMed]
- Zhou, Z.-H. A Brief Introduction to Weakly Supervised Learning. Natl. Sci. Rev. 2018, 5, 44–53. [Google Scholar] [CrossRef] [Green Version]
- Alpaydın, E.; Cheplygina, V.; Loog, M.; Tax, D.M.J. Single- vs. Multiple-Instance Classification. Pattern Recognit. 2015, 48, 2831–2838. [Google Scholar] [CrossRef]
- Schwab, E.; Cula, G.O.; Standish, K.; Yip, S.S.F.; Stojmirovic, A.; Ghanem, L.; Chehoud, C. Automatic Estimation of Ulcerative Colitis Severity from Endoscopy Videos Using Ordinal Multi-Instance Learning. Comput. Methods Biomech. Biomed. Eng. Imaging Vis. 2022, 10, 425–433. [Google Scholar] [CrossRef]
- Hamidzadeh, J.; Kashefi, N.; Moradi, M. Combined Weighted Multi-Objective Optimizer for Instance Reduction in Two-Class Imbalanced Data Problem. Eng. Appl. Artif. Intell. 2020, 90, 103500. [Google Scholar] [CrossRef]
- Frank, E.; Hall, M. A Simple Approach to Ordinal Classification. In Machine Learning: ECML 2001; De Raedt, L., Flach, P., Eds.; Lecture Notes in Computer Science; Springer: Berlin/Heidelberg, Germany, 2001; Volume 2167, pp. 145–156. [Google Scholar]
- Serrat, J.; Ruiz, I. Rank-Based Ordinal Classification. In Proceedings of the 2020 25th International Conference on Pattern Recognition (ICPR), Milan, Italy, 10–15 January 2021; pp. 8069–8076. [Google Scholar]
- Liu, G.; Wu, J.; Zhou, Z.-H. Key Instance Detection in Multi-Instance Learning. In Proceedings of the Asian Conference on Machine Learning, PMLR, Singapore, 17 November 2012; pp. 253–268. [Google Scholar]
- Shin, B.; Cho, J.; Yu, H.; Choi, S. Sparse Network Inversion for Key Instance Detection in Multiple Instance Learning. In Proceedings of the 2020 25th International Conference on Pattern Recognition (ICPR), Milan, Italy, 10–15 January 2021; pp. 4083–4090. [Google Scholar]
- Zhang, Y.-L.; Zhou, Z.-H. Multi-Instance Learning with Key Instance Shift. In Proceedings of the Twenty-Sixth International Joint Conference on Artificial Intelligence; International Joint Conferences on Artificial Intelligence Organization, Melbourne, Australia, 19–25 August 2017; pp. 3441–3447. [Google Scholar]
- Yan, Y.; Wang, X.; Guo, X.; Fang, J.; Liu, W.; Huang, J. Deep Multi-Instance Learning with Dynamic Pooling. In Proceedings of the 10th Asian Conference on Machine Learning, PMLR, Beijing, China, 14–16 November 2018; pp. 662–677. [Google Scholar]
- Ilse, M.; Tomczak, J.; Welling, M. Attention-Based Deep Multiple Instance Learning. In Proceedings of the 35th International Conference on Machine Learning, PMLR, Stockholm, Sweden, 10–15 July 2018; pp. 2127–2136. [Google Scholar]
- Astorino, A.; Fuduli, A.; Gaudioso, M.; Vocaturo, E. Multiple Instance Learning Algorithm for Medical Image Classification. SEBD 2019, 2400, 1–8. [Google Scholar]
- Zhou, Z.-H.; Zhang, M.-L. Neural Networks for Multi-Instance Learning. In Proceedings of the International Conference on Intelligent Information Technology, Beijing, China, 22–25 September 2002; pp. 455–459. [Google Scholar]
- Pham, A.T.; Raich, R.; Fern, X.Z.; Arriaga, J.P. Multi-Instance Multi-Label Learning in the Presence of Novel Class Instances. In Proceedings of the International Conference on Machine Learning(ICML), Lille, France, 7–9 July 2015; pp. 2427–2435. [Google Scholar]
- Ishida, T.; Niu, G.; Hu, W.; Sugiyama, M. Learning from Complementary Labels. In Proceedings of the Advances in Neural Information Processing Systems, Long Beach, CA, USA, 4–9 December 2017; Curran Associates, Inc.: New York, NY, USA, 2017; Volume 30. [Google Scholar]
- Gao, Y.; Zhang, M.-L. Discriminative Complementary-Label Learning with Weighted Loss. In Proceedings of the International Conference on Machine Learning(ICML). PMLR, Virtual, 18–24 July 2021; pp. 3587–3597. [Google Scholar]
- Albuquerque, T.; Cruz, R.; Cardoso, J.S. Ordinal Losses for Classification of Cervical Cancer Risk. PeerJ Comput. Sci. 2021, 7, e457. [Google Scholar] [CrossRef] [PubMed]
- Beckham, C.; Pal, C. A Simple Squared-Error Reformulation for Ordinal Classification 2017. arXiv 2016, arXiv:1612.00775. [Google Scholar]
- Gutiérrez, P.A.; Pérez-Ortiz, M.; Sánchez-Monedero, J.; Hervás-Martínez, C. Representing Ordinal Input Variables in the Context of Ordinal Classification. In Proceedings of the 2016 International Joint Conference on Neural Networks (IJCNN), Vancouver, BC, Canada, 24–29 July 2016; pp. 2174–2181. [Google Scholar]
- Lecun, Y.; Bottou, L.; Bengio, Y.; Haffner, P. Gradient-Based Learning Applied to Document Recognition. Proc. IEEE 1998, 86, 2278–2324. [Google Scholar] [CrossRef] [Green Version]
- Jegou, S.; Drozdzal, M.; Vazquez, D.; Romero, A.; Bengio, Y. The One Hundred Layers Tiramisu: Fully Convolutional DenseNets for Semantic Segmentation. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition Workshops, Honolulu, HI, USA, 21–26 July 2017; pp. 11–19. [Google Scholar]
- Lekamlage, C.D.; Afzal, F.; Westerberg, E.; Chaddad, A. Mini-DDSM: Mammography-Based Automatic Age Estimation. In Proceedings of the 2020 3rd International Conference on Digital Medicine and Image Processing, ACM, Kyoto Japan, 6–9 November 2020; pp. 1–6. [Google Scholar]
- Bhagat, P.K.; Choudhary, P.; Singh, K.M. Two Efficient Image Bag Generators for Multi-Instance Multi-Label Learning. In Proceedings of the Computer Vision and Image Processing, Jaipur, India, 27–29 September 2019; Nain, N., Vipparthi, S.K., Raman, B., Eds.; Springer: Singapore, 2020; pp. 407–418. [Google Scholar]
- Wei, X.-S.; Zhou, Z.-H. An Empirical Study on Image Bag Generators for Multi-Instance Learning. Mach. Learn. 2016, 105, 155–198. [Google Scholar] [CrossRef] [Green Version]
- Zhou, Z.-H.; Zhang, M.-L.; Chen, K.-J. A Novel Bag Generator for Image Database Retrieval with Multi-Instance Learning Techniques. In Proceedings of the 15th IEEE International Conference on Tools with Artificial Intelligence, Sacramento, CA, USA, 3–5 November 2003; pp. 565–569. [Google Scholar]
- Jyothi, S.; Bhargavi, K. A Survey on Threshold Based Segmentation Technique in Image Processing. 26 K Bhargavi Jyothi. Int. J. Innov. Res. Dev. 2014, 3, 234–239. [Google Scholar]
- Middleton, D. Channel Modeling and Threshold Signal Processing in Underwater Acoustics: An Analytical Overview. IEEE J. Ocean. Eng. 1987, 12, 4–28. [Google Scholar] [CrossRef] [Green Version]
- Hong, L.; Wan, Y.; Jain, A. Fingerprint Image Enhancement: Algorithm and Performance Evaluation. IEEE Trans. Pattern Anal. Mach. Intell. 1998, 20, 777–789. [Google Scholar] [CrossRef]
- Maini, R.; Aggarwal, H. A Comprehensive Review of Image Enhancement Techniques 2010. arXiv 2010, arXiv:1003.4053. [Google Scholar]
- Kingma, D.P.; Ba, J. Adam: A Method for Stochastic Optimization 2017. arXiv 2014, arXiv:1412.6980. [Google Scholar]
- Jaafar, B.; Mahersia, H.; Lachiri, Z. A Survey on Deep Learning Techniques Used for Breast Cancer Detection. In Proceedings of the 2020 5th International Conference on Advanced Technologies for Signal and Image Processing (ATSIP), Sfax, Tunisia, 2–5 September 2020; pp. 1–6. [Google Scholar]
- Zhang, Z.; Sabuncu, M. Generalized Cross Entropy Loss for Training Deep Neural Networks with Noisy Labels. In Proceedings of the Advances in Neural Information Processing Systems, Montreal, QC, Canada, 3–8 December 2018; Curran Associates, Inc.: New York, NY, USA, 2018; Volume 31. [Google Scholar]



{kind=link}
{kind=link}
{kind=link}
| Concepts | Descriptions |
|---|---|
| Bags | The data unit of OMIL dataset that has labels. Each bag contains several ordinal instances without label information. |
| Instance | The label class of instances in a bag is ordered, and the largest category belongs to the bag category. |
| Key instance | The instance with minimum loss, which is selected from bag . Bag-level label is provided for the instance to participate in the model-training process. |
| Network Layer | Input | Output | Filter | Stride | Padding | Parameter |
|---|---|---|---|---|---|---|
| Input | 224 × 224 × 1 | 224 × 224 × 1 | - | - | - | 0 |
| Conv1 | 224 × 224 × 1 | 220 × 220 × 10 | 5 × 5 × 10 | 1 | 0 | 260 |
| Relu | 220 × 220 × 10 | 220 × 220 × 10 | - | - | - | 0 |
| MaxPool | 220 × 220 × 10 | 110 × 110 × 10 | 2 × 2 | 2 | 0 | 0 |
| Conv2 | 110 × 110 × 10 | 108 × 108 × 20 | 3 × 3 × 20 | 1 | 0 | 1820 |
| Relu | 108 × 108 × 20 | 108 × 108 × 20 | - | - | - | 0 |
| FC1 | 108 × 108 × 20 | 500 | - | - | - | 116,640,500 |
| FC2 | 500 | 1 | - | - | - | 501 |
| Bag 1 | Bag 2 | Bag 3 |
|---|---|---|
| = 1 | = 2 | = 3 |
| = normal = normal = normal | = normal = normal = benign | = normal = benign = cancer |
| = {normal} | = {normal, benign} | = {normal, benign, cancer} |
| = {normal} | = {benign} | = {cancer} |
| Dataset | OMIL | OOMIL (Our Method) |
|---|---|---|
| DDSM | 49.882 | 52.021 |
| Proposed Method | Sensitivity (%) | Specificity (%) | Precision (%) | F1 (%) |
|---|---|---|---|---|
| OOMIL | 61.471 | 47.206 | 57.895 | 59.629 |
| Class | K | ||||
|---|---|---|---|---|---|
| 1 | 2 | 3 | 4 | 5 | |
| 0 | 20.294 | 43.529 | 57.059 | 52.059 | 71.765 |
| 1 | 26.176 | 32.941 | 22.059 | 42.353 | 35.882 |
| 2 | 85.294 | 54.706 | 60.000 | 49.118 | 22.353 |
| Loss | K | ||||
|---|---|---|---|---|---|
| 1 | 2 | 3 | 4 | 5 | |
| cross entropy (OOMIL) | 47.255 | 47.059 | 49.706 | 51.176 | 47.667 |
| min-uncertainty ordinal (OOMIL) | 48.529 | 47.451 | 49.679 | 52.021 | 47.983 |
| cross entropy (OMIL) | 46.972 | 47.183 | 48.127 | 48.743 | 46.430 |
| min-uncertainty ordinal (OMIL) | 47.943 | 47.372 | 49.232 | 49.882 | 46.846 |
Publisher’s Note: MDPI stays neutral with regard to jurisdictional claims in published maps and institutional affiliations. |
© 2022 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Xu, X.; Guo, Q.; Li, Z.; Li, D. Uncertainty Ordinal Multi-Instance Learning for Breast Cancer Diagnosis. Healthcare 2022, 10, 2300. https://doi.org/10.3390/healthcare10112300
Xu X, Guo Q, Li Z, Li D. Uncertainty Ordinal Multi-Instance Learning for Breast Cancer Diagnosis. Healthcare. 2022; 10(11):2300. https://doi.org/10.3390/healthcare10112300
Chicago/Turabian StyleXu, Xinzheng, Qiaoyu Guo, Zhongnian Li, and Dechun Li. 2022. "Uncertainty Ordinal Multi-Instance Learning for Breast Cancer Diagnosis" Healthcare 10, no. 11: 2300. https://doi.org/10.3390/healthcare10112300