
Leveraging Tweets for Artificial Intelligence Driven Sentiment Analysis on the COVID-19 Pandemic

 , , and
, , and
Abstract
:1. Introduction
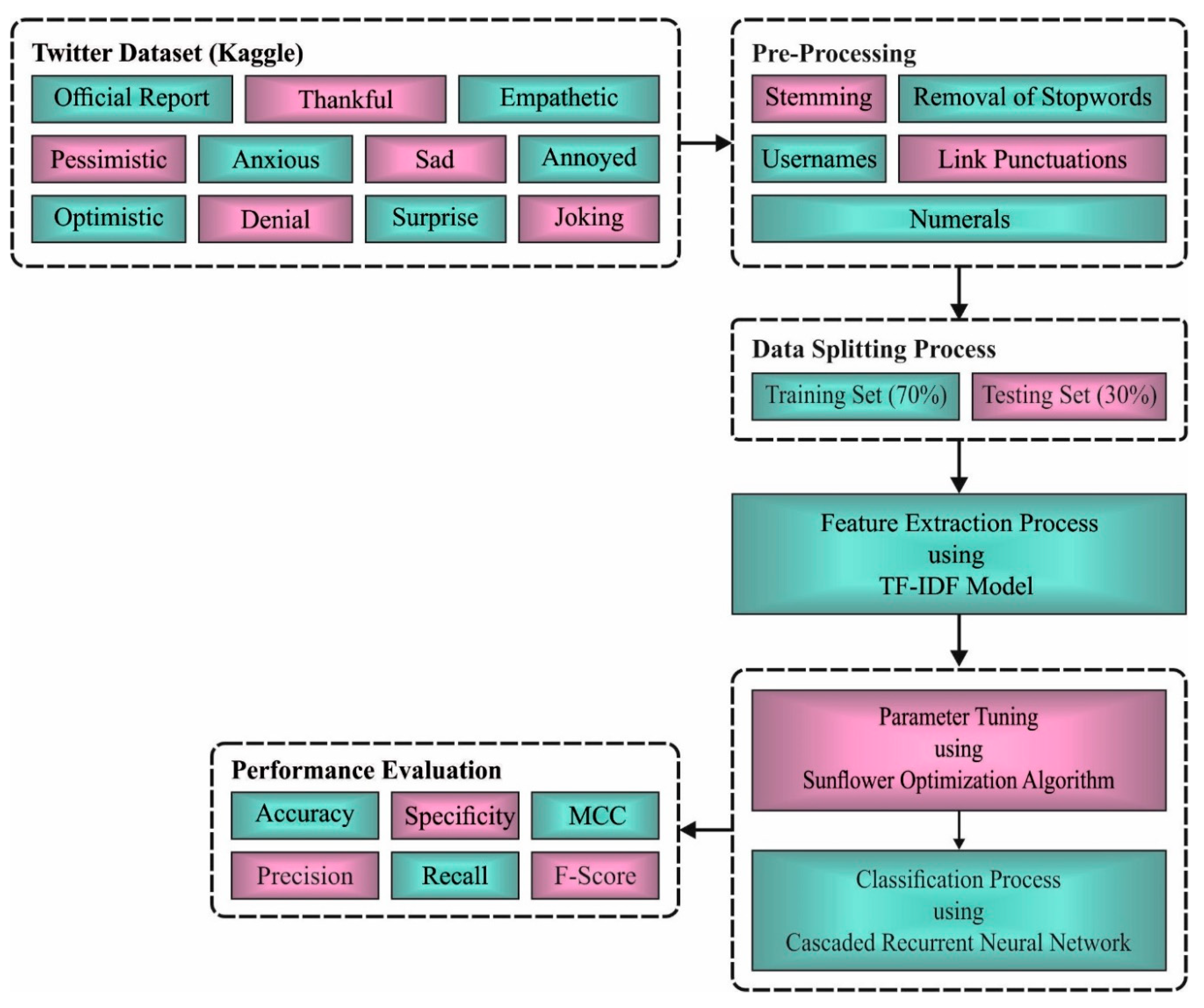
- An intelligent SFODLD-SAC model is presented consisting of TF-IDF-based feature extraction, CRNN classification, and SFO-based hyperparameter optimization for COVID-19 tweet analysis. To the best of our knowledge, the SFODLD-SAC model has been never presented in the literature;
- The SFODLD-SAC technique involves the design of an SFO algorithm to optimally choose the hyperparameters, which helps in increasing the classification accuracy and avoids computational overhead;
- The performance of the SFODLD-SAC model is validated using a benchmark dataset from the Kaggle repository, and the results are investigated under distinct sizes of training/testing data.
2. Literature Review
3. Materials and Methods
3.1. Data Used
3.2. Data Preprocessing
- Removing usernames and links in tweets that do not affect SA;
- Removing punctuation marks such as hashtags and converting them to lower case;
- Removing stopwords and numerals.
3.3. Sentiment Classification Using CRNN Model
3.4. Parameter Optimization
4. Performance Validation
4.1. Result Analysis
4.2. Discussion
5. Conclusions
Author Contributions
Funding
Data Availability Statement
Acknowledgments
Conflicts of Interest
References
- Mohan, S.; Solanki, A.K.; Taluja, H.K.; Singh, A. Predicting the impact of the third wave of COVID-19 in India using hybrid statistical machine learning models: A time series forecasting and sentiment analysis approach. Comput. Biol. Med. 2022, 144, 105354. [Google Scholar] [CrossRef] [PubMed]
- Kaur, H.; Ahsaan, S.U.; Alankar, B.; Chang, V. A proposed sentiment analysis deep learning algorithm for analyzing COVID-19 tweets. Inf. Syst. Front. 2021, 23, 1417–1429. [Google Scholar] [CrossRef] [PubMed]
- Mansour, R.F.; Escorcia-Gutierrez, J.; Gamarra, M.; Gupta, D.; Castillo, O.; Kumar, S. Unsupervised deep learning based variational autoencoder model for COVID-19 diagnosis and classification. Pattern Recognit. Lett. 2021, 151, 267–274. [Google Scholar] [CrossRef] [PubMed]
- Muthumayil, K.; Buvana, M.; Sekar, K.R.; Amraoui, A.E.; Nouaouri, I.; Mansour, R.F. Optimized convolutional neural network for automatic detection of COVID-19. Comput. Mater. Contin. 2021, 70, 1159–1175. [Google Scholar] [CrossRef]
- Xue, Y.; Onzo, B.M.; Mansour, R.F.; Su, S.B. Deep Convolutional Neural Network Approach for COVID-19 Detection. Comput. Syst. Sci. Eng. 2022, 42, 201–211. [Google Scholar] [CrossRef]
- Satu, M.S.; Khan, M.I.; Mahmud, M.; Uddin, S.; Summers, M.A.; Quinn, J.M.; Moni, M.A. TClustVID: A novel machine learning classification model to investigate topics and sentiment in COVID-19 tweets. Knowl.-Based Syst. 2021, 226, 107126. [Google Scholar] [CrossRef]
- Naseem, U.; Razzak, I.; Khushi, M.; Eklund, P.W.; Kim, J. COVIDSenti: A large-scale benchmark Twitter data set for COVID-19 sentiment analysis. IEEE Trans. Comput. Soc. Syst. 2021, 8, 1003–1015. [Google Scholar] [CrossRef]
- Pano, T.; Kashef, R. A complete VADER-based sentiment analysis of bitcoin (BTC) tweets during the era of COVID-19. Big Data Cogn. Comput. 2020, 4, 33. [Google Scholar] [CrossRef]
- Alamoodi, A.H.; Zaidan, B.B.; Zaidan, A.A.; Albahri, O.S.; Mohammed, K.I.; Malik, R.Q.; Almahdi, E.M.; Chyad, M.A.; Tareq, Z.; Albahri, A.S.; et al. Sentiment analysis and its applications in fighting COVID-19 and infectious diseases: A systematic review. Expert Syst. Appl. 2021, 167, 114155. [Google Scholar] [CrossRef]
- Samuel, J.; Ali, G.G.; Rahman, M.; Esawi, E.; Samuel, Y. COVID-19 public sentiment insights and machine learning for tweets classification. Information 2020, 11, 314. [Google Scholar] [CrossRef]
- Chandra, R.; Krishna, A. COVID-19 sentiment analysis via deep learning during the rise of novel cases. PLoS ONE 2021, 16, e0255615. [Google Scholar] [CrossRef] [PubMed]
- Chintalapudi, N.; Battineni, G.; Amenta, F. Sentimental analysis of COVID-19 tweets using deep learning models. Infect. Dis. Rep. 2021, 13, 329–339. [Google Scholar] [CrossRef] [PubMed]
- Gulati, K.; Kumar, S.S.; Boddu, R.S.K.; Sarvakar, K.; Sharma, D.K.; Nomani, M.Z.M. Comparative analysis of machine learning-based classification models using sentiment classification of tweets related to COVID-19 pandemic. Mater. Today Proc. 2022, 51, 38–41. [Google Scholar] [CrossRef]
- Mujahid, M.; Lee, E.; Rustam, F.; Washington, P.B.; Ullah, S.; Reshi, A.A.; Ashraf, I. Sentiment analysis and topic modeling on tweets about online education during COVID-19. Appl. Sci. 2021, 11, 8438. [Google Scholar] [CrossRef]
- Luo, Y.; Xu, X. Comparative study of deep learning models for analyzing online restaurant reviews in the era of the COVID-19 pandemic. Int. J. Hosp. Manag. 2021, 94, 102849. [Google Scholar] [CrossRef]
- Rustam, F.; Khalid, M.; Aslam, W.; Rupapara, V.; Mehmood, A.; Choi, G.S. A performance comparison of supervised machine learning models for Covid-19 tweets sentiment analysis. PLoS ONE 2021, 16, e0245909. [Google Scholar] [CrossRef]
- Singh, C.; Imam, T.; Wibowo, S.; Grandhi, S. A Deep Learning Approach for Sentiment Analysis of COVID-19 Reviews. Appl. Sci. 2022, 12, 3709. [Google Scholar] [CrossRef]
- Yin, H.; Song, X.; Yang, S.; Li, J. Sentiment analysis and topic modeling for COVID-19 vaccine discussions. World Wide Web 2022, 1–17. [Google Scholar] [CrossRef]
- Boon-Itt, S.; Skunkan, Y. Public perception of the COVID-19 pandemic on Twitter: Sentiment analysis and topic modeling study. JMIR Public Health Surveill. 2020, 6, e21978. [Google Scholar] [CrossRef]
- Aljameel, S.S.; Alabbad, D.A.; Alzahrani, N.A.; Alqarni, S.M.; Alamoudi, F.A.; Babili, L.M.; Aljaafary, S.K.; Alshamrani, F.M. A sentiment analysis approach to predict an individual’s awareness of the precautionary procedures to prevent COVID-19 outbreaks in Saudi Arabia. Int. J. Environ. Res. Public Health 2021, 18, 218. [Google Scholar] [CrossRef]
- Lyu, J.C.; Le Han, E.; Luli, G.K. COVID-19 vaccine–related discussion on Twitter: Topic modeling and sentiment analysis. J. Med. Internet Res. 2021, 23, e24435. [Google Scholar] [CrossRef] [PubMed]
- Basiri, M.E.; Nemati, S.; Abdar, M.; Asadi, S.; Acharrya, U.R. A novel fusion-based deep learning model for sentiment analysis of COVID-19 tweets. Knowl.-Based Syst. 2021, 228, 107242. [Google Scholar] [CrossRef]
- Imran, A.S.; Daudpota, S.M.; Kastrati, Z.; Batra, R. Cross-cultural polarity and emotion detection using sentiment analysis and deep learning on COVID-19 related tweets. IEEE Access 2020, 8, 181074–181090. [Google Scholar] [CrossRef] [PubMed]
- Agustiningsih, K.K.; Utami, E.; Alsyaibani, M.A. Sentiment Analysis of COVID-19 Vaccines in Indonesia on Twitter Using Pre-Trained and Self-Training Word Embeddings. J. Ilmu Komput. Dan Inf. 2022, 15, 39–46. [Google Scholar]
- Sentiment Analysis of COVID-19 Related Tweets. Available online: https://www.kaggle.com/competitions/sentiment-analysis-of-covid-19-related-tweets/data?select=validation.csv (accessed on 1 April 2022).
- Shankar, K.; Perumal, E.; Díaz, V.G.; Tiwari, P.; Gupta, D.; Saudagar, A.K.J.; Muhammad, K. An optimal cascaded recurrent neural network for intelligent COVID-19 detection using Chest X-ray images. Appl. Soft Comput. 2021, 113, 107878. [Google Scholar] [CrossRef] [PubMed]
- Gomes, G.F.; da Cunha, S.S.; Ancelotti, A.C. A sunflower optimization (SFO) algorithm applied to damage identification on laminated composite plates. Eng. Comput. 2019, 35, 619–626. [Google Scholar] [CrossRef]













{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Class Label | Class Name | No. of Instances |
|---|---|---|
| Class 0 | Optimistic | 250 |
| Class 1 | Thankful | 250 |
| Class 2 | Empathetic | 250 |
| Class 3 | Pessimistic | 250 |
| Class 4 | Anxious | 250 |
| Class 5 | Sad | 250 |
| Class 6 | Annoyed | 250 |
| Class 7 | Denial | 250 |
| Class 8 | Surprise | 250 |
| Class 9 | Official report | 250 |
| Class 10 | Joking | 250 |
| ID | Tweets | Labels |
|---|---|---|
| 1 | NO JOKE I WILL HOP ON A PLANE RN! (Well after COVID-19 lol) | (0) (10) |
| 2 | Has anyone else FB ads been killing it since this coronavirus hit? | (0) (5) (10) |
| 3 | Im waiting for someone to say to me that all this corona thing is just an April fool’s joke | (3) (4) |
| 4 | He is a liar. Proven day night. Time again. Lies when the truth will do. COVID-19 | (6) |
| 5 | NEW: U.S. CoronaVirus death toll reaches 4000 after nearly 900 new deaths were reported today (BNO News) COVID-19 CoronaVirusOutbreak | (8) |
| 6 | Coronavirus impact Govt extends I-T deadlines related to Sections 80C, 80D | (5) (8) |
| 7 | That moment you realize your new medication has side effects identical to coronavirus symptoms how will I know? | (4) (9) |
| 8 | Watch the government play off Corona virus as a big April Fool’s Joke | (10) |
| 9 | The problem of poverty has now covered the cover of religion. The issue has changed. There is relief from corona. All is well | (0) (4) |
| 10 | My mental health hasn’t suffered at all under the coronavirus quarantine! Ha-ha, April Fools. | (10) |
| 11 | i cannot die before watching a concert live coronavirus pls try to understand | (5) (10) |
| Training Set (70%) | ||||||
|---|---|---|---|---|---|---|
| Class Labels | Accuracy | Precision | Recall | Specificity | F-Score | MCC |
| 0 | 99.64 | 96.69 | 99.43 | 99.66 | 98.04 | 97.85 |
| 1 | 99.12 | 96.47 | 93.71 | 99.66 | 95.07 | 94.60 |
| 2 | 99.48 | 96.05 | 98.27 | 99.60 | 97.14 | 96.86 |
| 3 | 99.38 | 98.84 | 94.48 | 99.89 | 96.61 | 96.30 |
| 4 | 99.12 | 91.92 | 99.45 | 99.08 | 95.54 | 95.14 |
| 5 | 99.74 | 99.44 | 97.78 | 99.94 | 98.60 | 98.46 |
| 6 | 99.84 | 100.00 | 98.20 | 100.00 | 99.09 | 99.01 |
| 7 | 99.69 | 98.25 | 98.25 | 99.83 | 98.25 | 98.07 |
| 8 | 99.79 | 98.31 | 99.43 | 99.83 | 98.86 | 98.75 |
| 9 | 99.48 | 96.53 | 97.66 | 99.66 | 97.09 | 96.81 |
| 10 | 99.01 | 96.95 | 91.91 | 99.71 | 94.36 | 93.86 |
| Average | 99.48 | 97.22 | 97.14 | 99.71 | 97.15 | 96.88 |
| Testing Set (30%) | ||||||
|---|---|---|---|---|---|---|
| Class Labels | Accuracy | Precision | Recall | Specificity | F-Score | MCC |
| 0 | 99.52 | 96.05 | 98.65 | 99.60 | 97.33 | 97.08 |
| 1 | 99.88 | 100.00 | 98.67 | 100.00 | 99.33 | 99.26 |
| 2 | 99.64 | 96.25 | 100.00 | 99.60 | 98.09 | 97.91 |
| 3 | 99.39 | 100.00 | 92.75 | 100.00 | 96.24 | 95.99 |
| 4 | 99.88 | 98.53 | 100.00 | 99.87 | 99.26 | 99.20 |
| 5 | 99.76 | 98.57 | 98.57 | 99.87 | 98.57 | 98.44 |
| 6 | 99.76 | 100.00 | 97.59 | 100.00 | 98.78 | 98.65 |
| 7 | 99.64 | 96.34 | 100.00 | 99.60 | 98.14 | 97.96 |
| 8 | 99.64 | 97.37 | 98.67 | 99.73 | 98.01 | 97.82 |
| 9 | 99.27 | 96.20 | 96.20 | 99.60 | 96.20 | 95.80 |
| 10 | 99.76 | 100.00 | 97.40 | 100.00 | 98.68 | 98.56 |
| Average | 99.65 | 98.12 | 98.05 | 99.81 | 98.06 | 97.88 |
| Methods | Accuracy | Precision | Recall | F1 Score |
|---|---|---|---|---|
| Random Forest | 90.13 | 91.22 | 90.30 | 90.29 |
| XGBoost Algorithm | 90.16 | 90.35 | 90.39 | 90.36 |
| Support Vector Machine | 89.43 | 89.29 | 89.12 | 89.18 |
| Extra Tree Classifier | 92.32 | 93.08 | 92.42 | 92.13 |
| Decision Tree | 89.29 | 89.47 | 89.21 | 89.29 |
| SFODLD-SAC | 99.65 | 98.12 | 98.05 | 98.06 |
Publisher’s Note: MDPI stays neutral with regard to jurisdictional claims in published maps and institutional affiliations. |
© 2022 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Alkhaldi, N.A.; Asiri, Y.; Mashraqi, A.M.; Halawani, H.T.; Abdel-Khalek, S.; Mansour, R.F. Leveraging Tweets for Artificial Intelligence Driven Sentiment Analysis on the COVID-19 Pandemic. Healthcare 2022, 10, 910. https://doi.org/10.3390/healthcare10050910
Alkhaldi NA, Asiri Y, Mashraqi AM, Halawani HT, Abdel-Khalek S, Mansour RF. Leveraging Tweets for Artificial Intelligence Driven Sentiment Analysis on the COVID-19 Pandemic. Healthcare. 2022; 10(5):910. https://doi.org/10.3390/healthcare10050910
Chicago/Turabian StyleAlkhaldi, Nora A., Yousef Asiri, Aisha M. Mashraqi, Hanan T. Halawani, Sayed Abdel-Khalek, and Romany F. Mansour. 2022. "Leveraging Tweets for Artificial Intelligence Driven Sentiment Analysis on the COVID-19 Pandemic" Healthcare 10, no. 5: 910. https://doi.org/10.3390/healthcare10050910
APA StyleAlkhaldi, N. A., Asiri, Y., Mashraqi, A. M., Halawani, H. T., Abdel-Khalek, S., & Mansour, R. F. (2022). Leveraging Tweets for Artificial Intelligence Driven Sentiment Analysis on the COVID-19 Pandemic. Healthcare, 10(5), 910. https://doi.org/10.3390/healthcare10050910