
Predicting Suicidal Ideation, Planning, and Attempts among the Adolescent Population of the United States



Abstract
1. Introduction
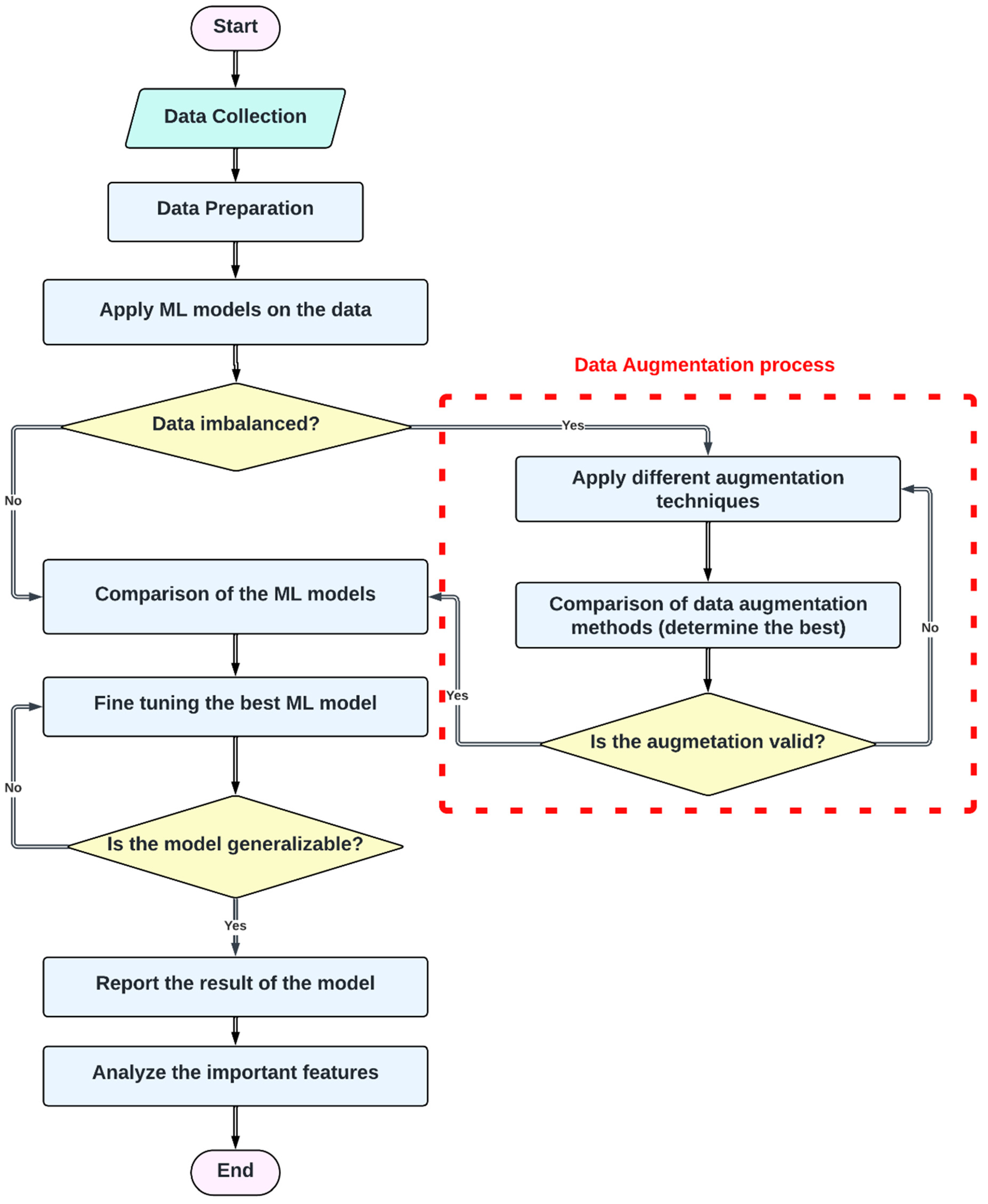
2. Methods and Materials
- Suicide Ideation (SI)—The variable was measured using the following question: During the past 12 months, did you ever seriously consider attempting suicide? The responses were recorded as ‘Yes’ or ‘No’. In our model, ‘Yes’ was coded as 1;
- Suicide planning (SP)—The variable was measured using the following question: During the past 12 months, did you make a plan about how you would attempt suicide? The responses were recorded as ‘Yes’ or ‘No’;
- Suicide Attempt (SA)—The variable was measured using the following question: During the past 12 months, how many times did you actually attempt suicide? The responses were recorded as 0 times, 1 time, 2 or 3 times, 4 or 5 times, or 6 or more times. In our study, we coded all responses indicating at least one attempt as 1 and the remainder as 0.
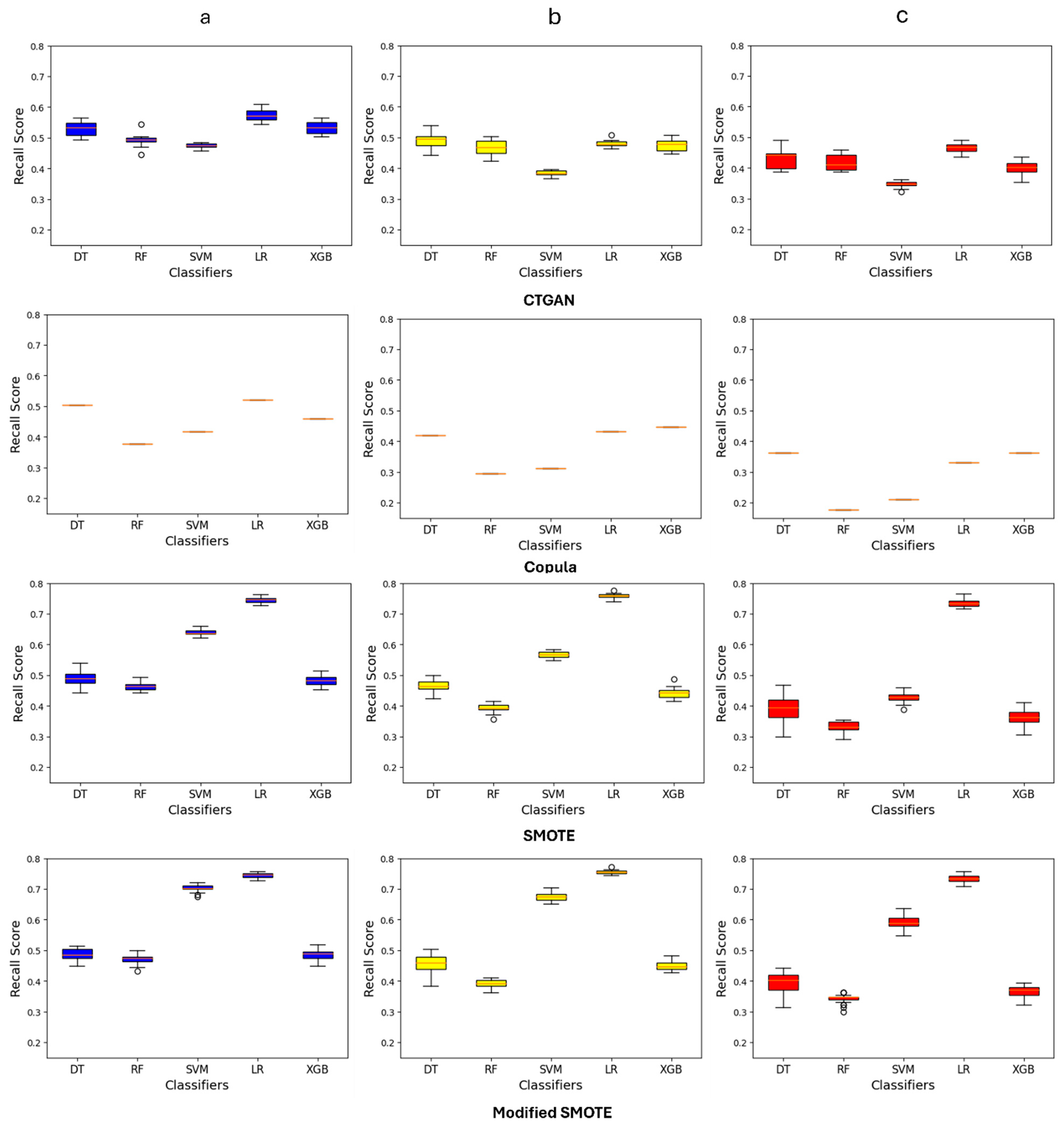
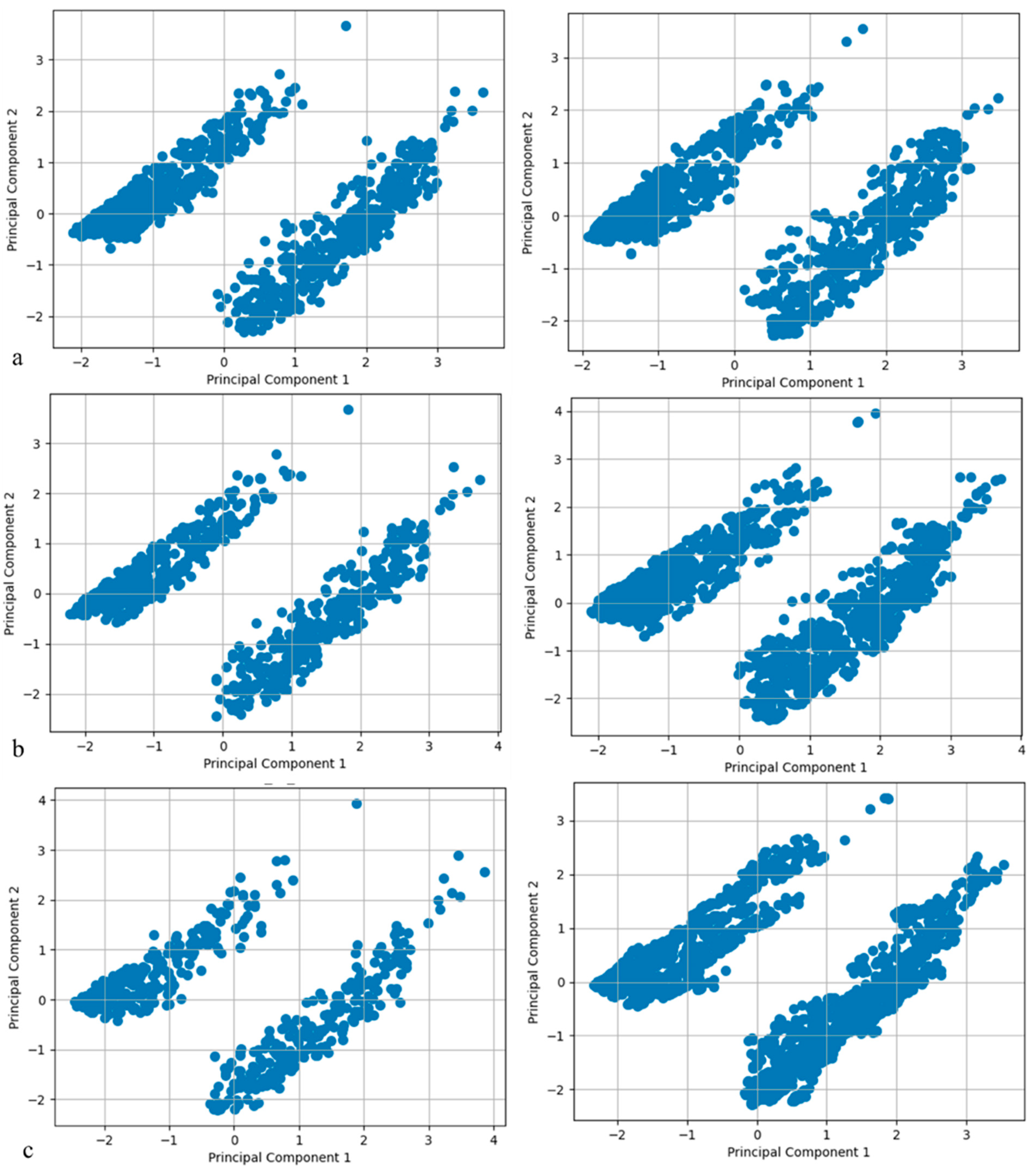
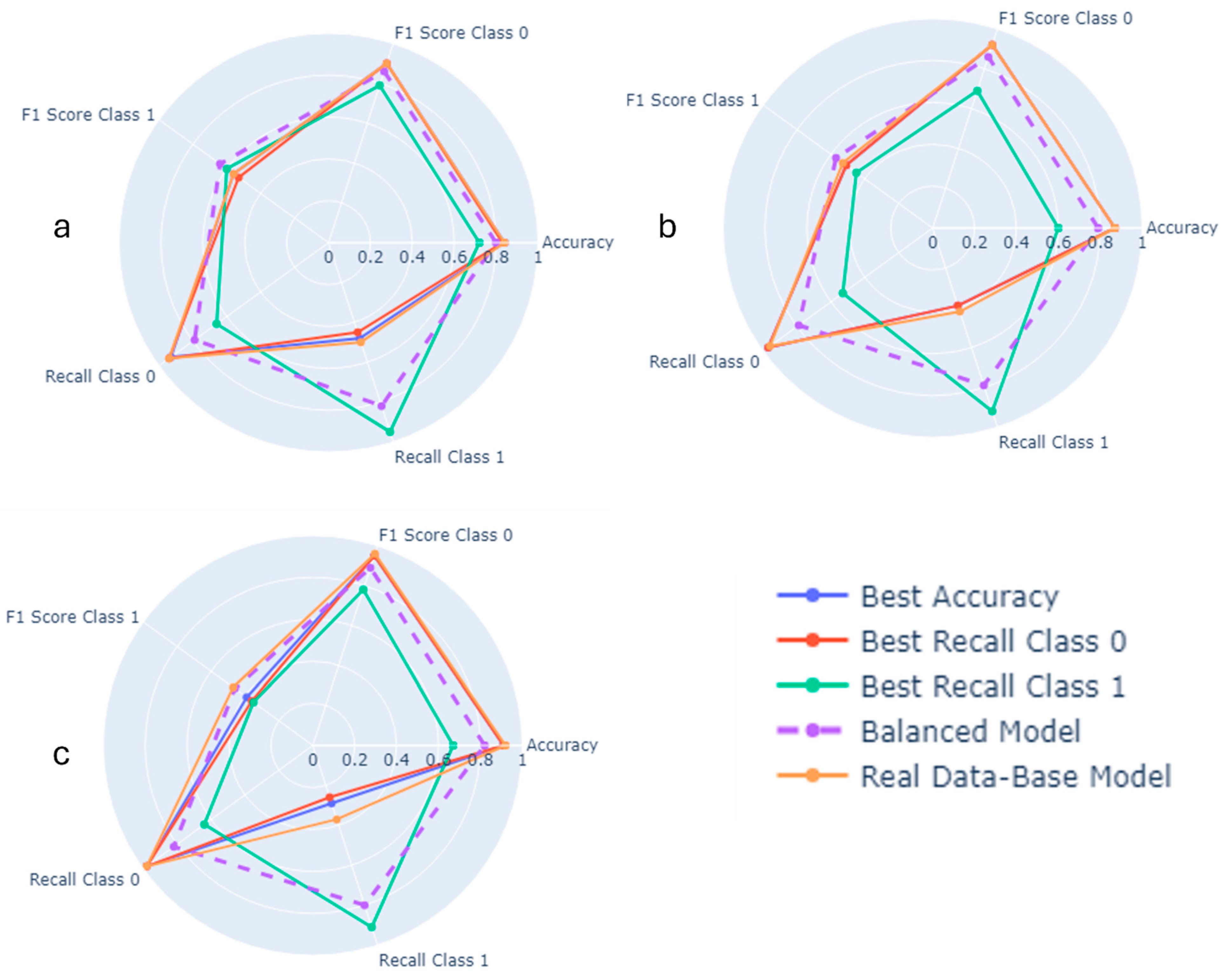
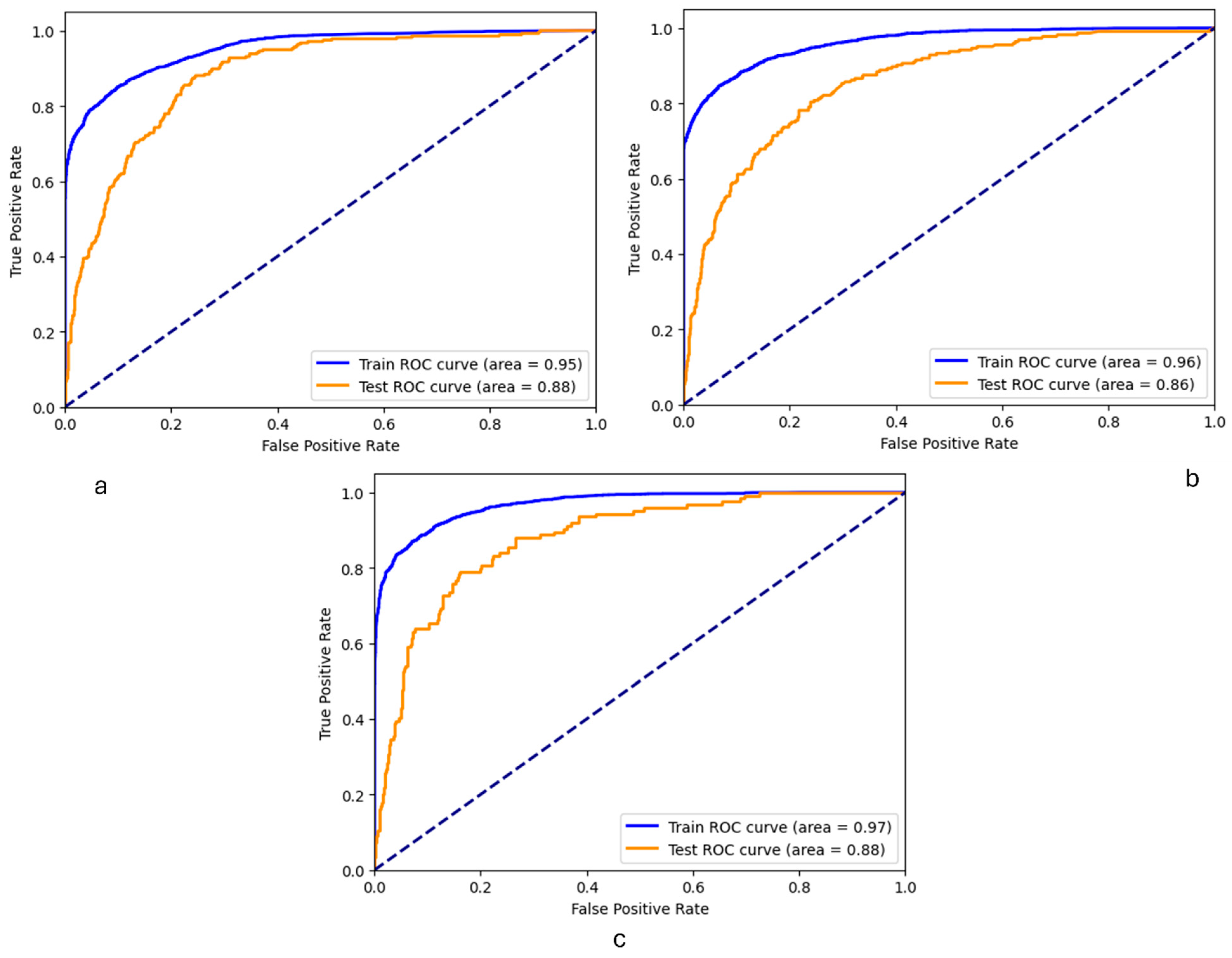
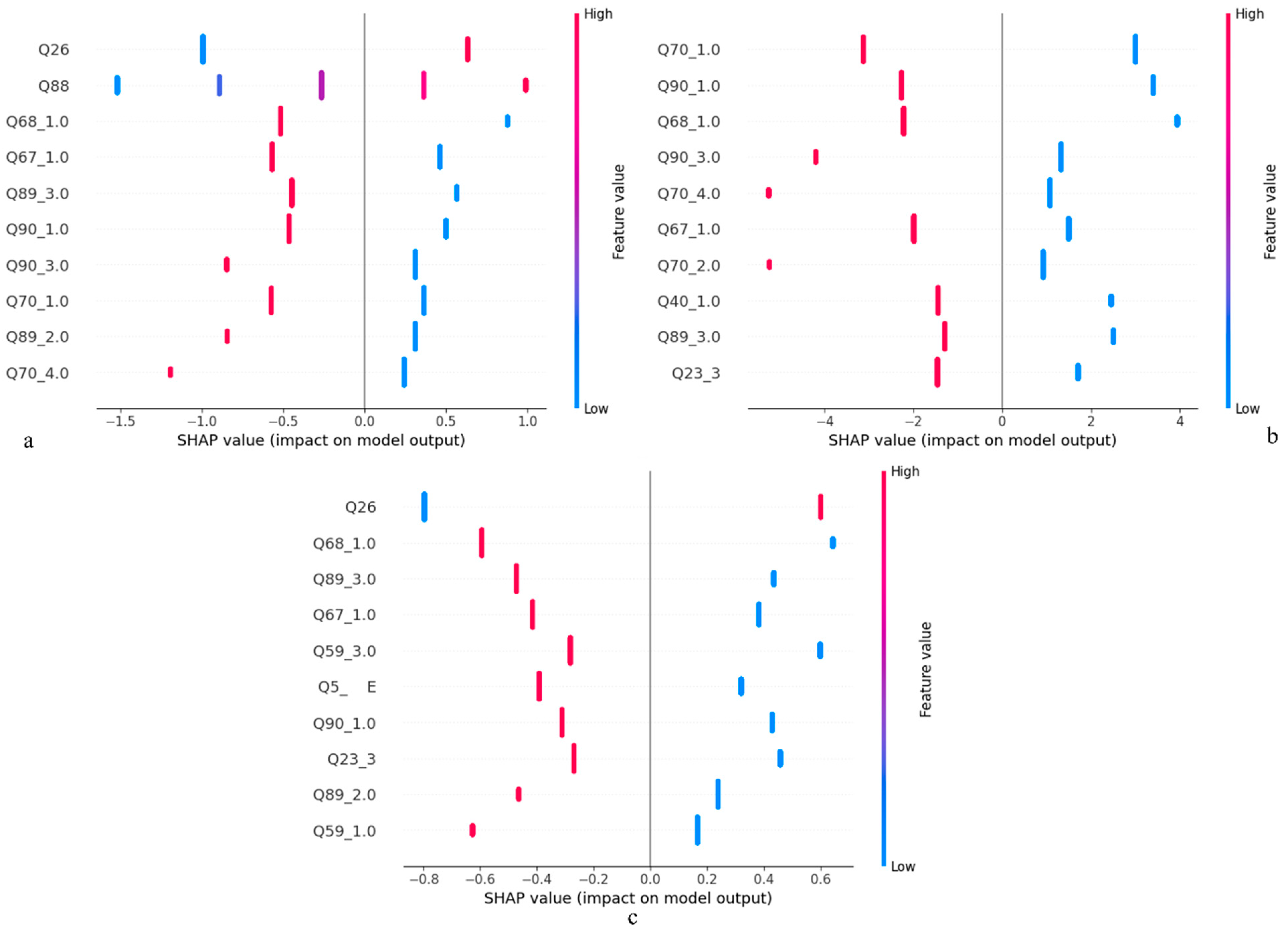
3. Result
4. Discussion
5. Conclusions
6. Summary Points
- -
- Sad feelings, hopelessness, sexual behavior, and being overweight were noted as some of the most important predictors;
- -
- The optimized logistic regression model demonstrated high discrimination capabilities across all target variables;
- -
- Encouraging these behaviors through public health initiatives, such as anti-smoking campaigns and programs that foster anti-bullying behaviors, could serve as preventive measures against suicide.
Supplementary Materials
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Data Availability Statement
Conflicts of Interest
References
- Brådvik, L. Suicide risk and mental disorders. Int. J. Environ. Res. Public Health 2018, 15, 2028. [Google Scholar] [CrossRef] [PubMed]
- Turecki, G.; Brent, D.A.; Gunnell, D.; O’Connor, R.C.; Oquendo, M.A.; Pirkis, J.; Stanley, B.H. Suicide and suicide risk. Nat. Rev. Dis. Primers 2019, 5, 74. [Google Scholar] [CrossRef]
- Knipe, D.; Padmanathan, P.; Newton-Howes, G.; Chan, L.F.; Kapur, N. Suicide and self-harm. Lancet 2022, 399, 1903–1916. [Google Scholar] [CrossRef]
- Hedegaard, H.; Curtin, S.C.; Warner, M. Increase in Suicide Mortality in the United States, 1999–2018; CDC: Atlanta, GA, USA, 2020.
- Hu, F.-H.; Jia, Y.-J.; Zhao, D.-Y.; Fu, X.-L.; Zhang, W.-Q.; Tang, W.; Hu, S.-Q.; Wu, H.; Ge, M.-W.; Du, W. Gender differences in suicide among patients with bipolar disorder: A systematic review and meta-analysis. J. Affect. Disord. 2023, 339, 601–614. [Google Scholar] [CrossRef]
- Chen, P.; Mao, L.; Nassis, G.P.; Harmer, P.; Ainsworth, B.E.; Li, F. Coronavirus disease (COVID-19): The need to maintain regular physical activity while taking precautions. J. Sport Health Sci. 2020, 9, 103. [Google Scholar] [CrossRef] [PubMed]
- Mahmud, S.; Mohsin, M.; Muyeed, A.; Nazneen, S.; Sayed, M.A.; Murshed, N.; Tonmon, T.T.; Islam, A. Machine learning approaches for predicting suicidal behaviors among university students in bangladesh during the covid-19 pandemic: A cross-sectional study. Medicine 2023, 102, e34285. [Google Scholar] [CrossRef]
- Bernert, R.A.; Hilberg, A.M.; Melia, R.; Kim, J.P.; Shah, N.H.; Abnousi, F. Artificial intelligence and suicide prevention: A systematic review of machine learning investigations. Int. J. Environ. Res. Public Health 2020, 17, 5929. [Google Scholar] [CrossRef]
- Cho, S.-E.; Geem, Z.W.; Na, K.-S. Development of a suicide prediction model for the elderly using health screening data. Int. J. Environ. Res. Public Health 2021, 18, 10150. [Google Scholar] [CrossRef] [PubMed]
- Jung, J.S.; Park, S.J.; Kim, E.Y.; Na, K.-S.; Kim, Y.J.; Kim, K.G. Prediction models for high risk of suicide in Korean adolescents using machine learning techniques. PLoS ONE 2019, 14, e0217639. [Google Scholar] [CrossRef]
- Kim, K.-W.; Lim, J.S.; Yang, C.-M.; Jang, S.-H.; Lee, S.-Y. Classification of adolescent psychiatric patients at high risk of suicide using the personality assessment inventory by machine learning. Psychiatry Investig. 2021, 18, 1137. [Google Scholar] [CrossRef]
- Heckler, W.F.; de Carvalho, J.V.; Barbosa, J.L.V. Machine learning for suicidal ideation identification: A systematic literature review. Comput. Hum. Behav. 2022, 128, 107095. [Google Scholar] [CrossRef]
- Jacobucci, R.; Littlefield, A.K.; Millner, A.J.; Kleiman, E.M.; Steinley, D. Evidence of Inflated Prediction Performance: A Commentary on Machine Learning and Suicide Research. Clin. Psychol. Sci. 2021, 9, 129–134. [Google Scholar] [CrossRef]
- Huang, X.; Zhang, L.; Chiu, D.; Liu, T.; Li, X.; Zhu, T. Detecting suicidal ideation in Chinese microblogs with psychological lexicons. In Proceedings of the 2014 IEEE 11th Intl Conf on Ubiquitous Intelligence and Computing and 2014 IEEE 11th Intl Conf on Autonomic and Trusted Computing and 2014 IEEE 14th Intl Conf on Scalable Computing and Communications and Its Associated Workshops, Bali, Indonesia, 9–12 December 2014; pp. 844–849. [Google Scholar]
- Zhang, L.; Huang, X.; Liu, T.; Li, A.; Chen, Z.; Zhu, T. Using linguistic features to estimate suicide probability of Chinese microblog users. In Proceedings of the Human Centered Computing: First International Conference, HCC 2014, Phnom Penh, Cambodia, 27–29 November 2014; Revised Selected Papers 1, 2015. pp. 549–559. [Google Scholar]
- Yao, H.; Rashidian, S.; Dong, X.; Duanmu, H.; Rosenthal, R.N.; Wang, F. Detection of suicidality among opioid users on reddit: Machine learning–based approach. J. Med. Internet Res. 2020, 22, e15293. [Google Scholar] [CrossRef] [PubMed]
- Sarsam, S.M.; Al-Samarraie, H.; Alzahrani, A.I.; Alnumay, W.; Smith, A.P. A lexicon-based approach to detecting suicide-related messages on Twitter. Biomed. Signal Process. Control 2021, 65, 102355. [Google Scholar] [CrossRef]
- Wang, R.; Yang, B.X.; Ma, Y.; Wang, P.; Yu, Q.; Zong, X.; Huang, Z.; Ma, S.; Hu, L.; Hwang, K.; et al. Medical-level suicide risk analysis: A novel standard and evaluation model. IEEE Internet Things J. 2021, 8, 16825–16834. [Google Scholar] [CrossRef]
- Jordan, P.; Shedden-Mora, M.C.; Löwe, B. Predicting suicidal ideation in primary care: An approach to identify easily assessable key variables. Gen. Hosp. Psychiatry 2018, 51, 106–111. [Google Scholar] [CrossRef] [PubMed]
- Colic, S.; Richardson, J.; Reilly, J.P.; Hasey, G.M. Using machine learning algorithms to enhance the management of suicide ideation. In Proceedings of the 2018 40th Annual International Conference of the IEEE Engineering in Medicine and Biology Society (EMBC), Honolulu, HI, USA, 18–21 July 2018; pp. 4936–4939. [Google Scholar]
- Pestian, J.; Santel, D.; Sorter, M.; Bayram, U.; Connolly, B.; Glauser, T.; DelBello, M.; Tamang, S.; Cohen, K. A machine learning approach to identifying changes in suicidal language. Suicide Life-Threat. Behav. 2020, 50, 939–947. [Google Scholar] [CrossRef] [PubMed]
- Cook, B.L.; Progovac, A.M.; Chen, P.; Mullin, B.; Hou, S.; Baca-Garcia, E. Novel use of natural language processing (NLP) to predict suicidal ideation and psychiatric symptoms in a text-based mental health intervention in Madrid. Comput. Math. Methods Med. 2016, 2016. [Google Scholar] [CrossRef] [PubMed]
- Gideon, J.; Schatten, H.T.; McInnis, M.G.; Provost, E.M. Emotion recognition from natural phone conversations in individuals with and without recent suicidal ideation. In Proceedings of the Interspeech, Graz, Austria, 15–19 September 2019. [Google Scholar]
- Dai, Z.; Shen, X.; Tian, S.; Yan, R.; Wang, H.; Wang, X.; Yao, Z.; Lu, Q. Gradually evaluating of suicidal risk in depression by semi-supervised cluster analysis on resting-state fMRI. Brain Imaging Behav. 2021, 15, 2149–2158. [Google Scholar] [CrossRef]
- Weng, J.-C.; Lin, T.-Y.; Tsai, Y.-H.; Cheok, M.T.; Chang, Y.-P.E.; Chen, V.C.-H. An autoencoder and machine learning model to predict suicidal ideation with brain structural imaging. J. Clin. Med. 2020, 9, 658. [Google Scholar] [CrossRef]
- Peis, I.; Olmos, P.M.; Vera-Varela, C.; Barrigon, M.L.; Courtet, P.; Baca-Garcia, E.; Artes-Rodriguez, A. Deep Sequential Models for Suicidal Ideation from Multiple Source Data. IEEE J. Biomed. Health Inform. 2019, 23, 2286–2293. [Google Scholar] [CrossRef]
- Ge, F.; Jiang, J.; Wang, Y.; Yuan, C.; Zhang, W. Identifying suicidal ideation among Chinese patients with major depressive disorder: Evidence from a real-world hospital-based study in China. Neuropsychiatr. Dis. Treat. 2020, 16, 665–672. [Google Scholar] [CrossRef]
- Lin, G.-M.; Nagamine, M.; Yang, S.-N.; Tai, Y.-M.; Lin, C.; Sato, H. Machine learning based suicide ideation prediction for military personnel. IEEE J. Biomed. Health Inform. 2020, 24, 1907–1916. [Google Scholar] [CrossRef]
- Belouali, A.; Gupta, S.; Sourirajan, V.; Yu, J.; Allen, N.; Alaoui, A.; Dutton, M.A.; Reinhard, M.J. Acoustic and language analysis of speech for suicidal ideation among US veterans. BioData Min. 2021, 14, 11. [Google Scholar] [CrossRef] [PubMed]
- Adolescent Behaviors and Experiences Survey (ABES). Available online: https://www.cdc.gov/healthyyouth/data/abes.htm (accessed on 12 December 2023).
- White, I.R.; Royston, P.; Wood, A.M. Multiple imputation using chained equations: Issues and guidance for practice. Stat. Med. 2011, 30, 377–399. [Google Scholar] [CrossRef]
- García-Laencina, P.J.; Sancho-Gómez, J.-L.; Figueiras-Vidal, A.R. Pattern classification with missing data: A review. Neural Comput. Appl. 2010, 19, 263–282. [Google Scholar] [CrossRef]
- Langkamp, D.L.; Lehman, A.; Lemeshow, S. Techniques for handling missing data in secondary analyses of large surveys. Acad. Pediatr. 2010, 10, 205–210. [Google Scholar] [CrossRef]
- Wang, Y.; Sohn, S.; Liu, S.; Shen, F.; Wang, L.; Atkinson, E.J.; Amin, S.; Liu, H. A clinical text classification paradigm using weak supervision and deep representation. BMC Med. Inform. Decis. Mak. 2019, 19, 1. [Google Scholar] [CrossRef] [PubMed]
- Mehedi, M.A.A.; Smith, V.; Hosseiny, H.; Jiao, X. Unraveling the complexities of urban fluvial flood hydraulics through AI. Sci. Rep. 2022, 12, 18738. [Google Scholar] [CrossRef] [PubMed]
- Lee, C.; Jo, B.; Woo, H.; Im, Y.; Park, R.W.; Park, C. Chronic disease prediction using the common data model: Development study. JMIR AI 2022, 1, e41030. [Google Scholar] [CrossRef]
- Chawla, N.V.; Bowyer, K.W.; Hall, L.O.; Kegelmeyer, W.P. SMOTE: Synthetic minority over-sampling technique. J. Artif. Intell. Res. 2002, 16, 321–357. [Google Scholar] [CrossRef]
- Xue-Kun Song, P. Multivariate dispersion models generated from Gaussian copula. Scand. J. Stat. 2000, 27, 305–320. [Google Scholar] [CrossRef]
- Xu, L.; Skoularidou, M.; Cuesta-Infante, A.; Veeramachaneni, K. Modeling tabular data using conditional gan. In Advances in Neural Information Processing Systems; MIT Press: Cambridge, MA, USA, 2019; Volume 32. [Google Scholar]
- Shah, F.M.; Haque, F.; Nur, R.U.; Al Jahan, S.; Mamud, Z. A hybridized feature extraction approach to suicidal ideation detection from social media post. In Proceedings of the 2020 IEEE Region 10 Symposium (TENSYMP), Dhaka, Bangladesh, 5–7 June 2020; pp. 985–988. [Google Scholar]
- Valeriano, K.; Condori-Larico, A.; Sulla-Torres, J. Detection of suicidal intent in Spanish language social networks using machine learning. Int. J. Adv. Comput. Sci. Appl. 2020, 11, 688–695. [Google Scholar] [CrossRef]
- Bantilan, N.; Malgaroli, M.; Ray, B.; Hull, T.D. Just in time crisis response: Suicide alert system for telemedicine psychotherapy settings. Psychother. Res. 2021, 31, 289–299. [Google Scholar] [CrossRef] [PubMed]
- Haghish, E.; Czajkowski, N.O.; von Soest, T. Predicting suicide attempts among Norwegian adolescents without using suicide-related items: A machine learning approach. Front. Psychiatry 2023, 14, 1216791. [Google Scholar] [CrossRef]
- Sheu, Y.-H.; Sun, J.; Lee, H.; Castro, V.M.; Barak-Corren, Y.; Song, E.; Madsen, E.M.; Gordon, W.J.; Kohane, I.S.; Churchill, S.E. An efficient landmark model for prediction of suicide attempts in multiple clinical settings. Psychiatry Res. 2023, 323, 115175. [Google Scholar] [CrossRef]
- Lim, J.S.; Yang, C.-M.; Baek, J.-W.; Lee, S.-Y.; Kim, B.-N. Prediction models for suicide attempts among adolescents using machine learning techniques. Clin. Psychopharmacol. Neurosci. 2022, 20, 609. [Google Scholar] [CrossRef]

{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Attribute | Overall Data | Suicide Ideation N (%) | Suicide Planning N (%) | Suicide Attempt N (%) |
|---|---|---|---|---|
| Age (years) | ||||
| 12 to 17 | 6622 (86) | 1350 (18) | 1068 (14) | 1348 (18) |
| 18 and above | 1070 (14) | 186 (2) | 138 (2) | 243 (3) |
| Sex | ||||
| Male | 3678 (48) | 490 (6) | 364 (5) | 702 (9) |
| Female | 3999 (52) | 1035 (13) | 832 (11) | 880 (11) |
| Ethnicity | ||||
| Hispanic or Latino | 2038 (26) | 401 (5) | 338 (4) | 450 (6) |
| Not Hispanic | 5634 (73) | 1136 (15) | 868 (11) | 1138 (15) |
| Race | ||||
| American Indian or Alaska Native | 276 (4) | 50 (<1) | 40 (<1) | 72 (<1) |
| Asian | 381 (5) | 69 (<1) | 62 (<1) | 71 (<1) |
| African American | 1301 (19) | 216 (3) | 177 (3) | 354 (5) |
| Native Hawaiian or other Pacific Islander | 98 (1) | 14 (<1) | 12 (<1) | 32 (<1) |
| Caucasian | 4335 (62) | 930 (13) | 702 (10) | 790 (11) |
| Multiracial | 639 (9) | 165 (2) | 135 (2) | 130 (2) |
| Models | Suicide Ideation | Suicide Planning | Suicide Attempt | ||||||
|---|---|---|---|---|---|---|---|---|---|
| Accuracy | Recall | Recall | Accuracy | Recall | Recall | Accuracy | Recall | Recall | |
| Class 0 | Class 1 | Class 0 | Class 1 | Class 0 | Class 1 | ||||
| Random Forest | 0.85 | 0.97 | 0.42 | 0.87 | 0.99 | 0.29 | 0.92 | 0.99 | 0.23 |
| Decision Tree | 0.78 | 0.88 | 0.41 | 0.82 | 0.91 | 0.43 | 0.87 | 0.93 | 0.36 |
| Logistic Regression | 0.84 | 0.94 | 0.50 | 0.87 | 0.96 | 0.42 | 0.92 | 0.98 | 0.37 |
| Support Vector Machine | 0.84 | 0.96 | 0.41 | 0.86 | 0.98 | 0.30 | 0.91 | 0.99 | 0.20 |
| Extreme Gradient Boosting | 0.84 | 0.94 | 0.48 | 0.87 | 0.96 | 0.45 | 0.92 | 0.98 | 0.35 |
| Parameters | Different Values | |
|---|---|---|
| Modified SMOTE | Sample strategy | 0.5, 0.6, 0.7, 0.75, 0.9, 1 |
| Model—Logistic Regression | C | 0.01, 0.1, 0.5, 1, 10, 100 |
| Solver | ‘lbfgs’, ‘liblinear’ | |
| Class weights | (0: 1, 1: 1), (0: 1, 1: 2), (0: 1, 1: 2.5), (0: 1, 1: 3), (0: 1, 1: 3.5), (0: 1, 1: 5), (0: 1, 1: 10) | |
| Feature Selection | Significant features | Recursive Feature Elimination |
| Ref. | Study Data | SI | SP | SA | Best Model | Results | Important Factors |
|---|---|---|---|---|---|---|---|
| Our model | Adolescent Behaviors and Experiences Survey (ABES). | x | x | x | LR | Recall: 0.82 Accuracy: 0.80 AUC: 0.88 | Sad feelings, hopelessness, experiences during COVID-19, sexual behavior, body weight |
| [29] | U.S. veterans’ recordings | x | RF | Recall: 0.84 Accuracy: 0.72 AUC: 0.80 | Delta energy entropy, Delta energy, Energy contour | ||
| [40] | Social media (Reddit) contents | x | Navie bayes | Recall: 0.87 Accuracy: 0.74 AUC: NR | 50 linguistic features | ||
| [41] | Human-annotated dataset | x | LR | Recall: 0.79 Accuracy: 0.79 AUC: NR | NR | ||
| [25] | Generalized q-sampling imaging (GQI) dataset | x | XGB | Recall: 0.73 Accuracy: 0.68 AUC: 0.84 | NR | ||
| [42] | Psychotherapy dyads | x | XGB | Recall: 0.66 Accuracy: NR AUC: 0.82 | NR | ||
| [43] | Nationwide survey data (Norwegian adolescents) | x | XGB | Recall: 0.77 Accuracy: NR AUC: 0.92 | Sadness and depression, contacting a psychologist, feeling worthless | ||
| [44] | MGB Research Patient Data Registry (RPDR) | x | regularized Cox | Recall: 0.70 Accuracy: 0.93 AUC: NR | Suicide ideation, mood disorder, age | ||
| [45] | Korea Youth Risk Behavior Survey (KYRBS) | x | XGB | Recall: 0.61 Accuracy: 0.97 AUC: NR | Suicide ideation, suicide planning, grade |
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2024 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Khosravi, H.; Ahmed, I.; Choudhury, A. Predicting Suicidal Ideation, Planning, and Attempts among the Adolescent Population of the United States. Healthcare 2024, 12, 1262. https://doi.org/10.3390/healthcare12131262
Khosravi H, Ahmed I, Choudhury A. Predicting Suicidal Ideation, Planning, and Attempts among the Adolescent Population of the United States. Healthcare. 2024; 12(13):1262. https://doi.org/10.3390/healthcare12131262
Chicago/Turabian StyleKhosravi, Hamed, Imtiaz Ahmed, and Avishek Choudhury. 2024. "Predicting Suicidal Ideation, Planning, and Attempts among the Adolescent Population of the United States" Healthcare 12, no. 13: 1262. https://doi.org/10.3390/healthcare12131262
APA StyleKhosravi, H., Ahmed, I., & Choudhury, A. (2024). Predicting Suicidal Ideation, Planning, and Attempts among the Adolescent Population of the United States. Healthcare, 12(13), 1262. https://doi.org/10.3390/healthcare12131262