
Deep Learning Approaches to Automated Video Classification of Upper Limb Tension Test



Abstract
:1. Introduction
2. Methods
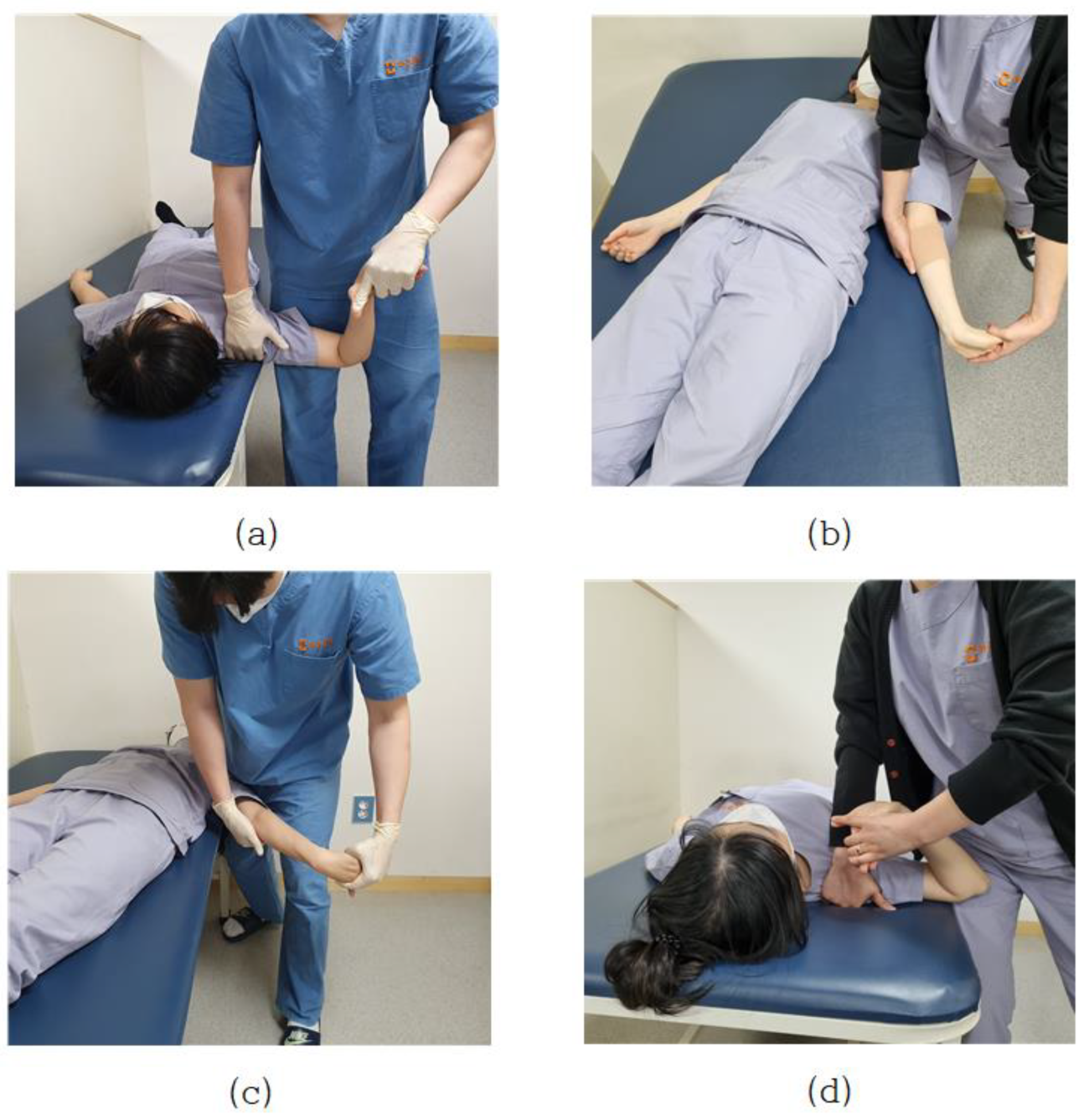
2.1. ULTT Clinical Settings
2.2. Deep Structured Learning Experimental Settings
2.3. Video Collection
2.4. Dataset and Preprocessing
2.5. Working with the Dataset
2.5.1. Extracting Features from the Frames Using CNN
2.5.2. Loss Function
2.5.3. Saving the Best Model and Classifying Videos
3. Results
4. Discussion
5. Conclusions
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Data Availability Statement
Acknowledgments
Conflicts of Interest
References
- Taylor, G.W.; Fergus, R.; LeCun, Y.; Bregler, C. Convolutional Learning of Spatio-Temporal Features. In Computer Vision—ECCV 2010; Daniilidis, K., Maragos, P., Paragios, N., Eds.; Springer: Berlin/Heidelberg, Germany, 2010; pp. 140–153. [Google Scholar]
- Tran, D.; Bourdev, L.; Fergus, R.; Torresani, L.; Paluri, M. Learning Spatiotemporal Features with 3D Convolutional Networks. In Proceedings of the 2015 IEEE International Conference on Computer Vision (ICCV), Santiago, Chile, 7–13 December 2015; pp. 4489–4497. [Google Scholar]
- Woo, D.-C.; Moon, H.S.; Kwon, S.; Cho, Y. A Deep Learning Application for Automated Feature Extraction in Transaction-based Machine Learning. J. Inf. Technol. Serv. 2019, 18, 143–159. [Google Scholar] [CrossRef]
- Jordan, M.; Mitchell, T.M. Machine Learning: Trends, Perspectives, and Prospects. Science 2015, 349, 255–260. [Google Scholar] [CrossRef] [PubMed]
- Baccouche, M.; Mamalet, F.; Wolf, C.; Garcia, C.; Baskurt, A. Sequential Deep Learning for Human Action Recognition. In Human Behavior Understanding; Salah, A.A., Lepri, B., Eds.; Springer: Berlin/Heidelberg, Germany, 2011; pp. 29–39. [Google Scholar]
- Ji, S.; Xu, W.; Yang, M.; Yu, K. 3D Convolutional Neural Networks for Human Action Recognition. IEEE Trans. Pattern Anal. Mach. Intell. 2013, 35, 221–231. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Donahue, J.; Anne Hendricks, L.; Guadarrama, S.; Rohrbach, M.; Venugopalan, S.; Saenko, K.; Darrell, T. Long-Term Recurrent Convolutional Networks for Visual Recognition and Description. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Boston, MA, USA, 7–12 June 2015; pp. 2625–2634. [Google Scholar]
- Ng, J.Y.-H.; Hausknecht, M.; Vijayanarasimhan, S.; Vinyals, O.; Monga, R.; Toderici, G. Beyond Short Snippets: Deep Networks for Video Classification. In Proceedings of the 2015 IEEE Conference on Computer Vision and Pattern Recognition (CVPR), Boston, MA, USA, 7–12 June 2015; pp. 4694–4702. [Google Scholar]
- Tran, A.; Cheong, L.-F. Two-Stream Flow-Guided Convolutional Attention Networks for Action Recognition. In Proceedings of the 2017 IEEE International Conference on Computer Vision Workshops (ICCVW), Venice, Italy, 22–29 October 2017; pp. 3110–3119. [Google Scholar]
- Baisware, A.; Sayankar, B.; Hood, S. Review on Recent Advances in Human Action Recognition in Video Data. In Proceedings of the 2019 9th International Conference on Emerging Trends in Engineering and Technology—Signal and Information Processing (ICETET-SIP-19), Nagpur, India, 1–2 November 2019; pp. 1–5. [Google Scholar]
- Roubleh, A.A.; Khalifa, O.O. Video Based Human Activities Recognition Using Deep Learning; AIP Publishing LLC.: Shah Alam, Malaysia, 2020; p. 020023. [Google Scholar]
- Ballas, N.; Yao, L.; Pal, C.; Courville, A. Delving Deeper into Convolutional Networks for Learning Video Representations. arXiv 2016, arXiv:1511.06432. [Google Scholar]
- Abiodun, O.I.; Jantan, A.; Omolara, A.E.; Dada, K.V.; Mohamed, N.A.; Arshad, H. State-of-the-Art in Artificial Neural Network Applications: A Survey. Heliyon 2018, 4, e00938. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Tealab, A. Time Series Forecasting Using Artificial Neural Networks Methodologies: A Systematic Review. Future Comput. Inform. J. 2018, 3, 334–340. [Google Scholar] [CrossRef]
- He, K.; Zhang, X.; Ren, S.; Sun, J. Identity Mappings in Deep Residual Networks. In Computer Vision—ECCV 2016; Leibe, B., Matas, J., Sebe, N., Welling, M., Eds.; Springer International Publishing: Cham, Switzerland, 2016; pp. 630–645. [Google Scholar]
- Sandler, M.; Howard, A.; Zhu, M.; Zhmoginov, A.; Chen, L.-C. MobileNetV2: Inverted Residuals and Linear Bottlenecks. In Proceedings of the 2018 IEEE/CVF Conference on Computer Vision and Pattern Recognition, Salt Lake City, UT, USA, 18–23 June 2018; pp. 4510–4520. [Google Scholar]
- Zoph, B.; Vasudevan, V.; Shlens, J.; Le, Q.V. Learning Transferable Architectures for Scalable Image Recognition. In Proceedings of the 2018 IEEE/CVF Conference on Computer Vision and Pattern Recognition, Salt Lake City, UT, USA, 18–23 June 2018; pp. 8697–8710. [Google Scholar]
- Pareek, P.; Thakkar, A. A Survey on Video-Based Human Action Recognition: Recent Updates, Datasets, Challenges, and Applications. Artif. Intell. Rev. 2021, 54, 2259–2322. [Google Scholar] [CrossRef]
- Tack, C. Artificial Intelligence and Machine Learning|Applications in Musculoskeletal Physiotherapy. Musculoskelet. Sci. Pract. 2019, 39, 164–169. [Google Scholar] [CrossRef] [PubMed]
- Bedard, N.A.; Schoenfeld, A.J.; Kim, S.C. Large Database Research Discussion Group Optimum Designs for Large Database Research in Musculoskeletal Pain Management. J. Bone Joint Surg. Am. 2020, 102 (Suppl. S1), 54–58. [Google Scholar] [CrossRef] [PubMed]
- Fernandez, J.; Dickinson, A.; Hunter, P. Population Based Approaches to Computational Musculoskeletal Modelling. Biomech. Model. Mechanobiol. 2020, 19, 1165–1168. [Google Scholar] [CrossRef] [PubMed]
- Jena, P.K. Impact of COVID-19 on Higher Education in India; Social Science Research Network: Rochester, NY, USA, 2020. [Google Scholar]
- MacDonald, C.W.; Lonnemann, E.; Petersen, S.M.; Rivett, D.A.; Osmotherly, P.G.; Brismée, J.M. COVID 19 and Manual Therapy: International Lessons and Perspectives on Current and Future Clinical Practice and Education. J. Man. Manip. Ther. 2020, 28, 134–145. [Google Scholar] [CrossRef] [PubMed]
- Rahmad, N.A.; As’ari, M.A.; Ghazali, N.F.; Shahar, N.; Sufri, N.A.J. A Survey of Video Based Action Recognition in Sports. IJEECS 2018, 11, 987. [Google Scholar] [CrossRef]
- Upper Limb Tension Tests as Tools in the Diagnosis of Nerve and Plexus Lesions: Anatomical and Biomechanical Aspects—ScienceDirect. Available online: https://www.sciencedirect.com/science/article/abs/pii/S026800339900042X (accessed on 12 September 2021).
- Clinical Neurodynamics—1st Edition. Available online: https://www.elsevier.com/books/clinical-neurodynamics/shacklock/978-0-7506-5456-2 (accessed on 12 September 2021).
- Kleinrensink, G.J.; Stoeckart, R.; Mulder, P.G.; Hoek, G.; Broek, T.; Vleeming, A.; Snijders, C.J. Upper Limb Tension Tests as Tools in the Diagnosis of Nerve and Plexus Lesions. Anatomical and Biomechanical Aspects. Clin. Biomech. 2000, 15, 9–14. [Google Scholar] [CrossRef]
- Musculoskeletal Examination, 4th ed.; Wiley: Hoboken, NJ, USA, 2015; Available online: https://www.wiley.com/en-ad/Musculoskeletal+Examination%2C+4th+Edition-p-9781118962763 (accessed on 12 September 2021).
- Reliability of Elbow Extension, Sensory Response, and Structural Differentiation of Upper Limb Tension Test A in a Healthy, Asymptomatic Population—IOS Press. Available online: https://content.iospress.com/articles/physiotherapy-practice-and-research/ppr190130 (accessed on 12 September 2021).
- The Effectiveness of Tensioning Neural Mobilization of Brachial Plexus in Patients with Chronic Cervical Radiculopathy: A Randomized Clinical Trial—ProQuest. Available online: https://www.proquest.com/openview/fd14d5270653689800cd7e2841441855/1?pq-origsite=gscholar&cbl=2026484 (accessed on 12 September 2021).
- Concordance of Upper Limb Neurodynamic Tests With Medical Examination and Magnetic Resonance Imaging in Patients With Cervical Radiculopathy: A Diagnostic Cohort Study—ScienceDirect. Available online: https://www.sciencedirect.com/science/article/abs/pii/S0161475413002352 (accessed on 12 September 2021).
- Rafiq, M.; Rafiq, G.; Agyeman, R.; Choi, G.S.; Jin, S.-I. Scene Classification for Sports Video Summarization Using Transfer Learning. Sensors 2020, 20, 1702. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Yasir Farhad, M.; Hossain, S.; Rezaul Karim Tanvir, M.D.; Ameen Chowdhury, S. Sports-Net18: Various Sports Classification Using Transfer Learning. In Proceedings of the 2020 2nd International Conference on Sustainable Technologies for Industry 4.0 (STI), Dhaka, Bangladesh, 19–20 December 2020; pp. 1–4. [Google Scholar]
- Enhancing Anomaly Detection in Surveillance Videos with Transfer Learning from Action Recognition|Proceedings of the 28th ACM International Conference on Multimedia. Available online: https://dl.acm.org/doi/10.1145/3394171.3416298 (accessed on 14 November 2021).
- Chakraborty, S.; Mondal, R.; Singh, P.K.; Sarkar, R.; Bhattacharjee, D. Transfer Learning with Fine Tuning for Human Action Recognition from Still Images. Multimed. Tools Appl. 2021, 80, 20547–20578. [Google Scholar] [CrossRef]
- Bilal, M.; Maqsood, M.; Yasmin, S.; Hasan, N.U.; Rho, S. A Transfer Learning-Based Efficient Spatiotemporal Human Action Recognition Framework for Long and Overlapping Action Classes. J. Supercomput. 2021, 1–36. [Google Scholar] [CrossRef]
- A Web Application Supported Learning Environment for Enhancing Classroom Teaching and Learning Experiences—ScienceDirect. Available online: https://www.sciencedirect.com/science/article/pii/S1877042812049786 (accessed on 14 April 2021).
- Bhattacharya, S.; Shaw, V.; Singh, P.K.; Sarkar, R.; Bhattacharjee, D. SV-NET: A Deep Learning Approach to Video Based Human Activity Recognition. In 11th International Conference on Soft Computing and Pattern Recognition (SoCPaR 2019); Abraham, A., Jabbar, M.A., Tiwari, S., Jesus, I.M.S., Eds.; Advances in Intelligent Systems and Computing; Springer International Publishing: Cham, Switzerland, 2021; Volume 1182, pp. 10–20. ISBN 978-3-030-49344-8. [Google Scholar]
- Wada, H.; Gabazza, E.C.; Asakura, H.; Koike, K.; Okamoto, K.; Maruyama, I.; Shiku, H.; Nobori, T. Comparison of Diagnostic Criteria for Disseminated Intravascular Coagulation (DIC): Diagnostic Criteria of the International Society of Thrombosis and Hemostasis and of the Japanese Ministry of Health and Welfare for Overt DIC. Am. J. Hematol. 2003, 74, 17–22. [Google Scholar] [CrossRef] [PubMed]
- Sirsat, M.S.; Fermé, E.; Câmara, J. Machine Learning for Brain Stroke: A Review. J. Stroke Cerebrovasc. Dis. 2020, 29, 105162. [Google Scholar] [CrossRef] [PubMed]
- Heo, J.; Yoon, J.G.; Park, H.; Kim, Y.D.; Nam, H.S.; Heo, J.H. Machine Learning-Based Model for Prediction of Outcomes in Acute Stroke. Stroke 2019, 50, 1263–1265. [Google Scholar] [CrossRef] [PubMed]
- Ouahabi, A.; Taleb-Ahmed, A. Deep learning for real-time semantic segmentation: Application in ultrasound imaging. Pattern Recognit. Lett. 2021, 144, 27–34. [Google Scholar]








{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| ULTT 1 | ULTT2A | ULTT2B | ULTT3 |
|---|---|---|---|
|
|
|
|
| Model | Training Loss | Training Accuracy | Validation Loss | Validation Accuracy |
|---|---|---|---|---|
| Xception | 0.0012 | 0.9999 | 0.0014 | 0.9999 |
| InceptionV3 | 0.0016 | 0.9998 | 0.0024 | 0.9996 |
| DenseNet201 | 0.0037 | 0.9998 | 0.0033 | 0.9996 |
| NASNetMobile | 0.0151 | 0.9977 | 0.0173 | 0.9967 |
| DenseNet121 | 0.0181 | 0.9972 | 0.0197 | 0.9965 |
| VGG16 | 0.1962 | 0.9619 | 0.1973 | 0.9605 |
| VGG19 | 0.242 | 0.9491 | 0.2418 | 0.9467 |
| ResNet101 | 0.6044 | 0.8093 | 0.6053 | 0.8102 |
Publisher’s Note: MDPI stays neutral with regard to jurisdictional claims in published maps and institutional affiliations. |
© 2021 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Choi, W.; Heo, S. Deep Learning Approaches to Automated Video Classification of Upper Limb Tension Test. Healthcare 2021, 9, 1579. https://doi.org/10.3390/healthcare9111579
Choi W, Heo S. Deep Learning Approaches to Automated Video Classification of Upper Limb Tension Test. Healthcare. 2021; 9(11):1579. https://doi.org/10.3390/healthcare9111579
Chicago/Turabian StyleChoi, Wansuk, and Seoyoon Heo. 2021. "Deep Learning Approaches to Automated Video Classification of Upper Limb Tension Test" Healthcare 9, no. 11: 1579. https://doi.org/10.3390/healthcare9111579
APA StyleChoi, W., & Heo, S. (2021). Deep Learning Approaches to Automated Video Classification of Upper Limb Tension Test. Healthcare, 9(11), 1579. https://doi.org/10.3390/healthcare9111579