Abstract
This study aimed to determine the feasibility of applying machine-learning methods to assess the progression of chronic kidney disease (CKD) in patients with coronavirus disease (COVID-19) and acute renal injury (AKI). The study was conducted on patients aged 18 years or older who were diagnosed with COVID-19 and AKI between April 2020 and March 2021, and admitted to a second-level hospital in Mérida, Yucatán, México. Of the admitted patients, 47.92% died and 52.06% were discharged. Among the discharged patients, 176 developed AKI during hospitalization, and 131 agreed to participate in the study. The study’s results indicated that the area under the receiver operating characteristic curve (AUC-ROC) for the four models was 0.826 for the support vector machine (SVM), 0.828 for the random forest, 0.840 for the logistic regression, and 0.841 for the boosting model. Variable selection methods were utilized to enhance the performance of the classifier, with the SVM model demonstrating the best overall performance, achieving a classification rate of 99.8% ± 0.1 in the training set and 98.43% ± 1.79 in the validation set in AUC-ROC values. These findings have the potential to aid in the early detection and management of CKD, a complication of AKI resulting from COVID-19. Further research is required to confirm these results.
1. Introduction
The incidence of acute kidney injury (AKI) triggered by COVID-19 varies from 0.5% to 58.6% depending on the different definitions employed and the various populations studied [1]. AKI in COVID-19 patients has multiple pathophysiological mechanisms, including direct tubular damage induced by the virus, loss of the brush border, toxic-induced tubular damage (rhabdomyolysis), non-ischemic vacuolar degeneration, glomerular damage, AKI associated with sepsis, and microvascular dysfunction (thrombotic disease with a high risk of fibrin thrombus formation in the pulmonary blood vessels and renal microvasculature) [2]. AKI increases the risk of developing chronic kidney disease (CKD) by eight times [3]. Therefore, it is crucial to identify patients at risk of CKD progression after AKI. Efforts have been made to use multivariate analysis to identify patients who will develop CKD; however, its usefulness is limited [4,5]. Modern statistical tools have been employed to identify cohorts of individuals within a population, encompassing artificial intelligence [6]. Given that the response variable was binary (CKD vs. no CKD), it was appropriate to utilize supervised learning classification, which is a type of artificial intelligence [7]. In this study, we investigated the feasibility of four supervised learning methods, namely support vector machine (SVM), random forest (RF), logistic regression (LR), and boosting, for the classification of patients who will progress to post-AKI CKD due to COVID-19.
2. Materials and Methods
2.1. Study Type and Design
This study is a cross-sectional ambispective (merge historical data with future follow-ups, allowing researchers to analyze both pre-existing and newly collected information) [8], and a prolective approach (captures data in real-time during the occurrence of causal phenomenon; the baseline state is initially documented, then the intervention, and finally the outcome) [9].
2.2. Population, Setting, and Period of Study
The study population comprised all adult patients who were discharged to the community after being hospitalized at the Regional General Hospital of the National Medical Center of Ignacio García Téllez of Instituto Mexicano del Seguro Social (IMSS), a second-level hospital located in Mérida, Yucatán, México, for COVID-19 and AKI between 1 April 2020 and 31 March 2021.
The inclusion criteria for the study were as follows: patients aged ≥ 18 years who had been hospitalized for COVID-19, diagnosed by molecular or antigenic testing for SARS-CoV-2, developed AKI during their hospital stay, and agreed to participate by signing an informed consent form. The following were the exclusion criteria: patients who passed away during hospitalization or after being discharged from COVID-19, those who received renal replacement therapy before contracting COVID-19, those who underwent renal transplantation, those who experienced SARS-CoV-2 reinfection, those with incomplete data, those refused to participate, and those who withdrew from the study.
2.3. Definitions
The degree of severity of COVID-19 was defined according to the criteria established by the World Health Organization [10]:
- Asymptomatic was characterized by the absence of symptoms.
- Mild disease was defined as symptomatic patients who met the case definition for COVID-19, without evidence of viral pneumonia or hypoxia.
- Moderate disease involved clinical signs of pneumonia, including fever, cough, dyspnea, and fast breathing, but there were no signs of severe pneumonia, with an SpO2 level of 90% or higher while breathing room air.
- Severe disease involved clinical signs of pneumonia, along with one of the following: a respiratory rate of over 30 breaths per minute, severe respiratory distress, or an SpO2 level below 90% while breathing room air.
- Critical disease was characterized by the presence of acute respiratory distress syndrome (ARDS).
The estimated glomerular filtration rate (eGFR) was calculated using a blood sample obtained after at least 8 h of fasting to measure the serum creatinine levels. The eGFR was estimated using the equation formulated by the Chronic Kidney Disease Epidemiology Collaboration (CKD-EPI 2021) [11]. AKI was defined as follows.
- Stage 1: creatinine increase ≥ 0.3 mg/dL or ≥150–200% of the baseline.
- Stage 2: creatinine increase ≥ 200–300% of the baseline.
- Stage 3: creatinine increases of ≥300% of the baseline or a serum creatinine level > 4 mg/dL with a sudden increase of at least 0.5 mg/dL [12].
Progression to CKD was defined based on the criteria of the Kidney Disease Quality Outcomes Initiative (K-DOQI) as a decrease in the glomerular filtration rate, as measured by the CKD-EPI 2021 formula, of greater than 25 mL/min/1.73 m2 in two measurements with an interval of >3 months, accompanied by a negative change in CKD staging. CKD staging was determined based on the K-DOQI [13].
2.4. Data Source of AKI and CKD Progression
The data used in this study were extracted from the Epidemiological Capture System, which is a comprehensive hospital database. Retrospectively, clinical data were extracted and analyzed from the electronic health records of patients who were hospitalized with COVID-19. These records contain extensive information about patients, including their demographic characteristics, vital sign monitoring, laboratory tests, imaging tests, drug treatments, length of stay, and discharge or death records.
To estimate the renal function of patients before hospitalization, serum creatinine values were obtained from the Comprehensive Laboratory System between 7 and 365 days before hospitalization. Additionally, patients’ laboratory information was linked to their specific hospital stay to assess the reliability of the subject selection process and data collection. There are no therapeutic guidelines for the management of AKI in patients with COVID-19, and conventional care for this condition was employed. This involves maintaining an adequate hemodynamic status, avoiding the use of potentially nephrotoxic drugs, and closely monitoring both clinical and biochemical parameters. Extracorporeal renal therapy was not administered in any patient. To validate the accuracy of the data, a team of external personnel randomly selected 20% of the patient records by using a random table and confirmed the information.
This study enrolled patients who experienced AKI and were subsequently discharged from the hospital. These individuals were invited to participate in the study and were contacted by the study team via phone to discuss the purpose of the research and address any questions they may have had. On the day of their initial consultation, participants received a letter of informed consent. CKD progression was determined through two medical consultations that were held three months apart and included comprehensive clinical assessments, such as vital signs, anthropometric measurements, and physical examinations. Blood and urine samples were collected and analyzed, and the resulting data were documented in a data-collection format. Patients with CKD progression were identified by comparing the creatinine values obtained from discharge and prospective consultations.
The follow-up period was structured as follows: two medical visits with a nephrologist were arranged for medical evaluation and data verification, with the first scheduled one month after hospital discharge and the second three months after the initial visit. At the initial consultation, the participants were provided with an informed consent letter and telephone number for contact in case of clinical discomfort or the need for external medical intervention. Throughout the follow-up period, patients followed the protocols established by the Secretary of Health of Mexico for the medical care of COVID-19 patients during a health contingency. If they missed any scheduled appointments, they were proactively located and followed up.
2.5. Prediction Variables
The following predictor variables were obtained during hospitalization: (1) demographic features, including age, sex, and body mass index; (2) comorbidities, such as hypertension, diabetes, obesity, cardiovascular disease, and kidney disease; (3) information on the number of days in hospital, severity of COVID-19, and severity of AKI; (4) laboratory parameters, including hematological parameters, glucose, creatinine, blood urea nitrogen, sodium, potassium, total bilirubin, albumin, alanine transaminase, aspartate transaminase, and lactate dehydrogenase; and (5) therapeutic and clinical management, including mechanical ventilation and vasopressor use. It is important to note that all patients received the same medical and pharmacological care and treatment was not considered a variable.
2.6. Data Preprocessing
To mitigate the potential bias caused by missing data, variables with more than 20% missing values were not considered in the analysis. Of the 44 variables included, only 4 had missing values, accounting for more than 6%. We used the available values of the variable containing missing data to determine the median, which represented the central value in the dataset. Subsequently, we substituted the missing data with computed median values. Finally, the Z-score method was used to standardize the variables.
To ensure balanced data distribution among the groups, the random oversampling (ROS) and Tomek’s link subsampling methods were employed. ROS increases the minority class without losing information, whereas the Tomek’s link method identifies the majority class elements closest to the minority class and removes them to highlight class distinctions [14]. Feature selection is an integral part of model construction, and we implemented five variable selection methods to identify the most crucial features: ROC and p-value plots, SHAP (Shapley additive explanations, determine the significance of the features and their impact on the final predictions [15]), principal component analysis (uses uncorrelated variables called principal components to describe a dataset [16]), and forward and backward regression. Two additional regression-based selections were later developed and employed only the hospital admission data.
2.7. Data Analysis
Descriptive statistics were used to analyze the demographic and clinical features of the patients. Descriptive statistics were used to summarize the continuous variables (means and standard deviations, medians, interquartile ranges, or frequency counts and percentages).
Continuous variables were compared between patients with and without composite events using an unpaired Student’s t-test or Mann–Whitney U test, as appropriate, and categorical variables were compared using the chi-square test or Fisher’s exact test.
For supervised learning, four machine-learning algorithms (SVM, RF, LR, and boosting) were used to train the models. The data employed for the model development were randomly divided into two parts, with 80% of the data utilized for training and the remaining 20% for internal validation. The optimal parameters for each algorithm were selected by grid search using 10-fold cross-validation based on the performance metrics (with preference given to the highest possible area under the curve [AUC]).
SVM is a classification algorithm that employs a hyperplane to separate data into distinct classes with the objective of maximizing the margin between them. To achieve this, the algorithm identifies the hyperplane that provides the greatest margin by evaluating the distance between each observation and prospective hyperplane. Once the hyperplane with the maximum margin has been determined, the test observations can be classified by reference to the side of the hyperplane on which they are situated. SVM may also employ different kernels to address nonlinearity [17].
RF is a machine-learning algorithm utilized for classification that employs a strategy of constructing multiple decision trees on randomly selected subsets of the training data and then combining their predictions to formulate a final prediction. Each tree in the forest was established using a distinct subset of features and a different subset of training data to mitigate overfitting and enhance the accuracy of the model. The ultimate prediction was derived by tabulating the majority vote for all the trees in the forest [18].
RL is a statistical approach used for binary classification problems, in which the output variable can only attain two possible values. It assesses the probability of an event transpiring based on input variables using a sigmoid function. The parameters of the logistic function are determined via maximum likelihood estimation, which is a statistical method for determining the values of the parameters that maximize the likelihood of observing data [19].
Boosting is a machine-learning technique that merges multiple elementary models, known as weak learners, to create a more precise and intricate model. The procedure involves sequentially adding new weak learners to the model, with each new learner concentrating on the inaccuracies of the previous learners. This methodology enables the model to enhance its accuracy gradually over time [20].
2.8. Metrics for Evaluating Model Performance
To evaluate the effectiveness of the models, we calculated their sensitivity and specificity and used the AUC as a metric to compare the performance of the machine-learning algorithm models. Additionally, we employed secondary metrics for the machine-learning models, such as accuracy, precision, recall, and F1-score, to further evaluate their performance. Accuracy measures the proportion of correctly predicted outcomes, precision represents the proportion of correctly identified positive cases among all the predicted positives, the recall score assesses the model’s ability to identify positive instances from actual positives, and the F1-score, which is the harmonic mean of precision and sensitivity, provides a comprehensive measure of the model’s overall output quality [21].
Analyses were conducted utilizing IBM SPSS Statistics version 24 and Python 3.11.3, which were obtained from the Python Software Foundation (Python 3.11.4 64-bit|Qt 5.15.2|PyQt5 5.15.7|Windows 10), available at http://www.python.org, accessed on 14 August 2023.
3. Results
3.1. Population, Setting, and Period of Study
Between 1 April 2020 and 31 July 2021, 3398 patients were admitted to our hospital with COVID-19. Of these, 1620 (47.92%) unfortunately passed away, while 1769 (52.06%) were discharged. We thoroughly examined the medical records and laboratory results of the discharged patients to identify those who developed AKI during hospitalization for COVID-19. A total of 176 (176/1769; 9.9%) patients having AKI met the rest of the inclusion criteria, but just 131 (131/176; 74.4%) consented to participate in our study and completed the follow-up process (Figure 1). Of our study population, 40 patients progressed to CKD (40/131; 30.5%).
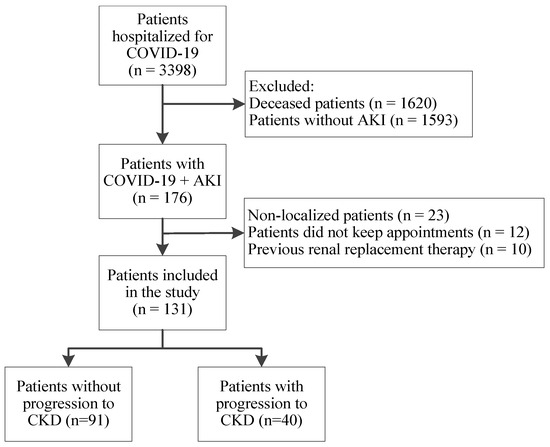
Figure 1.
The flowchart of patient selection.
3.2. Clinical and Epidemiological Characteristics of the Cohort
The relevant clinical, epidemiological, and laboratory findings are presented in Table 1 and Table S1. The study had an average patient age of approximately 61 years, with no major age discrepancies between the two groups (p = 0.167). The sex distribution was also comparable in both groups (p = 0.917), with approximately 62% of patients being male. Additionally, the non-progression group had a slightly higher body mass index (BMI), but this difference was not statistically significant (p = 0.162). The group that progressed to CKD had a higher prevalence of diabetes (57.5% vs. 33%, p = 0.008) and a lower prevalence of obesity (52.5% vs. 70.3%, p = 0.049). In addition, a history of kidney disease was more common in the group that progressed to CKD (50% vs. 27.5%, p = 0.012). There were no significant differences in the COVID-19 severity grades between the two groups (p = 0.343); however, kidney disease severity at Stage 3 was significantly different, with a higher percentage of patients in the progression group at this stage (20% vs. 5.5%, p = 0.033). There were no significant differences in the number of days spent on oxygen or in the hospital between the two groups. It is worth noting that patients who progressed to CKD had lower levels of hemoglobin during hospitalization (p = 0.008), and at discharge, their lymphocyte percentage decreased significantly (p = 0.003). Furthermore, at discharge, their glucose levels were elevated (p = 0.025) and creatinine levels were elevated (p = 0.006) compared with those in patients who did not progress to CKD.

Table 1.
Distribution of the clinical and laboratory variables a between the non-CKD progression and CKD progression.
3.3. Development and Internal Validation of the Predictive Models
Tables S2, S3, and Table 2 present a detailed analysis of the training, testing, and validation of the performance metrics of the multiple algorithms measured using various subsets of variables. The first column indicates the algorithms and specific subset of variables utilized for each algorithm, whereas the following seven columns display the accuracy, precision, recall, F1-score, sensitivity, specificity, and AUC results for each algorithm.
Table 2.
Concentration of validation results of classifiers with ROS rolling.
The results of the classifier implemented using ROS are noteworthy. In general, the SVM and boosting models performed exceptionally well for all of the metrics and sets of variables. For example, the SVM model achieved an average AUC of 91.58%, whereas the RF model achieved an average AUC of 87.22%. The performance of the RL model was relatively low, with an average AUC of 76.98%. The performance of the boosting model was moderate, with certain metrics exhibiting high values and others exhibiting low values. The overall average AUC was 82.88%. The Tomek’s link subsampling method displayed good results, although its performance in each category was not as good as that of ROS. The results of the Tomek’s link method are not included in the analysis.
Regarding the variable selection methods, the models tended to perform better on the “ROC” variable selection set (Figure 2). The SVM model achieved in the training cohort an AUC of 99.88% (0.11) for predicting composite outcomes and calibration [Brier score: 0.11, Hosmer–Lemeshow test p value = 0.75]. Internal validation confirmed the good discriminability of the predictive model, with a similar AUC of 98.43% (1.79) for predicting composite outcomes and calibration [Brier score: 0.11, Hosmer–Lemeshow test p value = 0.63] (Table 3).
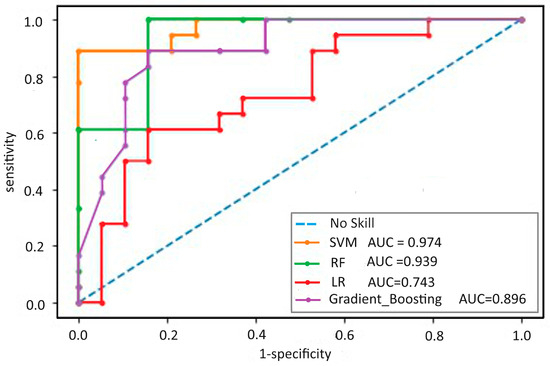
Figure 2.
Receiver operating characteristic curve of the four models; method of variable selection ROC. SVM: support vector machine; RF: random forest; LR: logistic regression; AUC: area under the curve.
Table 3.
Performance of the novel predictive model for composite outcome: method SVM and ROC variable selection.
4. Discussion
In this study, a predictive model for CKD progression in patients with AKI resulting from COVID-19 was developed using machine learning. The sample comprised a higher proportion of men than women (61.8%), which is consistent with the findings of Silver et al. (58.2%) [22]. More than half of the patients had high blood pressure and almost two-thirds were obese, as reported by van Son et al. (71%) [23]. The severity of COVID-19 was highest at Level 4, accounting for more than half of the cases.
Severe AKI was present in approximately one-third of the patients analyzed, and a few patients experienced cardiovascular events during the disease. Notably, the selected patients were COVID-19 survivors with AKI; thus, it is possible that the incidence of cardiovascular conditions was higher in these patients.
Some conditions that can explain the progression to CKD in our patients are as follows: (a) A decrease in the number of nephrons results in an increased filtration rate of the remaining nephrons, leading to elevated filtration pressure. This phenomenon, known as remnant nephron hypertrophy, can cause increased shear stress in podocytes, potentially resulting in their detachment. When this detachment occurs, it can lead to focal and segmental glomerulosclerosis, which can ultimately result in global glomerulosclerosis and nephron atrophy [24,25]; (b) Anemia, which is characterized by a low concentration of hemoglobin in the circulation, results in a reduced oxygen-carrying capacity, leading to tissue hypoxia and potentially impairing renal oxygenation, and is considered a non-conventional factor in CKD progression [26,27,28]; (c) Patients with CKD typically exhibit reduced lymphocyte counts, a characteristic sign associated with increased inflammation. Moreover, a decline in renal function over time leads to the activation and selective loss of T cells and CD4+ cells, while CD8+ cells significantly increase [29,30]; (d) Glucose filtration and glomerular hyperfiltration lead to tubular hyperreabsorption of glucose and sodium, resulting in glomerular and tubular hypertrophy. Over time, this can result in glomerulosclerosis and tubule atrophy [31].
To ensure the highest accuracy of the classifier, we purposefully excluded variables with missing values that were originally intended to be included in the model. These variables, such as D-dimer, were not mandatory to study in all COVID-19 hospitalized patients, even though they have been linked to a poor prognosis [32].
To enhance the utility of the classifier in a clinical setting, it is recommended to restrict the number of variables incorporated into the classifier. In this study, we evaluated the stability of the models under various scenarios using seven variable-selection methods. The results revealed that ROC analysis was the most effective method for selecting the optimal variables. This may be attributed to the fact that the ROC curve is less prone to variations in the scale and threshold of probabilities, thereby making it a reliable method for variable selection [33].
Of the classifiers utilized, the SVM generated the most favorable results. One explanation for the superior performance of the SVM is its capacity to effectively manage the nonlinear relationships between the features and target variables. Decision trees, on the other hand, rely on linear relationships, and can therefore struggle with nonlinear relationships [34,35,36,37]. In addition, the SVM is more robust to outliers than LR, RF, and boosting. These methods are sensitive to data values [38]. SVM demonstrates advantages over other learning methods and is often preferable for patient classification tasks because of its ability to handle nonlinear relationships and its robustness to outliers.
When interpreting the findings of the study, it is of the utmost importance to consider the following factors: (1) urine output was not included in the definition of AKI; (2) the study population did not receive COVID-19 vaccination, which may have influenced the natural progression of the disease; (3) the results only pertained to patients who survived hospitalization for COVID-19 and not those who were admitted and subsequently passed away; and (4) while the models displayed exceptional performance in predicting the progression to CKD during training and internal validation, external validation is necessary to confirm their accuracy.
To date, most clinical studies that have employed machine-learning methodologies have focused on the development and validation of risk classification models for predicting the occurrence of AKI in hospitalized patients [39,40,41,42,43] and the onset of AKI in critically ill patients in intensive care units [44,45]. Additionally, some studies have addressed chronic outcomes such as death at discharge, initiation, or discontinuation of renal replacement therapy, or specific CKD stages [46,47,48,49,50]. However, studies on CKD progression at all stages after AKI, which is a major adverse kidney condition, have received limited attention. The classification methods that have been studied can be applied to various entities that contribute to a decline in kidney function, such as post-surgery kidney cancer, by incorporating predictor variables such as preoperative proteinuria [51], thereby expanding their range of application.
Post-hospitalization AKI patient follow-up represents a significant challenge owing to the combination of two factors: the process is both time-consuming and expensive, and patients tend to drop out of follow-up care [52]. It is crucial to address these challenges because CKD is a potentially dangerous condition that requires careful management. The utilization of these risk classification tools may be critical for targeting strategies to optimize the care of high-risk progressive CKD patients in specialized post-discharge clinics, which can aid in the promotion of kidney and critical illness recovery and enhance patient-centered outcomes that are more likely to benefit from the intervention [53,54]. Lastly, the clinical significance of the proposed method lies in its potential to accurately identify high-risk individuals for CKD using readily available information prior to hospital discharge. This enables health care providers to make informed decisions about future care. The development of a user-friendly application (app) for convenient access to information and its appropriate categorization is a future possibility.
5. Conclusions
In this study, we showed that the four classifiers (SVM, RF, LR, and boosting) successfully identified patients who developed CKD after AKI caused by COVID-19. The SVM model demonstrated the best overall performance, achieving a classification rate of 99.8% ± 0.1 in the training set and 98.43% ± 1.79 in the validation set. These results were obtained using the ROS-balancing method and the selection of variables using the ROC. The models analyzed are promising for medical decision making; however, further research in this field is required.
Supplementary Materials
The following supporting information can be downloaded at: https://www.mdpi.com/article/10.3390/biomedicines12071511/s1, Table S1: Distribution of the laboratory variables between the no CKD progression and CKD progression; Table S2: Concentration of training results of classifiers with ROS rolling; Table S3: Concentration of test results for classifiers with ROS rolling.
Author Contributions
Conceptualization, C.G.-O., G.M.M.-S. and R.G.-H.; methodology, C.G.-O. and G.M.M.-S.; data curation, C.G.-O., R.G.-H. and C.B.-L.; validation, C.G.-O. and R.G.-H.; formal analysis, C.G.-O. and R.G.-H.; investigation, C.G.-O., G.M.M.-S., A.H.U.-C. and J.R.P.-S.; resources, C.G.-O. and G.M.M.-S.; writing—original draft preparation, C.G.-O., G.M.M.-S., A.H.U.-C. and J.R.P.-S.; writing—review and editing, C.G.-O., G.M.M.-S., R.G.-H., C.B.-L., A.H.U.-C. and J.R.P.-S.; supervision, C.G.-O. and G.M.M.-S.; project administration C.G.-O. All authors have read and agreed to the published version of the manuscript.
Funding
This research received no external funding.
Institutional Review Board Statement
This study was conducted in accordance with the Declaration of Helsinki, and approved by the National Scientific, Biosafety, and Ethics Committees of Instituto Mexicano del Seguro Social (protocol number R-2021-785-051 and approved on 19 May 2021) for studies involving humans.
Informed Consent Statement
Informed consent was obtained from all the subjects involved in the study.
Data Availability Statement
The datasets generated and/or analyzed during the current study are not publicly available because they are the property of the Instituto Mexicano del Seguro Social. Institutional and federal dispositions restrict unlimited access to personal data, but they are available from the corresponding authors upon reasonable request with prior authorization from the institution.
Acknowledgments
This research formed the Doctoral Degree thesis of C.G.-O. at the Universidad Nacional Autónoma de México of the Master’s and Doctorate Program in Medical, Dental and Health Sciences. C.G.-O. is grateful to the Instituto Mexicano del Seguro Social for their scholarship.
Conflicts of Interest
The authors declare no conflicts of interest.
References
- Hassanein, H.; Radhakrishnan, Y.; Sedor, J.; Vachharajani, T.; Vachharajani, V.T.; Augustine, J.; Demirjian, S.; Thomas, G. COVID-19 and the kidney. Clevel. Clin. J. Med. 2020, 87, 619–631. [Google Scholar] [CrossRef] [PubMed]
- Farouk, S.S.; Fiaccadori, E.; Cravedi, P.; Campbell, K.N. COVID-19 and the kidney: What we think we know so far and what we don’t. J. Nephrol. 2020, 33, 1213–1218. [Google Scholar] [CrossRef] [PubMed]
- Coca, S.G.; Singanamala, S.; Parikh, C.R. Chronic kidney disease after acute kidney injury: A systematic review and meta-analysis. Kidney Int. 2012, 81, 442–448. [Google Scholar] [CrossRef] [PubMed]
- Hsu, C.Y.; Chinchilli, V.M.; Coca, S.; Devarajan, P.; Ghahramani, N.; Go, A.S.; Hsu, R.K.; Ikizler, T.A.; Kaufman, J.; Liu, K.D.; et al. Post-acute kidney injury proteinuria and subsequent kidney disease progression: The assessment, serial evaluation, and subsequent sequelae in acute kidney injury (ASSESS-AKI) study. JAMA Intern. Med. 2020, 180, 402–410. [Google Scholar] [CrossRef] [PubMed]
- James, M.T.; Pannu, N.; Hemmelgarn, B.R.; Austin, P.C.; Tan, Z.; McArthur, E.; Manns, B.J.; Tonelli, M.; Wald, R.; Quinn, R.R.; et al. Derivation and external validation of prediction models for advanced chronic kidney disease following acute kidney injury. JAMA 2017, 318, 1787–1797. [Google Scholar] [CrossRef]
- Brereton, R.G.; Lloyd, G.R. Support vector machines for classification and regression. Analyst 2010, 135, 230–267. [Google Scholar] [CrossRef]
- Swapna, G.; Vinayakumar, R.; Soman, K.P. Diabetes detection using deep learning algorithms. ICT Express 2018, 2, 243–246. [Google Scholar]
- Talavera, J.O.; Roy-García, I.; Palacios-Cruz, L.; Rivas-Ruiz, R.; Hoyo, I.; Pérez-Rodríguez, M. Back to the clinic. Methods I. Research designs. Higher quality of information, more certainty to the answer. Gac. Médica México 2023, 155, 3484. [Google Scholar] [CrossRef]
- Wang, C.; Liu, F. (Eds.) Textbook of Clinical Epidemiology: For Medical Students; Springer Nature Singapore: Singapore, 2023. [Google Scholar]
- Living Guidance for Clinical Management of COVID-19. Available online: https://www.who.int/publications-detail-redirect/WHO-2019-nCoV-clinical-2021-2 (accessed on 19 May 2024).
- Inker, L.A.; Eneanya, N.D.; Coresh, J.; Tighiouart, H.; Wang, D.; Sang, Y.; Crews, D.C.; Doria, A.; Estrella, M.M.; Froissart, M.; et al. New creatinine- and cystatin C–based equations to estimate GFR without race. N. Engl. J. Med. 2021, 385, 1737–1749. [Google Scholar] [CrossRef]
- Kellum, J.A.; Lameire, N.; Aspelin, P.; Barsoum, R.S.; Burdmann, E.A.; Goldstein, S.L.; Herzog, C.A.; Joannidis, M.; Kribben, A.; Levey, A.S.; et al. Kidney disease: Improving global outcomes (KDIGO) acute kidney injury work group. KDIGO clinical practice guideline for acute kidney injury. Kidney Int. Suppl. 2012, 2, 1–138. [Google Scholar]
- Kidney Disease: Improving Global Outcomes (KDIGO) CKD Work Group. KDIGO clinical practice guideline for the evaluation and management of chronic kidney disease. Kidney Int. Suppl. 2013, 3, 1–150. [Google Scholar]
- Batista, G.E.A.P.A.; Prati, R.C.; Monard, M.C. A study of the behavior of several methods for balancing machine learning training data. ACM SIGKDD Explor. Newsl. 2004, 6, 20–29. [Google Scholar] [CrossRef]
- Misra, R.; Shyamasundar, R.K.; Chaturvedi, A.; Omer, R. (Eds.) Machine Learning and Big Data Analytics (Proceedings of International Conference on Machine Learning and Big Data Analytics (ICMLBDA) 2021); Lecture Notes in Networks and Systems; Springer International Publishing: Cham, Switzerland, 2022; Volume 256. [Google Scholar]
- Sanguansat, P. Principal Component Analysis—Multidisciplinary Applications; IntechOpen: London, UK, 2012. [Google Scholar] [CrossRef]
- Williams, C.K.I. Learning with Kernels: Support vector machines, regularization, optimization, and beyond. J. Am. Stat. Assoc. 2003, 98, 489. [Google Scholar] [CrossRef]
- Nguyen, J.M.; Jézéquel, P.; Gillois, P.; Silva, L.; Ben Azzouz, F.; Lambert-Lacroix, S.; Juin, P.; Campone, M.; Gaultier, A.; Moreau-Gaudry, A.; et al. Random forest of perfect trees: Concept, performance, applications and perspectives. Bioinformatics 2021, 37, 2165–2174. [Google Scholar] [CrossRef] [PubMed]
- Dreiseitl, S.; Ohno-Machado, L. Logistic regression and artificial neural network classification models: A methodology review. J. Biomed. Inform. 2002, 35, 352–359. [Google Scholar] [CrossRef] [PubMed]
- Schapire, R.E.; Freund, Y. Boosting: Foundations and Algorithms, 1st ed.; The MIT Press: Cambridge, MA, USA, 2012; pp. 23–52. [Google Scholar]
- Cook, N.R. Statistical evaluation of prognostic versus diagnostic models: Beyond the ROC curve. Clin. Chem. 2008, 54, 17–23. [Google Scholar] [CrossRef] [PubMed]
- Silver, S.A.; Beaubien-Souligny, W.; Shah, P.S.; Harel, S.; Blum, D.; Kishibe, T.; Meraz-Munoz, A.; Wald, R.; Harel, Z. The prevalence of acute kidney injury in patients hospitalized with COVID-19 infection: A systematic review and meta-analysis. Kidney Med. 2021, 3, 83–98. [Google Scholar] [CrossRef] [PubMed]
- Van Son, J.; Oussaada, S.M.; Şekercan, A.; Beudel, M.; Dongelmans, D.A.; Van Assen, S.; Eland, I.A.; Moeniralam, H.S.; Dormans, T.P.J.; Van Kalkeren, C.A.J.; et al. Overweight and obesity are associated with acute kidney injury and acute respiratory distress syndrome, but not with increased mortality in hospitalized COVID-19 patients: A retrospective cohort study. Front. Endocrinol. 2021, 12, 747732. [Google Scholar] [CrossRef]
- Romagnani, P.; Remuzzi, G.; Glassock, R.; Levin, A.; Jager, K.J.; Tonelli, M.; Massy, Z.; Wanner, C.; Anders, H.-J. Chronic Kidney Disease. Nat. Rev. Dis. Primers 2017, 3, 17088. [Google Scholar] [CrossRef]
- Helal, I.; Fick-Brosnahan, G.M.; Reed-Gitomer, B.; Schrier, R.W. Glomerular Hyperfiltration: Definitions, Mechanisms and Clinical Implications. Nat. Rev. Nephrol. 2012, 8, 293–300. [Google Scholar] [CrossRef]
- Deicher, R.; Hörl, W.H. Anaemia as a Risk Factor for the Progression of Chronic Kidney Disease. Curr. Opin. Nephrol. Hypertens. 2003, 12, 139. [Google Scholar] [CrossRef] [PubMed]
- Wang, B.; Li, Z.-L.; Zhang, Y.-L.; Wen, Y.; Gao, Y.-M.; Liu, B.-C. Hypoxia and Chronic Kidney Disease. EBioMedicine 2022, 77, 103942. [Google Scholar] [CrossRef] [PubMed]
- Iseki, K.; Kohagura, K. Anemia as a Risk Factor for Chronic Kidney Disease. Kidney Int. 2007, 72, S4–S9. [Google Scholar] [CrossRef] [PubMed]
- Agarwal, R.; Light, R.P. Patterns and Prognostic Value of Total and Differential Leukocyte Count in Chronic Kidney Disease. Clin. J. Am. Soc. Nephrol. 2011, 6, 1393–1399. [Google Scholar] [CrossRef] [PubMed]
- Litjens, N.H.R.; Van Druningen, C.J.; Betjes, M.G.H. Progressive Loss of Renal Function Is Associated with Activation and Depletion of Naive T Lymphocytes. Clin. Immunol. 2006, 118, 83–91. [Google Scholar] [CrossRef] [PubMed]
- Anders, H.-J.; Huber, T.B.; Isermann, B.; Schiffer, M. CKD in Diabetes: Diabetic Kidney Disease versus Nondiabetic Kidney Disease. Nat. Rev. Nephrol. 2018, 14, 361–377. [Google Scholar] [CrossRef] [PubMed]
- Dessie, Z.G.; Zewotir, T. Mortality-related risk factors of COVID-19: A systematic review and meta-analysis of 42 studies and 423,117 patients. BMC Infect. Dis. 2021, 21, 855. [Google Scholar] [CrossRef] [PubMed]
- Li, Y.; Qin, Y.; Wang, L.; Chen, J.; Ma, S. Grouped variable selection using area under the ROC with imbalanced data. Commun. Stat. Simul. Comput. 2016, 45, 1268–1280. [Google Scholar] [CrossRef]
- Cortes, C.; Vapnik, V.; Saitta, L. Support-vector networks. Mach. Learn. 1995, 20, 273–297. [Google Scholar] [CrossRef]
- Piccialli, V.; Sciandrone, M. Nonlinear optimization and support vector machines. 4OR-Q. J. Oper. Res. 2022, 16, 111–149. [Google Scholar] [CrossRef]
- Breiman, L. Random forests. Mach. Learn. 2001, 45, 5–32. [Google Scholar] [CrossRef]
- Ferreira, J.A. Models under which random forests perform badly; consequences for applications. Comput. Stat. 2022, 37, 1839–1854. [Google Scholar] [CrossRef]
- Aggarwal, C.C. Outlier Analysis, 2nd ed.; Springer: Cham, Switzerland; New York, NY, USA, 2017; pp. 219–247. [Google Scholar]
- Koyner, J.L.; Carey, K.A.; Edelson, D.P.; Churpek, M.M. The development of a machine learning inpatient acute kidney injury prediction model. Crit. Care Med. 2018, 46, 1070–1077. [Google Scholar] [CrossRef] [PubMed]
- Churpek, M.M.; Carey, K.A.; Edelson, D.P.; Singh, T.; Astor, B.C.; Gilbert, E.R.; Winslow, C.; Shah, N.; Afshar, M.; Koyner, J.L. Internal and external validation of a machine learning risk score for acute kidney injury. JAMA Netw. Open 2020, 3, e2012892. [Google Scholar] [CrossRef] [PubMed]
- Hsu, C.N.; Liu, C.L.; Tain, Y.L.; Kuo, C.Y.; Lin, Y.C. Machine learning model for risk prediction of community-acquired acute kidney injury hospitalization from electronic health records: Development and validation study. J. Med. Internet Res. 2020, 22, e16903. [Google Scholar] [CrossRef]
- Tomašev, N.; Glorot, X.; Rae, J.W.; Zielinski, M.; Askham, H.; Saraiva, A.; Mottram, A.; Meyer, C.; Ravuri, S.; Protsyuk, I.; et al. A clinically applicable approach to continuous prediction of future acute kidney injury. Nature 2019, 572, 116–119. [Google Scholar] [CrossRef]
- Simonov, M.; Ugwuowo, U.; Moreira, E.; Yamamoto, Y.; Biswas, A.; Martin, M.; Testani, J.; Wilson, F.P. A simple real-time model for predicting acute kidney injury in hospitalized patients in the US: A descriptive modeling study. PLoS Med. 2019, 16, e1002861. [Google Scholar] [CrossRef]
- Malhotra, R.; Kashani, K.B.; Macedo, E.; Kim, J.; Bouchard, J.; Wynn, S.; Li, G.; Ohno-Machado, L.; Mehta, R. A risk prediction score for acute kidney injury in the intensive care unit. Nephrol. Dial. Transplant. 2017, 32, 814–822. [Google Scholar] [CrossRef]
- Flechet, M.; Güiza, F.; Schetz, M.; Wouters, P.; Vanhorebeek, I.; Derese, I.; Gunst, J.; Spriet, I.; Casaer, M.; Van den Berghe, G.; et al. AKIpredictor, an online prognostic calculator for acute kidney injury in adult critically ill patients: Development, validation and comparison to serum neutrophil gelatinase-associated lipocalin. Intensive Care Med. 2017, 43, 764–773. [Google Scholar] [CrossRef]
- Gross, C.; Miao Jonasson, J.; Buchebner, D.; Agvall, B. Prognosis and mortality within 90 days in community-acquired acute kidney injury in the Southwest of Sweden. BMC Nephrol. 2023, 24, 171. [Google Scholar] [CrossRef]
- Sawhney, S.; Marks, A.; Fluck, N.; Levin, A.; Prescott, G.; Black, C. Intermediate and long-term outcomes of survivors of acute kidney injury episodes: A large population-based cohort study. Am. J. Kidney Dis. 2017, 69, 18–28. [Google Scholar] [CrossRef] [PubMed]
- Bagshaw, S.M.; Wald, R. Indications and timing of continuous renal replacement therapy application. Contrib. Nephrol. 2018, 194, 25–37. [Google Scholar] [PubMed]
- Schiffl, H. Discontinuation of renal replacement therapy in critically ill patients with severe acute kidney injury: Predictive factors of renal function recovery. Int. Urol. Nephrol. 2018, 50, 1845–1851. [Google Scholar] [CrossRef] [PubMed]
- Jones, J.; Holmen, J.; De Graauw, J.; Jovanovich, A.; Thornton, S.; Chonchol, M. Association of complete recovery from acute kidney injury with incident CKD stage 3 and all-cause mortality. Am. J. Kidney Dis. 2012, 60, 402–408. [Google Scholar] [CrossRef]
- Flammia, R.S.; Tufano, A.; Proietti, F.; Gerolimetto, C.; De Nunzio, C.; Franco, G.; Leonardo, C. Renal Surgery for Kidney Cancer: Is Preoperative Proteinuria a Predictor of Functional and Survival Outcomes after Surgery? A Systematic Review of the Literature. Minerva Urol. Nephrol. 2022, 74, 255–264. [Google Scholar] [CrossRef]
- Siew, E.D.; Liu, K.D.; Bonn, J.; Chinchilli, V.; Dember, L.M.; Girard, T.D.; Greene, T.; Hernandez, A.F.; Alp Ikizler, T.; James, M.T.; et al. Improving care for patients after hospitalization with AKI. J. Am. Soc. Nephrol. 2020, 31, 2237–2241. [Google Scholar] [CrossRef] [PubMed]
- Kurzhagen, J.T.; Dellepiane, S.; Cantaluppi, V.; Rabb, H. AKI: An increasingly recognized risk factor for CKD development and progression. J. Nephrol. 2020, 33, 1171–1187. [Google Scholar] [CrossRef] [PubMed]
- Ruiz-Ortega, M.; Rayego-Mateos, S.; Lamas, S.; Ortiz, A.; Rodrigues-Diez, R.R. Targeting the progression of chronic kidney disease. Nat. Rev. Nephrol. 2020, 16, 269–288. [Google Scholar] [CrossRef]


Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2024 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).