Abstract
Background: Fold change is a common metric in biomedical research for quantifying group differences in omics variables. However, inconsistent calculation methods and inadequate reporting lead to discrepancies in results. This study evaluated various fold-change calculation methods aiming at a recommendation of a preferred approach. Methods: The primary distinction in fold-change calculations lies in defining group expected values for log ratio computation. To challenge method interchangeability in a “stress test” scenario, we generated diverse artificial data sets with varying distributions (identity, uniform, normal, log-normal, and a mixture of these) and compared calculated fold-changes to known values. Additionally, we analyzed a multi-omics biomedical data set to estimate to what extent the findings apply to real-world data. Results: Using arithmetic means as expected values for treatment and reference groups yielded inaccurate fold-change values more frequently than other methods, particularly when subgroup distributions and/or standard deviations differed significantly. Conclusions: The arithmetic mean method, often perceived as standard or picked without considering alternatives, is inferior to other definitions of the group expected value. Methods using median, geometric mean, or paired fold-change combinations are more robust against violations of equal variances or dissimilar group distributions. Adhering to methods less sensitive to data distribution without trade-offs and accurately reporting calculation methods in scientific reports is a reasonable practice to ensure correct interpretation and reproducibility.
1. Introduction
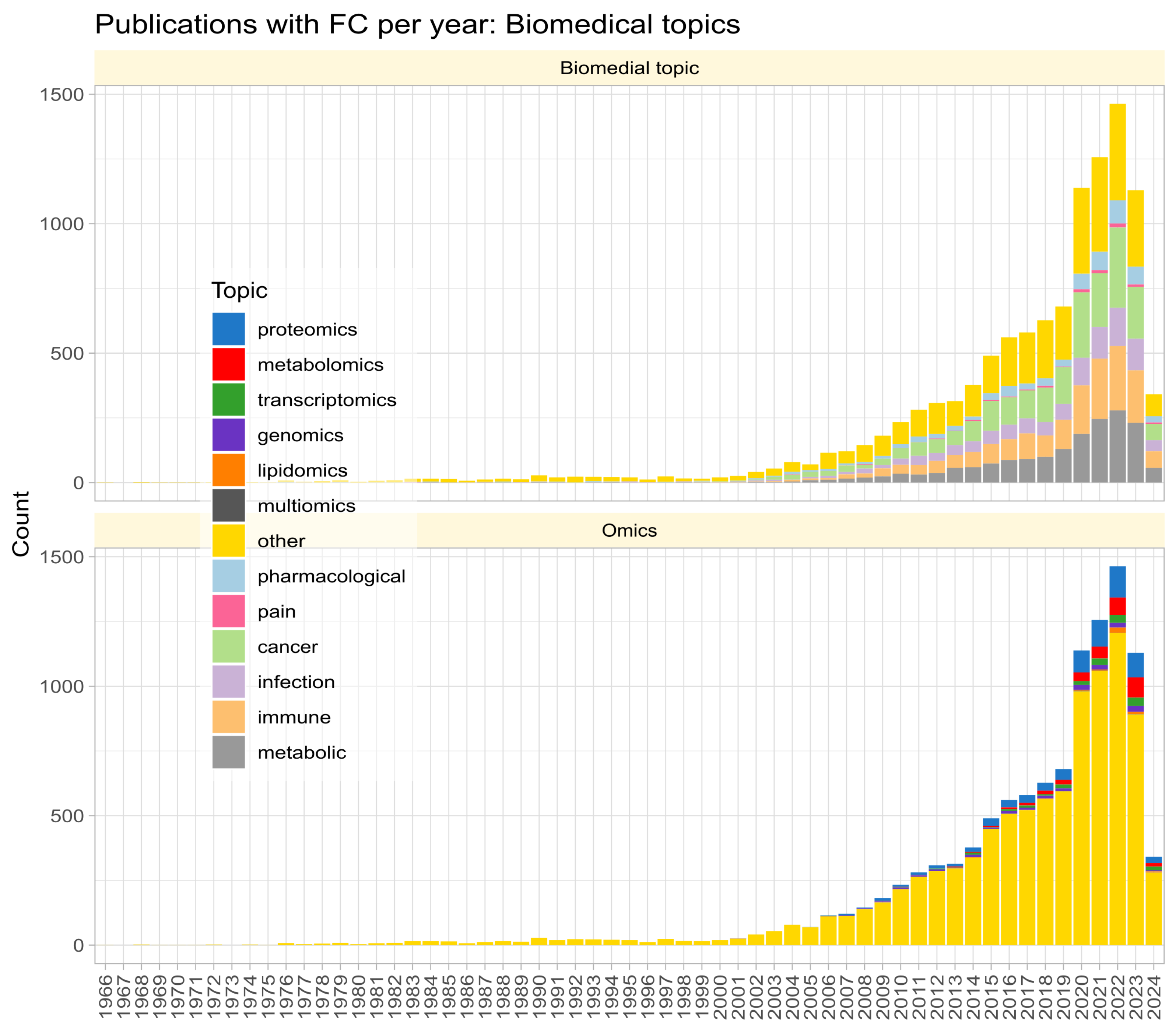
Fold change () is widely used in biomedical research to quantify the magnitude of group differences in omics variables, initially mainly in gene expression studies but nowadays adopted in other “omics” fields and even non-omics research, as evidenced by a PubMed search for “fold change”, where the term was found to be associated with a variety of fields beyond gene expression studies (Figure 1). provides a measure for the crucial step in omics data analysis of selecting subsets of genes or other variables of interest from the initial set of variables, along with other methods such as unusual ratio, univariate testing with -correction for multiple experiments, analysis of variance, and noise sampling methods, comparatively reviewed in [1].
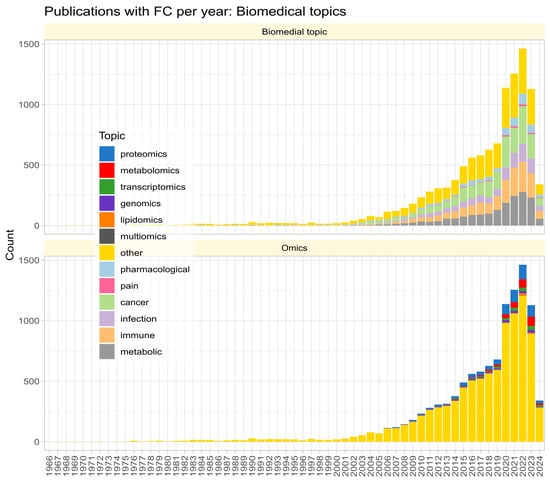
Figure 1.
Stacked bar chart of the number of publications per year according to a query of the PubMed database for “(“fold change” NOT (review[PT])” on 23 March 2024. The top panel shows the biomedical topic according to an article categorization of the most frequent biomedical contexts of fold change mention. The lower part shows the same for the term “omics” in the titles, keywords, or abstracts of the hits.
Fold change provides an intuitive measure of the magnitude of the difference between groups. Using allows direct interpretation of how many times, in multiples of 2, the marker expression was greater or less in the treatment group, and the number of folds by which the expression changes is equal for both up- and down-regulation, with the direction indicated by the sign, e.g., and . The term differential expression denotes that the average expression level of a measure in one group is larger or smaller than that in another group [2]. Fold change is often visualized in “volcano plots” [2] using a (p_value) on the y-axis and log2-ratio of signals between treatment and reference groups on the x-axis.
Fold-change calculation can significantly influence the interpretation of results and subsequent decision-making processes in biomedical research. Gene lists from microarray studies generated by fold-change ranking were more reproducible than those obtained by t-test p-value or other significance analyses [3,4], and fold-change is a potential criterion for uni-variate feature selection [5], alone or as a complement to other machine learning-based methods for omics analysis [6].
However, the exact method of calculating fold change is often not reported in scientific publications, although several methods exist. The definition of “average” (such as arithmetic or geometric mean) to quantify group expression levels can lead to inconsistencies. Despite previous studies downplaying the consequences [2,3,7], it seems crucial to carefully choose the most robust method against potential violations of standard assumptions about the data distribution and variance. This report reevaluates the influence of various fold-change calculation methods on fold-change values and aims to recommend a preferred approach.
2. Methods
2.1. Retrieval of Fold-Change Reporting in Biomedical Publications
On 23 March 2024, a PubMed (https://pubmed.ncbi.nlm.nih.gov/ (accessed on 21 July 2024)) search was performed using the query “(“fold change” NOT (review[PT])”. The R package “easyPubMed” (https://cran.r-project.org/package=easyPubMed [8] (accessed on 21 July 2024)) was used to retrieve details of the papers, including titles, abstracts, and publication years. To identify the main topics where fold-change reporting is common, words in the abstracts were filtered against generic text using the R package ‘PubMedWordcloud’ (https://cran.r-project.org/package=PubMedWordcloud [9] (accessed on 21 July 2024)). Recursive cABC analysis [10]), an item categorization technique, was then applied to the frequency of the remaining words using the R library “ABCanalysis” (https://cran.r-project.org/package=ABCanalysis [11] (accessed on 21 July 2024)). Biomedical domain experts identified biomedical topics based on the relevant terms. The type of omics research covered was determined by applying another cABC analysis to the occurrences of words containing the substring “omics”.
2.2. Common Basic Variants of the Fold-Change Calculation
There are numerous descriptions of fold-change calculation, such as in [12]. The calculation is based on the log ratio between the treatment and reference groups of a biological signal found in a data set, i.e., the values of a variable of interest. One common way of calculating the signal log ratio is:
where and are the positive, non-zero expected values of variable i measured under two different conditions a and b, such as before (a) and after (b) a treatment, or control (a) versus patient (b). From the log ratio, the value of fold change, , can be obtained by simple maths, for example as given in [12] (Equation (2), first curly brackets), or with an alternative shorter expression (Equation (2), second curly brackets):
2.2.1. Definition of Group Average from the Untransformed Data
There are several ways to define the expected values for a variable. Often, the arithmetic mean is used and then Equation (1) becomes
where the horizontal line placed over the variable, i.e., , denotes the arithmetic mean of variable v.
2.2.2. Definition of Group Average from Transformed Data
For log-normally distributed data, the geometric mean serves as a more appropriate measure of central tendency compared to the arithmetic mean. The geometric mean effectively captures the expected value for positive log-normal distributed data, and its application in omics studies has been recommended [13]. It is calculated as the nth root of the product of n items x, i.e., , which in the log domain becomes arithmetic mean in log scale, i.e., . When also using 2 as the base of logarithm for calculating the log ratio for fold change as in Equation (1), the log ratio is then
denoting the difference of the means of the logs of the two groups b and a.
Both calculation variants (i.e., calculating fold change via the log of the means as in Equation (3) or calculating it via the mean of the logs as in Equation (4)) are in use. However, for log-normal distributed data, the log of the mean is in general not equal to the mean of the log-transformed data, i.e., and for the values of fold-change obtained via the log ratios according to Equation (3) or Equation (4), respectively. Another measure of central tendency is the median, which is usually unaffected by the above discrepancy and was used, for example, in [14].
2.2.3. Pairwise Test/Reference Ratio Calculation
As an alternative approach, initially circumventing the necessity of defining the type of group average to be used, fold-change can be calculated by taking the ratio of each paired value from variable b and variable a. Let be a vector of length and be a vector of length . Then, for all possible combinations of an element of A with an element of B, expressed as , the log ratio can be calculated as
The pairs are either given if the experimental design involves related samples (e.g., before and after measurements), or they can be created by pairing each case in Group 1 with each case in Group 2 in all possible combinations.
2.3. Definition of an Error Measure for Deviations in Fold-Change Calculations
Comparative evaluations were mainly performed on artificial data sets where the true values of the fold changes were known at the time of data generation. Therefore, an error measure for fold-change estimates could be defined as
2.4. Comparative Evaluation of Common Calculation Methods
Evaluations were coded in the R language [15] using the R software package [16], version 4.4.0 for Linux (https://CRAN.R-project.org/ (accessed on 21 July 2024)), and in the matrix laboratory language using MATLAB (version 23.2.0.2485118 (R2023b)) and run on an AMD Ryzen Threadripper 3970X (Advanced Micro Devices, Inc., Santa Clara, CA, USA) desktop computer and an Intel® (Intel Corporation, Santa Clara, CA, USA) CoreTM i7-13700H notebook computer, both running on Ubuntu Linux 22.04.4 LTS (Canonical, London, UK). Figures were created using the R libraries “ggplot2” (https://cran.r-project.org/package=ggplot2 [17] (accessed on 21 July 2024)) “ComplexHeatmap” https://www.bioconductor.org/packages/ComplexHeatmap/ [18] (accessed on 21 July 2024), “ggthemes” (https://cran.r-project.org/package=ggthemes [19] (accessed on 21 July 2024)), “GGally” (https://cran.r-project.org/package=GGally [20] (accessed on 21 July 2024) and “ggforce” (https://cran.r-project.org/package=ggforce [21] (accessed on 21 July 2024). Referencing of R packages used for data analyses and visualizations in this report follows published advice on good software citation practice [22]). The equations used in the experiments are summarized in Table 1, along with the abbreviations or acronyms of the methods used in this report.

Table 1.
Calculation of log ratios between treatment/test (b) and reference (a). The left column gives the short names with equations indicated; the middle column gives the short names or descriptions used throughout the report, including in the figures; and the right column gives the calculations performed. The right column refers to the calculation method for the corresponding equation number in this report.
2.4.1. Evaluation of the Role of the Data Distribution for the Correct Calculation of
Fold-change calculations were evaluated on data generated to represent different distributions, including normal and log-normal, as well as identity, uniform, and mixed, where the latter is a random mixture of the four former distributions (Data set # 1; Table 2). Two vectors with different standard deviations of the sample sizes of a and b were performed using different calculation methods of .
Table 2.
Artificial data sets were created to assess certain effects of data distribution on the correct recovery of values by different calculation methods. All data sets contained vectors a and b, with vector a serving as the reference and the values of vector b being times the values of vector a. That is, vector a had a mean, if applicable, of , a standard deviation, if applicable, of , and a sample size of . Vector b had a mean of , a standard deviation of , and a sample size of . and denote independent uniform distributions, and N denotes the normal distribution.
2.4.2. Evaluation of the Role of Variance Equality for the Correct Calculation of
The above experiments highlighted specific problems with the log-normal distribution for certain variants of the computation. Given the frequent log-normal distribution of biological data sets, including non-omics data such as psychophysical measurements [23] and many others, this was brought into focus.
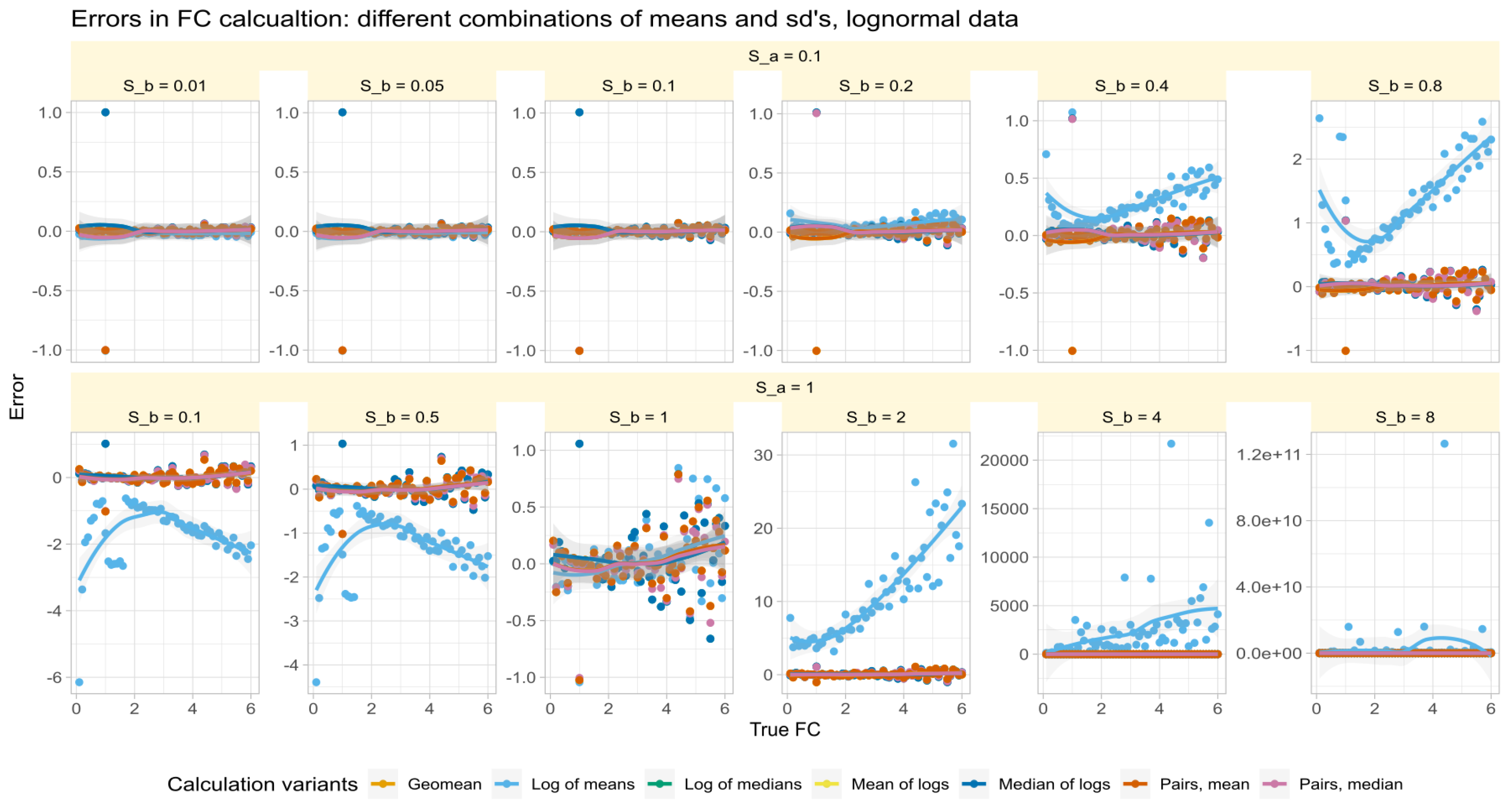
The effect of different values of and different standard deviations of treatment () and reference ()) on the accuracy of fold-change recovery was explored in log-normally distributed data (Data set # 2; Table 2). Across a wide range of simulated scenarios, with values of , , and , the errors in fold-change estimates were quantified according to Equation (6).
2.4.3. Evaluation of the Relationship of Calculation to Statistical Outcomes
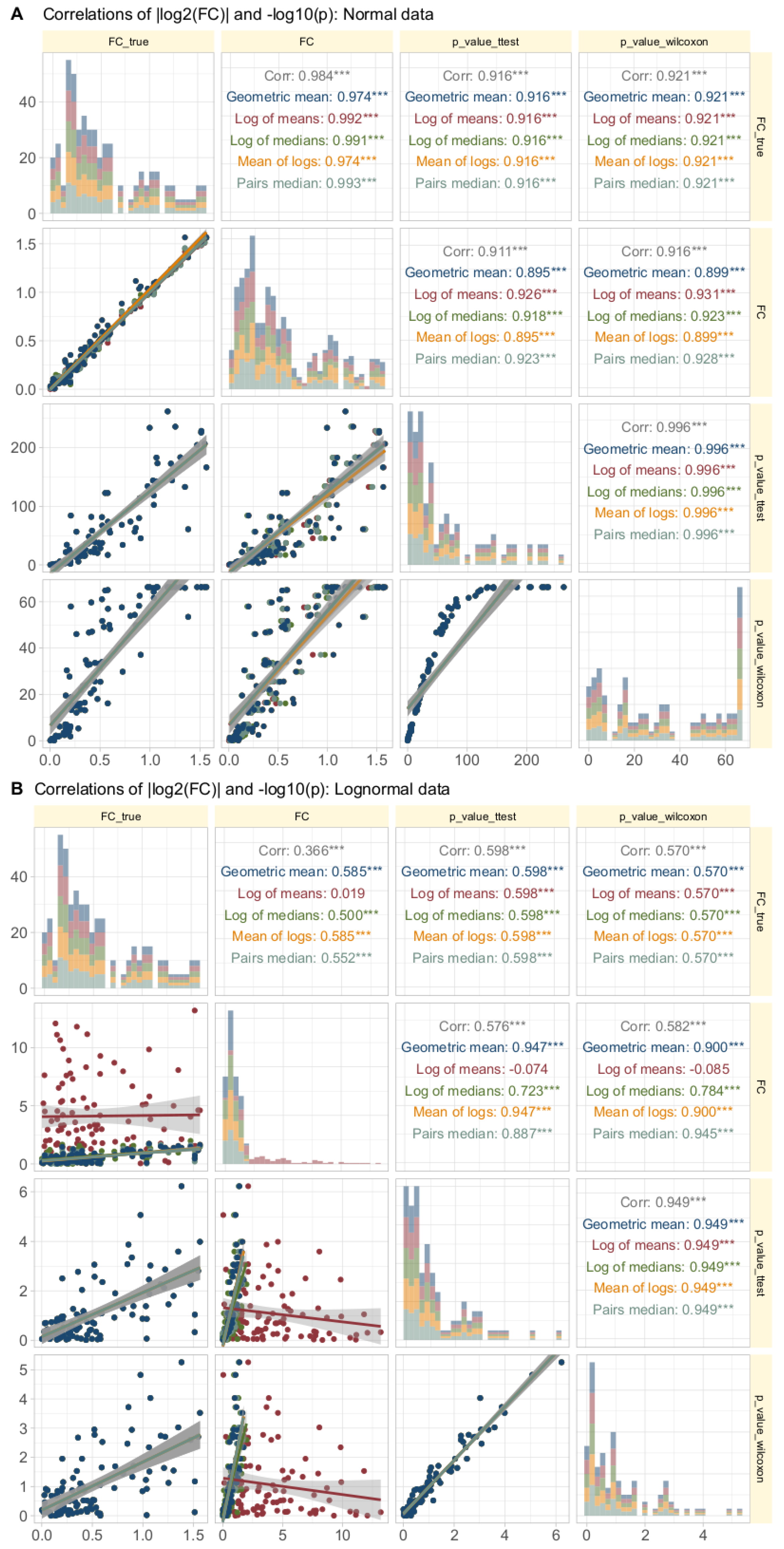
The two components of a volcano plot, fold change (), respectively, the log ratio of treatment and reference and the statistical significance (), were further evaluated using a simulated data set #3 Table 2 containing variables with either normal or log-normal distributions. This data set comprised 99 pairs of vectors, a (reference) and b (treatment), generated by randomly drawing values for means m, standard deviations and , and values of from predefined ranges. Different combinations of with different standard deviations .
Experiments were conducted on these 99 pairs of vectors a and b, employing different calculations for (mean of logs, log of means, paired approach) in combination with both nonparametric (Wilcoxon-Mann-Whitney U test [24,25]) and parametric (t-test [26]) statistical methods for comparing the vectors a and b in each of the d = 99 variables. The correlations of the absolute values of with the values of were assessed by calculating Spearman’s [27].
2.4.4. Evaluation of Calculation Method Dependency in Biomedical Data
Fold-change calculations are widely available in the biomedical literature. Therefore, for the present reassessment of fold-change calculation methods, the analysis was limited to an extended multi-omics data set (Data set # 3; Table 2). It originates from recent rheumatologic research and consists of an ongoing omics study of a cohort clinically described in [28]. This cross-sectional study of patients with rheumatic diseases was conducted in accordance with the Declaration of Helsinki on Biomedical Research Involving Human Subjects and was approved by the Ethics Committee of the Medical Faculty of the Goethe University, Frankfurt am Main, Germany (approval number 19-492_5). Informed written consent was obtained from each participant. For the present analysis, a subset of cases consisting of n = 95 patients with psoriatic arthritis and n = 50 healthy controls has been used. The omics assessments included d = 680 plasma concentrations of d = 328 proteins from an inflammatory panel and d = 352 lipid markers.
3. Results
3.1. Reporting Styles of Fold-Change Calculation in Biomedical Publications
The search of PubMed on 23 March 2024, using the query “(“fold change” NOT (review[PT])” returned 10,978 results (Figure 1). However, the true prevalence of fold-change reporting is likely much higher, as researchers often employ fold-change calculations and visualizations without explicitly using the term in titles, keywords, or abstracts. The number of publications per year has been increasing steadily since the turn of the century. An analysis of the context in which reporting of omics research results is most common revealed five main biomedical topics (pharmacological research, cancer, infection, immune processes, metabolism) and seven variants of omics research (with a recent publication each: proteomics [29], metabolomics [30], transcriptomics [31], genomics [32], lipidomics [33], multiomics [34], toxicogenomics [35]; Figure 1).
The exact calculation of fold-change () values is rarely reported in the literature. A review of over 200 papers found that only about 5% mentioned the calculation method, often in the context of informatics approaches to differential expression analysis rather than the use of in reporting biomedical findings. Among the few relevant papers, some used the arithmetic mean [12,36], while others mentioned log transformation, hinting at the use of the geometric mean [37], though this was rarely stated explicitly. Additionally, is sometimes calculated from pre-transformed data, such as in the method [38] as a standard in polymerase chain reaction (PCR) data analysis [39].
3.2. Role of the Data Distribution for the Correct Calculation of
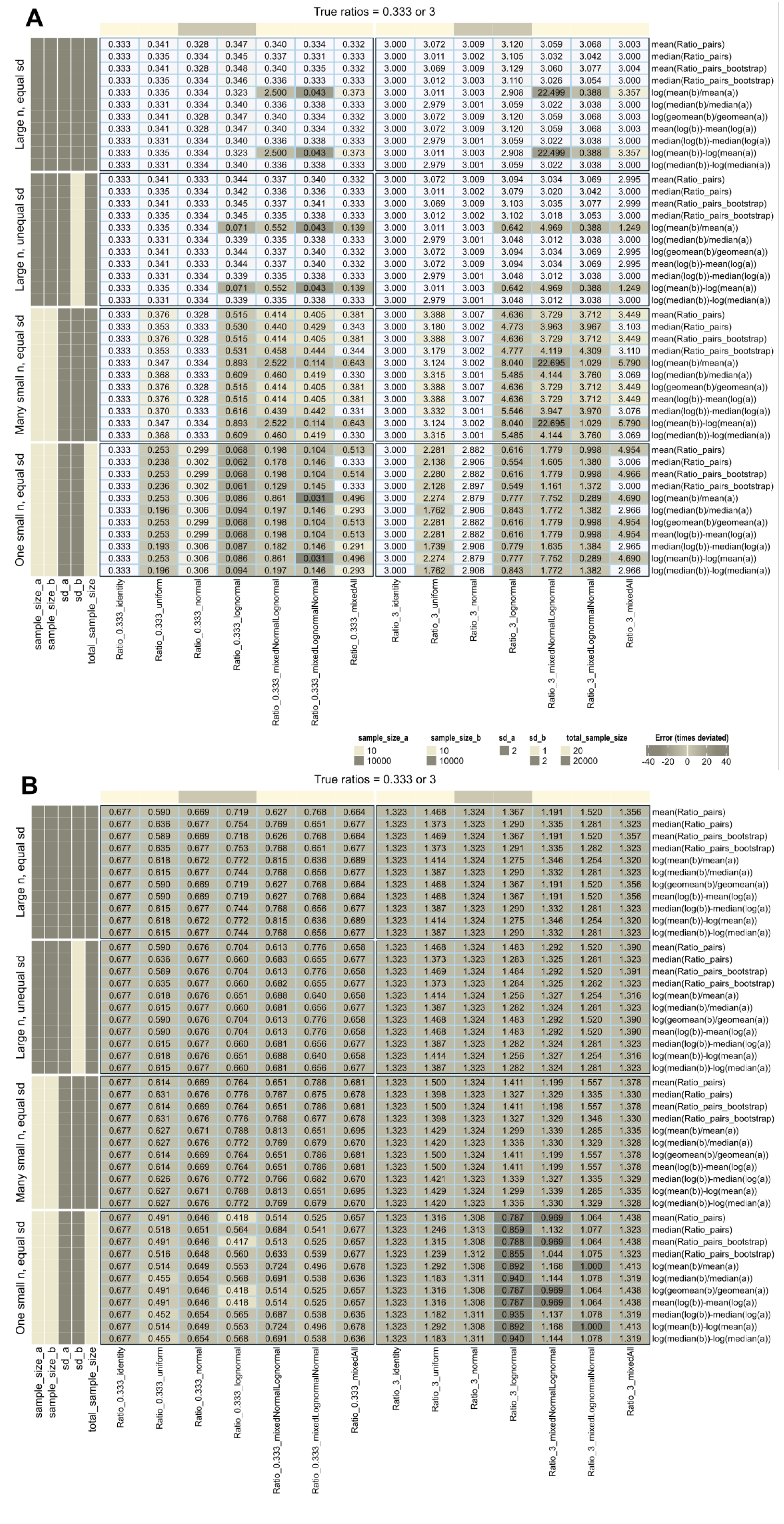
When the data distribution was normal, identity, or uniform and the sample size was large (n = 10,000), all calculation methods accurately recovered the true treatment-to-reference ratios (Figure 2A). However, when log-normal data were included, recovery was confounded by various conditions: most methods succeeded when the standard deviations of the treatment and reference groups were equal, except for the ratio of arithmetic means when the treatment and reference distributions were different. In contrast, all methods except the ratio of arithmetic means were robust to unequal variances.
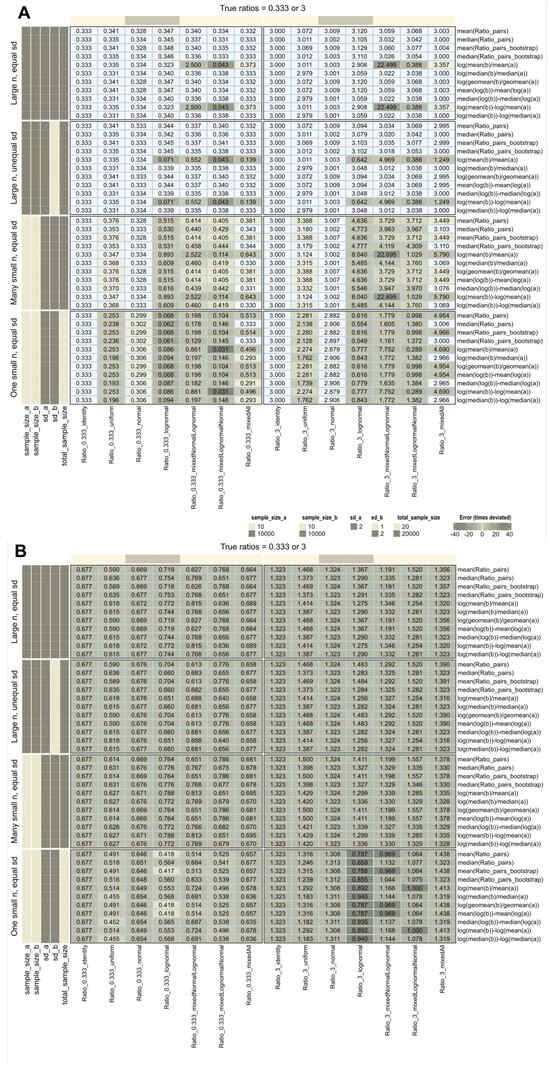
Figure 2.
Recovery of fold-change values used to generate artificial data (data set #1) with different distributions (identity, uniform, normal, and lognormal), including mixed distributions such as “mixed”, i.e., a mixture of all four distributions mentioned, or “mixedNormalLognormal” (treatment: normal, reference: lognormal) or “mixedlognormalNormal” (treatment: lognormal, reference: normal). The fold-change calculations are shown on the right and were performed using different methods as specified in Table 1. (A) calculations without further data transformation. (B) All data were again log-transformed, regardless of their original distribution. The cells are colored according to the errors in fold-change estimates quantified by Equation (6), with darker colors indicating higher absolute errors.
Recovery deteriorated drastically with small sample sizes, especially with log-normal data, and none of the methods provided accurate results. Repeating the experiments with small sample sizes slightly improved recovery for normal or identity distributions.
The intuitive use of fold-change assumes absolute expression levels. However, a pitfall arises when using pre-transformed data from standard workflows without realizing it. Applying additional log-transformations means log transforming already log-transformed data (Figure 2B). Rankings of variables may be preserved, but calculated fold changes no longer represent “times expression”, only arbitrary numbers, possibly better expressed as “times signal” as a more neutral description. When comparing studies or multi-omics data from different workflows, changes in fold-change magnitude, interpretation, and comparability become relevant.
3.3. Role of Variance Equality for the Correct Calculation of
The errors in test/reference ratios calculated by major methods in Data Set #2 were analyzed for log-normal data with varying standard deviations. The results (Figure 3) showed that all methods except those based on arithmetic means made small errors of about 0.1 times more or less than the true factor. The arithmetic mean-based method had varying effects depending on the fold change and standard deviation of the test relative to the reference.
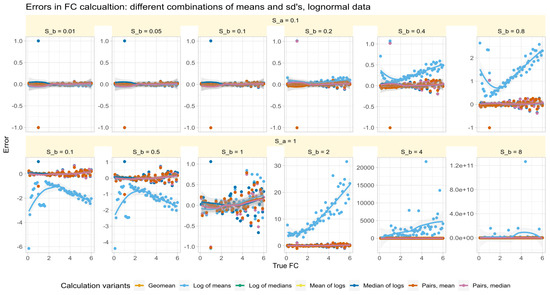
Figure 3.
Errors of fold-change recovery (Equation (6)) from synthetic data (data set #2) generated along a range of fold-change values of with standard deviation of reference of (upper line of panels) and (lower line of panels) and standard deviations of the treatment subgroup () at ratios (panels from left to right). The trends of the relations are shown as linear regression lines with 95% confidence intervals for the fits. The fold-change calculations were performed using different methods as specified in Table 1.
Specifically, when and were not equal, the error reversed direction at a value of . That is, when and , the arithmetic mean-based method overestimated the value of , was close to zero when , and underestimated the error when . Thus, the success of correctly estimating by arithmetic means depended first on the similarity of the standard deviations. This recalls a precondition of the calculation mentioned in [2], namely that can be considered a special case when the variances of all genes are equal.
3.4. Relationship between Calculated Fold Change and Statistical Significance
Intuitively, higher fold changes tend to be associated with higher statistical significance because larger expression differences between conditions are more likely to be statistically significant, assuming consistent variability within each condition. However, deviations from this intuitive expectation can occur due to high and different variability within and between conditions, leading to lower significance despite large fold changes.
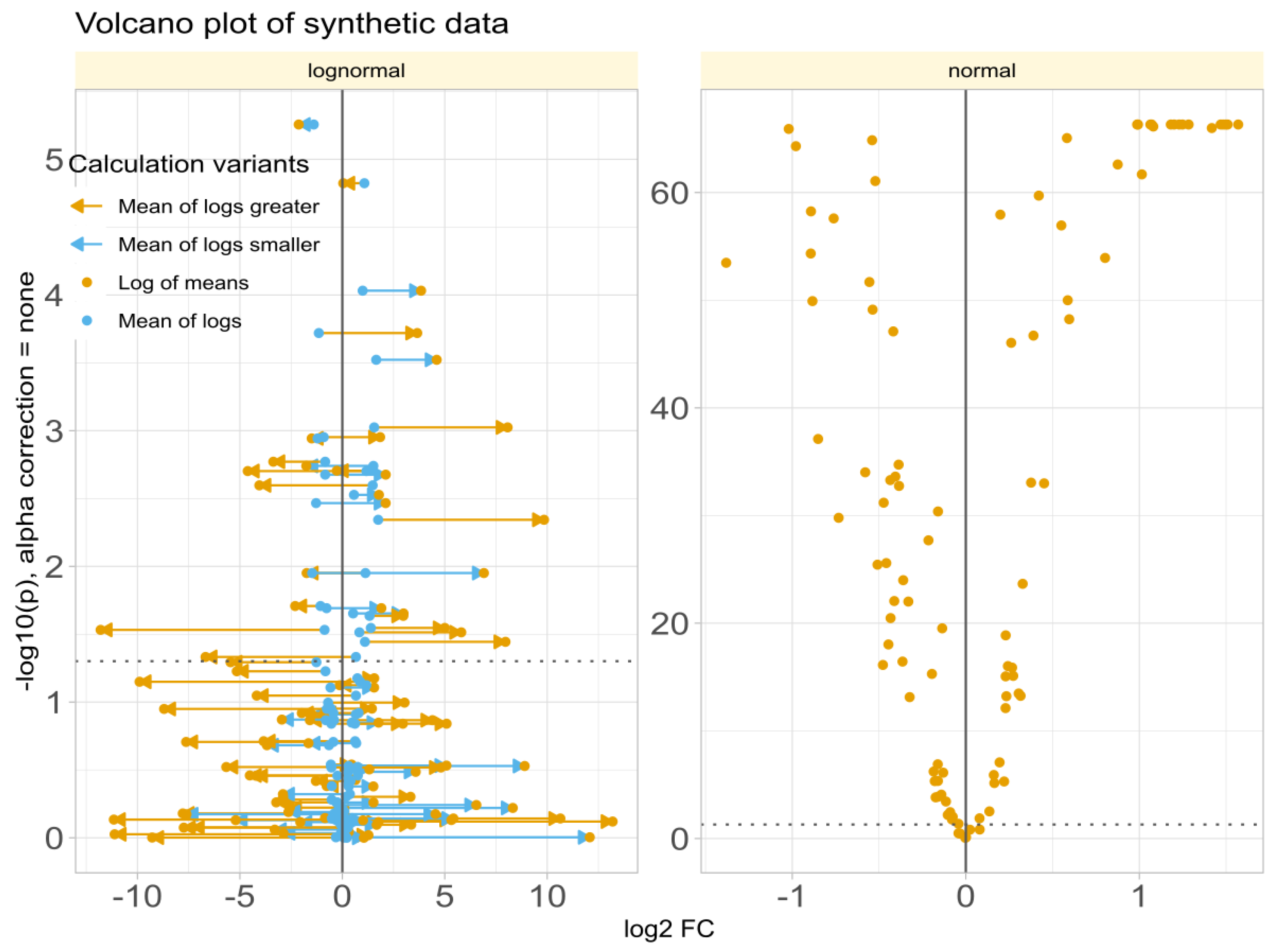
Data Set #3 tested the robustness of fold change () calculation by combining different fold changes with varying standard deviations in normally and log-normally distributed data. In normal distributed data, the choice of the calculation method was nevertheless irrelevant to the results (Figure 4A). The obtained values of correlated with the true values of and with the statistical significance of the group comparisons, and the correlations were quite similar regardless of the calculation method. The picture changed somewhat for log-normal data (Figure 4B), where it became clear that calculating using the logarithm of the mean was associated with a higher risk of inaccuracy than the alternatives. This was evident in the volcano plot (Figure 5), where extreme cases showed crossover from downregulation to upregulation or vice versa.
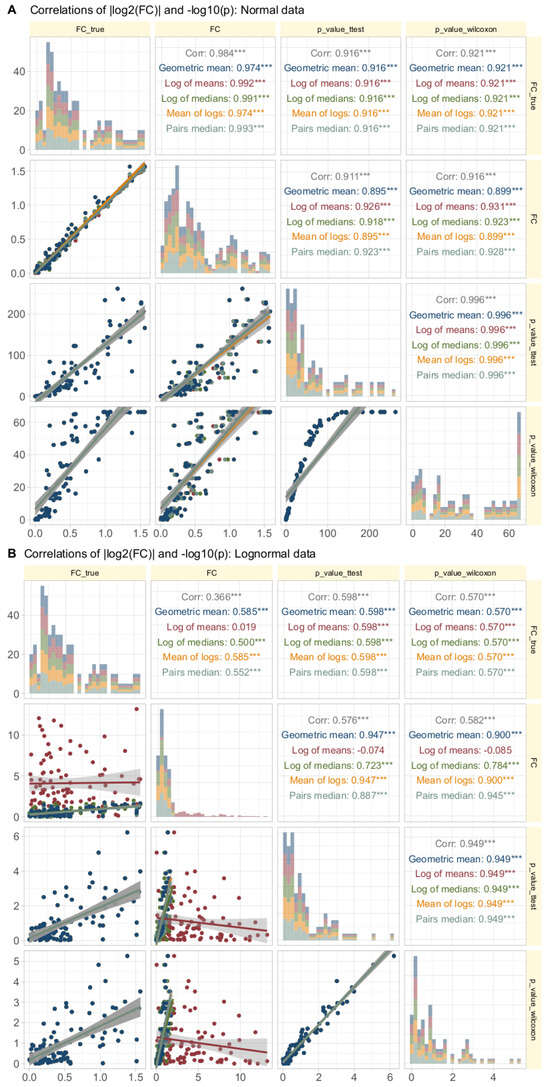
Figure 4.
Correlations of || and in synthetic data (data set #3) with normal (panel A at the top) or log-normal (panel B, bottom) distribution. Each d = 99 treatment and reference data sets were generated by randomly assigning fold-change values and treatment () and reference () standard deviations from predefined ranges. The trends of the relations are shown as linear regression lines with 95% confidence intervals for the fits. The diagonal shows stacked histograms of the distributions of the respective values. “” denotes the absolute value of the treatment/reference ratio used during data generation, i.e., ||, “” denotes the same for the value calculated according to different equations. The upper right triangle shows the Spearman’s correlation coefficient , with stars indicating the significance level (***: ). The fold-change calculations were performed using different methods, as specified in Table 1.
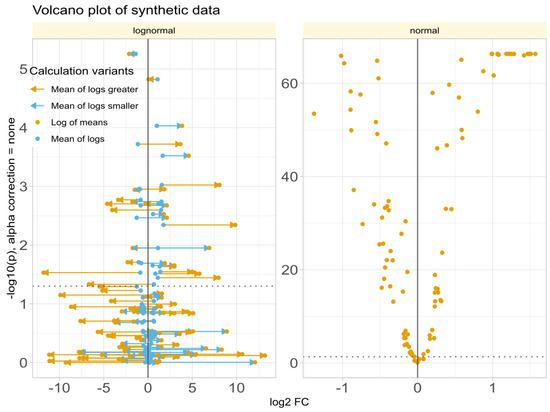
Figure 5.
Volcano plots of synthetic data (data set #3) with log-normal (left panel) or normal (right panel) distribution, obtained when fold changes were estimated using either “log of means”: calculation using the arithmetic mean as the definition of the expected or average value of each subgroup (Equation (3)) or the “mean of logs”: calculation using the arithmetic mean of the logs of treatment and reference as the definition of the expected or average value of each subgroup. The lines connect the points on the diagram that represent the same variables with calculated by either method. The ordinate displays without -correction.
3.5. Calculation Method Dependency in Biomedical Data
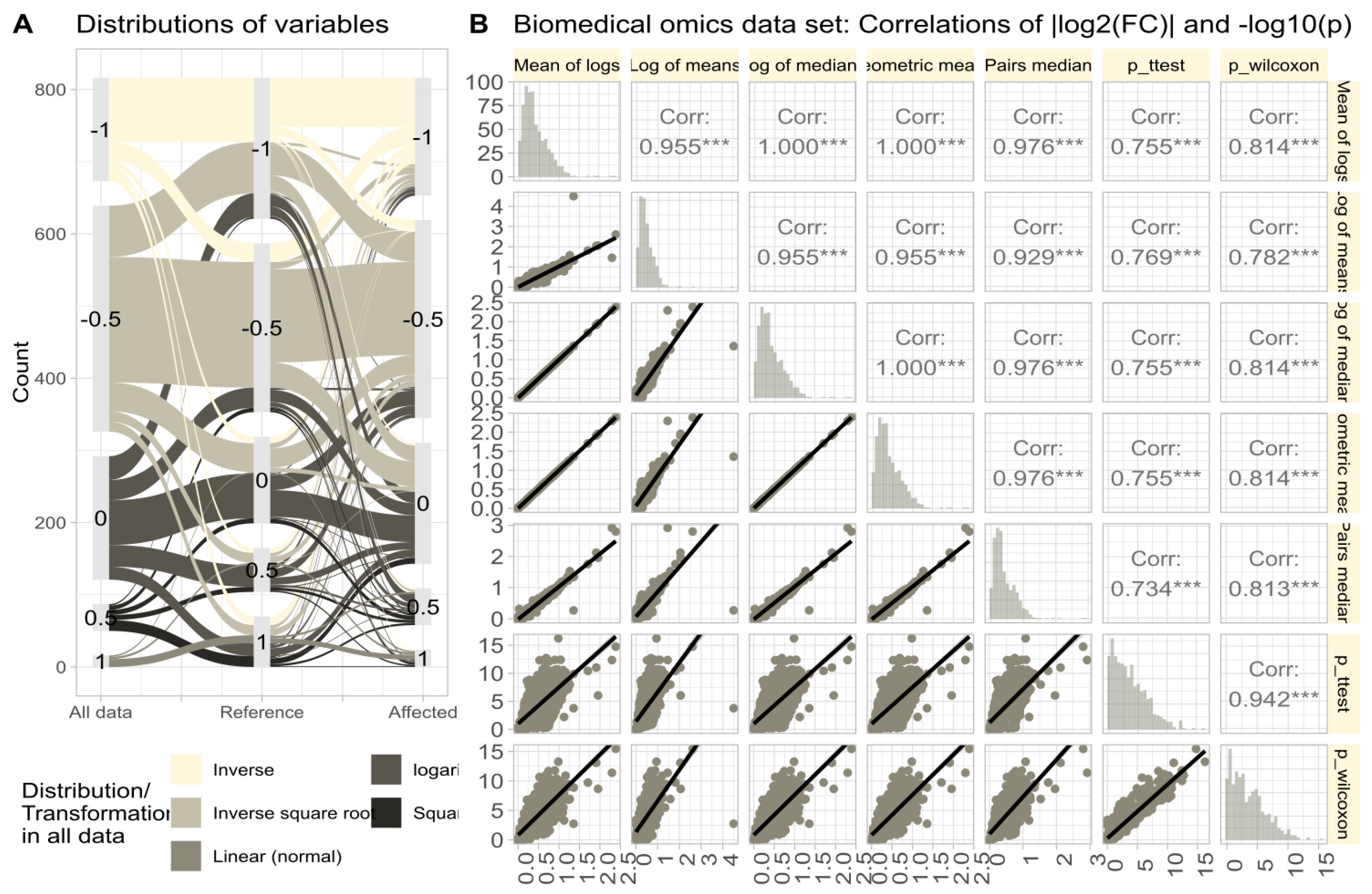
The omics data set #4 from rheumatology research showed diverse distributions, with only 14.3% of variables normally distributed in the raw data (Figure 6A). Log-transforming the data increased normality to 48.1%. Therefore, the Box-Cox transformation [40] was used to align the obtained values of with the steps of Tukey’s ladder of power [41]. The calculation of using different methods (logarithm of means, means of logs, etc.; Figure 6B) yielded similar results, with high correlations between values and statistical significances in parametric and non-parametric tests. Further stressing of the calculations by complete permutation of the entire data matrices in the x- and y-directions resulted in highly skewed data (skewness = 23.4, kurtosis = 837.6). Then, the correlations between methods decreased, and the pairwise method showed the strongest correlation with nonparametric test results (Figure 7).
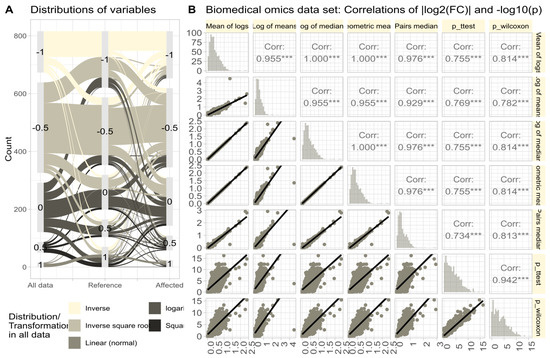
Figure 6.
Untransformed real-life omics data (proteomics, lipidomics; data set #4). (A) Distribution of variables according to the of the Box-Cox analysis. Sankey plot [42] showing the distribution of variables (i) in the complete data and separately for (ii) reference and (iii) treatment subgroups. (B) Correlations of || and in untransformed real-life omics data (proteomics, lipidomics) after complete permutation of the 2D-matrix in x and y direction. The trends of the relations are shown as linear regression lines with 95% confidence intervals of the fits. The diagonal shows stacked histograms of the distributions of the respective values. The upper right triangle shows the Spearman’s correlation coefficient with stars indicating the significance level (***: ). The fold-change calculations were performed using different methods, as specified in Table 1.

Figure 7.
Correlations of of || and in untransformed real-life omics data (proteomics, lipidomics) after complete permutation of the 2D-matrix in x and y direction. The trends of the relations are shown as linear regression lines with 95% confidence intervals of the fits. The diagonal shows stacked histograms of the distributions of the respective values. The upper right triangle shows the Spearman’s correlation coefficient with stars indicating the significance level (***: ). The fold-change calculations were performed using different methods, as specified in Table 1.
4. Discussion
Fold-change calculation is widely used to describe the effect of a treatment on a measurement or group differences. Despite its ease of calculation, the exact method used is often not reported. Although different methods exist, they appear to give similar results. However, a re-evaluation of these methods found that one method, using the arithmetic mean, is less robust to anomalies in the data distribution and can result in incorrect fold-change values more frequently than others. Unfortunately, this is often cited as the standard method for calculation [7,43].
The present experiments highlight the importance of sample size, distribution, and variance for accurate fold-change calculation. For small sample sizes (e.g., n = 10), none of the methods could accurately reproduce true ratios. This limitation has been addressed in studies on sample size calculation for differential expression [44,45], but variance estimation from small samples can be generally unreliable [2]. In addition, if the calculation is considered a special case when the variances of all genes are equal, the calculation via the supposed standard equation can go wrong.
The present biomedical data showed different distributions of the test and reference data subsets (Figure 6A), albeit to a degree that induced moderate consequences, but nevertheless show the possibility of such a scenario. The arithmetic mean fold-change calculation was most sensitive to violations of assumptions, and the logarithmic calculation performed worst when data were log-normally distributed. In settings with unequal distributions, the arithmetic mean calculation diverged from true values, while alternative equations provided accurate results and maintained correlation with statistical significance.
In the present experiments, different mathematically identical calculation equation variants were used to improve clarity and serve as internal validation. However, we could not reproduce the distinction between and made in previous work [7], as it seemed to interpret a difference as a ratio [46]. Here, we use fold change exclusively as a ratio. Evaluations focused on calculating numerical fold-change values without further refinement of up- or downregulation [47]. Comprehensive assessments highlight the need for more precise methods, especially for single-cell RNA-seq data [48], as the chosen statistical or fold change cutoff can provide multiple answers for microarray analysis [49].
Finally, the recommendation to use the median or geometric mean to quantify the expected value or group mean must be combined with the warning that even these values are not insensitive to unusual data constellations. The geometric mean is usually appropriate for log-normal data. The median is more general but can also be misleading. For example, in the analysis of right-skewed distributions observed in the analysis of social dynamics, the median can often be more misleading than the mean [50], and such scenarios are also not excluded in biomedical data. Above all, this simple example emphasizes that careful data exploration during preprocessing, including the adequate visualization of raw data [51], as an essential part of the omics data analysis workflow, cannot be replaced by an unquestioned standard procedure rigidly applied to the data at hand.
5. Conclusions
Fold-change reporting is widely used to summarize differential expression patterns, but the exact calculation method is often unclear. Different equations can produce different results, especially when data distributions are unequal. To ensure accurate interpretation and reproducibility, it is crucial to use methods less sensitive to data distribution and accurately report the calculation methods used [52]. The inferior arithmetic mean-based method is often perceived as the standard, despite mathematically different equations being possible that mainly differ in the estimation of the expected value. In conclusion, the choice of fold-change calculation method can significantly influence the interpretation of results and subsequent decision-making processes in biomedical research. Adopting less vulnerable methods and transparent reporting is a reasonable practice to ensure correct interpretation and reproducibility.
Author Contributions
J.L.—Conceptualization of the project, programming, writing of the manuscript, data analyses and creation of the figures, revision of the manuscript. D.K.—Literature research, manuscript proofreading, manuscript revision. A.U.—Critically evaluating the manuscript for significant intellectual content, proofreading the mathematical content of the manuscript. All authors have read and agreed to the published version of the manuscript.
Funding
J.L. was supported by the Deutsche Forschungsgemeinschaft (DFG Lo 612/16-1).
Institutional Review Board Statement
The biomedical data set has been acquired in a study that followed the recommendations of the Declaration of Helsinki on Biomedical Research Involving Human Subjects and was approved by the Ethics Committee of the Medical Faculty of the Goethe University, Frankfurt am Main, Germany (approval number 19-492_5).
Informed Consent Statement
For the biomedical data set, written informed consent, including into anonymized publication, was obtained from all participants.
Data Availability Statement
The biomedical data set used in the experiments in this report is available from the first author upon reasonable request and subject to approval by the appropriate ethics committee. The artificial data sets’ generation rules are precisely described in the report.
Conflicts of Interest
The authors have declared that no competing interests exist.
References
- Draghici, S. Statistical intelligence: Effective analysis of high-density microarray data. Drug Discov. Today 2002, 7, S55–S63. [Google Scholar] [CrossRef] [PubMed]
- Li, W. Volcano plots in analyzing differential expressions with mRNA microarrays. J. Bioinform. Comput. Biol. 2012, 10, 1231003. [Google Scholar] [CrossRef] [PubMed]
- Dembélé, D.; Kastner, P. Fold change rank ordering statistics: A new method for detecting differentially expressed genes. BMC Bioinform. 2014, 15, 14. [Google Scholar] [CrossRef] [PubMed]
- Guo, L.; Lobenhofer, E.K.; Wang, C.; Shippy, R.; Harris, S.C.; Zhang, L.; Mei, N.; Chen, T.; Herman, D.; Goodsaid, F.M.; et al. Rat toxicogenomic study reveals analytical consistency across microarray platforms. Nat. Biotechnol. 2006, 24, 1162–1169. [Google Scholar] [CrossRef] [PubMed]
- Guyon, I. An introduction to variable and feature selection. J. Mach. Learn. Res. 2003, 3, 1157–1182. [Google Scholar]
- Cheng, J.; Liu, H.P.; Lin, W.Y.; Tsai, F.J. Machine learning compensates fold-change method and highlights oxidative phosphorylation in the brain transcriptome of Alzheimer’s disease. Sci. Rep. 2021, 11, 13704. [Google Scholar] [CrossRef] [PubMed]
- Witten, D.M.; Tibshirani, R. A comparison of fold-change and the t-statistic for microarray data analysis. Analysis 2007, 1776, 58–85. [Google Scholar]
- Fantini, D. easyPubMed: Search and Retrieve Scientific Publication Records from PubMed. 2019. Available online: https://cran.r-project.org/package=easyPubMed (accessed on 21 July 2024).
- Fan, F.Y. PubMedWordcloud: Pubmed Word Clouds. R Package Version 0.3.6. 2019. Available online: https://CRAN.R-project.org/package=PubMedWordcloud (accessed on 21 July 2024).
- Lötsch, J.; Ultsch, A. Recursive computed ABC (cABC) analysis as a precise method for reducing machine learning based feature sets to their minimum informative size. Sci. Rep. 2023, 13, 5470. [Google Scholar] [CrossRef] [PubMed]
- Ultsch, A.; Lötsch, J. Computed ABC Analysis for Rational Selection of Most Informative Variables in Multivariate Data. PLoS ONE 2015, 10, e0129767. [Google Scholar] [CrossRef] [PubMed]
- Tadros, S.F.; D’Souza, M.; Zhu, X.; Frisina, R.D. Gene expression changes for antioxidants pathways in the mouse cochlea: Relations to age-related hearing deficits. PLoS ONE 2014, 9, e90279. [Google Scholar] [CrossRef]
- Olivier, J.; Johnson, W.D.; Marshall, G.D. The logarithmic transformation and the geometric mean in reporting experimental IgE results: What are they and when and why to use them? Ann. Allergy Asthma Immunol. 2008, 100, 333–337. [Google Scholar] [CrossRef] [PubMed]
- Jain, N.; Thatte, J.; Braciale, T.; Ley, K.; O’Connell, M.; Lee, J.K. Local-pooled-error test for identifying differentially expressed genes with a small number of replicated microarrays. Bioinformatics 2003, 19, 1945–1951. [Google Scholar] [CrossRef] [PubMed]
- Ihaka, R.; Gentleman, R. R: A Language for Data Analysis and Graphics. J. Comput. Graph. Stat. 1996, 5, 299–314. [Google Scholar] [CrossRef]
- R Core Team. R: A Language and Environment for Statistical Computing; Version 4.4.0; R Core Team: Vieanny, Austia, 2021. [Google Scholar]
- Wickham, H. ggplot2: Elegant Graphics for Data Analysis; Springer: New York, NY, USA, 2016; Available online: https://cran.r-project.org/package=ggplot2 (accessed on 21 July 2024).
- Gu, Z.; Eils, R.; Schlesner, M. Complex heatmaps reveal patterns and correlations in multidimensional genomic data. Bioinformatics 2016, 32, 2847–2849. [Google Scholar] [CrossRef] [PubMed]
- Arnold, J.B. ggthemes: Extra Themes, Scales and Geoms for ‘ggplot2’. 2024. R Package Version 5.1.0. Available online: https://cran.r-project.org/package=ggthemes (accessed on 22 July 2024).
- Schloerke, B.; Crowley, J.; Cook, D.; Briatte, F.; Marbach, M.; Thoen, E.; Elberg, A.; Larmarange, J. GGally: Extension to ‘ggplot2’. 2024. Available online: https://cran.r-project.org/package=GGally (accessed on 22 July 2024).
- Pedersen, T.L. ggforce: Accelerating ‘ggplot2’. 2024. Available online: https://cran.r-project.org/package=ggforce (accessed on 22 July 2024).
- Smith, A.M.; Katz, D.S.; Niemeyer, K.E.; Group, F.S.C.W. Software citation principles. PeerJ Comput. Sci. 2016, 2, e86. [Google Scholar] [CrossRef]
- Fechner, G.T. Elemente der Psychophysik; Breitkopf and Härtel: Leipzig, Germany, 1860. [Google Scholar]
- Mann, H.B.; Whitney, D.R. On a test of whether one of two random variables is stochastically larger than the other. Ann. Math. Stat. 1947, 18, 50–60. [Google Scholar] [CrossRef]
- Wilcoxon, F. Individual comparisons by ranking methods. Biometrics 1945, 1, 80–83. [Google Scholar] [CrossRef]
- Student. The Probable Error of a Mean. Biometrika 1908, 6, 1–25. [CrossRef]
- Spearman, C. The proof and measurement of association between two things. Am. J. Psychol. 1904, 15, 72–101. [Google Scholar] [CrossRef]
- Rischke, S.; Poor, S.M.; Gurke, R.; Hahnefeld, L.; Köhm, M.; Ultsch, A.; Geisslinger, G.; Behrens, F.; Lötsch, J. Machine learning identifies right index finger tenderness as key signal of DAS28-CRP based psoriatic arthritis activity. Sci. Rep. 2023, 13, 22710. [Google Scholar] [CrossRef] [PubMed]
- Wang, Y.; Guan, Z.Y.; Shi, S.W.; Jiang, Y.R.; Zhang, J.; Yang, Y.; Wu, Q.; Wu, J.; Chen, J.B.; Ying, W.X.; et al. Pick-up single-cell proteomic analysis for quantifying up to 3000 proteins in a Mammalian cell. Nat. Commun. 2024, 15, 1279. [Google Scholar] [CrossRef]
- Wang, W.C.; Huang, C.H.; Chung, H.H.; Chen, P.L.; Hu, F.R.; Yang, C.H.; Yang, C.M.; Lin, C.W.; Hsu, C.C.; Chen, T.C. Metabolomics facilitates differential diagnosis in common inherited retinal degenerations by exploring their profiles of serum metabolites. Nat. Commun. 2024, 15, 3562. [Google Scholar] [CrossRef] [PubMed]
- Caudal, E.; Loegler, V.; Dutreux, F.; Vakirlis, N.; Teyssonniere, E.; Caradec, C.; Friedrich, A.; Hou, J.; Schacherer, J. Pan-transcriptome reveals a large accessory genome contribution to gene expression variation in yeast. Nat. Genet. 2024, 56, 1278–1287. [Google Scholar] [CrossRef] [PubMed]
- Chen, P.B.; Chen, R.; LaPierre, N.; Chen, Z.; Mefford, J.; Marcus, E.; Heffel, M.G.; Soto, D.C.; Ernst, J.; Luo, C.; et al. Complementation testing identifies genes mediating effects at quantitative trait loci underlying fear-related behavior. Cell Genom. 2024, 4, 100545. [Google Scholar] [CrossRef] [PubMed]
- Kim, B.; Kim, G.; Jeon, H.P.; Jung, J. Lipidomics Analysis Unravels Aberrant Lipid Species and Pathways Induced by Zinc Oxide Nanoparticles in Kidney Cells. Int. J. Mol. Sci. 2024, 25, 4285. [Google Scholar] [CrossRef] [PubMed]
- Han, B.; Tian, D.; Li, X.; Liu, S.; Tian, F.; Liu, D.; Wang, S.; Zhao, K. Multiomics Analyses Provide New Insight into Genetic Variation of Reproductive Adaptability in Tibetan Sheep. Mol. Biol. Evol. 2024, 41, msae058. [Google Scholar] [CrossRef] [PubMed]
- Pandiri, A.R.; Auerbach, S.S.; Stevens, J.L.; Blomme, E.A.G. Toxicogenomics Approaches to Address Toxicity and Carcinogenicity in the Liver. Toxicol. Pathol. 2023, 51, 470–481. [Google Scholar] [CrossRef] [PubMed]
- Kumar, N.; Hoque, M.A.; Sugimoto, M. Robust volcano plot: Identification of differential metabolites in the presence of outliers. BMC Bioinform. 2018, 19, 128. [Google Scholar] [CrossRef] [PubMed]
- Hauber, A.L.; Rosenblatt, M.; Timmer, J. Uncovering specific mechanisms across cell types in dynamical models. PLoS Comput. Biol. 2023, 19, e1010867. [Google Scholar] [CrossRef] [PubMed]
- Livak, K.J.; Schmittgen, T.D. Analysis of relative gene expression data using real-time quantitative PCR and the 2(-Delta Delta C(T)) Method. Methods 2001, 25, 402–408. [Google Scholar] [CrossRef] [PubMed]
- Fu, W.J.; Hu, J.; Spencer, T.; Carroll, R.; Wu, G. Statistical models in assessing fold change of gene expression in real-time RT-PCR experiments. Comput. Biol. Chem. 2006, 30, 21–26. [Google Scholar] [CrossRef] [PubMed]
- Box, G.E.P.; Cox, D.R. An analysis of transformations. J. R. Stat. Soc. Ser. B (Methodol.) 1964, 26, 211–252. [Google Scholar] [CrossRef]
- Tukey, J.W.; Tukey, J.W. Exploratory Data Analysis; Addison-Wesley: Reading, MA, USA, 1977. [Google Scholar]
- Kennedy, A.B.W.; Sankey, H. Riall the Thermal Efficiency of Steam Engines. In Minutes of the Proceedings of the Institution of Civil Engineers; Waterloo: London, UK, 1898. [Google Scholar] [CrossRef]
- Tusher, V.G.; Tibshirani, R.; Chu, G. Significance analysis of microarrays applied to the ionizing radiation response. Proc. Natl. Acad. Sci. USA 2001, 98, 5116–5121. [Google Scholar] [CrossRef] [PubMed]
- Bi, R.; Liu, P. Sample size calculation while controlling false discovery rate for differential expression analysis with RNA-sequencing experiments. BMC Bioinform. 2016, 17, 146. [Google Scholar] [CrossRef] [PubMed]
- Li, C.I.; Su, P.F.; Shyr, Y. Sample size calculation based on exact test for assessing differential expression analysis in RNA-seq data. BMC Bioinform. 2013, 14, 357. [Google Scholar] [CrossRef] [PubMed]
- Choe, S.E.; Boutros, M.; Michelson, A.M.; Church, G.M.; Halfon, M.S. Preferred analysis methods for Affymetrix GeneChips revealed by a wholly defined control dataset. Genome Biol. 2005, 6, R16. [Google Scholar] [CrossRef] [PubMed]
- Newton, M.A.; Kendziorski, C.M.; Richmond, C.S.; Blattner, F.R.; Tsui, K.W. On Differential Variability of Expression Ratios: Improving Statistical Inference about Gene Expression Changes from Microarray Data. J. Comput. Biol. 2001, 8, 37–52. [Google Scholar] [CrossRef] [PubMed]
- Wang, T.; Li, B.; Nelson, C.E.; Nabavi, S. Comparative analysis of differential gene expression analysis tools for single-cell RNA sequencing data. BMC Bioinform. 2019, 20, 40. [Google Scholar] [CrossRef] [PubMed]
- Dalman, M.R.; Deeter, A.; Nimishakavi, G.; Duan, Z.H. Fold change and p-value cutoffs significantly alter microarray interpretations. BMC Bioinform. 2012, 13 (Suppl. S2), S11. [Google Scholar] [CrossRef] [PubMed]
- Kämpke, T. The use of mean values vs. medians in inequality analysis. J. Econ. Soc. Meas. 2010, 35, 43–62. [Google Scholar] [CrossRef]
- Lötsch, J.; Ultsch, A. Comments on the importance of visualizing the distribution of pain-related data. Eur. J. Pain 2023, 27, 787–793. [Google Scholar] [CrossRef]
- National Academies of Sciences, Engineering, and Medicine; Division of Behavioral and Social Sciences and Education; Division on Earth and Life Studies; Division on Engineering and Physical Sciences; Policy and Global Affairs; Board on Behavioral, Cognitive, and Sensory Sciences; Committee on National Statistics; Nuclear and Radiation Studies Board; Board on Mathematical Sciences and Analytics; Committee on Applied and Theoretical Statistics; et al. Reproducibility and Replicability in Science; Number 31596559; National Academies Press: Washington, DC, USA, 2019. [Google Scholar] [CrossRef]

Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2024 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).