
Which Curve Fits Best: Fitting ROC Curve Models to Empirical Credit-Scoring Data


Abstract
:1. Introduction
2. Literature Background
3. ROC Curve Models
3.1. Bibeta and Simplified Bibeta Models
3.2. Bigamma Model
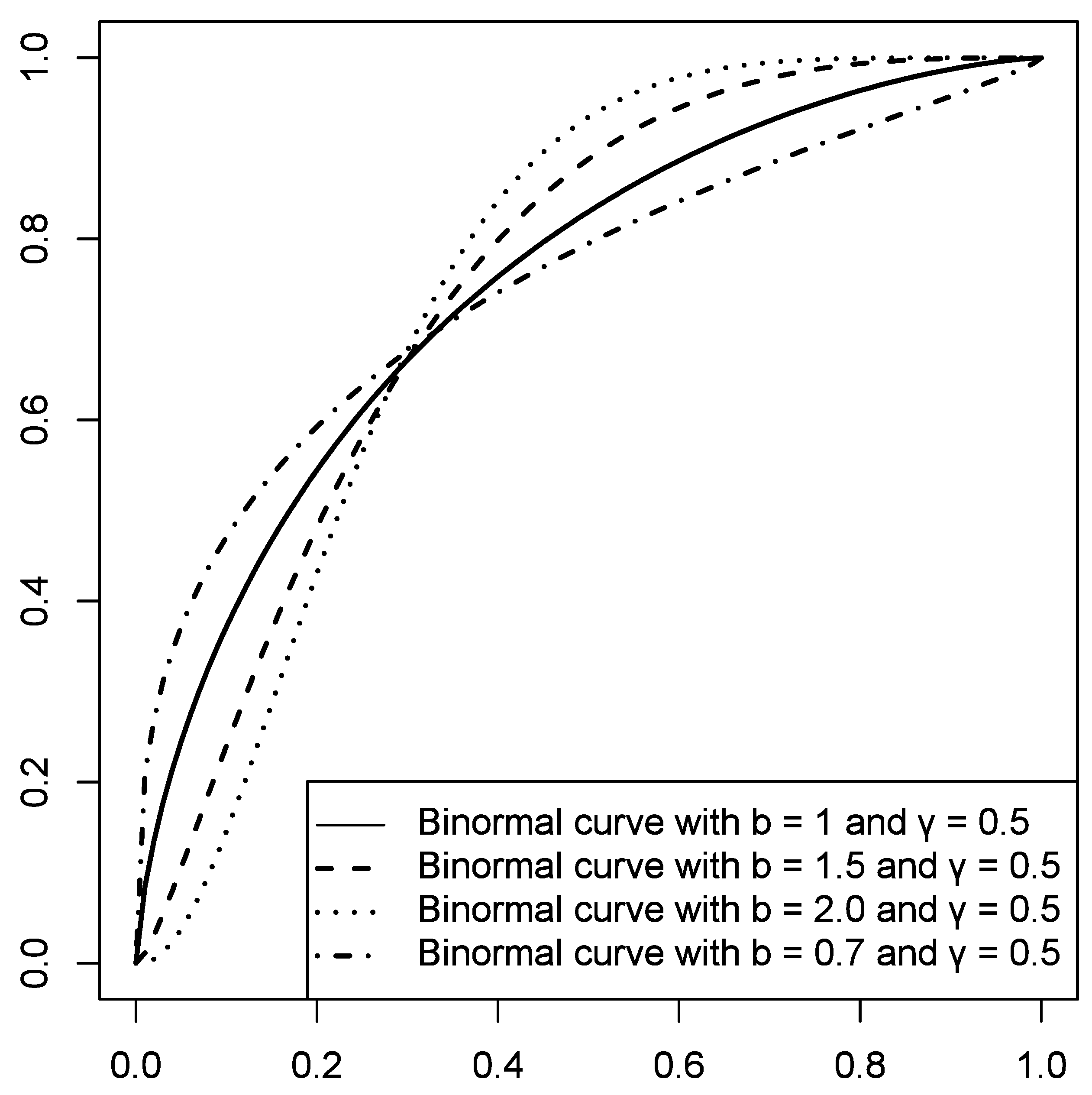
3.3. Binormal Model
3.4. Bilogistic Model
3.5. Power Function
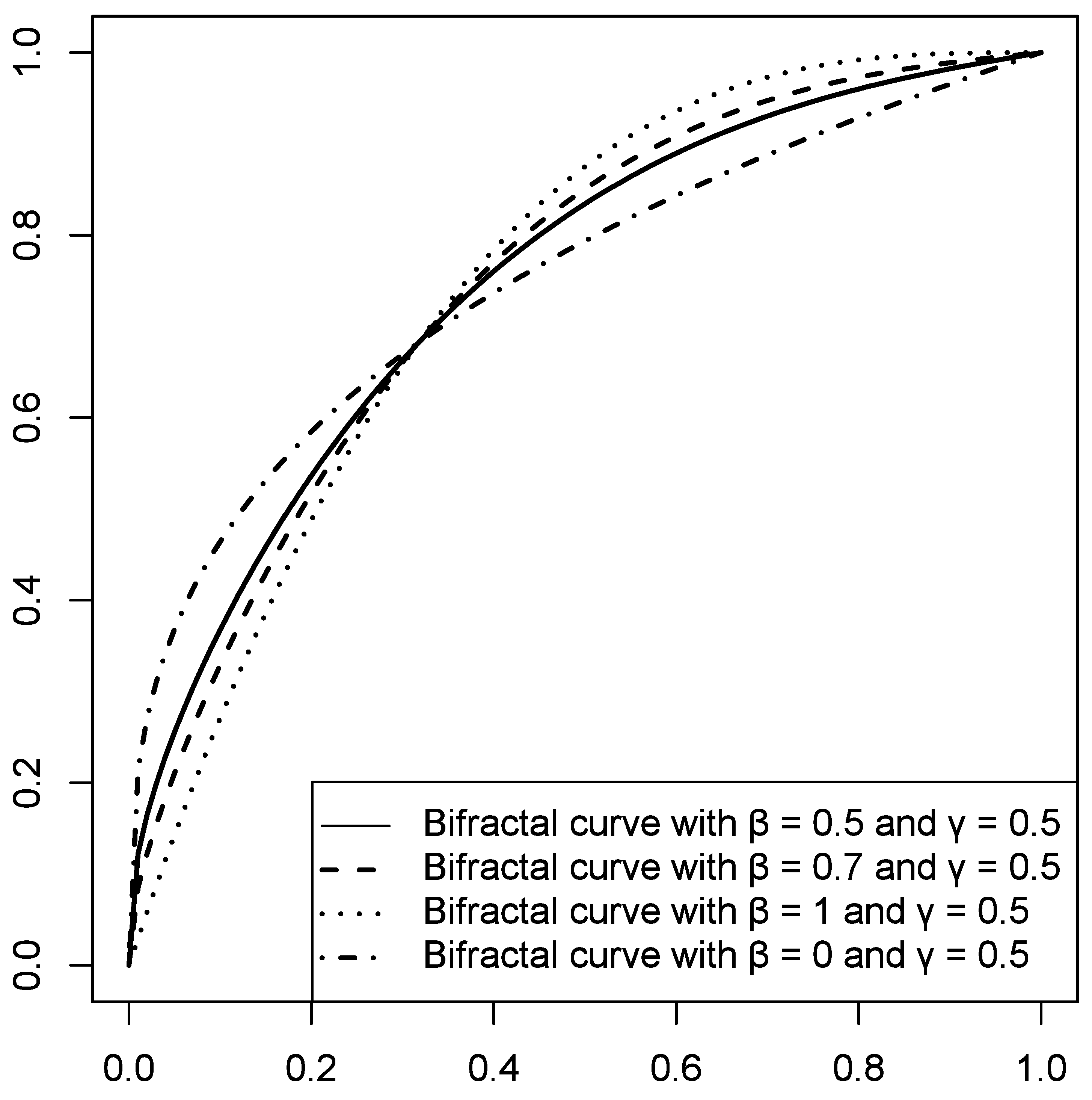
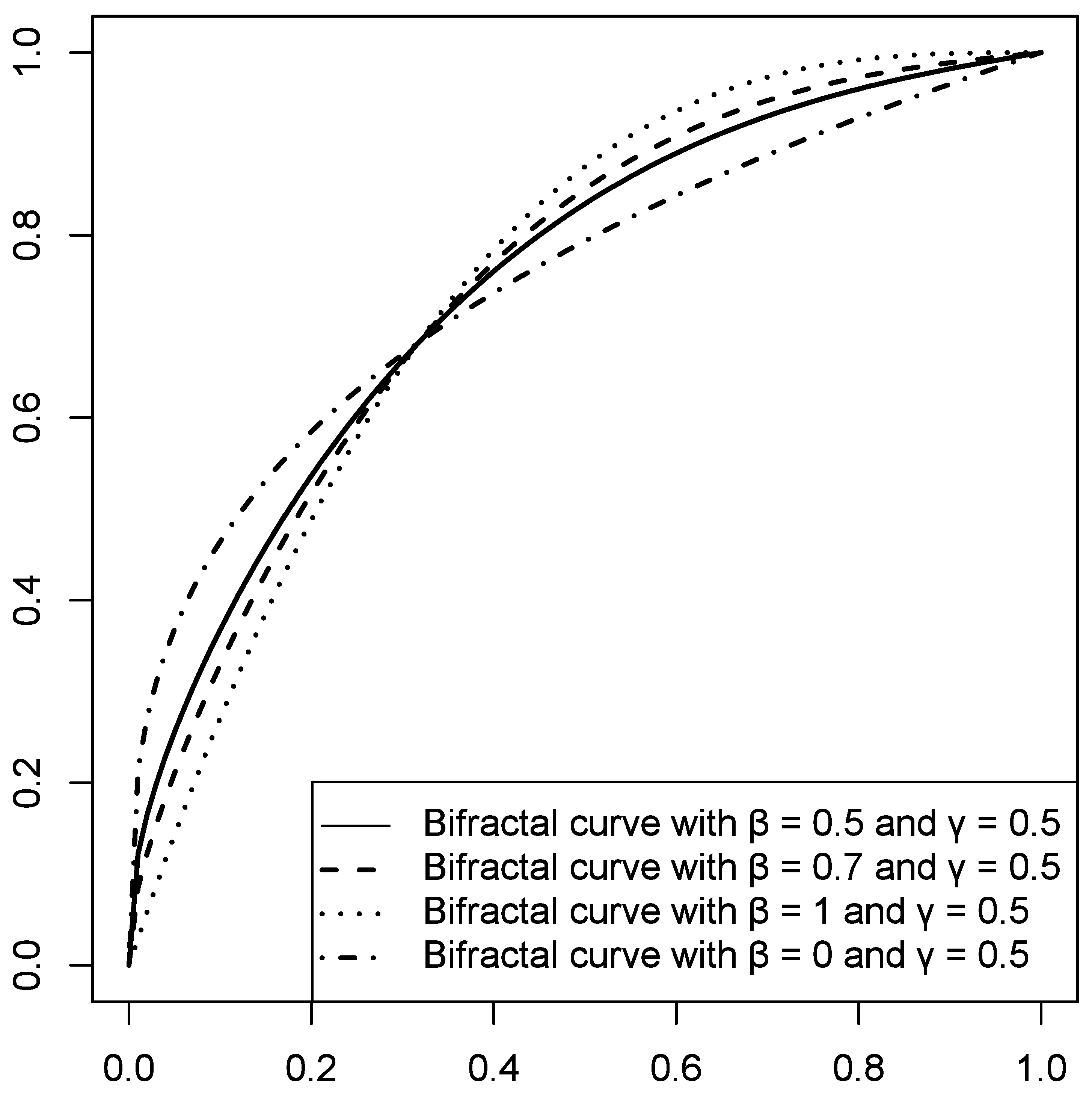
3.6. Bifractal Model
3.7. Reformulated Binormal and Midnormal Models
3.8. Midfractal Model
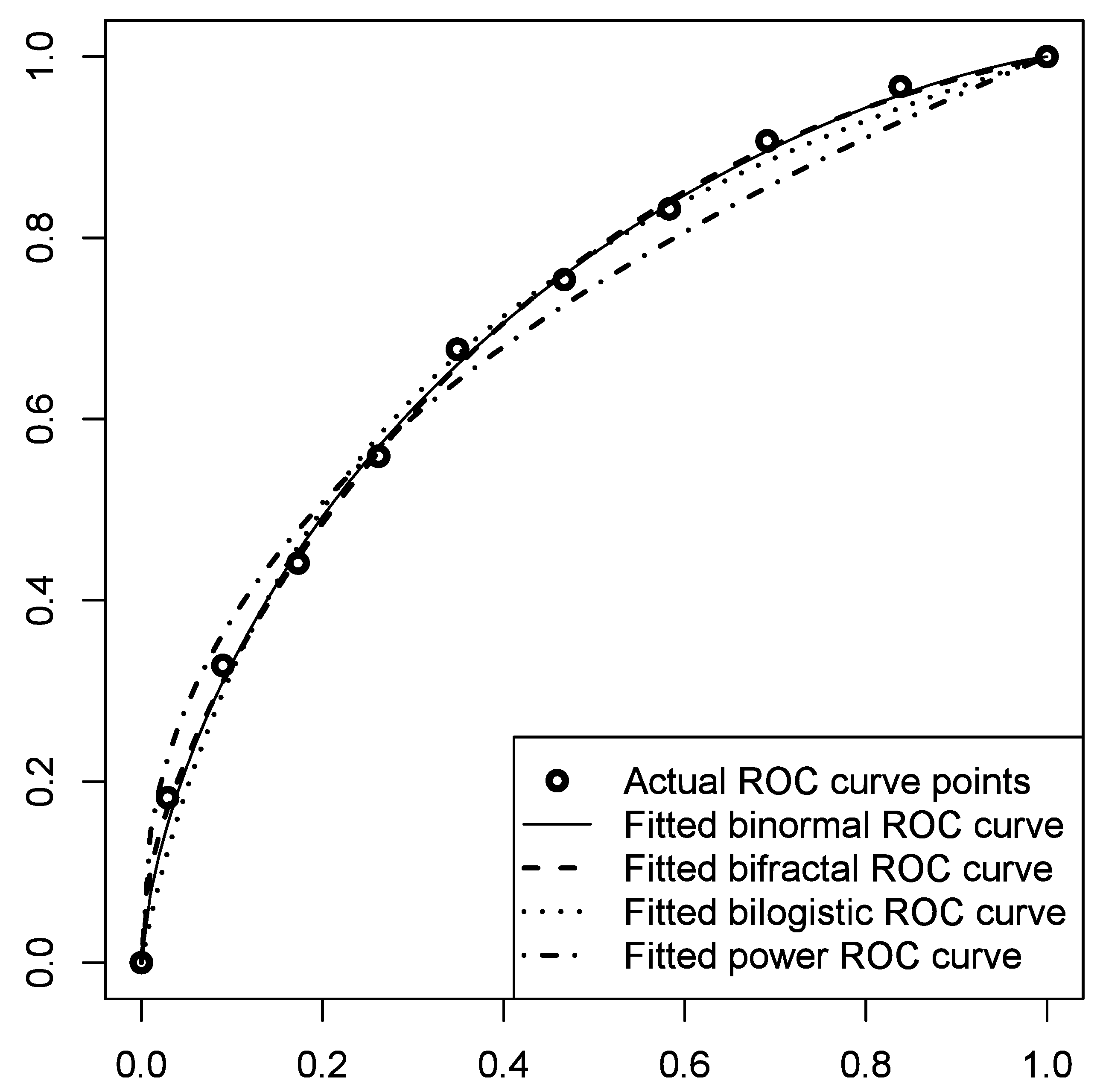
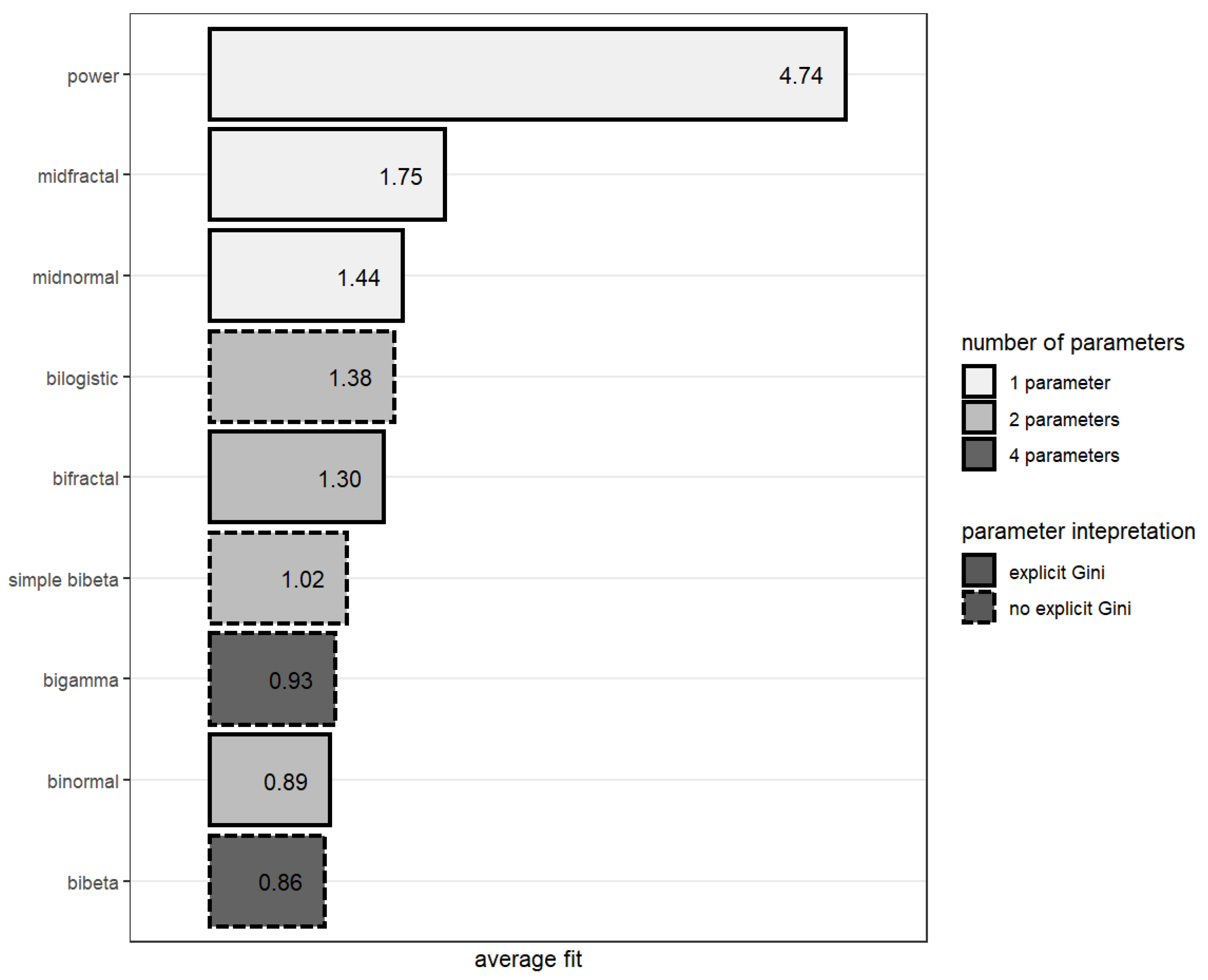
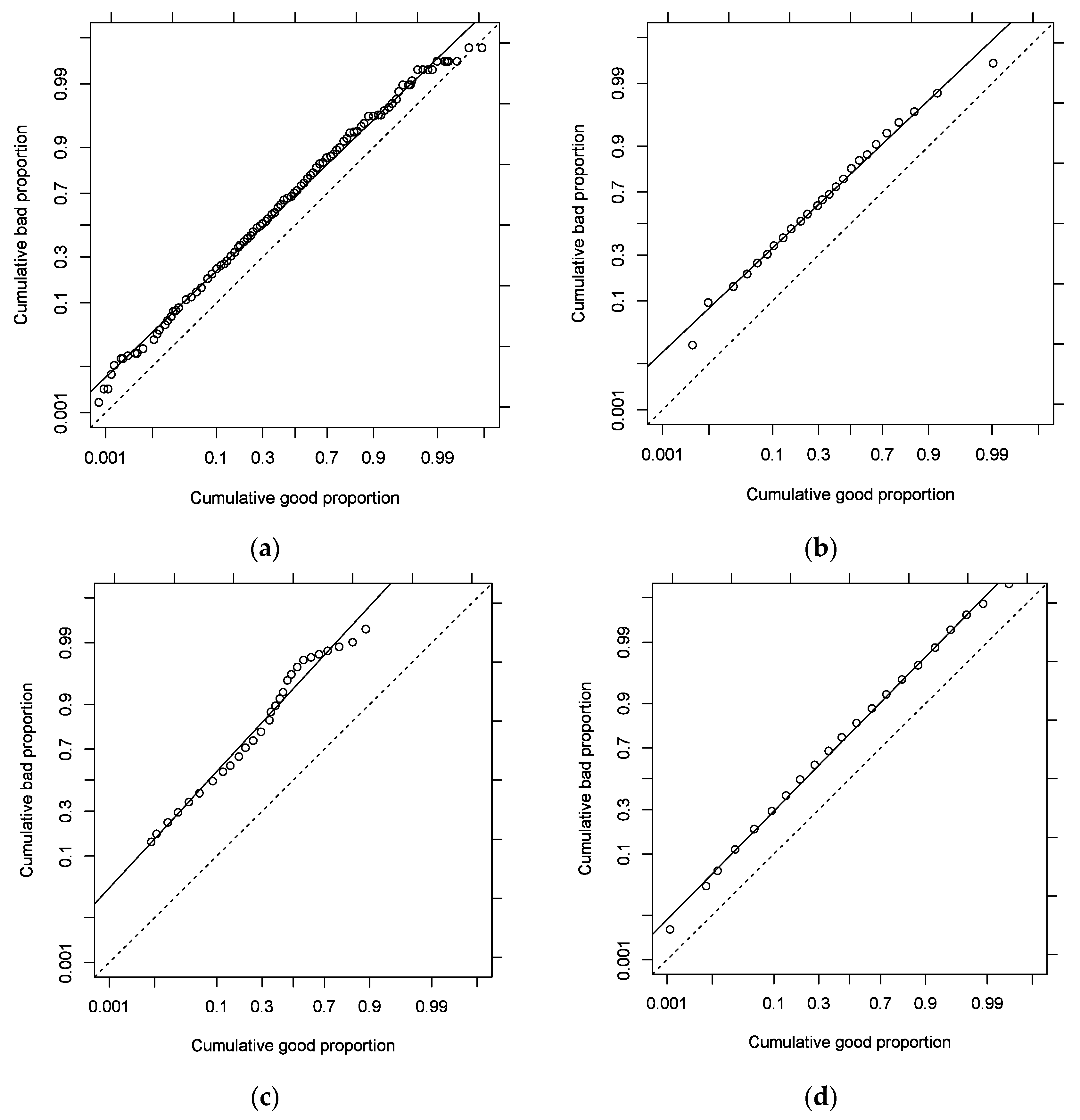
4. Fitting ROC Curve Models to Empirical Data
- (1)
- We used the following papers containing data or at least graphs of empirical ROC curves related to credit scoring: Řezáč and Řezáč (2011), Wójcicki and Migut (2010), Hahm and Lee (2011), Iyer et al. (2016), Tobback and Martens (2019), and Berg et al. (2020). Additionally, presentations by Jennings (2015) and Conolly (2017) were used. To obtain the numbers (x and y coordinates of the points that make up the empirical ROC) in some cases, it was necessary to read the data from the graph itself; therefore, an online tool was used to transform graphs into numbers by pointing and clicking.
- (2)
- Four retail lenders in Europe shared the empirical ROC curves of their credit-scoring models. The data were provided under the condition of anonymity. These models are presented in this article under the symbols A1, A2, B1, B2, B3, C1, and D1.
5. Discussion and Conclusions
Funding
Data Availability Statement
Conflicts of Interest
References
- Anderson, Raymond. 2007. The Credit Scoring Toolkit: Theory and Practice for Retail Credit Risk Management and Decision Automation. Oxford: Oxford University Press. [Google Scholar]
- Atapattu, Saman, Chintha Tellambura, and Hai Jiang. 2010. Analysis of area under the ROC curve of energy detection. IEEE Transactions on Wireless Communications 9: 1216–25. [Google Scholar] [CrossRef]
- Bamber, Donald. 1975. The area above the ordinal dominance graph and the area below the receiver operating characteristic graph. Journal of Mathematical Psychology 12: 387–415. [Google Scholar] [CrossRef]
- Bandos, Andriy I., Ben Guo, and David Gur. 2017. Estimating the Area Under ROC Curve When the Fitted Binormal Curves Demonstrate Improper Shape. Academic Radiology 24: 209–19. [Google Scholar] [CrossRef] [PubMed]
- Berg, Tobias, Valentin Burg, Ana Gombović, and Manju Puri. 2020. On the Rise of FinTechs: Credit Scoring Using Digital Footprints. The Review of Financial Studies 33: 2845–97. [Google Scholar] [CrossRef]
- Bewick, Viv, Liz Cheek, and Jonathan Ball. 2004. Statistics review 13: Receiver operating characteristic curves. Critical Care 8: 508. [Google Scholar] [CrossRef]
- Birdsall, Theodore G. 1973. The Theory of Signal Detectability: ROC Curves and Their Character. Ann Arbor: Cooley Electronics Laboratory, Department of Electrical and Computer Engineering, The University of Michigan. [Google Scholar]
- Blöchlinger, Andreas, and Markus Leippold. 2006. Economic benefit of powerful credit scoring. Journal of Banking & Finance 30: 851–73. [Google Scholar] [CrossRef]
- Bowyer, Kevin, Christine Kranenburg, and Sean Dougherty. 2001. Edge Detector Evaluation Using Empirical ROC Curves. Computer Vision and Image Understanding 84: 77–103. [Google Scholar] [CrossRef]
- Bradley, Andrew P. 1997. The use of the area under the ROC curve in the evaluation of machine learning algorithms. Pattern Recognition 30: 1145–59. [Google Scholar] [CrossRef]
- Chang, Chein-I. 2010. Multiparameter Receiver Operating Characteristic Analysis for Signal Detection and Classification. IEEE Sensors Journal 10: 423–42. [Google Scholar] [CrossRef]
- Chen, Weijie, and Nan Hu. 2016. Proper Bibeta ROC Model: Algorithm, Software, and Performance Evaluation. In Medical Imaging 2016: Image Perception, Observer Performance, and Technology Assessment. Presented at the Medical Imaging 2016: Image Perception, Observer Performance, and Technology Assessment, SPIE, San Diego, CA, USA, March 2; pp. 97–104. [Google Scholar] [CrossRef]
- Conolly, Stephen. 2017. Personality and Risk: A New Chapter for Credit Assessment. Presented at the Credit Scoring and Credit Control XV Conference, Edinburgh, UK, August 30–September 1; Available online: https://www.business-school.ed.ac.uk/crc-conference/accepted-papers (accessed on 27 April 2018).
- Cook, Nancy R. 2007. Use and misuse of the receiver operating characteristic curve in risk prediction. Circulation 115: 928–35. [Google Scholar] [CrossRef]
- Cook, Nancy R. 2008. Statistical evaluation of prognostic versus diagnostic models: Beyond the ROC curve. Clinical Chemistry 54: 17–23. [Google Scholar] [CrossRef] [PubMed]
- Davidov, Ori, and Yuval Nov. 2012. Improving an estimator of Hsieh and Turnbull for the binormal ROC curve. Journal of Statistical Planning and Inference 142: 872–77. [Google Scholar] [CrossRef]
- Djeundje, Viani B., Jonathan Crook, Raffaella Calabrese, and Mona Hamid. 2021. Enhancing credit scoring with alternative data. Expert Systems with Applications 163: 113766. [Google Scholar] [CrossRef]
- Dorfman, Donald D., Kevin S. Berbaum, Charles E. Metz, Russell V. Lenth, James A. Hanley, and Hatem Abu Dagga. 1997. Proper Receiver Operating Characteristic Analysis: The Bigamma Model. Academic Radiology 4: 138–49. [Google Scholar] [CrossRef]
- England, William L. 1988. An Exponential Model Used for Optimal Threshold Selection on ROC Curves. Medical Decision Making 8: 120–31. [Google Scholar] [CrossRef]
- Fang, Lian, and David C. Gossard. 1995. Multidimensional curve fitting to unorganized data points by nonlinear minimization. Computer-Aided Design 27: 48–58. [Google Scholar] [CrossRef]
- Faraggi, David, and Benjamin Reiser. 2002. Estimation of the area under the ROC curve. Statistics in Medicine 21: 3093–106. [Google Scholar] [CrossRef]
- Faraggi, David, Benjamin Reiser, and Enrique F. Schisterman. 2003. ROC curve analysis for biomarkers based on pooled assessments. Statistics in Medicine 22: 2515–27. [Google Scholar] [CrossRef]
- Fawcett, Tom. 2006. An Introduction to ROC Analysis. Pattern Recognition Letters 27: 861–74. [Google Scholar] [CrossRef]
- Frisken, Sarah F. 2008. Efficient Curve Fitting. Journal of Graphics Tools 13: 37–54. [Google Scholar] [CrossRef]
- Gneiting, Tilmann, and Peter Vogel. 2022. Receiver operating characteristic (ROC) curves: Equivalences, beta model, and minimum distance estimation. Machine Learning 111: 2147–59. [Google Scholar] [CrossRef]
- Gonçalves, Luzia, Ana Subtil, M. Rosário Oliveira, and Patricia de Zea Bermudez. 2014. ROC Curve Estimation: An Overview. REVSTAT-Statistical Journal 12: 1–20. [Google Scholar] [CrossRef]
- Gönen, Mithat, and Glenn Heller. 2010. Lehmann Family of ROC Curves. Medical Decision Making 30: 509–17. [Google Scholar] [CrossRef]
- Guest, Philip George. 2012. Numerical Methods of Curve Fitting. Cambridge: Cambridge University Press. [Google Scholar]
- Guido, Giuseppe, Sina Shaffiee Haghshenas, Sami Shaffiee Haghshenas, Alessandro Vitale, Vincenzo Gallelli, and Vittorio Astarita. 2020. Development of a Binary Classification Model to Assess Safety in Transportation Systems Using GMDH-Type Neural Network Algorithm. Sustainability 12: 6735. [Google Scholar] [CrossRef]
- Hahm, Joon-Ho, and Sangche Lee. 2011. Economic Effects of Positive Credit Information Sharing: The Case of Korea. Applied Economics 43: 4879–90. [Google Scholar] [CrossRef]
- Hajian-Tilaki, Karimollah. 2013. Receiver Operating Characteristic (ROC) Curve Analysis for Medical Diagnostic Test Evaluation. Caspian Journal of Internal Medicine 4: 627–35. [Google Scholar]
- Hamel, Lutz. 2009. Model Assessment with ROC Curves. In Encyclopedia of Data Warehousing and Mining, 2nd ed. Pennsylvania: IGI Global. [Google Scholar] [CrossRef]
- Hand, David J. 2009. Measuring classifier performance: A coherent alternative to the area under the ROC curve. Machine Learning 77: 103–23. [Google Scholar] [CrossRef]
- Hand, David J., and Christoforos Anagnostopoulos. 2013. When is the area under the receiver operating characteristic curve an appropriate measure of classifier performance? Pattern Recognition Letters 34: 492–95. [Google Scholar] [CrossRef]
- Hanley, James A. 1988. The Robustness of the “Binormal” Assumptions Used in Fitting ROC Curves. Medical Decision Making 8: 197–203. [Google Scholar] [CrossRef] [PubMed]
- Hanley, James A. 1996. The Use of the ‘Binormal’ Model for Parametric ROC Analysis of Quantitative Diagnostic Tests. Statistics in Medicine 15: 1575–85. [Google Scholar] [CrossRef]
- Hastie, Trevor, Robert Tibshirani, and Jerome Friedman. 2016. The Elements of Statistical Learning: Data Mining, Inference, and Prediction, 2nd ed. New York: Springer. [Google Scholar]
- Hautus, Michael J., Michael O’Mahony, and Hye-Seong Lee. 2008. Decision Strategies Determined from the Shape of the Same–Different ROC Curve: What Are the Effects of Incorrect Assumptions? Journal of Sensory Studies 23: 743–64. [Google Scholar] [CrossRef]
- Hsieh, Fushing, and Bruce W. Turnbull. 1996. Nonparametric and semiparametric estimation of the receiver operating characteristic curve. The Annals of Statistics 24: 25–40. [Google Scholar] [CrossRef]
- Idczak, Adam Piotr. 2019. Remarks on Statistical Measures for Assessing Quality of Scoring Models. Acta Universitatis Lodziensis. Folia Oeconomica 4: 21–38. [Google Scholar] [CrossRef]
- Iyer, Rajkamal, Asim Ijaz Khwaja, Erzo F. P. Luttmer, and Kelly Shue. 2016. Screening Peers Softly: Inferring the Quality of Small Borrowers. Management Science 62: 1554–77. [Google Scholar] [CrossRef]
- Janssens, A. Cecile J. W., and Forike K. Martens. 2020. Reflection on modern methods: Revisiting the area under the ROC Curve. International Journal of Epidemiology 49: 1397–403. [Google Scholar] [CrossRef]
- Jennings, Andrew. 2015. Expanding the Credit Eligible Population in the USA. Presented at the Credit Scoring and Credit Control XIV Conference—Conference Papers, Edinburgh, UK, August 26–28; Available online: https://www.business-school.ed.ac.uk/crc/category/conference-papers/2015/ (accessed on 27 April 2018).
- Jokiel-Rokita, Alicja, and Rafał Topolnicki. 2019. Minimum distance estimation of the binormal ROC curve. Statistical Papers 60: 2161–83. [Google Scholar] [CrossRef]
- Kochański, Błażej. 2021. Bifractal Receiver Operating Characteristic Curves: A Formula for Generating Receiver Operating Characteristic Curves in Credit-Scoring Contexts. Journal of Risk Model Validation 15: 1–18. [Google Scholar] [CrossRef]
- Krzanowski, Wojtek J., and David J. Hand. 2009. ROC Curves for Continuous Data, 1st ed. London: Chapman and Hall/CRC. [Google Scholar]
- Kürüm, Efsun, Kasirga Yildirak, and Gerhard-Wilhelm Weber. 2012. A classification problem of credit risk rating investigated and solved by optimisation of the ROC curve. Central European Journal of Operations Research 20: 529–57. [Google Scholar] [CrossRef]
- Lahiri, Kajal, and Liu Yang. 2018. Confidence Bands for ROC Curves With Serially Dependent Data. Journal of Business & Economic Statistics 36: 115–30. [Google Scholar] [CrossRef]
- Lappas, Pantelis Z., and Athanasios N. Yannacopoulos. 2021. A machine learning approach combining expert knowledge with genetic algorithms in feature selection for credit risk assessment. Applied Soft Computing 107: 107391. [Google Scholar] [CrossRef]
- Levy, Bernard C. 2008. Principles of Signal Detection and Parameter Estimation, 2008th ed. Berlin: Springer. [Google Scholar]
- Lloyd, Chris J. 2000. Fitting ROC Curves Using Non-linear Binomial Regression. Australian & New Zealand Journal of Statistics 42: 193–204. [Google Scholar] [CrossRef]
- Mandrekar, Jayawant N. 2010. Receiver Operating Characteristic Curve in Diagnostic Test Assessment. Journal of Thoracic Oncology 5: 1315–16. [Google Scholar] [CrossRef] [PubMed]
- Metz, Charles E. 1978. Basic principles of ROC analysis. Seminars in Nuclear Medicine 8: 283–98. [Google Scholar] [CrossRef]
- Metz, Charles E., and Xiaochuan Pan. 1999. “Proper” Binormal ROC Curves: Theory and Maximum-Likelihood Estimation. Journal of Mathematical Psychology 43: 1–33. [Google Scholar] [CrossRef]
- Mossman, Douglas, and Hongying Peng. 2016. Using Dual Beta Distributions to Create “Proper” ROC Curves Based on Rating Category Data. Medical Decision Making 36: 349–65. [Google Scholar] [CrossRef]
- Ogilvie, John C., and C. Douglas Creelman. 1968. Maximum-likelihood estimation of receiver operating characteristic curve parameters. Journal of Mathematical Psychology 5: 377–91. [Google Scholar] [CrossRef]
- Omar, Luma, and Ioannis Ivrissimtzis. 2019. Using theoretical ROC curves for analysing machine learning binary classifiers. Pattern Recognition Letters 128: 447–51. [Google Scholar] [CrossRef]
- Park, Seong Ho, Jin Mo Goo, and Chan-Hee Jo. 2004. Receiver Operating Characteristic (ROC) Curve: Practical Review for Radiologists. Korean Journal of Radiology 5: 11–18. [Google Scholar] [CrossRef]
- Pencina, Michael J., Ralph B. D’Agostino Sr., Ralph B. D’Agostino Jr., and Ramachandran S. Vasan. 2008. Evaluating the added predictive ability of a new marker: From area under the ROC curve to reclassification and beyond. Statistics in Medicine 27: 157–72, discussion 207–12. [Google Scholar] [CrossRef]
- Ramspek, Chava L., Kitty J. Jager, Friedo W. Dekker, Carmine Zoccali, and Merel van Diepen. 2021. External validation of prognostic models: What, why, how, when and where? Clinical Kidney Journal 14: 49–58. [Google Scholar] [CrossRef]
- Řezáč, Martin, and František Řezáč. 2011. How to Measure the Quality of Credit Scoring Models. Czech Journal of Economics and Finance (Finance a Úvěr) 61: 486–507. [Google Scholar]
- Řezáč, Martin, and Jan Koláček. 2012. Lift-Based Quality Indexes for Credit Scoring Models as an Alternative to Gini and KS. Journal of Statistics: Advances in Theory and Applications 7: 1–23. [Google Scholar]
- Satchell, Stephen, and Wei Xia. 2008. 8—Analytic models of the ROC Curve: Applications to credit rating model validation. In The Analytics of Risk Model Validation. Edited by George Christodoulakis and Stephen Satchell. Cambridge: Academic Press, pp. 113–33. [Google Scholar] [CrossRef]
- Scallan, Gerard. 2013. Why You Shouldn’t Use the Gini. ARCA Retail Credit Conference, Leura, Australia. Available online: https://www.scoreplus.com/assets/files/Whats-Wrong-with-Gini-why-you-shouldnt-use-it-ARCA-Retail-Credit-Conference-Nov-2013.pdf (accessed on 29 June 2022).
- Shen, Feng, Xingchao Zhao, Gang Kou, and Fawaz E. Alsaadi. 2021. A new deep learning ensemble credit risk evaluation model with an improved synthetic minority oversampling technique. Applied Soft Computing 98: 106852. [Google Scholar] [CrossRef]
- Siddiqi, Naeem. 2017. Intelligent Credit Scoring: Building and Implementing Better Credit Risk Scorecards. Hoboken: John Wiley & Sons. [Google Scholar]
- Somers, Robert H. 1962. A New Asymmetric Measure of Association for Ordinal Variables. American Sociological Review 27: 799–811. [Google Scholar] [CrossRef]
- Swets, John A. 1986. Form of Empirical ROCs in Discrimination and Diagnostic Tasks: Implications for Theory and Measurement of Performance. Psychological Bulletin 99: 181–98. [Google Scholar] [CrossRef]
- Swets, John A. 2014. Signal Detection Theory and ROC Analysis in Psychology and Diagnostics: Collected Papers. London: Psychology Press. [Google Scholar] [CrossRef]
- Tang, Tseng-Chung, and Li-chiu Chi. 2005. Predicting multilateral trade credit risks: Comparisons of Logit and Fuzzy Logic models using ROC curve analysis. Expert Systems with Applications 28: 547–56. [Google Scholar] [CrossRef]
- Thomas, Lyn C. 2009. Consumer Credit Models: Pricing, Profit and Portfolios. Oxford: Oxford University Press. [Google Scholar]
- Thomas, Lyn, Jonathan Crook, and David Edelman. 2017. Credit Scoring and Its Applications, 2nd ed. Philadelphia: Society for Industrial and Applied Mathematics. [Google Scholar] [CrossRef]
- Tobback, Ellen, and David Martens. 2019. Retail Credit Scoring Using Fine-Grained Payment Data. Journal of the Royal Statistical Society: Series A (Statistics in Society) 182: 1227–46. [Google Scholar] [CrossRef]
- Tripathi, Diwakar, Damodar R. Edla, Venkatanareshbabu Kuppili, and Annushree Bablani. 2020. Evolutionary Extreme Learning Machine with novel activation function for credit scoring. Engineering Applications of Artificial Intelligence 96: 103980. [Google Scholar] [CrossRef]
- Wichchukit, Sukanya, and Michael O’Mahony. 2010. A Transfer of Technology from Engineering: Use of ROC Curves from Signal Detection Theory to Investigate Information Processing in the Brain during Sensory Difference Testing. Journal of Food Science 75: R183–R193. [Google Scholar] [CrossRef] [PubMed]
- Wójcicki, Bartosz, and Grzegorz Migut. 2010. Wykorzystanie skoringu do przewidywania wyłudzeń kredytów w Invest-Banku. In Skoring w Zarządzaniu Ryzykiem. Kraków: Statsoft, pp. 47–57. [Google Scholar]
- Xia, Yufei, Junhao Zhao, Lingyun He, Yinguo Li, and Mengyi Niu. 2020. A novel tree-based dynamic heterogeneous ensemble method for credit scoring. Expert Systems with Applications 159: 113615. [Google Scholar] [CrossRef]





{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Model | Parameters | Fitting Objective (fobj) |
|---|---|---|
| Binormal (Equation (21)) | b = 0.9539; γ = 0.4290 | fobj = 8.09 × 10−5 |
| Bifractal (Equation (19)) | β = 0.4239; γ = 0.4298 | fobj = 8.40 × 10−5 |
| Bilogistic (Equation (12)) | α0 = 1.2884; α1 = 0.9279 | fobj = 3.31 × 10−4 |
| Power (Equations (16) or (17)) | θ = 0.4072 or γ = 0.4212 | fobj = 1.27 × 10−3 |
| Binormal | Midnormal | Bifractal | Midfractal | Bilogistic | Bibeta | Simplified Bibeta | Bigamma | Power | |
|---|---|---|---|---|---|---|---|---|---|
| Berg et al. (2020), Credit Bureau model | 0.79 | 1.40 | 1.14 | 1.58 | 0.53 | 0.80 | 1.07 | 0.80 | 2.75 |
| Berg et al. (2020), Digital Footprint model2 | 0.53 | 2.14 | 1.00 | 2.25 | 1.35 | 0.53 | 0.65 | 0.64 | 2.66 |
| Conolly (2017), curve I | 0.84 | 1.40 | 1.19 | 1.71 | 1.22 | 0.90 | 0.94 | 0.95 | 5.15 |
| Conolly (2017), curve II | 0.82 | 0.94 | 1.06 | 1.14 | 0.80 | 0.83 | 0.96 | 0.94 | 2.46 |
| Jennings (2015) | 0.75 | 1.09 | 1.38 | 1.64 | 0.78 | 0.77 | 1.11 | 0.80 | 5.76 |
| Hahm and Lee (2011), model A | 1.38 | 3.14 | 2.13 | 3.59 | 1.06 | 1.45 | 1.70 | 1.39 | 3.39 |
| Hahm and Lee (2011), model B | 0.68 | 0.95 | 1.65 | 1.79 | 1.11 | 0.91 | 1.04 | 0.69 | 5.24 |
| Iyer et al. (2016) | 0.42 | 1.42 | 1.04 | 1.77 | 1.29 | 0.43 | 0.61 | 0.42 | 6.13 |
| Řezáč and Řezáč (2011) | 0.82 | 1.11 | 1.34 | 1.58 | 1.11 | 0.90 | 1.05 | 1.05 | 5.21 |
| Řezáč and Řezáč (2011)—additional data points read from the graph | 0.53 | 0.53 | 0.71 | 0.72 | 1.50 | 0.50 | 0.53 | 0.52 | 4.45 |
| Tobback and Martens (2019) | 1.95 | 2.52 | 1.89 | 2.51 | 3.24 | 1.08 | 1.64 | 1.60 | 7.55 |
| Wójcicki and Migut (2010) | 0.67 | 0.98 | 1.66 | 1.80 | 1.63 | 0.68 | 0.85 | 0.74 | 6.54 |
| Model A1 | 0.50 | 0.55 | 0.68 | 0.73 | 0.88 | 0.51 | 0.62 | 0.60 | 3.36 |
| Model A2 | 0.68 | 0.81 | 0.80 | 0.88 | 0.88 | 0.68 | 0.80 | 0.78 | 3.00 |
| Model B1 | 0.90 | 0.90 | 1.34 | 1.40 | 2.04 | 0.82 | 0.83 | 0.84 | 5.41 |
| Model B2 | 1.66 | 3.32 | 1.69 | 3.32 | 1.55 | 1.67 | 1.81 | 1.83 | 8.61 |
| Model B3 | 1.71 | 2.27 | 2.08 | 2.63 | 2.61 | 1.55 | 1.60 | 1.57 | 4.03 |
| Model C1 | 0.46 | 0.71 | 0.95 | 1.13 | 0.72 | 0.49 | 0.79 | 0.78 | 4.78 |
| Model D1 | 0.90 | 1.18 | 0.92 | 1.13 | 1.82 | 0.78 | 0.79 | 0.79 | 3.57 |
| Model | Pros | Cons |
|---|---|---|
| Bigamma/bibeta/simple bibeta | Good fit. “Proper” with some restrictions. | 4 parameters (2 in case of simple bibeta), no explicit AUROC parameter, complicated implementation (requires beta and gamma distribution functions). |
| Bilogistic | 2 parameters, simple mathematical operations. | On average, the worst among the models with more than one parameter, presence of non-concave regions. |
| Bifractal/midfractal | 2 parameters (or 1 in case of midfractal), explicit Gini parameter, interpretable shape parameter, only the simplest mathematical operations needed, monotone in the whole domain. | Lack of theoretical background, clearly “algebraic”. |
| Binormal/midnormal | 2 parameters (or 1 in case of midnormal), the model may be reformulated to produce an explicit Gini parameter. Mathematical tractability, convenience, good empirical fit in case of credit scoring and in other domains. | Presence of “hooks”: non-concave regions of the curve if b ≠ 1. |
| Power | One parameter | Very poor fit. |
Publisher’s Note: MDPI stays neutral with regard to jurisdictional claims in published maps and institutional affiliations. |
© 2022 by the author. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Kochański, B. Which Curve Fits Best: Fitting ROC Curve Models to Empirical Credit-Scoring Data. Risks 2022, 10, 184. https://doi.org/10.3390/risks10100184
Kochański B. Which Curve Fits Best: Fitting ROC Curve Models to Empirical Credit-Scoring Data. Risks. 2022; 10(10):184. https://doi.org/10.3390/risks10100184
Chicago/Turabian StyleKochański, Błażej. 2022. "Which Curve Fits Best: Fitting ROC Curve Models to Empirical Credit-Scoring Data" Risks 10, no. 10: 184. https://doi.org/10.3390/risks10100184
APA StyleKochański, B. (2022). Which Curve Fits Best: Fitting ROC Curve Models to Empirical Credit-Scoring Data. Risks, 10(10), 184. https://doi.org/10.3390/risks10100184