Abstract
In this study, we proposed two types of hybrid models based on the heterogeneous autoregressive (HAR) model and support vector regression (SVR) model to forecast realized volatility (RV). The first model is a residual-type model, where the RV is first predicted using the HAR model, and the residuals are used to train the SVR model. The residual component is then predicted using the SVR model, and the results from both the HAR and SVR models are combined to obtain the final prediction. The second model is a weight-based model, which is a combination of the HAR and SVR models and uses the same independent variables and dependent variables as the HAR model; we adjust the contribution of the two models to the predicted values by giving different weights to each model. In particular, four volatility models are used in RV forecasting as basic models. For empirical analysis, the RV of returns of the Tokyo stock price index and five individual stocks of TOPIX 30 is used as the dataset. The empirical results reveal that according to the model confidence set test, the weight-type model outperforms the HAR model and the residual-type HAR–SVR model.
1. Introduction
Volatility plays an important role in risk management. However, there is an inherent problem with volatility: real volatility is latent and is not directly observable. Volatility can be estimated using other approaches, such as the autoregressive conditional heteroskedasticity (ARCH) and generalized autoregressive conditional heteroskedasticity (GARCH) models proposed by Engle (1982) and Bollerslev (1986). Such models have been developed and studied extensively; however, because GARCH models use open-to-close return data, they are still subject to unobserved latent volatility. To overcome this problem and take full advantage of information from high-frequency intraday data, Andersen et al. (2003) proposed a framework to compute the summation of the squared high-frequency intraday returns to construct realized volatility (RV) using high-frequency data for measuring, modeling, and forecasting latent volatility. When the measurement error of the RV is ignored, volatility essentially becomes “observable”.
For forecasting RV, Corsi (2009) introduced a simple and easy-to-implement model called the heterogeneous autoregressive (HAR) model. This model utilizes the past daily, weekly, and monthly RVs called 1, 5, and 22 lags, respectively, as variables to predict the future daily RV. The HAR model captures the long-term memory and persistence of essential features in financial data. The goal of (G)ARCH models is to estimate and forecast unobservable latent volatility, whereas RV is a nonparametric estimator of latent volatility, and autoregressive moving average (ARMA)-type models, including the HAR model, are used to predict observable estimators, which are distinguished from each other by the difference in the dependent variables Guidolin and Pedio (2018), McAleer and Medeiros (2008).
Since its introduction, the HAR model has been widely used and continuously refined. Corsi and Renò (2012) further developed the HAR model into the HAR with component jumps (HAR-CJ) model by decomposing RV into continuous and jump components. Building on the realized semivariance, Patton and Sheppard (2015) proposed a HAR-semivariance (HAR-SV) model and demonstrated that it is better than the HAR-CJ model. Bollerslev et al. (2016) considered the distribution of measurement error and realized quarticity (RQ) as an estimator of the variance in the measurement error to construct the HARQ model, which outperformed the other HAR series models in an empirical analysis. Wen et al. (2016) used alternative risk measures to construct a series of HAR-type models for predicting volatility in crude oil futures. Audrino et al. (2018) proposed the flexible HAR (1, 2, …, p) model, which goes beyond the traditional HAR (1, 5, 22) model. This model treats all past p days of RV as estimators, using the least absolute shrinkage and selection operator (LASSO) method with a regularization term to estimate the model, which mitigates the problem of overfitting. Lyócsa and Stašek (2021) introduced a method to improve the predictive accuracy of the HAR model by combining multiple results from HAR models with different volatility estimators. This approach involves averaging the predictions of all the models by using different volatility estimators to derive the final prediction.
In recent years, several studies have used machine learning methods directly in financial forecasting or implementing time series models to improve forecasting accuracy. Various studies by Gupta et al. (2023), Ramos-Pérez et al. (2019), Demirer et al. (2020), Carr et al. (2019), and others have discussed the prediction of RV in financial markets using individual machine learning models such as artificial neural networks and support vector machine (SVM).
In addition to this, studies have combined machine learning models with financial time series models to better capture both linear and nonlinear patterns in time series. Kim and Won (2018) combined long short-term memory (LSTM)-based methods with a GARCH-type model to construct numerous hybrid models. The empirical results with returns data of the KOSPI 200 index revealed that the LSTM-based hybrid models are better than single GARCH-type models in prediction accuracy. Zhang and Qiao (2021) and Sun and Yu (2020) proposed HAR- and GARCH-type support vector regression (SVR) models, respectively. Their finding showed that SVR effectively improved the prediction accuracy of HAR-type and GARCH-type models. Pai and Lin (2005), Li et al. (2010), and Zhu et al. (2017) investigated a hybrid model based on the autoregressive integrated moving average (ARIMA) and SVR or SVM for time series forecasting in different fields, revealing that a hybrid model can improve on the ARIMA model in prediction accuracy.
However, in these studies, the researches did not consider the optimal hyperparameter setting of machine learning models when combining machine learning with financial time series models. Therefore, in this study, following Huang (2012), we use the genetic algorithm (GA) method to optimize the hyperparameters of the SVR model so that we can choose more appropriate hyperparameters. Based on this automated machine learning model, we propose two types of hybrid models that combine the HAR model with the SVR to predict the RV of stock indices and individual stocks returns. The first type predicts the residual of the HAR model predictions using the GA-optimized SVR model as a nonlinear component. Then, we use the sum of the two predicted components as the predicted value of volatility. The second is a weight-type model, where the predicted value is described as , which captures the nonlinear component. We construct the two types hybrid models based on four basic HAR-type models. Then, we compare the performance of these models in out-of-sample forecasting. Additionally, we use other extensions of the HAR model, such as HAR-semivariance (HAR-SV), HAR-signed jumps (HAR-SJ), and HAR-RQ (HARQ), in this study and combine them with SVR. In the empirical analysis, we collect high-frequency intraday price data (and, thus, computing the returns) from the Tokyo stock price index (TOPIX) and five individual stocks of TOPIX 30 in the Japanese market from 2020 to 2022 as our dataset for an out-of-sample forecasting test to compare the performance of the hybrid models and basic HAR-type model. Our main contributions are as follows: (1) we propose that the problem of parameter tuning in RV prediction using machine learning models can be made more efficient using automatic machine learning models; (2) we apply the optimization algorithm not only for hyperparameter optimization but also in the selection of weights when combining different predictive values; and (3) we conduct an empirical study in the Japanese stock market and prove the effectiveness of this method.
The rest of this paper is structured as follows. First, in Section 2 we introduce the volatility estimators that will be used in this study. Second, in Section 3, we present all the base models employed in this study and the methodology that will be used to combine the models. Next, in Section 4, we conduct an empirical analysis of our dataset and report and discuss the results. Finally, we present the conclusions in Section 5.
2. Volatility Estimators
2.1. Realized Volatility
We consider a log-price of a single asset, which follows a stochastic process as follows:
where is the drift term, is the instantaneous volatility term, and is a standard Brownian motion.
In this price process, the latent volatility is the integrated variance (IV), and the one-day IV is defined by the following equation:
In this equation, the is the instantaneous volatility at time .
As mentioned above, daily IV is unobservable and daily RV computed from high-frequency return data is used as an estimator of IV (Andersen et al. 2001a, 2001b; Barndorff-Nielsen and Shephard 2002).
The definition of within a day is as follows:
where is the return of the ith subinterval, M is the number of subinterval on the day t, and is the logarithm of the price at time point i in day t.
Therefore, the weekly and monthly average RVs are as follows
2.2. Realized Semivariance
According to Barndorff-Nielsen et al. (2008), the realized semi-volatility is primarily used to measure the positive and negative variation in the returns. The daily positive RV() is as follows:
and the daily negative RV() is as follows:
Furthermore, by definition, can be decomposed into and , as follows:
This decomposition holds for any given point in time.
2.3. Signed Jump
was introduced by Patton and Sheppard (2015), and the daily is defined by the following equation:
When the positive price fluctuation is greater than the negative price fluctuation, is positive, and when the negative fluctuation is greater than the positive fluctuation, is negative.
3. Basic Models
3.1. Heterogeneous Autoregressive Model
The HAR-RV model is widely used in finance to predict the RV of financial assets using high-frequency data. It was proposed by Corsi (2009). It is a time-varying autoregressive model that uses lagged RV at different time scales as predictors to forecast RV. The most classical HAR-RV model is the HAR-RV (1, 5, 22) model, which uses three predictors—daily RV, weekly average RV, and monthly average RV.
3.2. HAR-RSV and HAR-SJ Model
Based on realized semivariance (RSV), Patton and Sheppard (2015) have proposed a HAR-semivariance (HAR-SV) model. This model decomposes the daily into and by Equation (8), and then uses the and to construct the HAR model. The model is defined as follows:
We include the HAR-RV-with-jumps (HAR-RV-J) model, which was proposed by Andersen et al. (2007), in our study. Then, we replace the jump component with the SJ component, because Patton and Sheppard (2015) found that a signed jumps model is helpful for forecasting volatility, to create a model we call the HAR-SJ model. The model is defined as follows:
3.3. The HARQ Model
RV aims to estimate the IV of assets over a given period. However, the M of Equation (3) has an upper bound, causing an estimation error. According to Barndorff-Nielsen and Shephard (2002), RV can be expressed as follows:
where denotes mixed normal, and is the integrated quarticity (IQ), which is defined as follows:
Then, the IQ can be estimated by the RQ
Following Bollerslev et al. (2016), we can construct the HARQ model as follows:
We refer to HAR-RV, HAR-SV, HAR-SJ, and HARQ collectively as HAR-X models.
3.4. Genetic Algorithms and Support Vector Regression
SVR is an extension of the classification method SVM that was introduced in 1995 (Cortes and Vapnik 1995). SVR minimizes the error to obtain the regression equation by setting two parallel lines and enclosing the region between these two lines as tightly as possible around the output values. When data are difficult to fit in lower dimensions, one of the advantages of SVR is that it can map data in lower dimensional spaces to higher dimensional spaces by means of a kernel function, allowing the model to fit the data better. In the SVR training procedure, given a T days dataset , where is the training vector, , and is the output value, , the one-day ahead forecasting of SVR in time t can be expressed as a linear equation as follows:
where , the predictor used in the HAR-X models will be used to obtain SVR models, so or 4, depending on the type of HAR-X model (only in the HAR-RV model is ), is the jth predictor in time t, and is the coefficient of .
To obtain the , SVR transforms the regression problem into a convex optimization problem,
subject to
where represents how large errors can be tolerated in regression tasks; is the actual value; and is the predicted value on the day i. Moreover, to allow some errors, Bennett and Mangasarian (1992) introduced the soft margin method, which uses the slack variables and to relax the restriction in Equation (19), and Cortes and Vapnik (1995) used this in SVM. Then, the optimization problem is as follows:
subject to
where the penalty coefficient is a constant. Solving this optimization problem by constructing a Lagrange function, we can obtain the time t coefficients (for details see Smola and Schölkopf 2004; Cortes and Vapnik 1995). Through the kernal function, SVR can be used to construct nonlinear time series problems. Furthermore, by choosing different kernel functions, SVR can construct different SVMs to obtain different regression equations. Commonly used kernel functions include the linear kernel function, polynomial kernel function, and radial basis function (RBF).
Among them, the RBF kernel function (Equation (22)) is the most adaptable to various problems. Parameter describes the variance of the kernel function, and together with the penalty coefficient C and the sensitivity , it affects the model’s fitting ability to the data. Thus, the aim of optimizing SVR is to find the optimal values of these three parameters , and 1.
GA is a search algorithm based on the principles of natural selection in biological evolution; Whitley (1994) provided a tutorial on the GA.
The basic principle of GA is to use a fitness function to evaluate individuals, eliminate those with low fitness, and retain those with the highest fitness to generate the next generation of individuals, thereby iteratively searching for the optimal solution. In our approach, we use the GA method to iteratively search for the optimal values of the three parameters () of the SVR to automatically optimize and find the best model.
3.5. Hybrid Model
In this study, we propose two types of hybrid HAR-X-SVR models, called HAR-X-SVR-1 and HAR-X-SVR-2, respectively. Following Pai and Lin (2005), our HAR-X-SVR-1 model decomposes the RV of returns into linear and nonlinear parts, as presented in the following equation:
where is the linear part prediction; is the nonlinear part prediction; and is the residual. Then, we use the HAR-X model to predict the linear part and assume that the HAR-X model can capture all the linear information. Therefore, let and represent the predictions of the HAR-X model and the SVR model for day t, respectively; then, the remaining part is the nonlinear part and the residual, as presented in the following equation:
In the HAR-X-SVR-2 model, we construct the HAR-X-SVR model by combining the HAR and SVR with a GA-optimized weight . The prediction of RV is calculated as below:
In addition to searching for the three parameters of SVR using GA, we search for the weight for the HAR-X-SVR-2 model (see Algorithm 1).
| Algorithm 1 HAR-X-SVR Model for T days forecasting |
|
4. Empirical Analysis
4.1. Data Description
In this study, our dataset was collected from the high-frequency intraday price data of the TOPIX and five individual stocks on TOPIX 30 from 1 January 2020 to 30 December 2022. We calculated the daily RV and other volatility estimators using the five-minute returns data. The computation method is presented in Equations (3), (6), (7), and (9). There are total 731 observations in our dataset.
In Table 1, we provide a summary of the data, including the maximum, minimum, and standard deviation of RV for TOPIX and individual stocks, as well as the 5%, 50%, and 95% quantiles of RV. Notably, the maximum and 95% quantile values of RV exhibit great variation because of the inclusion of the stock market crash in early 2020 due to the impact of the coronavirus pandemic.

Table 1.
Data summary.
Figure 1 and Figure 2 depict the RV of our datasets, with the vertical coordinate being the RV and the horizontal coordinate being the date, where the blue and red lines represent the 95% quantile value and the average value, respectively. The graphs reveal that all datasets reached a high level at the beginning of the coronavirus pandemic, with long periods exceeding the 95% quantile value. Among them, 8802, 8316, and 8411 reached a high level at the end of 2022 again but not as high as at the beginning of the coronavirus pandemic, and the extreme RV value of 8316 occurred at the end of 2022. Furthermore, 8802, 8316, 8411, and TOPIX had a high level of RV at the end of the other periods, and they all had relatively stable levels of RV during the other periods, whereas 2914 and 9432 had a few higher peaks.
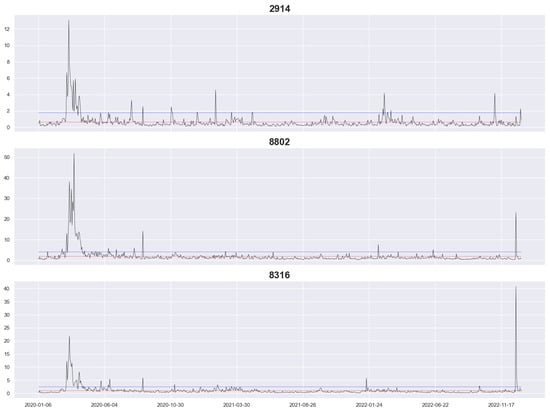
Figure 1.
Realized volatility for stocks 2914, 8802, and 8316.
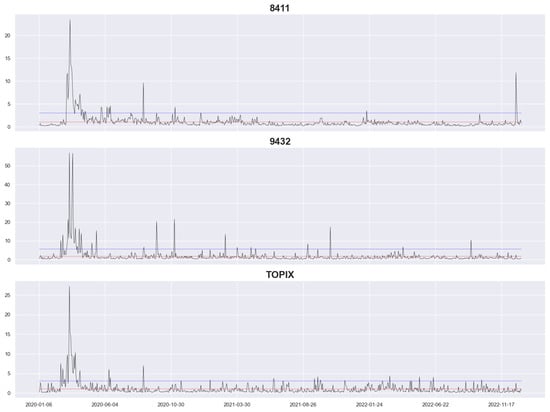
Figure 2.
Realized volatility for stocks 8411 and 9432 and TOPIX as a whole.
4.2. Out-of-Sample Forecasting
In this study, we used the first 400 days data to train the models and the remaining 331 days data for the out-of-sample forecasting test. A fixed-length rolling window (RW) approach was used to update the different models each day, and we also used an increasing window (IW) approach to train the models. The training sizes of the IW are from 400 to 730 days. Such a design is intended to consider the possible effects of different windowing approaches on the prediction results.
Throughout the training process, for HAR-X-SVR-1, we estimate HAR-X, derive the in-sample residuals, and use the in-sample residuals as the dependent variable to train the SVR. For HAR-X-SVR-2, we use the predictor and dependent variables that are identical to the corresponding HAR-X.
We employed four basic models: HAR-RV, HAR-SV, HAR-SJ, and HARQ. This resulted in 3 models under each basic model and 12 models in total. Among these models, the HAR-X model is estimated using OLS. After obtaining predictions from all the models, we calculated the loss function of the models in 22-day intervals as a sample for comparing the performance of each model with model confidence set (MCS). Patton (2011) finds that the mean square error (MSE) and the quasi-likelihood (Q-LIKE) are robust when comparing forecasting models. Following this paper, we utilized two loss functions—MSE and Q-LIKE—which are defined as follows:
Model Confidence Set
The MCS method, introduced by Hansen et al. (2011), is an approach used to select the optimal predictive model. It addresses the challenge of comparing the performance of different models within different intervals, where reliance on a single loss function value alone may not be sufficient. The main procedure is to select a loss function for comparison and calculate the loss for all models in each period. In the case of time series models, a predetermined interval length is defined, and the loss is calculated for each interval within an extended period.
The set of all models is defined as , and an additional set of models is denoted as M(). Then, an equivalence test and an elimination rule are defined. The is used to test whether the models in the set M exhibit “good” performance based on the computed loss function. If any models in M demonstrate poor performance, the hypothesis is rejected, and the elimination rule is applied to eliminate models. This process continues until the delta hypothesis is accepted.
Throughout the process, each model is assigned a p-value, with a p-value of 1 indicating the best model, and models that are eliminated earlier have lower p-values. For details on the specific steps, see the study by Hansen et al. (2011).
4.3. Results
Based on different loss functions and windowing approaches, we report the p-values of our models for MCS on different datasets in Table 2, Table 3, Table 4 and Table 5. The higher the p-value, the higher the performance of a model under the loss function—the highest is 1, and the lowest is 0. Moreover, we rank the models according to the p-values and sort the models according to the magnitude of the p-values.
Table 2.
MCS results for HAR-RV-based models.
Table 3.
MCS result for HAR-SV-based models.
Table 4.
MCS result for HAR-SJ-based models.
Table 5.
MCS result for HARQ-based models.
In Table 2, we report the MCS p-values for the models we used the HAR-RV model to construct. The hybrid model significantly outperforms the HAR-RV model in datasets 2914, 8316, and 8411, and the HAR-RV model outperforms the hybrid model in dataset 2914 only under Q-LIKE when using the IW approach.
Furthermore, the hybrid model HAR-RV-SVR-1 significantly outperforms HAR-RV-SVR-2 only under MSE in dataset 8411 when using the RW approach. No hybrid model outperformed the HAR-RV model in the 8802 and 9432 datasets. In the TOPIX dataset, HAR-RV performs better under MSE, and HAR-RV-SVR-2 performs better under Q-LIKE. Using all datasets, we calculated the average rank of HAR-RV, HAR-RV-SVR1, and HAR-RV-SVR-2; based on the average rank, HAR-RV-SVR-2 performs better than the other two models.
The results for the HAR-SV-based models (Table 3) reveal that HAR-SV-SVR-2 significantly outperforms HAR-SV and HAR-SV-SVR-1, and HAR-SV only outperforms HAR-SV-SVR-2 under Q-LIKE in datasets 8802, 9432, and 2914 using the RW, IW, and IW approaches, respectively. After combining all rankings, we find that HAR-SV-SVR-2 significantly outperforms HAR-SV and HAR-SVR-1 in terms of average ranking.
The results for the HAR-SJ-based models (Table 4) reveal that HAR-SJ-SVR-2 significantly outperforms HAR-SJ and HAR-SJ-SVR-1 in datasets 2914, 8316, and 8411; in contrast, in datasets 8802 and 9432, HAR-SJ slightly outperforms the other two hybrid models. In the TOPIX dataset, HAR-SJ performs better under MSE, and HAR-SJ-SVR-2 performs better under Q-LIKE. After combining all rankings, we find that HAR-SJ-SVR-2 outperforms the other two models.
Similar to the results for the HAR-SV-based models, the results for the HARQ-based models (Table 5) reveal that HARQ-SVR-2 outperforms the other two models, and the HARQ model outperforms the other two models in datasets 9432 and 2914 under Q-LIKE. However, in terms of average ranking, HARQ-SVR-2 significantly outperforms the other two models. After combining all four HAR-X-based models, we find that the average rankings of HAR-X, HAR-X-SVR-1, and HAR-X-SVR-2 are 1.896, 2.333, and 1.229 under the RW approach and 1.771, 2.375, and 1.375 under the IW approach, respectively. In both the RW and IW approaches, the HAR-X-SVR-2 significantly outperforms the other two types of models.
4.4. Discussion
4.4.1. Summary
Regarding return volatility forecasting, in addition to the classic (G)ARCH and ARMA models, there has been an influx of research on forecasting using various types of machine learning models with the development of machine learning technology. Sezer et al. (2020) provided an exhaustive introduction to the application of deep learning models in financial time series forecasting. In recent years, some studies have attempted to combine statistical and machine learning models to improve forecasting accuracy (e.g., Zhang and Qiao 2021; Kim and Won 2018). However, they still take a human-set approach to selecting hyperparameters for machine learning models, which is time-consuming and labor-intensive and requires much experience in adjusting the parameters to the optimal level. Waring et al. (2020) provided an exhaustive overview of the application of machine learning and automated machine learning to time series forecasting. They also compared different frameworks and techniques, although they did not conduct an empirical analysis. Therefore, in this study, we propose the use of automatic machine learning methods to solve the problem of setting hyperparameters when using machine learning, thus simplifying the parameter tuning of machine learning. Our model is not limited to hyperparameter optimization but also includes the selection of weights when combining the forecasts from the HAR and SVR models with an automatic optimization algorithm. The weights of the model are dynamic and are updated daily according to the training set.
4.4.2. Empirical Results
We compare the two hybrid models with the regular HAR-X model in the Japanese stock market; Kim and Won (2018) and Zhang and Qiao (2021) analyzed the performance of the hybrid model in the Korean and Chinese stock markets, respectively. Their studies revealed that the hybrid model is helpful for improving RV forecasting accuracy. In our empirical study, we use six datasets, including an index dataset (TOPIX) and five individual stock datasets (stock symbol: 2914, 8316, 8411, 8802, 9432). Among these six datasets, we find that our HAR-X-SVR-2 model is consistently the best-performing model when using the index dataset (TOPIX) and outperforms the other two models in 12 out of 16 cases. In the individual stock dataset, it outperforms the other models in 66 out of 80 cases and 78 out of a total of 96 cases, which is 81.25% of the total2. Using different window approaches, no significant effect is observed on the ranking of the models, with HAR-X-SVR-2 outperforming the other two models in 37 out of 48 cases for RW and 41 out of 48 cases for IW. Among the three results where the base model is used with more information (HAR-SV, HARQ, and HAR-SJ), the average ranking of the HAR-X-SVR-2 model is higher than the average ranking when simply using the HAR-RV model as the base model, i.e., when the model has more information, the HAR-X-SVR2 model tends to better utilize the information contained in the predictor than the other two models. Although the other hybrid model has been used by Pai and Lin (2005), which had good performance in stock price prediction, it did not outperform the HAR model in RV prediction. Therefore, at least in the Japanese stock market, the second type of hybrid model performs more reliably than the others. Future research can study a greater number of models to expand the predicted values to more combinations of models while considering more automatic machine learning frameworks.
4.4.3. Limitations and Future Research
The limitations of this study are as follows. This study did not empirically analyze the model’s reliability in other countries, such as the UK and US, and other financial markets, such as FX markets. Additionally, the correlation between assets was not considered in this study. Moreover, this study does not explore certain other machine learning or automated machine learning models.
To address the limitations, we make several suggestions for future research. First, more empirical studies should be conducted in different countries and markets for different financial products to confirm whether the hybrid model proposed in this study is generalizable to more markets. Second, multivariate models should be employed to consider correlations across markets for different assets. Finally, more machine learning models and automated machine learning frameworks should be applied. This will enable researchers to provide a more detailed analysis of the effectiveness of hybrid models in the future.
5. Conclusions
This study proposed the use of HAR-X-SVR models, which are used for RV prediction, and tested their out-of-sample forecasting performance under TOPIX and five individual stocks datasets. It constructed two types of hybrid models by combining four basic HAR-X models with SVR using two different combining methods, and these two types of hybrid models were compared with basic HAR-X models. In the Japanese stock market, the empirical results revealed that although the first hybrid model is effective in improving model accuracy in the stock price prediction study by Pai and Lin (2005), the first hybrid model is not significantly effective in improving model accuracy in forecasting RV. However, our second hybrid model performs very well in all six datasets, especially when based on the HAR-SV and HARQ models. Based on the empirical results, we suggest that combining different machine learning models with time series models can be useful for improving prediction accuracy in the Japanese stock market. Nevertheless, confirming the feasibility and viability of such an approach in different markets requires a more comprehensive and meticulous investigation.
We have proposed the following recommendations for future research in order to more comprehensively examine the hybrid model’s credibility. In this study, we only considered hybrid models to enhance the forecasting ability of HAR models. Other volatility models, such as MEM models (Engle and Gallo 2006), can be considered in subsequent work. Furthermore, automatic machine learning methods have developed rapidly in recent years, so the application of machine learning frameworks such as AutoGluon (Erickson et al. 2020) can be considered in subsequent studies. Our approach can be generalized to multivariate analysis using multivariate models such as the multivariate-HARQ (M-HARQ) model (Bollerslev et al. 2018) for multivariate forecasting while considering correlations between different markets.
Author Contributions
Conceptualization, Y.Z. and T.M.; software, Y.Z.; data curation, Y.Z. and T.M.; formal analysis, Y.Z.; writing—original draft preparation, Y.Z.; writing—review and editing, Y.Z. and T.M.; supervision, T.M. All authors have read and agreed to the published version of the manuscript.
Funding
This study is partly supported by the Institute of Statistical Mathematics (ISM) cooperative research program [2023-ISMCRP-2034] and JSPS KAKENHI [Grant Number 21K01433].
Data Availability Statement
Restrictions apply to the availability of these data. Data was obtained from Nikkei Media Marketing, Inc.
Conflicts of Interest
The authors declare no conflicts of interest.
Notes
| 1 | For more introduction to property of RBF, see Micchelli (1986) and Boser et al. (1992) |
| 2 | The results obtained from different datasets with different loss functions, basic model and windowing approach are considered as a case, e.g., in the case of the results with HAR-RV as the basic model, the results of MSE obtained with the TOPIX dataset and under the RW approach are a case. |
References
- Andersen, Torben G., Tim Bollerslev, and Francis X. Diebold. 2007. Roughing it up: Including jump components in the measurement, modeling, and forecasting of return volatility. The Review of Economics and Statistics 89: 701–20. [Google Scholar] [CrossRef]
- Andersen, Torben G., Tim Bollerslev, Francis X. Diebold, and Heiko Ebens. 2001a. The distribution of realized stock return volatility. Journal of Financial Economics 61: 43–76. [Google Scholar] [CrossRef]
- Andersen, Torben G., Tim Bollerslev, Francis X. Diebold, and Paul Labys. 2001b. The distribution of realized exchange rate volatility. Journal of the American Statistical Association 96: 42–55. [Google Scholar] [CrossRef]
- Andersen, Torben G., Tim Bollerslev, Francis X. Diebold, and Paul Labys. 2003. Modeling and forecasting realized volatility. Econometrica 71: 579–625. [Google Scholar] [CrossRef]
- Audrino, Francesco, Chen Huang, and Ostap Okhrin. 2018. Flexible har model for realized volatility. Studies in Nonlinear Dynamics & Econometrics 23: 20170080. [Google Scholar]
- Barndorff-Nielsen, Ole E., and Neil Shephard. 2002. Estimating quadratic variation using realized variance. Journal of Applied Econometrics 17: 457–77. [Google Scholar] [CrossRef]
- Barndorff-Nielsen, Ole E., Silja Kinnebrock, and Neil Shephard. 2008. Measuring Downside Risk-Realised Semivariance. CREATES Research Paper (2008-42). Available online: https://ssrn.com/abstract=1262194 (accessed on 11 January 2024).
- Bennett, Kristin P., and Olvi L. Mangasarian. 1992. Robust linear programming discrimination of two linearly inseparable sets. Optimization Methods and Software 1: 23–34. [Google Scholar] [CrossRef]
- Bollerslev, Tim. 1986. Generalized autoregressive conditional heteroskedasticity. Journal of Econometrics 31: 307–27. [Google Scholar] [CrossRef]
- Bollerslev, Tim, Andrew J. Patton, and Rogier Quaedvlieg. 2016. Exploiting the errors: A simple approach for improved volatility forecasting. Journal of Econometrics 192: 1–18. [Google Scholar] [CrossRef]
- Bollerslev, Tim, Andrew J. Patton, and Rogier Quaedvlieg. 2018. Modeling and forecasting (un) reliable realized covariances for more reliable financial decisions. Journal of Econometrics 207: 71–91. [Google Scholar] [CrossRef]
- Boser, Bernhard E., Isabelle M. Guyon, and Vladimir N. Vapnik. 1992. A training algorithm for optimal margin classifiers. Paper presented at the Fifth Annual Workshop on Computational Learning Theory, Pittsburgh, PA, USA, July 27–29; pp. 144–52. [Google Scholar]
- Carr, Peter, Liuren Wu, and Zhibai Zhang. 2019. Using machine learning to predict realized variance. arXiv arXiv:1909.10035. [Google Scholar]
- Corsi, Fulvio. 2009. A simple approximate long-memory model of realized volatility. Journal of Financial Econometrics 7: 174–96. [Google Scholar] [CrossRef]
- Corsi, Fulvio, and Roberto Renò. 2012. Discrete-Time Volatility Forecasting with Persistent Leverage Effect and the Link With Continuous-Time Volatility Modeling. Journal of Business & Economic Statistics 30: 368–80. [Google Scholar]
- Cortes, Corinna, and Vladimir Vapnik. 1995. Support vector machine. Machine Learning 20: 273–97. [Google Scholar] [CrossRef]
- Demirer, Riza, Rangan Gupta, and Christian Pierdzioch. 2020. Forecasting Realized Stock-Market Volatility: Do Industry Returns Have Predictive Value? Available online: https://ssrn.com/abstract=3744537 (accessed on 8 December 2020).
- Engle, Robert F. 1982. Autoregressive conditional heteroscedasticity with estimates of the variance of united kingdom inflation. Econometrica 50: 987–1007. [Google Scholar] [CrossRef]
- Engle, Robert F., and Giampiero M. Gallo. 2006. A multiple indicators model for volatility using intra-daily data. Journal of Econometrics 131: 3–27. [Google Scholar] [CrossRef]
- Erickson, Nick, Jonas Mueller, Alexander Shirkov, Hang Zhang, Pedro Larroy, Mu Li, and Alexander Smola. 2020. Autogluon-tabular: Robust and accurate automl for structured data. arXiv arXiv:2003.06505. [Google Scholar]
- Guidolin, Massimo, and Manuela Pedio. 2018. Essentials of Time Series for Financial Applications. Cambridge: Academic Press. [Google Scholar]
- Gupta, Rangan, Jacobus Nel, and Christian Pierdzioch. 2023. Investor confidence and forecastability of us stock market realized volatility: Evidence from machine learning. Journal of Behavioral Finance 24: 111–22. [Google Scholar] [CrossRef]
- Hansen, Peter R., Asger Lunde, and James M. Nason. 2011. The model confidence set. Econometrica 79: 453–97. [Google Scholar] [CrossRef]
- Huang, Chien-Feng. 2012. A hybrid stock selection model using genetic algorithms and support vector regression. Applied Soft Computing 12: 807–18. [Google Scholar] [CrossRef]
- Kim, Ha Young, and Chang Hyun Won. 2018. Forecasting the volatility of stock price index: A hybrid model integrating lstm with multiple garch-type models. Expert Systems with Applications 103: 25–37. [Google Scholar] [CrossRef]
- Li, Xuemei, Lixing Ding, Yuyuan Deng, and Lanlan Li. 2010. Hybrid support vector machine and arima model in building cooling prediction. Paper presented at 2010 International Symposium on Computer, Communication, Control and Automation (3CA), Tainan, Taiwan, May 5–7, vol. 1, pp. 533–36. [Google Scholar]
- Lyócsa, Štefan, and Daniel Stašek. 2021. Improving stock market volatility forecasts with complete subset linear and quantile har models. Expert Systems with Applications 183: 115416. [Google Scholar] [CrossRef]
- McAleer, Michael, and Marcelo C. Medeiros. 2008. Realized volatility: A review. Econometric Reviews 27: 10–45. [Google Scholar] [CrossRef]
- Micchelli, Charles A. 1986. Algebraic aspects of interpolation. Paper presented at Symposia in Applied Mathematics, New York, NY, USA, March 29–30, vol. 36, pp. 81–102. [Google Scholar]
- Pai, Ping-Feng, and Chih-Sheng Lin. 2005. A hybrid arima and support vector machines model in stock price forecasting. Omega 33: 497–505. [Google Scholar] [CrossRef]
- Patton, Andrew J. 2011. Volatility forecast comparison using imperfect volatility proxies. Journal of Econometrics 160: 246–56. [Google Scholar] [CrossRef]
- Patton, Andrew J., and Kevin Sheppard. 2015. Good volatility, bad volatility: Signed jumps and the persistence of volatility. Review of Economics and Statistics 97: 683–97. [Google Scholar] [CrossRef]
- Ramos-Pérez, Eduardo, Pablo J. Alonso-González, and José Javier Núñez-Velázquez. 2019. Forecasting volatility with a stacked model based on a hybridized artificial neural network. Expert Systems with Applications 129: 1–9. [Google Scholar] [CrossRef]
- Sezer, Omer Berat, Mehmet Ugur Gudelek, and Ahmet Murat Ozbayoglu. 2020. Financial time series forecasting with deep learning: A systematic literature review: 2005–2019. Applied Soft Computing 90: 106181. [Google Scholar] [CrossRef]
- Smola, Alex J., and Bernhard Schölkopf. 2004. A tutorial on support vector regression. Statistics and Computing 14: 199–222. [Google Scholar] [CrossRef]
- Sun, Hao, and Bo Yu. 2020. Forecasting financial returns volatility: A garch-svr model. Computational Economics 55: 451–71. [Google Scholar] [CrossRef]
- Waring, Jonathan, Charlotta Lindvall, and Renato Umeton. 2020. Automated machine learning: Review of the state-of-the-art and opportunities for healthcare. Artificial Intelligence in Medicine 104: 101822. [Google Scholar] [CrossRef] [PubMed]
- Wen, Fenghua, Xu Gong, and Shenghua Cai. 2016. Forecasting the volatility of crude oil futures using har-type models with structural breaks. Energy Economics 59: 400–13. [Google Scholar] [CrossRef]
- Whitley, Darrell. 1994. A genetic algorithm tutorial. Statistics and Computing 4: 65–85. [Google Scholar] [CrossRef]
- Zhang, Gaoxun, and Gaoxiu Qiao. 2021. Out-of-sample realized volatility forecasting: Does the support vector regression compete combination methods. Applied Economics 53: 2192–205. [Google Scholar] [CrossRef]
- Zhu, Bangzhu, Julien Chevallier, Bangzhu Zhu, and Julien Chevallier. 2017. Carbon price forecasting with a hybrid arima and least squares support vector machines methodology. In Pricing and Forecasting Carbon Markets: Models and Empirical Analyses. Berlin and Heidelberg: Springer, pp. 87–107. [Google Scholar]
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2024 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).