1. Introduction
When measuring the insurer’s exposure to numerous risks, and especially to assess their own funds requirement (or Solvency Capital Requirement in insurance, denoted further by SCR, and representing the 99.5th percentile of the aggregated loss distribution), one of the most sensitive steps is the modelling of the dependence between those risks.
This is of course a major question, which, as such, has recently attracted attention from the scientific community. See, for instance, the works by
Georgescu et al. (
2017),
Cifuentes and Charlin (
2016),
Bernard et al. (
2014),
Clemente and Savelli (
2013),
Cheung and Vanduffel (
2013),
Clemente and Savelli (
2011),
Devineau and Loisel (
2009),
Filipovic (
2009),
Sandström (
2007),
Denuit et al. (
1999), and references therein. This aggregation step allows for taking into account mitigation, or the potentiality of those individual risks occurring simultaneously. According to the European Directive Solvency II (
EIOPA (
2009)), there are two main approaches to compute aggregated risk measures considering the dependence structure between risks. In the first case, this aggregation is performed through a
variance–covariance approach via the Standard Formula, below
where
is the 99.5th percentile of the random loss
associated to risk
i, and
is the linear correlation such that
. This technique was shown to be valid for elliptical loss distributions, which is not the case in general
1.
Another possibility for insurers is to calculate the SCR thanks to their internal model, once the latter has been approved by supervisors. In this case, insurers usually work with copulas for the aggregation of risk factors in order to obtain the full distribution of losses. Copulas can indeed model most general situations of dependence, as shown by the well known Sklar’s theorem. In practice, internal models require the implementation of these successive steps:
calibration of marginal distributions for each risk factor (e.g., equity, interest rates);
modelling the dependence between risk factors through a copula;
aggregation of risks, leading to the entire distribution of the aggregate loss (sometimes an intermediate step links the risk factors to their associated loss thanks to proxy functions, see
Section 5.1). Taking the 99.5th percentile of this distribution allows the evaluation of the SCR.
The aggregation thus requires a correlation matrix as an input, whatever the technique (at least when copulas are Gaussian or Student, which is the case for several insurance companies using an internal model). The dimensions of this matrix can be huge in practice (e.g., 1000 × 1000, i.e., with around 500,000 different values), depending on the modular structure chosen (for instance, the dimensions of correlation matrices remain low in the Standard Formula, see
Section 2.1). The matrix includes numerous correlation coefficients that can result from empirical statistical measures, expert judgments or automatic formulas. As a matter of fact, it is thus rarely
2 positive semidefinite (PSD): this is what is commonly called a pseudo-correlation matrix. Unfortunately, this matrix cannot be used directly to aggregate risks. Indeed, both
variance–covariance and
copula aggregation techniques require the correlation matrix to be PSD (that is with all eigenvalues
) for the following main reasons:
Coherence: it is a well-known property that correlation matrices are PSD. Negative eigenvalues indicate that a logical error was made while establishing the coefficients of the matrix. For instance, consider the case of a 3 × 3 matrix: if the coefficients indicate a strong positive correlation between the first and second risk factors, a strong positive correlation between the second and third risk factors, but a strong negative correlation between the first and third risk factors, this will generate a negative eigenvalue corresponding to the coherence mistake made.
Prudence: taking more risk could decrease the insurer’s SCR if there exists one negative eigenvalue associated to an eigenvector with positive coefficients. For instance, consider the loss vector (100 M€, 10 M€, 40 M€) and the correlation matrix
Using the variance–covariance approach, the riskiest situation in terms of losses (106.20 M€; 16.20 M€; 44.81 M€) leads to a lower SCR (70.48 M€ against 74.16 M€).
Ability to perform simulations: in the copula approach, the input correlation matrix has to be PSD to apply Choleski decomposition. This is necessary for Gaussian or Student vectors, which are the most common cases for such tasks in practice.
Using PSD correlation matrices is therefore crucial, which explains why it is explicitly required by the Delegated Rules of the Solvency II regulation (
EIOPA (
2015), see Appendix XVIII). Accordingly, insurers apply algorithms on their pseudo-correlation matrix in order to make it become PSD: this is the so-called
PSDization process. Most common algorithms can be separated into three categories: Alternating Projections, Newton and Hypersphere algorithms. One focuses in this paper on the Rebonato–Jäckel algorithm, which belongs to the latter family (see
Section 3 for further details about the motivation of this choice).
Considering this framework, the impact on the SCR of standard operations on the correlation matrix should be verified. Our interest lies in studying operational choices such as weighting the correlation coefficients during PSDization (to reflect the confidence experts may have on these coefficients), switching some columns of the matrix (i.e., reordering the risks before aggregation), or adding one dimension (which can correspond to an additional business line with low materiality on the overall SCR). To the authors’ knowledge, the impact of such operations on the PSDization step has not been studied formally in the literature before. Numerical examples support the main idea of this work: transformations of the matrix, with low or null theoretical impact on the SCR, sometimes lead to unexpected changes of this global SCR. For large insurance companies, this is all the more important since a 1% change of SCR can cost millions of euros in terms of capital. This would strongly affect the Return On Equity index, an essential profitability indicator for investors.
The publication is organized as follows:
Section 2 introduces the pseudo-correlation matrices to be considered hereafter.
Section 3 describes most common PSD algorithms, and motivates our choice. With the help of some significant examples,
Section 4 illustrates to which extent
PSDization leads to modifying the initial pseudo-correlation coefficients. The cases of higher risk matrix dimensions, weighted correlation coefficients and risk permutations are studied. Finally, real-life sensitivities are assessed in
Section 5 thanks to the use of genetic algorithms and simulations, and provide some interesting results concerning the aforementioned operations and their impact on the global SCR of the company.
4. Sensitivity of the Matrices to PSDization
In this section, we would like to illustrate how the correlation matrix can be modified when performing
PSDization by the Rebonato-Jackël algorithm, with toy examples. We specifically investigate how the coefficients of
(
Appendix A) change during the sole
PSDization, and also look at the evolution of individual correlation coefficients when considering other classical operations for practitioners: permutations of some coefficients before
PSDization, change of matrix dimension (before
PSDization), or weights given to the correlation coefficients during
PSDization. For this purpose, we consider the following initial weighting matrix
These operations mainly correspond to the decisions that actuaries have to make when developing internal models for risk aggregation. Note that the impact on the capital requirement can be substantially different from the impact in terms of matrix norm, according to the respective importance of the loss marginals. This impact will be studied in
Section 5.
4.1. Impact of Permutations
To study how permutations of risks defining the correlation matrix impact the standard
PSDization process, we first consider the permutation
such as
As a result,
Table 3 shows the obtained modifications of the correlation coefficients:
Examining the coefficients, we notice that they are significantly modified: first by the PSDization process itself, but also by the permutation of risks. This last result is surprising, since there should be no theoretical impact with this operation. However, because our algorithm presents local minima issues, the choice of the order of risk factors (arbitrarily made by the insurer) matters when performing PSDization.
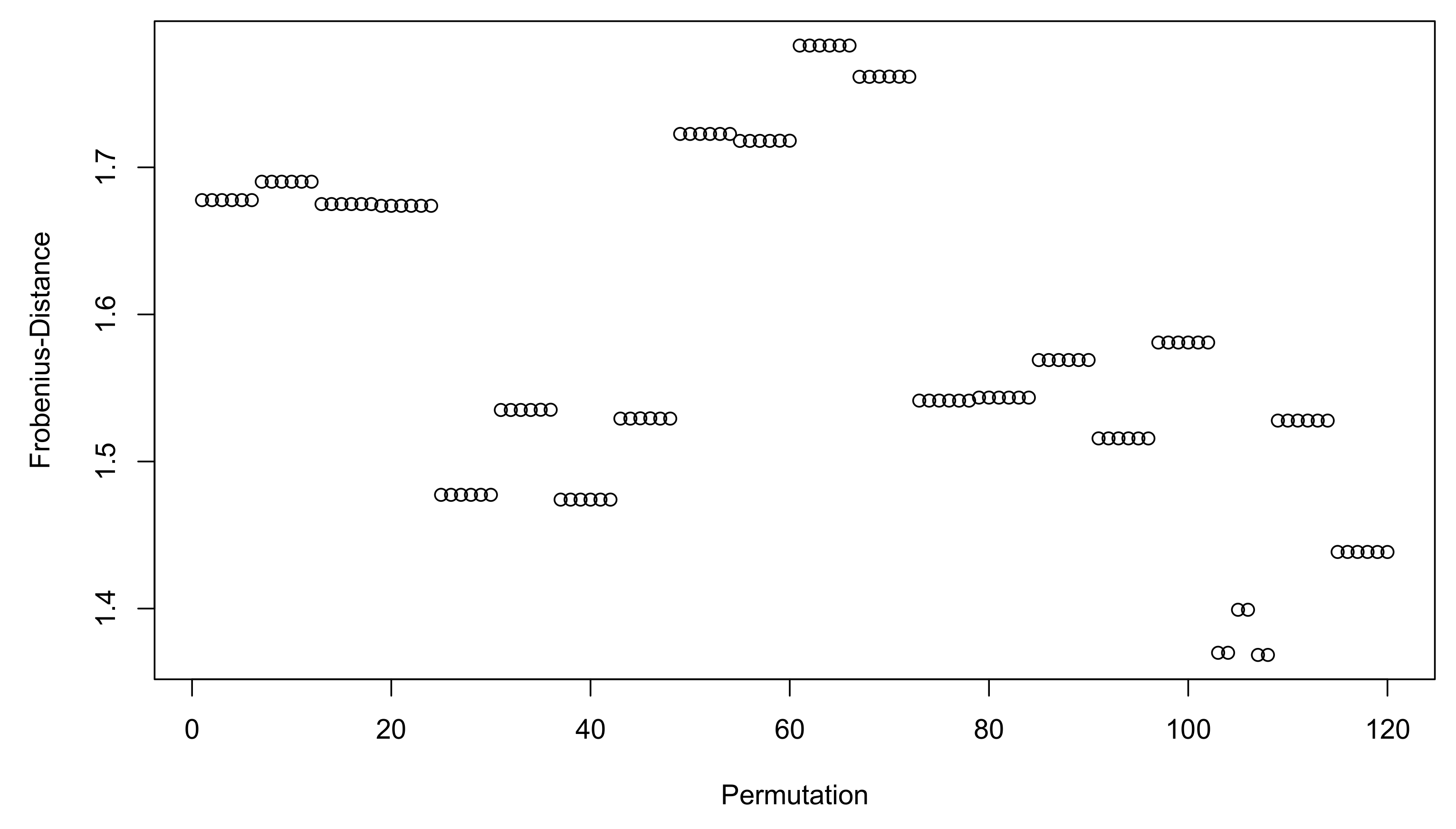
To figure out more comprehensively the impact of permutations, it would be best to look at the exhaustive list of permutations for a given pseudo-correlation matrix. Remember that a D-dimensional matrix admits D! permutations, and let us consider the example
.
Figure 1 shows the Frobenius distance to the initial matrix for the 5! permutations of
, knowing that this distance between
and
initially equals 1.68 without any permutation. The Frobenius norm is clearly not the norm that the algorithm optimizes, but it simply illustrates to which extent the solution matrix
is modified. Two remarks can be made here. First, the distances follow a block pattern caused by the order of the permutations. Second, the permutations do not always lead to an increase in the distance to the initial pseudo-correlation matrix.
4.2. Adding a Risk: Increase the Matrix Dimension
Another arbitrary element chosen by the actuaries of the company is the number of risk factors to be aggregated. In some cases, it may be necessary to model many risk factors, according to the use of the internal model that is made by the business units (need to model many lines of business when modelling the reserving loss factor for instance). These choices have to be made for risk factors that are not material at Group level, even if they can be important for the concerned subsidiaries. Nevertheless, these choices will impact the final SCR through the modification brought to the overall correlation matrix during
PSDization. Still based on the same example, let us consider the following case:
As can be noticed, the correlation is low between the added and the other risks.
Direct
PSDization obviously gives the same results, whereas correlation coefficients are slightly modified after
PSDization when introducing the new risk (see
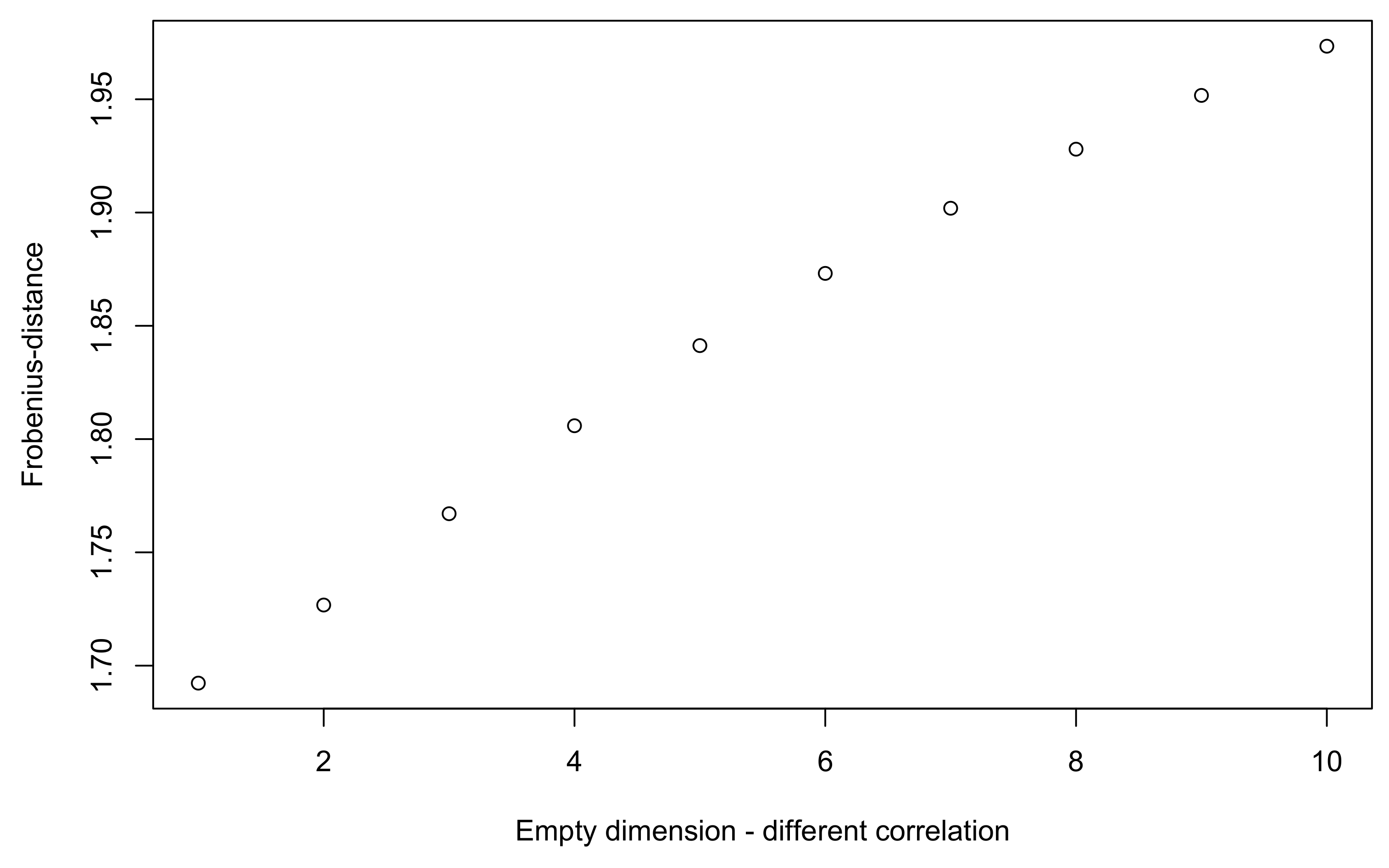
Table 4). Changes to these coefficients are difficult to anticipate, but it seems that the impact is lower in this case than with permutations. A natural question would be to understand whether the value of the correlation coefficient that was added is key to explaining the modifications obtained in the PSDized correlation matrix.
Figure 2 shows this impact on the Frobenius norm, with a new risk with correlation coefficients that vary from 0.1 to 1. Results are intuitive: the higher the coefficients added, the wider the Frobenius norm.
PSDization is indeed a whole process that takes into account every coefficient, including the one that was added.
4.3. Impact of Confidence Weights
Finally, the choice of the weights associated to the terms of the correlation matrix, which somewhat represents the confidence level given by experts to the individual correlation coefficients, can also have a significant impact on the
PSDized matrix. To illustrate this, still keeping in mind the example
with the initial weights listed in
, we consider the new following weights:
The
PSDized matrix is now given in
Table 5:
Clearly, correlation coefficients significantly vary. It illustrates that, as expected, the lower the weight, the further the modifications are from the initial coefficient. An increased weight on some correlation coefficients clearly leads to an increased importance in the
PSDization process, and thus less modification for them (so as to minimize the Frobenius norm). To generalize and better understand to which extent the weights could impact the correlation coefficients after
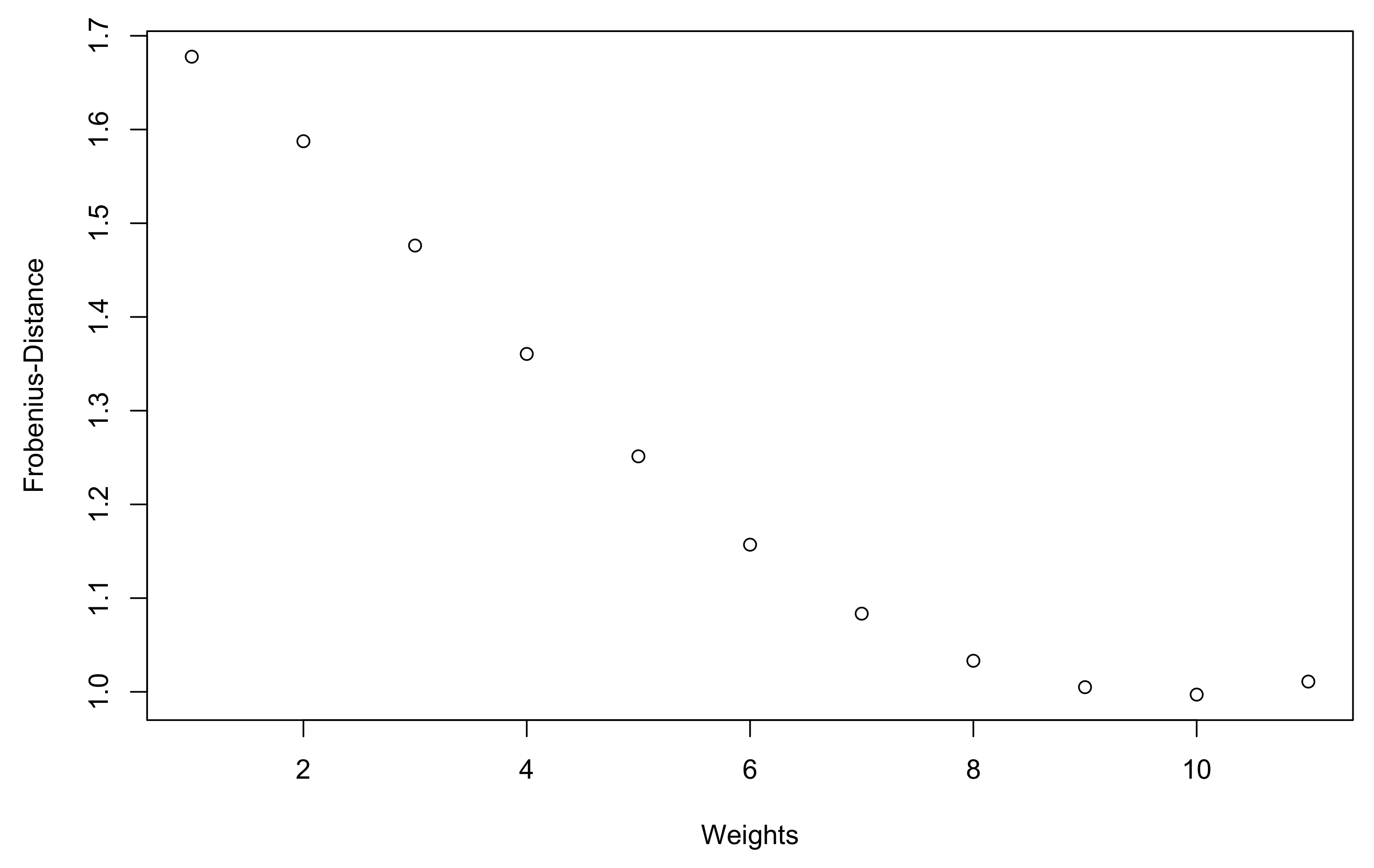
PSDization,
Figure 3 shows the Frobenius norm between the solution
and the initial matrix
, with weights varying from
to a limit weighting matrix given by
This limit weighting matrix is used for illustration purposes only. It corresponds to increasing linearly by
the lowest weights of the matrix
, while decreasing the highest weights by the same factor.
Figure 3 shows that the Frobenius norm decreases as the weighting matrix is distorted towards the limit
, and a closer analysis reveals that this phenomenon is mainly due to the correlation coefficients
,
,
and
of
(and their transposed coefficients), which exhibit lesser modifications than with the initial weighting matrix since their weights are significantly increased: from 0.1 to 0.5 and respectively from 0.2 to 0.6.
4.4. Summary and Comments on the Other Two Algorithms
To put it in a nutshell,
Figure 4 shows the impact of permutations and weights (the two most prominent operations) on the Frobenius norm, in the conditions stated above. It shows that the impact on the norm is more important when weights vary than when the order of risk factors is changed.
In addition, it must be noted that low dimensions are used in this publication so as to keep computation time at an acceptable level, but when dimensions increase, the initial matrix can be farther from the PSD target. Indeed, Gerschgorin’s circle theorem states that
,
Spec(G),
such as
In particular, if G is a pseudo-correlation matrix of dimension
, its eigenvalues
belong to the interval
. To illustrate this practically, a matrix
of size
was randomly generated (defined as the symmetric part of an initial matrix with 10,000 valuesbetween −1 and 1, and diagonal coefficients forced to 1). The matrix thus obtained has 43 negative eigenvalues, where the lowest one equals −6.74. In this case,
must be significantly transformed to become PSD: for all three algorithms, the most modified coefficient changes from 0.96 to 0.10. Nevertheless, the AP and the Newton algorithms still give overall better results than the Rebonato–Jäckel algorithm:
Furthermore, according to the authors’ observations, permutations do not affect the PSD solution when using the AP or the Newton algorithms, whatever the dimension of the correlation matrix. The previously observed sensitivity to permutations is due to the convergence of the Rebonato–Jäckel algorithm to a local minimum. Since a PSD matrix remains PSD after permutations, and since the norms studied do not change under permutation, the PSD solution should remain the same before and after permutation (provided that the algorithm used reaches the absolute minimum). It is therefore expected that the known extensions of the Newton algorithm to integrate weights would not generate a significant sensitivity to permutations.
Finally, let us mention that our conclusions about the addition of a new risk dimension apply to all algorithms. Adding a new dimension modifies the eigenvalues, and can thus require further transformations to become PSD. However, the ability to use weights can help reduce this impact. For example, when adding an empty dimension to
with a 10% correlation between the initial and the added risk factors, the ability to set weights associated to this new dimension to 0 (instead of 1 for all other correlation coefficients) enables the Rebonato–Jäckel algorithm to reach the nearest solution:
After these illustrations, we can now move on to the analysis of such transformations on the capital requirement.
5. Analysis of Solvency Capital Requirement Sensitivity
The importance of PSDization on the final correlation matrix (to be used to assess the insurer’s own funds requirement) has now been highlighted. The correlation coefficients chosen by the experts, or even those defined by statistical means can be significantly modified. The aim of this section is to provide some real-life sensitivities concerning the computation of the global SCR thanks to internal models. We would like to see SCR as a function of the main parameters in the actuary’s hand.
To carry this out, genetic algorithms are used to find a range
3 of values to which the SCR belongs; given a copula, realizations of risk factors, and proxy functions (more details later). The implemented algorithms are detailed in
Appendix D.1 and
Appendix D.2, respectively, for the case of permutations and weights. They correspond to an adaptation of the Rebonato-Jackël algorithm that incorporates these operations. At the end, the range is obtained for a given pseudo-correlation matrix G, a given weighting matrix H, and possibly a given permutation
. Hence, we want to evaluate the function
g such that
, where
stands for the effect of
on the risk factors represented in G, and
represents the nearest (from G) PSD matrix obtained using the Rebonato-Jackël algorithm with weights
H. The considered permutation
was presented at the beginning of
Section 4.1.
5.1. Loss Factors or Risk Factors?
It must first be stated that estimating the loss generated by the occurrence of some given risk is a difficult task. It is easier to describe the behavior of risk factors through marginal distributions. For instance, if the interest rates rise, the potential loss for the insurer depends on impacts on both assets (e.g., value of obligations drops) and liabilities (contract credited rates may vary, which should modify expected lapse rates). To compute the loss associated to the variation of some risk factors, one thus needs a (very) complex transformation. In practice, to save computation time, simple functions (polynomial form) approximate these losses. However, the insurer can sometimes directly evaluate the loss related to one given loss factor: this is the case for example when considering the reserve risk, which can be modeled by classical statistical methods (bootstrap). The insurer’s total loss,
P, thus reads
where
f is a given (proxy) function,
and
are random variables,
is the set of loss factors and
is the set of risk factors.
For our next analysis,
Table 6 gives the different functional forms depending on the risk dimension and the risk factors
. For the sake of simplicity, one considers that all our marginals (
and
) follow the same distribution but with different parameters. This common distribution is lognormal
, since it is widely used in insurance for prudential reasons.
Table 7 sums up the parameters involved in the eight different cases under study: vectors
(where
k refers to the dimension of the vector) will be used to compute the global loss in the case of loss factors aggregation (meaning that
), whereas vectors
will be the input of proxy functions defined in
Table 6 for risk factors aggregation (
). We distinguish these two configurations to see whether taking into account proxy functions gives very different SCR sensibilities as compared to only aggregate risk factors.
5.2. Variance–Covariance or Copula Approach, Pros and Cons
Except for the PSDization step itself; which generates different results, another important choice lies in the aggregation approach. Here, one would like to detail the reasons for choosing one of them (i.e., copula or variance–covariance). Let us consider the simplest framework: the loss P only depends on loss factors (no need to apply proxy functions that link risk factors to loss factors). It is then possible to model this loss as follows: .
Individual loss factors have to be modeled and estimated by the actuaries for internal models, or come from standardized shocks if using the Standard Formula. Fortunately, it is likely that extreme events corresponding to the 99.5th percentile of every loss factors do not occur at the same time: there is thus a mitigation effect, which generally implies
As already mentioned in
Section 1, the regulation states that the variance–covariance approach can be used to aggregate risks, with the given correlation matrices. This method has some advantages, but also some drawbacks (
Embrechts et al. 2013). Of course, it is the easiest way to aggregate risks: the formula is quickly implemented (which allows for computing sensitivities without too much effort), and easy to understand. However, it does not provide the entire distribution of the aggregated loss, knowing that the insurer is sometimes interested in other risk measures than the unique 99.5th percentile. Moreover, this approach is not adequate for modelling nonlinear correlations, which are common when considering the tails of loss distributions. It means that it is very tricky to calibrate the correlation matrix so as to ensure that we can effectively estimate the 99.5th percentile of the aggregated loss. In their paper,
Clemente and Savelli (
2011) and
Sandström (
2007) discussed this and proposed a way to modify the Solvency II aggregation formula in order to consider skewed marginal distribution. Finally, the variance–covariance approach is too restrictive since it does not allow the correlation of risk factors, but only the correlation of losses. This makes the interpretation of scenarios generating a huge aggregated loss very difficult.
For all these reasons, internal models are generally developed using copulas: they enable the simulation of a large number of joint replications of risk factors, before applying proxy functions (most of the time). With this technique, insurers obtain the full distribution of
P, and thus richer information among which is the quantile of interest (
Embrechts and Puccetti (
2010),
Lescourret and Robert (
2006)). Common copulas in the insurance industry (Gaussian and Student copulas) are based on the linear correlation matrix, the marginals being the risk and loss factors. This is linked to the main property of copulas: they allow the definition of the correlation structure and the marginals separately. For example, aggregation with the Gaussian copula can be simulated with the following steps:
simulation of the marginals stand-alone (stored in the vector , where n stands for the number of risk factors and B the number of random samples);
simulation of a Gaussian vector Y through the expression , where T represents the Choleski decomposition of the correlation matrix and Z is an independent Gaussian vector of size n;
ordering X in the same order as Y to ensure that ( stands for the quantile corresponding to x).
5.3. Results Using a Simplified Internal Model
Applications presented hereafter were designed to consider a wide range of operational situations in which the insurer aims to estimate its global SCR.
For a given PSD correlation matrix
, and given values for the vector of risk factors (simulated with lognormal distributions), one performs
Q = 131,072 =
simulations for the aggregation of risk factors (dependence structure). As a matter of fact, there are two sources of uncertainty explaining the variation of SCR values (
). First, the genetic algorithm itself is likely to have reached different local solutions depending on the simulation. Second, the simulation of the Gaussian or Student vectors to model the correlation through copulas may change. In order to focus the study on correlation, it must be noted that marginals were simulated initially and then kept fixed. Roughly, it can be assumed that the confidence interval of the global SCR is similar to that of a Gaussian distribution (
) because of the Central Limit Theorem and of the independence of the simulations of each SCR, i.e.,
where
stands for the standard deviation of SCR, and
m its mean. Of course, the estimation of these parameters is made simple using their empirical counterparts, denoted by
and
.
Table 8 summarizes the estimated quantities for each case in our framework.
Then, we study the impact of our transformations (permutation, weights varying, and higher dimension) as compared to this standard deviation
. More precisely, we consider one operation, perform the same number of simulations, and store the minimum and maximum values of the vector
. This way, it is possible to define a normalized range (NR) for these values, as expressed below:
If NR is lower than (
), the transformation is said to have a limited impact on the SCR. Otherwise, it is considered as a significant impact. The worst cases correspond to situations where NR is greater than (
). The multiplier 2 enables us to take into account the fact that there are two sources of uncertainty (genetic algorithm and simulated dependence structure). All the results are stored in
Table 9.
5.3.1. Impact of Permutations on the Global Solvency Capital Requirement
Of the 14 examples under study (seven pseudo-correlation matrices
times Gaussian or Student copula, see
Table 9), the permutation systematically has a very strong impact on the global SCR. This change can represent up to 6.7% in practice, although it should have no theoretical impact. This is mainly due to the
PSDization process, which leads to the selection of different local minima after a permutation is made. This highlights two phenomenona: the need to control the bias induced by the initial choice of the insurer concerning the order of risk factors, and the need to initially define PSD correlation matrices (revisiting experts’ opinions, and identifying incoherent correlation submatrices).
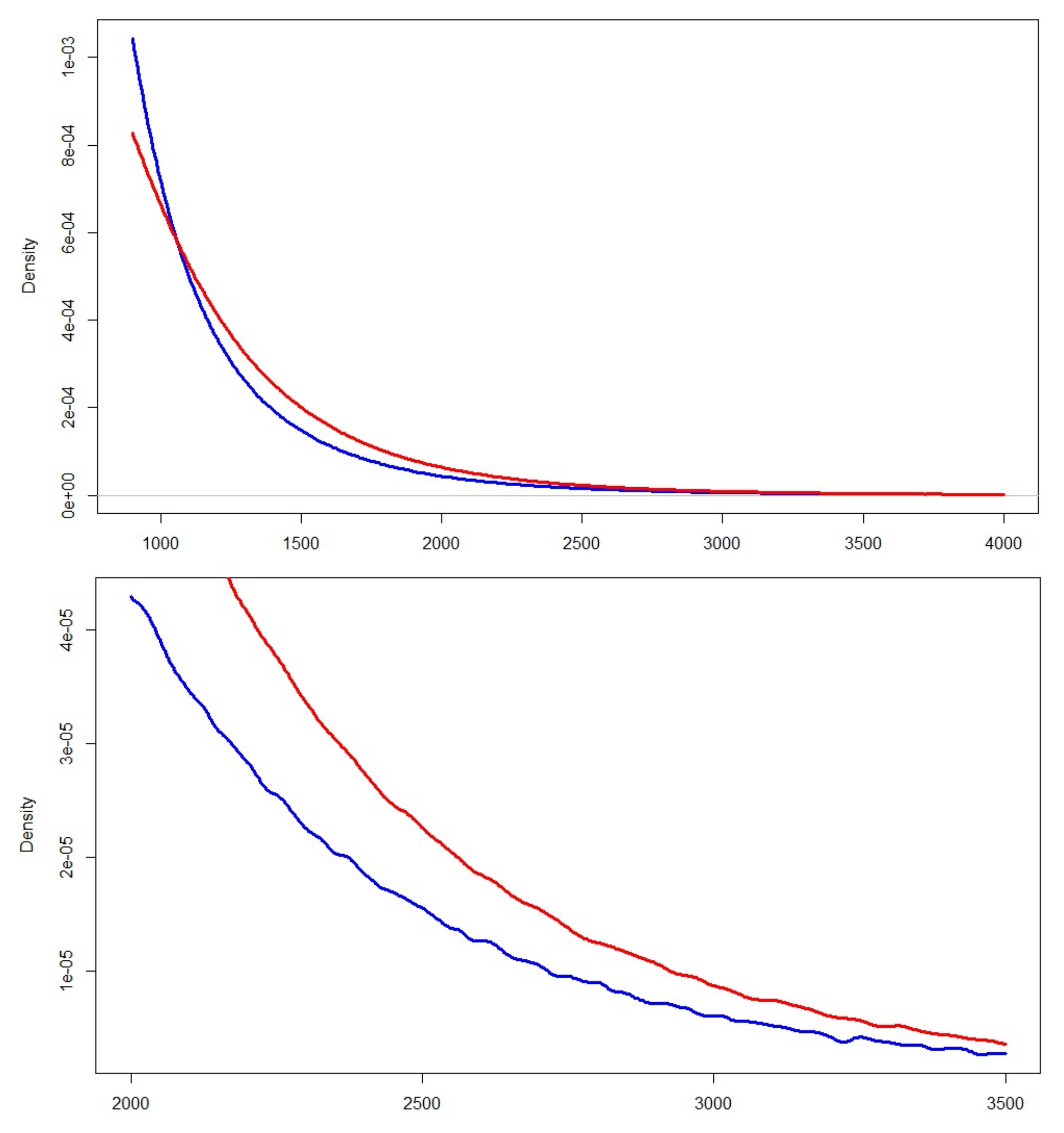
To have a more comprehensive view of this impact,
Figure 5 illustrates it on the total loss distribution (rather than the sole 99.5th percentile), with
,
and considering the aggregation of loss factors. The red curve corresponds to the loss distribution after applying the permutation
to
in the case of a Gaussian copula, whereas the blue one corresponds to the permutation
.
5.3.2. Impact of the Modification of Weights on Solvency Capital Requirement
Our sensitivities relate to weighting coefficients varying in a given range. This range is defined by weights between
and
. This sensitivity is denoted by ‘W Sensi1’ in
Table 9. Of the 28 examples analyzed here, (seven pseudo-correlation matrices
, times (Gaussian or Student copula), times (risk or loss factors)), 17 cases have a very strong impact on the SCR. The range
can represent more than 5.4% of the SCR, which is really huge in practice.
The same analysis with stronger constraints (weights belonging to an interval of width 0.2 around the initial weights, i.e.,
and
, see ‘W Sensi2’ in
Table 9) shows that of 28 examples, seven cases have a very significant impact on the final SCR, with a range likely to represent more than 4.7% of the SCR. Furthermore, this shows the necessity to properly define correlation coefficients at the very beginning.
5.3.3. Impact of Adding a Dimension to the Correlation Matrix
In practice, the insurer’s global loss often incorporates some negligible loss factor. In the simple case where there are only loss factors affecting the global loss, it means that
where
thus tends to 0. The limit case would be
, which means that the (n+1)th risk factor would have no impact on the insurer’s loss, but still plays a role through its presence in the correlation matrix and its impact in the
PSDization process. The correlation between this risk factor and others is set to 0.1 (as in
Section 4.2). We measure the SCR value before and after adding this dimension.
Of the 28 examples analyzed (see ‘dim+1’ in
Table 9), almost one third (nine cases exactly) lead to a statistically significant impact on the final SCR (strong or very strong impact on SCR). However, except in one specific case involving an impact value around 6%, most of the impacts seem to be lower than with other operations. Once again, it is important to realize that this transformation should have no theoretical impact. Of course, it suggests that it would be worth conducting deeper analysis on this aspect, especially on the addition of more than one dimension and on the modification of the correlation coefficients of the added risk factor.
6. Conclusions
Insurers using internal models, as well as supervisors, wonder quite rightly about the robustness of their
PSDization algorithm. Our study shows and highlights the importance of
PSDization through quantified answers to very practical questions on a series of real-life examples. Of the 98 (3 × 28 + 14) examples based on various configurations (different copulas and ways to consider risks, see
Table 9), approximately one half (exactly 47) have significant impacts on the global SCR (up to 6%) when studying sensitivities to our three tuning parameters (weights given to individual correlation coefficients, permutations, and addition of a fictive business line). It can be noted that permutations always lead to a significant variation of the overall SCR, with a normalized range (see Equation (
2)) often greater than in other cases. Adequate sensitivities should therefore be performed when using the Rebonato–Jäckel algorithm since there is to the authors’ knowledge no way to know a priori which would be the most adapted choice of risk order for a given company. Knowing that these transformations are either theoretically neutral, or should have a limited impact on the global capital requirement, this underlines that practitioners’ choices are fundamental when performing risk aggregation in internal models. Moreover, the use of proxy functions do not seem to change conclusions: SCR sensitivity is similar when considering only loss factors. A strong control of
PSDization by supervisors thus makes sense, and a good understanding of the behaviour of the
PSDization algorithm is required.
The following best practices were identified: (i) develop a sound internal control framework on both the triggers generating negative eigenvalues (e.g., expert judgments) and the PSDization step itself, and (ii) assess the need for adding a new risk (e.g., new business line) in terms of its impact on the correlation matrix and thus on the global SCR. Regarding the former point, independent validations and systematic reviews of the modifications brought to the correlation matrix by the algorithm should be analyzed, and a wide number of sensitivities has to be implemented to challenge the results. Concerning the dimension of the risk matrix, there seems to be a compromise to find: adding business lines allows for increasing granularity when describing the correlation between risks, but tends to cause more disturbance on the individual correlation coefficients during PSDization. As usual, the best choice lies in an intermediate dimension.
Finally, this work could be extended in several ways, among which the definition of algebraic tests to anticipate inconsistencies in the experts’ choices; and a deeper understanding of the permutations leading to the minimum or maximum values of the SCR. In particular, if these permutations show some similar features, it would be possible to define best practices when ordering risk factors.








{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}