1. Introduction
A random variable (r.v.)
is phase-type (PH) with representation
if it is distributed as the lifetime
of a killed (terminating) time-homogenous Markov process
with
states, initial distribution
(a row vector), and generator
, where † is an additional absorbing state. PH distributions originate from queueing theory and the work of A.K. Erlang, A. Jensen and M.F. Neuts. However, in recent decades, they have found numerous applications to different areas. The main reason for this is that many calculations that are explicit for exponential distributions are often computationally tractable with PH assumptions and that, in addition, PH distributions are dense so that a given distribution
F on
can be approximated arbitrarily well by a PH distribution provided one takes
p large enough. For surveys of the theory and applications, see (
Asmussen 2003;
Asmussen and Albrecher 2010;
Bladt and Nielsen 2017). The present paper is concerned with some applications to life insurance, an area where PH distributions have been far less employed than in the related areas of non-life insurance. There are many papers in ruin theory that assume that claim sizes are PH distributed; see (
Cai and Li 2005b) and the review paper (
Bladt 2005). Some papers assume that the claim time is PH distributed; see (
Stanford et al. 2000). (
Zadeh et al. 2014) considered disability insurance using a PH model. (
Zadeh and Stanford 2016) studied credibility theory using PH distributions. In finance, PH distributions have also been used extensively. For example, (
Asmussen et al. 2004) considered option pricing under an exponential phase-type Lévy model; (
Cai and Li 2005a) dealt with applications of PH distributions to risk measures; and (
Egami and Yamazaki 2014) considered PH approximations of Lévy models. On the contrary, the only references of applications of PH distributions to life insurance we know of are (
Lin and Liu 2007) and (
Zadeh et al. 2014).
The motivation for the present study is some valuation problems of equity-linked products in life insurance considered in
Gerber et al. (
2012,
2013,
2015) (GSY). Let
be the remaining lifetime of an insured of age
x when signing the contract, then the payment of this class of benefits has the form
where
is the price at time
t of some stock or stock index and
the running maximum. An example of such a benefit is the guaranteed minimum death benefit (GMDB)
, but there are many others; see the list in
Section 4. Defining
as
,
as the running maximum of
X, and
as the displacement from the maximum, we then have:
(note that
), and the fair value of the benefit is the expected discounted payment.
A widely-used model (
Cont and Tankov 2004) assumes that
is a Lévy process, and the key vehicle in GSY for the computations for such expectations is the classical Wiener-Hopf factorization:
Lemma 1. For a Lévy process and an independent exponential time τ, the r.v.’s and are independent. Further, For the geometric Brownian motion model where
X is a Brownian motion (BM) with drift,
and
both have an exponential distribution, and for more general jump diffusions, a number of computational procedures have been developed (see
Section 5 for references). In GSY, they approximate the density/tail of
by a linear combination of exponential terms, which allows them to reduce the computations to simple integrations using Lemma 1.
The approximation of the distribution of
by a linear combination of exponential terms in GSY uses an ad hoc optimization procedure. The main problem there is that it is very difficult to make the linear combination of exponential densities to be a density function; in particular, very often, in the tail part, the linear combination of exponential densities can be negative. Since, in the application to valuing equity-linked insurance products, the distribution at the tail part plays an important role, this motivated us to consider using the PH distribution to approximate the future lifetime distribution. For PH distributions, more classical statistical methods using maximum likelihood have, however, been developed (
Asmussen et al. 1996), and in view of the denseness of PH distributions and the fact that they have proven a computationally-tractable generalization of the exponential distribution in other settings, a natural idea is therefore to use a PH approximation
to
. The first step in implementing this for pricing equity-linked benefits is to develop a version of the Wiener-Hopf factorization for the case where
is PH and independent of
X. This has been done in a companion paper (
Asmussen and Ivanovs 2019), and the contribution of the present paper is to provide the further steps such as PH fitting of human mortality and computations of prices of equity-linked benefits for BM and jump diffusions.
2. Preliminaries
The vector of killing rates of a PH
r.v.
is given by
, where
is a column vector with all entries equal to one. The density is
, and the tail
is
. Here, the exponential
of a matrix is defined as
. We shall often use formulas like:
that are immediate analogues of standard formulas for univariate exponentials. For example, taking
gives the Laplace transform
as
. Of course, the existence of
has to be verified, which for a PH generator
is a standard fact.
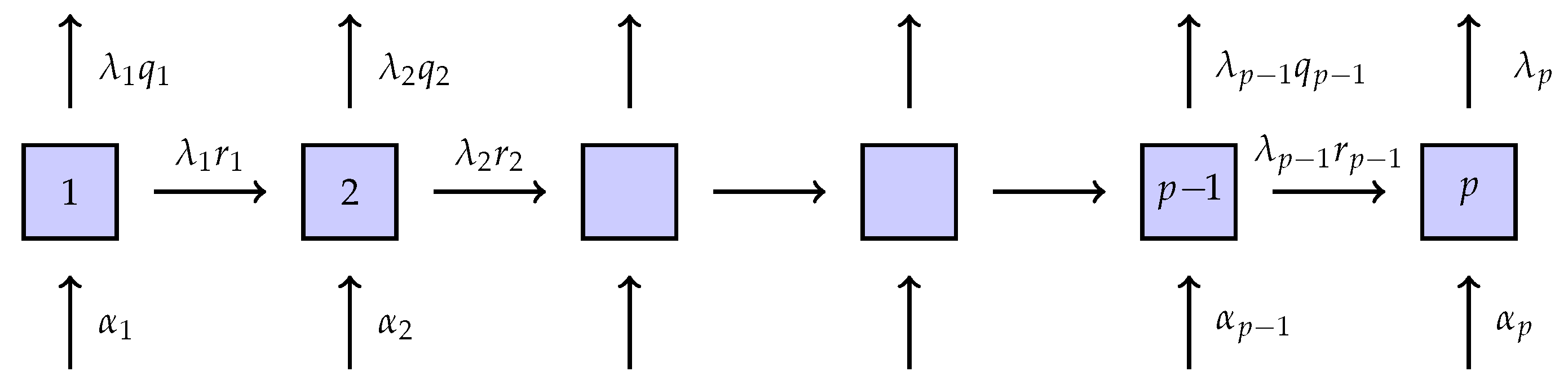
The subclass of generalized Coxian (GC) distributions will play a particular role. Here, the states are run through in lexicographical order, with exponential
holding time in state
i, and it is possible to enter or exit from any state (see
Figure 1), where
is the probability of exit after a visit to
i and
the probability of going to the next state. The structure of Coxian distributions is similar, except that only State 1 can be entered so that
. Coxian distributions are in particular used in (
Lin and Liu 2007) and (
Zadeh et al. 2014).
Remark 1. Though computational tractability and denseness are the main reasons for the popularity of PH distributions, other advantages have also sometimes been advocated. For example, whereas in the majority of examples, the PH modeling is purely descriptive, there are others where attempts have been made to give the Markov states a physical meaning like in compartment models and, in the life insurance context, in (
Lin and Liu 2007) and (
Zadeh et al. 2014). This makes the number
p of phases quite large there, of order 200, whereas we have taken the descriptive point of view. The fit obviously becomes better when increasing
p, but how good it needs to be depends very much on what it will be used for. In this paper, we consider the valuation problem, that is to calculate the net premium (expected discounted payoff) for equity-linked insurance products, and our numerical examples will show that taking
will be sufficient for the precision one needs in this context.
3. PH Fits of Human Mortality Data
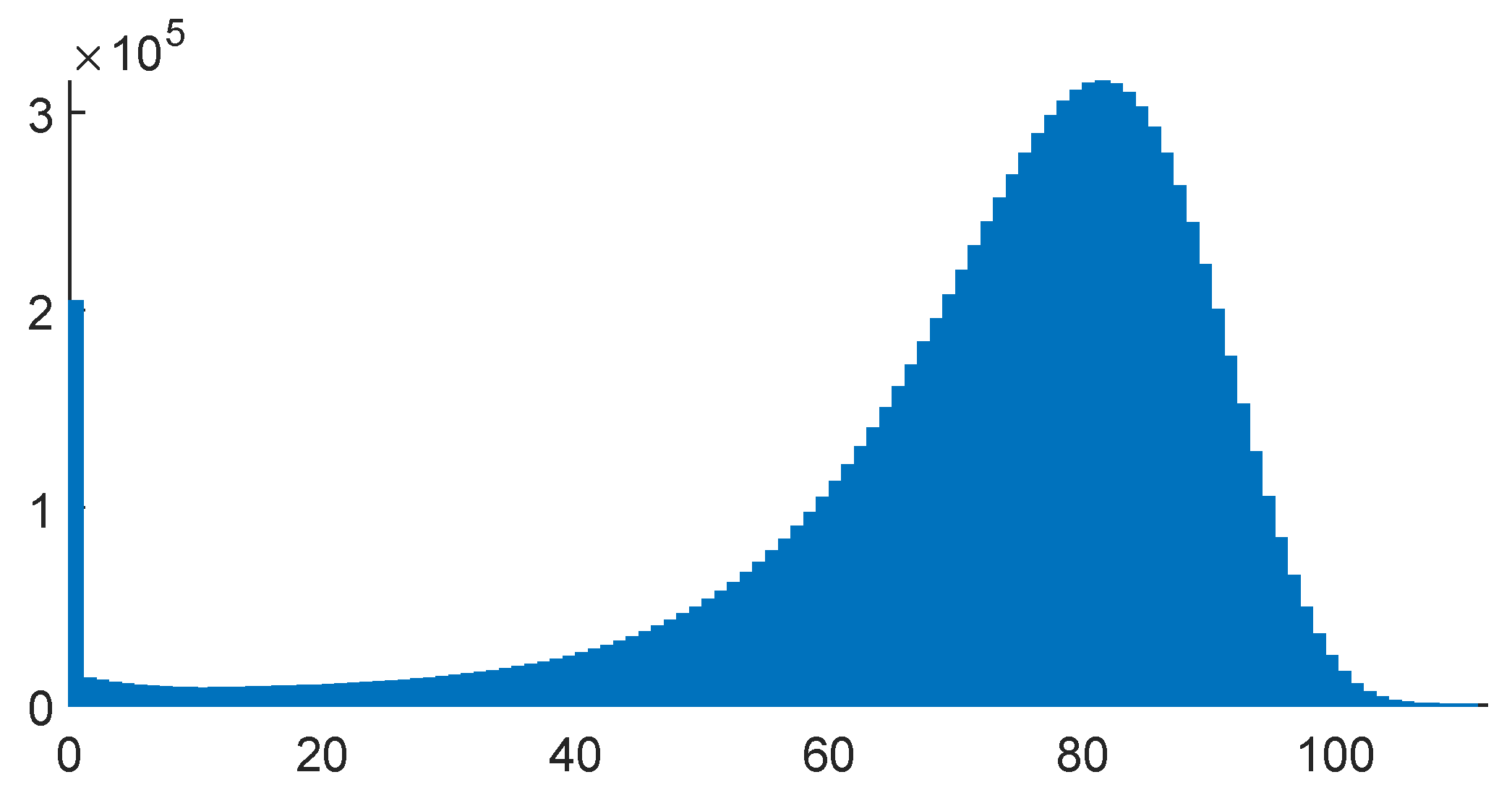
The distribution of human lifetimes of course varies somewhat according to the period where the data were collected, geographical and social conditions, etc., but the basic shapes are much alike. We have therefore concentrated on a single example, the illustrative life table in Appendix 2A of (
Bowers et al. 1997). The form of the distribution, as illustrated via the number of deaths in consecutive years, is given in
Figure 2.
We use an EM algorithm to fit various types of phase-type distributions to this life table. This idea was originally developed in (
Asmussen et al. 1996), with the case of censored data and other implementation details given in (
Olsson 1996). Olsson (
Olsson 1998) has written a C implementation of this algorithm called EMpht, which is available online. The overwhelming computational burden is in the E step, where many complicated integrals involving matrix exponentials must be evaluated. This is done approximately by converting the problem into a system of ODEs, which are approximately solved via a Runge-Kutta method. While the original C implementation is still very adequate for creating fits with a small number of phases
p, it can be improved upon for larger
p.
We wrote a new implementation using the Julia language. It allows for the E step to be evaluated in three different ways: (i) using an ODE solver (as in (
Asmussen et al. 1996;
Olsson 1996)), (ii) using quadrature methods, and (iii) using the uniformization method of Okamura et al.
Okamura et al. (
2011a,
2011b). We used this last method to generate the fits found later in this paper; the code we used to create the figures below will be made available online (
Asmussen et al. 2019). Each fit was given one hour execution time restricted to one thread on the processor Intel(R) Xeon(R) CPU E5-2698 v4 @ 2.20 GHz. The EM algorithm could have been terminated much earlier without a major difference to the quality of the fits, but as we were comparing the various values of
p, we wanted to ensure no individual fit was judged poorly for simply being stuck in a local maxima.
The PH representation in terms of is heavily overparameterized. There is an abundance of sets that leads to the same distribution. Consider, e.g., the PH with (where stands for transposition) and where is a diagonal matrix with on the diagonal (i.e., a hyperexponential distribution). If the diagonal elements in are permuted in any of the possibilities, then the distribution is unchanged. This example indicates that the maximum of the likelihood function ℓ is attained at several parameter values so that the choice of the initial parameter set will determine which one is found by the EM algorithm. The presence of local maxima with values cannot be excluded, but we are not aware of serious cases where the EM algorithm has been stuck in one of these.
In life insurance calculations, the relevant lifetime is not the overall one , but rather the remaining lifetime of the insured at the time when he/she signs the contract. That is, if the age of the insured at that time is x, the relevant distribution is that of given . As a typical example, we took and fitted PH distributions with various structure and various numbers p of phases. Note that while we fit the distribution of , which starts at zero, in the following, we plot given (i.e., the x axes begin at and not zero).
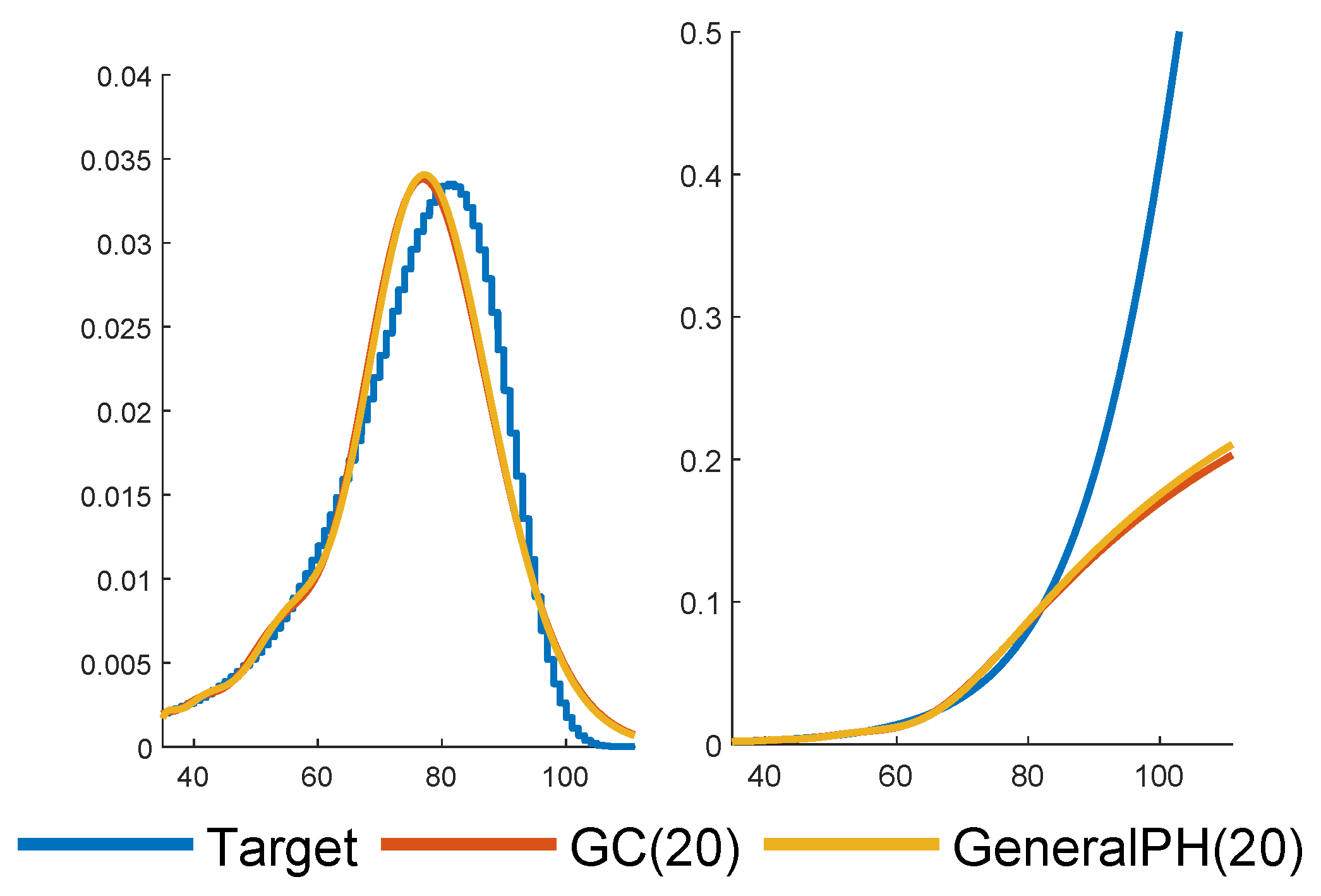
As a first illustration, we fit both a general structure PH and a generalized Coxian (GC) one with
phases. The results are in
Figure 3, with the densities of the fitted PH distributions in the left panel together with the data and the corresponding hazard rates in the right panel.
The fits of the two structures are almost identical (but the shape of the density is somewhat off the data, which indicates that a larger valuer of p could be appropriate). The general structure leads to a system of ODEs of dimension , whereas the corresponding number for GC is only . Due to this curse of dimensionality and the marginal differences of the fits, we have only considered GC structures for higher values of p.
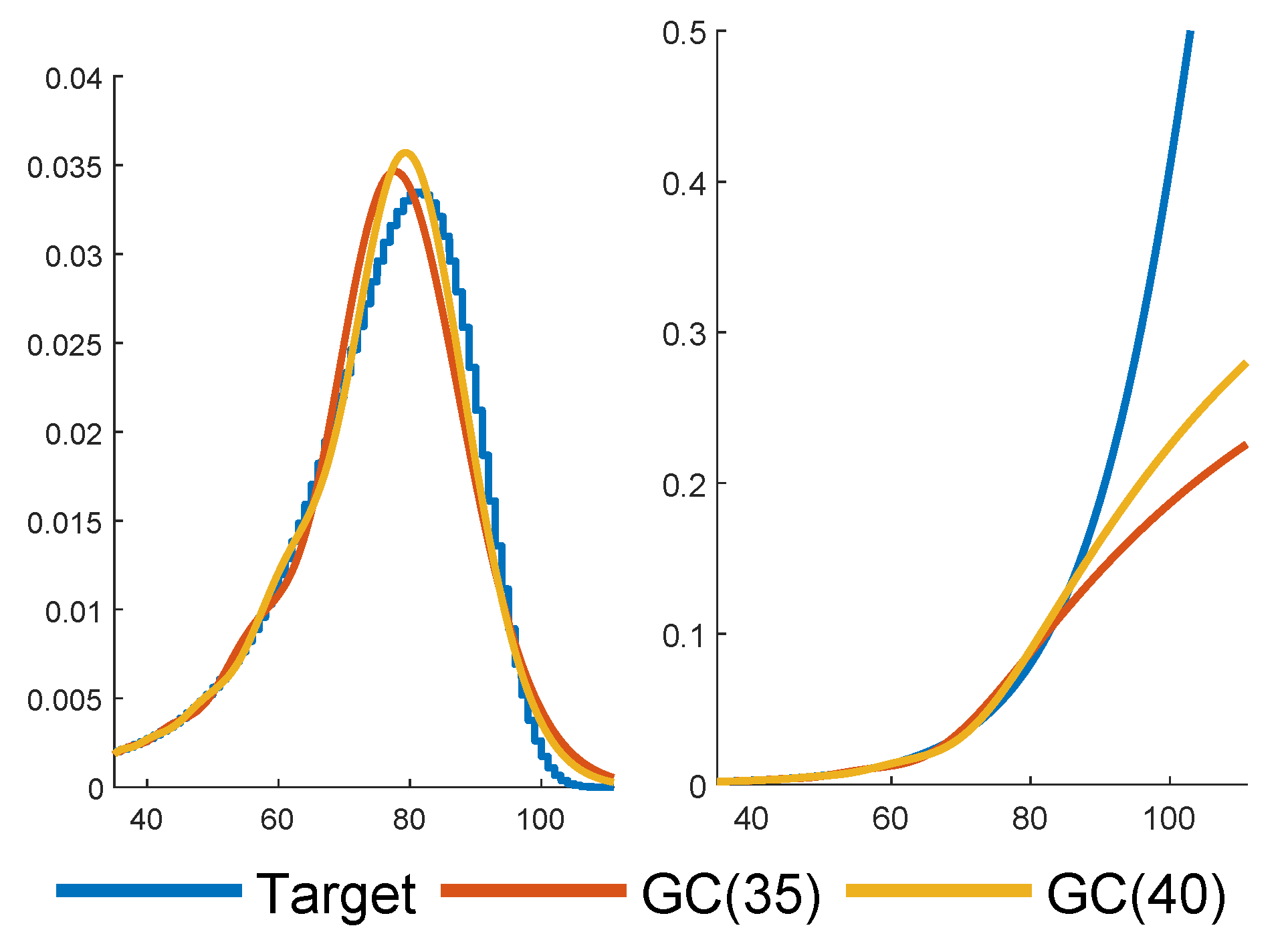
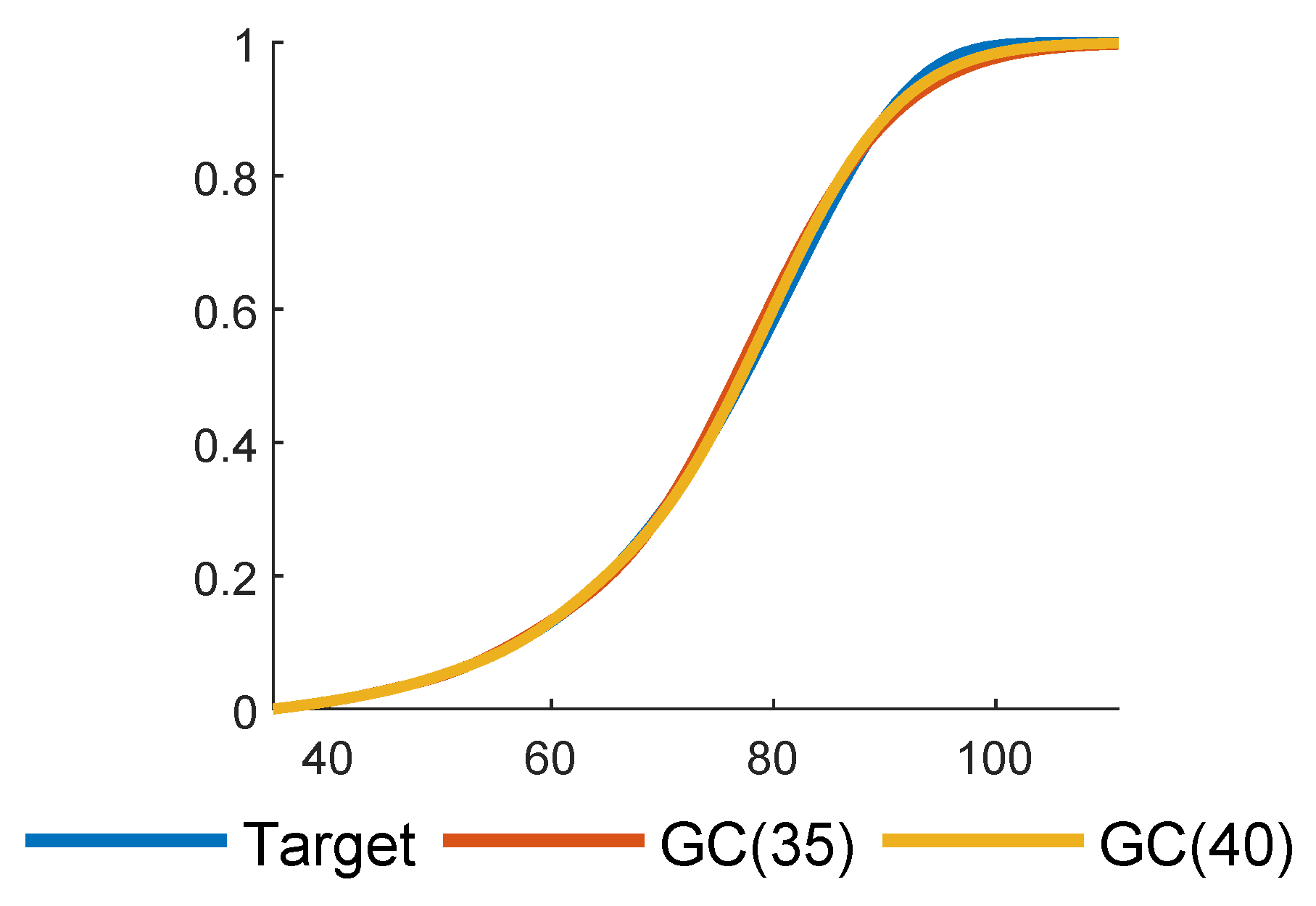
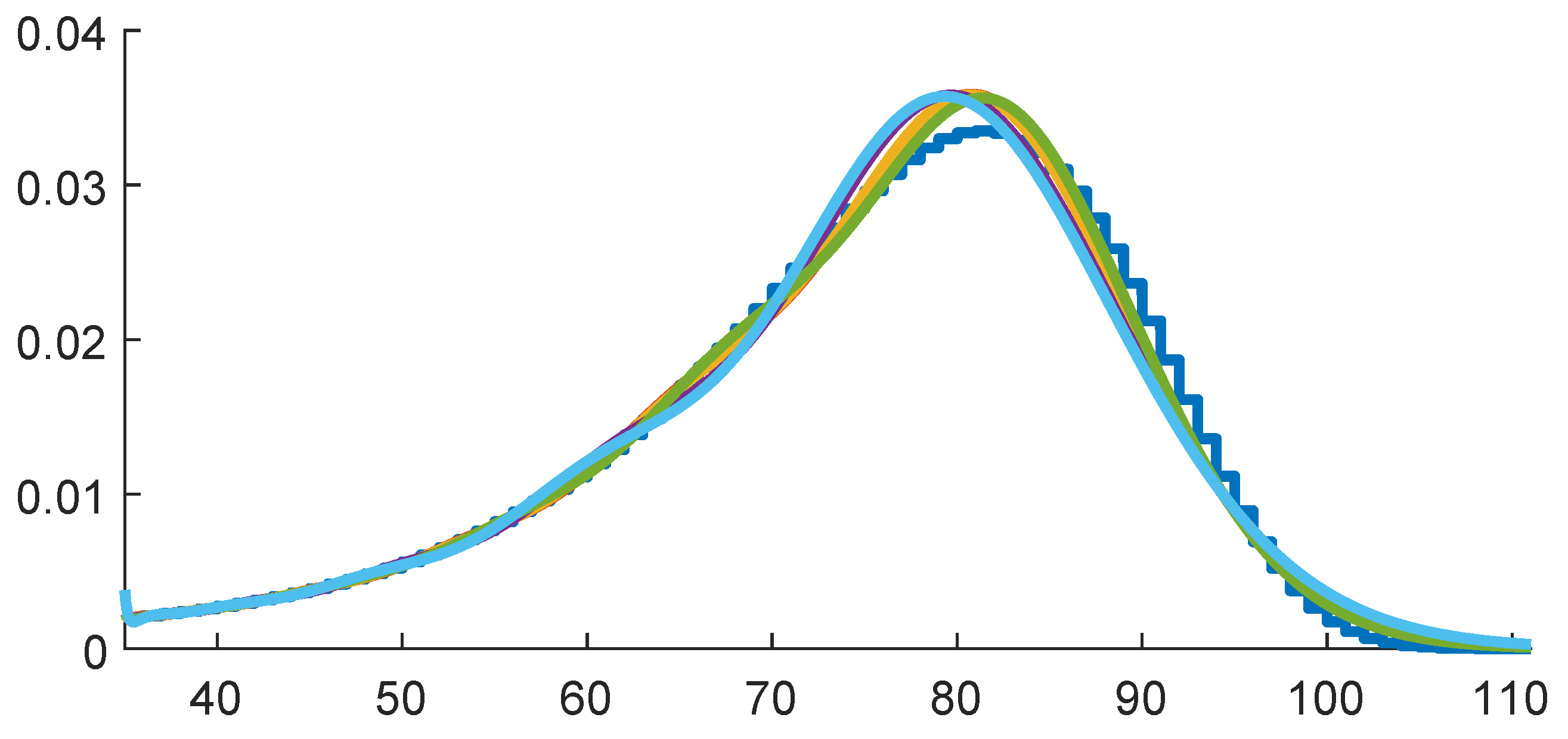
Figure 4 shows GC fits for
and
. As expected,
improves upon
.
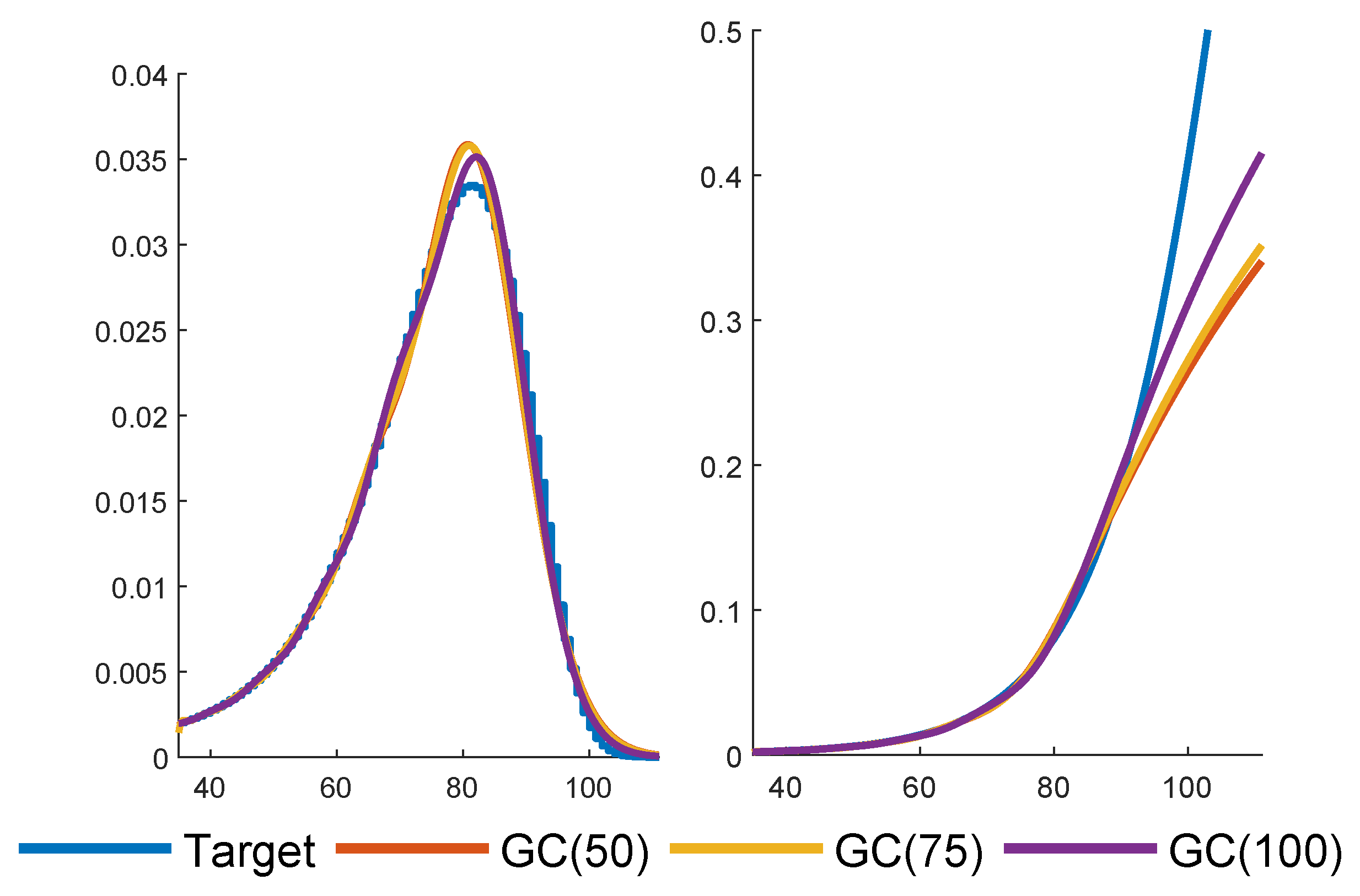
In
Figure 5, we complement
Figure 4 by plots of the tails. Such plots are frequently used to illustrate the quality of fits, but in our minds, a good agreement is not an argument in itself: two tails may come out quite similar in a comparison even if the shapes of the densities are rather different. Finally,
Figure 6 gives GC fits with
.
Which value of
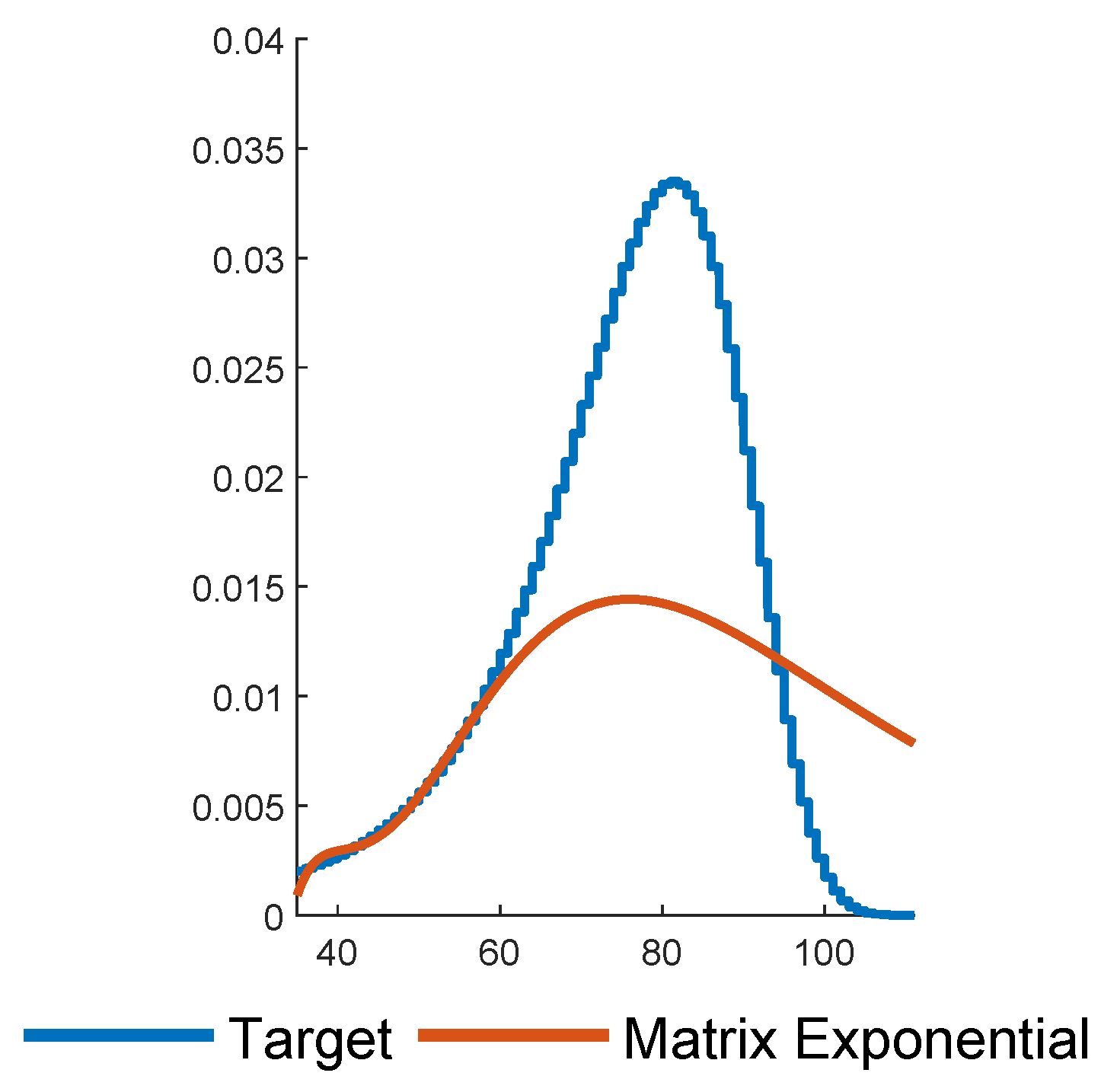
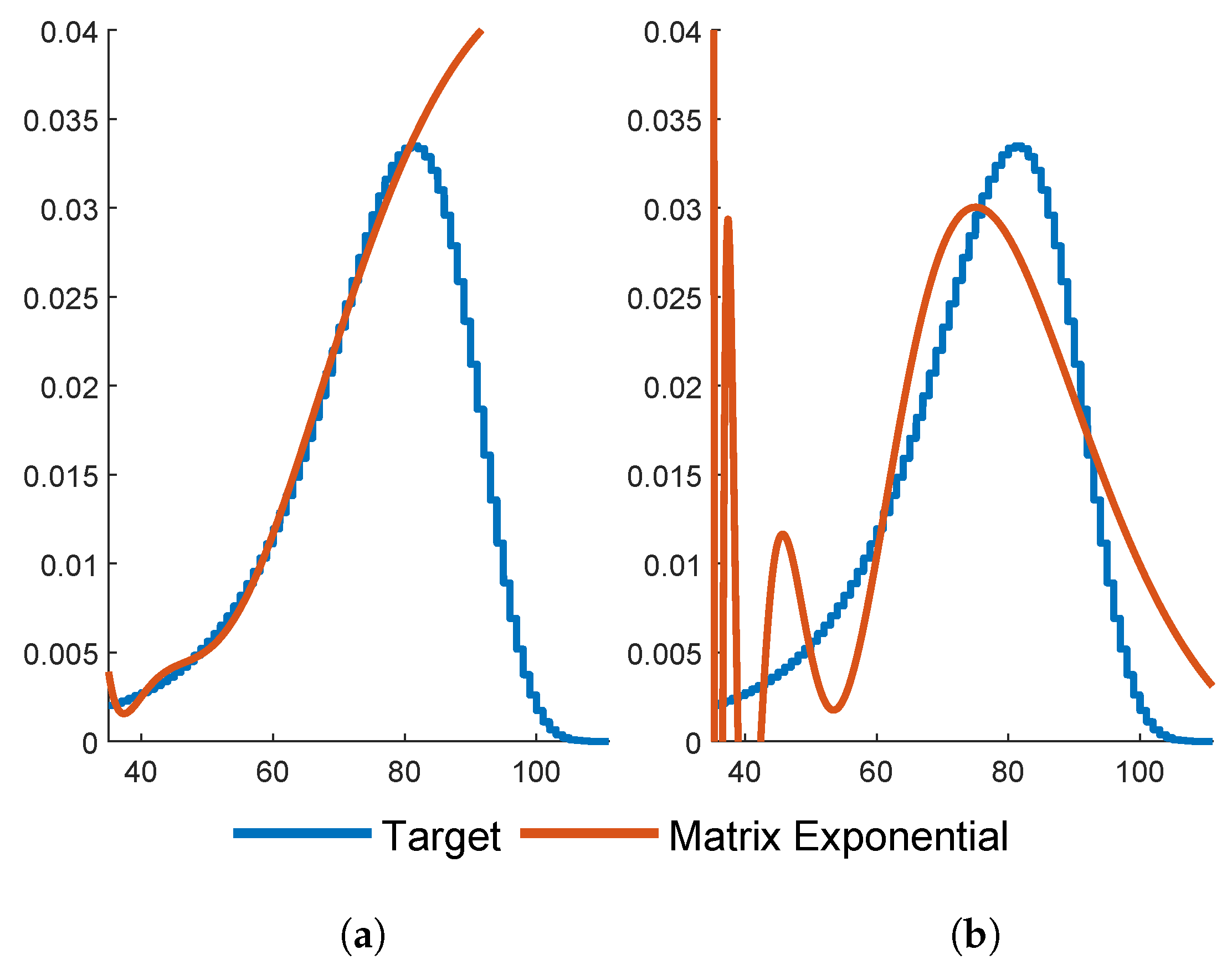
p should one then work with? There exists hardly a single criterion for answering such questions, i.e., assessing the quality of the fits to the data. Some concerns may be aesthetic, such as avoiding negative values of the density (cf.
Appendix A below), support outside the obvious range of the data (cf. kernel estimates), or an excessive number of parameters (as is the case for most PH fits as compared to, e.g., the classical Gompertz-Makeham fit of life table data). Other concerns may have to do with the features of the distribution which are considered especially important, be it the overall shape of the density (caught well by maximum likelihood), the cumulative distribution function (c.d.f.), although c.d.f.’s may look close even for rather different distributions, the tail (where maximum likelihood fails and other tools such as the Hill estimator may be more appropriate), the hazard rate (as showing up in numerous life insurance contexts), or the behavior in a more narrow range (cf. a life insurance contract signed at the start of employment and running up to the time of retirement). For the present purposes and related ones like applications in queueing and insurance risk, the main point is, however, that PH fitting is not done for its own sake, but for the purpose of facilitating some calculation, here of the prices of equity-linked products, in queueing, say of waiting time characteristics, etc. In the rest of the paper, we therefore study the performance of the PH approach and the various fits and return to a discussion of the issue in the concluding
Section 8.
4. Valuation of Benefits
The main application of the results in this paper is valuing equity-linked insurance products, in particular GMDBs in various deferred annuities. The time of payment of this kind of product is at the time
of death of the policyholder, often denoted
, where
x is his/her age at
when he/she signs the contract. The amount of the payment depends on the price
of a stock (or stock index) at that time and possibly also on the history of the stock price as, e.g., in (
1). There are many different products (benefit functions) in the market. One example is the GMDB with benefit function being:
where
K is the guaranteed amount, e.g.,
. The second term on the right-hand side (r.h.s.) of (
2) is the payoff of a life-contingent put option. Another popular product is the so-called high-water benefit (HWB) with the payoff function being:
Another form of the HWB function is:
where
. Since:
the second term on the r.h.s. of (
3) is the payoff of a life-contingent fractional lookback option.
In practice, the policyholders can withdraw. Note that the payment of the GMDB can be written as the payoff of a put option (plus a share of underlying stock). When the stock price rises, put options become less valuable; hence, policies may lapse. This motivates considering the benefit function:
where
is the indicator function and
H is a “barrier”. This is a barrier option payoff form.
Since we can approximate the distribution of
by a PH distribution, the valuation problem becomes calculating:
where
denotes a discounting factor and
is PH r.v. One example is to take
as the force of interest, but the company may want to use a lower
in its technical reserve to ensure a conservative pricing.
5. The Factorization: Implementation for Jump Diffusions
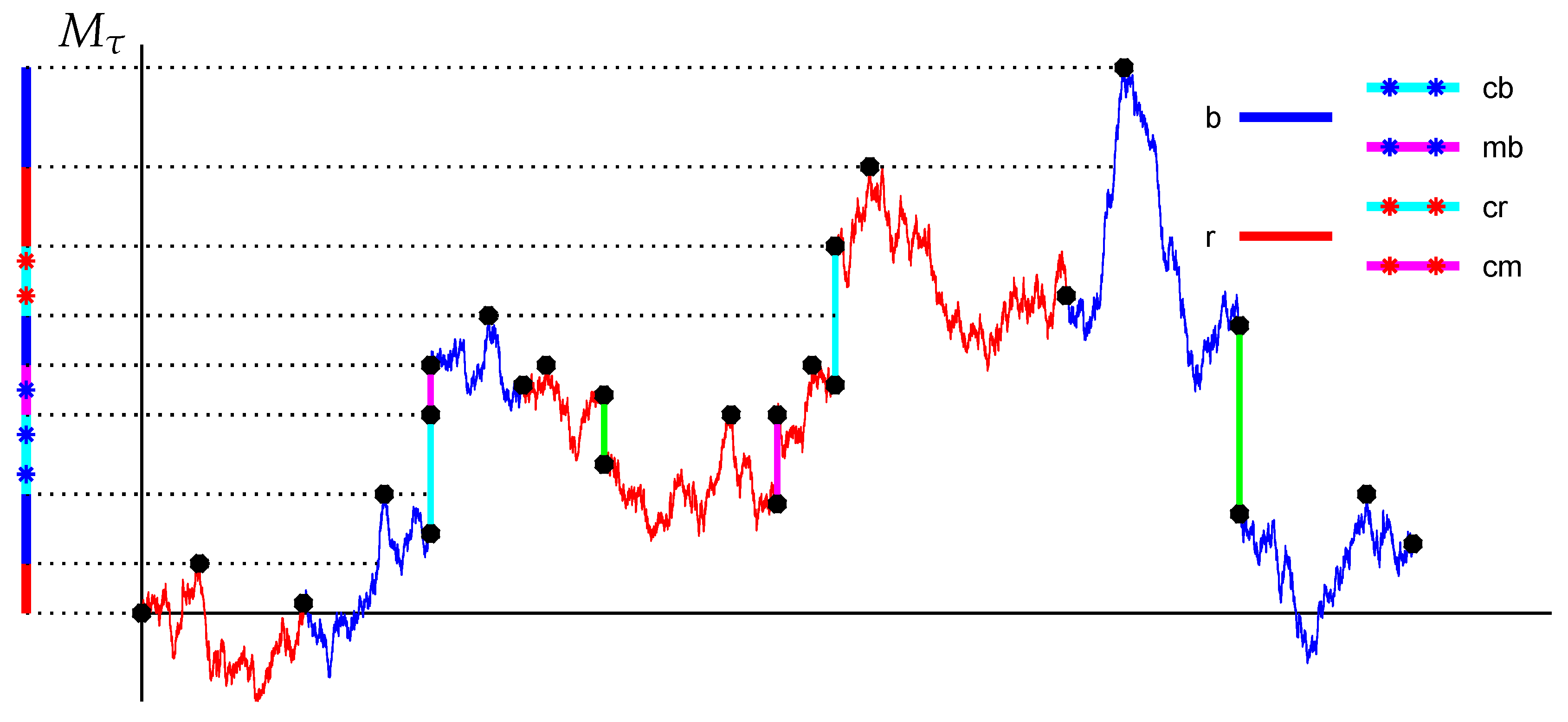
Our basic assumption is that X is a jump diffusion with Brownian parameters , upward jumps at rate and with a PH distribution of the sizes, and similar parameters for the downward jumps.
We will first need to introduce the equivalent time-reversed PH representation
of
. It is obtained by considering:
It turns out (
Asmussen 2003, III.5) that
is a terminating time-homogeneous Markov process with initial distribution
and generator
given by:
where
denotes the diagonal matrix with the positive vector
on the diagonal. To see this, consider a doubly-infinite stationary Markovian arrival process (
Asmussen 2003, XI.1) with generator
, where
gives the rates of phase changes with arrivals, and note that the corresponding stationary distribution of the phase process is proportional to
. Now, just use the standard time reversion for non-killed Markov processes. Considering, for the ease of exposition, the case
of no discounting, the form of the factorization identity of (
Asmussen and Ivanovs 2019) that is most convenient for our purposes is then:
where
is the probability measure where
is generated by the time-reversed representation and
X evolves as
did under
,
is the time at which the maximum is attained, and
.
The distributions of
are particularly simple if
X is BM
and
exponential
. In fact, they are then exponential with rates
, respectively
, where:
If more generally,
is a jump diffusion with both up- and down-ward PH jumps, there is an abundance of results and algorithms giving the distributions in various representations or their Laplace transforms. See, among others, (
Bean et al. 2005;
Breuer 2008;
Dieker and Mandjes 2011;
Horváth and Telek 2017;
Jacobsen 2005;
Jiang and Pistorius 2008;
Lewis and Mordecki 2008;
Mordecki 2002;
Pistorius 2006). The most appropriate form for our purposes is that for (computable) matrices
of dimension
, respectively
, one has:
where
are the
element of the vectors
, respectively
; this occurs already in (
Asmussen 1995), as well as several later sources, but we have in fact used a new and (we feel) somewhat more straightforward approach; see
Appendix B.
Multiplying (7), (
8) by
, respectively
and summing over
, the factorization (
6) then takes the form:
where
. The modification with discounting is explained in Section 4 of (
Asmussen and Ivanovs 2019) and becomes:
where
,
are calculated as
with
replaced by
(here, the
remain unchanged, i.e.,
,
and
are computed for the case
). This can be rewritten in matrix form as follows:
Corollary 1. (ii)
For functions f and g,where , are the matrices , respectively . Proof. Since , it may be replaced by its transpose in (9), and this gives the first identity in (i); the second follows by transposition. Part (ii) then follows by integration. ▯
For computations, the matrix form rather than the sum form is convenient for keeping the code short and transparent, and in many software packages like MATLAB, it also is faster. In a number of our examples, the matrices , come out in a simple form, avoiding integration. Here is a first example:
Example 1. For the HWB, we need to compute:
Thus (assuming
w.l.o.g.), we have
,
in Part (ii) of Corollary 1, and we get:
⋄
Corollary 2. Define . Then: Proof. For
, we have:
and so, the result follows immediately by Part (ii) of Corollary 1. The proof for
is similar; one only has to note that if
is defined as
with
and
interchanged, then
. ▯
Remark 2. The distribution of
restricted to
is in fact (defective) PH, but in general, with a different generator
than
(for this one would have needed that
be proportional to
). This follows from the general fact that if
and
is a phase generator, but possibly
, then
where:
and here,
is a phase generator; all needed positivity properties follow from
and
being non-negative.
Similar remarks apply to the negative part of
. These observations may be seen as an extension to jump diffusions at PH times of the standard fact that Brownian motion at an independent exponential time has a two-sided exponential distribution (often called the Laplace distribution). A similar result for matrix-exponential distributions is on p. 478 of (
Bladt and Nielsen 2017), but is in terms of Laplace transforms rather than densities.
Example 2. For the GMDB, the price is (taking
):
In the most common case
, the first term equals:
when
, whereas the second is:
⋄
Example 3. The calculation of reserves:
is closely related to price calculations. However, the details may be somewhat more cumbersome since for a fixed
t, the expressions for
have two components, the quantities
and
, which are known at time
t, and the unknown random ones:
In terms of these and the relations:
we can write
, where:
Since the conditional distribution of
given
is PH
where
, this gives:
(note that for the reversal, we need not calculate
by replacing
by
in (
5), but can use the same
for all
t, cf. Section 2.2 of (
Asmussen and Ivanovs 2019)).
Example 4. For the GMDB, we have:
where
. Combining with Remark 2, we therefore arrive at the same expression as in Example 2 when
, only with
K replaced by
and
by
. The case
may arise by randomness, but is just a minor modification.
Example 5. The details for the HWB reserves are somewhat more complicated than for the GMDB. Here, one needs to consider
, corresponding to:
One approach (potentially the easier one) may be simply to insert in (11) and do the two-dimensional numerical integration. However, in fact, one can reduce to a one-dimensional numerical integration similar to Corollary 2. To this end, note that
after simple derivations comes out as:
of these four possibilities, (12d) (and to a slightly lesser extent, (12c)) is the most complicated one with which to deal. The contribution to the reserve from (12c) is zero if
, since then, the defining region is empty. Otherwise, it becomes:
which after two integrations reduces to an expression, which, though complicated, only involves known matrices and their exponentials, except that:
is left to be determined by numerical integration. ⋄
6. Numerical Examples
For the underlying stock price process
, the most popular model is the geometric Brownian motion model. Since this model cannot capture the asymmetric leptokurtic features and the volatility smile, many modified models have been proposed in the literature; one of these is the jump diffusion model, cf. (
Kou 2002). Empirical studies show that the daily return distribution tends to have larger kurtosis than the distribution of monthly returns, and the jump diffusion model can capture this feature; see (
Das and Foresi 1996). As an illustrative example, we suppose that the yearly interest rate is
and the yearly volatility
. The jumps follow a compound Poisson process with upward jump rate
with the jump sizes being exponential with rate
(mean 1/50) and downward jump rate
with jump size being exponential with rate
. When considering the valuation of an insurance product alone, it is not necessary to use a risk-neutral valuation approach. However, since in our setting, the underlying involves an equity, it is natural to use an equivalent martingale measure
, defined by the requirement
. This does not define
uniquely since the market is incomplete due to the jumps and the mortality risk. Our choice was to let the parameters
remain unchanged, which gives the risk-neutral Brownian drift as:
For the illustrative example, we have:
It is left to compute the
. Writing:
we obtain:
and thus, it suffices to consider
. Essentially, two types of algorithms are available. One set is based on finding roots in the complex plane of equations of the form
where
is the Lévy exponent of
X. The other uses fixed-point equations of the form
and iteration,
, with
and
suitably chosen.
We give a few examples of previous algorithms of both types in
Appendix B. When implementing these with
having one of the GC representations fitted in
Section 3, our experience was that the root-finding method was only feasible for a rather small number
p of phases. More precisely, for
or
, meaningless results were produced, with warnings of the matrix
being close to singular. This is understandable since many eigenvalues of the relevant matrices are almost identical. Since the iterative algorithms ran without problems also for large values of
p, we have therefore concentrated on these. In fact, we have developed a new iterative algorithm, which may be simpler than previous ones. It is presented in
Appendix B, but for now, we concentrate on some numerical examples.
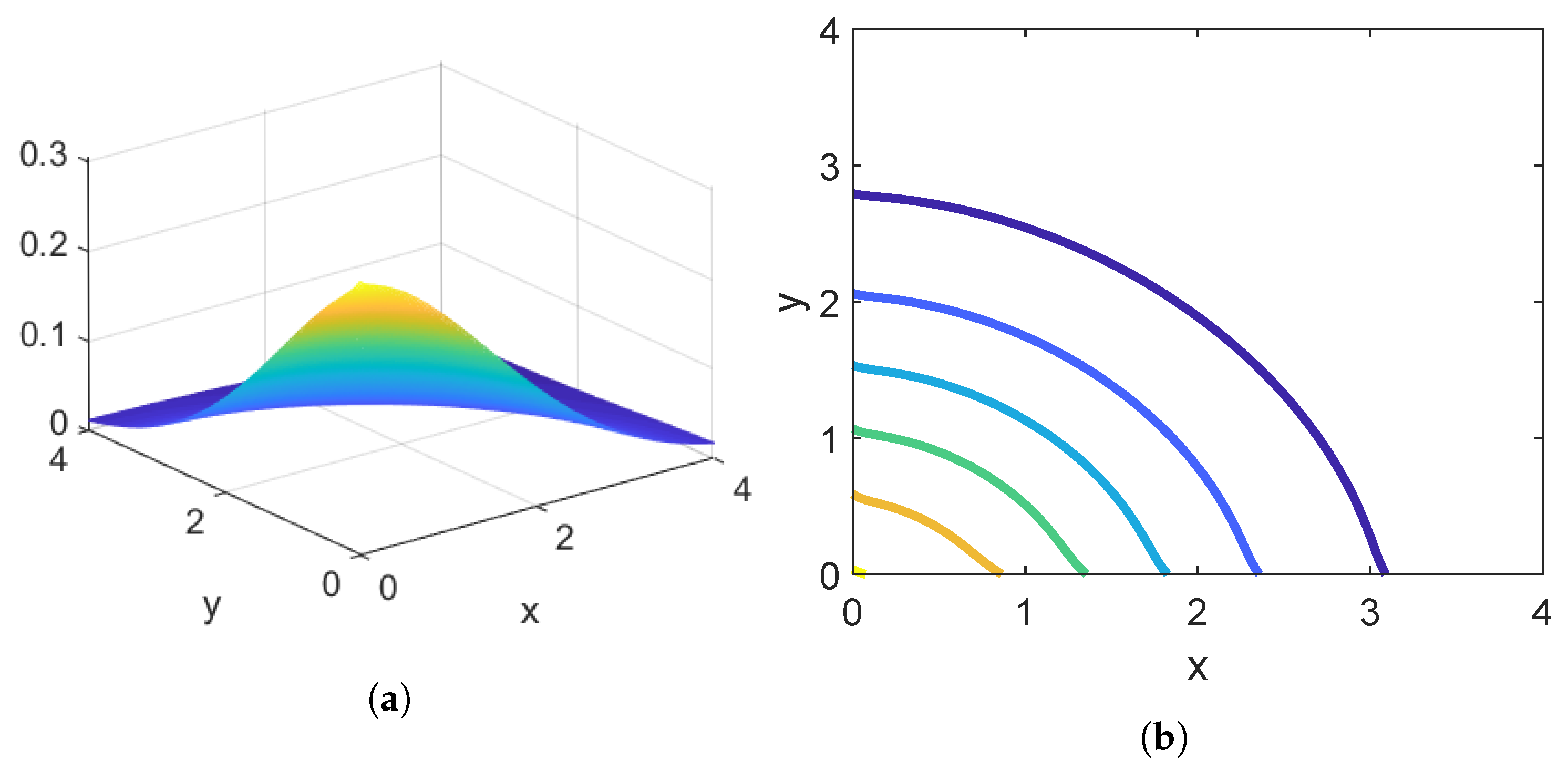
Example 6. In
Figure 7, we have plotted the marginal densities of
,
, and
.
Example 7. Figure 8 gives the joint distribution of
and
(computed by Corollary 1) for our jump diffusion with the parameters given above.
Example 8. To consider the sensitivity of the algorithms to the value
p of chosen phases for
, we took
or 0.00 and computed the price (10) for
20, 35, 40, 50, 75, 100 and the GC fits presented in
Section 3 for two products, the HWB with
and the GMDB with
; the relevant formulas are available from Examples 1 and 2. The results are in
Table 1. We also complemented with a Monte Carlo simulation estimate with an associated 95% confidence interval based on
replications, where
was generated from the discrete life table distribution with an additional randomization within the year.
A related question is how varying different fits can be for a fixed
p due to issues such as non-uniqueness of PH representations and possibly local maxima of the likelihood. We illustrate this point in
Table 2, which is a parallel of
Table 1. We fix
p at 50, but use five different initial values (seeds) for the EM algorithm, all allowed the same running time. The fitted densities are in
Figure 9.
Our conclusion is that the differences are too minor to be of any concern, and certainly, using a single fit with will produce acceptable results. Insisting on more than 2–3-digit precision in price estimates does not make sense due to issues such as model uncertainty and that payments will be adjusted later via bonus and dividend arrangements.
The programming was done in MATLAB on a 2014 MacBook Air with a 1.4 GHz Intel Core i5 processor. As an example of execution times, MATLAB’s tic-toc command reported approximately two seconds for each HWB or GMDB value using the PH methodology. The figures for the Monte Carlo values were much higher, approximately 30,000 replications per minute (recall that replications were used). The programming is very simple, with the main effort lying in writing a routine for computing for a given set of input parameters. This amounted to 50 lines of code in our implementation. Given this ease, we did some further price computations, even if our aim here is not to illustrate pricing aspects, but rather the computational ones.
Example 9. We first consider varying the discount rate
, but not the force of interest
r, cf. the remarks following (
4) (that in particular motivate taking
). The results for the HWB are in
Table 3 and show the expected picture, that the price is decreasing in the discount rate.
Example 10. The next example is discounting with the force of interest, i.e., taking
and varying
r. The numerical values are in
Table 4, and the picture is again that the price is decreasing in
. The intuition is less clear-cut here, since the Brownian drift
is increasing and thus pulls in the opposite direction.
Example 11. Next, we give an illustration of a feature of the factorization: if
is exponential, then
and
are independent. cf. Lemma 1. In the PH case, there is dependence caused by the common value of
. How does this influence the price? A numerical illustration is in
Table 5, where the entries are the ratios between the correct price with dependence and the incorrect one computed assuming independence, i.e., as:
The other settings are as in
Table 3.
Table 5 shows that in some cases, dependence indeed influences the price quite a bit.
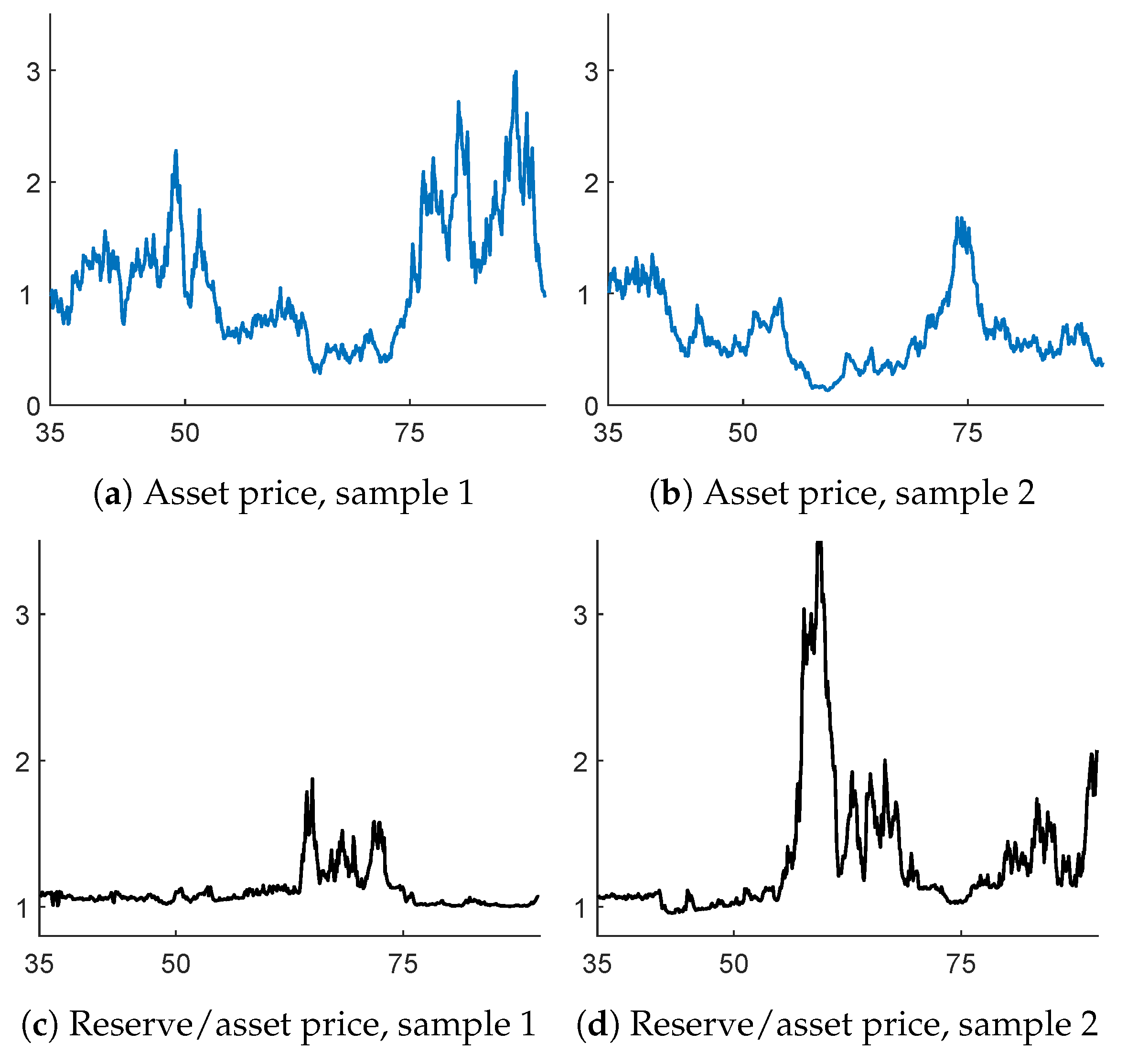
Example 12. As a follow-up of Example 3, we finally consider the evaluation of reserves. Two paths of the jump diffusion were simulated, and the reserve was calculated for each value of
t using the formulas of Examples 3, 4 and 5. The results are given in the graphs of
Figure 10. The upper panel gives the stock price
(assuming
) and the lower one the ratio
as function of the age
a of the insured.
When
,
because of the martingale property. Hence, the ratio in the lower panel should always be at least one. This is also confirmed from the figure, as well as the expectation that the ratio should be close to one when
is large.
In the calculations, we used the fact that and need not be recalculated for each t, cf. the remarks following (11). This gave a substantial speed-up.
7. Erlangization and Extrapolation
A multitude of papers in finance, insurance, and queuing theory explore the idea of Erlangization or Canadization, that is approximation of a deterministic time
T by an Erlang
time
with the same mean. Here,
q is the number of stages and
is the rate, so that
is the sum of
q mean
exponential r.v.’s. This idea has various applications: explicit identities (see, e.g., (
Asmussen et al. 2002;
Carr 1998;
Stanford et al. 2005)); this is used in (
Kuznetsov et al. 2011) together with the traditional Wiener-Hopf factorization to provide an algorithm simulating
to approximate
and as a numerical tool for calculating
as the limit of
(or just
) under suitable continuity conditions on
f; see, e.g., (
Asmussen et al. 2002;
Carr 1998;
Leung et al. 2015). This last procedure uses the fact that
converges in probability to
T as
. In (
Asmussen et al. 2002), it is combined with extrapolation, which is based on the asymptotics:
valid for
f smooth and some
. This
C is typically not available, but (13) suggests eliminating
C by estimating
using:
which converges to
at the improved rate
. The numerical examples of (
Asmussen et al. 2002) indicate that often, calculations with
q set as small as 2–4 will give very good precision.
The relevance for the present purposes is that the time horizon of many life insurance contracts is not the remaining lifetime
of the insured, but rather
, where
T is a fixed deterministic number. For example, when the age of the insured is 35 at the time of underwriting,
corresponds to contract expiry at age 80 if the insured is still alive. Some calculations can be found in Section 10 of (
Gerber et al. 2012) for
exponential and a call or put option, but rely heavily on this particular structure. For our life insurance applications, it is crucial that
is again PH when
and
are independent. The details involve the Kronecker product ⊗ and sum ⊕ so that:
For two Markov process generators, the Kronecker sum is the generator of independent versions, and so,
is PH with generator
of dimension
where
is the PH generator of
. Written out with lexicographical order of the states:
Example 13. We consider a HWB or GMDB contract signed at age 35 of the insured and expiring at the time
of death or at age 70, whatever comes first. We took
and used the GC fit with
, leading to the numerical values given in
Table 6; in comparison, Monte Carlo simulation with
50,000 replications gave the 95% confidence interval 1.636 ± 0.034 for the HWB and 1.097 ± 0.029 for the GMDB.
The extrapolation is done via (14), with the required smoothness being obvious for the GMDB. For the HWB, is not smooth at , but some rough heuristics (that we omit) suggest that (13) remains in force for this special f. Certainly, extrapolation appears to produce sensible results also for the GMDB. In both cases, it seems that 4–6 is enough to obtain sufficiently precise estimates, whereas without extrapolation, one would need at least . This is a considerable improvement upon simple Erlangization, since the dimension of the matrices in the computations (where inversion is the heavy part) is . This means that for , one would need to invert matrices of dimension 400 when , but 1000 when , and since the inversion of an matrix has complexity (or slightly less with sophisticated methods), this corresponds to reducing computation time by a factor of about .
8. Conclusions
In this paper, we have considered pricing calculations for life insurance products like the guaranteed minimum death benefit and the high-water benefit. The payout occurs at the death time of the insured, and its size is linked to an asset price S either via its current value or to features of its past evolution during the time of the contract such as the maximum .
The key observation is that for the most popular model of
S, an exponential jump diffusion, the distributions of
and/or
are available when the jumps and
are phase-type. This has long been known in the geometric Brownian motion setting without jumps when
is exponential and is essentially just the Wiener-Hopf factorization of Brownian motion. There is also an extensive literature for PH jumps, and for
itself being PH, the relevant Wiener-Hopf factorization has recently been developed in (
Asmussen and Ivanovs 2019).
The program thus involves two steps, first fitting a PH distribution of to lifetime data and next implementing the pricing calculations.
The shape of lifetime data with a steep decline after the mode makes the fitting of PH distributions non-trivial, necessitating the number
p of phases to be relatively high. However, we already made the points that a good fit is one that produces reliable estimates of the prices of the life insurance products, and that giving more than 2–3-digit precision in price estimates does not make sense due to issues such as uncertainty about the model and its parameters (think, e.g., of longevity risk) and bonus/dividend arrangements. We found
to be more than sufficient in the sense of providing appropriate accuracy of the calculated price of life insurance products and could well have worked with smaller values. An alternative is developed in GSY, to use matrix-exponentials fitted at a selected number of points, but we show in
Appendix A that this approach has its pitfalls.
Fitting of so high-dimensional PH distributions is slow, though we developed in part some new software giving substantial speed-up. However, given this step has been passed, pricing calculations are both very easy to program and run very fast, also compared to Monte Carlo simulation, and this may be the main advantage of our approach. A limitation is of course that we need the pay-out to be of the form (
1), and there are many products for which this is not the case. Alternatives such as Monte Carlo simulation and traditional methods based on Thiele-type differential equations may then be more suitable. Therefore, we do not claim the superiority of our own approach for all purposes, but have rather tried to clarify its advantages and disadvantages.

















{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}