1. Introduction
During the 20th Century, mortality has declined at all ages, producing a steep increase in life expectancy. This decrease is mainly due to the reduction of infectious disease mortality (between 1900 and 1950), as well as cardio-circulatory diseases and cancer mortality (in the most recent decades). Knowledge of future mortality rates is an important matter for life insurance companies with the goal of achieving adequate pricing of their life products. Therefore, sophisticated techniques to forecast future mortality rates have become increasingly popular in actuarial science, in order to deal with the longevity risk. Among the stochastic mortality models proposed in the literature, the Lee-Carter model
Lee and Carter (
1992) is the most widely used in the world, probably for its robustness. The original model applies singular-value decomposition (SVD) to the log-force of mortality to find three latent parameters: a fixed age component and a time component capturing the mortality trend that is multiplied by an age-specific function. Then, the time component is forecasted using a random walk. More recent approaches involve non-linear regression and generalized linear models (GLM), e.g.,
Brouhns et al. (
2002) assumed a Poisson distribution for deaths and calculated the Lee-Carter model parameters by log-likelihood maximization.
In recent years, machine learning techniques have assumed an increasingly central role in many areas of research, from computer science to medicine, including actuarial science. Machine learning is an application of artificial intelligence through a series of algorithms that are optimized on data samples or previous experience. That is, given a certain model defined as a function of a group of parameters, learning consists of improving these parameters using datasets or accumulated experience (the “training data”). Even though machine learning may not explain everything, it is very useful in detecting patterns, even unknown and unidentifiable ones, as well as hidden correlations. In this way, it allows us to understand processes better, make predictions about the future based on historical data, and categorize sets of data automatically.
We can distinguish between supervised and unsupervised learning methods. In the supervised learning methods, the goal is to establish the relations between a range of predictors (independent variables) and a determined target (dependent variable), whereas in the unsupervised learning methods, the algorithm sets patterns among a range of variables in order to group records that show similarities, without considering an output measure. While in the supervised method, the algorithm learns from the dataset the rules that are fed to the machine, in the unsupervised method, it has to identify the rules autonomously. Logistic and multiple regression, classification and regression trees, and naive Bayes are examples of supervised learning methods, while association rules and clustering are classified as unsupervised learning methods.
Despite the increasing usage in different fields of research, applications of machine learning in demography are not so popular. The main reason lies in the findings often being seen as “black boxes” and considered difficult to interpret. Moreover, the algorithms are not theory driven (but quite data driven), while demographers are often interested in analyzing specific hypotheses. They are likely to be unwilling to use algorithms whose decisions cannot be rationally explained.
However, we believe that machine learning techniques can be valuable as a complement to standard mortality models, rather than a substitute.
In the literature related to mortality modeling, there are very few contributions on this topic. The work in
Deprez et al. (
2017) showed that machine learning algorithms are useful to assess the goodness of fit of the mortality estimates provided by standard stochastic mortality models (they considered Lee-Carter and Renshaw-Haberman models). They applied a regression tree boosting machine to “analyze how the modeling should be improved based on feature components of an individual, such as its age or its birth cohort. This (non-parametric) regression approach then allows us to detect the weaknesses of different mortality models” (p. 337). In addition, they investigated cause-of-death mortality. In a recent paper, the work in
Hainaut (
2018) used neural networks to find the latent factors of mortality and forecast them according to a random walk with drift. Finally, the work in
Richman and Wüthrich (
2018) extended the Lee-Carter model to multiple populations using neural networks.
We investigate the ability of machine learning to improve the accuracy of some standard stochastic mortality models, both in the estimation and forecasting of mortality rates. The novelty of this paper is primarily in the mortality forecasting that takes advantage of machine learning, clearly capturing patterns that are not identifiable with a standard mortality model. Following
Deprez et al. (
2017), we use tree-based machine learning techniques to calibrate a parameter (the machine learning estimator) to be applied to mortality rates fitted by the standard mortality model.
We analyze three famous stochastic mortality models: the Lee-Carter model
Lee and Carter (
1992), which is still the most frequently implemented, the Renshaw-Haberman model
Renshaw and Haberman (
2006), which also considers the cohort effect, and the Plat model
Plat (
2009), which tries to combine the parameters of the Lee-Carter model with those of the Cairns-Blake-Dowd model with the cohort effect, named “M7” (
Cairns et al. (
2009)).
Three different kinds of supervised learning methods are considered for calibrating the machine learning estimator: decision tree, random forest, and gradient boosting, which are all tree-based.
We show that the implementation of these machine learning techniques, based on features components such as age, sex, calendar year, and birth cohort, leads to a better fit of the historical data, with respect to the estimates given by the Lee-Carter, Renshaw-Haberman, and Plat models. We also apply the same logic to improve the mortality forecasts provided by the Lee-Carter model, where the machine learning estimator is extrapolated using the Lee-Carter framework. Out-of-sample tests are performed for the improved model in order to verify the quality of forecasting.
The paper is organized as follows. In
Section 2, we specify the model and introduce the tree-based machine learning estimators. In
Section 3, we present the stochastic mortality models considered in the paper. In
Section 4, we illustrate the usage of tree-based machine learning estimators to improve both the fitting and forecasting quality of the original mortality models. Conclusions and further research are then given in
Section 5.
2. The Model
We consider the following categorical variables, identifying an individual: gender (g), age (a), calendar year (t), and year of birth (c). We assign to each individual the feature with the feature space, where: , , , . Other categorical variables could be included in the feature space X, e.g., the marital status, the income, and other individual information.
We assume that the number of deaths meets the following conditions:
where is the central death rate and are the exposures.
Let us define
as the expected number of deaths estimated by a standard stochastic mortality model (such as Lee-Carter, Cairns-Blake-Dowd, etc.) and
the corresponding central death rate. Following
Deprez et al. (
2017), but modeling the central death death rate instead of mortality rate (
), we initially set:
The condition
means that the specified mortality model perfectly fits the crude rates. However, in the real world, a mortality model could overestimate (
) or underestimate (
) the crude rates. Therefore, we calibrate the parameter
, based on the feature
, according to three different machine learning techniques. We find
as a solution of a regression tree algorithm applied to the ratio between the death observations and the corresponding value estimated by the specified mortality model
:
We denote by
the machine learning estimator obtained by solving Equation (
1), where mdl indicates the stochastic mortality model and ML the machine learning algorithm used to improve the mortality rates given by a certain model. The estimator
is then applied to the central death rate of the specified mortality model,
, aiming to obtain a better fit of the observed data:
As in
Deprez et al. (
2017), we measure the improvement in the mortality rates attained by the tree growing algorithm through the relative changes of central death rates:
The work in
Hainaut (
2018) used neural networks to learn the logarithm of the central death rates directly from the features of the mortality data, by using age, calendar year, and gender (and region) as predictors in a neural network. We instead rely on the classical form of the Lee-Carter model that we improve ex-post using machine learning algorithms, considered complementary and not an alternative to the standard mortality modeling.
To estimate , we use the following tree-based machine learning (ML) techniques:
Decision tree
Random forest
Gradient boosting
2.1. Decision Trees
The tree-based methods for regression and classification (
Breiman et al. 1984) have become popular alternatives to linear regression. They are based on the partition of the feature space
, through a sequence of binary splits, and the set of splitting rules used to segment the predictor space can be summarized in a tree (
Hastie et al. 2016). Once the entire feature space is split into a certain number of simple regions recursively, the response for a given observation can be predicted using the mean of the training observations in the region to which that observation belongs (
James et al. 2017;
Alpaydin 2010).
Let
be the partition of
; the decision tree estimator is calculated as:
Decision trees (DT) algorithms have advantages over other types of regression models. As pointed out by
James et al. (
2017): they are easy to interpret; they can easily handle qualitative predictors without the need to create dummy variables; they can catch any kind of correlation in the data. However, they suffer from some important drawbacks: they do not always have predictive accuracy levels similar to those of traditional regression and classification models; they can lack robustness: a small modification of the data can produce a tree that strongly differs from the one initially estimated.
The ML estimator is obtained using the R package
rpart (
Therneau and Atkinson 2017). The algorithm provides the estimate of
given by the average of the response variable values
belonging to the same region identified by the regression tree. The values of the complexity parameter (
) for the decision trees are chosen with the aim of making the number of splits considered uniform.
2.2. Random Forest
The aggregation of many decision trees can improve the predictive performance of trees. Therefore, we first apply bagging (also called bootstrap aggregation) to produce a certain number,
B, of decision trees from the bootstrapped training samples, in turn obtained from the bootstrap of the original training dataset. Random forest (RF) differs from bagging in the way of considering the predictors: RF algorithms account only for a random subset of the predictors at each split in the tree, as described in detail by
Breiman (
2001). If there is a strong predictor in the dataset, the other predictors will have more of a chance to be chosen as split candidates from the final set of predictors (
James et al. 2017). The RF estimator is calculated as follows:
The RF estimator is obtained by applying the algorithm from the R package
randomForest (
Liaw 2018). Since this procedure proved to be very costly from a computational point of view, the number of trees must be carefully chosen: it should not be too large, but at the same time able to produce an adequate percentage of variance explained and a low mean of squared residuals, MSR.
2.3. Gradient Boosting
Consider the loss in using a certain function to predict a variable on the training data; gradient boosting (GB) aims at minimizing the in-sample loss with respect to this function by a stage-wise adaptive learning algorithm that combines weak predictors.
Let
be the function; the gradient boosting algorithm finds an approximation
to the function
that minimizes the expected value of the specified differentiable loss function (optimization problem). At each stage
i of gradient boosting (
), we suppose that there is some imperfect models
, then the gradient boosting algorithm improves on
by constructing a new model that adds an estimator
h to provide a better model:
where
is a base learner function (
is the set of arbitrary differentiable functions) and
is a multiplier obtained by solving the optimization problem. The GB estimator is obtained using the R package
gbm (
Ridgeway 2007). The
gbm package requires choosing the number of trees (
) and other key parameters as the number of cross-validation folds (
), the depth of each tree involved in the estimate (
), and the learning rate parameter (
). The number of trees, representing the number of GB iterations, must be accurately chosen, as a high number would reduce the error on the training set, while a low number would result in overfitting. The number of cross-validation folds to perform should be chosen according to the dataset size. In general, five-fold cross-validation, which corresponds to
of the data involved in testing, is considered a good choice in many cases. Finally, the interaction depth represents the highest level of variable interactions allowed or the maximum nodes for each tree.
4. Numerical Analysis
4.1. Model Fitting
We fit the Lee-Carter (LC), Renshaw-Haberman (RH) and Plat models on the Italian population. Data were downloaded from the Human Mortality Database (
www.mortality.org), while model fitting was performed with
StMoMo package provided by
Villegas et al. (
2015). The following sets of gender
, ages
, years
, and cohort
were considered in the analysis:
, , , and .
The model accuracy was measured by the Bayes information criterion (BIC) and the Akaike information criterion (AIC), which are measures generally used to evaluate the goodness of fit of mortality models
1. Log-likelihood
, AIC and BIC values are reported in
Table 1, from which we observe that the RH model fits the historical data very well. It has the highest BIC and AIC values for both genders, with respect to the other models; then, in order, the LC model and the Plat model.
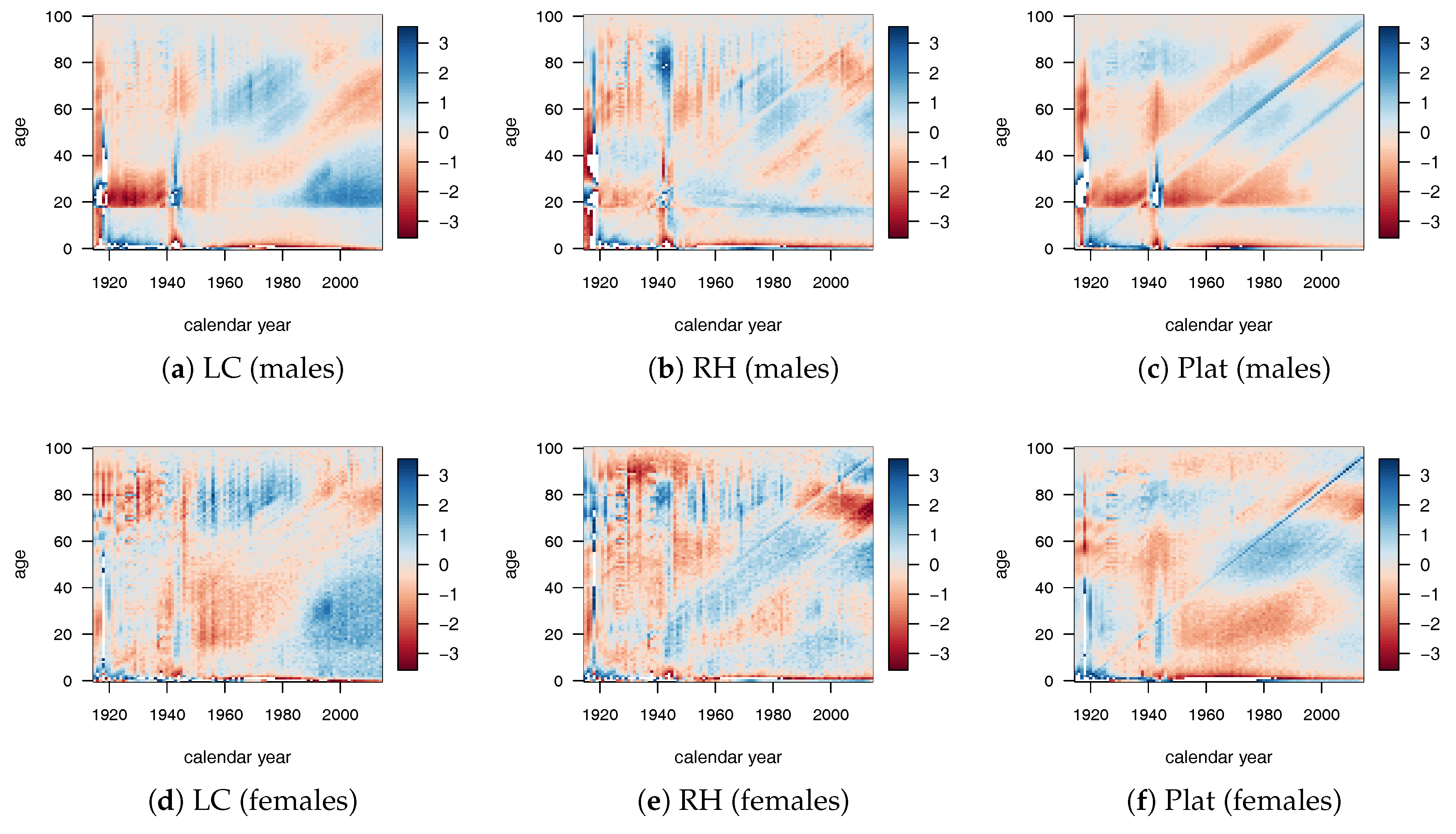
The goodness of fit is also tested by the residuals analysis. From
Figure 1, we can observe that the RH provided the best fit, despite the highest number of parameters. The LC model provided a good fit especially for the old-age population, while the Plat model provided the worst performance despite the high number of parameters involved.
4.2. Model Fitting Improved by Machine Learning
In the following, we specify the parameters used to calibrate the ML algorithms described in
Section 2 using the
rpart,
randomForest, and
gbm packages, respectively:
The level of improvement in central death rates resulting from the application of ML algorithms was measured by
, the relative changes described in Equation (
3).
Numerical results for the LC, RH, and Plat model combined with the tree-based ML algorithms are shown in
Figure 3 for males. Similar results were obtained for females.
The white areas represent very small variations of , approximately around zero. Larger white areas were observed for gradient boosting applied to the LC and RH model. In all cases, there were also significant changes that were less prominent for the RH model that best fit the historical data. Many regions were identified by diagonal splits (highlighting a cohort effect), strengthening our choice to insert the cohort parameter in the decision tree algorithms.
Especially for the LC model, we point out that the relative changes were mainly concentrated in the young ages. For the Plat model, we observed small values of with respect to the other mortality models, with the exception of the population aged under 40 that showed quite significant changes. From these early results, DT and RT seemed to work better than the GB algorithm.
Since the most significant changes were concentrated in the younger ages, we show the mortality rates (in log scale) only for the age group 0–50 (
Figure 4). For the sake of brevity, we show the results for the male population. Similar results were obtained for females and are reported in the
Appendix (see
Figure A1).
From the plots, we can argue that ML estimators led to an improvement in the quality of fit in all the mortality models considered. The plots show that the application of an ML estimator involves significant changes in the values of the mortality rate with a significant improvement in the fitting of the data. Among the stochastic mortality models considered here, the Plat model is the one that achieved the highest fit improvements from the use of ML algorithms.
Further, we measured the goodness of fit of the models with the mean absolute percent error (MAPE), defined as:
where
N is the data dimension and
and
are respectively the actual and estimated values of mortality. The MAPEs are summarized in
Table 3.
The highest MAPE reduction was achieved by the Plat model, with a reduction from to after the application of the RF algorithm (from to for the female population).
In summary, all the ML algorithms improved the standard stochastic mortality models herein considered, and the RF algorithm turned out to be the most effective one.
4.3. LC Model Forecasting Improved by Machine Learning
In this subsection, we describe how the ML estimator, , can be used to obtain an improvement of the mortality forecasting given by the standard stochastic models.
Setting aside the logic of machine learning, our idea was to model and forecast
using the same framework of the original mortality model. The forecasted values of
were then used to improve the forecasted values of mortality rates obtained from the original model. This approach was tested on the LC model; therefore, the ML estimator
is modeled as:
where the sets of parameters
,
, and
have the same meaning of
,
, and
in Equation (
8). Combining Equations (
2), (
8), and (
14), we obtain the following LC model improved by machine learning:
To verify the model accuracy, we provide out-of-sample forecasts, where the fitting period was set to 1915–2000 and the forecasting period to 2001–2014. In the forecasting,
and
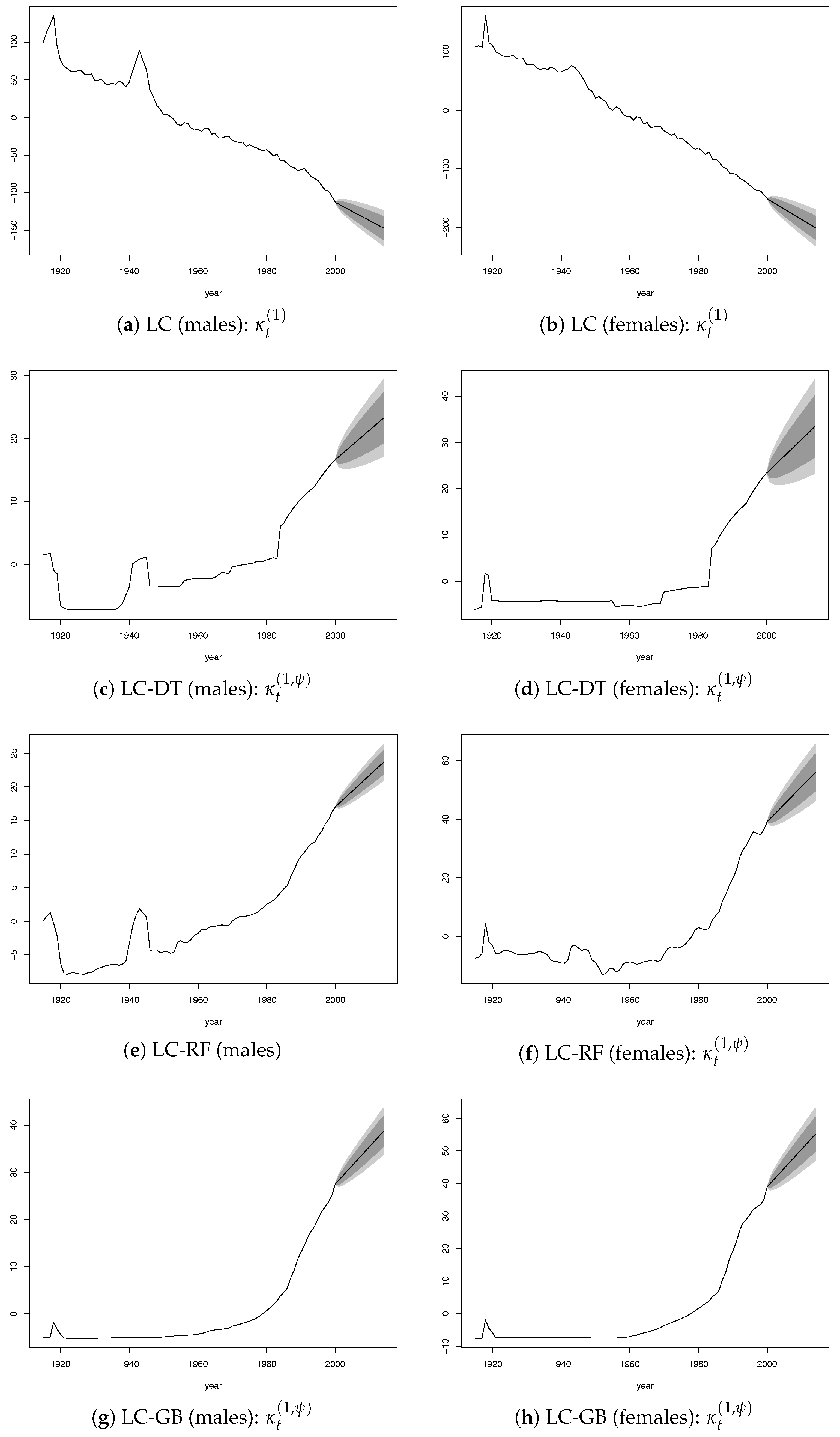
were both modeled by a random walk with drift using values for the past 41 years (1960–2000). The plots of the time-dependent parameters
and
by gender are provided in the
Appendix (
Figure A2).
The values of parameter
of the LC standard model (
Figure A2a,b) have been strongly decreasing from the end of the Second World War, which resulted in a strong reduction of mortality over time, with a further acceleration after the mid-1980s. The ML algorithms reduced this effect through the parameter
,which showed a growing trend after 1960 with greater strength since the 1980s (
Figure A2c–h).
The use of the same framework of the original mortality model to fit and forecast the ML estimators has a dual purpose. On the one hand, it allows improving the forecasting provided by the original model and on the other hand analyzing the effect of the improvement directly on the model’s parameters. As discussed in the Introduction, machine learning is recognized to be very effective at detecting unknown and unidentifiable patterns in the data, but lacks an underlying theory that may be fundamental to provide a rational explanation of the results obtained. From this point of view, our approach can contribute to filling the gap between machine learning and theory combining a data-driven approach with a model-driven one.
Goodness of Forecasting
The forecasting results given by the out-of-sample test were compared using two measures: the root mean squared logarithmic error (RMSLE) and the root mean squared error (RMSE). The first one (RMSLE) takes into account
, providing a relatively large amount of weight to errors at young ages, while the second one (RMSE) is based on
and provides a relatively large amount of weight to errors at older ages.
Table 4 shows the out-of-sample test results for the LC model improved by machine learning when
was forecasted using the LC framework. Values in bold indicate the model with the smaller RMSLE and RMSE. The RF algorithm provided the best performance, except for male RMSE, where GB was the best. The higher reduction of RMSLE was 77% for male and 71% for female, while when considering RMSE, it was 51% for male and 80% for females. However, we can conclude that all the ML estimators produced a significant improvement in forecasting with respect to the standard LC model.
4.4. Results for a Shorter Estimation Period: 1960–2014
We now use a more recent period (starting from 1960 instead of 1915) to analyze the level of the improvement provided by ML algorithms on a smaller dataset. The aim was to check if the change of the calibration period can have an important impact on the results, since the ML algorithms work better with larger datasets. We show in
Table 5 the values of MAPE used to analyze the quality of fitting. Furthermore, for a shorter calibration period, all the ML algorithms improved the standard stochastic mortality models, and the level of the improvement in the model fit remained high. The RF algorithm continued to be the best one.
The values of
for the LC, RH, and Plat model combined with the tree-based ML algorithms for the new calibration period are shown in
Figure 5 for males. Similar results were obtained for females and are reported in the
Appendix (see
Figure A3).
Also in this case, there were significant changes, but there were less regions identified by diagonal splits (highlighting a cohort effect) with respect to the time period 1915–2014. Moreover, we observed that the significant changes were concentrated both in the young and old ages. The concentration in the old ages was less evident in the 1915–2014 analysis.
Out-of-sample tests were performed on the forecasting period 2001–2014, while the fitting period was set to 1960–2000. Also in this case,
and
were both modeled by a random walk with drift using values from 1960–2000. The plots of
and
by gender are provided in the
Appendix (
Figure A4). Different from the results obtained with the dataset for 1915–2000, where
showed a roughly monotone trend since 1960, in the case of a shorter estimation period, this trend oscillated: decreasing until the mid-1980s, increasing until 1997, then decreasing and increasing again for a few years (see
Figure A2c–h and
Figure A4c–h). As a consequence, the values of future
were approximately constant (due to the random walk with drift behavior), while they were increasing in the case of a longer estimation period (1915–2000). We observed that the reduction of mortality over the time period 1960–2000 was less strong than that registered for the years 1915–2000
2, and this fact led to more adequate projections, requiring less adjustments from
.
Goodness of Forecasting
Table 6 shows the out-of-sample test results for the LC model. Values in bold indicate the model with the smaller RMSLE and RMSE. The best performance in terms of RMSLE was given by the RF algorithm, while in terms of RMSE, GB provided smaller values. The higher reduction of RMSLE was 68% for male and 64% for female, while in terms of RMSE, it was 8% for male and 6% for females.
In light of these results, we can state that, also with a smaller dataset, all the ML estimators produced a better quality of forecasting with respect to the standard LC, but the level of the improvement was less satisfactory for the older ages than the one obtained with the larger dataset (1915–2014). The reduction level obtained by RMSE for both genders was significantly lower than that achieved in the case of the 1915–2014 dataset. ML algorithms require large datasets to attain excellent performance, and using a smaller dataset makes the algorithms less effective in detecting unknown patterns, especially at old ages, where there are few observations.












{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}