Direct and Hierarchical Models for Aggregating Spatially Dependent Catastrophe Risks

Abstract
:1. Introduction
2. Copula Trees
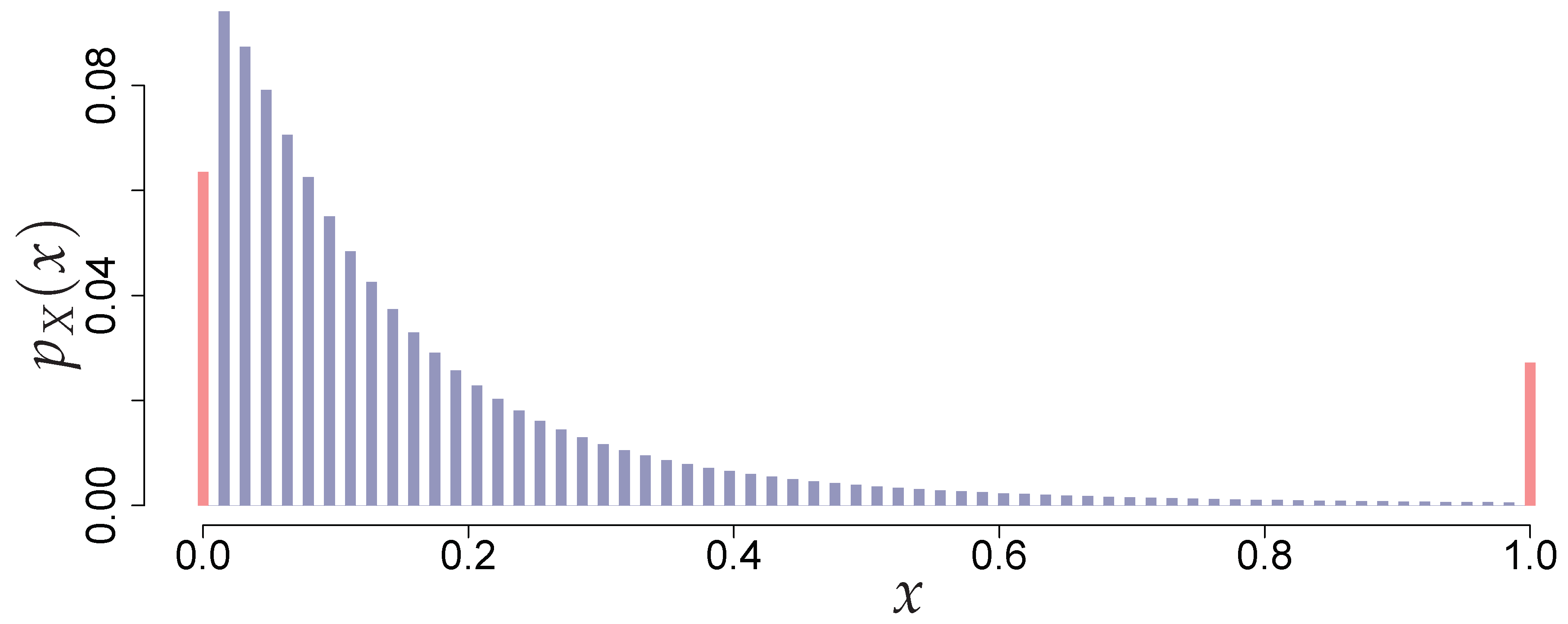
2.1. Problem Statement
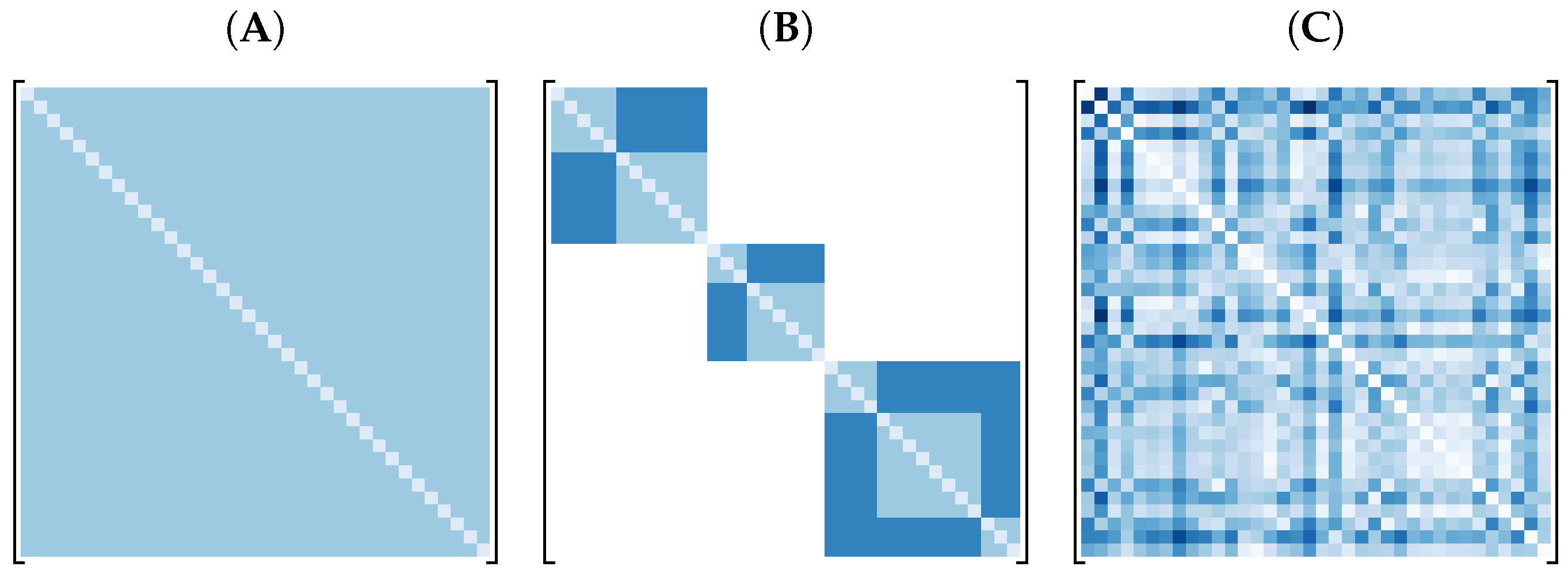
2.2. Direct Model
2.3. Hierarchical Model
2.4. Implementation of Risk Aggregation at Branching Nodes
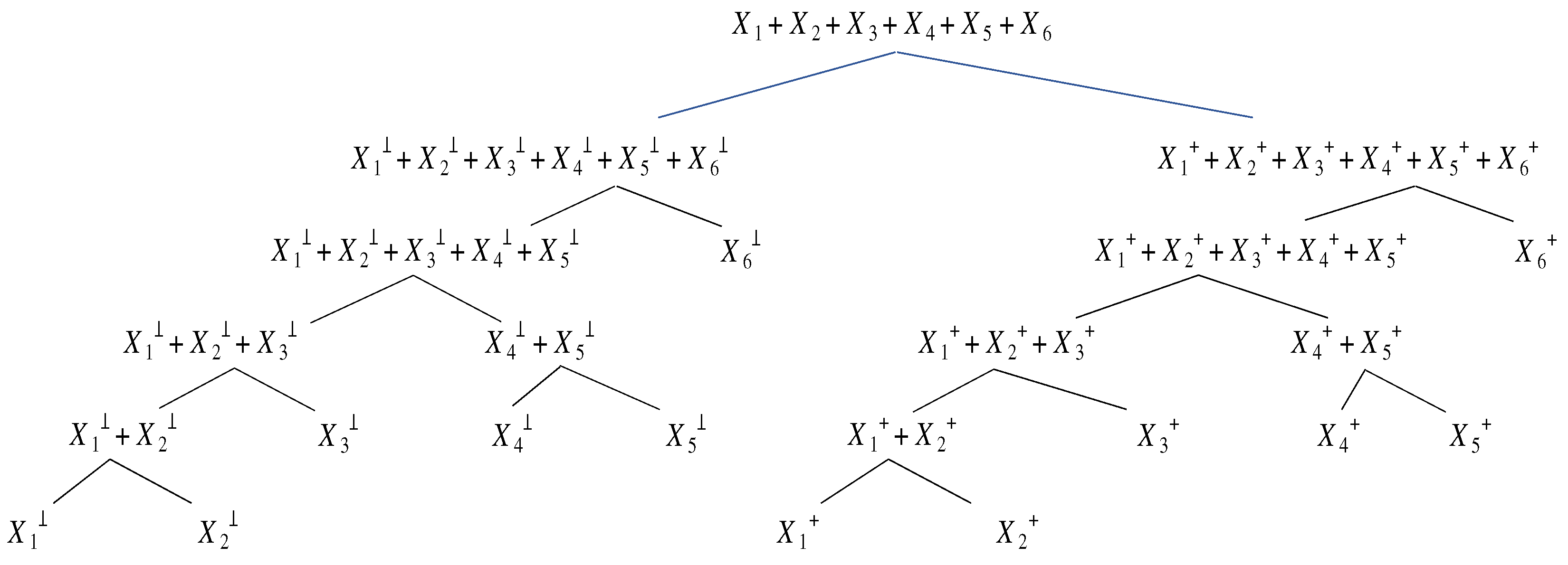
2.4.1. Split-Atom Convolution
| Algorithm 1: Split-Atom Convolution: 9-products |
| Input: Two discrete pdfs and with supports: ; ; and probabilities: ; - maximum number of points for discretizing convolution grid
and the associated probabilities , where , , . |
| Algorithm 2: Brute force convolution for supports with the same span |
| Input: Two discrete probability density functions and , where the supports of X and Y are defined using the same span h as: , and the associated probabilities as ,
and the corresponding probabilities . |
2.4.2. Regriding
| Algorithm 3: Linear regriding |
 |
| Algorithm 4: 4-point regridding, Stage I |
 |
| Algorithm 5: 4-point regridding, Stage II |
 |
2.4.3. Comonotonization and Mixture Approximation
| Algorithm 6: Distribution of the comonotonic sum |
 |
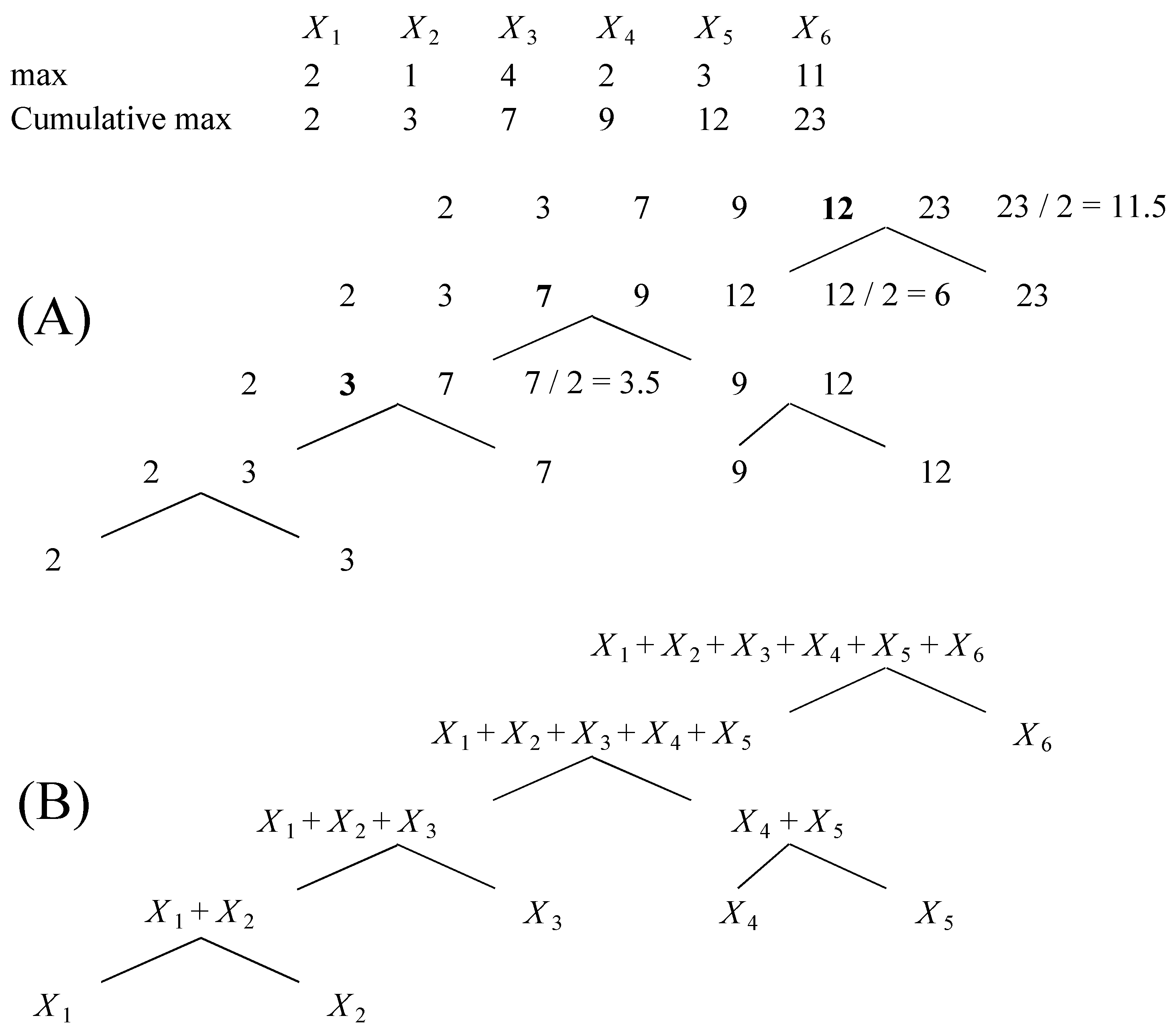
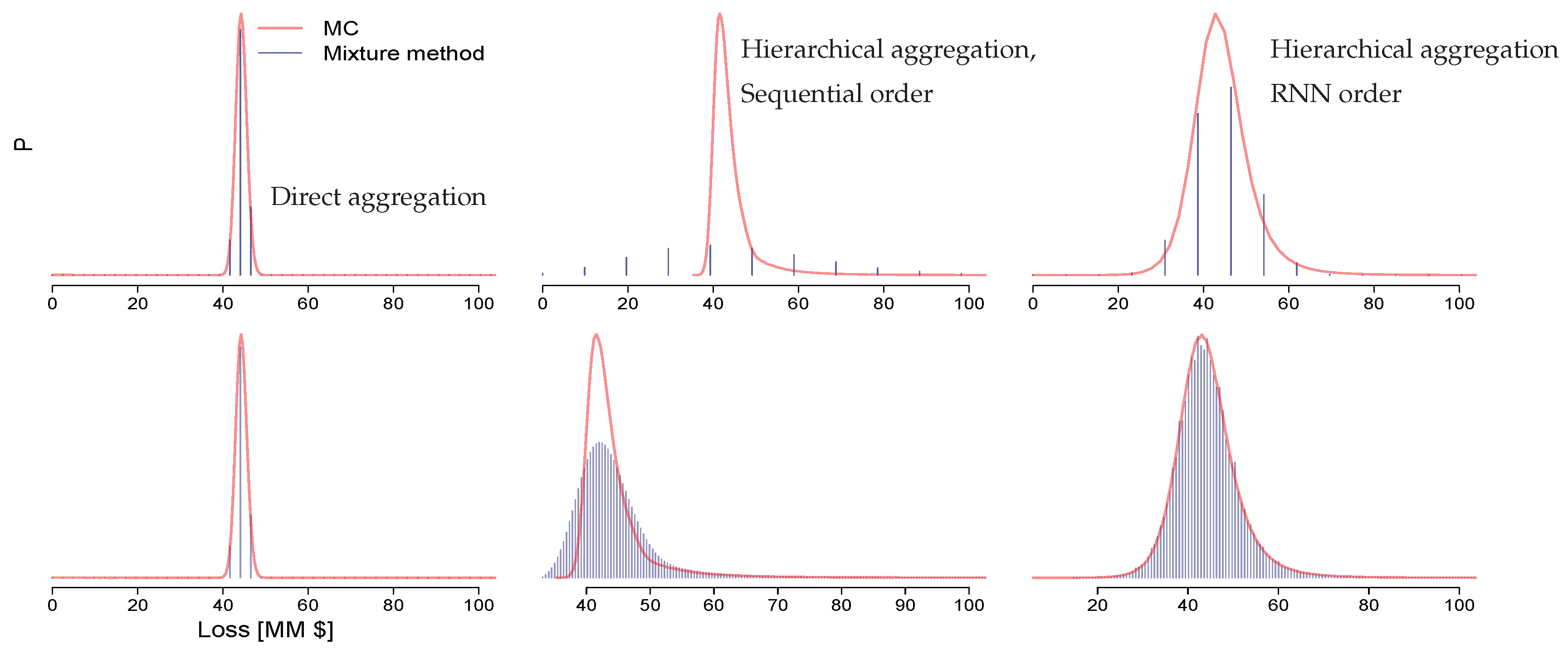
2.5. Order of Convolutions and Tree Topology
3. Results
4. Conclusions
5. Future Research Directions
Author Contributions
Funding
Conflicts of Interest
Appendix A
| Algorithm A1: Split-Atom Convolution: 4-products |
| Input: Two discrete pdfs and with supports: ; ; and probabilities: ; ; - maximum number of points for discretizing convolution grid
and the associated probabilities , where . |
| Algorithm A2: Modified local moment matching |
| Input: Discrete pdf with fine scale support and associated probabilities ; the support of coarse scale probability mass function : . Requirement: , , .
|
Appendix B
References
- AIR-Worldwide. 2015. AIR Hurricane Model for the United States. Available online: https://www.air-worldwide.com/publications/brochures/documents/air-hurricane-model-for-the-united-states-brochure (accessed on 5 May 2019).
- Arbenz, Philipp, Christoph Hummel, and Georg Mainik. 2012. Copula based hierarchical risk aggregation through sample reordering. Insurance: Mathematics and Economics 51: 122–33. [Google Scholar] [CrossRef]
- Artzner, Philippe, Freddy Delbaen, Jean-Marc Eber, and David Heath. 1999. Coherent measures of risk. Mathematical Finance 9: 203–28. [Google Scholar] [CrossRef]
- Chaubey, Yogendra P., Jose Garrido, and Sonia Trudeau. 1998. On the computation of aggregate claims distributions: Some new approximations. Insurance: Mathematics and Economics 23: 215–30. [Google Scholar] [CrossRef]
- Cherubini, Umberto, Elisa Luciano, and Walter Vecchiato. 2004. Copula Methods in Finance. Wiley Finance Series; Chichester: John Wiley and Sons Ltd. [Google Scholar]
- Clark, K. 2015. Catastrophe Risk; International Actuarial Association/Association Actuarielle Internationale. Available online: http://www.actuaries.org/LIBRARY/Papers/RiskBookChapters/IAA_Risk_Book_Iceberg_Cover_and_ToC_5May2016.pdf (accessed on 5 May 2019).
- Cormen, Thomas H., Charles E. Leiserson, Ronald L. Rivest, and Clifford Stein. 2009. Introduction to Algorithms, 3rd ed. Cambridge: MIT Press. [Google Scholar]
- Côté, Marie-Pier, and Christian Genest. 2015. A copula-based risk aggregation model. The Canadian Journal of Statistics 43: 60–81. [Google Scholar] [CrossRef]
- Denuit, Michel, Jan Dhaene, and Carmen Ribas. 2001. Does positive dependence between individual risks increase stop-loss premiums? Insurance: Mathematics and Economics 28: 305–8. [Google Scholar] [CrossRef]
- Dhaene, Jan, Michel Denuit, Marc J. Goovaerts, Rob Kaas, and David Vyncke. 2002. The concept of comonotonicity in actuarial science and finance: Theory. Insurance: Mathematics and Economics 31: 3–33. [Google Scholar] [CrossRef]
- Dhaene, Jan, Daniël Linders, Wim Schoutens, and David Vyncke. 2014. A multivariate dependence measure for aggregating risks. Journal of Computational and Applied Mathematics 263: 78–87. [Google Scholar] [CrossRef]
- Einarsson, Baldvin, Rafał Wójcik, and Jayanta Guin. 2016. Using intraclass correlation coefficients to quantify spatial variability of catastrophe model errors. Paper Presented at the 22nd International Conference on Computational Statistics (COMPSTAT 2016), Oviedo, Spain, August 23–26; Available online: http://www.compstat2016.org/docs/COMPSTAT2016_proceedings.pdf (accessed on 5 May 2019).
- Evans, Diane L., and Lawrence M. Leemis. 2004. Algorithms for computing the distributions of sums of discrete random variables. Mathematical and Computer Modelling 40: 1429–52. [Google Scholar] [CrossRef]
- Galsserman, Paul. 2004. Monte Carlo Methods in Financial Engineering. New York: Springer. [Google Scholar]
- Gerber, Hans U. 1982. On the numerical evaluation of the distribution of aggregate claims and its stop-loss premiums. Insurance: Mathematics and Economics 1: 13–18. [Google Scholar] [CrossRef]
- Grossi, Patricia, Howard Kunreuther, and Don Windeler. 2005. An introduction to catastrophe models and insurance. In Catastrophe Modeling: A New Approach to Managing Risk. Edited by Patricia Grossi and Howard Kunreuther. Huebner International Series on Risk. Insurance and Economic Security. Boston: Springer Science+Business Media. [Google Scholar]
- Hennessy, John L., and David A. Patterson. 2007. Computer Architecture: A Quantitative Approach, 4th ed. San Francisco: Morgan Kaufmann. [Google Scholar]
- Hürlimann, Werner. 2001. Analytical evaluation of economic risk capital for portfolios of gamma risks. ASTIN Bulletin 31: 107–22. [Google Scholar] [CrossRef]
- Iman, Ronald L., and William-Jay Conover. 1982. A distribution-free approach to inducing rank order correlation among input variables. Communications in Statistics-Simulation and Computation 11: 311–34. [Google Scholar] [CrossRef]
- Koch, Inge, and Ann De Schepper. 2006. The Comonotonicity Coefficient: A New Measure of Positive Dependence in a Multivariate Setting. Available online: https://ideas.repec.org/p/ant/wpaper/2006030.html (accessed on 5 May 2019).
- Koch, Inge, and Ann De Schepper. 2011. Measuring comonotonicity in m-dimensional vectors. ASTIN Bulletin 41: 191–213. [Google Scholar]
- Latchman, Shane. 2010. Quantifying the Risk of Natural Catastrophes. Available online: http://understandinguncertainty.org/node/622 (accessed on 5 May 2019).
- Lee, Woojoo, and Jae Youn Ahn. 2014. On the multidimensional extension of countermonotonicity and its applications. Insurance: Mathematics and Economics 56: 68–79. [Google Scholar] [CrossRef]
- Lee, Woojoo, Ka Chun Cheung, and Jae Youn Ahn. 2017. Multivariate countermonotonicity and the minimal copulas. Journal of Computational and Applied Mathematics 317: 589–602. [Google Scholar] [CrossRef]
- McKay, Michael D., Richard J. Beckman, and William J. Conover. 1979. A comparison of three methods for selecting values of input variables in the analysis of output from a computer code. Technometrics 21: 239–45. [Google Scholar]
- McNeil, Alexander J., and Johanna Nešlehová. 2009. Multivariate Archimedean copulas, d-monotone functions and l1–norm symmetric distributions. The Annals of Statistics 37: 3059–97. [Google Scholar] [CrossRef]
- Nelsen, Roger B. 2006. An Introduction to Copulas. Springer Series in Statistics; New York: Springer. [Google Scholar]
- Panjer, Harry H., and B. W. Lutek. 1983. Practical aspects of stop-loss calculations. Insurance: Mathematics and Economics 2: 159–77. [Google Scholar] [CrossRef]
- Robertson, John. 1992. The computation of aggregate loss distributions. Proceedings of the Casualty Actuarial Society 79: 57–133. [Google Scholar]
- Shevchenko, Pavel V. 2010. Calculation of aggregate loss distributions. The Journal of Operational Risk 5: 3–40. [Google Scholar] [CrossRef]
- Venter, Gary G. 2001. D.e. Papush and g.s. Patrik and f. Podgaits. CAS Forum. Available online: http://www.casact.org/pubs/forum/01wforum/01wf175.pdf (accessed on 5 May 2019).
- Venter, Gary G. 2013. Effects of Parameters of Transformed Beta Distributions. CAS Forum. Available online: https://www.casact.org/pubs/forum/03wforum/03wf629c.pdf (accessed on 5 May 2019).
- Vilar, José L. 2000. Arithmetization of distributions and linear goal programming. Insurance: Mathematics and Economics 27: 113–22. [Google Scholar] [CrossRef]
- Walhin, J. F., and J. Paris. 1998. On the use of equispaced discrete distributions. ASTIN Bulletin 28: 241–55. [Google Scholar] [CrossRef]
- Wang, Shaun. 1998. Aggregation of correlated risk portfolios: Models and algorithms. Proceedings of the Casualty Actuarial Society 85: 848–939. [Google Scholar]
- Wojcik, Rafał, Charlie Wusuo Liu, and Jayanta Guin. 2016. Split-Atom convolution for probabilistic aggregation of catastrophe losses. In Proceedings of 51st Actuarial Research Conference (ARCH 2017.1). SOA Education and Research Section. Available online: https://www.soa.org/research/arch/2017/arch-2017-iss1-guin-liu-wojcik.pdf (accessed on 5 May 2019).
- Zhang, Jilian, Kyriakos Mouratidis, and HweeHwa Pang. 2011. Heuristic algorithms for balanced multi-way number partitioning. Paper Presented at the International Joint Conference on Artificial Intelligence (IJCAI), Barcelona, Spain, July 16–22; Research Collection School Of Information Systems. Menlo Park: AAAI Press, pp. 693–98. [Google Scholar]








{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| MC | Linear Regriding No Truncation | Linear Regriding Tail Truncation | 4-Point Regridding | ||
|---|---|---|---|---|---|
| (A) | 44.3 | 44.3 (0.00%) | 44.3 (0.00%) | 44.3 (0.00%) | |
| 7.1 | 10.9 (53.02%) | 7.1 (0.00%) | 7.1 (0.00%) | ||
| TVaR1% | 51.4 | 2550.9 (4864.2%) | 2550.8 (4864.0%) | 2550.8 (4863.9%) | |
| TVaR5% | 48.5 | 502.1 (934.7%) | 501.4 (932.8%) | 501.9 (933.8%) | |
| TVaR10% | 47.6 | 252.0 (429.7%) | 250.7 (427.1%) | 251.0 (427.6%) | |
| (B) | 44.3 | 44.3 (0.00%) | 44.3 (0.00%) | 44.3 (0.00%) | |
| 7.1 | 7.6 (6.11%) | 7.1 (0.00%) | 7.1 (0.00%) | ||
| TVaR1% | 93.7 | 81.2 (−13.3%) | 84.7 (−9.6%) | 88.0 (−6.1%) | |
| TVaR5% | 66.3 | 62.5 (−5.8%) | 68.5 (3.4%) | 66.8 (0.8%) | |
| TVaR10% | 58.6 | 67.3 (15.0%) | 60.5 (3.3%) | 59.8 (2.1%) | |
| (C) | 44.3 | 44.3 (0.00%) | 44.3 (0.00%) | 44.3 (0.00%) | |
| 7.1 | 7.2 (1.55%) | 7.1 (0.00%) | 7.1 (0.00%) | ||
| TVaR1% | 75.9 | 151.0 (98.9%) | 95.0 (25.2%) | 76.0 (0.1%) | |
| TVaR5% | 62.9 | 184.4 (193.4%) | 98.0 (55.8%) | 63.5 (0.9%) | |
| TVaR10% | 58.4 | 95.8 (63.9%) | 87.0 (48.9%) | 59.1 (1.1%) |
| Aggregation Model | MC | Linear Regridding No Truncation | Linear Regriding Tail Truncation | 4-Point Regriding |
|---|---|---|---|---|
| Direct | 1539 | 0.25 | 0.26 | 0.33 |
| Hierarchical, sequential | 12,769 | 0.34 | 0.35 | 0.44 |
| Hierarchical, RNN | 10,512 | 0.40 | 0.41 | 0.52 |
© 2019 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (http://creativecommons.org/licenses/by/4.0/).
Share and Cite
Wójcik, R.; Liu, C.W.; Guin, J. Direct and Hierarchical Models for Aggregating Spatially Dependent Catastrophe Risks. Risks 2019, 7, 54. https://doi.org/10.3390/risks7020054
Wójcik R, Liu CW, Guin J. Direct and Hierarchical Models for Aggregating Spatially Dependent Catastrophe Risks. Risks. 2019; 7(2):54. https://doi.org/10.3390/risks7020054
Chicago/Turabian StyleWójcik, Rafał, Charlie Wusuo Liu, and Jayanta Guin. 2019. "Direct and Hierarchical Models for Aggregating Spatially Dependent Catastrophe Risks" Risks 7, no. 2: 54. https://doi.org/10.3390/risks7020054
APA StyleWójcik, R., Liu, C. W., & Guin, J. (2019). Direct and Hierarchical Models for Aggregating Spatially Dependent Catastrophe Risks. Risks, 7(2), 54. https://doi.org/10.3390/risks7020054