Abstract
In this paper, we focus on a new generalization of multivariate general compound Hawkes process (MGCHP), which we referred to as the multivariate general compound point process (MGCPP). Namely, we applied a multivariate point process to model the order flow instead of the Hawkes process. The law of large numbers (LLN) and two functional central limit theorems (FCLTs) for the MGCPP were proved in this work. Applications of the MGCPP in the limit order market were also considered. We provided numerical simulations and comparisons for the MGCPP and MGCHP by applying Google, Apple, Microsoft, Amazon, and Intel trading data.
1. Introduction
In this paper, we introduced a new class of stochastic models, which can be considered as a generalization of the multivariate general compound Hawkes process (MGCHP) in Guo and Swishchuk (2020). We called this model the multivariate general compound point processes (MGCPP). A Law of Large Numbers (LLN) and two Functional Central Limit Theorems (FCLT) for MGCPP were proved. FCLTs of the MGCPP can be viewed as a link between price volatility and the order flow. Thus, we applied this asymptotic method to study the mid-price modeling in the limit order book (LOB).
Hawkes process was applied to financial modelling for the first time in 2007 Bowsher (2007). Bacry et al. (2013) proved a LLN and FCLT for multivariate Hawkes process and applied them to study some economic phenomenons in 2013. Volatilities between five stocks were estimated by a 5-dimensional Hawkes process in Bauwens and Hautsch (2009) in 2009. Other types of Hawkes processes have been studied widely as well. The nonlinear Hawkes process was considered by Brémaud and Massoulié (1996) and the corresponding FCLT was proved in Zhu (2013). Some applications of multivariate Hawkes process to financial data are given in Embrechts et al. (2011). The regime-switching Hawkes process was considered by Vinkovskaya (2014) to describe the dynamics dependency on the bid–ask spread in limit order book. In Swishchuk and Vadori (2017), a semi-Markov process based on a renewal process was applied to the mid-price modeling in LOB. Swishchuk et al. (2017) also considered the general case of the semi-Markovian models in 2017. A good textbook for algorithmic and High-Frequency trading methods was written by Cartea et al. (2015) in 2015. Zheng et al. (2014) introduced a multivariate point process describing the dynamics of the Bid and Ask price of a financial asset. The point process is similar to a Hawkes process, with additional constraints on its intensity corresponding to the natural ordering of the best Bid and Ask prices. Chen et al. (2019) developed a new approach for investigating the properties of the Hawkes process without the restriction to mutual excitation or linear link functions. They employed a thinning process representation and a coupling construction to bound the dependence coefficient of the Hawkes process. Using recent developments on weakly dependent sequences, a concentration inequality for second-order statistics of the Hawkes process was established. This concentration inequality was applied to cross-covariance analysis in the high-dimensional regime, and it was verified the theoretical claims with simulation studies. A framework for fitting multivariate Hawkes process for large-scale problems (long history and a wide variety of events) was proposed by Lemonnier et al. (2017). Liniger thesis addresses theoretical and practical questions arising in connection with multivariate, marked, linear Hawkes process Liniger (2009). Yang et al. (2017) developed a nonparametric and online learning algorithm that estimates the triggering functions of a multivariate Hawkes process. An introduction to point processes from a martingale point of view may be found in Bjork’s lecture notes Bjork (2011).
Guo and Swishchuk (2020) constructed a multivariate general compound Hawkes process (MGCHP) which is an extended model from Cont and De Larrard (2013) and Swishchuk (2017). In Guo and Swishchuk (2020), they applied the multivariate Hawkes process to model the order flow of several stocks in limit order market and proved limit theorems for the MGCHP. In this paper, we proposed a new mid-price model which is a generalization of the MGCHP and we called it the multivariate general compound point process (MGCPP). For the MGCPP, we applied a multi-dimensional simple point process to represent the order flow in LOB instead of the Hawkes process. We also proved the corresponding LLN and FCLTs for the MGCPP. One of the reasons why we considered the generalized model is parameters for simple point process are much easier to estimate than Hawkes process. So, we provided the numerical comparisons of the MGCPP and MGCHP by real high-frequency trading data and we found that results of the new generalized model are as good as the MGCHP.
This paper is organized as follows. Definitions and assumptions of the multivariate general compound point process (MGCPP) can be found in Section 2. Functional central limit theorem (FCLT) I and law of large numbers were proved in Section 3. We also provided numerical examples simulated by real data for the FCLT I in Section 3. In Section 4, we considered a FCLT II for the MGCPP and applied it in the mid-price prediction. Section 5 concludes the paper.
2. Definition of Multivariate General Compound Point Process (MGCPP)
In this Section, we proposed a multivariate stochastic model for the mid-price in the limit order book. This is a generalization for models in Cont and De Larrard (2013), Guo and Swishchuk (2020), and Swishchuk (2017). Here, we assume the order flow was described by a multivariate simple point process with some good asymptotic properties.
Definition 1
((Counting Process). (see, e.g., Bjork (2011))). We called a stochastic process counting process if it satisfies: the trajectories of are right continues and piecewise constant with probability one, , and or 1 with probability one.
Counting process is the simplest type of point process. In the following discussion of paper, we adopt Definition 1 as the definition of a point process. The point process can be determined by the conditional intensity function λ(t) in the form of
where λ(t) ≥ 0 and is the corresponding natural filtration.
2.1. Assumptions for Multivariate Point Processes
Let be d-dimensional point process with following assumptions:
Assumption 1.
We assume there’s a law of large numbers (LLN) of the in the form of:
as almost surely, where .
Assumption 2.
We also assume there’s a Functional Central Limit Theorem (FCLT) of the in the form of:
in law of the Skorohod topology, where is a standard d-dimensional Brownian motion and Σ is a d-by-d covariance matrix.
Here, denotes the order flow in the limit order market for d stocks. Liquidity for the high-frequency trading data guarantees there are enough price changes in one day or even a small window size . So, it is reasonable to consider those two limit assumptions in the limit order book modeling.
Remark 1.
For a simple example, if we consider the point process as a multivariate homogeneous Poisson process with independent coordinates, then two assumptions above are LLN and FCLT for the multi-dimensional Poisson process. Let be a d-dimensional Poisson process with intensity . Here, we used notation to distinguish the general case and the Poisson example. Then, we have the LLN in the form of
as almost surely. Further, the FCLT in the form of
converge in law for the Skorokhod topology to as , where ∘ is the element-wise product.
Remark 2.
Another interesting example is limit theorems for the multivariate Hawkes process (MHP) in Bacry et al. (2013). Let be a d-dimensional Hawkes process. The intensity function for each Hi is in the form of
Let , , and , then the LLN for MHP is in the form of
as almost surely, where is a d-by-d identity matrix. We can also have the FCLT for MHP:
in law of the Skorohod topology, where is a standard d-dimensional Brownian motion and is a diagonal matrix determined by . Details about the LLN and FCLT of MHP can be found in Bacry et al. (2013).
2.2. Definition for MGCPP
Next, we consider a price process in the form as:
where are independent ergodic continuous-time Markov chains, independent of . The state space of is denoted by . are bounded continuous functions. We refer as multivariate general compound point processes (MGCPP).
Remark 3.
If we consider the one-dimensional case, let be a Poisson process, , and is a sequence of independent random variables such that , then is a stochastic model for the dynamics of a limit order book discussed in Cont and De Larrard (2013).
Remark 4.
When is a multivariate Hawkes process in Remark 2, then is a multivariate general compound Hawkes processes (MGCHP) which proposed in Guo and Swishchuk (2020).
3. LLNs and Diffusion Limits for MGCPP
In this Section, we considered the diffusion limit theorems for the MGCPP. It provides us a link between the order flow and the price process . The functional central limit theorem (FCLT) and law of large numbers (LLN) for the MGCPP are generalizations for the diffusion limit theorems of the MGCHP in Guo and Swishchuk (2020).
3.1. LLN for MGCPP
Theorem 1
(LLN for MGCPP). Let be a d-dimensional MGCPP defined before, we have
as almost surely.
Proof of Theorem 1.
From the definition of MGCPP in Equation (7), we have
Since is a constant, we have
Recall the strong LLN of Markov chain (see, e.g., Norris (1998)), we have
where is defined by . Consider the LLN of MPP in Assumption 1, we have
as almost surely, we obtain
Rewrite (9) in the multivariate case, we derive the LLN for the MGCPP. ☐
3.2. Diffusion Limits for MGCPP: Stochastic Centralization
Theorem 2
(FCLT I: Stochastic Centralization). Let be independent ergodic Markov chains defined before. is the state space and the ergodic probabilities is given by . We assume is independent of . Let be d-dimensional MGCPP, we have
where is a standard d-dimensional Brownian motion. Λ is a d-by-d diagonal matrix in the form of . , and are given by
Here, , and with
where is the transition probability matrix for , is the matrix of stationary distributions of , and is the jth entry of .
Proof of Theorem 2.
From the definition of MGCPP, we have
and
here the is defined by . Then, for some n, we have
Since is a constant, when , we have
Consider the following sums:
and
where is the floor function. By applying the martingale method in Swishchuk and Vadori (2017) and Vadori and Swishchuk (2015), we have
converge weakly in Skorokhod topology. From the assumption (1), we have the LLN for the MPP in the form of
Using change of time in (15) and let , we have
Rewrite (16) in the multivariate form we derive the weak convergence for MGCPP:
☐
Next, we considered a simple special case of the MGCPP. Let be a Markov chain with two dependent states and the ergodic probabilities . In the limit order market, the is the fixed tick size and the d-dimensional point process represents the order flow for d stocks. Here, we set in Equation (7). Then, we can derive the corresponding limit theorems for this kind of special case.
Corollary 1
(FCLT I two-state MGCPP: Stochastic Centralization).
and are given by
where , and
are transition probabilities of the Markov chain .
Corollary 2
(LLN for two-state MGCPP). Let be d-dimensional general compound point process with two-state Markov chain , we have
Here, and are constants defined in Corollary 1.
Proof of Corollarys 1 and 2.
Set Markov chain with two states and in Theorem 2 and Theorem 1, we can derive Corollarys 1 and 2 directly. ☐
Remark 5.
From the FCLT I of MGCPP, we can derive an approximation for the mid-price :
for all and some lagre enough n. Since is the price process in high-frequency trading, the time is always measured in a very short period (e.g., milliseconds). So, even if the window size s with , the n will equal to 10,000 which is a very large number. In this way, it is reasonable to consider this kind of approximation in the LOB.
Remark 6.
When is a multivariate Hawkes process in Remark 2, then the is a MGCHP model, corresponding FCLTs and LLNs were considered in Guo and Swishchuk (2020). To distinguish with the general case, we also applied the to denote the multivariate Hawkes process and to denote the price process by MGCHP. Then we have the FCLT for MGCHP in the form of
where is a multivariate standard Brownian motion and is defined in Remark 2. We can find clearly that the limit theorem for MGCPP is a generalization of the Hawkes case. Also, when we consider an one-dimensional case, if is a renewal process, the corresponding limit theorems for the semi-Markovian model were discussed in Swishchuk and Vadori (2017) and Swishchuk et al. (2017).
3.3. Numerical Examples for FCLT: Stochastic Centralization
In this Section, we tested the FCLT I of MGCPP model with the LOBSTER data and compared our results with the simulation results by MGCHP in Guo and Swishchuk (2020). In their paper, they applied two stocks in the LOBSTER data set, namely the mid-price of Microsoft and Intel. As for the Markov chain part, they used the two-state Markov chain ().
In order to make our results comparable with the MGCHP, we first applied the same data set (Microsoft and Intel) and same two-state Markov chain () for the MGCPP model. Next, we explore more simulation examples (by Apple, Amazon, and Google data) which were mentioned in Guo and Swishchuk (2020). For those three stocks, we applied the MGCPP model with both two-state Markov chain and -state Markov chain.
3.3.1. Data Description and Parameter Estimations
The level one LOBSTER data was considered in this paper. The LOBSTER data set contained the stock prices and order flows of Apple, Amazon, Google, Microsoft, and Intel on 21 June 2012. The tick size is one cent () and time was measured in milliseconds (0.001 s). We can find the basic data description and check the liquidity from Table 1. Notation # is the number sign.

Table 1.
Data description and stock liquidity of Apple, Amazon, Google, Microsoft, and Intel.
Next, we estimate via the LLN assumption of . From Assumption 1, when n is large enough, we can derive the approximation:
Take the expectation for (21), we have
In this way, we derived the estimated parameters for 5 stocks in Table 2.
Table 2.
Estimated parameters of 5 stocks via the law of large numbers (LLN) and functional central limit theorem (FCLT) assumptions.
In the definition of the MGCPP, we assumed Markov chains are independent. So, we checked correlations of the price increments between 5 stocks in Table 3. As can be seen in Table 3, correlations are relatively weak (around 0.3). So, it is reasonable to consider Markov chains here are independent. In the future work, we will discuss the dependent case for different data sets.
Table 3.
Correlations of price increments between 5 stocks. We set the time step as 10 s.
Next, we estimated parameters for the Markov chain by applying the two-state MGCPP model in Corollary 1. The transition matrix P of two dependent state Markov chain is denoted as
We calculated frequency in our data to estimate the and in P by
where , , , and are the number of price goes up twice, goes down twice, goes up and then down, goes down and then up, respectively. The result is in Table 4:
Table 4.
Transition matrix and constant parameters for two-state MGCPP. and were calculated by Equation (19).
3.3.2. Comparison with MGCHP with Two Dependent Orders
In this Section, we compared the simulation results of MGCPP with the multivariate general compound Hawkes process (MGCHP) model to show that the simple generalized model can also reach a good accuracy as the MGCHP who has a sophisticated intensity function (see Equation (5)). In Guo and Swishchuk (2020), they simulated the MGCHP with two dependent states for Microsoft and Intel’s data. So here we also conduct simulations for Microsoft and Intel’s data with the two-state MGCPP.
We tested the MGCPP model by comparing the standard deviation for the left hand side and right hand side in the FCLT:
We separated the data set into disjoint windows . Since the time was measured in milliseconds, we set . Then we can calculate:
and the standard deviation is in the form of
Figure 1 gives a standard deviation comparison of MGCPP, MGCHP, and the raw data for 2 stocks in different window sizes from 0.1 s to 12 s in steps of 0.1 s. First, we could find the MGCPP parameters make the standard deviation of LHS very similar to the RHS for each stocks when n is large. So, generally speaking, we can say our MGCPP model fits the data well. Second, the MGCPP curve is very close to the MGCHP curve or we could say the simulation results via Intel and Microsoft stocks data are nearly same. It shows that even we do not have a sophisticated intensity function as the Hawkes process, we still can reach a relative good result with a simple point process model. This can help us deal with the computing efficiency problem when using the MGCHP model. We’ll give more quantitative error analysis later.
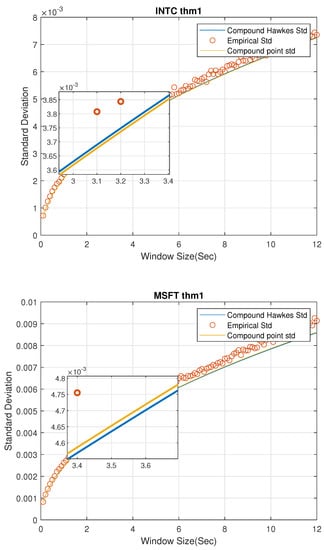
Figure 1.
Standard deviation comparisons for 2 stocks by FCLT I for multivariate general compound point process (MGCPP) and multivariate general compound Hawkes process (MGCHP).
Remark 7.
Since the number of windows decreases as the window size nt increases, we can find that the spread of data increases when the window size increases in Figure 1. For example, when we consider nt = 0.1 s, the number of windows is 234,000. However, a 12-s window size yields 1950 windows which will lead the standard deviation increases.
Intuitively, Figure 1 shows that the standard deviation of MGCHP and MGCPP are very close and both of them fit the real standard deviation very well. Next, we analyze MGCHP and MGCPP models quantitatively.
We computed the mean square error (MSE) of the real standard deviation and theoretical standard deviations in Table 5. As can be seen from Table 5, MGCHP model performs better than the MGCPP model with both Intel and Microsoft data. For Intel stock data, the MSE of MGCHP is 17% better than MGCPP and nearly 10% better than MGCPP model with the Microsoft stock data. However, when we compare the order of magnitude of the MSE (−8) with the real standard deviation (−2 and −3), we still can conclude that MGCPP is good enough for the mid-price modeling task.
Table 5.
The mean square error (MSE) of the real standard deviation and theoretical standard deviations from MGCHP and MGCPP.
Recall Equation (23), we can find the standard deviation and the square root of time step have a linear relationship. So, we can fit the real standard deviation data with the square root curve by using the least-square regression. Then, we can set the regression curve as a benchmark and compare the benchmark coefficients with two stochastic models.
From Table 6, we can find that the percentage error of both two stochastic models are all smaller than 5% and there is no significant difference between the MGCPP coefficient and the MGCHP coefficient.
Table 6.
Coefficients calculated by MGCHP and MGCPP models. Benchmark coefficients are coefficients of the least-square regression curves. Percentage errors are differences between two stochastic models with the benchmark.
Based on the previous analysis, we can conclude that the empirical results of MGCHP and MGCPP are very close and all of them have a very good performance in the mid-price modeling. However, as for the MGCHP, we need to estimate many parameters. As the Guo and Swishchuk (2020) mentioned, if we consider a two-dimensional MGCHP (two stocks), we have to estimate 5 parameters for the Hawkes process part and the number of parameters increases dramatically to 55 when we consider a 5-dimensional case (5 stocks). The parameter estimation procedure is also quite time consuming for the MGCHP because of the complicated likelihood function of multivariate Hawkes process. For example, it takes a dozen hours to estimate parameters for a 3-dimensional Hawkes process (21 parameters) with LOBSTER data set by using the maximum likelihood estimation (MLE) and the particle swarm optimization (PSO) method in Guo and Swishchuk (2020). On the contrary, the number of parameters for MGCPP is much smaller than the MGCHP. In the two-dimensional case, we have 2 parameters to be estimated in the simple point process part and this increases to 5 parameters in the 5-dimensional case, which is much smaller than 55. The parameter estimation procedure is also quite simple and fast (in several seconds with the same data set) because we do not have to deal with the likelihood function. In this way, from the numerical perspective, the generalized model MGCPP is better than the MGCHP because of the fast and simple estimation procedure.
Remark 8.
Note that the numbers of parameters we mentioned before are all parameters of the order flow . Parameters of Markov chains for MGCHP and MGCPP are same.
In general, we showed that the results of the new generalized model are as good as the MGCHP and this kind of generalization has better numerical properties. In the following parts, we will explore the MGCPP model more.
3.3.3. MGCPP with -State Dependent Orders
We give more simulation examples by using the Google, Apple, and Amazon data with the MGCPP model with -state dependent orders in this section. Thanks to Swishchuk and Huffman (2020), we can conclude that the accuracy of the general compound Hawkes process model increases when the number of states increases. For Google, Apple, and Amazon in the LOBSTER data set, the best number of states is 4 to 7. In the previous section, we also showed that simulation results of MGCPP are nearly same as the MGCHP. So, it is reasonable to consider a MGCPP model with 7-state Markov chain here.
We applied the method in Swishchuk and Huffman (2020) to calculate the state values for each stock. First, we compute the changes of mid-price and separate the data into two sets by positive increments or negative increments. Next, we calculate the quantiles for both data sets and split the data set according to the quantiles. If there are identical quantiles, we merge them into one. Then, we set the state values as the average of mid-price changes located in each quantile (or merged quantile).
Figure 2, Figure 3 and Figure 4 give standard deviation comparisons for MGCPP with 2-state Markov chain and 7-state Markov chain simulated by different tickers’ data. Since the 2-state simulation results here are not as good as the results simulated by Intel’s and Microsoft’s data, we take bigger time steps and window sizes (from 10 s to 20 min with 10 s time step) to capture more dynamics. From figures we can find that the 7-state model has a significant improvement than the 2-state model. Seven-state curves for AAPL and GOOG are very close to the real standard deviation, although the theoretical curve of AMZN is underestimated even with the 7-state model.
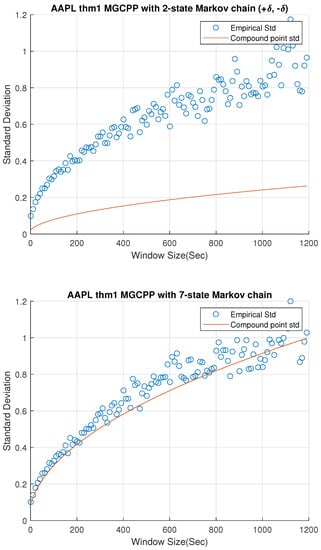
Figure 2.
Standard deviation comparisons for MGCPP with 2-state Markov chain and 7-state Markov chain simulated by Apple’s stock data.
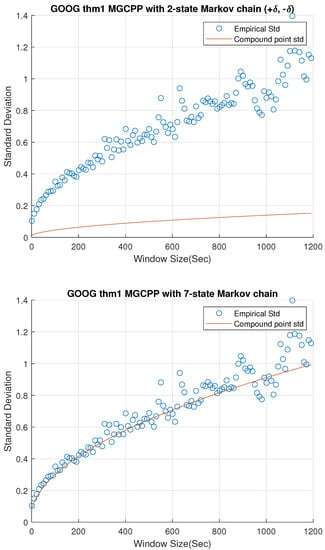
Figure 3.
Standard deviation comparisons for MGCPP with 2-state Markov chain and 7-state Markov chain simulated by Google’s stock data.
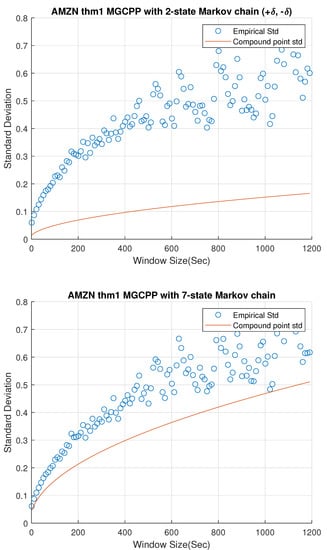
Figure 4.
Standard deviation comparisons for MGCPP with 2-state Markov chain and 7-state Markov chain simulated by Amazon’s stock data.
Table 7 lists the MSE and coefficients of the 2-state and 7-state models with different tickers. We can find the improvement of 7-state model quantitatively from the table. The results of AAPL and GOOG are good enough for the mid-price modeling. As for AMZN, although we derive a remarkable improvement from 2-state model (74.60% error) to 7-state model (28.29% error), we cannot make the error smaller than 5% or 10%. This is to say, MGCPP model may not be able to capture the full dynamics for AMZN data, but it still can be a strong candidate for modeling the mid-price, which is consistent with the conclusion of compound Hawkes model in Swishchuk and Huffman (2020).
Table 7.
The MSE and coefficients computed by MGCPP with 2-state and 7-state Markov chain for different tickers. The regression coefficients were derived by fitting the real standard deviations with square root curve. The MGCPP coefficients were computed by Equation (23).
Remark 9.
The MGCPP is not only a generalization of MGCHP, but also a generalization for all multivariate compound models whose point processes satisfy the Assumptions 1 and 2. The reason we use Hawkes process for comparison is we want to take the advantage of numerical examples in references.
4. Diffusion Limit for the MGCPP: Deterministic Centralization
We proved a LLN and FCLT for the MGCPP in the previous section. Limit theorems provide us an approximation for the mid-price modeling in the LOB. Recall the approximation in Remark 5, we have
where the is the price process and is the order flow. However, in the real-world problems, Equation (24) cannot help us with the forecasting task directly because we cannot observe the future order flow in advance. This is the motivation for us to consider a FCLT II for the MGCPP model.
4.1. FCLT for MGCPP: Deterministic Centralization
Theorem 3.
(FCLT II: Deterministic Centralization). Let be independent ergodic Markov chains defined before. is the state space and the ergodic probabilities is given by . Assume is independent of . Let be d-dimensional MGCPP, we have
where and are independent d-dimensional Brownian motions. Parameters , , Λ, and Σ are defined in Theorem 2.
Proof of Theorem 3.
Recall the FCLT for MPP (Assumption 2), we have
in law for the Skorokhod topology. From Theorem 2, we have the FCLT for MGCPP
in the weak law of Skorokhod topology. Here, we assume two multivariate Brownian motions in (26) and (27) are mutually independent and we refer them and . Let be the -algebra generated by , , . Since and the Markov chain are independent, is only determined by and , we can have processes
and
are -conditional independent. Similar to the central limit theorem in Prakasa-Rao (2009), we consider the convergence of conditional expectations for processes (28) and (29) on . Then with the characteristic functions for both limiting processes, we have the joint convergence
as . Next, consider
Remark 10.
4.2. Numerical Examples for FCLT: Deterministic Centralization
In this Section, we applied the LOBSTER data to test the FCLT II. According to the numerical examples of FCLT I, we consider the standard deviation of the approximation in Remark 11, namely
First, we estimated the covariance matrix Σ by applying the Assumption 2. When n is large enough, have the approximation:
Take the covariance for both side of (37), we have
Then, we can derive the estimated Σ for 5 stocks in Table 8.
Table 8.
Estimated covariance matrix of 5 stocks via the FCLT assumption.
Comparisons of real standard deviation and theoretical standard deviation can be found in Figure 5. Since results of INTC and MSFT are good enough with the 2-state Markov chain in FCLT I, we also applied 2-state Markov chain for INTC and MSFT here. As for AAPL, GOOG, and AMZN, we used the MGCPP model with 7-state Markov chain. Window sizes here start from 1 s and increase to 20 min in time steps of 10 s. As can be seen in Figure 5, the results for FCLT II are as good as the FCLT I results in Figure 1, Figure 2, Figure 3 and Figure 4. We also computed the MSE and coefficients in Table 9. Benchmark coefficients are from the least-square regression curves which are similar as benchmarks in Table 6.
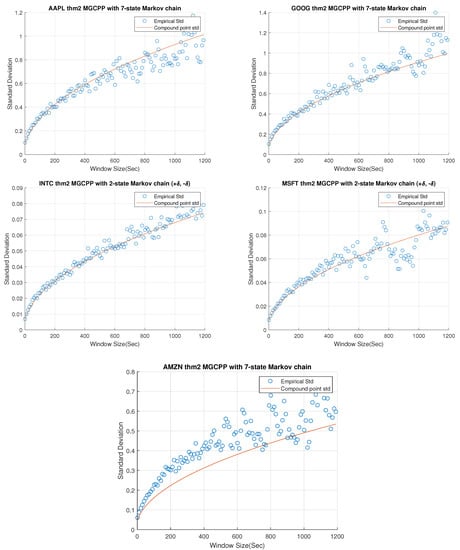
Figure 5.
Standard deviation comparisons for 5 stocks by FCLT II for the MGCPP. INTC and MSFT are simulated with 2-state Markov chain while AAPL, AMZN, and GOOG are using 7-state Markov chain.
Table 9.
The MSE and coefficients computed by MGCPP FCLT II.
We see that the percentage errors of MSFT and AAPL are very small (less than ) and the results of INTC and GOOG are also good (less than ). The percentage error of AMZN is large, but it is still smaller than the error derived from FCLT I in Table 7. In general, the simulation results of FCLT II is as good as the FCLT I and we can apply this FCLT II to model a mid-price.
4.3. Rolling Cross-Validation
In this section, we tested the forecast ability of the MGCPP model. Since we did not assume the multivariate point process is stationary, we cannot apply the K-fold cross-validation directly. Here, we used the rolling K-fold cross-validation method which proposed in Bergmeir et al. (2018). We divided the last 50 mins’ data into 5 disjoint 10-min windows for each stock. For the fold 1, We take the first 280 mins’ data as the training set to estimate parameters. Then, we applied the data in the next 10-min window to calculate the percentage error. Next, we merge the test set into the training set in fold 1 as the new training set in fold 2 and apply the next 10-min window as a new test set. Repeating this procedure 5 times, we will get 5 percentage errors. The mean value of the 5 percentage errors will be the test error E for this stock. So, the overall test error for our multivariate model is the average of all test errors. Figure 6 gives an example diagram for the rolling cross-validation.
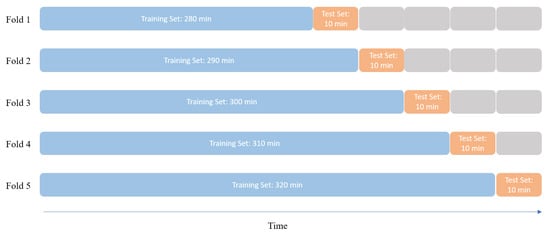
Figure 6.
Diagram for the Rolling cross-validation.
Table 10 lists test errors for different tickers and the overall test error for the MGCPP model. As can be seen from the table, the test error for each stock is relatively large and the overall test error (15.46%) is nearly double the overall percentage error (7.92%) in Table 9. That is because the results in Table 9 is a fitting error while the test errors in Table 10 is a kind of forecast error. We did not apply any future information when we conduct the forecast task. So, even the 15.46% overall test error is not as good as the fitting one, it is still a good prediction in the LOB and can provide lots of insights in the forecast task.
Table 10.
Test Errors for different tickers by applying 5-fold cross-validation. The errors are percentage errors between benchmark coefficients and the MGCPP coefficients.
5. Conclusions and Future Work
In this paper, we proposed a MGCPP model for the mid-price modeling in limit order book. This kind of process is a generalization of several stochastic models in the limit order market. We applied LOBSTER data to conduct simulations and found the multivariate generalized model is as good as the general compound Hawkes process model. We also tested the prediction ability of this kind of process. In general, the MGCPP performs very well in LOB modeling and it can be a meaningful reference in the mid-price prediction. In the future, we will explore more applications of the MGCPP and consider related option pricing problems under this kind of frame work.
Author Contributions
Q.G.: methodology, software, validation, data curation, visualization, writing—original draft preparation. B.R.: conceptualization, methodology. A.S.: project administration, supervision, writing—review and editing, conceptualization, methodology. All authors have read and agreed to the published version of the manuscript.
Funding
This research was funded by NSERC grant number: RT732266.
Acknowledgments
All authors wish to thank NSERC for continuing support.
Conflicts of Interest
The authors declare no conflict of interest.
References
- Bacry, Emmanuel, Sylvain Delattre, Marc Hoffmann, and Jean-François Muzy. 2013. Some limit theorems for Hawkes processes and application to financial statistics. Stochastic Processes and Their Applications 123: 2475–99. [Google Scholar] [CrossRef]
- Bowsher, Clive G. 2007. Modelling security market events in continuous time: Intensity based, multivariate point process models. Journal of Econometrics 141: 876–912. [Google Scholar] [CrossRef]
- Brémaud, Pierre, and Laurent Massoulié. 1996. Stability of nonlinear Hawkes processes. The Annals of Probability 1: 1563–88. [Google Scholar]
- Bjork, Tomas. 2011. Introduction to Point Processes from a Martingale Point of View. Stockholm: KTH. [Google Scholar]
- Bauwens, Luc, and Nikolaus Hautsch. 2009. Modelling Financial High Frequency Data Using Point Processes. Berlin/Heidelberg: Springer. [Google Scholar]
- Bergmeir, Christoph, Rob J. Hyndman, and Bonsoo Koo. 2018. A note on the validity of cross-validation for evaluating autoregressive time series prediction. Computational Statistics and Data Analysis 120: 70–83. [Google Scholar] [CrossRef]
- Cartea, Álvaro, Sebastian Jaimungal, and José Penalva. 2015. Algorithmic and High-Frequency Trading. Cambridge: Cambridge University Press. [Google Scholar]
- Chen, Shizhe, Ali Shojaie, Eric Shea-Brown, and Daniela Witten. 2019. The Multivariate Hawkes Process in High Dimensions: Beyond Mutual Excitation. arXiv arXiv:1707.04928v2. [Google Scholar]
- Cont, Rama, and Adrien De Larrard. 2013. Price dynamics in a Markovian limit order market. SIAM Journal on Financial Mathematics 4: 1–25. [Google Scholar] [CrossRef]
- Embrechts, Paul, Thomas Liniger, and Lu Lin. 2011. Multivariate Hawkes processes: An application to financial data. Journal of Applied Probability 48: 367–78. [Google Scholar] [CrossRef]
- Guo, Qi, and Anatoliy Swishchuk. 2020. Multivariate general compound Hawkes processes and their applications in limit order books. Wilmott 107: 42–51. [Google Scholar] [CrossRef]
- Lemonnier, Rémi, Kevin Scaman, and Argyris Kalogeratos. 2017. Multivariate Hawkes Processes for Large-Scale Inference. Paper presented at Thirty-First AAAI Conference on Artificial Intelligence, San Francisco, CA, USA, February 4–9. [Google Scholar]
- Liniger, Thomas Josef. 2009. Multivariate Hawkes Processes. Ph.D. dissertation, Swiss Federal Institute of Technology in Zurich, Zurich, Switzerland. [Google Scholar]
- Norris, James R. 1998. Markov Chains. Cambridge: Cambridge University Press. [Google Scholar]
- Rao, B. L. S. Prakasa. 2009. Conditional independence, conditional mixing and conditional association. Annals of the Institute of Statistical Mathematics 61: 441–60. [Google Scholar]
- Swishchuk, Anatoliy. 2017. Risk model based on compound Hawkes process. Wilmott 94: 50–57. [Google Scholar]
- Swishchuk, Anatoliy, and Nelson Vadori. 2017. A semi-Markovian modelling of limit order markets. SIAM Journal on Financial Mathematics 8: 240–73. [Google Scholar] [CrossRef]
- Swishchuk, Anatoliy, Tyler Hofmeister, Katharina Cera, and Julia Schmidt. 2017. General semi-Markov model for limit order books. International Journal of Theoretical and Applied Finance 20: 1750019. [Google Scholar] [CrossRef]
- Swishchuk, Anatoliy, and Aiden Huffman. 2020. General compound Hawkes processes in limit order books. Risks 8: 28. [Google Scholar] [CrossRef]
- Vinkovskaya, Ekaterina. 2014. A Point Process Model for the Dynamics of LOB. Ph.D. dissertation, Columbia University, New York, NY, USA. [Google Scholar]
- Vadori, Nelson, and Anatoliy Swishchuk. 2015. Strong law of large numbers and central limit theorems for functionals of inhomogeneous Semi-Markov processes. Stochastic Analysis and Applications 33: 213–43. [Google Scholar] [CrossRef]
- Yang, Yingxiang, Jalal Etesami, Niao He, and Negar Kiyavash. 2017. Online Learning for Multivariate Hawkes Processes. Paper presented at 31st Conference on Neural Information Processing Systems, Long Beach, CA, USA, December 4–9. [Google Scholar]
- Zheng, Ban, François Roueff, and Frédéric Abergel. 2014. Ergodicity and scaling limit of a constrained multivariate Hawkes process. SIAM Journal on Financial Mathematics 5: 99–136. [Google Scholar] [CrossRef]
- Zhu, Lingjiong. 2013. Central limit theorem for nonlinear Hawkes processes. Journal of Applied Probability 50: 760–71. [Google Scholar] [CrossRef]
© 2020 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (http://creativecommons.org/licenses/by/4.0/).