1. Introduction
Urban economy and real estate markets are two interconnected fields of research. They overlap in so far as the real estate price evolution is analyzed under an urban approach: it has been shown that less than 8% of the variation in price levels across cities can be accounted for by national effects
Glaeser et al. (
2014), while the remaining part is explained by local factors. In other words, national macroeconomic variables such as population growth, global migration, interest rates or national income, have really tiny power in explaining the real estate market, comparing with the macroeconomic variables accounted at a local level, such as the city population, the migration towards a particular city or the opportunities of jobs in a given urban area, that directly press on built environment and housing demand. On the other hand, the local real estate market influences the urban economy as long as it offers advantageous investment opportunities and facilities able to attract w orkers and economic activities: according to
Arvanitidis (2014), the property market institution has a pivotal role through which local economic potential can be realized and served. In this sense, urban economy and real estate market influence each other.
Recently, some phenomena are affecting both urban economy and real estate market evolution. According to the
United Nations (2019), the world’s population is expected to grow by 5.9 billion by the end of the century, and about the 80% of which is expected to live in or move toward cities, due to economic and political motivations. Moreover, the population is aging and the proportion of elderly who remains to live in the city is increasing, thanks to alternative pension products based on the property value, like home equity plan and reverse mortgages
Di Lorenzo et al. (2020a). In Europe, 25% of the population is already aged 60 years and the proportion who lives in city is growing: by 2050, two-thirds of the world population are expected to live in cities
Lopez-Alcala (2016). A complete overview of the urban situation has to take into account data on migration: according to the International Organization of Migration, in 2015 in Europe there have been one million migrants, and many of them stay i n cities
McKinsey (2016). As population grows and the urbanization goes on, real estate markets have to face pressure on prices and affordability
van Doorn et al. (2019), caused by the mismatch between demand and supply: inflows of people in cities are pressing and asking for new buildings. On the other hand, the increase of working population into metropolitan areas are bearing long-term opportunities for investors. In this context, understanding real estate market evolution is crucial for various real estate stakeholders such as house owners, investors, banks, insurances and other institutional investors like real estate funds. The housing demand is supported by both the need of a house to live in and the research of competitive yields. As highlighted by the emerging trend in Real Estate Europe survey
Morrison et al. (2019), real estate has grown as a proportion of the balance sheets of many institutional investors because it has provided the yield and returns that other asset types have not. In particular, in the last decade we have experienced geopolitical uncertainty and decrease in the interest rate and this has reinforced the longing of secure and profitable long-term income. Moreover, many financial intermediaries offer financial and insurance products whose valuation is influenced by the expectation on the real estate market, like mortgages or reverse mortgages
Di Lorenzo et al. (2020a). The link between real estate markets and financial market is evident from the recent world economic crisis. Moreover, real estate property represents a major part of the individual wealth
Arvanitidis (2014), so it is clear that real estate pricing mechanism is an important driver of the economy.
In light of these considerations, the importance of a precise awareness of the inner workings in the real estate market and an accurate price prediction is evident. The academic literature on this topic is fervent. In order to describe the dynamics of the market and produce predictions, the features that influence the real estate price have to be identified.
Gao et al. (2019) grouped these features into two categories: non-geographical factors, that concern the peculiarities of the house, such as the number of bedrooms or the floor space area; and geographical factors, such as the distance to the city center and to main services like the schools.
Rahadi et al. (2015) divide the variables explanatory of the house price into three groups: physical conditions, concept and location
Chica-Olmo (2007). Physical conditions are properties possessed by the house; the concept concerns internalized ideas of home like minimalist home or healthy and green environment (
Ozdenerol et al. 2015;
Miller et al. 2009;
Coen et al. 2018). Another point of view is the macroeconomic perspective
Grum and Govekar (2016), according to which many factors drive the behavior of the real estate market, such as interest rates, government regulation, economic growth, political instability and so on. However,
Glaeser et al. (2014) presents an urban approach and show how most variation in housing price changes is local and not national. The empirical evidence confirms that the most important factors driving the value of a house are the size and the location: (
Bourassa et al. 2010;
Case et al. 2004;
Gerek 2014 and
Montero et al. 2018) show how different locations have a strong impact on their prices. Spatial location broadly aims to analyze the role of geography and location in economic phenomena, and a particular strand of research is devoted to the analysis of real estate market fluctuations as one of the economic phenomenon in a particular geographic area.
Once the explanatory variables have been chosen, the prediction model has to be identified. The hedonic pricing model has proposed extensively in the literature of house price prediction (
Krol 2013;
Selim et al. 2009;
Del Giudice et al. 2017b). It is essentially used for analyzing the relationship between house price and house features through classical regression methods, assuming that the value of a house is the sum of all its attributes value
Liang et al. (2015).
Manjula et al. (2017) uses multivariate regression models. Some related works
Greenstein et al. (2015) are concerned with trying to estimate the health of a real estate market using the housing index price.
Alfiyatin et al. (2017) model house price combine regression analysis and particle swarm optimization. In the last few years, with the diffusion of the application of artificial intelligence in various fields and in the context of real estate
Zurada et al. (2011), many authors have used machine learning algorit hms to gain a better fitting of the models. House price predictions have been produced through machine learning (
Baldominos et al. 2018;
Winson 2018) and deep learning methods, such as artificial neural networks (
Nghiep et al. 2001;
Selim et al. 2009;
Yacim et al. 2016;
Yacim et al. 2018;
Di Lorenzo et al. 2020b), support vector machine (
Gu et al. 2011;
Wang et al. 2014) and adaptive boosting
Park and Bae (2015). Other contributions deepen the expert systems based on fuzzy logic
(Sarip et al. 2016;
Del Giudice et al. 2017a;
Guan et al. 2008).
Guan et al. (2014) propose adaptive neuro-fuzzy inference systems for real estate appraisal.
Park and Bae (2015) analyze the problem of classification of an investment in worthy or not, performing different algorithms: decision trees, Naive Bayes and AdaBoost.
Manganelli et al. (2007) study the sales of residential property in a city in the Campania region in Italy using linear programming to analyze the real estate da ta.
Del Giudice et al. (2017b) predict house price through a Markov chain hybrid Monte Carlo method, and test neural networks, multiple regression analysis and penalized spline semiparametric method.
Gao et al. (2019) describe a multi task learning approach to predict location centered house price.
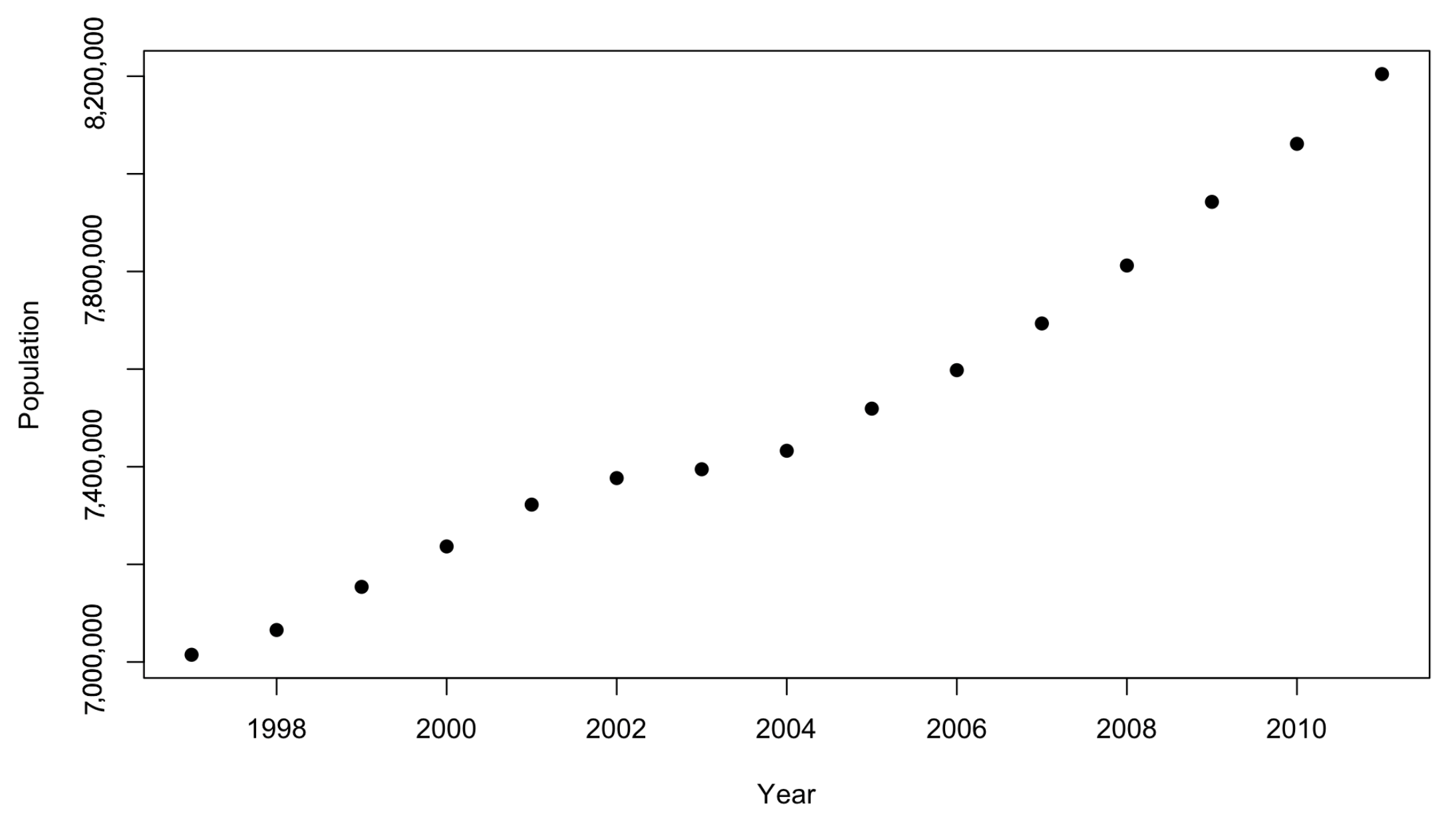
This paper follows the recent developments of the literature on real estate and proposes to take advantage of the random forest algorithm to better explain which variables have more importance in describing the evolution of the house price following an urban approach. To this aim, we focus on a given city, and analyze the local variables that influences the interaction between housing demand and supply and the price. We perform random forest on real estate data of London, that already in the 1990s was attracting literature attention for the economy of its agglomeration
Crampton and Evans (1992) and continues to stimulate the international debate for having experienced in the three last decades an extraordinary building boom
National Geographic (2018). The novelty of our paper consists in deepening a machine learning (ML) technique for real estate price prediction under an urban approach. In order to achieve this goal, we insert in the algorithm the house price in London as output variable, and some local urban economic variables as input variables. The random forest provides useful support for understanding the relationships between information variables and the target variable and highlighting the importance of each factor. There is a lot of research articles that employ the random forest approach. For instance, it has been considered in early warning systems that signal a country’s vulnerability to financial crises.
Tanaka et al. (2016) proposed a novel random forests-based early warning system for predicting bank failures.
Tanaka et al. (2019) developed a vulnerability analysis by building bankruptcy models for multiple industries using random forests to predict the probability of firm bankruptcy.
Beutel et al. (2019) compared the predictive performance of different machine learning (including random forest) models applied to early warning for systemic banking crises.
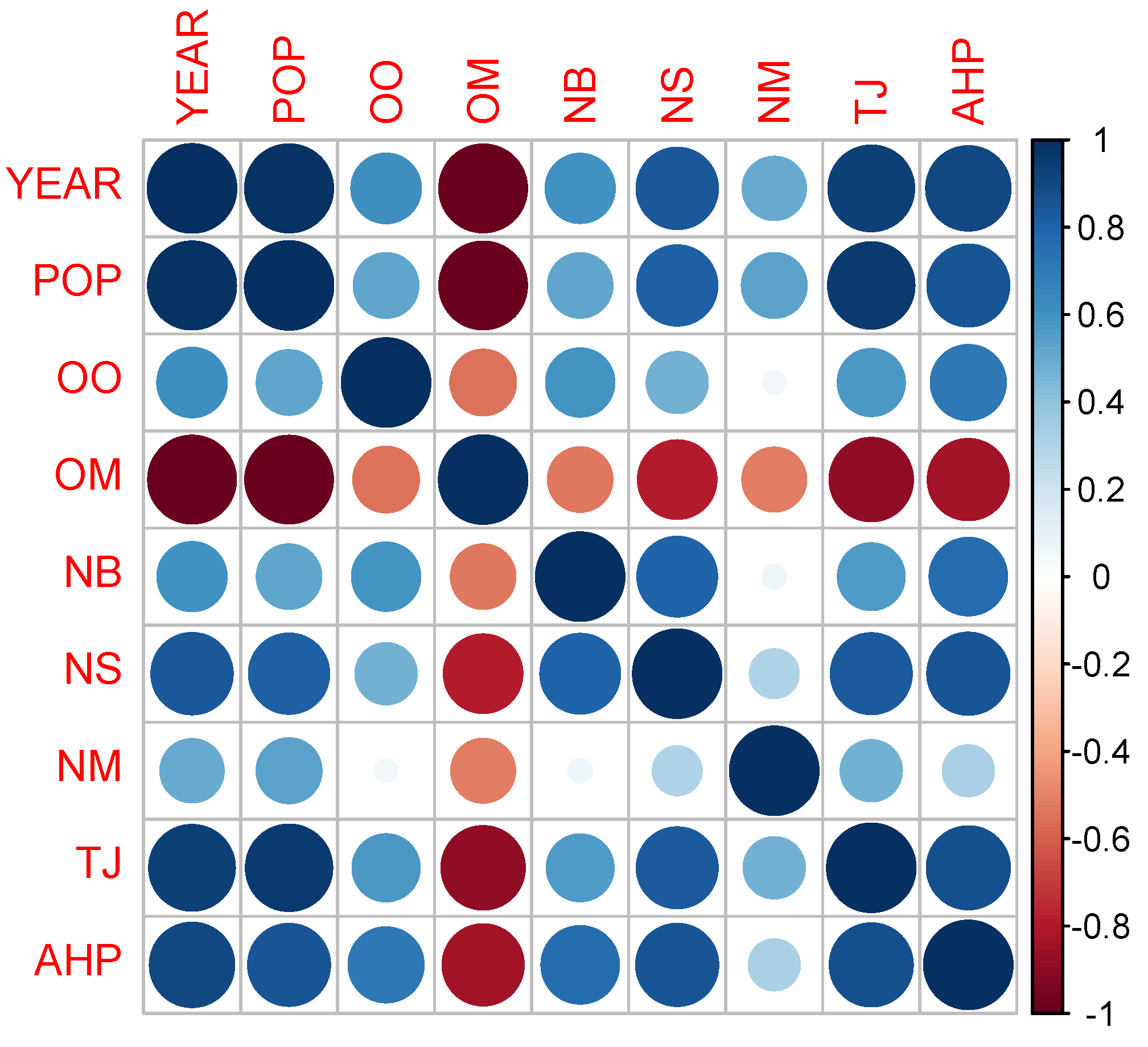
Moreover, we use different explanatory variables with respect to those previously listed. The variables choice is based on an urban point of view, where the main force driving the market is the interaction between local demand and supply, explained by factors like the population growth or the net migration for the demand side, and new buildings and net supply.
The paper is structured as follows.
Section 2 describes the regression tree architecture, the random forest technique and the variable importance measure. In
Section 3 we present the case study based on the London real estate market. Final remarks are provided in
Section 4.
2. The Model
In this section we introduce machine learning techniques for regression problems. In
Section 2.1 we briefly describe the regression tree architecture on which the random forest algorithm is based. In
Section 2.2 we illustrate the functioning of the random forest and in
Section 2.3 we present the variable importance measure used in the case study to catch the importance of each predictor in predicting the target variable.
Machine learning is generally used to perform classification or regression over large datasets. However, it is also proved useful in small datasets to identify hidden patterns that are difficult to detect through more traditional regression techniques such as Generalized Linear Models (GLMs) and Generalized Additive Models (GAMs).
Consider a generic regression problem to estimate the relationship between a target (or response) variable,
Y, and a set of predictors (or features),
:
where
is the error term. The quantity
represents the expected squared prediction error. It can rewritten as the sum of the reducible error
−
and the irreducible error
. A machine learning technique aims at estimating
f by minimizing the reducible error.
Among the machine learning algorithms, we refer to the random forest that falls into the category of the ensemble methods. It allows obtaining the error decrease by reducing the prediction variance, maintaining the bias, which is the difference between the model prediction and the real value of the target variable.
2.1. Regression Tree Architecture
The random forest algorithm is founded on the regression tree architecture. The regression trees enable attaining the best function approximation
through a procedure consisting in the following steps
Loh (2011):
The predictor space (i.e., the set of possible values for ) is divided into J distinct and non-overlapping regions, .
For each observation that falls into the region , the algorithm provides the same prediction, which is the mean of the response values for the training observations in .
As described in
James et al. (2017), the fundamental concept is to split the predictors’ space into rectangles, identifying the regions
that minimize the Residual Sum of Squares (RSS):
Once building the regions , the response is predicted for a given test observation using the mean of the training observations in the region to which that test observation appertain.
The consideration of all the possible partitions of the feature is computationally infeasible, thus we use a top-down approach through a recursive binary partition
Quinlan (1986): the algorithm starts at the top of the tree, where all values of the target variable stand in a single region, and then successively partitions the predictors’ space. The best split is identified according to the entropy or the index of Gini that is a homogeneity measure for every node. The highest homogeneity (or purity) is achieved when only one class of the target variable is attending the node.
Breiman (2001) has listed the most interesting properties of regression tree-based methods. They belong to non-parametric methods able to catch tricky relations between inputs and outputs, without involving any a-priori assumption. They manage miscellaneous data by applying features selection so as to be robust to not significant or noisy variables. They are also robust to outliers or missing values and easy to be unfolded.
2.2. Random Forest
The random forest (RF) algorithm creates a collection of decision trees from a casually variant of the tree. Once one specific learning set is defined, the RF presents a random perturbation to the learning procedure and in this way a differentiation among the trees is produced. Successively the predictions of all these trees is derived through the impelementation of aggregation techniques. The first aggregation procedure was described by
Breiman (1996); the authors proposed the well know bagging based on random bootstrap copies of the original data to assemble different trees. Later in 2001 the same authors
Breiman (2001) proposed the random forest as an extention of the procedure of the bagging such that it combines the bootstrap with randomization of the input variables to separate internal nodes
t. This means that the algorithm does not identify the best split
among all variables, but firstly creates a random subset of
K variables for each node and among them determines the best split.
The RF estimator of the target variable
is a function of the regression tree estimator,
, where
is the vector of the predictors,
represents the indicator function and
are the regions of the predictors space obtained by minimizing RSS. It is identified by the average values of the variable belonging to the same region
. Therefore, denoting the number of bootstrap samples by
B and the decision tree estimator developed on the sample
by
, the RF estimator is defined as follows:
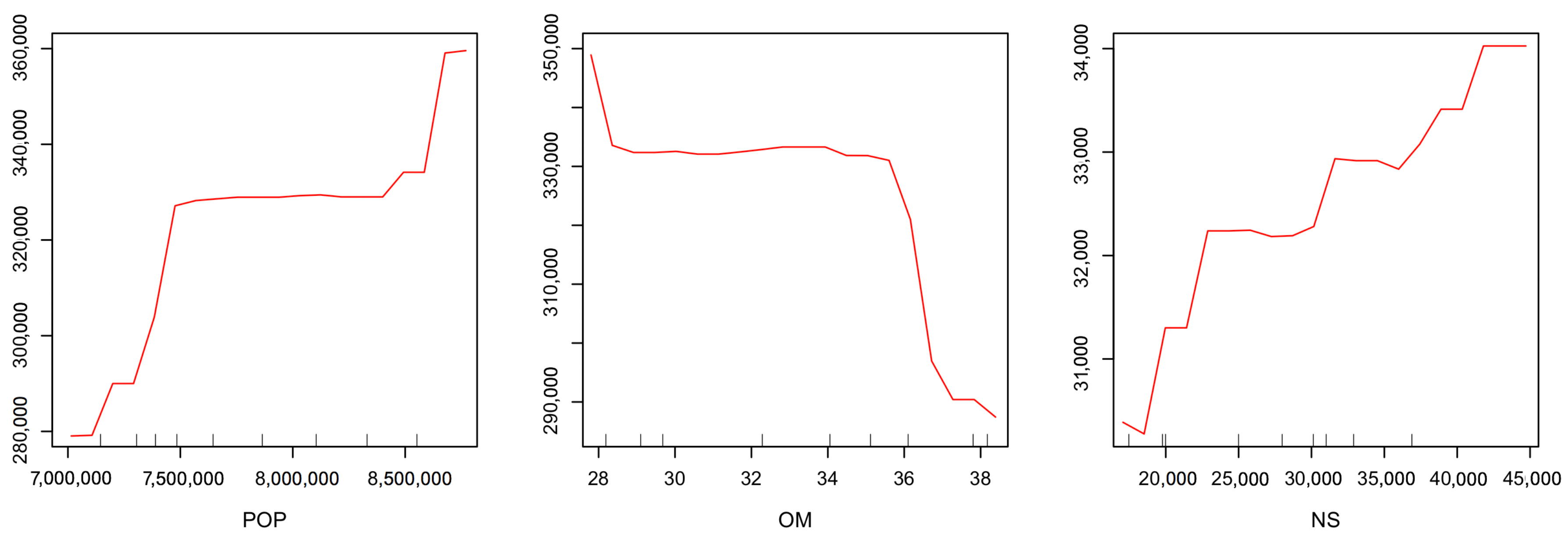
The choice of the number of trees to include in the forest should be done carefully, in order to reach the highest percentage of explained variance and the lowest mean of squared residuals (MSR).
2.3. Variable Importance
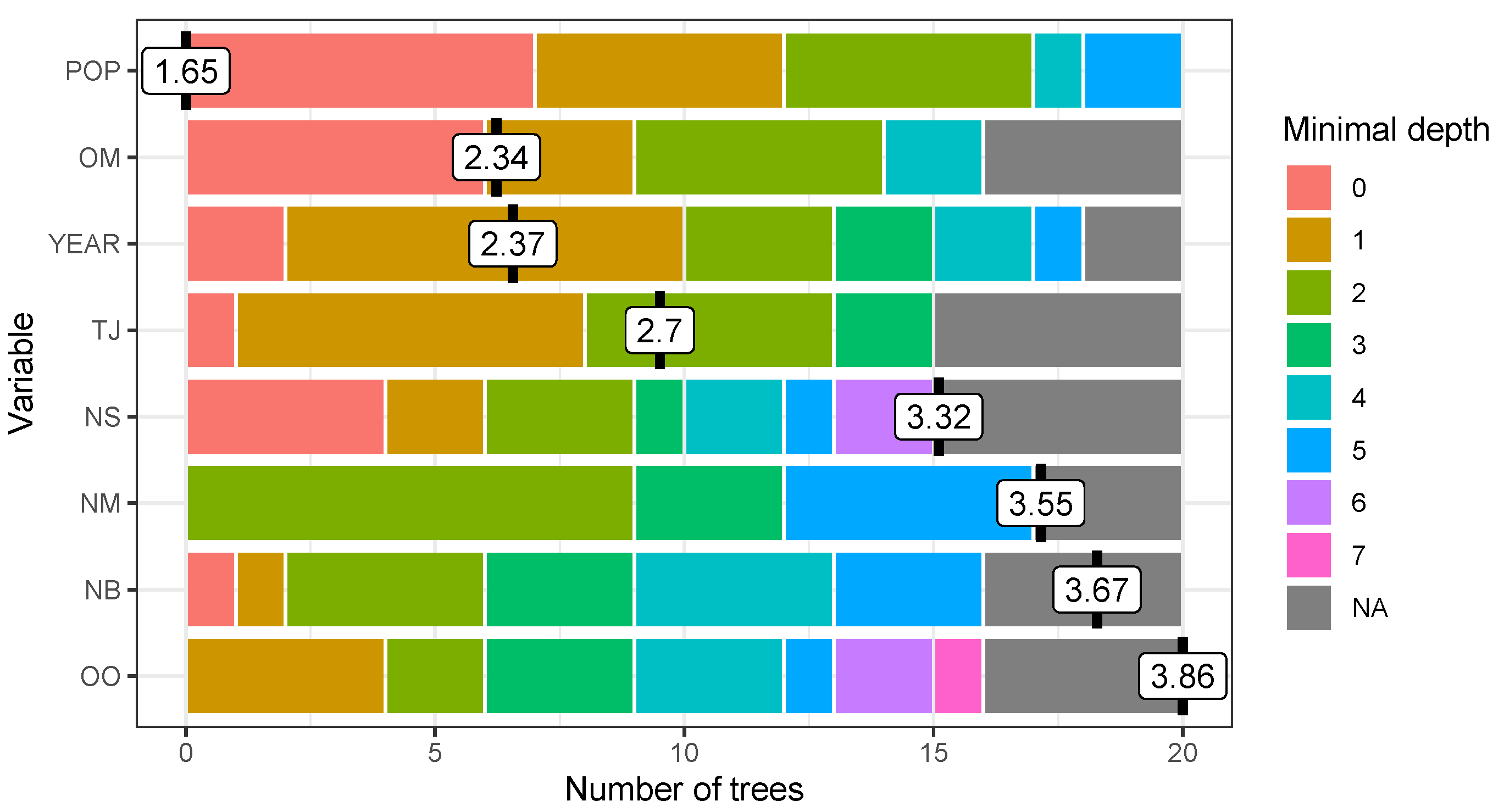
ML algorithms are usually viewed as a black-box, as the large number of trees makes the understanding of the prediction rule hard. To get from the algorithm interpretable information on the contribution of different variables we follow the common approach consisting in the calculation of the variable importance measures.
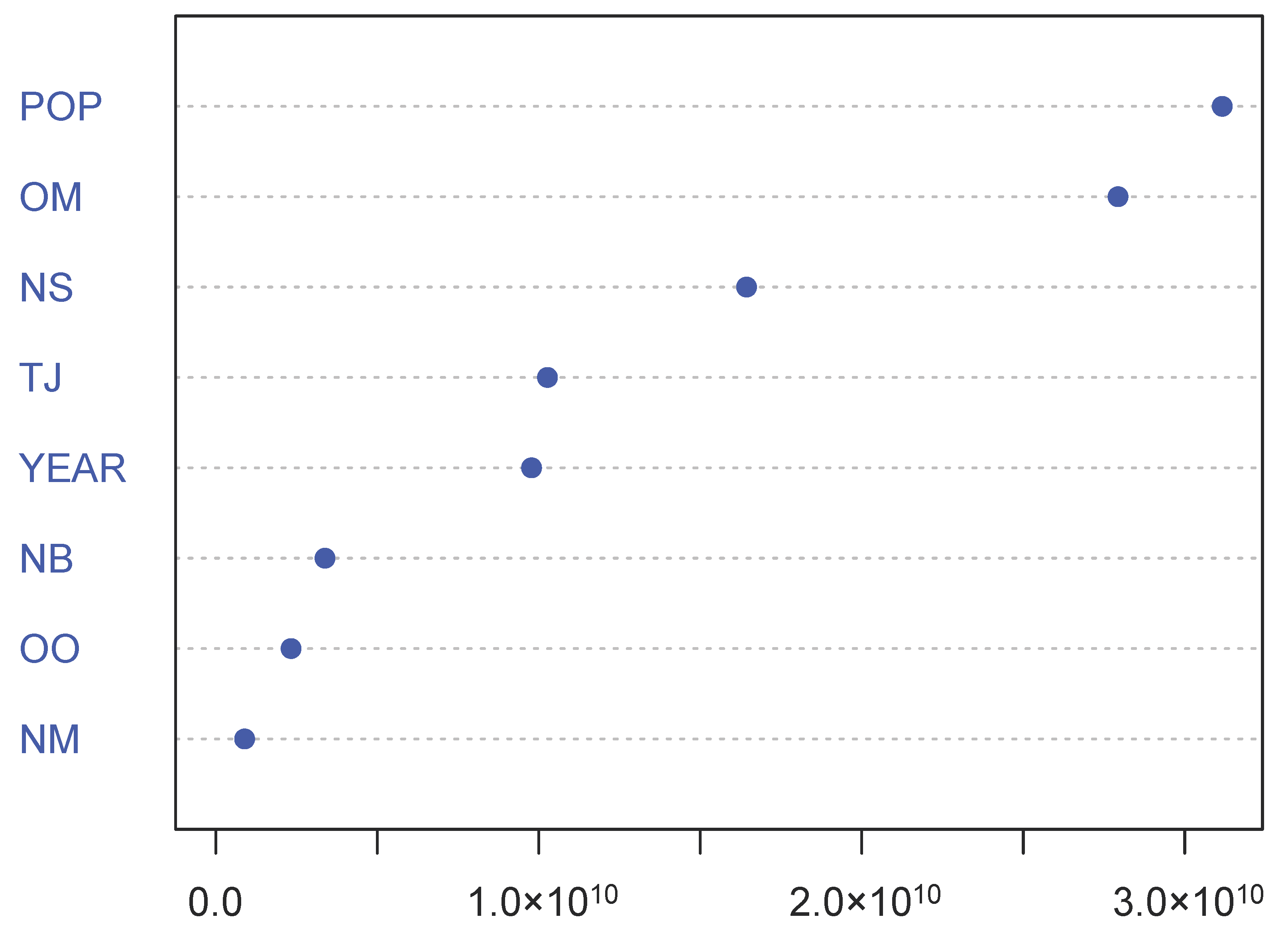
Variable importance is determined according to the relative influence of each predictor, by measuring the number of times a predictor is selected for splitting during the tree building process, weighted by the squared error improvement to the model as a result of each split, and averaged over all trees.
According to the definition provided by
Breiman (2001), the RF variable importance is a measure providing the importance of a variable in the RF prediction rule. These measures are often able to detect the interaction effects, i.e., when the predictor variables interact with each other, without any a priori specification
Wright et al. (2016).
A weighted impurity measure has been proposed in
Breiman (2001) for evaluating the importance of a variable
in predicting the target
Y, for all nodes
t averaged over all
trees in the forest. Among the variants of the variable importance measures, we refer to the Gini importance, obtained assigning the Gini index to the impurity
index. This measure is often called Mean Decrease Gini, here denoted by
:
where
is the variable used in split
and
is the impurity decrease of a binary split
dividing node
t into a left node
and a right node
:
where
N is the sample size,
the proportion of samples reaching
t, and
and
are the proportion of samples reaching the left node
and the right node
respectively.
The
defined in Equation (
3) provides the importance of feature
, which takes into account the number of splits enclosing the variable. The study of the importance of the feature provides more insight into the learning mode of the algorithm.
4. Conclusions
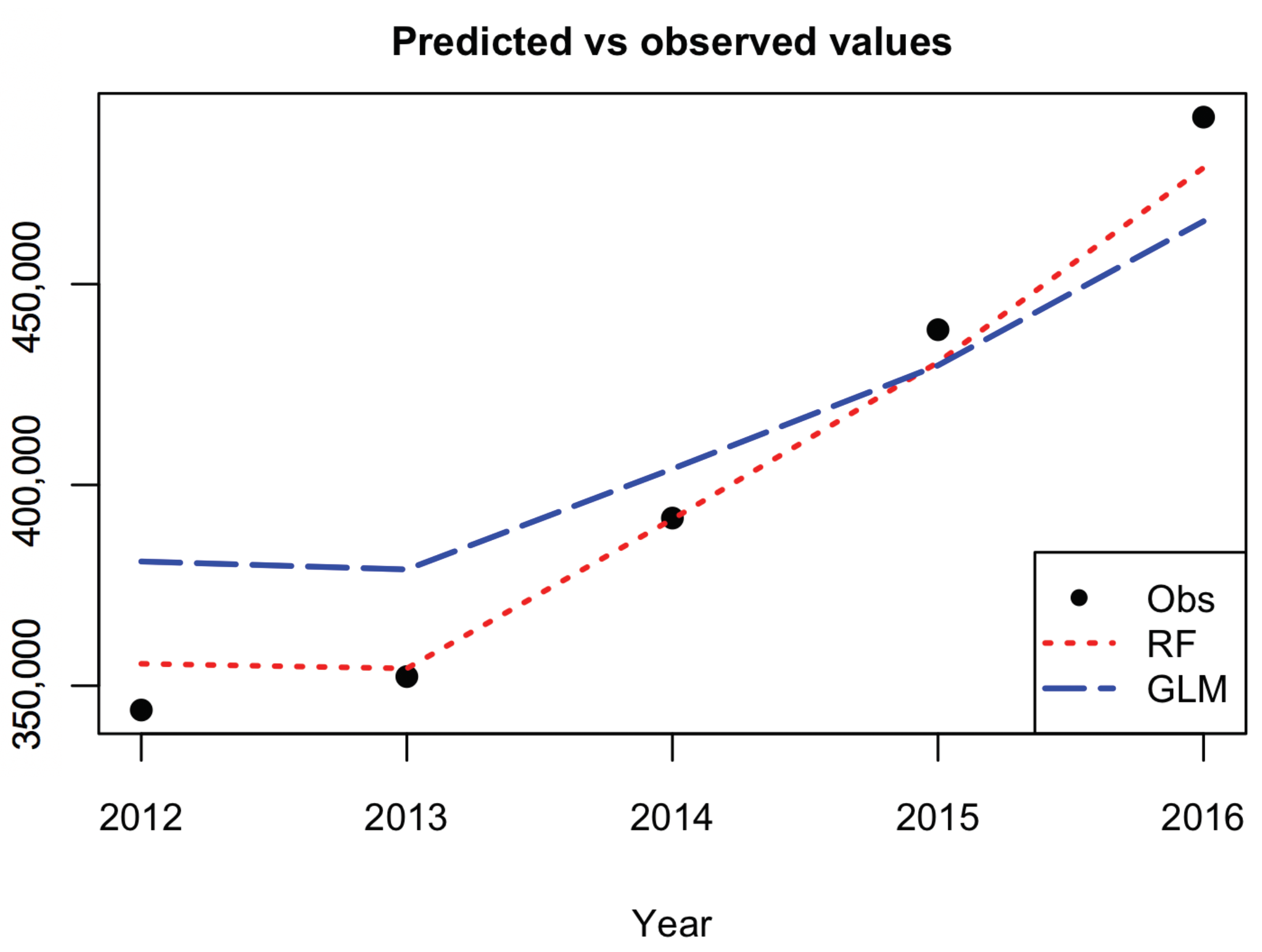
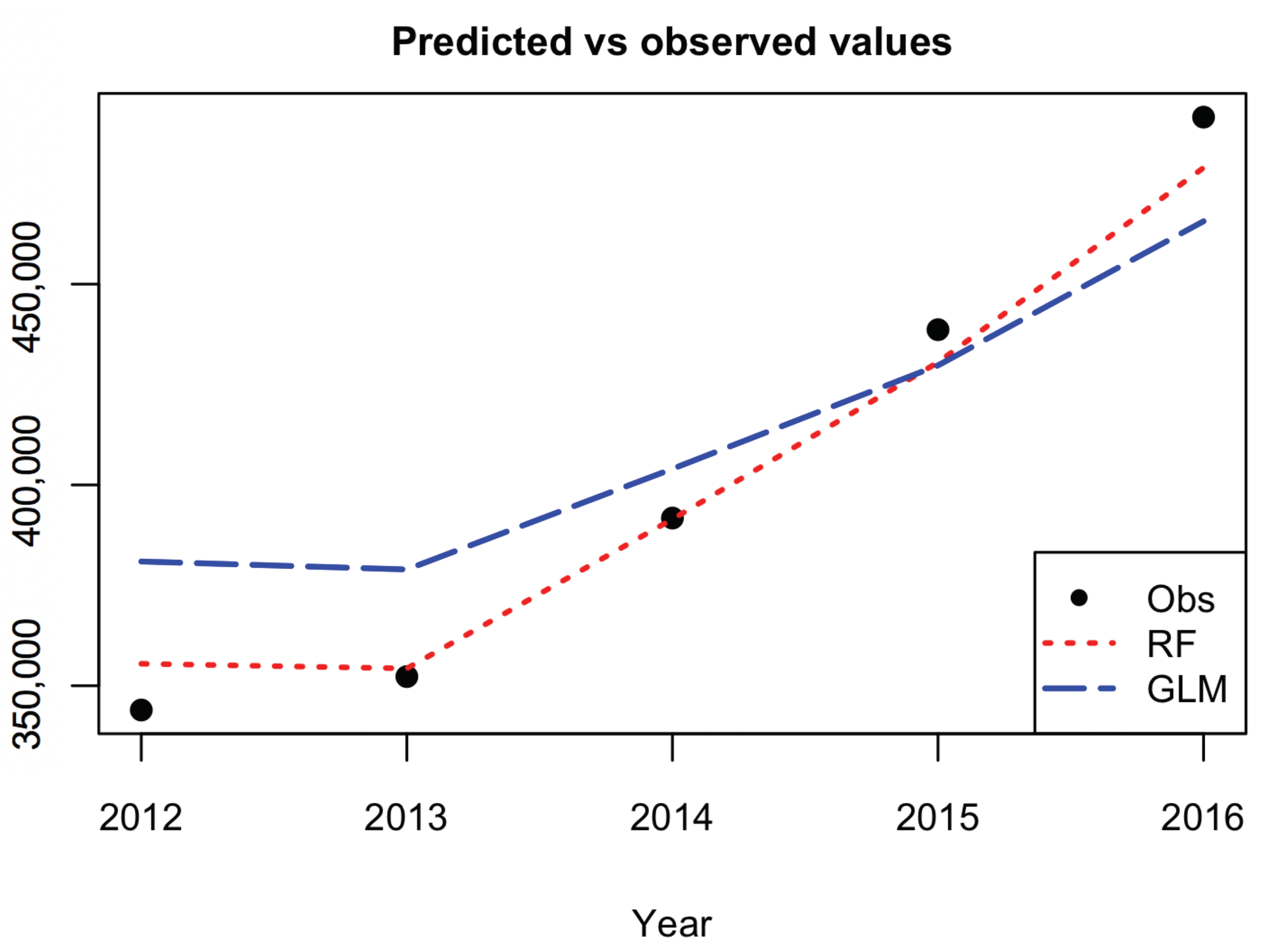
In this paper we have implemented a machine learning algorithm, RF, to predict houses price with an application to UK real estate data. In particular, we have analyzed the average house price of the center of London, taking in consideration urban explicative variables of the demand and supply of the houses. The point of view offered is different and complementary with respect to the literature on the field, which considers features attaining the buildings like size and location, and is based on an urban perspective to explain the evolution of the local real estate market. This is the main reason our data set has been selected. Despite the dataset size being small, the numerical results show a better prediction improvement by RF with respect to the traditional regression approach based on GLM. The use of RF in small datasets is common among data scientists as the bootstrapping, on which RF is based, allows the algorithm to perform well anyway. RF is relatively easy to build and does not require expensive hyperparameters tuning. Besides, to avoid overfitting that generally affects the models trained on small datasets, we control both the number of trees and the maximum depth. This improves the model’s ability to do not see patterns that do not exist. As regard to the importance of variables, the algorithm selects the local population as the most predictive variable. This result confirms that the demand size is the main driver of the real estate market. The space for further works is twofold: on one hand the model presented is flexible and can be easily extended to combine variables related to supply and demand with others attaining to the physical features of the house, on the other hand, different machine learning algorithms, like that deals with the problem of the endogeneity of predictors and the bias of results, can be implemented and compared. The research conducted can be reproduced for the analysis of other real estate dataset. A more accurate forecast of the evolution of real estate market prices must exploit not only variables relating to local characteristics of the market, but also combine them with different information sources such as macroeconomic ones. The improvements achieved can show practical feedback for the whole society. As population and urbanization grow, the need for models able to catch the possible evolution of the real estate market concerns more stakeholders, from homeowners to real estate companies to insurance companies and so on. In modern society we are witnessing the growth of the elderly “cash poor house rich”, those who own a home but have retirement incomes so low that they cannot ensure a decent survival and the necessary medical care. Faced with this phenomenon, the insurance market of Reverse Mortgage is developing considerably. In this context, the role that data play will be at the core of the forecasting of assets future value in terms of real-world evaluation and of the cost of insurance contracts related to house valuation.










{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}