A Bayesian Internal Model for Reserve Risk: An Extension of the Correlated Chain Ladder


Abstract
:1. Introduction
2. The Correlated Chain Ladder
2.1. Model Specification
2.2. Parameter Specification
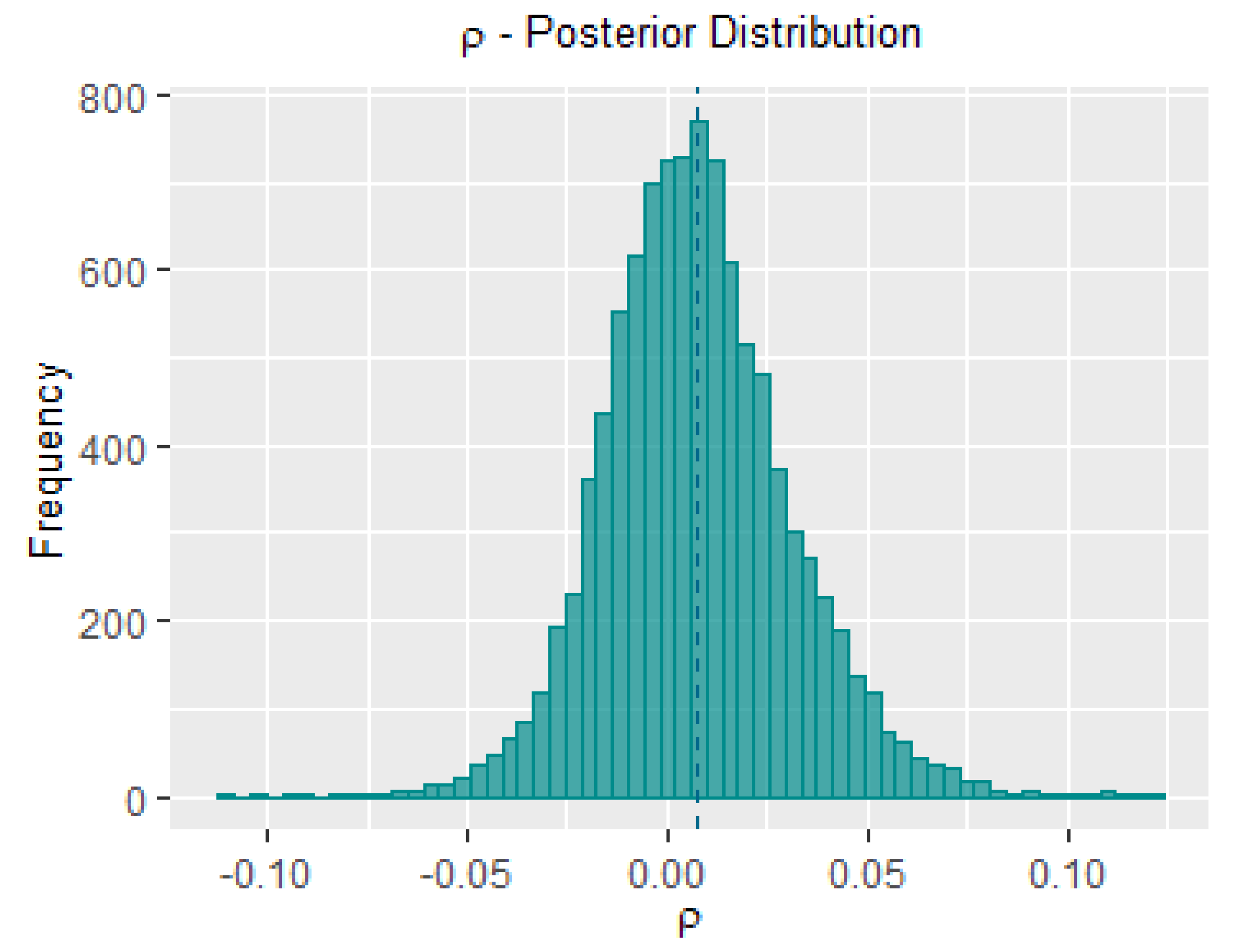
2.3. Posterior and Predictive Distributions
3. An Extension in a One-Year Framework
- The starting point is represented by the K parameters sets simulated with the MCMC procedure.We rearrange them according to the original CCL parametrization in order to proceed with the simulations. For each k, we have:where, being the cumulative payment not available in lower triangle (i.e., for ), we simulate it from a .Hence, for each parameters set we have a matrix containing the posteriorlog-mean parameters and a vector containing posterior log-variance parameters.
- We simulate the sets of losses starting from the elements of and . Following a one-year approach, we only generate, for each k, S different realizations of the next year future cumulative payments (with ), hence performing a total of simulations. We end up with an array of dimension where each element is a trapezoid composed of the original triangle and a further simulated diagonal related to payments in the calendar year . In Table 1 we provide a visualization to clarify this object: each column stands for a different parameter set k and each row is representative of the s-th batch of simulations over the parameters sets, i.e., a Bayesian predictive distribution.
- Next year incremental payments reported in Formula (9) can be easily obtained by transforming the array of simulated cumulative values in an array of incremental amounts with the following formula:for . In this step, we obtained diagonals of simulated values of the next year payments.
- Now, we perform the learning update. We use the information generated by the s-th batch of simulations to update the probability of each parameter set. To this extent, we compute the likelyhood of the observations for each element of the array. Being the density function of a log-normal random variable, for every element we have:Given the sample of K sets, resampling from the sample guarantees that the probability of sampling a specific set is the same for all the sets. In other words, all the sets initially sampled from the MCMC procedure are equally likely. Then, by means of the Bayes theorem, it is possible to obtain the posterior probability of the k-th parameter set given the simulated losses as:In other words, for each simulation, we re-evaluate the probability of each set obtaining a posterior probability distribution. If each set is representative of a possible scenario of the reserving process, we have effectively the posterior distribution of all possible scenarios. By iterating the process we obtain S different posterior distributions for the parameters.
- By virtue of the log-normal assumption, for each parameters’ set, the expected cumulative payments at times greater than t can be computed as:for , and . The Best Estimate easily follows.For each batch of simulations s, we use the posterior distribution computed at step 4 in order to obtain a post run-off re-weighted next year Best Estimate. For every s:Thus, we are able to obtain a predictive distribution of the expected values of the residual reserve according to Solvency II standards.
- The predictive distribution of claims development results can be derived by assessing the distribution of the obligations at the end of year . For each simulation, we add to each value of the residual reserve distribution the realized diagonal. For each s, we have at disposal K batches of diagonals over all the parameter sets. Thus, we sample a diagonal and we add it to the value calculated at step 6. In this way, we obtain the s-th realization of the next year obligations:Again, by iterating this process over all the S batches of simulations, we finally obtain a predictive distribution of future obligations.
4. An Application of the Model
4.1. Dataset and Model Calibration
- -
- is the natural logarithm of the premium earned for the i-th generation.
- -
- is the natural logarithm of the expected loss ratio, for the i-th generation.
- -
- is a random noise defined as follows:We deemed the variability of the loss ratio sufficient, given that oldest accident years are almost closed.
4.2. Main Results in a Run-Off View
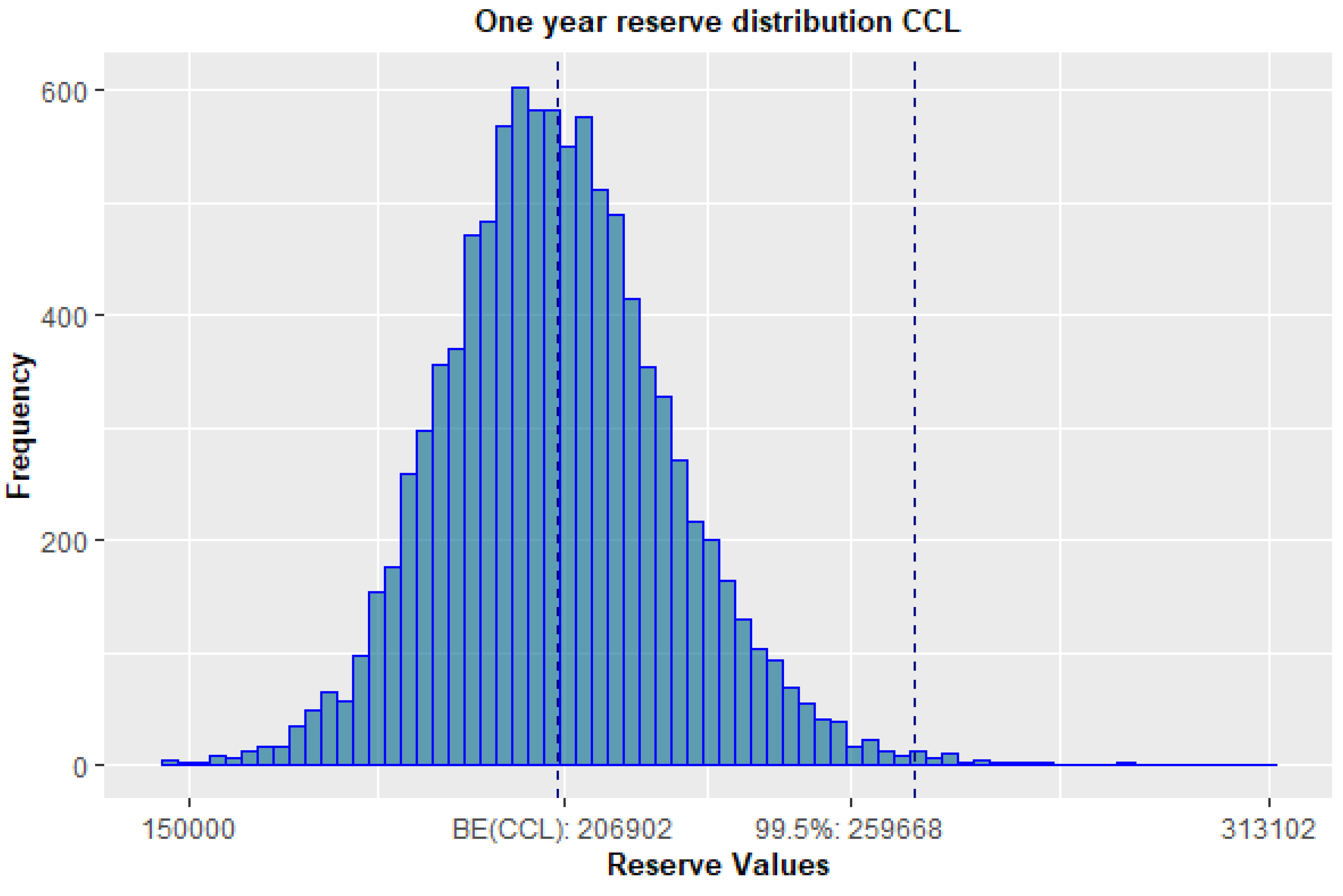
4.3. One-Year View
4.4. Important Remarks
5. Conclusions
Author Contributions
Funding
Conflicts of Interest
Legal Disclaimer
Appendix A. An N-Years Generalization
- Starting from the point 2 of the outline of the algorithm structured in the previous section, we simulate a array in which every element is composed by a number n of diagonals, where again K is the number of parameter sets and S is the number of simulations for each parameter set. The -th set of diagonals represent an hypothetical development of the triangle on which we will build a recursive update. In the one-year model, we had for the first diagonal:where stands for the trapezoid obtained by adding 1 future diagonal to the triangle. We can then use the probabilities obtained in this way to update our knowledge after a second year of run-off:Then, recursively obtain the probabilities of each scenario after n years:Iterating over S, we have S probability distributions that we will use as before to compute S determinations of the residual reserve after n years.
- At this point, for each parameters’ set we calculate the Best Estimate at time for claims incurred at time t. As for the one-year version, we compute the expected values of the lower triangle:for . Again, from these values we can obtain the expected values of incremental amounts and the new Best Estimate for a given parameters’ set .
- By iterating step 2 on all parameters sets we obtain K values of the next-n-years Best Estimate. For each batch of simulations s we use the posterior distribution of parameters’ sets computed at step 1 in order to reweight the Best Estimates in light of the realized simulations. For every s we obtain one value:
- As before we use the simulated cumulative developments stored in the array to obtain a new array of simulated incremental developments:for .
- Having at disposal simulated diagonals and the n years Best Estimates it is possible to obtain the predictive distribution of the next-n-years obligations. For every value of the Best Estimate we add a realized development of payments for the first n years. For the s-th value of the Best Estimate we have K simulated scenarios of developments. Hence, we sample a scenario and we add it to the s-th realization of the n years Best Estimate:where w is a random number between 1 and K. Again, by iterating this process over all the S batches of simulations, we finally obtain a predictive distribution of the next-n-years obligations.
Appendix B. Data

{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Accident | Development Years | Earned | ||||||||||
|---|---|---|---|---|---|---|---|---|---|---|---|---|
| Years | 0 | 1 | 2 | 3 | 4 | 5 | 6 | 7 | 8 | 9 | 10 | Premium |
| 0 | 50,145.22 | 108,869.70 | 118,157.58 | 123,434.78 | 128,075.39 | 128,620.06 | 133,727.32 | 137,249.55 | 139,652.12 | 140,224.86 | 140,668.36 | 187,498.55 |
| 1 | 66,529.63 | 120,628.35 | 135,607.54 | 138,325.18 | 141,986.84 | 143,254.48 | 148,625.10 | 151,619.72 | 153,318.71 | 154,132.17 | 209,638.07 | |
| 2 | 67,249.55 | 120,410.05 | 132,236.67 | 139,283.38 | 143,759.42 | 146,514.73 | 148,870.33 | 153,126.08 | 155,180.52 | 217,899.50 | ||
| 3 | 71,335.57 | 127,456.02 | 140,645.27 | 147,157.83 | 147,993.28 | 150,819.76 | 152,306.83 | 155,879.16 | 218,391.25 | |||
| 4 | 76,200.45 | 146,032.65 | 160,291.64 | 168,785.03 | 171,834.53 | 172,940.93 | 176,259.91 | 234,357.93 | ||||
| 5 | 75,407.41 | 155,886.72 | 174,502.23 | 181,683.61 | 189,903.49 | 192,026.62 | 243,614.50 | |||||
| 6 | 60,923.30 | 115,047.56 | 122,880.04 | 131,293.91 | 136,295.32 | 216,966.57 | ||||||
| 7 | 60,214.31 | 120,050.52 | 132,031.54 | 137,061.78 | 197,976.27 | |||||||
| 8 | 51,171.99 | 100,917.33 | 113,701.60 | 192,253.76 | ||||||||
| 9 | 61,167.95 | 112,561.89 | 211,541.73 | |||||||||
| 10 | 70,564.48 | 247,891.00 | ||||||||||
| Accident | Development Years | ||||||||||
|---|---|---|---|---|---|---|---|---|---|---|---|
| Years | 0 | 1 | 2 | 3 | 4 | 5 | 6 | 7 | 8 | 9 | 10 |
| 0 | 10.88 | 11.60 | 11.68 | 11.72 | 11.76 | 11.76 | 11.80 | 11.83 | 11.85 | 11.85 | 11.85 |
| 1 | 11.07 | 11.70 | 11.81 | 11.84 | 11.86 | 11.87 | 11.91 | 11.93 | 11.94 | 11.95 | |
| 2 | 11.13 | 11.70 | 11.79 | 11.84 | 11.88 | 11.90 | 11.91 | 11.94 | 11.95 | ||
| 3 | 11.15 | 11.76 | 11.85 | 11.90 | 11.90 | 11.92 | 11.93 | 11.96 | |||
| 4 | 11.25 | 11.89 | 11.99 | 12.04 | 12.05 | 12.06 | 12.08 | ||||
| 5 | 11.23 | 11.96 | 12.07 | 12.11 | 12.15 | 12.17 | |||||
| 6 | 11.01 | 11.65 | 11.72 | 11.79 | 11.82 | ||||||
| 7 | 10.98 | 11.70 | 11.79 | 11.83 | |||||||
| 8 | 10.84 | 11.52 | 11.64 | ||||||||
| 9 | 11.01 | 11.63 | |||||||||
| 10 | 11.12 | ||||||||||
| Accident | Development Years | ||||||||||
|---|---|---|---|---|---|---|---|---|---|---|---|
| Years | 0 | 1 | 2 | 3 | 4 | 5 | 6 | 7 | 8 | 9 | 10 |
| 0 | 10.95 | 11.60 | 11.70 | 11.74 | 11.77 | 11.78 | 11.81 | 11.83 | 11.85 | 11.85 | 11.85 |
| 1 | 11.04 | 11.70 | 11.80 | 11.84 | 11.87 | 11.88 | 11.90 | 11.93 | 11.94 | 11.94 | |
| 2 | 11.05 | 11.71 | 11.81 | 11.85 | 11.88 | 11.89 | 11.91 | 11.94 | 11.95 | ||
| 3 | 11.07 | 11.73 | 11.83 | 11.87 | 11.90 | 11.91 | 11.93 | 11.96 | |||
| 4 | 11.23 | 11.88 | 11.98 | 12.02 | 12.05 | 12.06 | 12.09 | ||||
| 5 | 11.32 | 11.98 | 12.08 | 12.12 | 12.15 | 12.16 | |||||
| 6 | 10.99 | 11.64 | 11.74 | 11.79 | 11.81 | ||||||
| 7 | 11.03 | 11.69 | 11.79 | 11.83 | |||||||
| 8 | 10.88 | 11.53 | 11.63 | ||||||||
| 9 | 10.98 | 11.64 | |||||||||
| 10 | 11.17 | ||||||||||
| Years | Prior Loss Ratio | Posterior Loss Ratio |
|---|---|---|
| 1 | 0.73756 | 0.7359 |
| 2 | 0.7178 | 0.7163 |
| 3 | 0.731 | 0.7282 |
| 4 | 0.806 | 0.8045 |
| 5 | 0.85 | 0.8487 |
| 6 | 0.685 | 0.6838 |
| 7 | 0.787 | 0.7863 |
| 8 | 0.705 | 0.7053 |
| 9 | 0.72 | 0.7209 |
| 10 | 0.74 | 0.7407 |
References
- Berger, James O., José M. Bernardo, and Dongchu Sun. 2009. The formal definition of reference priors. The Annals of Statistics 37: 905–38. [Google Scholar] [CrossRef]
- Bornhuetter, Ronald L., and Ronald E. Ferguson. 1972. The actuary and IBNR. In Proceedings of the Casualty Actuarial Society. Arlington: Casualty Actuarial Society, pp. 181–95. [Google Scholar]
- Dacorogna, Michel, Alessandro Ferriero, and David Krief. 2018. One-Year Change Methodologies for Fixed-Sum Insurance Contracts. Risks 6: 75. [Google Scholar] [CrossRef] [Green Version]
- Diers, Dorothea. 2009. Stochastic re-reserving in multi-year internal models—An approach based on simulations. Presented at Astin Colloquium, Helsinki, Finland, June 1–4. [Google Scholar]
- Efron, Bradley. 2011. The Bootstrap and Markov Chain Monte Carlo. The Journal of Biopharmaceutical Statistics 21: 1052–62. [Google Scholar] [CrossRef] [PubMed]
- England, Peter D., and Richard Verrall. 1999. Analytic and bootstrap estimates of prediction errors in claims reserving. Insurance Mathematics and Economics 25: 281–93. [Google Scholar] [CrossRef]
- European Commission. 2009. Directive 2009/138/EC of the European Parliament and of the Council of 25 November 2009 on the Taking-Up and Pursuit of the Business of Insurance and Reinsurance (Solvency II). Luxembourg: European Commission. [Google Scholar]
- Frees, Edward W., Richard A. Derrig, and Glenn Meyers, eds. 2016. Predictive Analytics Applications in Actuarial Science. Cambridge: Cambridge University Press. [Google Scholar]
- Friedland, Jacqueline. 2010. Estimating Unpaid Claims Using Basic Techniques. Casualty Actuarial Society. Available online: https://www.casact.org/press/index.cfm?fa=viewArticle&articleID=816 (accessed on 19 November 2020).
- Hastie, Trevor, Robert Tibshirani, and Jerome Friedman. 2009. The Elements of Statistical Learning, Data Mining Inference and Prediction, 2nd ed. Stanford: Stanford University. [Google Scholar]
- Hindley, David. 2017. Deterministic Reserving Methods. In Claims Reserving in General Insurance (International Series on Actuarial Science). Cambridge: Cambridge University Press, pp. 40–145. [Google Scholar]
- Hoffman, Matthew D., and Andrew Gelman. 2014. The No-U-Turn Sampler: Adaptively Setting Path Lengths in Hamiltonian Monte Carlo. Journal of Machine Learning Research 15: 1351–81. [Google Scholar]
- Klugman, Stuart A. 1992. Bayesian Statistics in Actuarial Science. Boston: Kluwer. [Google Scholar]
- Mack, Thomas. 1993. Distribution Free calculation of the standard error of Chain Ladder reserve estimates. ASTIN Bulletin The Journal of the IAA 23: 213–25. [Google Scholar] [CrossRef] [Green Version]
- Meyers, Glenn. 2017. A Cost of Capital Risk Margin Formula For Non-Life Insurance Liabilities. Variance. [Google Scholar]
- Meyers, Glenn. 2015. Stochastic Loss Reserving Using Bayesian MCMC Models. CAS monograph series; Arlington: Casualty Actuarial Society. [Google Scholar]
- Ntzoufras, Ioannis, and Petros Dellaportas. 2002. Bayesian Modelling of Outstanding Liabilities Incorporating Claim Count Uncertainty. North American Actuarial Journal 6: 113–28. [Google Scholar] [CrossRef] [Green Version]
- Peters, Gareth W., Rodrigo S. Targino, and Mario V. Wüthrich. 2017. Full bayesian analysis of claims reserving uncertainty. Insurance Mathematics and Economics 73: 41–53. [Google Scholar] [CrossRef]
- Wüthrich, Mario V., and Michael Merz. 2007. Stochastic Claims Reserving Methods in Insurance. Hoboken: Wiley. [Google Scholar]
- Wüthrich, Mario V., Michael Merz, Hans Bühlmann, Massimo De Felice, Alois Gisler, and Franco Moriconi. 2008. Modelling the Claims Development Result for Solvency Purpose. CAS E-Forum. [Google Scholar]
- Wüthrich, Mario V. 2007. Using a Bayesian Approach for Claims Reserving. Variance 1: 292–301. [Google Scholar]
| 1. | In this framework, the dynamics of the one-year change in P&C insurance reserves estimation has been also studied in Dacorogna et al. (2018) by analyzing the process that leads to the ultimate risk in the case of “fixed-sum” insurance contracts. |
| 2. | Statistical literature drew many parallels between Bayesian MCMC and Bootstrap procedures. In statistical inference, these algorithms represent two different ways offered respectively by the Bayesian and frequentist paradigms to assess parameter uncertainty (see, e.g., Efron (2011); Hastie et al. (2009)). The Bootstrap algorithm, and especially its non-parametric version, generates many samples from the data, from which is possible to obtain the distribution of a statistic or a parameter, mimicking the Bayesian effect of a posterior distribution. This distribution is produced in a quick and simple way, requiring no probabilistic assumptions, no prior elicitation nor MCMC procedures and can be effectively considered an “approximation of a non-parametric, non-informative posterior distribution” (Hastie et al. 2009). |
| 3. | In general, parameters could be more than two and left up to the needs of the modeler. |
| 4. | Anyway this structure is not exclusive of Bayesian models as it is applied also in frequentist models, as for instance the Over-Dispersed Poisson bootstrap Model England and Verrall (1999). |
| 5. | For instance, different distributions may be chosen for different accident years i. |
| 6. | According to Article 76 of the Solvency II Directive European Commission (2009), the claims reserve must be equal to the current amount that insurance and reinsurance undertakings would have to pay if they were to transfer their insurance and reinsurance obligations immediately to another insurance or reinsurance undertaking. This definition leads to a claims reserve evaluated as the sum of the best estimate and risk margin. As prescribed by Solvency II, risk margin is not considered in (8) to avoid problems of circularity. |
| 7. | Cumulative payments are reported in Table A1. |
| 8. | As a general rule we advise to check the order of magnitude of parameters implied by the observations in the triangle, in order to feed the model with consistent inputs and speed up convergence. |
| 9. | With adapt-delta = 0.98 and maximum treedepth = 13. |
| 10. | Computed by the package rstan. |
| 11. | For each parameters set we calculated the expected value of the lower triangle and discounted it according to the December 2018 Eiopa term structure. Subsequently, we obtained a CCL BE by calculating the mean of these discounted expected values. |


| Simulation Array | |||||
|---|---|---|---|---|---|
| ⋯ | ⋯ | ||||
| 1 | ⋯ | ⋯ | |||
| ⋯ | ⋯ | ⋯ | |||
| s | ⋯ | ⋯ | |||
| ⋯ | ⋯ | ⋯ | |||
| S | ⋯ | ⋯ | |||
| Years | Prior Loss Ratio | Log-Mean | Log-Std |
|---|---|---|---|
| 1 | 0.73756 | −0.30645 | 0.000005 |
| 2 | 0.7178 | −0.3336 | 0.000005 |
| 3 | 0.731 | −0.31531 | 0.001 |
| 4 | 0.806 | −0.2177 | 0.008 |
| 5 | 0.85 | −0.16455 | 0.025 |
| 6 | 0.685 | −0.38037 | 0.035 |
| 7 | 0.787 | −0.24156 | 0.05 |
| 8 | 0.705 | −0.35159 | 0.08 |
| 9 | 0.72 | −0.33054 | 0.08 |
| 10 | 0.74 | −0.30314 | 0.085 |
| Effective Sample Size | |||||||
|---|---|---|---|---|---|---|---|
| - | 9740 | 9687 | 10,152 | ||||
| - | 10,214 | 9719 | 9586 | ||||
| - | 10,130 | 9564 | 10,361 | ||||
| - | 10,010 | 9137 | 9244 | ||||
| 10,024 | 10,290 | 9413 | 10,089 | ||||
| 9902 | 9940 | 9343 | 10,048 | ||||
| 10,362 | 9595 | 10,044 | 10,387 | ||||
| 9736 | 9875 | 9626 | 9767 | ||||
| 9874 | 9743 | 9773 | 9595 | ||||
| 9936 | 9605 | 9863 | 9935 | ||||
| 10,166 | 9747 | 9872 | 10,064 | ||||
| Reserve | CV | 99% Quantile | ||||
|---|---|---|---|---|---|---|
| Years | CCL | Bootstrap-ODP | CCL | Bootstrap-ODP | CCL | Bootstrap-ODP |
| 1 | 144.21 | 502.86 | 4.27 | 1.61 | 1914.01 | 3148.01 |
| 2 | 910.77 | 1259.90 | 0.67 | 0.91 | 2681.07 | 4706.00 |
| 3 | 3138.16 | 3448.71 | 0.21 | 0.50 | 4901.30 | 8262.38 |
| 4 | 9010.50 | 8305.66 | 0.18 | 0.32 | 13,046.03 | 15,440.29 |
| 5 | 11,923.17 | 13,865.66 | 0.18 | 0.25 | 16,994.27 | 22,596.10 |
| 6 | 10,111.27 | 11,535.85 | 0.18 | 0.26 | 14,627.64 | 19,249.20 |
| 7 | 15,857.02 | 15,843.07 | 0.15 | 0.22 | 21,780.24 | 24,550.01 |
| 8 | 17,128.40 | 18,939.31 | 0.17 | 0.20 | 24,191.44 | 28,935.08 |
| 9 | 32,759.73 | 32,282.18 | 0.15 | 0.16 | 45,654.94 | 45,031.20 |
| 10 | 104,906.96 | 103,560.53 | 0.17 | 0.12 | 153,970.68 | 133,452.21 |
| CCL | Bootstrap-ODP | Mack | |
|---|---|---|---|
| Mean | 205,890.19 | 209,543.74 | 209,255.94 |
| SD | 19,912.03 | 18,872.71 | 16,335.99 |
| CV | 0.097 | 0.090 | 0.078 |
| Skewness | 0.46 | 0.06 | - |
| Kurtosis | 4.43 | 3.05 | - |
| 1st quartile | 192,706.64 | 196,582.00 | - |
| Median | 204,958.17 | 209,066.00 | - |
| 3rd quartile | 217,790.79 | 222,285.75 | - |
| 99% quantile | 257,935.78 | 254,001.40 | - |
| 99.5% quantile | 268,426.73 | 259,138.41 | - |
| Max | 357,274.68 | 282,362.20 | - |
| One-Year CCL | Re-Reserving | Merz–Wüthrich | |
|---|---|---|---|
| Best Estimate | 206,902.20 | 210,651.33 | 210,651.33 |
| Mean of one-year obligations | 205,756.09 | 209,184.98 | 209,255.94 |
| SD | 17,325.32 | 14,748.63 | 13,421.28 |
| CV | 0.084 | 0.071 | 0.071 |
| One Year on Total | 0.87 | 0.78 | 0.90 |
| Skewness | 0.36 | 0.18 | 0.21 |
| Kurtosis | 3.86 | 2.98 | 3.08 |
| Quantile 75% | 216,180.39 | 219,181.26 | 220,356.51 |
| Quantile 95% | 251,118.22 | 245,427.65 | 247,556.06 |
| Quantile 99.5% | 259,668.71 | 248,781.01 | 251,946.20 |
| Max | 313,101.79 | 267,166.99 | - |
| Expected Shortfall 99% | 262,529.18 | 250,566.40 | 253,601.99 |
| Reserve Risk SCR | 52,766.51 | 38,129.68 | 41,294.86 |
| SCR over BE | 25.50% | 18.10% | 19.60% |
Publisher’s Note: MDPI stays neutral with regard to jurisdictional claims in published maps and institutional affiliations. |
© 2020 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (http://creativecommons.org/licenses/by/4.0/).
Share and Cite
Ercole, C.G.; Paolo, C.G. A Bayesian Internal Model for Reserve Risk: An Extension of the Correlated Chain Ladder. Risks 2020, 8, 125. https://doi.org/10.3390/risks8040125
Ercole CG, Paolo CG. A Bayesian Internal Model for Reserve Risk: An Extension of the Correlated Chain Ladder. Risks. 2020; 8(4):125. https://doi.org/10.3390/risks8040125
Chicago/Turabian StyleErcole, Carnevale Giulio, and Clemente Gian Paolo. 2020. "A Bayesian Internal Model for Reserve Risk: An Extension of the Correlated Chain Ladder" Risks 8, no. 4: 125. https://doi.org/10.3390/risks8040125
APA StyleErcole, C. G., & Paolo, C. G. (2020). A Bayesian Internal Model for Reserve Risk: An Extension of the Correlated Chain Ladder. Risks, 8(4), 125. https://doi.org/10.3390/risks8040125