_Bryant.png)
Large Language Models in Healthcare and Medical Domain: A Review


Abstract
:1. Introduction
- Section 2 provides a foundational understanding of LLMs, covering their key architectures such as transformers, foundational models, and multi-modal capabilities.
- In Section 3, the focus shifts to the application of LLMs in healthcare, discussing their use cases and the metrics for assessing their performance within clinical settings.
- Section 4 critically examines the challenges associated with LLMs in healthcare, including issues related to explainability, security, bias, and ethical considerations.
- This paper concludes by summarizing the findings, highlighting the transformative potential of LLMs while acknowledging the need for careful implementation to navigate their limitations and ethical implications.
2. Review of Large Language Models
2.1. Transformers
2.2. Large Foundational Models
2.3. Multimodal Language Models
3. Large Language Models in Healthcare and Medicine
3.1. Large Language Models for Medical and Healthcare Applications
3.2. Use Cases of Large Language Models in Healthcare
- Medical Diagnosis: Certain clinical procedures may depend on the use of data analysis, clinical research, and recommendations [50,51]. LLMs can potentially contribute to medical diagnosis by conducting analyses on patient symptoms, medical records, and pertinent data, potentially aiding in the identification of potential illnesses or conditions with a certain degree of accuracy. Large language models have the potential to contribute to several aspects, such as clinical decision assistance, clinical trial recruiting, clinical data administration, research support, patient education, and other related areas [52,53]. Corroborating this perspective, methodologies utilizing transformer models such as BERT, RoBERTa, and DistilBERT were used for the purpose of predicting COVID-19 diagnosis based on textual descriptions of acute alterations in chemosensation [54]. Similarly, a number of alternative investigations have been undertaken within the literature, including strategies using large language models for the diagnosis of Alzheimer’s disease [55] and dementia [56]. Furthermore, a corpus of literature has emerged advocating the integration of large language model chatbots to cater to analogous objectives [57,58,59,60].
- Patient Care: Large language models have emerged as transformative tools with the capacity to significantly enhance the realm of patient care [61]. Through the provision of personalized recommendations [62], customized treatment strategies, and continual monitoring of patients’ advancement throughout their medical journey [63], LLMs offer the promise of revolutionizing healthcare delivery. By harnessing the capabilities of LLMs, healthcare providers can ensure a more personalized and patient-centric approach to care. This technology enables the delivery of precise and well-informed medical guidance [64], aligning interventions with patients’ distinct requirements and circumstances. The effective use of LLMs within clinical practice not only enhances patient outcomes, it enables healthcare professionals to make data-driven decisions, leading to enhanced patient care. As LLMs continue to advance, the potential for augmenting patient care through personalized recommendations and ongoing monitoring remains a promising trajectory in modern medicine [65]. In essence, LLMs represent a pivotal leap forward, holding the capacity to reshape the landscape of patient care by fostering precision, adaptability, and patient-centeredness [66].
- Clinical Decision Support: Language models (LMs) have evolved into crucial decision support tools for healthcare professionals. By analyzing extensive medical data, LMs can provide evidence-based recommendations, enhancing diagnostic accuracy, treatment selection, and overall patient care. This fusion of artificial intelligence with healthcare expertise holds immense promise for improved medical decision-making. A body of existing research has illuminated promising prospects for the application of language models within clinical decision support, particularly within the domains of radiology [67], oncology [68], and dermatology [69].
- Medical Literature Analysis: Large language models (LLMs) exhibit remarkable efficiency in comprehensively reviewing and succinctly summarizing extensive volumes of medical literature. This capability aids both researchers and clinicians in maintaining topicality with cutting-edge developments and evidence-based methodologies, ultimately fostering informed and optimized healthcare practices. In a fast-evolving field like healthcare, the ability to maintain currency with the latest advancements is paramount, and LLMs can play a pivotal role in ensuring that healthcare remains at the forefront of innovation and evidence-based care delivery [70,71].
- Drug Discovery: Large language models have a significant impact in facilitating drug discovery through their capacity to scrutinize intricate molecular structures, discern promising compounds with therapeutic potential, and forecast the efficacy and safety profiles of these candidates [72,73]. Chemical language models have exhibited notable achievements in the domain of de novo drug design [74]. In a corresponding study, the authors explored the utilization of pretrained biochemical language models to initialize targeted molecule generation models, comparing one-stage and two-stage warm start strategies as well as evaluating compound generation using beam search and sampling. They ultimately demonstrated that warm-started models outperformed baseline models and that the one-stage strategy exhibited superior generalization in terms of docking evaluation and benchmark metrics, while beam search proved more effective than sampling for assessing compound quality [75].
- Virtual Medical Assistants and Health Chatbots: LLMs can also serve as the underlying intelligence for health chatbots, which are revolutionizing the healthcare landscape by delivering continuous and personalized health-related support. Such chatbots can offer medical advice, monitor health conditions, and even extend their services to encompass mental health support, a particularly pertinent aspect of healthcare given the growing awareness of mental well-being [57,60].
- Radiology and Imaging: By integrating visual and textual data, multimodal visual language models hold significant promise for augmenting medical imaging analysis. Radiologists can benefit from these models as they facilitate the early identification of abnormalities in medical images and contribute to the generation of more precise and comprehensive diagnostic interpretations, ultimately advancing the accuracy and efficiency of diagnostic processes in the field of medical imaging [67,76,77,78,79,80,81].
- Automated Medical Report Synthesis from Imaging Data: Automated medical report generation from images is crucial for streamlining the time-consuming and error-prone task faced by pathologists and radiologists. This emerging field at the intersection of healthcare and artificial intelligence (AI) aims to alleviate the burden on experienced medical practitioners and enhance the accuracy of less experienced ones. The integration of AI with medical imaging facilitates the automatic drafting of reports, encompassing abnormal findings, relevant normal observations, and patient history. Early efforts employed data-driven neural networks, combining convolutional and recurrent models for single-sentence reports; however, limitations arose in capturing the complexity of real medical scenarios [5]. Recent advances have leveraged LLMs such as ChatCAD [67], enabling more sophisticated applications. ChatCAD enhances medical image CAD networks, yielding significant improvements in report generation. ChatCAD+ further addresses writing style mismatches, ensuring universality and reliability across diverse medical domains by incorporating a template retrieval system for consistency with human expertise [41]. In [82], the authors used a pretrained language model (PLM) and in-context learning (ICL) to generate clinical notes from doctor–patient conversations. These integrated systems signify a pivotal advancement in automating medical report generation through the strategic utilization of LLMs.
3.3. Explainable AI Methods for Interpreting Healthcare LLMs
3.4. Future Trajectories of Large Language Models in Healthcare
3.5. Performance Evaluation and Benchmarks
3.6. Quantitative Performance Comparison of LLMs in the Healthcare Domain
4. Limitations and Open Challenges
4.1. Model Explainability and Transparency
4.2. Security and Privacy Considerations
4.3. Bias and Fairness
4.4. Hallucinations and Fabricated Information
4.5. Legal and Ethical Reasons
5. Conclusions
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Data Availability Statement
Conflicts of Interest
References
- Shi, H.; Peng, W.; Chen, H.; Liu, X.; Zhao, G. Multiscale 3D-shift graph convolution network for emotion recognition from human actions. IEEE Intell. Syst. 2022, 37, 103–110. [Google Scholar] [CrossRef]
- Yu, H.; Cheng, X.; Peng, W.; Liu, W.; Zhao, G. Modality unifying network for visible-infrared person re-identification. In Proceedings of the IEEE/CVF International Conference on Computer Vision, Paris, France, 1–6 October 2023; pp. 11185–11195. [Google Scholar]
- Li, Y.; Peng, W.; Zhao, G. Micro-expression action unit detection with dual-view attentive similarity-preserving knowledge distillation. In Proceedings of the 2021 16th IEEE International Conference on Automatic Face and Gesture Recognition (FG 2021), Jodhpur, India, 15–18 December 2021; IEEE: Piscataway, NJ, USA, 2021; pp. 1–8. [Google Scholar]
- Hong, X.; Peng, W.; Harandi, M.; Zhou, Z.; Pietikäinen, M.; Zhao, G. Characterizing subtle facial movements via Riemannian manifold. ACM Trans. Multimed. Comput. Commun. Appl. (TOMM) 2019, 15, 94. [Google Scholar] [CrossRef]
- He, K.; Mao, R.; Lin, Q.; Ruan, Y.; Lan, X.; Feng, M.; Cambria, E. A survey of large language models for healthcare: From data, technology, and applications to accountability and ethics. arXiv 2023, arXiv:2310.05694. [Google Scholar]
- Wang, Y.; Zhao, Y.; Petzold, L. Are Large Language Models Ready for Healthcare? A Comparative Study on Clinical Language Understanding. arXiv 2023, arXiv:2304.05368. [Google Scholar]
- Yu, P.; Xu, H.; Hu, X.; Deng, C. Leveraging generative AI and large Language models: A Comprehensive Roadmap for Healthcare Integration. Healthcare 2023, 11, 2776. [Google Scholar] [CrossRef] [PubMed]
- Peng, W.; Feng, L.; Zhao, G.; Liu, F. Learning optimal k-space acquisition and reconstruction using physics-informed neural networks. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, New Orleans, LA, USA, 18–24 June 2022; pp. 20794–20803. [Google Scholar]
- Peng, W.; Adeli, E.; Bosschieter, T.; Park, S.H.; Zhao, Q.; Pohl, K.M. Generating realistic brain mris via a conditional diffusion probabilistic model. In Proceedings of the International Conference on Medical Image Computing and Computer-Assisted Intervention, Vancouver, BC, Canada, 8–12 October 2023; Springer: Berlin/Heidelberg, Germany, 2023; pp. 14–24. [Google Scholar]
- Brown, T.; Mann, B.; Ryder, N.; Subbiah, M.; Kaplan, J.D.; Dhariwal, P.; Neelakantan, A.; Shyam, P.; Sastry, G.; Askell, A.; et al. Language models are few-shot learners. Adv. Neural Inf. Process. Syst. 2020, 33, 1877–1901. [Google Scholar]
- OpenAI. GPT-4 Technical Report. 2023. Available online: https://arxiv.org/abs/2303.08774 (accessed on 8 July 2024).
- Zhang, C.; Zhang, C.; Li, C.; Qiao, Y.; Zheng, S.; Dam, S.K.; Zhang, M.; Kim, J.U.; Kim, S.T.; Choi, J.; et al. One small step for generative AI, one giant leap for agi: A complete survey on chatgpt in aigc era. arXiv 2023, arXiv:2304.06488. [Google Scholar]
- Touvron, H.; Lavril, T.; Izacard, G.; Martinet, X.; Lachaux, M.A.; Lacroix, T.; Rozière, B.; Goyal, N.; Hambro, E.; Azhar, F.; et al. Llama: Open and efficient foundation language models. arXiv 2023, arXiv:2302.13971. [Google Scholar]
- Lee, J.; Yoon, W.; Kim, S.; Kim, D.; Kim, S.; So, C.H.; Kang, J. BioBERT: A pre-trained biomedical language representation model for biomedical text mining. Bioinformatics 2020, 36, 1234–1240. [Google Scholar] [CrossRef] [PubMed]
- Huang, K.; Altosaar, J.; Ranganath, R. Clinicalbert: Modeling clinical notes and predicting hospital readmission. arXiv 2019, arXiv:1904.05342. [Google Scholar]
- Petroni, F.; Rocktäschel, T.; Lewis, P.; Bakhtin, A.; Wu, Y.; Miller, A.H.; Riedel, S. Language models as knowledge bases? arXiv 2019, arXiv:1909.01066. [Google Scholar]
- Radford, A.; Narasimhan, K.; Salimans, T.; Sutskever, I. Improving Language Understanding by Generative Pre-Training. 2018. Available online: https://api.semanticscholar.org/CorpusID:49313245 (accessed on 8 July 2024).
- Chowdhery, A.; Narang, S.; Devlin, J.; Bosma, M.; Mishra, G.; Roberts, A.; Barham, P.; Chung, H.W.; Sutton, C.; Gehrmann, S.; et al. Palm: Scaling language modeling with pathways. arXiv 2022, arXiv:2204.02311. [Google Scholar]
- Radford, A.; Wu, J.; Child, R.; Luan, D.; Amodei, D.; Sutskever, I. Language models are unsupervised multitask learners. OpenAI Blog 2019, 1, 9. [Google Scholar]
- Vaswani, A.; Shazeer, N.; Parmar, N.; Uszkoreit, J.; Jones, L.; Gomez, A.N.; Kaiser, Ł.; Polosukhin, I. Attention is all you need. Adv. Neural Inf. Process. Syst. 2017, 30, 5998–6008. [Google Scholar]
- Fedus, W.; Zoph, B.; Shazeer, N. Switch transformers: Scaling to trillion parameter models with simple and efficient sparsity. J. Mach. Learn. Res. 2022, 23, 5232–5270. [Google Scholar]
- Du, N.; Huang, Y.; Dai, A.M.; Tong, S.; Lepikhin, D.; Xu, Y.; Krikun, M.; Zhou, Y.; Yu, A.W.; Firat, O.; et al. Glam: Efficient scaling of language models with mixture-of-experts. In Proceedings of the International Conference on Machine Learning, Baltimore, MD, USA, 17–23 July 2022; pp. 5547–5569. [Google Scholar]
- Wang, H.; Li, J.; Wu, H.; Hovy, E.; Sun, Y. Pre-trained language models and their applications. Engineering 2023, 25, 51–65. [Google Scholar] [CrossRef]
- Wei, J.; Bosma, M.; Zhao, V.Y.; Guu, K.; Yu, A.W.; Lester, B.; Du, N.; Dai, A.M.; Le, Q.V. Finetuned language models are zero-shot learners. arXiv 2021, arXiv:2109.01652. [Google Scholar]
- Rombach, R.; Blattmann, A.; Lorenz, D.; Esser, P.; Ommer, B. High-resolution image synthesis with latent diffusion models. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, New Orleans, LA, USA, 18–24 June 2022; pp. 10684–10695. [Google Scholar]
- Rawte, V.; Sheth, A.; Das, A. A survey of hallucination in large foundation models. arXiv 2023, arXiv:2309.05922. [Google Scholar]
- Yin, S.; Fu, C.; Zhao, S.; Li, K.; Sun, X.; Xu, T.; Chen, E. A Survey on Multimodal Large Language Models. arXiv 2023, arXiv:2306.13549. [Google Scholar]
- Wu, C.; Yin, S.; Qi, W.; Wang, X.; Tang, Z.; Duan, N. Visual chatgpt: Talking, drawing and editing with visual foundation models. arXiv 2023, arXiv:2303.04671. [Google Scholar]
- Li, J.; Li, D.; Savarese, S.; Hoi, S. Blip-2: Bootstrapping language-image pre-training with frozen image encoders and large language models. In Proceedings of the International Conference on Machine Learning, Honolulu, HI, USA, 23–29 July 2023; pp. 19730–19742. [Google Scholar]
- Zong, Z.; Ma, B.; Shen, D.; Song, G.; Shao, H.; Jiang, D.; Li, H.; Liu, Y. Mova: Adapting mixture of vision experts to multimodal context. arXiv 2024, arXiv:2404.13046. [Google Scholar]
- Lin, B.; Tang, Z.; Ye, Y.; Cui, J.; Zhu, B.; Jin, P.; Zhang, J.; Ning, M.; Yuan, L. Moe-llava: Mixture of experts for large vision-language models. arXiv 2024, arXiv:2401.15947. [Google Scholar]
- Li, J.; Wang, X.; Zhu, S.; Kuo, C.W.; Xu, L.; Chen, F.; Jain, J.; Shi, H.; Wen, L. Cumo: Scaling multimodal llm with co-upcycled mixture-of-experts. arXiv 2024, arXiv:2405.05949. [Google Scholar]
- Thirunavukarasu, A.J.; Ting, D.S.J.; Elangovan, K.; Gutierrez, L.; Tan, T.F.; Ting, D.S.W. Large language models in medicine. Nat. Med. 2023, 29, 1930–1940. [Google Scholar] [CrossRef]
- Devlin, J.; Chang, M.W.; Lee, K.; Toutanova, K. Bert: Pre-training of deep bidirectional transformers for language understanding. arXiv 2018, arXiv:1810.04805. [Google Scholar]
- Liu, Y.; Ott, M.; Goyal, N.; Du, J.; Joshi, M.; Chen, D.; Levy, O.; Lewis, M.; Zettlemoyer, L.; Stoyanov, V. Roberta: A robustly optimized bert pretraining approach. arXiv 2019, arXiv:1907.11692. [Google Scholar]
- Labrak, Y.; Bazoge, A.; Morin, E.; Gourraud, P.A.; Rouvier, M.; Dufour, R. BioMistral: A Collection of Open-Source Pretrained Large Language Models for Medical Domains. arXiv 2024, arXiv:2402.10373. [Google Scholar]
- Singhal, K.; Tu, T.; Gottweis, J.; Sayres, R.; Wulczyn, E.; Hou, L.; Clark, K.; Pfohl, S.; Cole-Lewis, H.; Neal, D.; et al. Towards expert-level medical question answering with large language models. arXiv 2023, arXiv:2305.09617. [Google Scholar]
- Liu, Z.; Li, Y.; Shu, P.; Zhong, A.; Yang, L.; Ju, C.; Wu, Z.; Ma, C.; Luo, J.; Chen, C.; et al. Radiology-Llama2: Best-in-Class Large Language Model for Radiology. arXiv 2023, arXiv:2309.06419. [Google Scholar]
- Liu, Z.; Yu, X.; Zhang, L.; Wu, Z.; Cao, C.; Dai, H.; Zhao, L.; Liu, W.; Shen, D.; Li, Q.; et al. Deid-gpt: Zero-shot medical text de-identification by gpt-4. arXiv 2023, arXiv:2303.11032. [Google Scholar]
- Umapathi, L.K.; Pal, A.; Sankarasubbu, M. Med-halt: Medical domain hallucination test for large language models. arXiv 2023, arXiv:2307.15343. [Google Scholar]
- Zhao, Z.; Wang, S.; Gu, J.; Zhu, Y.; Mei, L.; Zhuang, Z.; Cui, Z.; Wang, Q.; Shen, D. ChatCAD+: Towards a Universal and Reliable Interactive CAD using LLMs. arXiv 2023, arXiv:2305.15964. [Google Scholar] [CrossRef] [PubMed]
- Luo, R.; Sun, L.; Xia, Y.; Qin, T.; Zhang, S.; Poon, H.; Liu, T.Y. BioGPT: Generative pre-trained transformer for biomedical text generation and mining. Briefings Bioinform. 2022, 23, bbac409. [Google Scholar] [CrossRef] [PubMed]
- Yang, X.; Chen, A.; PourNejatian, N.; Shin, H.C.; Smith, K.E.; Parisien, C.; Compas, C.; Martin, C.; Flores, M.G.; Zhang, Y.; et al. Gatortron: A large clinical language model to unlock patient information from unstructured electronic health records. arXiv 2022, arXiv:2203.03540. [Google Scholar]
- Yuan, H.; Yuan, Z.; Gan, R.; Zhang, J.; Xie, Y.; Yu, S. BioBART: Pretraining and evaluation of a biomedical generative language model. arXiv 2022, arXiv:2204.03905. [Google Scholar]
- Lu, Q.; Dou, D.; Nguyen, T. ClinicalT5: A generative language model for clinical text. In Proceedings of the Findings of the Association for Computational Linguistics: EMNLP, Abu Dhabi, United Arab Emirates, 7–11 December 2022; pp. 5436–5443. [Google Scholar]
- Yuan, Z.; Liu, Y.; Tan, C.; Huang, S.; Huang, F. Improving biomedical pretrained language models with knowledge. arXiv 2021, arXiv:2104.10344. [Google Scholar]
- Raj, D.; Sahu, S.; Anand, A. Learning local and global contexts using a convolutional recurrent network model for relation classification in biomedical text. In Proceedings of the 21st Conference on Computational Natural Language Learning (CoNLL 2017), Vancouver, BC, Canada, 3–4 August 2017; pp. 311–321. [Google Scholar]
- Lyu, C.; Chen, B.; Ren, Y.; Ji, D. Long short-term memory RNN for biomedical named entity recognition. BMC Bioinform. 2017, 18, 462. [Google Scholar] [CrossRef] [PubMed]
- Dasgupta, I.; Lampinen, A.K.; Chan, S.C.; Creswell, A.; Kumaran, D.; McClelland, J.L.; Hill, F. Language models show human-like content effects on reasoning. arXiv 2022, arXiv:2207.07051. [Google Scholar]
- Singhal, K.; Azizi, S.; Tu, T.; Mahdavi, S.S.; Wei, J.; Chung, H.W.; Scales, N.; Tanwani, A.; Cole-Lewis, H.; Pfohl, S.; et al. Large language models encode clinical knowledge. Nature 2023, 620, 172–180. [Google Scholar] [CrossRef] [PubMed]
- Chen, Z.; Micsinai Balan, M.; Brown, K. Language models are few-shot learners for prognostic prediction. arXiv 2023, arXiv:2302.12692. [Google Scholar]
- Xue, V.W.; Lei, P.; Cho, W.C. The potential impact of ChatGPT in clinical and translational medicine. Clin. Transl. Med. 2023, 13, e1206. [Google Scholar] [CrossRef]
- Chen, Z.; Balan, M.M.; Brown, K. Boosting Transformers and Language Models for Clinical Prediction in Immunotherapy. arXiv 2023, arXiv:2302.12692. [Google Scholar]
- Li, H.; Gerkin, R.C.; Bakke, A.; Norel, R.; Cecchi, G.; Laudamiel, C.; Niv, M.Y.; Ohla, K.; Hayes, J.E.; Parma, V.; et al. Text-based predictions of COVID-19 diagnosis from self-reported chemosensory descriptions. Commun. Med. 2023, 3, 104. [Google Scholar] [CrossRef] [PubMed]
- Mao, C.; Xu, J.; Rasmussen, L.; Li, Y.; Adekkanattu, P.; Pacheco, J.; Bonakdarpour, B.; Vassar, R.; Shen, L.; Jiang, G.; et al. AD-BERT: Using pre-trained language model to predict the progression from mild cognitive impairment to Alzheimer’s disease. J. Biomed. Inform. 2023, 144, 104442. [Google Scholar] [CrossRef] [PubMed]
- Agbavor, F.; Liang, H. Predicting dementia from spontaneous speech using large language models. PLoS Digit. Health 2022, 1, e0000168. [Google Scholar] [CrossRef] [PubMed]
- Bill, D.; Eriksson, T. Fine-Tuning a LLM Using Reinforcement Learning from Human Feedback for a Therapy Chatbot Application; KTH: Stockholm, Sweden, 2023. [Google Scholar]
- Balas, M.; Ing, E.B. Conversational ai models for ophthalmic diagnosis: Comparison of chatgpt and the isabel pro differential diagnosis generator. JFO Open Ophthalmol. 2023, 1, 100005. [Google Scholar] [CrossRef]
- Lai, T.; Shi, Y.; Du, Z.; Wu, J.; Fu, K.; Dou, Y.; Wang, Z. Psy-LLM: Scaling up Global Mental Health Psychological Services with AI-based Large Language Models. arXiv 2023, arXiv:2307.11991. [Google Scholar]
- Bilal, M.; Jamil, Y.; Rana, D.; Shah, H.H. Enhancing Awareness and Self-diagnosis of Obstructive Sleep Apnea Using AI-Powered Chatbots: The Role of ChatGPT in Revolutionizing Healthcare. Ann. Biomed. Eng. 2023, 52, 136–138. [Google Scholar] [CrossRef] [PubMed]
- Javaid, M.; Haleem, A.; Singh, R.P. ChatGPT for healthcare services: An emerging stage for an innovative perspective. Benchcouncil Trans. Benchmarks Stand. Eval. 2023, 3, 100105. [Google Scholar] [CrossRef]
- Ali, S.R.; Dobbs, T.D.; Hutchings, H.A.; Whitaker, I.S. Using ChatGPT to write patient clinic letters. Lancet Digit. Health 2023, 5, e179–e181. [Google Scholar] [CrossRef] [PubMed]
- Nguyen, J.; Pepping, C.A. The application of ChatGPT in healthcare progress notes: A commentary from a clinical and research perspective. Clin. Transl. Med. 2023, 13, e1324. [Google Scholar] [CrossRef] [PubMed]
- Walker, H.L.; Ghani, S.; Kuemmerli, C.; Nebiker, C.A.; Müller, B.P.; Raptis, D.A.; Staubli, S.M. Reliability of Medical Information Provided by ChatGPT: Assessment Against Clinical Guidelines and Patient Information Quality Instrument. J. Med. Internet Res. 2023, 25, e47479. [Google Scholar] [CrossRef] [PubMed]
- Iftikhar, L.; Iftikhar, M.F.; Hanif, M.I. Docgpt: Impact of chatgpt-3 on health services as a virtual doctor. Paediatrics 2023, 12, 45–55. [Google Scholar]
- Yang, H.; Li, J.; Liu, S.; Du, L.; Liu, X.; Huang, Y.; Shi, Q.; Liu, J. Exploring the Potential of Large Language Models in Personalized Diabetes Treatment Strategies. medRxiv 2023. [Google Scholar] [CrossRef]
- Wang, S.; Zhao, Z.; Ouyang, X.; Wang, Q.; Shen, D. Chatcad: Interactive computer-aided diagnosis on medical image using large language models. arXiv 2023, arXiv:2302.07257. [Google Scholar]
- Sorin, V.; Barash, Y.; Konen, E.; Klang, E. Large language models for oncological applications. J. Cancer Res. Clin. Oncol. 2023, 149, 9505–9508. [Google Scholar] [CrossRef] [PubMed]
- Matin, R.N.; Linos, E.; Rajan, N. Leveraging large language models in dermatology. Br. J. Dermatol. 2023, 189, 253–254. [Google Scholar] [CrossRef] [PubMed]
- Sallam, M. The utility of ChatGPT as an example of large language models in healthcare education, research and practice: Systematic review on the future perspectives and potential limitations. medRxiv 2023. [Google Scholar] [CrossRef]
- Tang, L.; Sun, Z.; Idnay, B.; Nestor, J.G.; Soroush, A.; Elias, P.A.; Xu, Z.; Ding, Y.; Durrett, G.; Rousseau, J.F.; et al. Evaluating large language models on medical evidence summarization. NPJ Digit. Med. 2023, 6, 158. [Google Scholar] [CrossRef]
- Liu, Z.; Roberts, R.A.; Lal-Nag, M.; Chen, X.; Huang, R.; Tong, W. AI-based language models powering drug discovery and development. Drug Discov. Today 2021, 26, 2593–2607. [Google Scholar] [CrossRef] [PubMed]
- Datta, T.T.; Shill, P.C.; Al Nazi, Z. Bert-d2: Drug-drug interaction extraction using bert. In Proceedings of the 2022 International Conference for Advancement in Technology (ICONAT), Goa, India, 21–22 January 2022; IEEE: Piscataway, NJ, USA, 2022; pp. 1–6. [Google Scholar]
- Grisoni, F. Chemical language models for de novo drug design: Challenges and opportunities. Curr. Opin. Struct. Biol. 2023, 79, 102527. [Google Scholar] [CrossRef] [PubMed]
- Uludoğan, G.; Ozkirimli, E.; Ulgen, K.O.; Karalı, N.; Özgür, A. Exploiting pretrained biochemical language models for targeted drug design. Bioinformatics 2022, 38, ii155–ii161. [Google Scholar] [CrossRef] [PubMed]
- Ma, L.; Han, J.; Wang, Z.; Zhang, D. CephGPT-4: An Interactive Multimodal Cephalometric Measurement and Diagnostic System with Visual Large Language Model. arXiv 2023, arXiv:2307.07518. [Google Scholar]
- Khader, F.; Mueller-Franzes, G.; Wang, T.; Han, T.; Arasteh, S.T.; Haarburger, C.; Stegmaier, J.; Bressem, K.; Kuhl, C.; Nebelung, S.; et al. Medical Diagnosis with Large Scale Multimodal Transformers–Leveraging Diverse Data for More Accurate Diagnosis. arXiv 2022, arXiv:2212.09162. [Google Scholar]
- Thawkar, O.; Shaker, A.; Mullappilly, S.S.; Cholakkal, H.; Anwer, R.M.; Khan, S.; Laaksonen, J.; Khan, F.S. Xraygpt: Chest radiographs summarization using medical vision-language models. arXiv 2023, arXiv:2306.07971. [Google Scholar]
- Liu, J.; Hu, T.; Zhang, Y.; Gai, X.; Feng, Y.; Liu, Z. A ChatGPT Aided Explainable Framework for Zero-Shot Medical Image Diagnosis. arXiv 2023, arXiv:2307.01981. [Google Scholar]
- Monajatipoor, M.; Rouhsedaghat, M.; Li, L.H.; Jay Kuo, C.C.; Chien, A.; Chang, K.W. Berthop: An effective vision-and-language model for chest X-ray disease diagnosis. In Medical Image Computing and Computer Assisted Intervention—MICCAI 2022: 25th International Conference, Singapore, September 18–22, 2022, Proceedings, Part V; Springer: Cham, Switzerland, 2022; pp. 725–734. [Google Scholar]
- Roshanzamir, A.; Aghajan, H.; Soleymani Baghshah, M. Transformer-based deep neural network language models for Alzheimer’s disease risk assessment from targeted speech. BMC Med. Inform. Decis. Mak. 2021, 21, 92. [Google Scholar] [CrossRef] [PubMed]
- Giorgi, J.; Toma, A.; Xie, R.; Chen, S.; An, K.; Zheng, G.; Wang, B. Wanglab at mediqa-chat 2023: Clinical note generation from doctor-patient conversations using large language models. In Proceedings of the 5th Clinical Natural Language Processing Workshop, Toronto, ON, Canada, 9 July 2023; pp. 323–334. [Google Scholar]
- Huang, G.; Li, Y.; Jameel, S.; Long, Y.; Papanastasiou, G. From explainable to interpretable deep learning for natural language processing in healthcare: How far from reality? Comput. Struct. Biotechnol. J. 2024, 24, 362–373. [Google Scholar] [CrossRef] [PubMed]
- Thorsen-Meyer, H.C.; Placido, D.; Kaas-Hansen, B.S.; Nielsen, A.P.; Lange, T.; Nielsen, A.B.; Toft, P.; Schierbeck, J.; Strøm, T.; Chmura, P.J.; et al. Discrete-time survival analysis in the critically ill: A deep learning approach using heterogeneous data. NPJ Digit. Med. 2022, 5, 142. [Google Scholar] [CrossRef] [PubMed]
- Zhang, A.Y.; Lam, S.S.W.; Ong, M.E.H.; Tang, P.H.; Chan, L.L. Explainable AI: Classification of MRI brain scans orders for quality improvement. In Proceedings of the 6th IEEE/ACM International Conference on Big Data Computing, Applications and Technologies, New York, NY, USA, 2 December 2019; pp. 95–102. [Google Scholar]
- Ozyegen, O.; Kabe, D.; Cevik, M. Word-level text highlighting of medical texts for telehealth services. Artif. Intell. Med. 2022, 127, 102284. [Google Scholar] [CrossRef] [PubMed]
- Dobrakowski, A.G.; Mykowiecka, A.; Marciniak, M.; Jaworski, W.; Biecek, P. Interpretable segmentation of medical free-text records based on word embeddings. J. Intell. Inf. Syst. 2021, 57, 447–465. [Google Scholar] [CrossRef]
- Gao, Y.; Li, R.; Caskey, J.; Dligach, D.; Miller, T.; Churpek, M.M.; Afshar, M. Leveraging a medical knowledge graph into large language models for diagnosis prediction. arXiv 2023, arXiv:2308.14321. [Google Scholar]
- Yang, K.; Ji, S.; Zhang, T.; Xie, Q.; Kuang, Z.; Ananiadou, S. Towards interpretable mental health analysis with large language models. arXiv 2023, arXiv:2304.03347. [Google Scholar]
- Hong, S.; Xiao, L.; Zhang, X.; Chen, J. ArgMed-Agents: Explainable Clinical Decision Reasoning with Large Language Models via Argumentation Schemes. arXiv 2024, arXiv:2403.06294. [Google Scholar]
- Yang, K.; Zhang, T.; Kuang, Z.; Xie, Q.; Huang, J.; Ananiadou, S. MentaLLaMA: Interpretable mental health analysis on social media with large language models. In Proceedings of the ACM on Web Conference 2024, Singapore, 13–17 May 2024; pp. 4489–4500. [Google Scholar]
- Savage, T.; Nayak, A.; Gallo, R.; Rangan, E.; Chen, J.H. Diagnostic reasoning prompts reveal the potential for large language model interpretability in medicine. NPJ Digit. Med. 2024, 7, 20. [Google Scholar] [CrossRef] [PubMed]
- Lin, B.; Xu, Y.; Bao, X.; Zhao, Z.; Zhang, Z.; Wang, Z.; Zhang, J.; Deng, S.; Yin, J. SkinGEN: An explainable dermatology diagnosis-to-generation framework with interactive vision-language models. arXiv 2024, arXiv:2404.14755. [Google Scholar]
- Lee, M.H.; Chew, C.J. Understanding the effect of counterfactual explanations on trust and reliance on ai for human-AI collaborative clinical decision making. Proc. ACM Hum.-Comput. Interact. 2023, 7, 369. [Google Scholar] [CrossRef]
- McInerney, D.J.; Young, G.; van de Meent, J.W.; Wallace, B.C. Chill: Zero-shot custom interpretable feature extraction from clinical notes with large language models. arXiv 2023, arXiv:2302.12343. [Google Scholar]
- Naseem, U.; Khushi, M.; Kim, J. Vision-language transformer for interpretable pathology visual question answering. IEEE J. Biomed. Health Inform. 2022, 27, 1681–1690. [Google Scholar] [CrossRef]
- Park, S.; Kim, G.; Oh, Y.; Seo, J.; Lee, S.; Kim, J.; Moon, S.; Lim, J.; Ye, J. Vision Transformer for COVID-19 CXR Diagnosis using Chest X-ray Feature Corpus. arXiv 2021, arXiv:2103.07055. [Google Scholar]
- Pan, J. Large language model for molecular chemistry. Nat. Comput. Sci. 2023, 3, 5. [Google Scholar] [CrossRef] [PubMed]
- Liang, J.; Wang, Z.; Ma, Z.; Li, J.; Zhang, Z.; Wu, X.; Wang, B. Online Training of Large Language Models: Learn while chatting. arXiv 2024, arXiv:2403.04790. [Google Scholar]
- Che, T.; Liu, J.; Zhou, Y.; Ren, J.; Zhou, J.; Sheng, V.S.; Dai, H.; Dou, D. Federated learning of large language models with parameter-efficient prompt tuning and adaptive optimization. arXiv 2023, arXiv:2310.15080. [Google Scholar]
- Zhao, H.; Chen, H.; Yang, F.; Liu, N.; Deng, H.; Cai, H.; Wang, S.; Yin, D.; Du, M. Explainability for large language models: A survey. ACM Trans. Intell. Syst. Technol. 2024, 15, 20. [Google Scholar] [CrossRef]
- Kim, Y.; Xu, X.; McDuff, D.; Breazeal, C.; Park, H.W. Health-llm: Large language models for health prediction via wearable sensor data. arXiv 2024, arXiv:2401.06866. [Google Scholar]
- Pahune, S.; Rewatkar, N. Large Language Models and Generative AI’s Expanding Role in Healthcare. 2024. Available online: https://www.researchgate.net/profile/Saurabh-Pahune-2/publication/377217911_Large_Language_Models_and_Generative_AI’s_Expanding_Role_in_Healthcare/links/659aad286f6e450f19d3f129/Large-Language-Models-and-Generative-AIs-Expanding-Role-in-Healthcare.pdf (accessed on 8 July 2024).
- Reddy, S.; Rogers, W.; Makinen, V.P.; Coiera, E.; Brown, P.; Wenzel, M.; Weicken, E.; Ansari, S.; Mathur, P.; Casey, A.; et al. Evaluation framework to guide implementation of AI systems into healthcare settings. BMJ Health Care Inform. 2021, 28, e100444. [Google Scholar] [CrossRef] [PubMed]
- Reddy, S. Evaluating large language models for use in healthcare: A framework for translational value assessment. Inform. Med. Unlocked 2023, 41, 101304. [Google Scholar] [CrossRef]
- Anil, R.; Dai, A.M.; Firat, O.; Johnson, M.; Lepikhin, D.; Passos, A.; Shakeri, S.; Taropa, E.; Bailey, P.; Chen, Z.; et al. Palm 2 technical report. arXiv 2023, arXiv:2305.10403. [Google Scholar]
- Liao, W.; Liu, Z.; Dai, H.; Xu, S.; Wu, Z.; Zhang, Y.; Huang, X.; Zhu, D.; Cai, H.; Liu, T.; et al. Differentiate chatgpt-generated and human-written medical texts. arXiv 2023, arXiv:2304.11567. [Google Scholar]
- Manoel, A.; Garcia, M.d.C.H.; Baumel, T.; Su, S.; Chen, J.; Sim, R.; Miller, D.; Karmon, D.; Dimitriadis, D. Federated Multilingual Models for Medical Transcript Analysis. In Proceedings of the Conference on Health, Inference, and Learning, Honolulu, HI, USA, 23–29 July 2023; pp. 147–162. [Google Scholar]
- Zhang, Y.; Nie, A.; Zehnder, A.; Page, R.L.; Zou, J. VetTag: Improving automated veterinary diagnosis coding via large-scale language modeling. NPJ Digit. Med. 2019, 2, 35. [Google Scholar] [CrossRef] [PubMed]
- Wang, G.; Yang, G.; Du, Z.; Fan, L.; Li, X. ClinicalGPT: Large Language Models Finetuned with Diverse Medical Data and Comprehensive Evaluation. arXiv 2023, arXiv:2306.09968. [Google Scholar]
- Li, J.; Wang, X.; Wu, X.; Zhang, Z.; Xu, X.; Fu, J.; Tiwari, P.; Wan, X.; Wang, B. Huatuo-26M, a Large-scale Chinese Medical QA Dataset. arXiv 2023, arXiv:2305.01526. [Google Scholar]
- Yang, X.; Chen, A.; PourNejatian, N.; Shin, H.C.; Smith, K.E.; Parisien, C.; Compas, C.; Martin, C.; Costa, A.B.; Flores, M.G.; et al. A large language model for electronic health records. NPJ Digit. Med. 2022, 5, 194. [Google Scholar] [CrossRef] [PubMed]
- Crema, C.; Buonocore, T.M.; Fostinelli, S.; Parimbelli, E.; Verde, F.; Fundarò, C.; Manera, M.; Ramusino, M.C.; Capelli, M.; Costa, A.; et al. Advancing Italian Biomedical Information Extraction with Large Language Models: Methodological Insights and Multicenter Practical Application. arXiv 2023, arXiv:2306.05323. [Google Scholar]
- Zhang, T.; Kishore, V.; Wu, F.; Weinberger, K.Q.; Artzi, Y. Bertscore: Evaluating text generation with bert. arXiv 2019, arXiv:1904.09675. [Google Scholar]
- Beaulieu-Jones, B.R.; Shah, S.; Berrigan, M.T.; Marwaha, J.S.; Lai, S.L.; Brat, G.A. Evaluating Capabilities of Large Language Models: Performance of GPT4 on Surgical Knowledge Assessments. medRxiv 2023. [Google Scholar] [CrossRef]
- Hendrycks, D.; Burns, C.; Basart, S.; Zou, A.; Mazeika, M.; Song, D.; Steinhardt, J. Measuring massive multitask language understanding. arXiv 2020, arXiv:2009.03300. [Google Scholar]
- Chen, M.; Tworek, J.; Jun, H.; Yuan, Q.; Pinto, H.P.D.O.; Kaplan, J.; Edwards, H.; Burda, Y.; Joseph, N.; Brockman, G.; et al. Evaluating large language models trained on code. arXiv 2021, arXiv:2107.03374. [Google Scholar]
- Klu AI. MMLU Benchmark (Massive Multi-Task Language Understanding). 2024. Available online: https://paperswithcode.com/sota/multi-task-language-understanding-on-mmlu (accessed on 8 July 2024).
- Jin, Q.; Dhingra, B.; Cohen, W.W.; Lu, X. Probing biomedical embeddings from language models. arXiv 2019, arXiv:1904.02181. [Google Scholar]
- Mayr, A.; Klambauer, G.; Unterthiner, T.; Hochreiter, S. DeepTox: Toxicity prediction using deep learning. Front. Environ. Sci. 2016, 3, 80. [Google Scholar] [CrossRef]
- Jin, Q.; Dhingra, B.; Liu, Z.; Cohen, W.W.; Lu, X. Pubmedqa: A dataset for biomedical research question answering. arXiv 2019, arXiv:1909.06146. [Google Scholar]
- Papers with Code. Medical Papers with Code. 2024. Available online: https://paperswithcode.com/area/medical (accessed on 8 July 2024).
- Lee, J.; Myeong, I.S.; Kim, Y. The Drug-Like Molecule Pre-Training Strategy for Drug Discovery. IEEE Access 2023, 11, 61680–61687. [Google Scholar] [CrossRef]
- Ali, H.; Qadir, J.; Alam, T.; Househ, M.; Shah, Z. In Proceedings of the ChatGPT and Large Language Models (LLMs) in Healthcare: Opportunities and Risks, Mount Pleasant, MI, USA, 16–17 September 2023.
- Briganti, G. A clinician’s guide to large language models. Future Med. AI 2023, 1, FMAI1. [Google Scholar] [CrossRef]
- Bisercic, A.; Nikolic, M.; van der Schaar, M.; Delibasic, B.; Lio, P.; Petrovic, A. Interpretable Medical Diagnostics with Structured Data Extraction by Large Language Models. arXiv 2023, arXiv:2306.05052. [Google Scholar]
- Jiang, Y.; Qiu, R.; Zhang, Y.; Zhang, P.F. Balanced and Explainable Social Media Analysis for Public Health with Large Language Models. arXiv 2023, arXiv:2309.05951. [Google Scholar]
- Omiye, J.A.; Gui, H.; Rezaei, S.J.; Zou, J.; Daneshjou, R. Large language models in medicine: The potentials and pitfalls. arXiv 2023, arXiv:2309.00087. [Google Scholar] [CrossRef] [PubMed]
- Thapa, S.; Adhikari, S. ChatGPT, Bard, and Large Language Models for Biomedical Research: Opportunities and Pitfalls. Ann. Biomed. Eng. 2023, 51, 2647–2651. [Google Scholar] [CrossRef] [PubMed]
- Tian, S.; Jin, Q.; Yeganova, L.; Lai, P.T.; Zhu, Q.; Chen, X.; Yang, Y.; Chen, Q.; Kim, W.; Comeau, D.C.; et al. Opportunities and Challenges for ChatGPT and Large Language Models in Biomedicine and Health. arXiv 2023, arXiv:2306.10070. [Google Scholar] [CrossRef] [PubMed]
- Novelli, C.; Casolari, F.; Hacker, P.; Spedicato, G.; Floridi, L. Generative AI in EU law: Liability, privacy, intellectual property, and cybersecurity. arXiv 2024, arXiv:2401.07348. [Google Scholar] [CrossRef]
- Hacker, P.; Engel, A.; Mauer, M. Regulating ChatGPT and other large generative AI models. In Proceedings of the 2023 ACM Conference on Fairness, Accountability, and Transparency, Chicago, IL, USA, 12–15 June 2023; pp. 1112–1123. [Google Scholar]

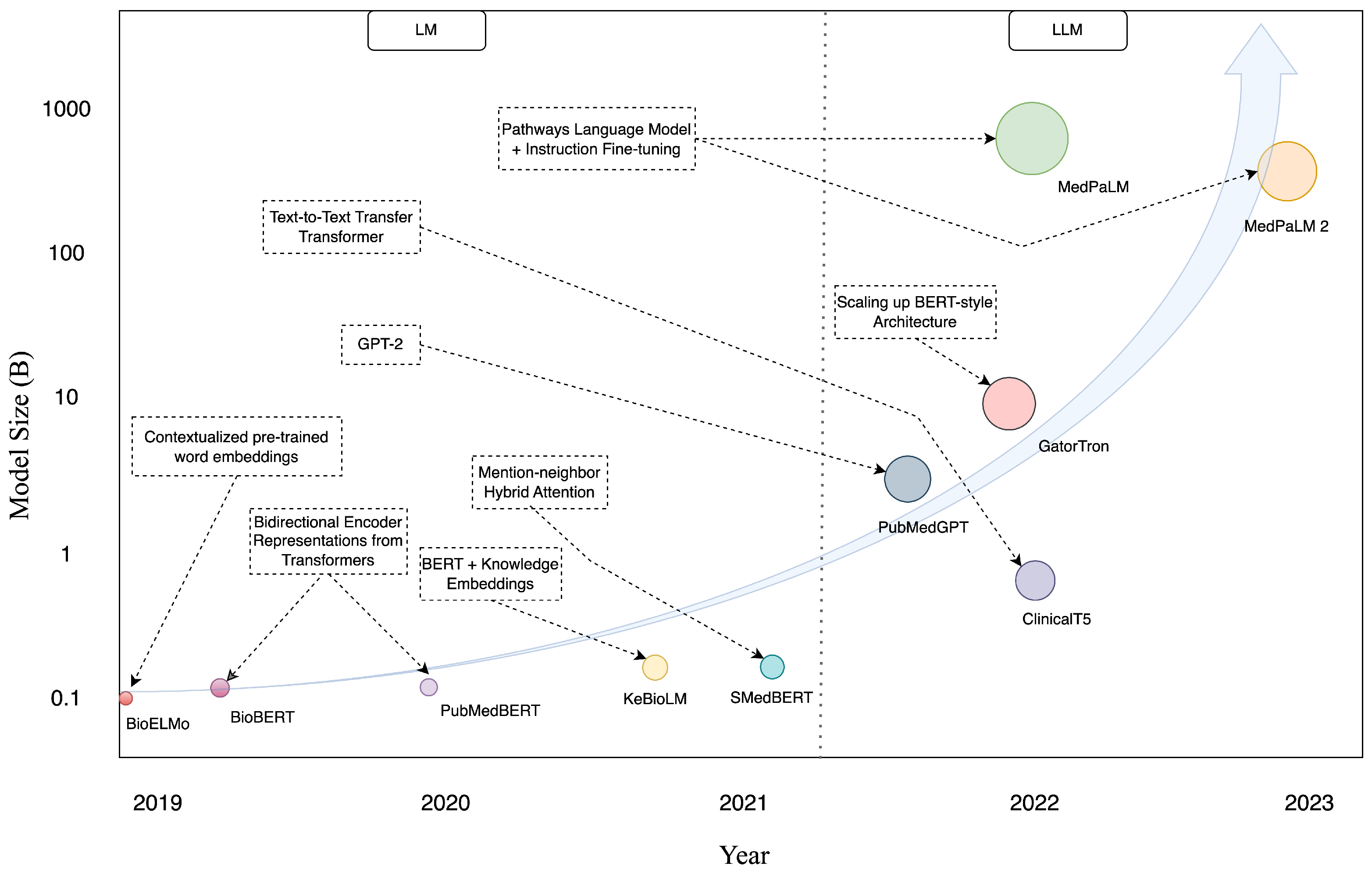

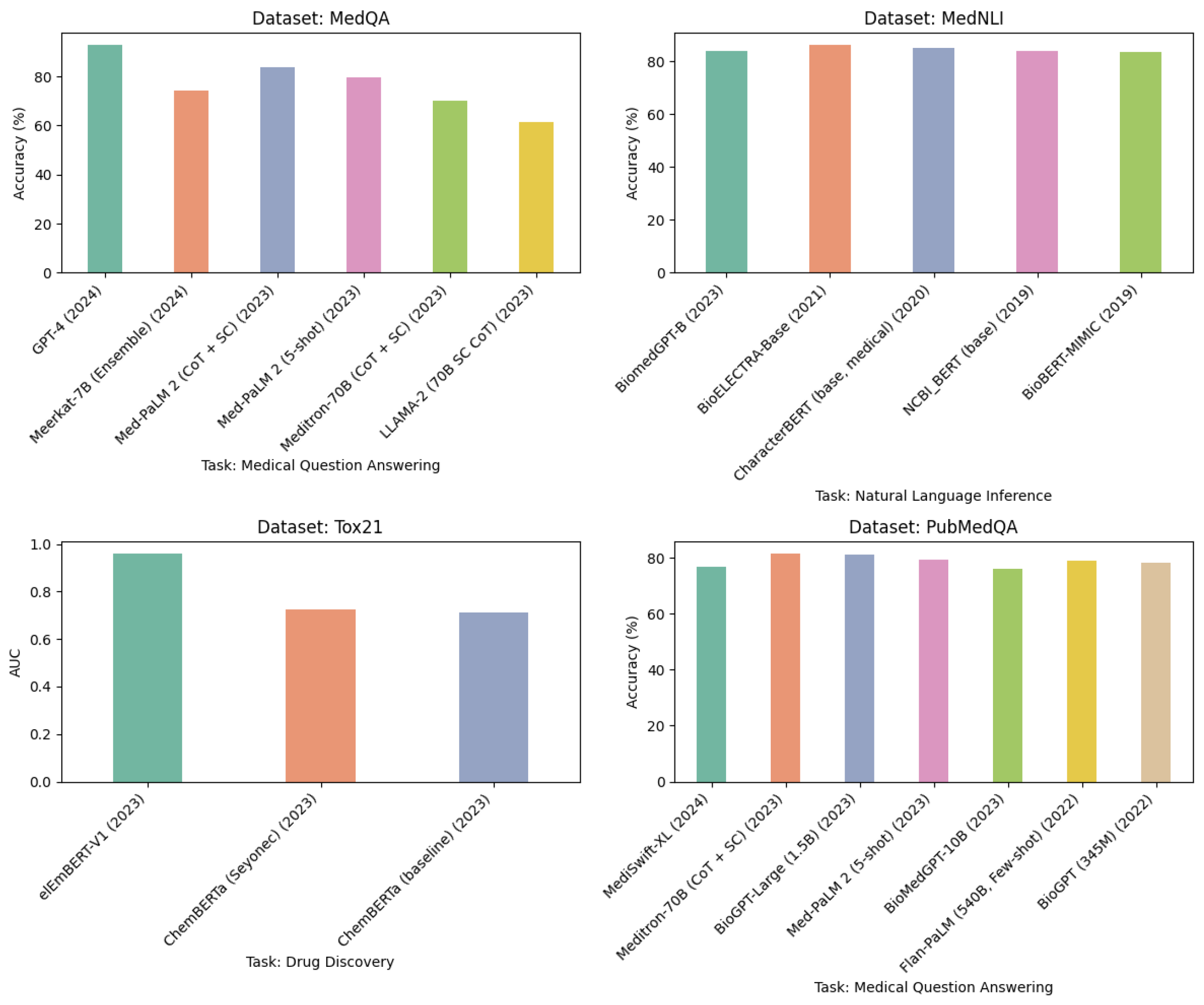


{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Method | Year | Task | Institution | Source Code |
|---|---|---|---|---|
| BioMistral [36] | 2024 | Medical Question Answering | Avignon Université, Nantes Université | model (https://huggingface.co/BioMistral/BioMistral-7B, accessed on 8 July 2024) |
| Med-PaLM 2 [37] | 2023 | Medical Question Answering | Google Research, DeepMind | |
| Radiology-Llama2 [38] | 2023 | Radiology | University of Georgia | |
| DeID-GPT [39] | 2023 | De-identification | University of Georgia | code (https://github.com/yhydhx/ChatGPT-API, accessed on 8 July 2024) |
| Med-HALT [40] | 2023 | Hallucination test | Saama AI Research | code (https://github.com/medhalt/medhalt, accessed on 8 July 2024) |
| ChatCAD [41] | 2023 | Computer-aided diagnosis | ShanghaiTech University | code (https://github.com/zhaozh10/ChatCAD, accessed on 8 July 2024) |
| BioGPT [42] | 2023 | Classification, relation extraction, question answering, etc. | Microsoft Research | code (https://github.com/microsoft/BioGPT, accessed on 8 July 2024) |
| GatorTron [43] | 2022 | Semantic textual similarity, natural language inference, and medical question answering | University of Florida | code (https://github.com/uf-hobi-informatics-lab/GatorTron, accessed on 8 July 2024) |
| BioMedLM | 2022 | Biomedical question answering | Stanford CRFM, MosaicML | code (https://github.com/stanford-crfm/BioMedLM, accessed on 8 July 2024) |
| BioBART [44] | 2022 | Dialogue, summarization, entity linking, and NER | Tsinghua University, International Digital Economy Academy | code (https://github.com/GanjinZero/BioBART, accessed on 8 July 2024) |
| ClinicalT5 [45] | 2022 | Classification, NER | University of Oregon, Baidu Research | model (https://huggingface.co/xyla/Clinical-T5-Large, accessed on 8 July 2024) |
| KeBioLM [46] | 2021 | Biomedical pre-training, NER, and relation extraction | Tsinghua University, Alibaba Group | code (https://github.com/GanjinZero/KeBioLM, accessed on 8 July 2024) |
| CRNN [47] | 2017 | Relation classification | Indian Institute of Technology | code (https://github.com/desh2608/crnn-relation-classification, accessed on 8 July 2024) |
| LSTM RNN [48] | 2017 | Named entity recognition | Wuhan University | code (https://github.com/lvchen1989/BNER, accessed on 8 July 2024) |
| Method | Year | Task | XIAI Attributes | XIAI Evaluation Metric |
|---|---|---|---|---|
| MentaLLaMA [code (https://github.com/SteveKGYang/MentalLLaMA, accessed on 8 July 2024)] [91] | 2024 | Mental health analysis | Prompt-based (ChatGPT w/task-specific instructions) | BART-score, Human Eval |
| ArgMed-Agents [90] | 2024 | Clinical decision reasoning | Prompt-based (Self-argumentation iterations + symbolic solver) | Pred. accuracy with LLM evaluator |
| Diagnostic reasoning prompts [92] | 2024 | Medical Question Answering (MedQA) | Prompt-based (Bayesian, differential diagnosis, analytical, and intuitive reasoning) | Expert Evaluation, Inter-rater agreement |
| SkinGEN [93] | 2024 | Dermatological diagnosis | Visual explanations (Stable Diffusion), interactive framework. | Perceived explainability ratings |
| DR. KNOWS [88] | 2023 | Automated diagnosis generation | Knowledge Graph (explainable diagnostic pathway) | |
| Human-AI Collaboration [94] | 2023 | Clinical decision making | Salient features, counterfactual explanations | Agreement Level, Usability Questionnaires |
| ChatGPT [89] | 2023 | Mental health analysis | Prompt-based (emotional cues and expert-written few-shot examples) | BART-score, Human Eval |
| CHiLL [95] | 2023 | Clinical predictive tasks, Chest X-ray report classification | Interpretable features, linear models | Expert Evaluation, Clinical Judgement Alignment |
| Trap-VQA [96] | 2022 | Pathology Visual Question Answering (PathVQA) | Grad-CAM, SHapley Additive exPlanations | Qualitative Evaluation |
| Vision Transformer [97] | 2021 | Covid-19 diagnosis | Saliency maps | Visualisation |
| ClinicalBERT [code (https://github.com/kexinhuang12345/clinicalBERT, accessed on 8 July 2024)] [15] | 2019 | Predicting hospital readmission | Attention weights | Visualisation |
| Eval. Metric | Description | References | Key Highlights |
|---|---|---|---|
| Perplexity | Perplexity, a probabilistic metric, quantifies the uncertainty in the predictions of a language model. Lower values indicate higher prediction accuracy and coherence. | [107] | - |
| [108] | The federated learning model achieved a best perplexity value of 3.41 for English. | ||
| [109] | The Transformer model achieved a test perplexity of 15.6 on the PSVG dataset, significantly outperforming the LSTM’s perplexity of 20.7. | ||
| [88] | The lowest perplexity achieved was 3.86 × 10−13 | ||
| BLEU | The BLEU score assesses the quality of machine translation by comparing it to reference translations. | [110] | The best BLEU-1 score achieved was 13.9 by the ClinicalGPT model. |
| [111] | T-5 (fine-tuned) model achieved the best BLEU-1 score of 26.63. | ||
| GLEU | GLEU score computes mean scores of various n-grams to assess text generation quality. | [110] | The best GLEU score achieved was 2.2 by the Bloom-7B model. |
| [111] | T-5 (fine-tuned) model achieved the best GLEU score of 11.38. | ||
| ROUGE | ROUGE score evaluates summarization and translation by measuring overlap with reference summaries. | [110] | The best ROGUE-L score achieved was 21.3 by the ClinicalGPT model. |
| [111] | T-5 (fine-tuned) model achieved the best ROGUE-L score of 24.85. | ||
| Distinct n-grams | Measures the diversity of generated responses by counting unique n-grams. | [111] | On the Huatuo-26M dataset, the fine-tuned T5 model achieved Distinct-1 and Distinct-2 scores of 0.51 and 0.68, respectively. |
| F1 Score | The F1 score balances precision and recall, measuring a model’s accuracy in identifying positive instances and minimizing false results. | [112] | The GatorTron-large model achieved the best F1 score of 0.9627 for medical relation extraction. |
| [43] | The GatorTron-large model achieved the best F1 score of 0.9000 for clinical concept extraction and 0.9627 for medical relation extraction. | ||
| [113] | The multicenter Transformers-based model achieved an overall F1 score of 84.77% on the PsyNIT dataset. | ||
| [73] | The BERT-D2 model achieved an F1 score of 81.97% on the DDI Extraction 2013 corpus. | ||
| BERTScore | BERTScore calculates similarity scores between tokens in candidate and reference sentences, using contextual embeddings. | [114] | - |
| [82] | The Longformer-Encoder-Decoder (LEDlarge-PubMed) model achieved the best BERTScore F1 of 70.7. | ||
| Human Evaluation | Involves expert human assessors rating the quality of model-generated content, providing qualitative insights into its performance. | [115] | The median performance for all human SCORE users was 65%, whereas ChatGPT correctly answered 71% of multiple-choice SCORE questions and 68% of Data-B questions. |
| Organization | Model | MMLU Score | Coding (HumanEval) | Release Date |
|---|---|---|---|---|
| OpenAI | GPT-4 Opus | 88.7 | - | May 2024 |
| Anthropic | Claude 3.5 Sonnet | 88.7 | 92.0 | June 2024 |
| Anthropic | Claude 3 Opus | 86.8 | - | March 2024 |
| OpenAI | GPT-4 Turbo | 86.4 | 85.4 | April 2024 |
| OpenAI | GPT-4 | 86.4 | 90.2 | April 2023 |
| Meta | Llama 3 400B | 86.1 | - | - |
| Gemini 1.5 Pro | 85.9 | 84.1 | May 2024 | |
| Gemini Ultra | 83.7 | - | December 2023 | |
| OpenAI | GPT-3.5 Turbo | - | 73.2 | - |
| Meta | Llama 3 (70B) | - | 81.7 | - |
| Meta | Llama 3 (8B) | - | 62.2 | - |
| Gemini 1.5 Flash | - | 74.3 | - |
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2024 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Nazi, Z.A.; Peng, W. Large Language Models in Healthcare and Medical Domain: A Review. Informatics 2024, 11, 57. https://doi.org/10.3390/informatics11030057
Nazi ZA, Peng W. Large Language Models in Healthcare and Medical Domain: A Review. Informatics. 2024; 11(3):57. https://doi.org/10.3390/informatics11030057
Chicago/Turabian StyleNazi, Zabir Al, and Wei Peng. 2024. "Large Language Models in Healthcare and Medical Domain: A Review" Informatics 11, no. 3: 57. https://doi.org/10.3390/informatics11030057
APA StyleNazi, Z. A., & Peng, W. (2024). Large Language Models in Healthcare and Medical Domain: A Review. Informatics, 11(3), 57. https://doi.org/10.3390/informatics11030057