
Uncertainty Estimation for Machine Learning Models in Multiphase Flow Applications


Abstract
:1. Introduction
1.1. The Measurement Setting
- Bottomhole pressure and temperature,
- Wellhead pressure and temperature upstream of the choke,
- Wellhead pressure and temperature downstream of the choke,
- Choke opening (i.e., the percentage of opening of the choke valve).
1.2. Production Parameters
1.3. Structure and Novelty of the Paper
2. Previous Work
3. Data-Driven Models and Uncertainty Estimation
3.1. Feed-Forward Neural Network
3.2. Gaussian Processes
3.3. Local Linear Forest
3.4. Confidence Estimation for Tree-Based Methods: Infinitesimal Jackknife
3.5. Random Forests
3.6. Metrics
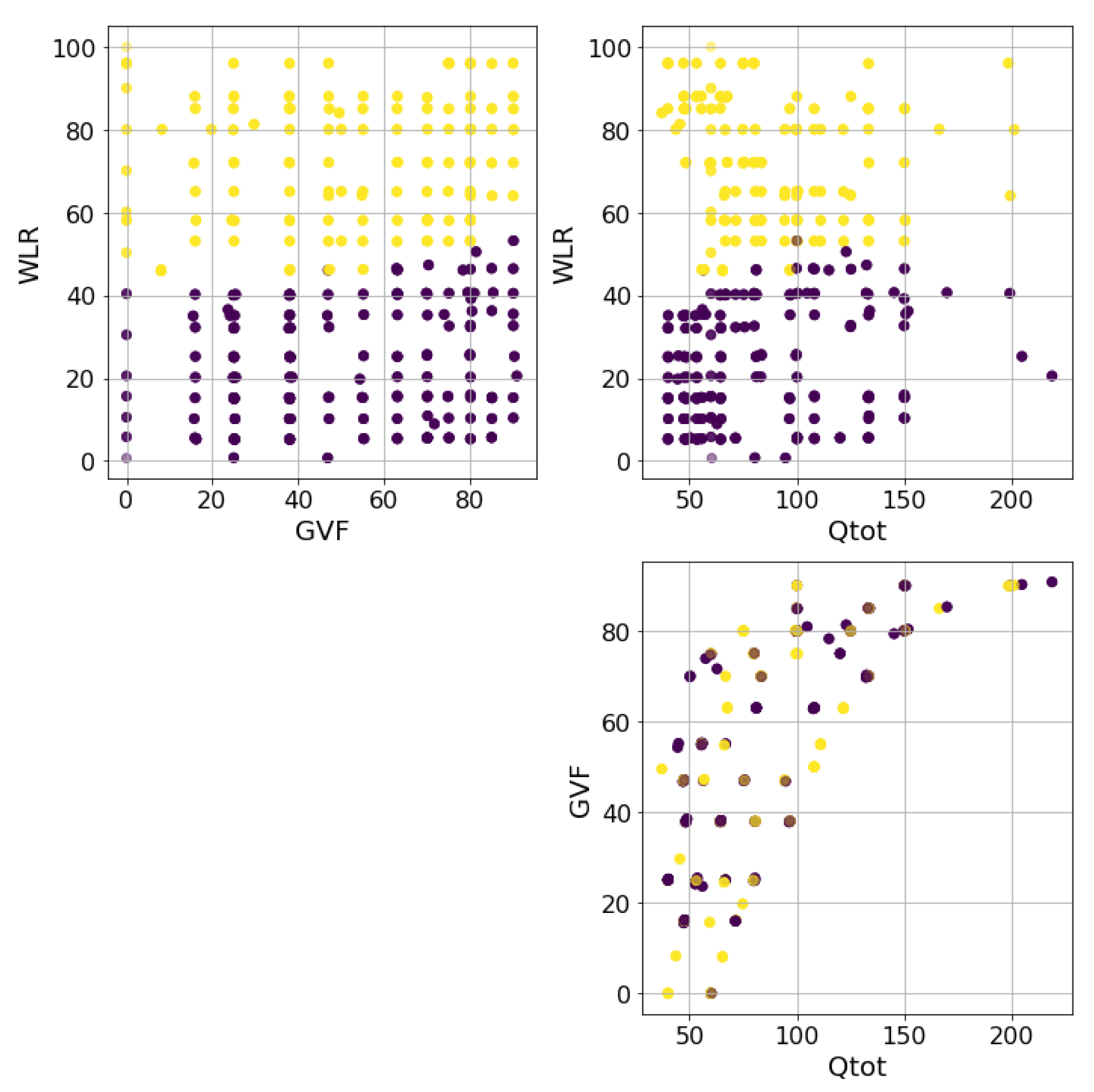
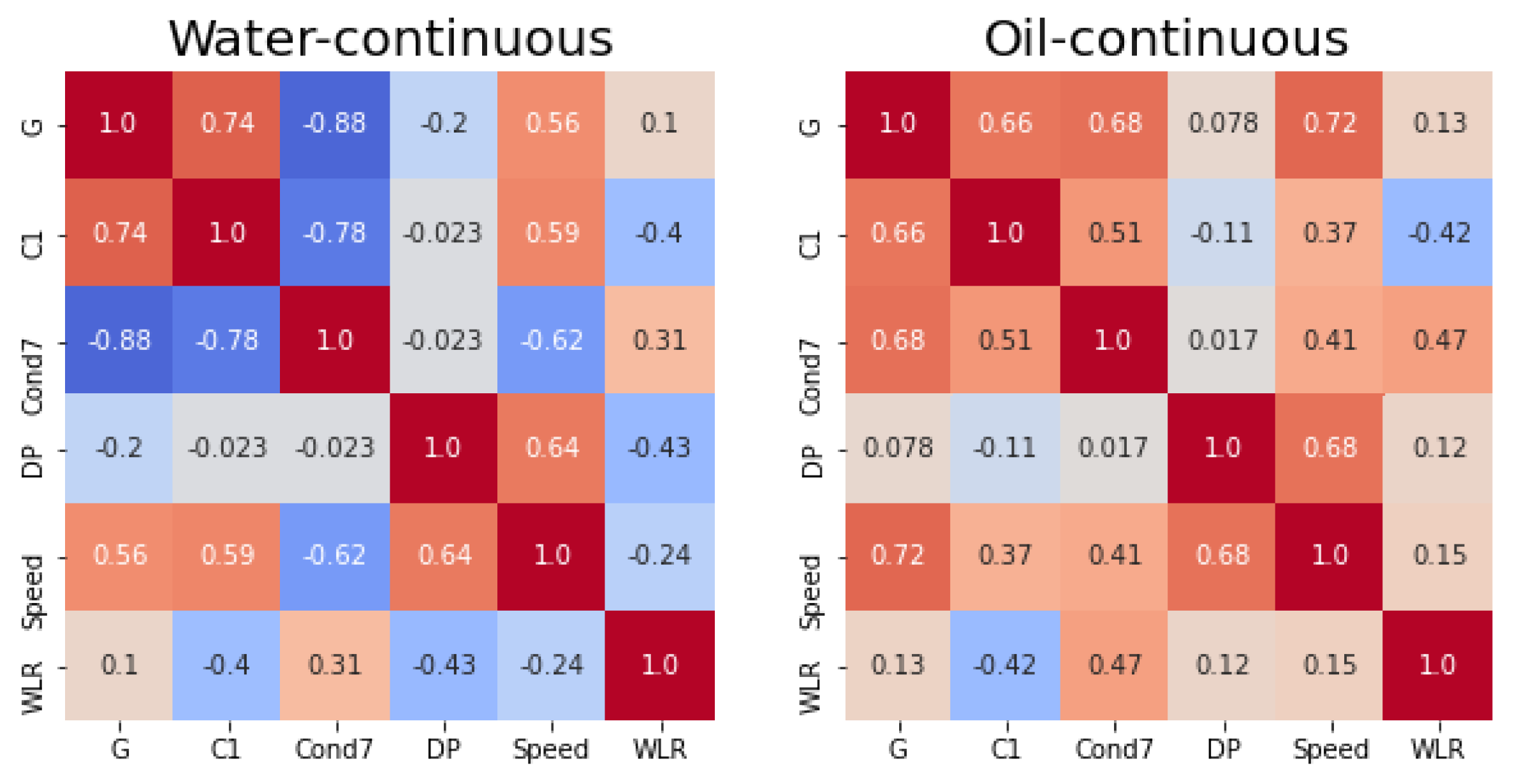
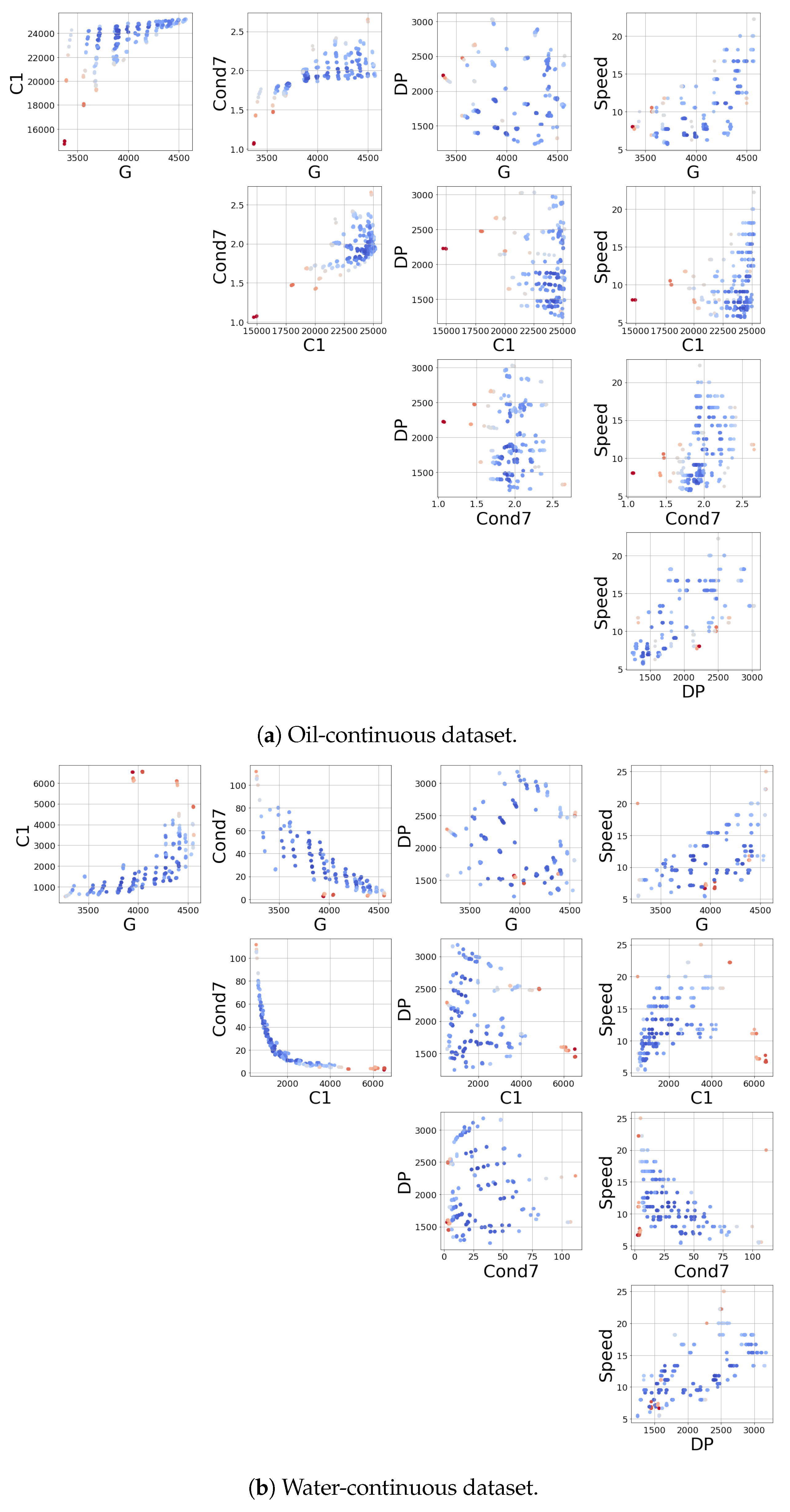
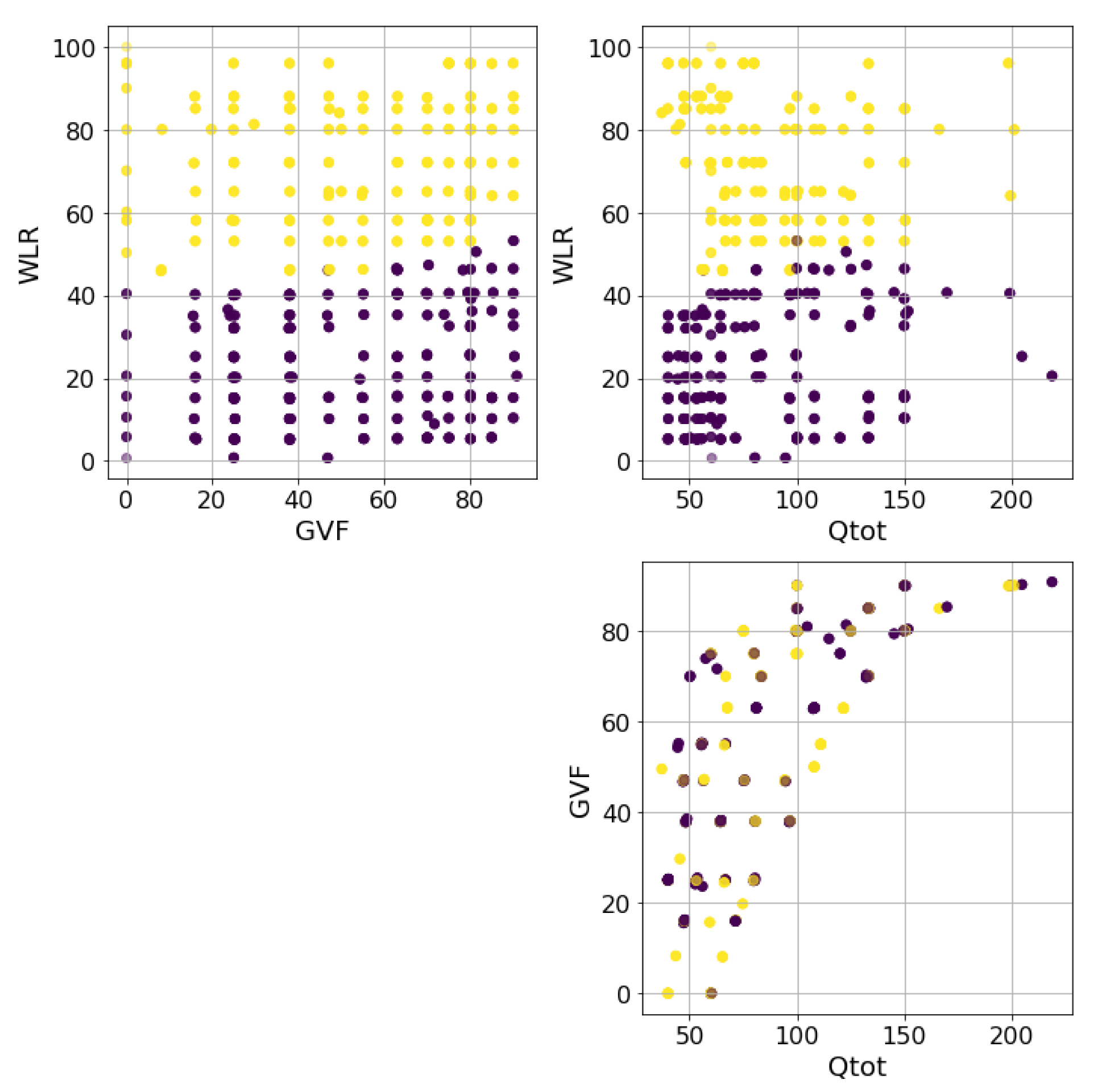
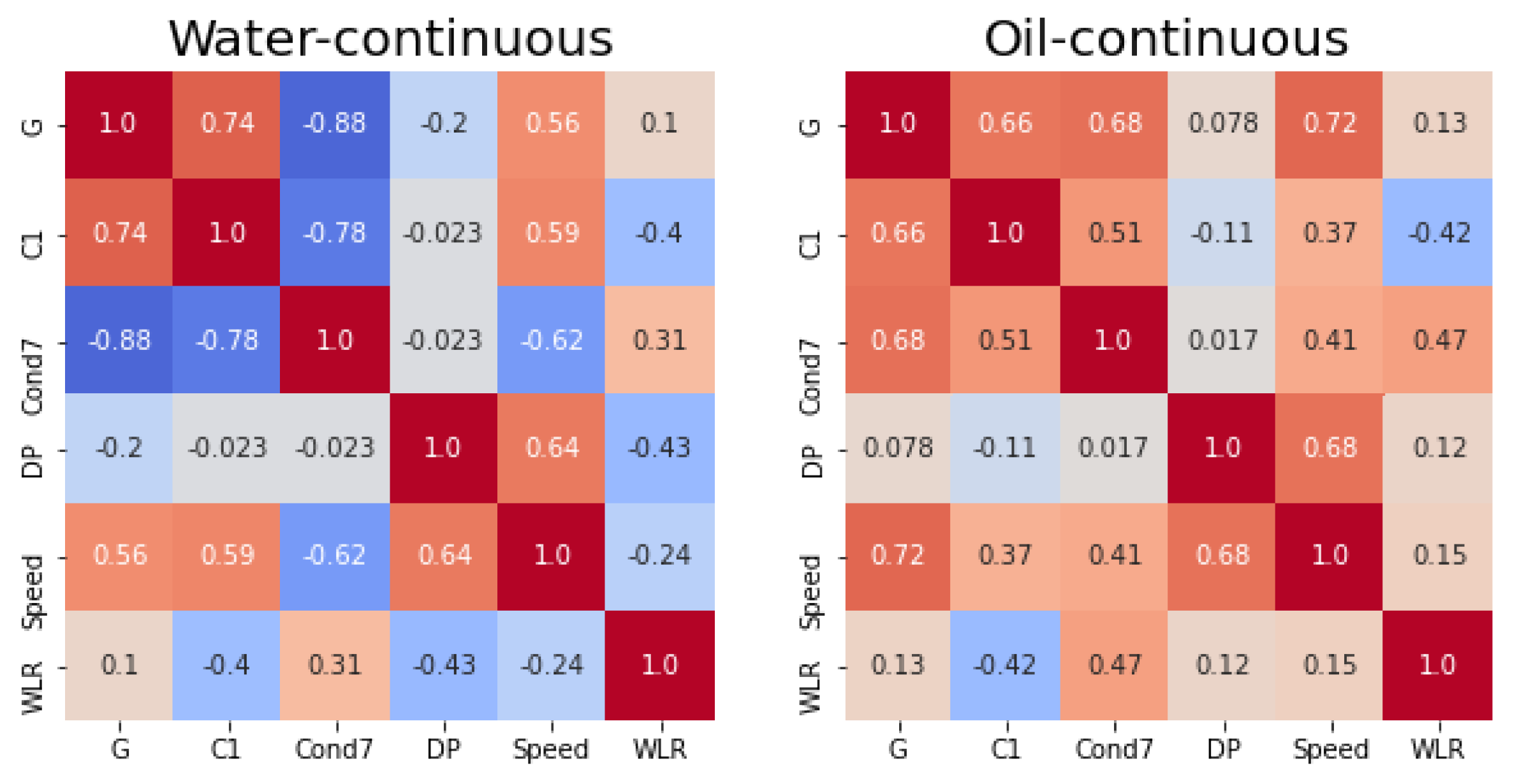
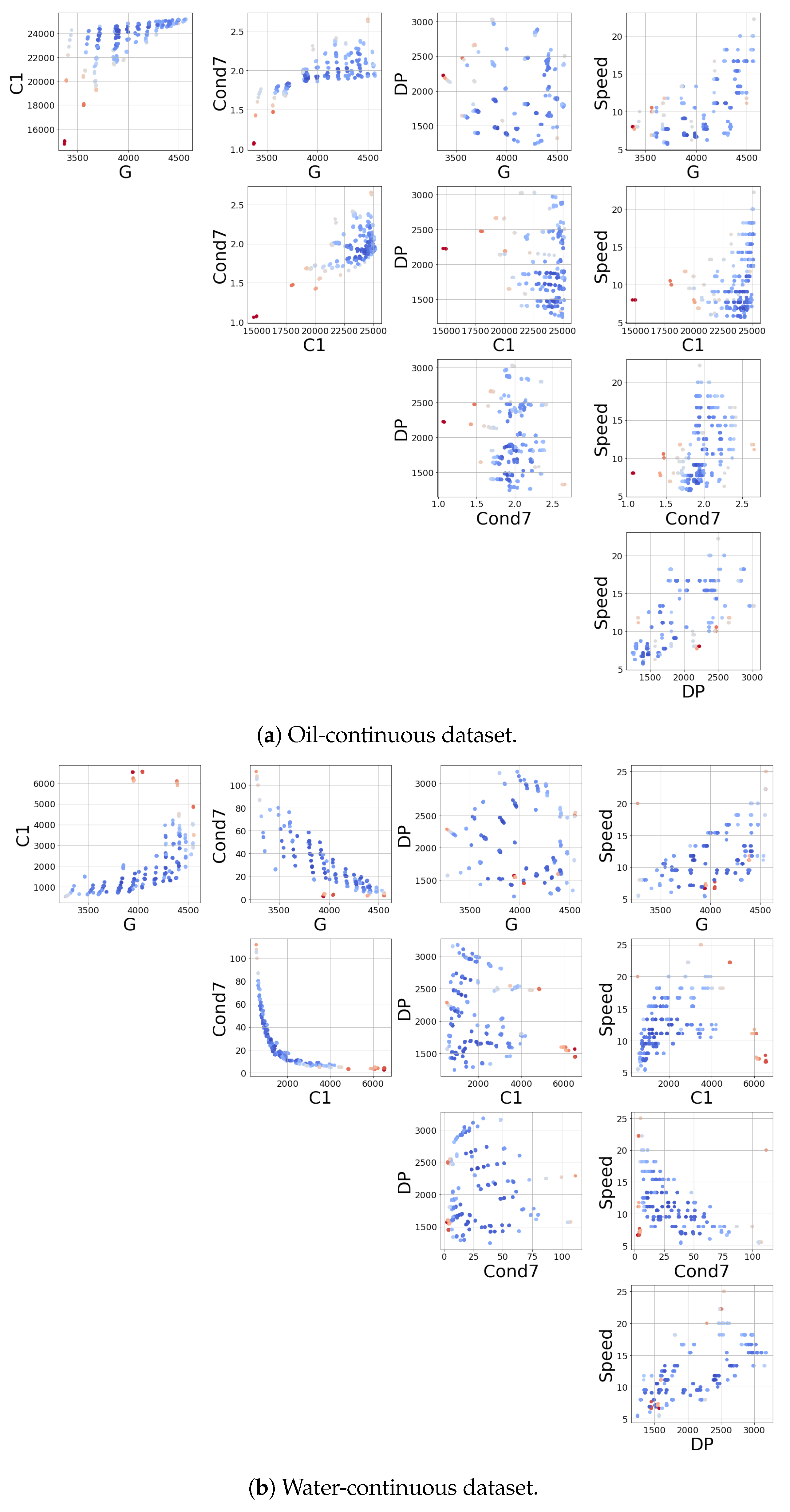
4. Instrument and Data Collection
4.1. Multiphase Flow Measurement Technology
4.1.1. Venturi Meter
4.1.2. Electrical Impedance Sensors
4.1.3. Gamma Densitometer
4.2. Data Collection
- Gas and liquid reference meters
- Temperature, pressure, and pressure difference transmitters
- Online gas densitometer
- Gas volume fraction
- Nucleonic level measurement
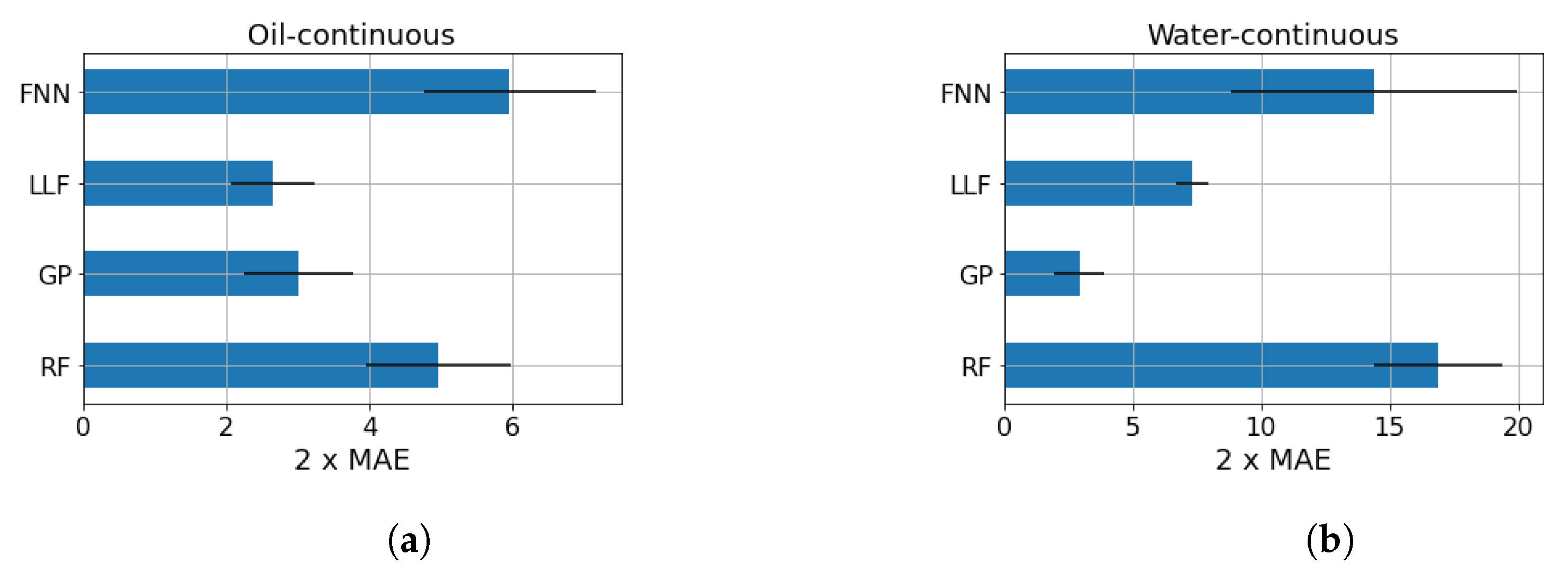
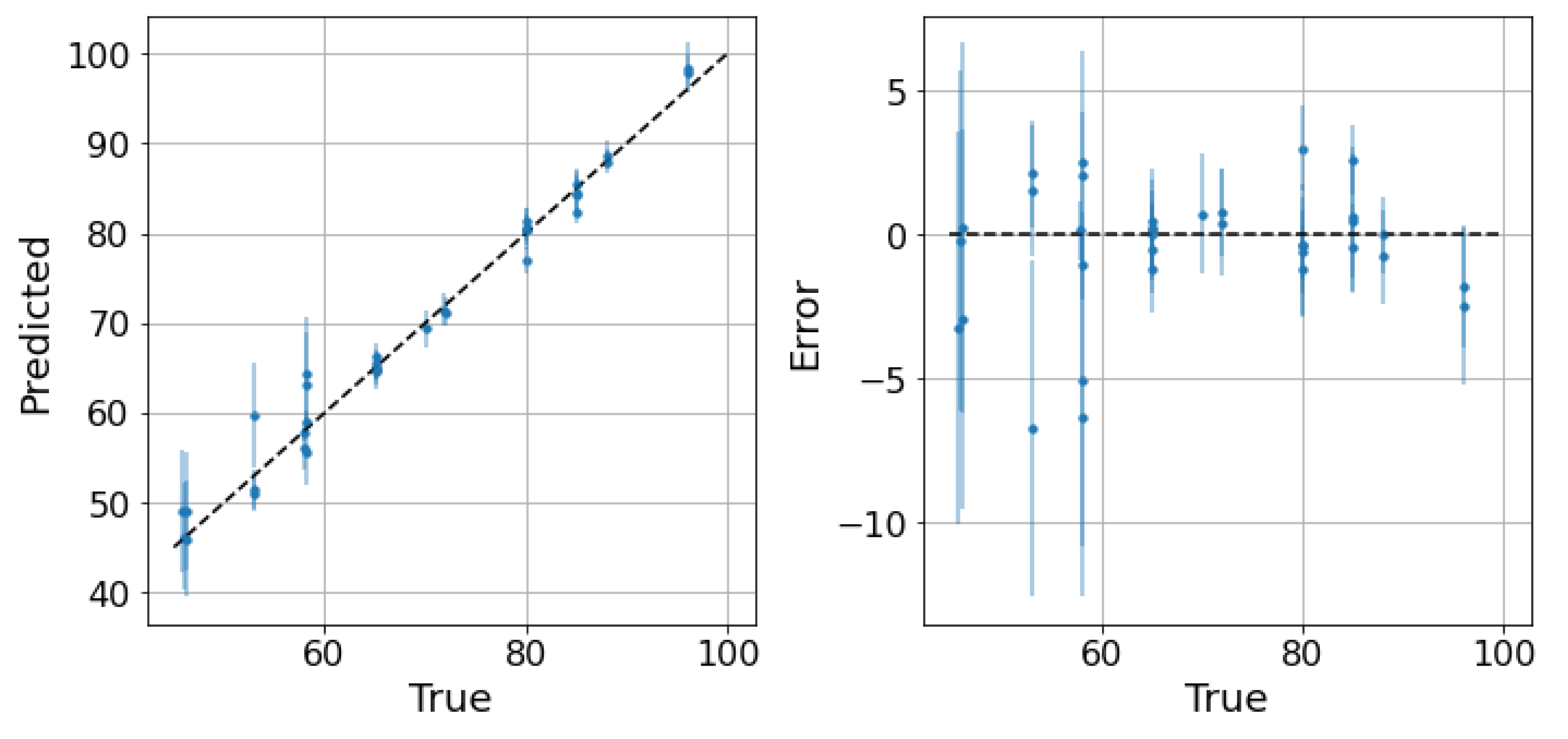
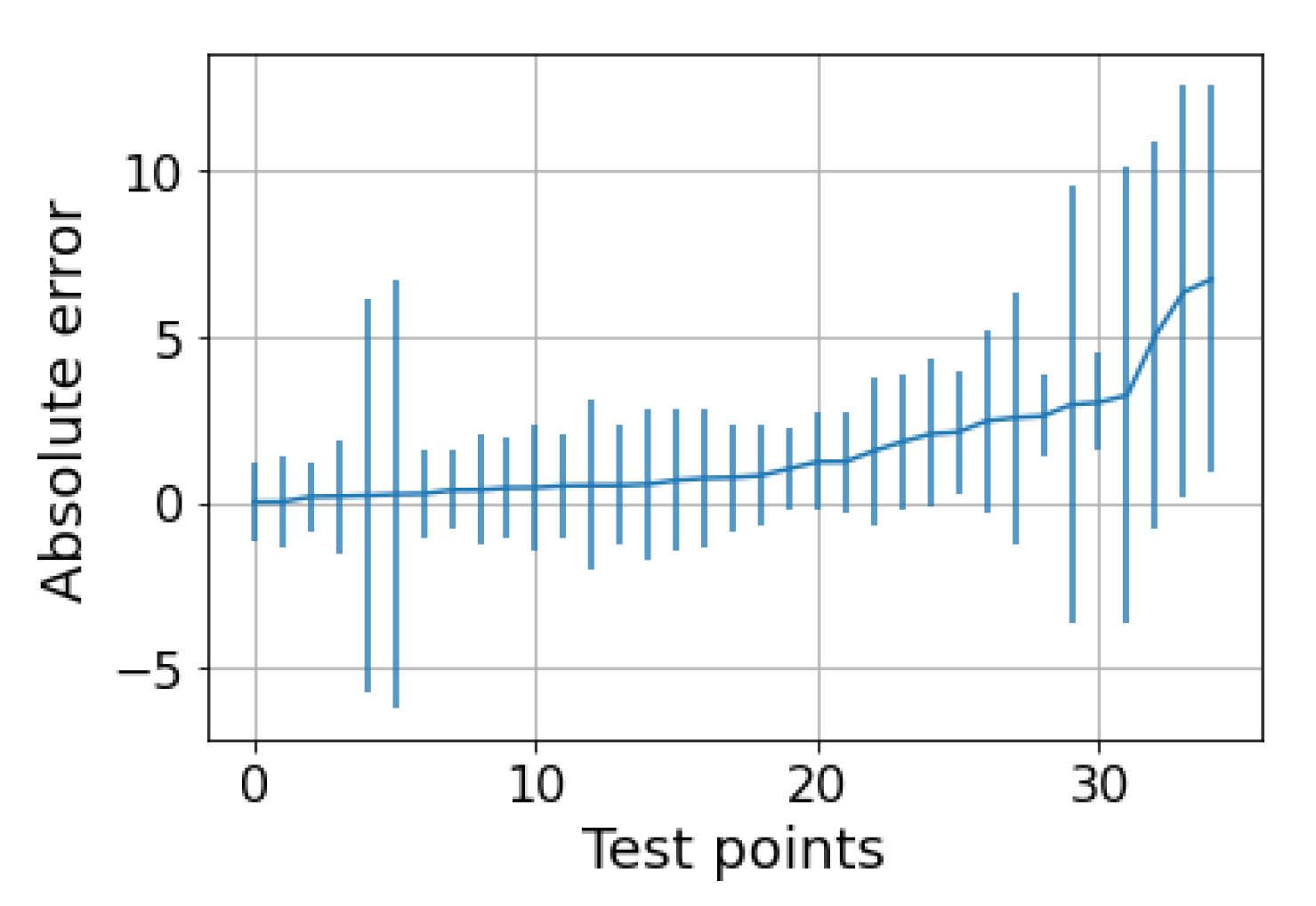
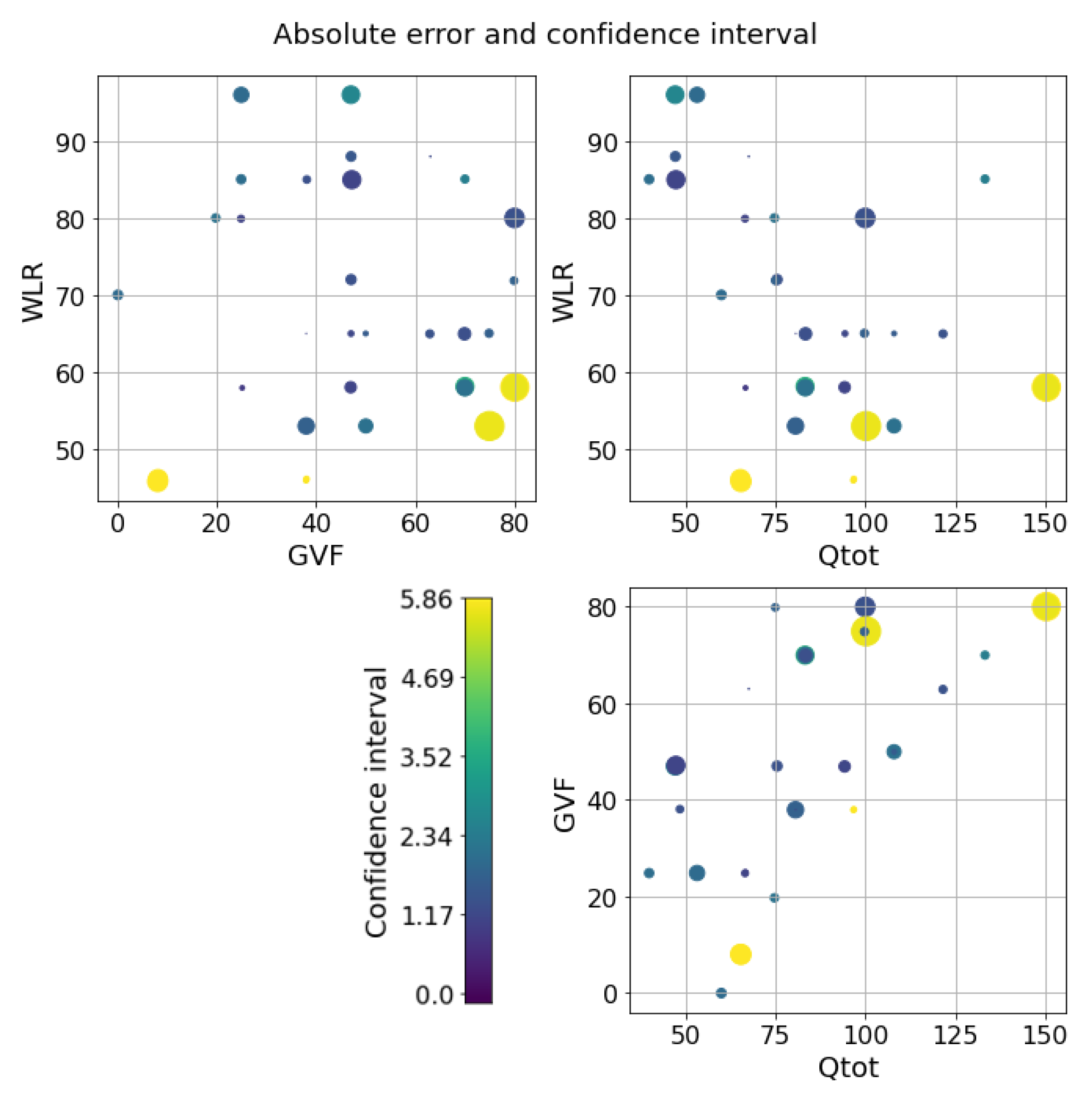
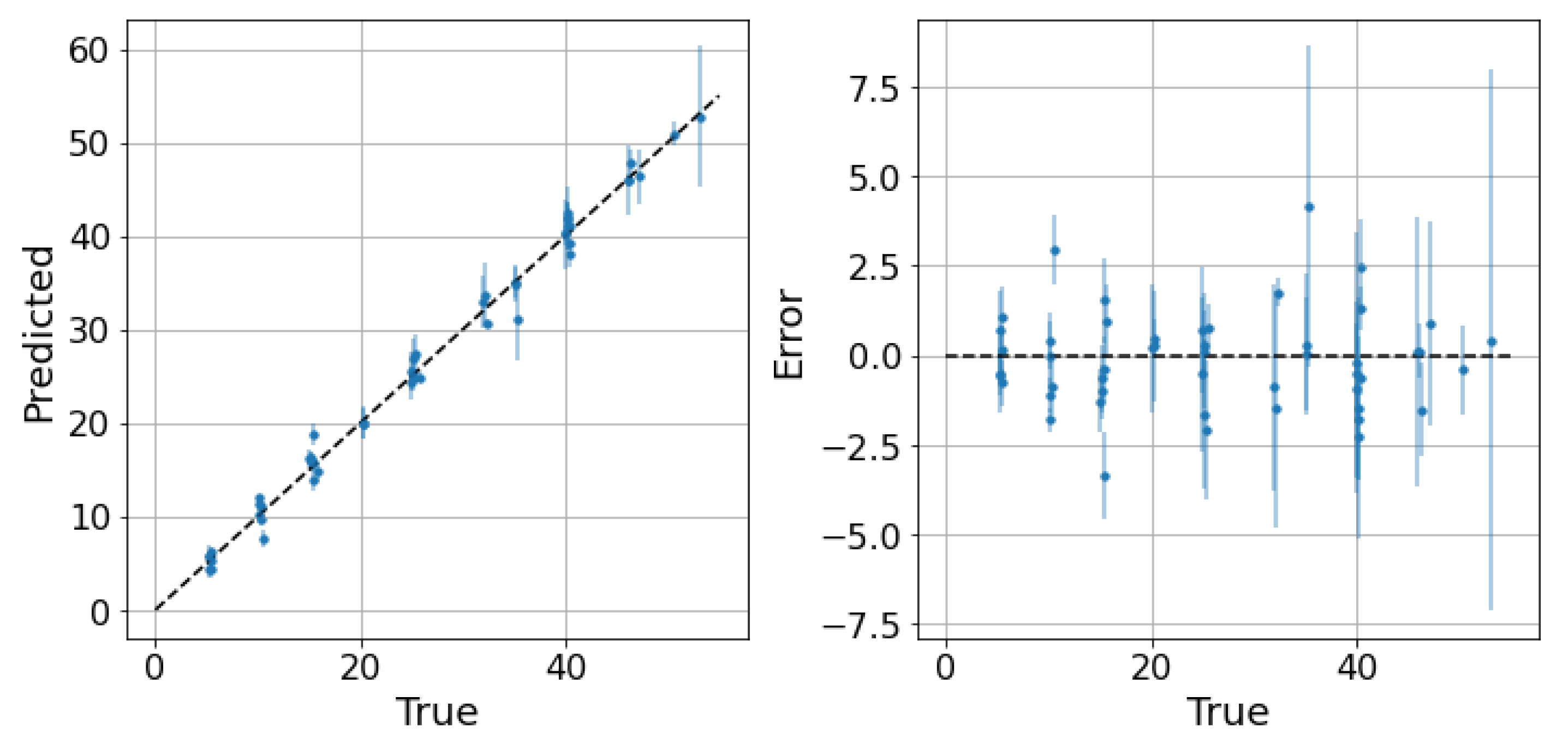
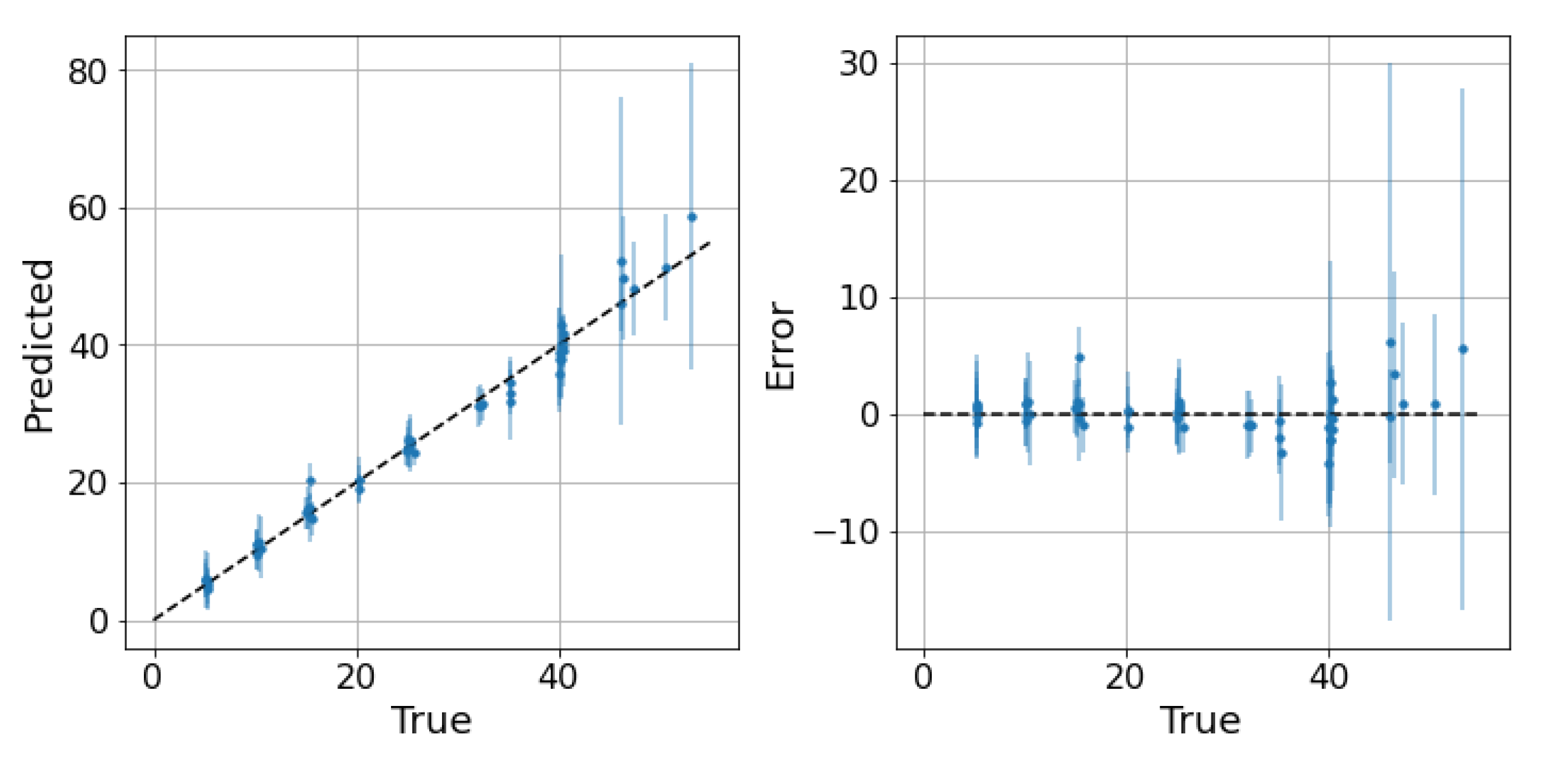
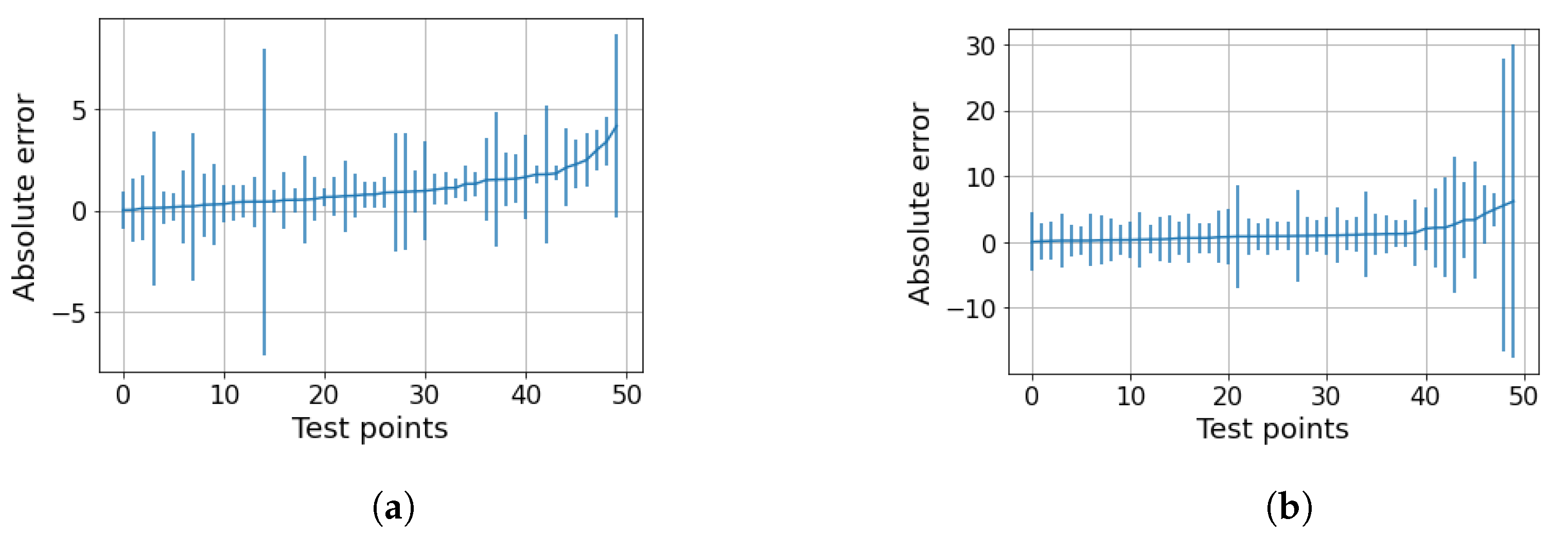
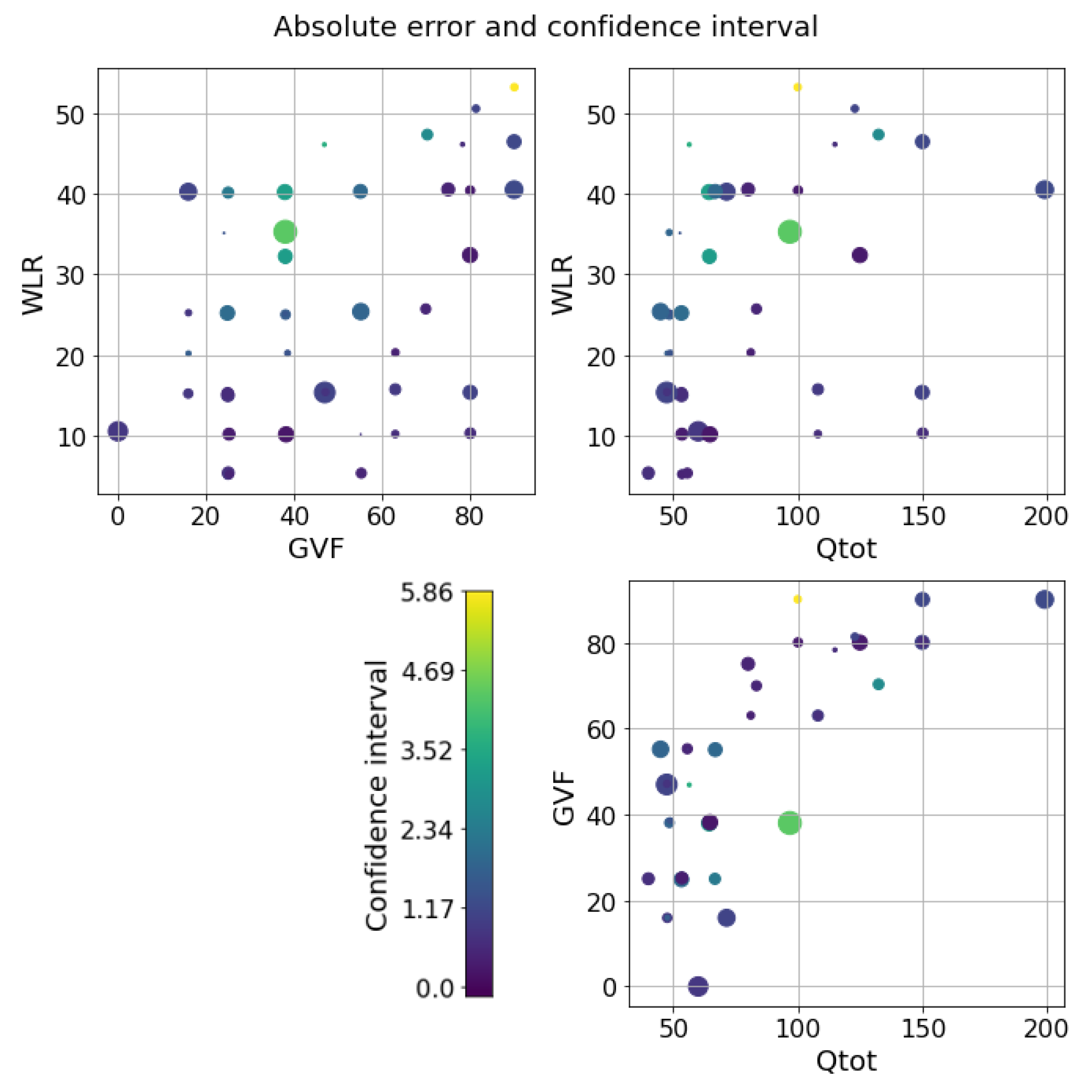
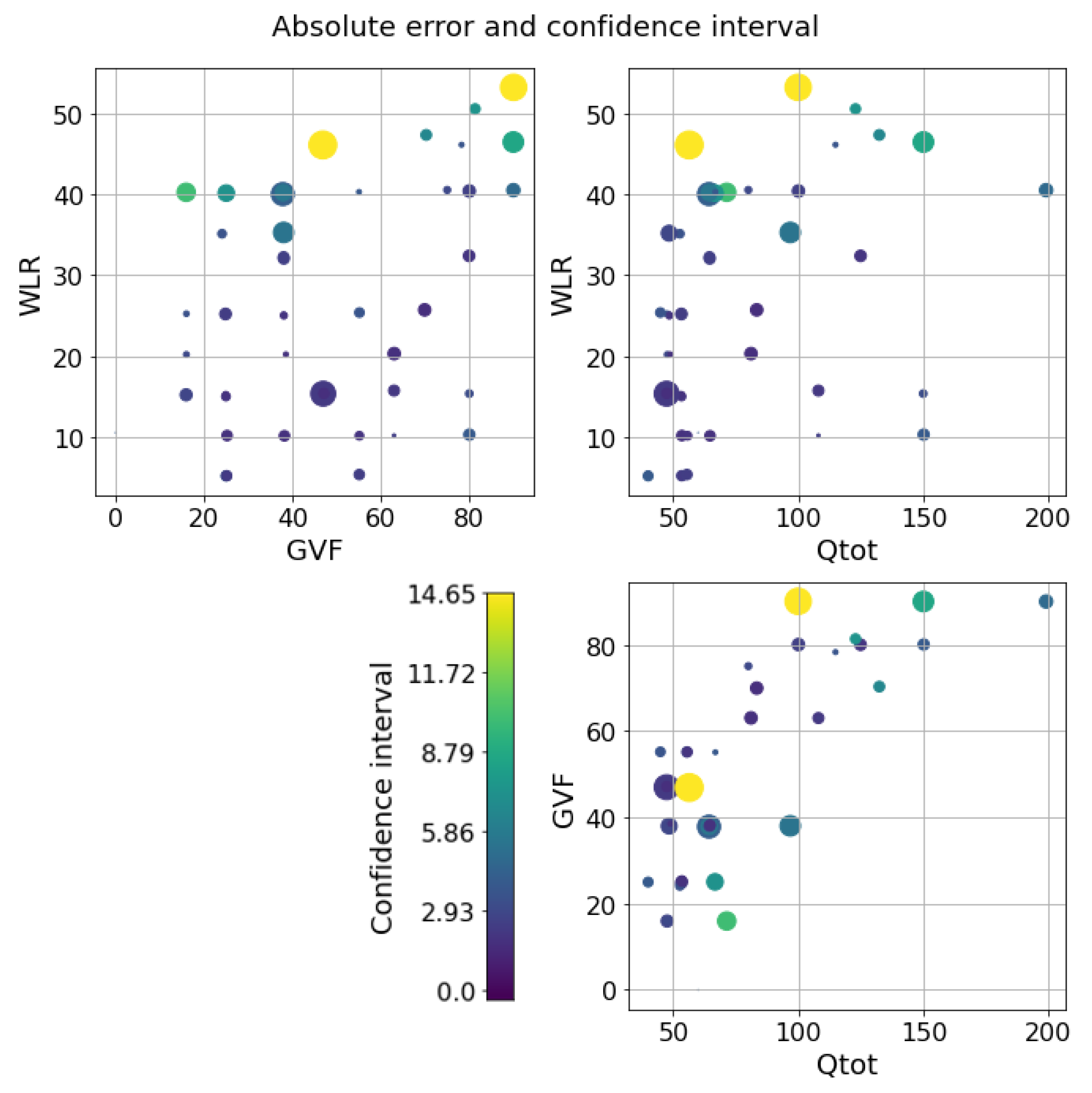
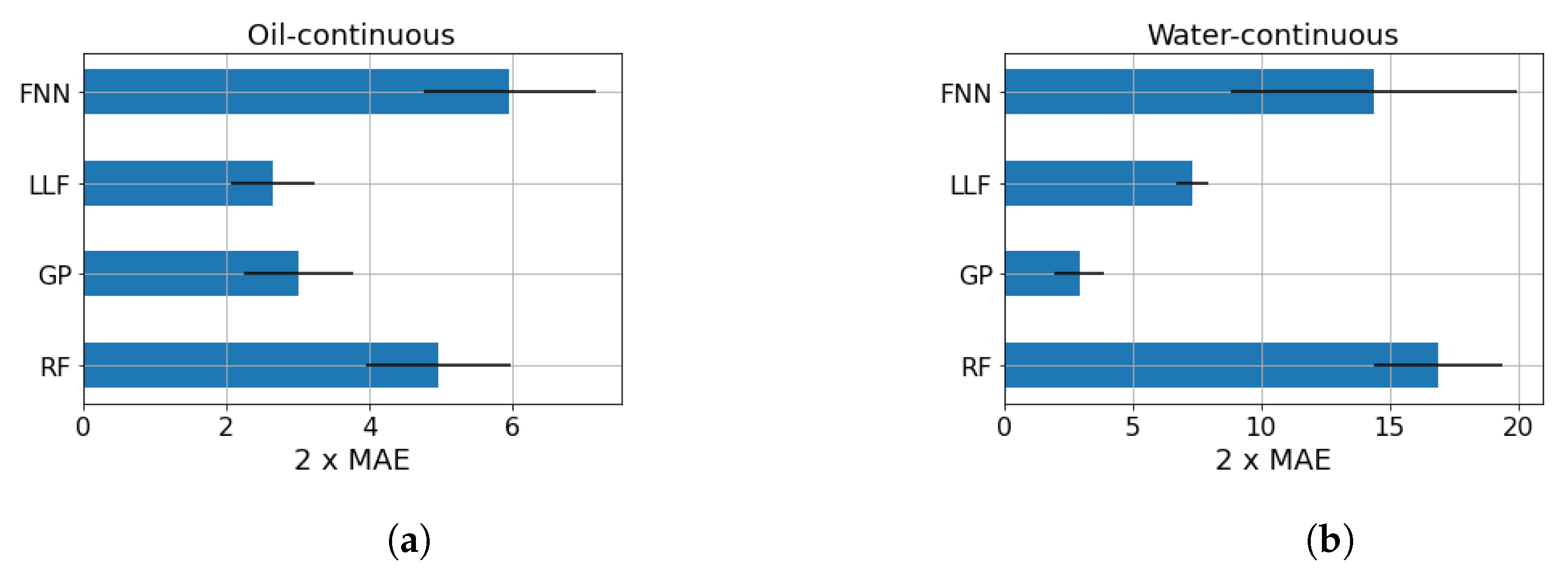
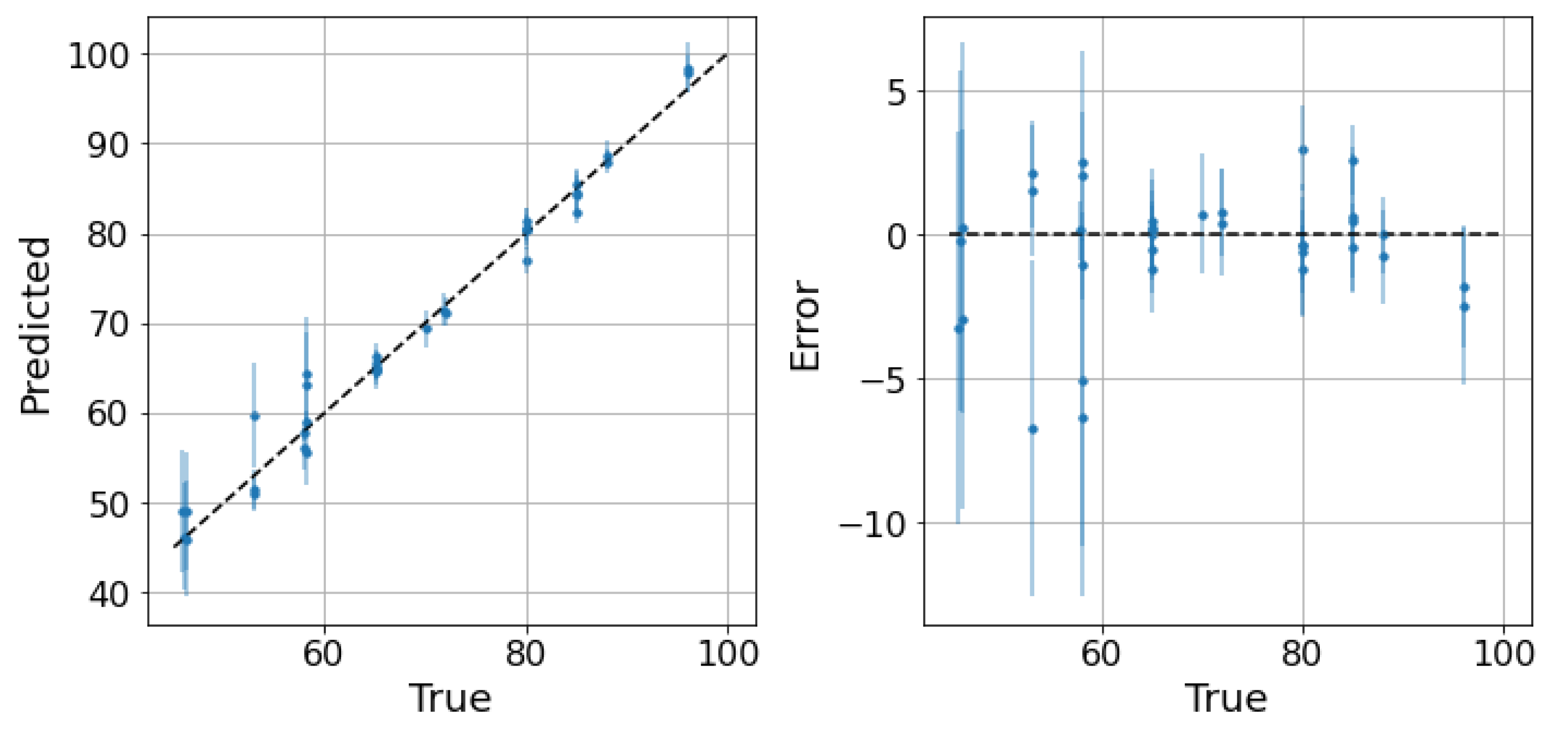
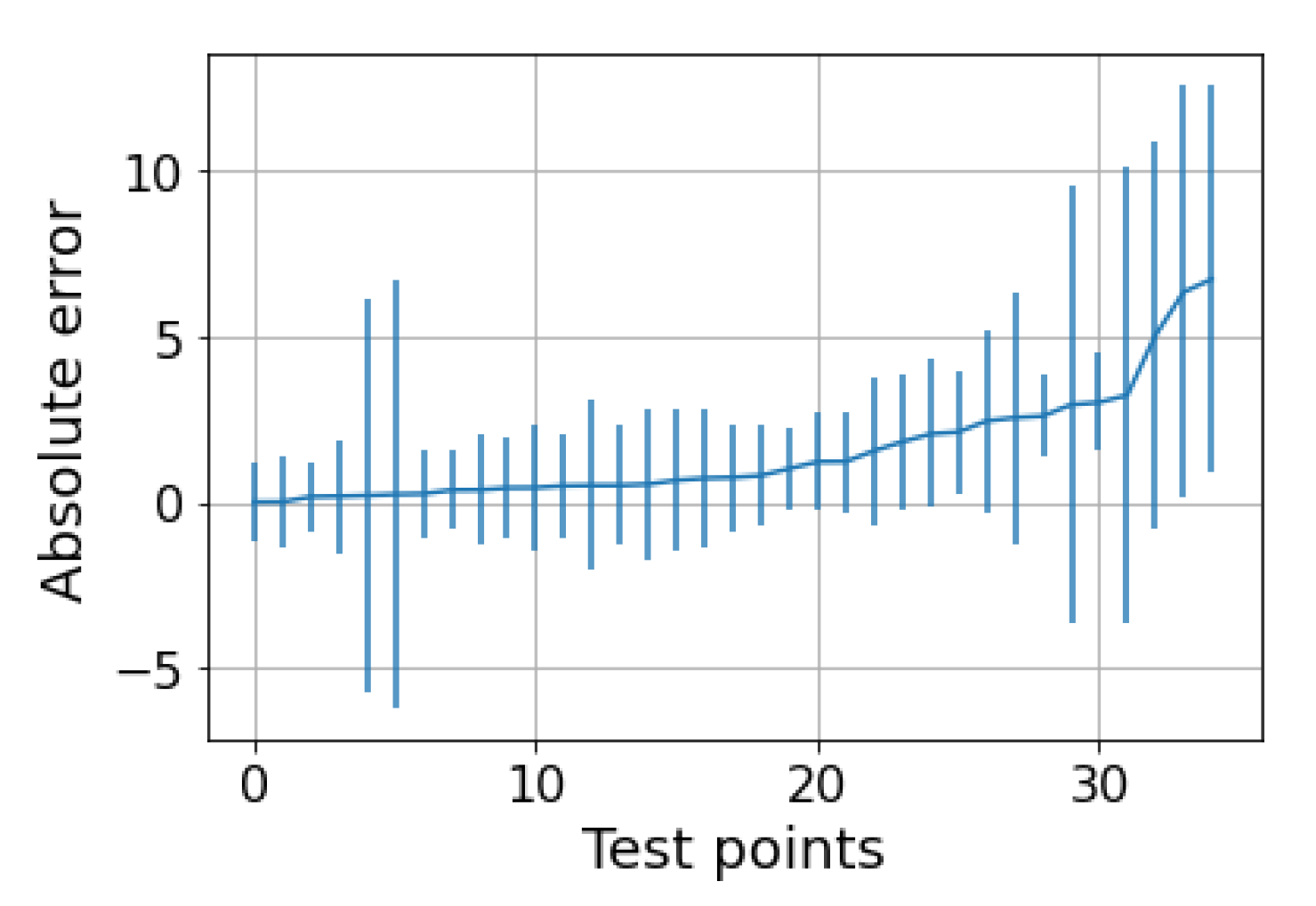
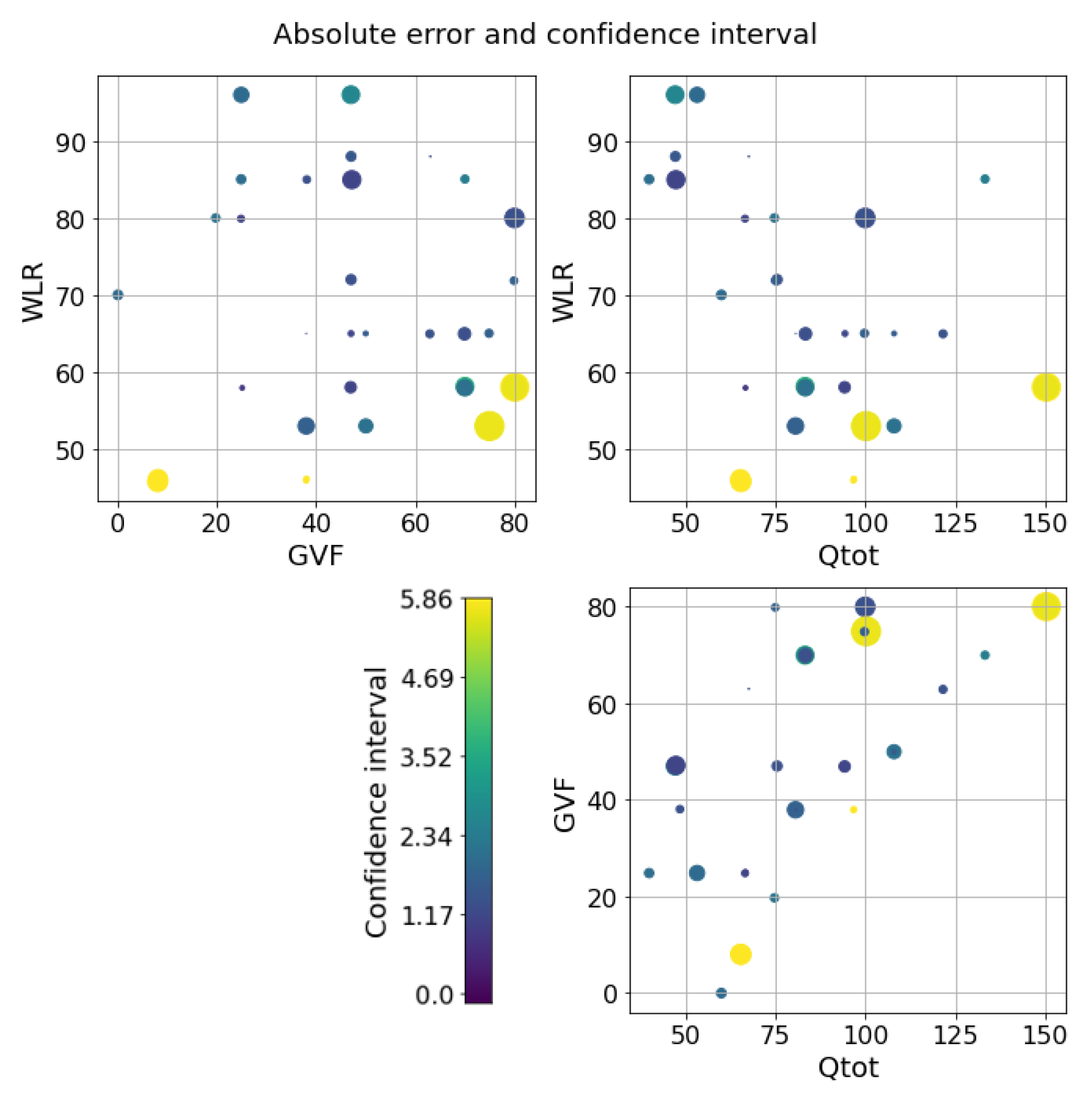
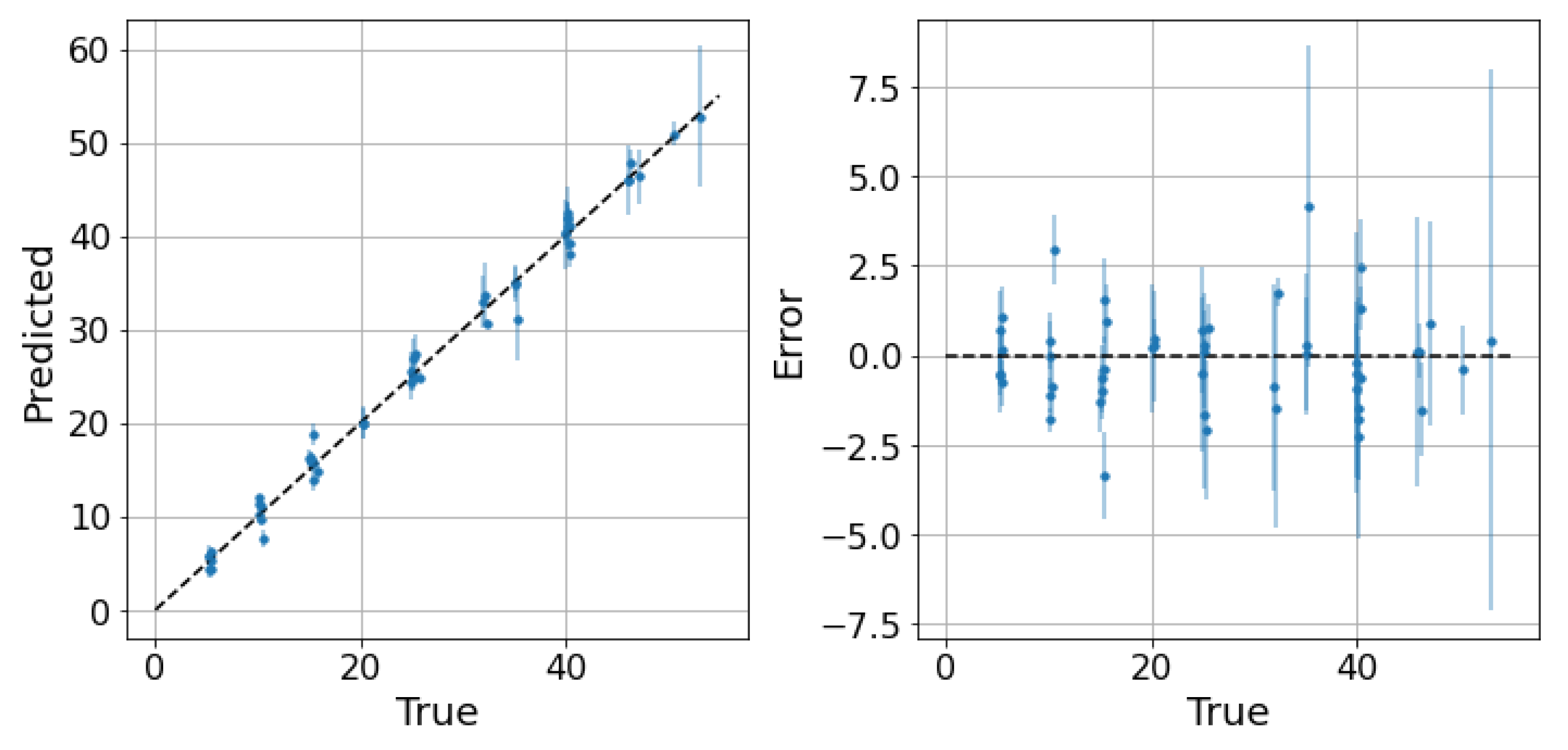
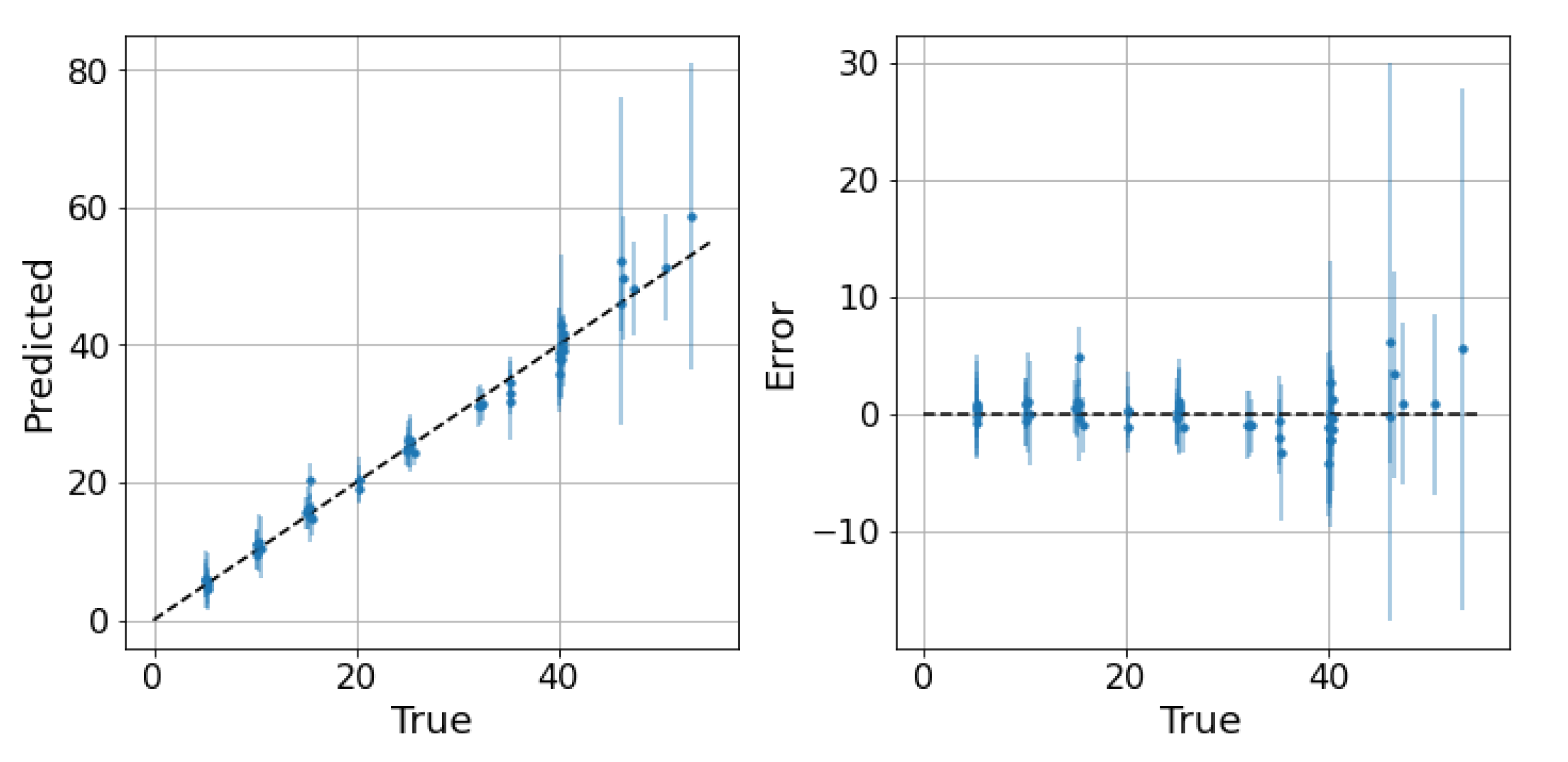
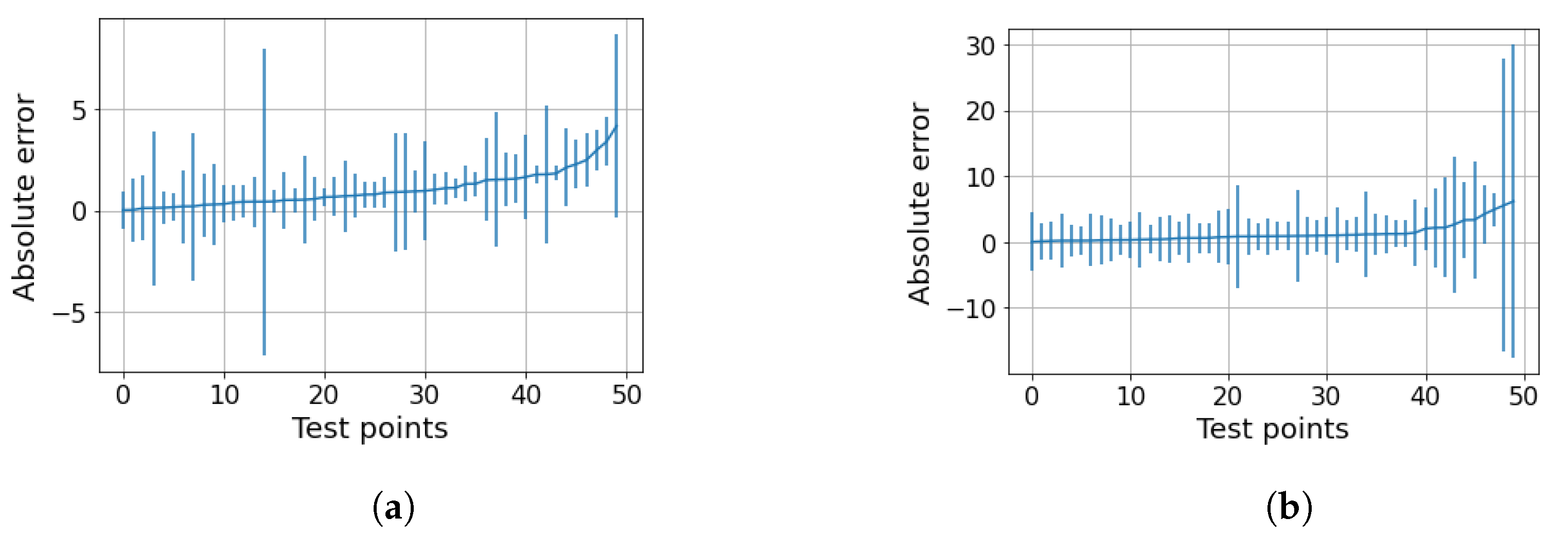
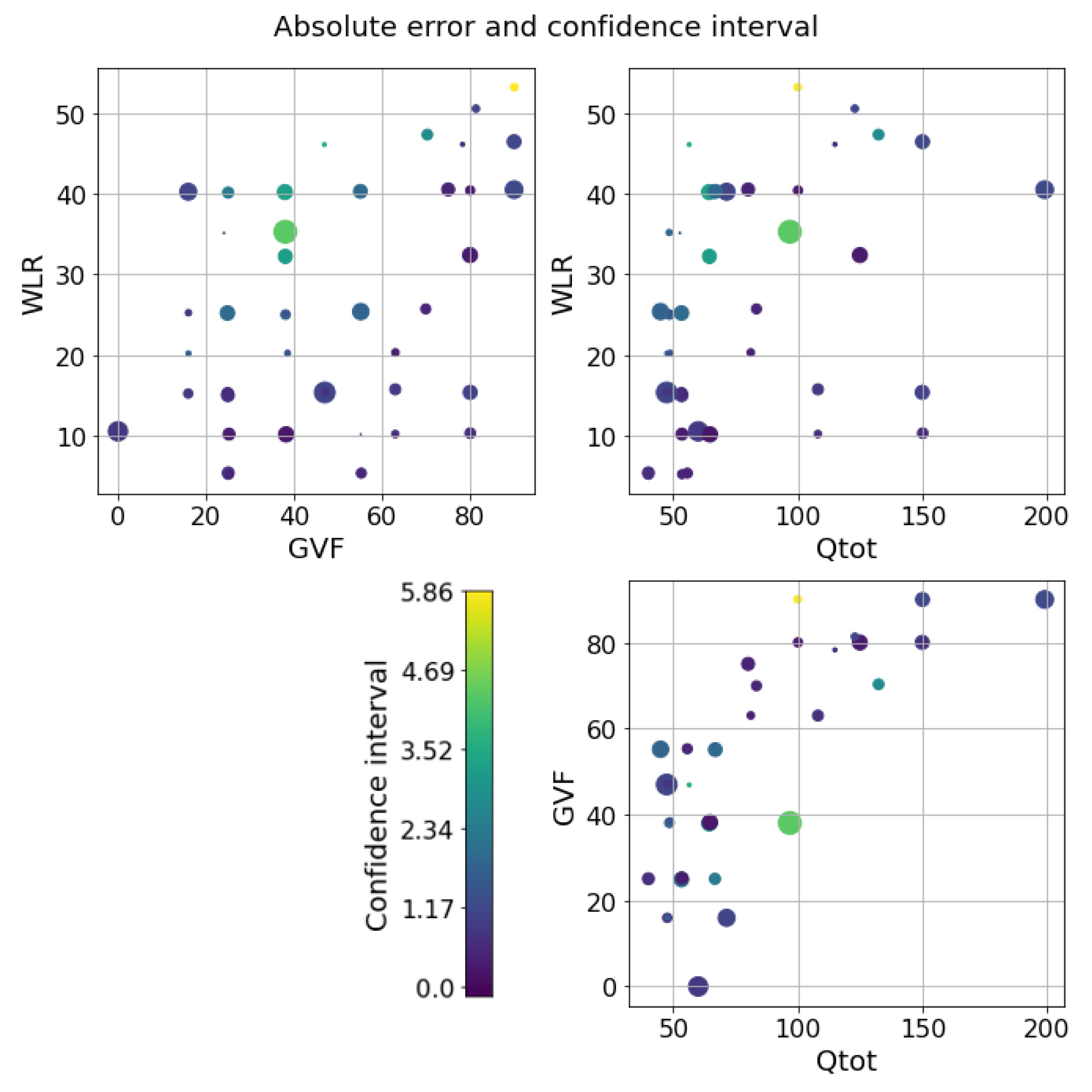
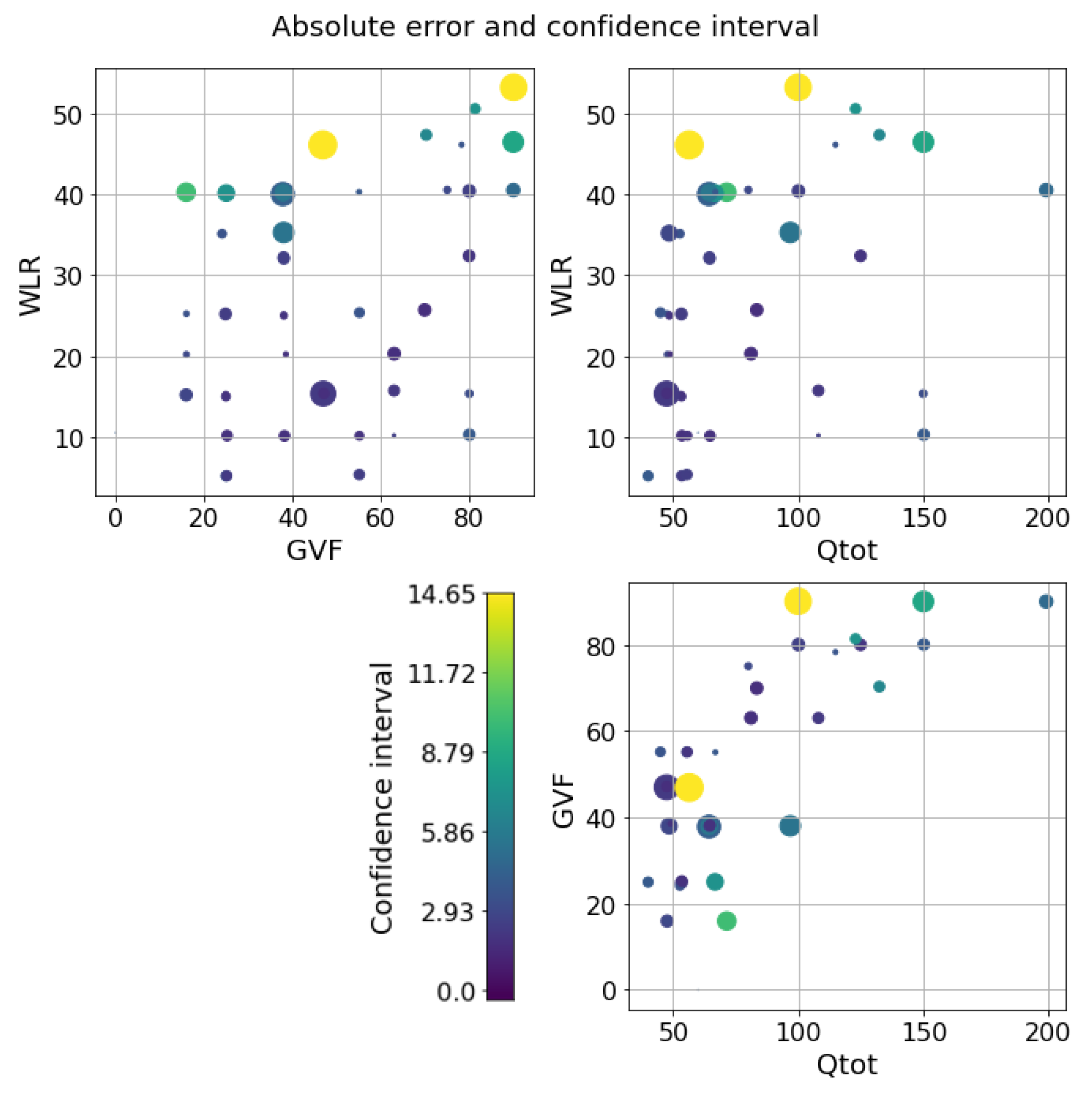
5. Results
6. Conclusions
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Data Availability Statement
Conflicts of Interest
References
- Market Report: Oil 2021. Available online: https://www.iea.org/reports/oil-2021 (accessed on 1 September 2021).
- Datta, D.; Mishra, S.; Rajest, S.S. Quantification of tolerance limits of engineering system using uncertainty modeling for sustainable energy. Int. J. Intell. Netw. 2020, 1, 1–8. [Google Scholar] [CrossRef]
- Paziresh, M.; Jafari, M.A.; Feshari, M. Confidence Interval for Solutions of the Black-Scholes Model. Adv. Math. Financ. Appl. 2019, 4, 49–58. [Google Scholar]
- Tang, N.S.; Qiu, S.F.; Tang, M.L.; Pei, Y.B. Asymptotic confidence interval construction for proportion difference in medical studies with bilateral data. Stat. Methods Med. Res. 2011, 20, 233–259. [Google Scholar] [CrossRef] [PubMed]
- Council, N.R. Assessing the Reliability of Complex Models: Mathematical and Statistical Foundations of Verification, Validation, and Uncertainty Quantification; The National Academies Press: Washington, DC, USA, 2012. [Google Scholar] [CrossRef]
- Hansen, L.S.; Pedersen, S.; Durdevic, P. Multi-phase flow metering in offshore oil and gas transportation pipelines: Trends and perspectives. Sensors 2019, 19, 2184. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Thorn, R.; Johansen, G.A.; Hjertaker, B.T. Three-phase flow measurement in the petroleum industry. Meas. Sci. Technol. 2012, 24, 012003. [Google Scholar] [CrossRef]
- Bikmukhametov, T.; Jäschke, J. First principles and machine learning virtual flow metering: A literature review. J. Pet. Sci. Eng. 2020, 184, 106487. [Google Scholar] [CrossRef]
- Sircar, A.; Yadav, K.; Rayavarapu, K.; Bist, N.; Oza, H. Application of machine learning and artificial intelligence in oil and gas industry. Pet. Res. 2021. [Google Scholar] [CrossRef]
- Zambonin, G.; Altinier, F.; Beghi, A.; Coelho, L.d.S.; Fiorella, N.; Girotto, T.; Rampazzo, M.; Reynoso-Meza, G.; Susto, G.A. Machine learning-based soft sensors for the estimation of laundry moisture content in household dryer appliances. Energies 2019, 12, 3843. [Google Scholar] [CrossRef] [Green Version]
- Musil, F.; Willatt, M.J.; Langovoy, M.A.; Ceriotti, M. Fast and accurate uncertainty estimation in chemical machine learning. J. Chem. Theory Comput. 2019, 15, 906–915. [Google Scholar] [CrossRef] [Green Version]
- Imbalzano, G.; Zhuang, Y.; Kapil, V.; Rossi, K.; Engel, E.A.; Grasselli, F.; Ceriotti, M. Uncertainty estimation for molecular dynamics and sampling. J. Chem. Phys. 2021, 154, 074102. [Google Scholar] [CrossRef]
- Tian, Y.; Yuan, R.; Xue, D.; Zhou, Y.; Ding, X.; Sun, J.; Lookman, T. Role of uncertainty estimation in accelerating materials development via active learning. J. Appl. Phys. 2020, 128, 014103. [Google Scholar] [CrossRef]
- Li, Y.; Gao, Z.; He, Z.; Zhuang, Y.; Radi, A.; Chen, R.; El-Sheimy, N. Wireless fingerprinting uncertainty prediction based on machine learning. Sensors 2019, 19, 324. [Google Scholar] [CrossRef] [Green Version]
- Ani, M.; Oluyemi, G.; Petrovski, A.; Rezaei-Gomari, S. Reservoir uncertainty analysis: The trends from probability to algorithms and machine learning. In Proceedings of the SPE Intelligent Energy International Conference and Exhibition, OnePetro, Aberdeen, Scotland, UK, 6–8 September 2016. [Google Scholar]
- Alizadehsani, R.; Roshanzamir, M.; Hussain, S.; Khosravi, A.; Koohestani, A.; Zangooei, M.H.; Abdar, M.; Beykikhoshk, A.; Shoeibi, A.; Zare, A.; et al. Handling of uncertainty in medical data using machine learning and probability theory techniques: A review of 30 years (1991–2020). Ann. Oper. Res. 2021, 1–42. [Google Scholar] [CrossRef]
- Yan, Y.; Wang, L.; Wang, T.; Wang, X.; Hu, Y.; Duan, Q. Application of soft computing techniques to multiphase flow measurement: A review. Flow Meas. Instrum. 2018, 60, 30–43. [Google Scholar] [CrossRef]
- Gel, A.; Garg, R.; Tong, C.; Shahnam, M.; Guenther, C. Applying uncertainty quantification to multiphase flow computational fluid dynamics. Powder Technol. 2013, 242, 27–39. [Google Scholar] [CrossRef]
- Hu, X. Uncertainty Quantification Tools for Multiphase Gas-Solid Flow Simulations Using MFIX. Ph.D. Thesis, Iowa State University, Ames, IA, USA, 2014. [Google Scholar]
- Zhang, X.; Xiao, H.; Gomez, T.; Coutier-Delgosha, O. Evaluation of ensemble methods for quantifying uncertainties in steady-state CFD applications with small ensemble sizes. Comput. Fluids 2020, 203, 104530. [Google Scholar] [CrossRef] [Green Version]
- Valdez, A.R.; Rocha, B.M.; Chapiro, G.; dos Santos, R.W. Uncertainty quantification and sensitivity analysis for relative permeability models of two-phase flow in porous media. J. Pet. Sci. Eng. 2020, 192, 107297. [Google Scholar] [CrossRef]
- Roshani, G.; Nazemi, E.; Roshani, M. Intelligent recognition of gas-oil-water three-phase flow regime and determination of volume fraction using radial basis function. Flow Meas. Instrum. 2017, 54, 39–45. [Google Scholar] [CrossRef]
- AL-Qutami, T.A.; Ibrahim, R.; Ismail, I.; Ishak, M.A. Radial basis function network to predict gas flow rate in multiphase flow. In Proceedings of the 9th International Conference on Machine Learning and Computing, Singapore, 24–26 February 2017; pp. 141–146. [Google Scholar]
- Zhao, C.; Wu, G.; Zhang, H.; Li, Y. Measurement of water-to-liquid ratio of oil-water-gas three-phase flow using microwave time series method. Measurement 2019, 140, 511–517. [Google Scholar] [CrossRef]
- Bahrami, B.; Mohsenpour, S.; Noghabi, H.R.S.; Hemmati, N.; Tabzar, A. Estimation of flow rates of individual phases in an oil-gas-water multiphase flow system using neural network approach and pressure signal analysis. Flow Meas. Instrum. 2019, 66, 28–36. [Google Scholar] [CrossRef]
- Khan, M.R.; Tariq, Z.; Abdulraheem, A. Application of artificial intelligence to estimate oil flow rate in gas-lift wells. Nat. Resour. Res. 2020, 29, 4017–4029. [Google Scholar] [CrossRef]
- Dave, A.J.; Manera, A. Inference of Gas-liquid Flowrate using Neural Networks. arXiv 2020, arXiv:2003.08182. [Google Scholar]
- Zhang, H.; Yang, Y.; Yang, M.; Min, L.; Li, Y.; Zheng, X. A Novel CNN Modeling Algorithm for the Instantaneous Flow Rate Measurement of Gas-liquid Multiphase Flow. In Proceedings of the 2020 12th International Conference on Machine Learning and Computing, Shenzhen, China, 15–17 February 2020; pp. 182–187. [Google Scholar]
- Hu, D.; Li, J.; Liu, Y.; Li, Y. Flow Adversarial Networks: Flowrate Prediction for Gas–Liquid Multiphase Flows Across Different Domains. IEEE Trans. Neural Netw. Learn. Syst. 2019, 31, 475–487. [Google Scholar] [CrossRef]
- Fan, S.; Yan, T. Two-phase air–water slug flow measurement in horizontal pipe using conductance probes and neural network. IEEE Trans. Instrum. Meas. 2013, 63, 456–466. [Google Scholar] [CrossRef]
- Ismail, I.; Gamio, J.; Bukhari, S.A.; Yang, W. Tomography for multi-phase flow measurement in the oil industry. Flow Meas. Instrum. 2005, 16, 145–155. [Google Scholar] [CrossRef]
- Mohamad, E.J.; Rahim, R.; Rahiman, M.H.F.; Ameran, H.; Muji, S.; Marwah, O. Measurement and analysis of water/oil multiphase flow using Electrical Capacitance Tomography sensor. Flow Meas. Instrum. 2016, 47, 62–70. [Google Scholar] [CrossRef]
- Aravantinos, V.; Schlicht, P. Making the relationship between uncertainty estimation and safety less uncertain. In Proceedings of the IEEE 2020 Design, Automation & Test in Europe Conference & Exhibition (DATE), Grenoble, France, 9–13 March 2020; pp. 1139–1144. [Google Scholar]
- Liu, J.Z.; Paisley, J.; Kioumourtzoglou, M.A.; Coull, B. Accurate uncertainty estimation and decomposition in ensemble learning. arXiv 2019, arXiv:1911.04061. [Google Scholar]
- Shrestha, D.L.; Solomatine, D.P. Machine learning approaches for estimation of prediction interval for the model output. Neural Netw. 2006, 19, 225–235. [Google Scholar] [CrossRef]
- Abdar, M.; Pourpanah, F.; Hussain, S.; Rezazadegan, D.; Liu, L.; Ghavamzadeh, M.; Fieguth, P.; Cao, X.; Khosravi, A.; Acharya, U.R.; et al. A review of uncertainty quantification in deep learning: Techniques, applications and challenges. Inf. Fusion 2021, 76, 243–297. [Google Scholar] [CrossRef]
- Vaysse, K.; Lagacherie, P. Using quantile regression forest to estimate uncertainty of digital soil mapping products. Geoderma 2017, 291, 55–64. [Google Scholar] [CrossRef]
- Gal, Y.; Ghahramani, Z. Dropout as a bayesian approximation: Representing model uncertainty in deep learning. In Proceedings of the International Conference on Machine Learning, PMLR, New York City, NY, USA, 19–24 June 2016; pp. 1050–1059. [Google Scholar]
- Goodfellow, I.; Bengio, Y.; Courville, A.; Bengio, Y. Deep Learning; Volume 1, MIT Press: Cambridge, MA, USA, 2016. [Google Scholar]
- Rasmussen, C.E. Gaussian processes in machine learning. In Summer School on Machine Learning; Springer: Berlin, Heidelberg, 2003; pp. 63–71. [Google Scholar]
- Duvenaud, D. Automatic Model Construction with Gaussian Processes. Ph.D. Thesis, Computational and Biological Learning Laboratory, University of Cambridge, Cambridge, UK, 2014. [Google Scholar]
- Friedberg, R.; Tibshirani, J.; Athey, S.; Wager, S. Local linear forests. J. Comput. Graph. Stat. 2020, 30, 503–517. [Google Scholar] [CrossRef]
- Wager, S.; Hastie, T.; Efron, B. Confidence intervals for random forests: The jackknife and the infinitesimal jackknife. J. Mach. Learn. Res. 2014, 15, 1625–1651. [Google Scholar] [PubMed]
- Hastie, T.; Tibshirani, R.; Friedman, J. The Elements of Statistical Learning; Springer Series in Statistics; Springer New York Inc.: New York, NY, USA, 2001. [Google Scholar]
- Breiman, L. Random forests. Mach. Learn. 2001, 45, 5–32. [Google Scholar] [CrossRef] [Green Version]
- Barbariol, T.; Feltresi, E.; Susto, G.A. Self-Diagnosis of Multiphase Flow Meters through Machine Learning-Based Anomaly Detection. Energies 2020, 13, 3136. [Google Scholar] [CrossRef]
- Corneliussen, S.; Couput, J.P.; Dahl, E.; Dykesteen, E.; Frøysa, K.E.; Malde, E.; Moestue, H.; Moksnes, P.O.; Scheers, L.; Tunheim, H. Handbook of Multiphase Flow Metering; Norwegian Society for Oil and Gas Measurement: Olso, Norway, 2005. [Google Scholar]
- Barbosa, C.M.; Salgado, C.M.; Brandão, L.E.B. Study of Photon Attenuation Coefficient in Brine Using MCNP Code; Sao Paulo, Barsil, 2015; Available online: https://core.ac.uk/download/pdf/159274404.pdf (accessed on 23 July 2021).
- ProLabNL. Available online: http://www.prolabnl.com (accessed on 1 September 2021).
- Liu, F.T.; Ting, K.M.; Zhou, Z.H. Isolation forest. In Proceedings of the 2008 Eighth IEEE International Conference on Data Mining, Pisa, Italy, 15–19 December 2008; pp. 413–422. [Google Scholar]

{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| FNN | GP | LLF | RF | |
|---|---|---|---|---|
| 2 MAE | 14.36 | 2.94 | 7.34 | 16.89 |
| 2 RMSE | 17.60 | 3.89 | 9.66 | 19.96 |
| 95th percentile | 15.79 | 3.86 | 9.68 | 17.24 |
| FNN | GP | LLF | RF | |
|---|---|---|---|---|
| 2 MAE | 5.96 | 3.02 | 2.66 | 4.97 |
| 2 RMSE | 8.13 | 5.47 | 4.27 | 7.42 |
| 95th percentile | 8.20 | 4.87 | 3.57 | 7.07 |
Publisher’s Note: MDPI stays neutral with regard to jurisdictional claims in published maps and institutional affiliations. |
© 2021 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Frau, L.; Susto, G.A.; Barbariol, T.; Feltresi, E. Uncertainty Estimation for Machine Learning Models in Multiphase Flow Applications. Informatics 2021, 8, 58. https://doi.org/10.3390/informatics8030058
Frau L, Susto GA, Barbariol T, Feltresi E. Uncertainty Estimation for Machine Learning Models in Multiphase Flow Applications. Informatics. 2021; 8(3):58. https://doi.org/10.3390/informatics8030058
Chicago/Turabian StyleFrau, Luca, Gian Antonio Susto, Tommaso Barbariol, and Enrico Feltresi. 2021. "Uncertainty Estimation for Machine Learning Models in Multiphase Flow Applications" Informatics 8, no. 3: 58. https://doi.org/10.3390/informatics8030058
APA StyleFrau, L., Susto, G. A., Barbariol, T., & Feltresi, E. (2021). Uncertainty Estimation for Machine Learning Models in Multiphase Flow Applications. Informatics, 8(3), 58. https://doi.org/10.3390/informatics8030058