
Modelling Service Quality of Internet Service Providers during COVID-19: The Customer Perspective Based on Twitter Dataset

 , , and
, , and
Abstract
:1. Introduction
- Extracting customer perception about the service quality of ISPs by adopting a computational intelligence technique—namely Sentiment Analysis. ISPs are paid very limited attention to among researcher compared with other types of enterprise.
- Providing a framework for modelling the service quality of ISPs based on the sentiment score extracted from the Twitter dataset.
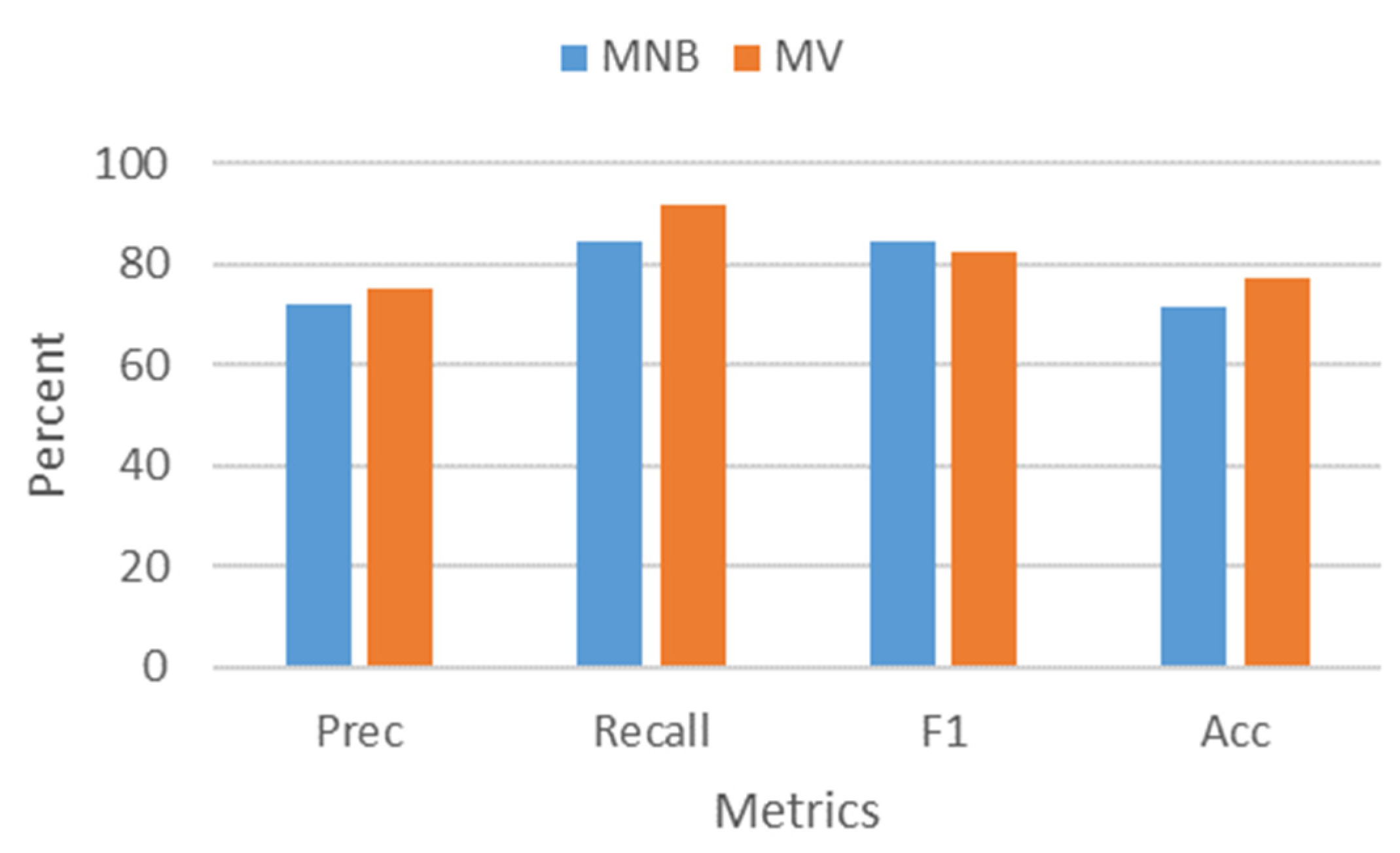
- Evaluating the performance of the sentiment analysis task of the proposed framework using several performance metrics.
2. Related Work
- (1)
- This study aimed to provide a framework for determining the service quality of ISPs by using an extensive dataset from social media, particularly Twitter. Compared with the common pencil-based survey that is time-consuming, costly and labour-intensive, this approach seems to be a promising alternative for revealing service quality;
- (2)
- Studies that explore service quality in Indonesia, especially the service quality of ISPs, have to date been extremely limited. To the best of our knowledge, this is the first study to model the service quality of Indonesian ISPs.
3. Materials and Methods
4. Results and Discussion
5. Conclusions
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Data Availability Statement
Acknowledgments
Conflicts of Interest
References
- Quach, T.N.; Jebarajakirthy, C.; Thaichon, P. The effects of service quality on internet service provider customers’ behaviour: A mixed methods study. Asia Pac. J. Mark. Logist. 2016, 28, 435–463. [Google Scholar] [CrossRef]
- Alamsyah, A.; Bernatapi, E.A. Evolving Customer Experience Management in Internet Service Provider Company using Text Analytics. In Proceedings of the 2019 International Conference on ICT for Smart Society (ICISS), Bandung, Indonesia, 19–20 November 2019. [Google Scholar]
- Berry, L.L.; Parasuraman, A.; Zeithaml, V.A. SERVQUAL: A multiple-item scale for measuring consumer perceptions of service quality. J. Retail. 1988, 64, 12–40. [Google Scholar]
- Abbas, J. HEISQUAL: A modern approach to measure service quality in higher education institutions. Stud. Educ. Eval. 2020, 67, 100933. [Google Scholar] [CrossRef]
- Thaichon, P.; Lobo, A.; Prentice, C.; Quach, T.N. The development of service quality dimensions for internet service providers: Retaining customers of different usage patterns. J. Retail. Consum. Serv. 2014, 21, 1047–1058. [Google Scholar] [CrossRef]
- Rintyarna, B.S. Mapping acceptance of Indonesian organic food consumption under COVID-19 pandemic using Sentiment Analysis of Twitter dataset. J. Theor. Appl. Inf. Technol. 2021, 99, 1009–1019. [Google Scholar]
- Rintyarna, B.S.; Sarno, R.; Fatichah, C. Enhancing the performance of sentiment analysis task on product reviews by handling both local and global context. Int. J. Inf. Decis. Sci. 2018, 11. [Google Scholar] [CrossRef]
- Rintyarna, B.S.; Sarno, R.; Fatichah, C. Evaluating the performance of sentence level features and domain sensitive features of product reviews on supervised sentiment analysis tasks. J. Big Data 2020, 6, 84. [Google Scholar] [CrossRef] [Green Version]
- Eslami, S.P.; Ghasemaghaei, M.; Hassanein, K. Which online reviews do consumers find most helpful? A multi-method investigation. Decis. Support Syst. 2018, 113, 32–42. [Google Scholar] [CrossRef]
- Wallach, H. Conclusion: Computational social science: Toward a collaborative future. Comput. Soc. Sci. Discov. Predict. 2016. [Google Scholar] [CrossRef]
- Al-Razgan, M.; Alrowily, A.; Al-Matham, R.N.; Alghamdi, K.M.; Shaabi, M.; Alssum, L. Using diffusion of innovation theory and sentiment analysis to analyze attitudes toward driving adoption by Saudi women. Technol. Soc. 2021, 65, 101558. [Google Scholar] [CrossRef]
- Rogers, E.M.; Singhal, A.; Quinlan, M.M. Diffusion of Innovations; Taylor and Francis: Abingdon-on-Thames, UK, 2019; ISBN 9781351358712. [Google Scholar]
- Jacomy, M.; Venturini, T.; Heymann, S.; Bastian, M. ForceAtlas2, a Continuous Graph Layout Algorithm for Handy Network Visualization Designed for the Gephi Software. PLoS ONE 2014, 9, e98679. [Google Scholar] [CrossRef] [PubMed]
- Hutto, C.J.; Gilbert, E. VADER: A Parsimonious Rule-based Model for Sentiment Analysis of Social Media Text. In Proceedings of the International AAAI Conference on Web and Social Media, Ann Arbor, MI, USA, 1–4 June 2014; pp. 216–225. [Google Scholar]
- Asani, E.; Vahdat-nejad, H.; Sadri, J. Machine Learning with Applications Restaurant recommender system based on sentiment analysis. Mach. Learn. Appl. 2021, 6, 100114. [Google Scholar]
- Baccianella, S.; Esuli, A.; Sebastiani, F. SentiwordNet 3.0: An Enhanced Lexical Resource for Sentiment Analysis and Opinion Mining. In Proceedings of the Ninth International Conference on Language Resources and Evaluation, Valletta, Malta, 17–23 May 2010; pp. 2200–2204. [Google Scholar]
- Rintyarna, B.S.; Sarno, R.; Fatichah, C. Semantic Features for Optimizing Supervised Approach of Sentiment Analysis on Product Reviews. MDPI Computers 2019, 8, 55. [Google Scholar] [CrossRef] [Green Version]
- Sakyi, D. A comparative analysis of service quality among ECOWAS seaports. Transp. Res. Interdiscip. Perspect. 2020, 6, 100152. [Google Scholar] [CrossRef]
- Erdoǧmu, N.; Esen, M. An investigation of the effects of technology readiness on technology acceptance in e-HRM. Procedia-Soc. Behav. Sci. 2011, 24, 487–495. [Google Scholar] [CrossRef] [Green Version]
- Shah, F.T.; Syed, Z.; Imam, A.; Raza, A. The impact of airline service quality on passengers’ behavioral intentions using passenger satisfaction as a mediator. J. Air Transp. Manag. 2020, 85, 101815. [Google Scholar] [CrossRef]
- Chen, T.; Xu, R.; He, Y.; Wang, X. Improving sentiment analysis via sentence type classification using BiLSTM-CRF and CNN. Expert Syst. Appl. 2017, 72, 221–230. [Google Scholar] [CrossRef] [Green Version]
- Jaafar, M.; Abdul Aziz, A.R.; Ramayah, T.; Saad, B. Integrating information technology in the construction industry: Technology readiness assessment of Malaysian contractors. Int. J. Proj. Manag. 2007, 25, 115–120. [Google Scholar] [CrossRef]
- Tavakol, M.; Dennick, R. Making sense of Cronbach’s alpha. Int. J. Med. Educ. 2011, 2, 53–55. [Google Scholar] [CrossRef] [PubMed]
- Sidorov, G.; Gelbukh, A.; Gómez-Adorno, H.; Pinto, D. Soft similarity and soft cosine measure: Similarity of features in vector space model. Comput. Sist. 2014, 18, 491–504. [Google Scholar] [CrossRef]
- Lewis, D.D. Naive (Bayes) at forty: The independence assumption in information retrieval. In Proceedings of the European Conference on Machine Learning, Chemnitz, Germany, 21–23 April 1998; p. 16. [Google Scholar]







{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Metrics | Keywords | Description |
|---|---|---|
| network quality | kualitas jaringan, jaringan, network, sinyal, lambat, lemot |
|
| customer service | layanan pelanggan, layanan, CS, service, servis |
|
| information quality | kualitas informasi, informasi, up to date, lengkap, informatif |
|
| privacy and security | privasi, keamanan, kuota, paket data, paket, data, gagal, isi ulang, cepat habis |
|
| + | ||||
| − | ||||
| N | ||||
| + | ||||
| + | ||||
| … | ||||
| N |
| ISPs | Grabbed Twit |
|---|---|
| By.U | 5446 |
| MPWR | 4198 |
| ISPs | Pos | Neg | Neu |
|---|---|---|---|
| By.U | 3451 | 756 | 1232 |
| MPWR | 2315 | 321 | 1562 |
| Metrics | Initial Keywords | Expanded Keywords |
|---|---|---|
| network quality | 6 | 25 |
| customer service | 5 | 8 |
| information quality | 5 | 28 |
| privacy and security | 10 | 24 |
| Metrics | Initial Keywords | Translation Result | English Synonym with WordNet | Expanded Keywords |
|---|---|---|---|---|
| network quality | kualitas jaringan, jaringan, network, sinyal, lambat, lemot | network quality, network, network, signal, slow, slow | web, net, network, mesh, meshing, meshwork, signalling, sign, dense, dim, dull, dumb, obtuse, boring, deadening, dull, ho-hum, irksome, tedious, tiresome, wearisome | kualitas jaringan, jaringan, network, sinyal, lambat, lemot, bersih, bertautan, meshing, meshwork, pemberian isyarat, tanda, padat, redup, membosankan, bodoh, tumpul, membosankan, mematikan, membosankan, ho-hum, menjengkelkan, membosankan, melelahkan, melelahkan |
| customer service | layanan pelanggan, layanan, CS, service, servis | customer service, service, CS, service, servicing | overhaul, inspection and repair | layanan pelanggan, layanan, CS, service, servis, overhaul, inspeksi dan perbaikan |
| information quality | kualitas informasi, informasi, up to date, lengkap, informatif | quality of information, information, up to date, complete, informative | data, entropy, cutting-edge, consummate, accomplished, double-dyed, everlasting, gross, perfect, pure, sodding, stark, staring, thorough, thoroughgoing, utter, unadulterated, concluded, ended, over, all over, terminated | kualitas informasi, informasi, up to date, lengkap, informative, data, entropi, mutakhir, sempurna, tercapai, dicelup ganda, abadi, kotor, sempurna, murni, basah kuyup, mencolok, menatap, menyeluruh, menyeluruh, mengucapkan, murni, menyimpulkan, berakhir, lebih, seluruh, diakhiri |
| privacy and security | privasi, keamanan, kuota, paket data, paket, data, gagal, isi ulang, cepat habis | privacy, security, quota, data plan, packet, data, fail, recharge, run out fast | privateness, secrecy, concealment, certificate, limitation, information, go bad, give way, die, give out, conk out, go, break, break down, reload | privasi, keamanan, kuota, paket data, paket, data, gagal, isi ulang, cepat habis, privasi, kerahasiaan, penyembunyian, sertifikat, pembatasan, informasi, rusak, memberi jalan, mati, memberikan, conk out, pergi, istirahat, mogok, reload |
Publisher’s Note: MDPI stays neutral with regard to jurisdictional claims in published maps and institutional affiliations. |
© 2022 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Rintyarna, B.S.; Kuswanto, H.; Sarno, R.; Rachmaningsih, E.K.; Rachman, F.H.; Suharso, W.; Cahyanto, T.A. Modelling Service Quality of Internet Service Providers during COVID-19: The Customer Perspective Based on Twitter Dataset. Informatics 2022, 9, 11. https://doi.org/10.3390/informatics9010011
Rintyarna BS, Kuswanto H, Sarno R, Rachmaningsih EK, Rachman FH, Suharso W, Cahyanto TA. Modelling Service Quality of Internet Service Providers during COVID-19: The Customer Perspective Based on Twitter Dataset. Informatics. 2022; 9(1):11. https://doi.org/10.3390/informatics9010011
Chicago/Turabian StyleRintyarna, Bagus Setya, Heri Kuswanto, Riyanarto Sarno, Emy Kholifah Rachmaningsih, Fika Hastarita Rachman, Wiwik Suharso, and Triawan Adi Cahyanto. 2022. "Modelling Service Quality of Internet Service Providers during COVID-19: The Customer Perspective Based on Twitter Dataset" Informatics 9, no. 1: 11. https://doi.org/10.3390/informatics9010011