
Development of a Simulator for Prototyping Reinforcement Learning-Based Autonomous Cars



Abstract
:1. Introduction
1.1. Research Questions and Hypothesis
- Research Question (RQ)1: Will creating a reset system for the vehicle that stops the car after it is stuck improve the learning speed?
- Research Question (RQ)2: Will creating a reward for each road tile be sufficient to inform the vehicle to stay on the road?
- Research Question (RQ)3: Will a penalty for driving off the road decrease the number of time steps required for learning to stay on the road?
1.2. Intervention
2. Background
2.1. Reinforcement Learning-Based Autonomous Vehicles
2.2. Simulators
3. Method
- Task 1 is to drive straight, leading to a hill.
- Task 2 requires the vehicle to drive straight and then drive up a short twisting hill and turn the corner.
- Task 3 is to clear a steep right turn up a hill, then turn left when on top of the hill.
3.1. Sensors
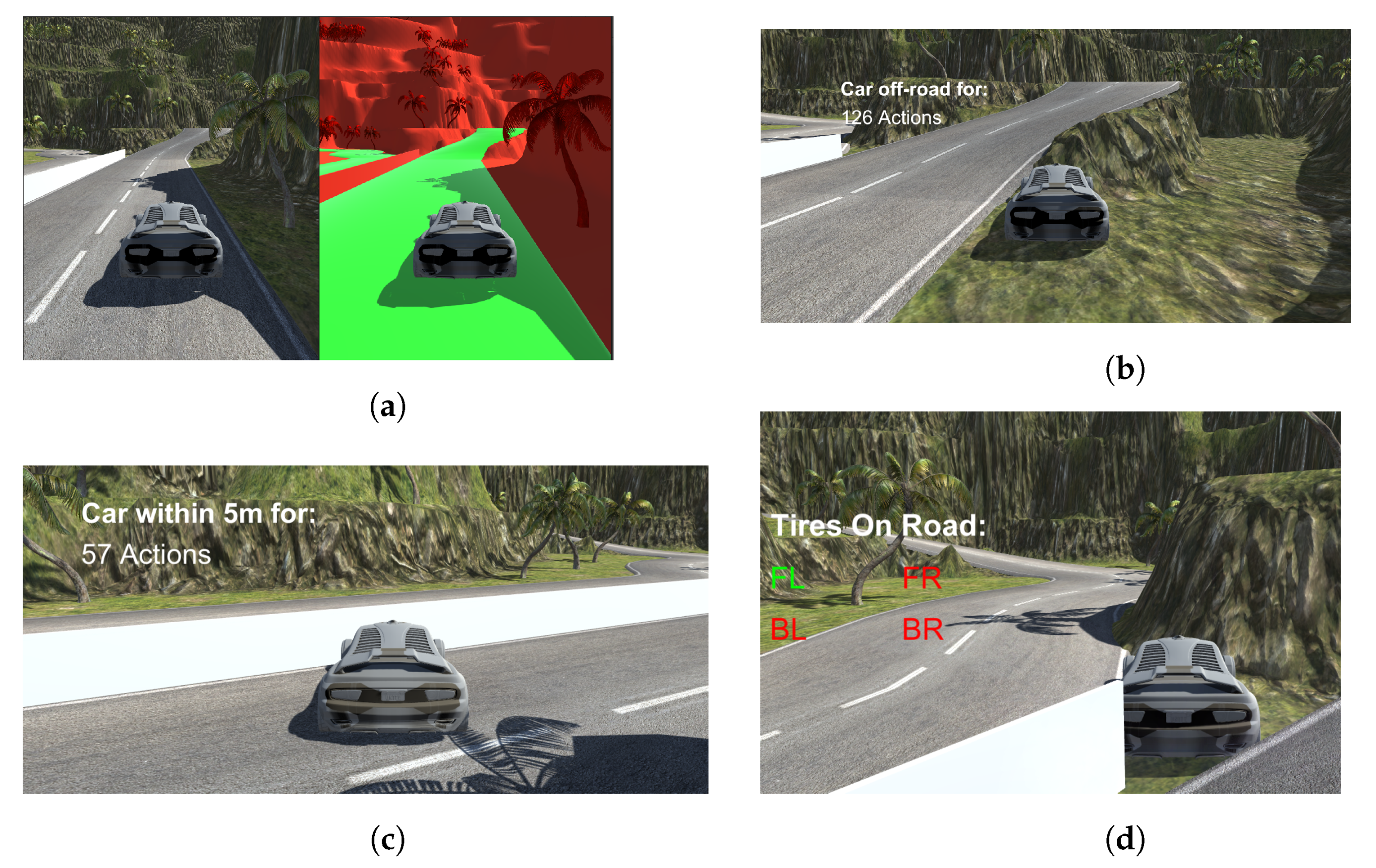
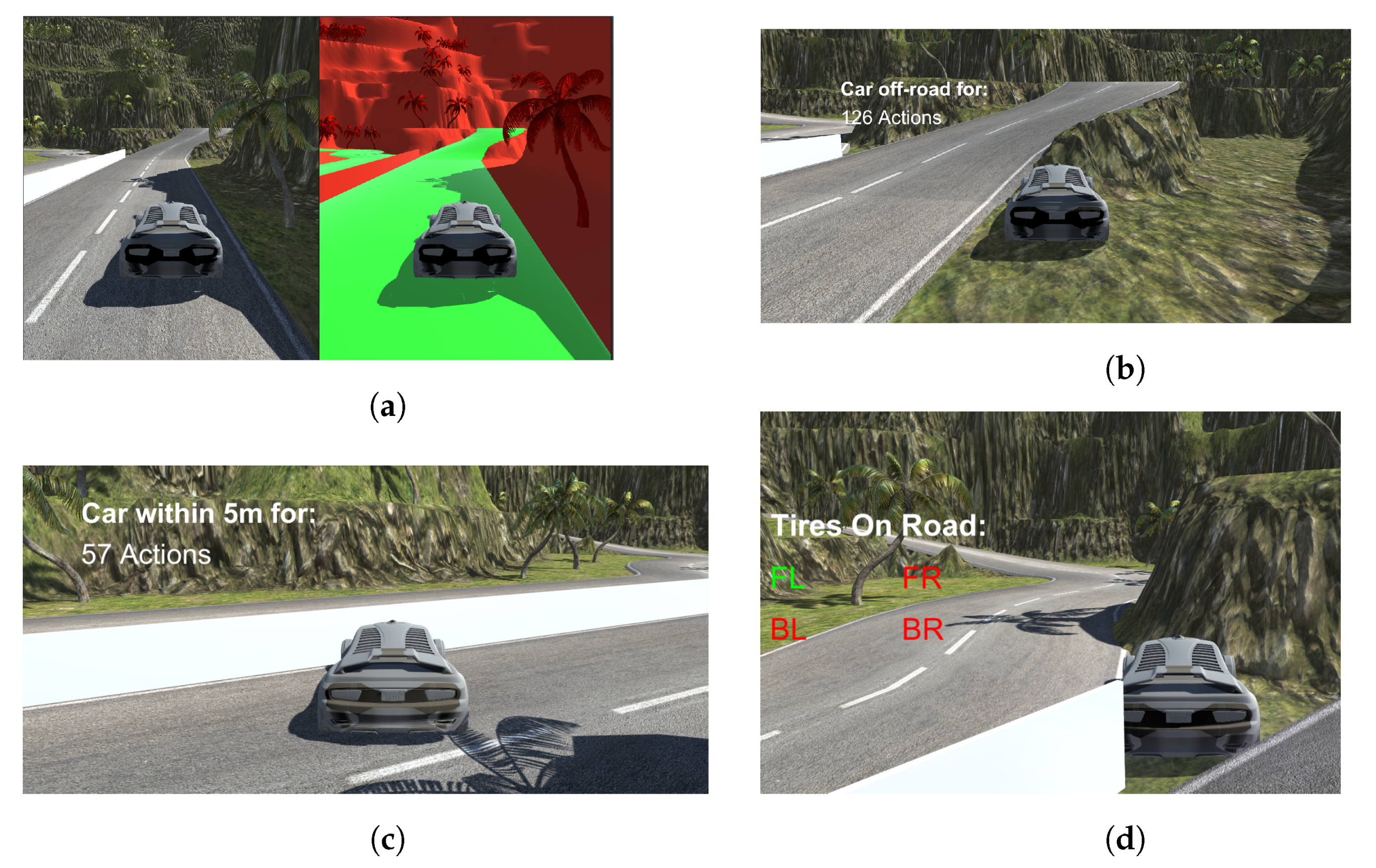
- Sensor 1 detects when the car drives off the road, giving a penalty for going off the road. It was developed by the authors and was validated by manually driving in the environment, checking when any of the tires were off the road, and confirming that the sensor was triggered.
- Sensor 2 is the location sensor, detecting if the car is in the exact location for a more extended period. The location sensor is similar to a GPS, in that it gives the position relative to the world’s origin. This sensor is created by Unity and is part of the game engine itself.
- Sensor 3 is a camera sensor made to capture RGB images of the environment the vehicle is driving in. This sensor comes with Unity, giving an idealized view. The version of the sensor included does not include ray tracing or any such feature, instead relying on an overhead light, with more simplified lighting calculations.
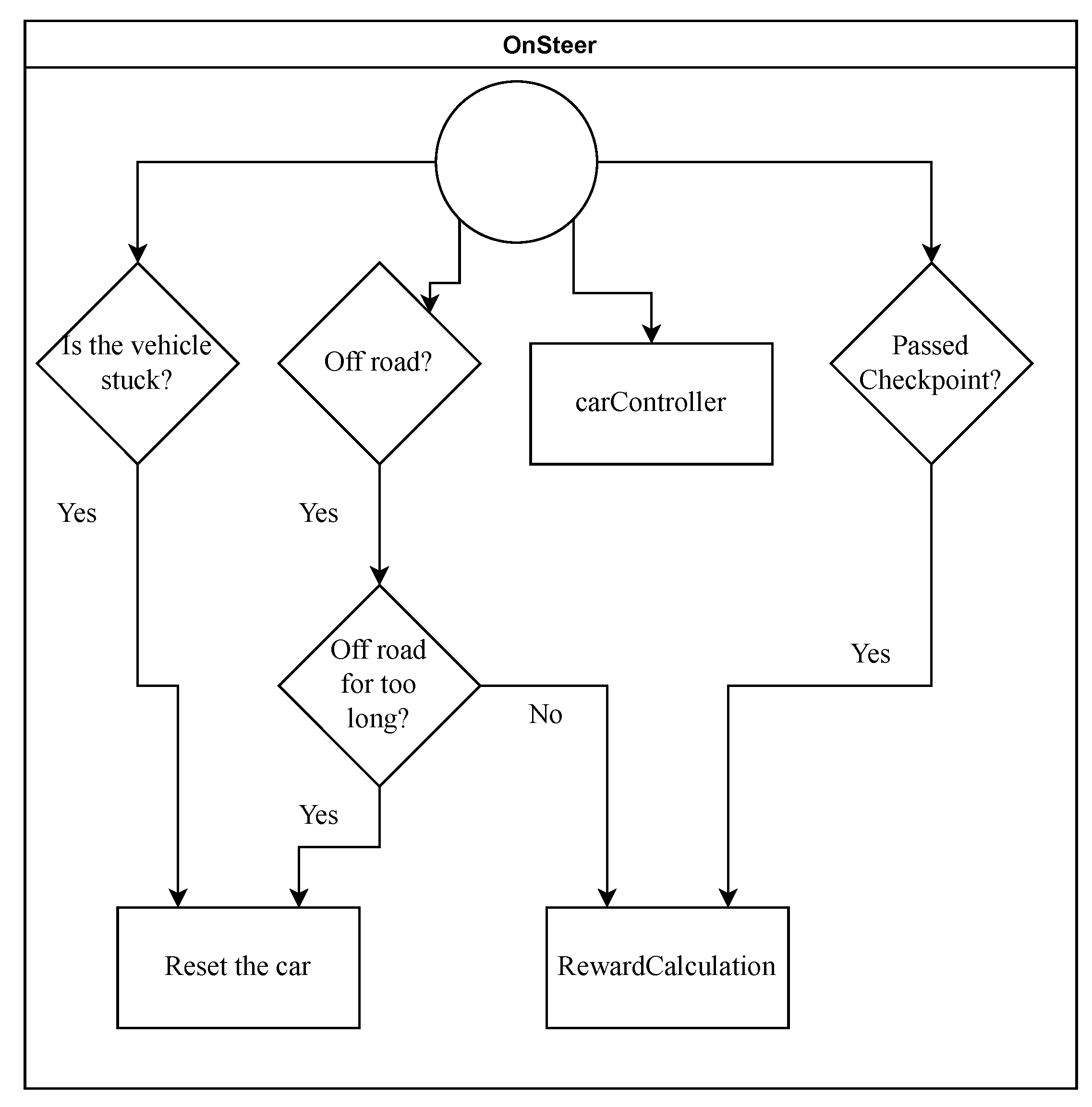
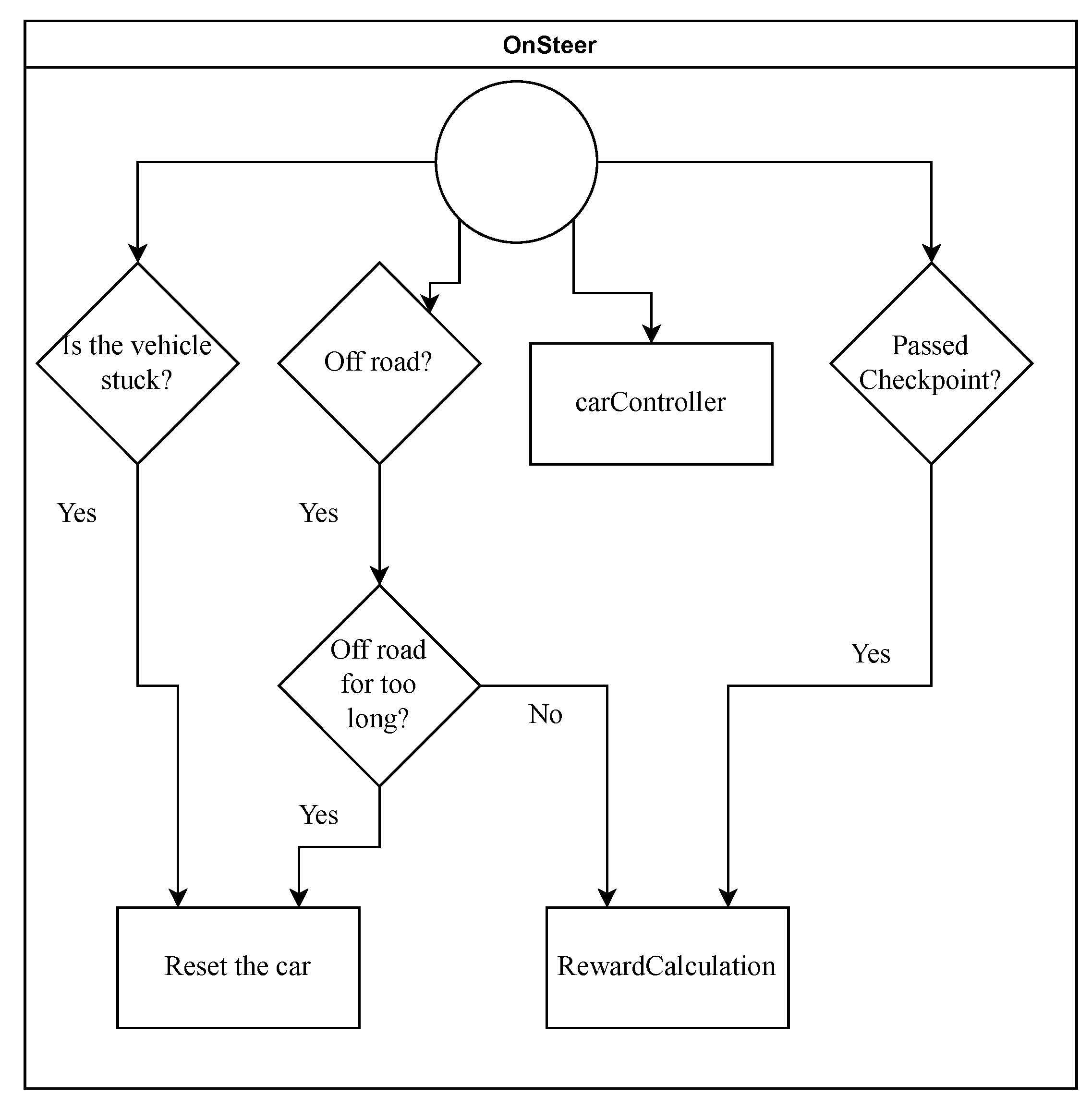
- Sensor 4 checks if the vehicle is stuck and resets it. The sensor is also an addition from the authors, and uses a ray cast from the tires, aims it downwards, and checks if there is a road tile below it. This is carried out by checking the render mask of the objects below it, and if any of the tires are not on the road, the vehicle is reset. Combining this with a small script developed by the authors, we check if the vehicle has been stuck, has been by the divider, or is off-road for 300 actions. If the vehicle has carried out any of these for 300 actions, it is reset to a checkpoint and gives feedback back to the vehicle, telling it that the episode finished.
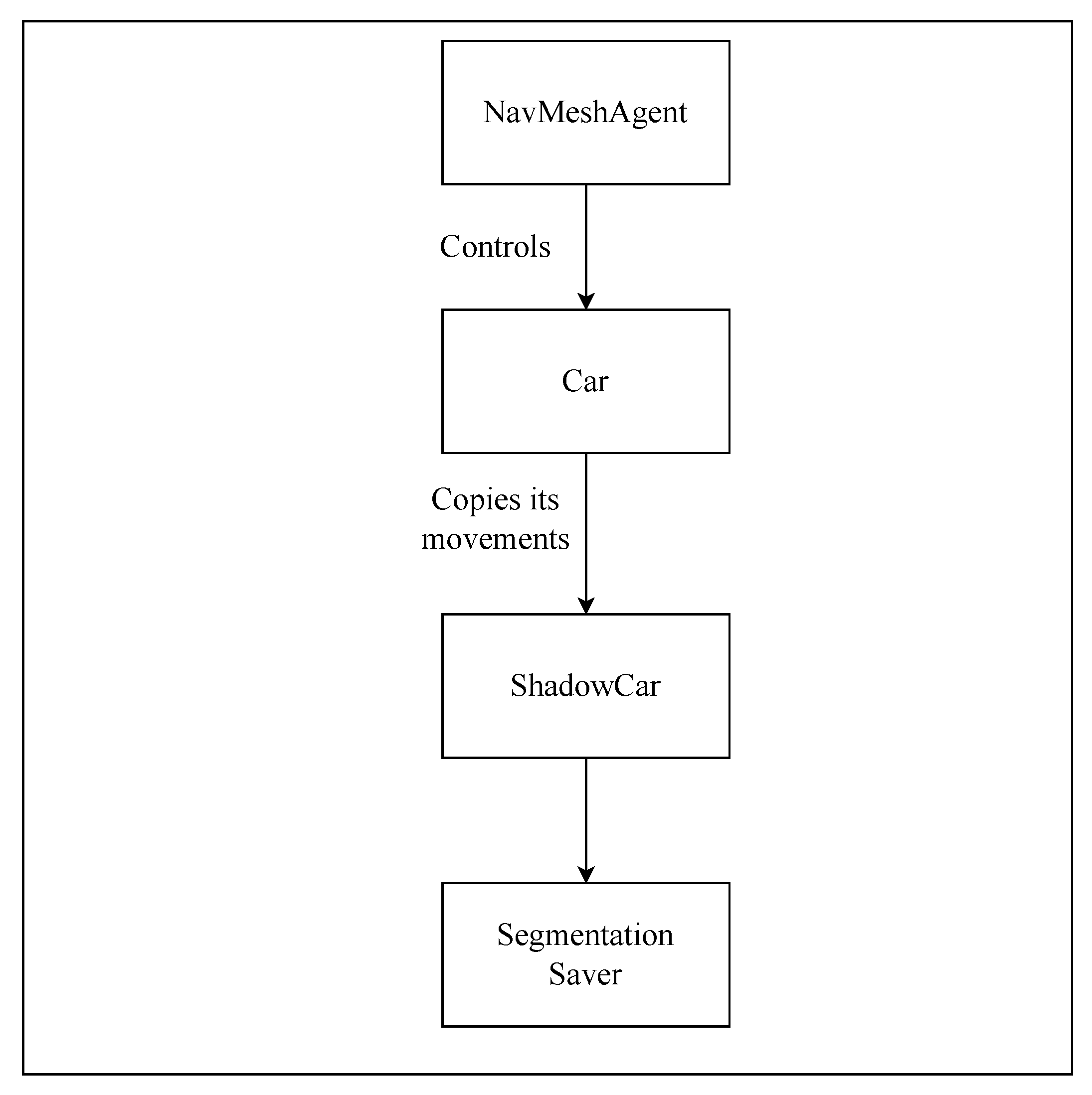
- Sensor 5 is a segmented camera, which is also an idealized sensor. We created it by making changes to shaders in a duplicated world, and these shaders show the respective color of an object, such as when the road would be a different color than the trees. The passive data collector for the segmented camera is shown in Figure 2. To obtain the image in the same location in both environments, we shadow the vehicle driven by the AI algorithm. This vehicle can also be driven using a navigation mesh, which allows for the passive collection of segmented images. An RGB and segmented image can be found in Figure 3a.
3.2. RL Feedback
3.3. RL Algorithm
3.4. Modifications
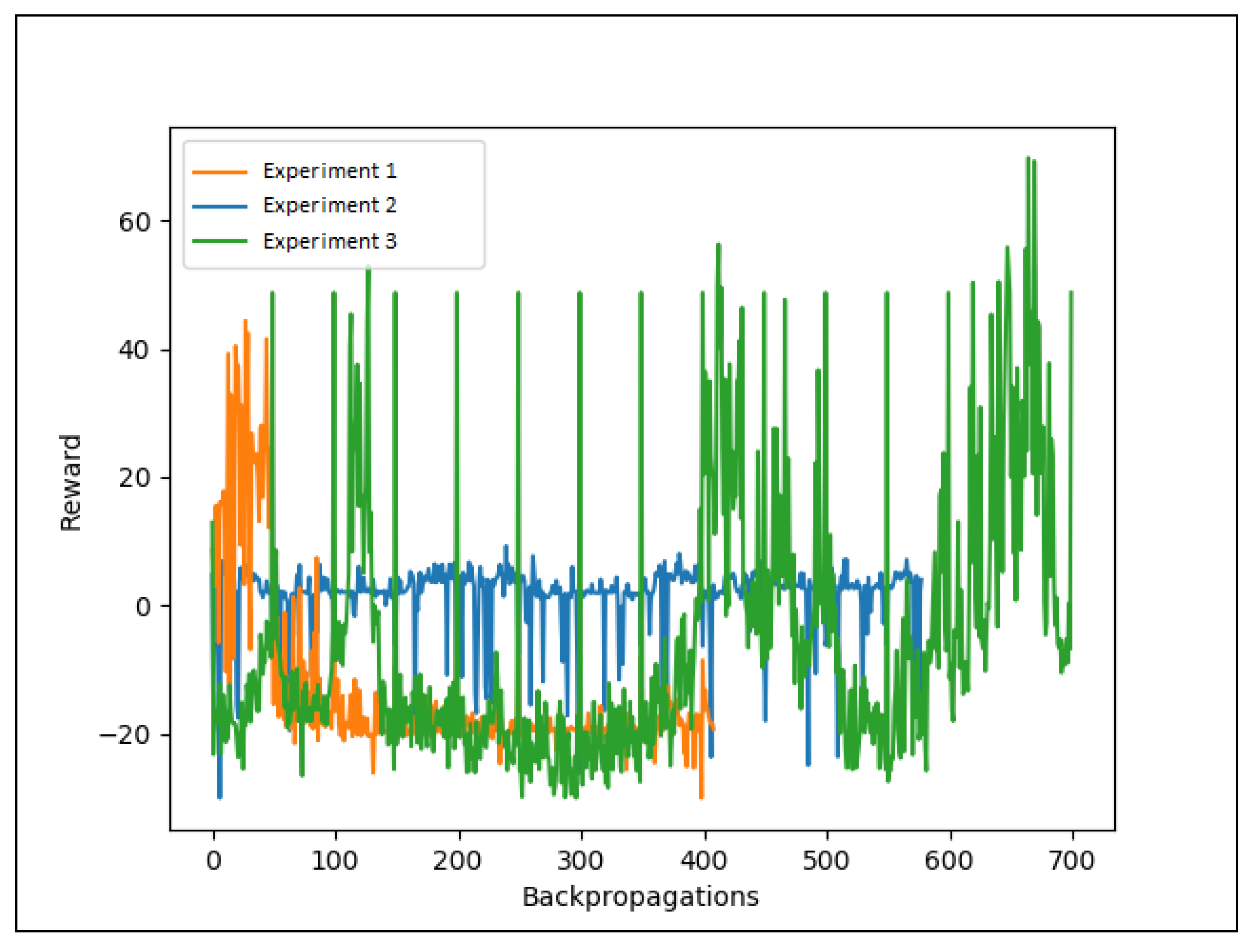
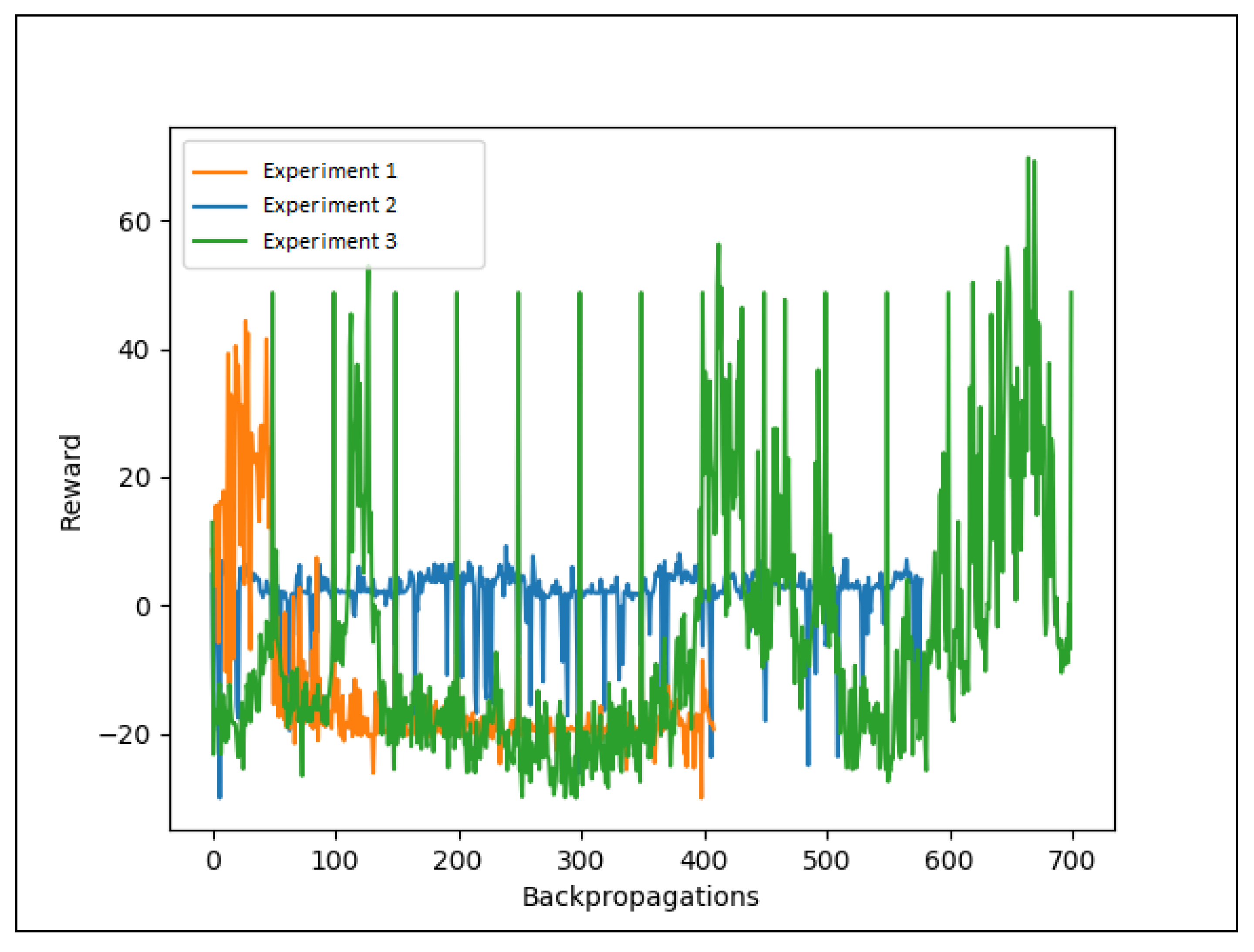
4. Results
Research Questions
5. Discussion and Conclusions
Additional Insight and Future Work
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Data Availability Statement
Acknowledgments
Conflicts of Interest
References
- Dosovitskiy, A.; Ros, G.; Codevilla, F.; López, A.; Koltun, V. CARLA: An Open Urban Driving Simulator. In Proceedings of the 1st Annual Conference on Robot Learning, Mountain View, CA, USA, 13–15 November 2017; pp. 1–16. [Google Scholar]
- Balaji, B.; Mallya, S.; Genc, S.; Gupta, S.; Dirac, L.; Khare, V.; Roy, G.; Sun, T.; Tao, Y.; Townsend, B.; et al. DeepRacer: Educational Autonomous Racing Platform for Experimentation with Sim2Real Reinforcement Learning. IEEE Int. Conf. Robot. Autom. 2020, 2746–2754. [Google Scholar]
- Naumann, M.; Poggenhans, F.; Lauer, M.; Stiller, C. CoInCar-Sim: An Open-Source Simulation Framework for Cooperatively Interacting Automobiles. IEEE Intell. Veh. Symp. Proc. 2018, 2018, 1879–1884. [Google Scholar] [CrossRef]
- Quiter, C.; Rehn, A. Deepdrive/Deepdrive: Deepdrive is a Simulator That Allows Anyone with a PC to Push the State-of-the-Art in Self-Driving. 2021. Available online: https://github.com/deepdrive/deepdrive (accessed on 1 February 2022).
- Vector Informatik GmbH. DYNA4|Virtual Test Driving|Vector. 2021. Available online: https://www.vector.com/int/en/products/products-a-z/software/dyna4/ (accessed on 1 February 2022).
- Li, Q.; Peng, Z.; Zhang, Q.; Liu, C.; Zhou, B. Improving the Generalization of End-to-End Driving through Procedural Generation. arXiv 2020, arXiv:2012.13681. [Google Scholar]
- Cai, P.; Lee, Y.; Luo, Y.; Hsu, D. SUMMIT: A Simulator for Urban Driving in Massive Mixed Traffic. In Proceedings of the IEEE International Conference on Robotics and Automation, Paris, France, 31 May–31 August 2020; pp. 4023–4029. [Google Scholar]
- Berner, C.; Brockman, G.; Chan, B.; Cheung, V.; Dȩbiak, P.; Dennison, C.; Farhi, D.; Fischer, Q.; Hashme, S.; Hesse, C.; et al. Dota 2 with Large Scale Deep Reinforcement Learning. arXiv 2019, arXiv:1912.06680. [Google Scholar]
- Mnih, V.; Kavukcuoglu, K.; Silver, D.; Rusu, A.A.; Veness, J.; Bellemare, M.G.; Graves, A.; Riedmiller, M.; Fidjeland, A.K.; Ostrovski, G.; et al. Human-level control through deep reinforcement learning. Nature 2015, 518, 529–533. [Google Scholar] [CrossRef] [PubMed]
- Vinyals, O.; Babuschkin, I.; Czarnecki, W.M.; Mathieu, M.; Dudzik, A.; Chung, J.; Choi, D.H.; Powell, R.; Ewalds, T.; Georgiev, P.; et al. Grandmaster level in StarCraft II using multi-agent reinforcement learning. Nature 2019, 575, 350–354. [Google Scholar] [CrossRef] [PubMed]
- Silver, D.; Huang, A.; Maddison, C.J.; Guez, A.; Sifre, L.; van den Driessche, G.; Schrittwieser, J.; Antonoglou, I.; Panneershelvam, V.; Lanctot, M.; et al. Mastering the game of Go with deep neural networks and tree search. Nature 2016, 529, 484–489. [Google Scholar] [CrossRef] [PubMed]
- Silver, D.; Schrittwieser, J.; Simonyan, K.; Antonoglou, I.; Huang, A.; Guez, A.; Hubert, T.; Baker, L.; Lai, M.; Bolton, A.; et al. Mastering the game of Go without human knowledge. Nature 2017, 550, 354–359. [Google Scholar] [CrossRef] [PubMed]
- Sharifzadeh, S.; Chiotellis, I.; Triebel, R.; Cremers, D. Learning to Drive using Inverse Reinforcement Learning and Deep Q-Networks. NeurIPS Workshop on Deep Learning for Action and Interaction. arXiv 2016, arXiv:1612.03653. [Google Scholar]
- Liang, X.; Wang, T.; Yang, L.; Xing, E. CIRL: Controllable Imitative Reinforcement Learning for Vision-based Self-driving. In Proceedings of the European Conference on Computer Vision (ECCV), Munich, Germany, 8–14 September 2018. [Google Scholar]
- Kendall, A.; Hawke, J.; Janz, D.; Mazur, P.; Reda, D.; Allen, J.M.; Lam, V.D.; Bewley, A.; Shah, A. Learning to drive in a day. In Proceedings of the IEEE International Conference on Robotics and Automation, Montreal, QC, Canada, 20–24 May 2019; pp. 8248–8254. [Google Scholar] [CrossRef]
- Duan, J.; Li, S.E.; Guan, Y.; Sun, Q.; Cheng, B. Hierarchical Reinforcement Learning for Self-Driving Decision-Making without Reliance on Labeled Driving Data. IET Intell. Transp. Syst. 2020, 14, 297–305. [Google Scholar] [CrossRef] [Green Version]
- Kiran, B.R.; Sobh, I.; Talpaert, V.; Mannion, P.; Sallab, A.A.A.; Yogamani, S.; Pérez, P. Deep Reinforcement Learning for Autonomous Driving: A Survey. IEEE Trans. Intell. Transp. Syst. 2020, 1–18. [Google Scholar] [CrossRef]
- Bailey, T.; Durrant-Whyte, H. Simultaneous localization and mapping (SLAM): Part II. IEEE Robot. Autom. Mag. 2006, 13, 108–117. [Google Scholar] [CrossRef] [Green Version]
- rFpro. Driving Simulation for Autonomous Driving, ADAS, Vehicle Dynamics and Motorsport. 2021. Available online: https://www.rfpro.com/ (accessed on 1 February 2022).
- CARLA Community. CARLA Simulator. 2017. Available online: https://carla.readthedocs.io/en/latest/ (accessed on 1 February 2022).
- CARLA Community. Sensors Reference-CARLA Simulator. 2017. Available online: https://carla.readthedocs.io/en/latest/core_sensors/ (accessed on 1 February 2022).
- CARLA Community. 2nd-Actors and Blueprints-CARLA Simulator. 2017. Available online: https://carla.readthedocs.io/en/latest/core_actors/ (accessed on 1 February 2022).
- The MathWorks, I. Automated Driving Toolbox-MATLAB. 2021. Available online: https://se.mathworks.com/products/automated-driving.html (accessed on 1 February 2022).
- Li, Q.; Peng, Z.; Zhang, Q.; Liu, C.; Zhou, B. Vehicle Configuration—PGDrive 0.1.1 Documentation. 2020. Available online: https://github.com/decisionforce/pgdrive (accessed on 1 February 2022).


{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Experiments | RTR | ORP | CBIE |
|---|---|---|---|
| Experiment 1 | No | No | Yes |
| Experiment 2 | Yes | No | No |
| Experiment 3 | Yes | Yes | No |
Publisher’s Note: MDPI stays neutral with regard to jurisdictional claims in published maps and institutional affiliations. |
© 2022 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Holen, M.; Knausgård, K.M.; Goodwin, M. Development of a Simulator for Prototyping Reinforcement Learning-Based Autonomous Cars. Informatics 2022, 9, 33. https://doi.org/10.3390/informatics9020033
Holen M, Knausgård KM, Goodwin M. Development of a Simulator for Prototyping Reinforcement Learning-Based Autonomous Cars. Informatics. 2022; 9(2):33. https://doi.org/10.3390/informatics9020033
Chicago/Turabian StyleHolen, Martin, Kristian Muri Knausgård, and Morten Goodwin. 2022. "Development of a Simulator for Prototyping Reinforcement Learning-Based Autonomous Cars" Informatics 9, no. 2: 33. https://doi.org/10.3390/informatics9020033
APA StyleHolen, M., Knausgård, K. M., & Goodwin, M. (2022). Development of a Simulator for Prototyping Reinforcement Learning-Based Autonomous Cars. Informatics, 9(2), 33. https://doi.org/10.3390/informatics9020033