
Association Measure and Compact Prediction for Chemical Process Data from an Information-Theoretic Perspective

Abstract
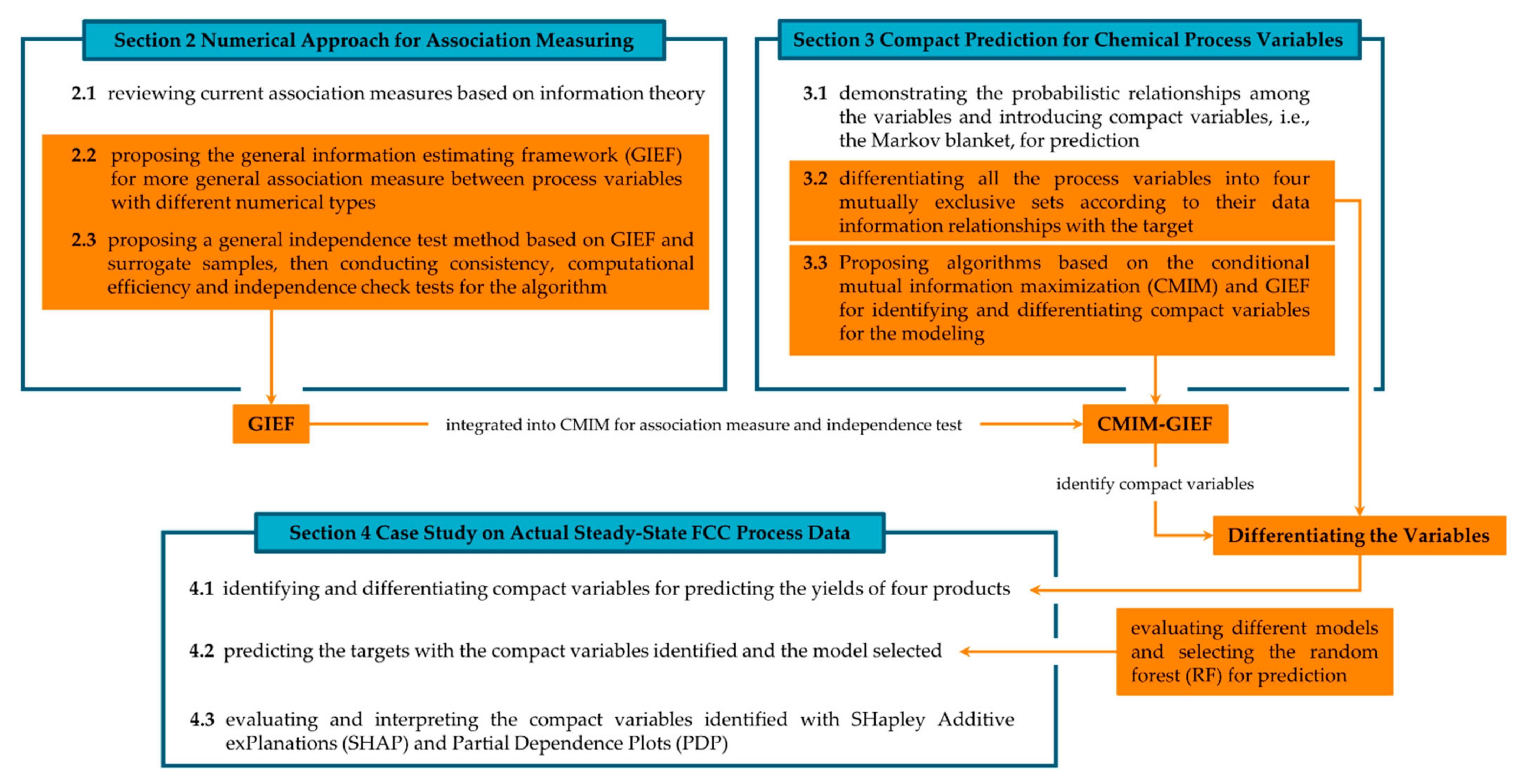
:1. Introduction
2. Data Predictability and Numerical Approach for Information Estimation
2.1. Numerical Approaches for Estimating Marginal Entropy and MI
2.2. GIEF: A General Framework for Data Information Estimation
2.3. Performance Tests for GIEF and Other Association Measuring Methods
2.3.1. Consistency and Time Costs
2.3.2. Test of Independence in GIEF
3. Compact Prediction for Chemical Process Data Based on Association Measure, Independence Test and Probabilistic Graph
3.1. Compact Variables Set and the Markov Blanket
3.2. Variable Differentiation from the Information-Theoretic Perspective
- Strongly associated variables : if a variable node is directly connected to on and cannot be blocked by any other node sets , then is strongly associated with , that is, for , ;
- Interactively associated variables : if a node is not directly connected to on but conditionally associated with given nodes set , then is interactively associated with , that is, and so that ;
- Redundantly associated variables : if a node is associated with but conditionally independent of given some nodes , then is called a redundant associated variable for , that is, and so that ;
- Irrelevant variables : if a node is neither associated nor conditionally associated with given any subset , then is called completely irrelevant to , that is, for , .
3.3. Algorithms for Identifying and Differentiating Compact Variables in Chemical Processes
4. Case Study on Actual Steady-State FCC Process Data
4.1. Identifying Compact Associated Variables for the FCC Product Yields
4.2. Prediction Based on the Compact Associated Variables Identified
4.3. Evaluating and Interpreting the Compact Associated Variables Identified
5. Conclusions
Supplementary Materials
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Data Availability Statement
Conflicts of Interest
Appendix A
Appendix B

Appendix C
References
- Harmon Ray, W.; Villa, C.M. Nonlinear Dynamics Found in Polymerization Processes—A Review. Chem. Eng. Sci. 2000, 55, 275–290. [Google Scholar] [CrossRef]
- Luo, L.; Zhang, N.; Xia, Z.; Qiu, T. Dynamics and Stability Analysis of Gas-Phase Bulk Polymerization of Propylene. Chem. Eng. Sci. 2016, 143, 12–22. [Google Scholar] [CrossRef]
- Afshar Ebrahimi, A.; Mousavi, H.; Bayesteh, H.; Towfighi, J. Nine-Lumped Kinetic Model for VGO Catalytic Cracking; Using Catalyst Deactivation. Fuel 2018, 231, 118–125. [Google Scholar] [CrossRef]
- Jia, Z.; Lin, Y.; Jiao, Z.; Ma, Y.; Wang, J. Detecting Causality in Multivariate Time Series via Non-Uniform Embedding. Entropy 2019, 21, 1233. [Google Scholar] [CrossRef] [Green Version]
- Arunthavanathan, R.; Khan, F.; Ahmed, S.; Imtiaz, S.; Rusli, R. Fault Detection and Diagnosis in Process System Using Artificial Intelligence-Based Cognitive Technique. Comput. Chem. Eng. 2020, 134, 106697. [Google Scholar] [CrossRef]
- Wu, H.; Zhao, J. Deep Convolutional Neural Network Model Based Chemical Process Fault Diagnosis. Comput. Chem. Eng. 2018, 115, 185–197. [Google Scholar] [CrossRef]
- Luo, L.; He, G.; Chen, C.; Ji, X.; Zhou, L.; Dai, Y.; Dang, Y. Adaptive Data Dimensionality Reduction for Chemical Process Modeling Based on the Information Criterion Related to Data Association and Redundancy. Ind. Eng. Chem. Res. 2022, 61, 1148–1166. [Google Scholar] [CrossRef]
- Chen, C.; Zhou, L.; Ji, X.; He, G.; Dai, Y.; Dang, Y. Adaptive Modeling Strategy Integrating Feature Selection and Random Forest for Fluid Catalytic Cracking Processes. Ind. Eng. Chem. Res. 2020, 59, 11265–11274. [Google Scholar] [CrossRef]
- Wu, D.; Zhao, J. Process Topology Convolutional Network Model for Chemical Process Fault Diagnosis. Process Saf. Environ. Prot. 2021, 150, 93–109. [Google Scholar] [CrossRef]
- Dong, Y.; Tian, W.; Zhang, X. Fault Diagnosis of Chemical Process Based on Multivariate PCC Optimization. In Proceedings of the 2017 36th Chinese Control Conference (CCC), Dalian, China, 26–28 July 2017; pp. 7370–7375. [Google Scholar]
- Jin, J.; Zhang, S.; Li, L.; Zou, T. A Novel System Decomposition Method Based on Pearson Correlation and Graph Theory. In Proceedings of the 2018 IEEE 7th Data Driven Control and Learning Systems Conference (DDCLS), Enshi, China, 25–27 May 2018; pp. 819–824. [Google Scholar]
- Yu, H.; Khan, F.; Garaniya, V. An Alternative Formulation of PCA for Process Monitoring Using Distance Correlation. Ind. Eng. Chem. Res. 2016, 55, 656–669. [Google Scholar] [CrossRef]
- Tian, W.; Ren, Y.; Dong, Y.; Wang, S.; Bu, L. Fault Monitoring Based on Mutual Information Feature Engineering Modeling in Chemical Process. Chin. J. Chem. Eng. 2019, 27, 2491–2497. [Google Scholar] [CrossRef]
- Fujiwara, K.; Kano, M. Efficient Input Variable Selection for Soft-Senor Design Based on Nearest Correlation Spectral Clustering and Group Lasso. ISA Trans. 2015, 58, 367–379. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Eghtesadi, Z.; McAuley, K.B. Mean-Squared-Error-Based Method for Parameter Ranking and Selection with Noninvertible Fisher Information Matrix. AIChE J. 2016, 62, 1112–1125. [Google Scholar] [CrossRef]
- Ge, Z.; Song, Z. Distributed PCA Model for Plant-Wide Process Monitoring. Ind. Eng. Chem. Res. 2013, 52, 1947–1957. [Google Scholar] [CrossRef]
- Joswiak, M.; Peng, Y.; Castillo, I.; Chiang, L.H. Dimensionality Reduction for Visualizing Industrial Chemical Process Data. Control. Eng. Pract. 2019, 93, 104189. [Google Scholar] [CrossRef]
- Ge, Z. Review on Data-Driven Modeling and Monitoring for Plant-Wide Industrial Processes. Chemom. Intell. Lab. Syst. 2017, 171, 16–25. [Google Scholar] [CrossRef]
- Lee, H.; Kim, C.; Lim, S.; Lee, J.M. Data-Driven Fault Diagnosis for Chemical Processes Using Transfer Entropy and Graphical Lasso. Comput. Chem. Eng. 2020, 142, 107064. [Google Scholar] [CrossRef]
- Kim, C.; Lee, H.; Lee, W.B. Process Fault Diagnosis via the Integrated Use of Graphical Lasso and Markov Random Fields Learning & Inference. Comput. Chem. Eng. 2019, 125, 460–475. [Google Scholar] [CrossRef]
- Bauer, M.; Cox, J.W.; Caveness, M.H.; Downs, J.J.; Thornhill, N.F. Finding the Direction of Disturbance Propagation in a Chemical Process Using Transfer Entropy. IEEE Trans. Contr. Syst. Technol. 2007, 15, 12–21. [Google Scholar] [CrossRef] [Green Version]
- Trunk, G.V. A Problem of Dimensionality: A Simple Example. IEEE Trans. Pattern Anal. Mach. Intell. 1979, PAMI-1, 306–307. [Google Scholar] [CrossRef]
- Koppen, M. The Curse of Dimensionality. In Proceedings of the 5th Online World Conference on Soft Computing in Industrial Applications, London, UK, 4–18 September 2000; pp. 4–8. [Google Scholar]
- Hughes, G. On the Mean Accuracy of Statistical Pattern Recognizers. IEEE Trans. Inform. Theory 1968, 14, 55–63. [Google Scholar] [CrossRef] [Green Version]
- Biyela, P.; Rawatlal, R. Development of an Optimal State Transition Graph for Trajectory Optimisation of Dynamic Systems by Application of Dijkstra’s Algorithm. Comput. Chem. Eng. 2019, 125, 569–586. [Google Scholar] [CrossRef]
- Gupta, U.; Heo, S.; Bhan, A.; Daoutidis, P. Time Scale Decomposition in Complex Reaction Systems: A Graph Theoretic Analysis. Comput. Chem. Eng. 2016, 95, 170–181. [Google Scholar] [CrossRef] [Green Version]
- Kramer, M.A.; Palowitch, B.L. A Rule-Based Approach to Fault Diagnosis Using the Signed Directed Graph. AIChE J. 1987, 33, 1067–1078. [Google Scholar] [CrossRef]
- Moharir, M.; Kang, L.; Daoutidis, P.; Almansoori, A. Graph Representation and Decomposition of ODE/Hyperbolic PDE Systems. Comput. Chem. Eng. 2017, 106, 532–543. [Google Scholar] [CrossRef]
- Zhang, S.; Li, H.; Qiu, T. An Innovative Graph Neural Network Model for Detailed Effluent Prediction in Steam Cracking. Ind. Eng. Chem. Res. 2021, 60, 18432–18442. [Google Scholar] [CrossRef]
- Pellet, J.-P.; Elisseeff, A. Using Markov Blankets for Causal Structure Learning. J. Mach. Learn. Res. 2008, 9, 48. [Google Scholar]
- Ling, Z.; Yu, K.; Wang, H.; Li, L.; Wu, X. Using Feature Selection for Local Causal Structure Learning. IEEE Trans. Emerg. Top. Comput. Intell. 2021, 5, 530–540. [Google Scholar] [CrossRef]
- Gao, T.; Wei, D. Parallel Bayesian Network Structure Learning. In Proceedings of the 35th International Conference on Machine Learning, Stockholm, Sweden, 10–15 July 2018; 2018; pp. 1685–1694. [Google Scholar]
- Wang, X.R.; Lizier, J.T.; Nowotny, T.; Berna, A.Z.; Prokopenko, M.; Trowell, S.C. Feature Selection for Chemical Sensor Arrays Using Mutual Information. PLoS ONE 2014, 9, e89840. [Google Scholar] [CrossRef] [Green Version]
- Duso, L.; Zechner, C. Path Mutual Information for a Class of Biochemical Reaction Networks. In Proceedings of the 2019 IEEE 58th Conference on Decision and Control (CDC), Nice, France, 11–13 December 2019; pp. 6610–6615. [Google Scholar]
- Cote-Ballesteros, J.E.; Grisales Palacios, V.H.; Rodriguez-Castellanos, J.E. A Hybrid Approach Variable Selection Algorithm Based on Mutual Information for Data-Driven Industrial Soft-Sensor Applications. Cienc. Ing. Neogranadina 2022, 32, 59–70. [Google Scholar] [CrossRef]
- Li, L.; Dai, Y. An adaptive soft sensor deterioration evaluation and model updating method for time-varying chemical processes. Chem. Ind. Chem. Eng. Q. 2020, 26, 135–149. [Google Scholar] [CrossRef]
- Severino, A.G.V.; de Lima, J.M.M.; de Araújo, F.M.U. Industrial Soft Sensor Optimized by Improved PSO: A Deep Representation-Learning Approach. Sensors 2022, 22, 6887. [Google Scholar] [CrossRef] [PubMed]
- He, Y.; Zhou, L.; Ge, Z.; Song, Z. Dynamic Mutual Information Similarity Based Transient Process Identification and Fault Detection. Can. J. Chem. Eng. 2018, 96, 1541–1558. [Google Scholar] [CrossRef]
- Ji, C.; Ma, F.; Wang, J.; Wang, J.; Sun, W. Real-Time Industrial Process Fault Diagnosis Based on Time Delayed Mutual Information Analysis. Processes 2021, 9, 1027. [Google Scholar] [CrossRef]
- Ji, C.; Ma, F.; Zhu, X.; Wang, J.; Sun, W. Fault Propagation Path Inference in a Complex Chemical Process Based on Time-Delayed Mutual Information Analysis. In Computer Aided Chemical Engineering; Elsevier: Amsterdam, The Netherlands, 2020; Volume 48, pp. 1165–1170. ISBN 978-0-12-823377-1. [Google Scholar]
- Topolski, M. Application of Feature Extraction Methods for Chemical Risk Classification in the Pharmaceutical Industry. Sensors 2021, 21, 5753. [Google Scholar] [CrossRef]
- Ross, B.C. Mutual Information between Discrete and Continuous Data Sets. PLoS ONE 2014, 9, e87357. [Google Scholar] [CrossRef]
- Liang, J.; Hou, L.; Luan, Z.; Huang, W. Feature Selection with Conditional Mutual Information Considering Feature Interaction. Symmetry 2019, 11, 858. [Google Scholar] [CrossRef] [Green Version]
- Darbellay, G.A. Predictability: An Information-Theoretic Perspective. In Signal Analysis and Prediction; Procházka, A., Uhlíř, J., Rayner, P.W.J., Kingsbury, N.G., Eds.; Birkhäuser Boston: Boston, MA, USA, 1998; pp. 249–262. ISBN 978-1-4612-1768-8. [Google Scholar]
- Delsole, T. Predictability and Information Theory. Part I: Measures of Predictability. J. Atmos. Sci. 2004, 61, 16. [Google Scholar] [CrossRef]
- DelSole, T. Predictability and Information Theory. Part II: Imperfect Forecasts. J. Atmos. Sci. 2005, 62, 3368–3381. [Google Scholar] [CrossRef]
- Shannon, C.E. A Mathematical Theory of Communication. Bell Syst. Tech. J. 1948, 27, 379–423. [Google Scholar] [CrossRef] [Green Version]
- Cover, T.M.; Thomas, J.A. Elements of Information Theory; John Wiley & Sons: Hoboken, NJ, USA, 2006. [Google Scholar]
- Kozachenko, L.F.; Leonenko, N.N. Sample Estimate of the Entropy of a Random Vector. Probl. Inf. Transm. 1987, 23, 9–16. [Google Scholar]
- Kraskov, A.; Stoegbauer, H.; Grassberger, P. Estimating Mutual Information. Phys. Rev. E 2004, 69, 066138. [Google Scholar] [CrossRef] [PubMed]
- Koller, D.; Friedman, N. Probabilistic Graphical Models: Principles and Techniques. In Adaptive Computation and Machine Learning; MIT Press: Cambridge, MA, USA, 2009; ISBN 978-0-262-01319-2. [Google Scholar]
- Steuer, R.; Kurths, J.; Daub, C.O.; Weise, J.; Selbig, J. The Mutual Information: Detecting and Evaluating Dependencies between Variables. Bioinformatics 2002, 18, S231–S240. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Darbellay, G.A.; Vajda, I. Estimation of the Information by an Adaptive Partitioning of the Observation Space. IEEE Trans. Inform. Theory 1999, 45, 1315–1321. [Google Scholar] [CrossRef] [Green Version]
- Lombardi, D.; Pant, S. A Non-Parametric k-Nearest Neighbour Entropy Estimator. Phys. Rev. E 2016, 93, 14. [Google Scholar]
- Singh, H.; Misra, N.; Hnizdo, V.; Fedorowicz, A.; Demchuk, E. Nearest Neighbor Estimates of Entropy. Am. J. Math. Manag. Sci. 2003, 23, 301–321. [Google Scholar] [CrossRef]
- López, J.; Maldonado, S. Redefining Nearest Neighbor Classification in High-Dimensional Settings. Pattern Recognit. Lett. 2018, 110, 36–43. [Google Scholar] [CrossRef]
- Pal, A.K.; Mondal, P.K.; Ghosh, A.K. High Dimensional Nearest Neighbor Classification Based on Mean Absolute Differences of Inter-Point Distances. Pattern Recognit. Lett. 2016, 74, 1–8. [Google Scholar] [CrossRef]
- Lord, W.M.; Sun, J.; Bollt, E.M. Geometric K-Nearest Neighbor Estimation of Entropy and Mutual Information. Chaos 2018, 28, 033114. [Google Scholar] [CrossRef] [Green Version]
- Lindner, B.; Chioua, M.; Groenewald, J.W.D.; Auret, L.; Bauer, M. Diagnosis of Oscillations in an Industrial Mineral Process Using Transfer Entropy and Nonlinearity Index. IFAC-PapersOnLine 2018, 51, 1409–1416. [Google Scholar] [CrossRef]
- Shu, Y.; Zhao, J. Data-Driven Causal Inference Based on a Modified Transfer Entropy. In Computer Aided Chemical Engineering; Elsevier: Amsterdam, The Netherlands, 2012; Volume 31, pp. 1256–1260. ISBN 978-0-444-59505-8. [Google Scholar]
- Kinney, J.B.; Atwal, G.S. Equitability, Mutual Information, and the Maximal Information Coefficient. Proc. Natl. Acad. Sci. USA 2014, 111, 3354–3359. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Pethel, S.; Hahs, D. Exact Test of Independence Using Mutual Information. Entropy 2014, 16, 2839–2849. [Google Scholar] [CrossRef] [Green Version]
- Altman, N.; Krzywinski, M. Association, Correlation and Causation. Nat. Methods 2015, 12, 899–900. [Google Scholar] [CrossRef] [Green Version]
- Karell-Albo, J.A.; Legón-Pérez, C.M.; Madarro-Capó, E.J.; Rojas, O.; Sosa-Gómez, G. Measuring Independence between Statistical Randomness Tests by Mutual Information. Entropy 2020, 22, 741. [Google Scholar] [CrossRef]
- Reshef, D.N.; Reshef, Y.A.; Finucane, H.K.; Grossman, S.R.; McVean, G.; Turnbaugh, P.J.; Lander, E.S.; Mitzenmacher, M.; Sabeti, P.C. Detecting Novel Associations in Large Data Sets. Science 2011, 334, 1518–1524. [Google Scholar] [CrossRef] [Green Version]
- Zhu, B.; Chen, Z.-S.; He, Y.-L.; Yu, L.-A. A Novel Nonlinear Functional Expansion Based PLS (FEPLS) and Its Soft Sensor Application. Chemom. Intell. Lab. Syst. 2017, 161, 108–117. [Google Scholar] [CrossRef]
- Jiang, Q.; Yan, X. Neighborhood Stable Correlation Analysis for Robust Monitoring of Multiunit Chemical Processes. Ind. Eng. Chem. Res. 2020, 59, 16695–16707. [Google Scholar] [CrossRef]
- Galagali, N. Bayesian Inference of Chemical Reaction Networks. Ph.D. Thesis, MIT, Cambridge, MA, USA, 2016. [Google Scholar]
- Verron, S.; Tiplica, T.; Kobi, A. Monitoring of Complex Processes with Bayesian Networks. In Bayesian Network; Rebai, A., Ed.; Sciyo: Rijeka, Croatia, 2010; ISBN 978-953-307-124-4. [Google Scholar]
- Kumari, P.; Bhadriraju, B.; Wang, Q.; Kwon, J.S.-I. A Modified Bayesian Network to Handle Cyclic Loops in Root Cause Diagnosis of Process Faults in the Chemical Process Industry. J. Process Control. 2022, 110, 84–98. [Google Scholar] [CrossRef]
- Pearl, J. Probabilistic Reasoning in Intelligent Systems: Networks of Plausible Inference; Morgan Kaufmann Publishers Inc.: San Francisco, CA, USA, 1988; ISBN 1-55860-479-0. [Google Scholar]
- Gharahbagheri, H.; Imtiaz, S.; Khan, F. Combination of KPCA and Causality Analysis for Root Cause Diagnosis of Industrial Process Fault. The Canadian J. Chem. Eng. 2017, 95, 1497–1509. [Google Scholar] [CrossRef]
- Fleuret, F. Fast Binary Feature Selection with Conditional Mutual Information. J. Mach. Learn. Res. 2004, 5, 1531–1555. [Google Scholar]
- Bennasar, M.; Hicks, Y.; Setchi, R. Feature Selection Using Joint Mutual Information Maximisation. Expert Syst. Appl. 2015, 42, 8520–8532. [Google Scholar] [CrossRef] [Green Version]
- Peng, H.; Fan, Y. Feature Selection by Optimizing a Lower Bound of Conditional Mutual Information. Inf. Sci. 2017, 418–419, 652–667. [Google Scholar] [CrossRef] [PubMed]
- Xiang, S.; Bai, Y.; Zhao, J. Medium-Term Prediction of Key Chemical Process Parameter Trend with Small Data. Chem. Eng. Sci. 2022, 249, 117361. [Google Scholar] [CrossRef]
- Zhang, Y.; Luo, L.; Ji, X.; Dai, Y. Improved Random Forest Algorithm Based on Decision Paths for Fault Diagnosis of Chemical Process with Incomplete Data. Sensors 2021, 21, 6715. [Google Scholar] [CrossRef]
- Aldrich, C.; Auret, L. Fault detection and diagnosis with random forest feature extraction and variable importance methods. IFAC Proc. Vol. 2010, 43, 79–86. [Google Scholar] [CrossRef]
- Jiang, B.; Luo, Y.; Lu, Q. Maximized Mutual Information Analysis Based on Stochastic Representation for Process Monitoring. IEEE Trans. Ind. Inform. 2019, 15, 1579–1587. [Google Scholar] [CrossRef]
- Louppe, G.; Wehenkel, L.; Sutera, A.; Geurts, P. Understanding Variable Importances in Forests of Randomized Trees. Adv. Neural Inf. Process. Syst. 2013, 1, 431–439. [Google Scholar]
- Han, H.; Guo, X.; Yu, H. Variable Selection Using Mean Decrease Accuracy and Mean Decrease Gini Based on Random Forest. In Proceedings of the 2016 7th IEEE International Conference on Software Engineering and Service Science (ICSESS), Beijing, China, 26–28 August 2016; pp. 219–224. [Google Scholar]
- Zhang, Y.; Zhou, H.; Qin, S.J.; Chai, T. Decentralized Fault Diagnosis of Large-Scale Processes Using Multiblock Kernel Partial Least Squares. IEEE Trans. Ind. Inf. 2010, 6, 3–10. [Google Scholar] [CrossRef]
- McClure, K.S.; Gopaluni, R.B.; Chmelyk, T.; Marshman, D.; Shah, S.L. Nonlinear Process Monitoring Using Supervised Locally Linear Embedding Projection. Ind. Eng. Chem. Res. 2014, 53, 5205–5216. [Google Scholar] [CrossRef]
- Lundberg, S.M.; Lee, S.-I. A Unified Approach to Interpreting Model Predictions. Adv. Neural Inf. Process. Syst. 2017, 30, 10. [Google Scholar]
- Zhang, Y.; Li, Z.; Wang, Z.; Jin, Q. Optimization Study on Increasing Yield and Capacity of Fluid Catalytic Cracking (FCC) Units. Processes 2021, 9, 1497. [Google Scholar] [CrossRef]
- Dasila, P.K.; Choudhury, I.; Saraf, D.; Chopra, S.; Dalai, A. Parametric Sensitivity Studies in a Commercial FCC Unit. ACES 2012, 2, 136–149. [Google Scholar] [CrossRef]
- Brown, G.; Pocock, A.; Zhao, M.-J.; Lujan, M. Conditional Likelihood Maximisation: A Unifying Framework for Information Theoretic Feature Selection. J. Mach. Learn. Res. 2012, 13, 27–66. [Google Scholar]












{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Dataset | Description | ||
|---|---|---|---|
| random | 0.94 (0.92, 0.96) | 0.94 (0.93, 0.96) | |
| linear | 0 (0, 0) | 0 (0, 0) | |
| parabola | 0 (0, 0) | 0 (0, 0) | |
| categorical | 0 (0, 0) | 0 (0, 0) |
| Dataset | Description | ||
|---|---|---|---|
| M1 | 0.96 (0.95, 0.98) | 0.94 (0.92, 0.95) | |
| M2 | 0.92 (0.90, 0.93) | 0.92 (0.91, 0.94) | |
| M3 | 0 (0, 0) | 0 (0, 0) | |
| M4 | 0 (0, 0) | 0 (0, 0) |
| Target | Variables in MB | Variables Not in MB | Total | |||
|---|---|---|---|---|---|---|
| - | Number | Distribution of MI | Number | Distribution of MI | Number | Distribution of MI |
| 25 | 0.701 (0.569, 0.808) | 192 | 0.447 (0.303, 0.584) | 217 | 0.476 (0.338, 0.615) | |
| 23 | 0.890 (0.787, 1.000) | 194 | 0.549 (0.373, 0.744) | 217 | 0.583 (0.408, 0.773) | |
| 20 | 0.840 (0.707, 0.961) | 197 | 0.526 (0.354, 0.692) | 217 | 0.555 (0.382, 0.705) | |
| 28 | 0.520 (0.409, 0.598) | 189 | 0.313 (0.222, 0.403) | 217 | 0.340 (0.231, 0.439) | |
| Variable Number | Variable Name | Note | Value Range | Targets Affected |
|---|---|---|---|---|
| 5 | TI-3107B | fresh material temperature in the lifting tube nozzle, °C | [401, 457] | |
| 24 | TI-3112 | outlet temperature of the settler, °C | [504, 514] | |
| 26 | TI-3117 | temperature of the slide valve in the settler, °C | [499, 518] | |
| 132 | TI-3546 | outlet temperature (A) of the evaporation section, °C | [391, 547] | |
| 133 | TI-3542 | outlet temperature (B) of the evaporation section, °C | [127, 181] | |
| 134 | TI-3551 | outlet temperature of coal saver in the waste heat boiler, °C | [129, 192] | |
| 201 | TI-3237 | outlet temperature at the bottom of the stripper tower, °C | [136, 180] | |
| 13 | FIC-3104 | flowrate of refining slurry in the lift tube, t/h | [6, 35] | |
| 52 | FIC-3118 | flowrate of combustion oil in the first regenerator, m3/min | [0, 7] | |
| 158 | FIQ-3519 | inlet flowrate (A) of fuel gas in the waste heat boiler, t/h | [0, 2717] | |
| 159 | FIQ-3520 | inlet flowrate (B) of fuel gas in the waste heat boiler, t/h | [0, 1163] | |
| 194 | FIC-3203 | flowrate of oil slurry returning to the fractionation tower, t/h | [220, 407] | |
| 204 | FIC-3223 | steam flowrate (A) in the stripper tower, t/h | [1, 2] | |
| 212 | FIC-3403 | steam flowrate (B) in the stripper tower, t/h | [16, 83] | |
| 71 | PI-3114 | main air pressure of the second regenerator, MPa | [0.27, 0.35] |
| Target | Strongly Associated | Interactively Associated | Redundantly Associated | Irrelevant | Total |
|---|---|---|---|---|---|
| 25 | 0 | 144 | 48 | 217 | |
| 23 | 0 | 151 | 43 | 217 | |
| 20 | 0 | 157 | 40 | 217 | |
| 28 | 0 | 101 | 88 | 217 |
| Parameter | Note | Value |
|---|---|---|
| criterion | the function to measure the quality of a split | “mse” 1 |
| max_features | the number of features to consider when looking for the best split | “sqrt” 2 |
| min_samples_split | the minimum number of samples required to split an internal node | 10 |
| min_samples_leaf | the minimum number of samples needed to be at a leaf node | 3 |
| n_estimators | the number of trees in the forest | 100 |
Publisher’s Note: MDPI stays neutral with regard to jurisdictional claims in published maps and institutional affiliations. |
© 2022 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Luo, L.; He, G.; Zhang, Y.; Ji, X.; Zhou, L.; Dai, Y.; Dang, Y. Association Measure and Compact Prediction for Chemical Process Data from an Information-Theoretic Perspective. Processes 2022, 10, 2659. https://doi.org/10.3390/pr10122659
Luo L, He G, Zhang Y, Ji X, Zhou L, Dai Y, Dang Y. Association Measure and Compact Prediction for Chemical Process Data from an Information-Theoretic Perspective. Processes. 2022; 10(12):2659. https://doi.org/10.3390/pr10122659
Chicago/Turabian StyleLuo, Lei, Ge He, Yuequn Zhang, Xu Ji, Li Zhou, Yiyang Dai, and Yagu Dang. 2022. "Association Measure and Compact Prediction for Chemical Process Data from an Information-Theoretic Perspective" Processes 10, no. 12: 2659. https://doi.org/10.3390/pr10122659