
Face Verification Based on Deep Learning for Person Tracking in Hazardous Goods Factories


Abstract
:1. Introduction
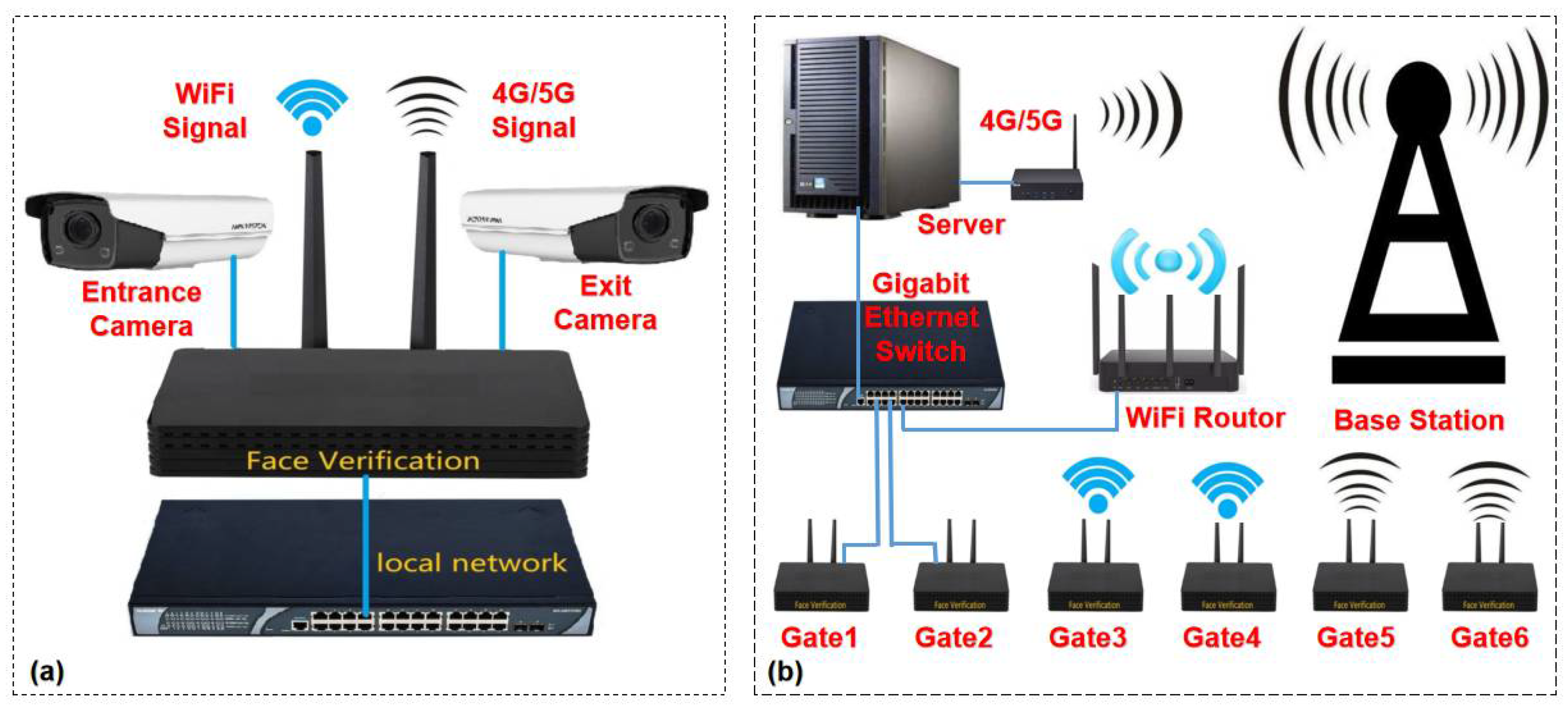
2. Materials and Methods
3. Algorithms in the Gate Face Verification Model
3.1. Face Extractor Based on MTCNN
3.2. Module of Face Image Normalization
- (1)
- Normalization of face image size
- (2)
- Lateral face processing
3.3. The Proposed MDCNN for Feature Extraction
3.4. Face Verification or Recognition
3.5. Training of the Model
3.5.1. Training of MTCNN
3.5.2. Training of MDCNN
4. Results of Experiments
4.1. Details of Training Process
4.2. Evaluation for Face Recognition with Multi-View
4.3. Evaluation for Face Recognition Benchmark Dataset without Multi-View
4.3.1. Performance on LFW Dataset
4.3.2. Performance on YTF Dataset
4.4. Evaluation for Face Recognition with Multi-Face
4.5. Prototype System and Test of Real Scenario at Factory Gates
5. Conclusions
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Data Availability Statement
Conflicts of Interest
References
- Li, Y.; Wang, H. Quantitative Area Risk Assessment and Safety Planning on Chemical Industry Parks. In Proceedings of the International Conference on Quality, Reliability, Risk, Maintenance, and Safety Engineering, Chengdu, China, 15–18 July 2013; pp. 413–419. [Google Scholar]
- Fang, L.; Liang, J.; Jiang, L.; Wang, E. Design and Development of the AI-assisted Safety System for Hazardous Plant. In Proceedings of the 13th International Congress on BioMedical Engineering and Informatics, Chengdu, China, 17–19 October 2020; pp. 60–65. [Google Scholar]
- Pavlenko, E.N.; Pavlenko, A.E.; Dolzhikova, M.V. Safety Management Problems of Chemical Plants. In Proceedings of the International Multi-Conference on Industrial Engineering and Modern Technologies (FarEastCon), Vladivostok, Russia, 6–9 October 2020; pp. 768–774. [Google Scholar]
- Ma, Y.; Chang, D. Study on Safety Production Management Improvement of Small and Medium Sized Chemical Enterprises. In Proceedings of the International Conference on Logistics, Informatics and Service Sciences (LISS), Sydney, NSW, Australia, 24–27 July 2016; pp. 978–983. [Google Scholar]
- Cevikap, H.; Triggs, B. Face Recognition Based on Image Sets. In Proceedings of the 2010 IEEE Conference on Computer Vision and Pattern Recognition (CVPR), San Francisco, CA, USA, 13–18 June 2010; pp. 2567–2573. [Google Scholar]
- Deng, J.; Guo, J.; Yang, J.; Xue, N.; Cotsia, I.; Zafeiriou, S.P. ArcFace: Additive Angular Margin Loss for Deep Face Recognition. In Proceedings of the IEEE Transactions on Pattern Analysis and Machine Intelligence, Long Beach, CA, USA, 15–20 June 2019. [Google Scholar] [CrossRef]
- Wang, F.; Cheng, J.; Liu, W.; Liu, H. Additive Margin Softmax for Face Verification. IEEE Signal Process. Lett. 2018, 25, 926–930. [Google Scholar] [CrossRef] [Green Version]
- Wang, H.; Wang, Y.; Zhou, Z.; Ji, X.; Gong, D.; Zhou, J.; Li, Z.; Liu, W. CosFace: Large Margin Cosine Loss for Deep Face Recognition. In Proceedings of the 2018 IEEE/CVF Conference on Computer Vision and Pattern Recognition, Salt Lake City, UT, USA, 18–23 June 2018; pp. 5265–5274. [Google Scholar] [CrossRef] [Green Version]
- Hsu, G.J.; Wu, H.; Yap, M.H. A Comprehensive Study on Loss Functions for Cross-Factor Face Recognition. In Proceedings of the 2020 IEEE/CVF Conference on Computer Vision and Pattern Recognition Workshops (CVPRW), Seattle, WA, USA, 14–19 June 2020; pp. 3604–3611. [Google Scholar] [CrossRef]
- Chan, C.H.; Kittler, J. Angular Sparsemax for Face Recognition. In Proceedings of the 25th International Conference on Pattern Recognition (ICPR), Milan, Italy, 10–15 January 2021; pp. 10473–10479. [Google Scholar] [CrossRef]
- Ahmed, N.K.; Hemayed, E.E.; Fayek, M.B. Hybrid Siamese Network for Unconstrained Face Verification and Clustering under Limited Resources. Big Data Cogn. Comput. 2020, 4, 19. [Google Scholar] [CrossRef]
- Cui, Z.; Li, W.; Xu, D.; Shan, S.G.; Chen, X. Fusing Robuts Face Region Descriptors Via Multiple Learning for Face Recognition in The Wild. In Proceedings of the 2013 IEEE Conference on Computer Vision and Pattern Recognition (CVPR), Portland, OR, USA, 23–28 June 2013; pp. 3554–3561. [Google Scholar]
- Taigman, Y.; Yang, M.; Ranzato, M.A.; Wolf, L. DeepFace: Closing the Gap to Human-Level Performance in Face Verification. In Proceedings of the 2014 IEEE Conference on Computer Vision and Pattern Recognition (CVPR), Columbus, OH, USA, 23–28 June 2014; pp. 1701–1708. [Google Scholar]
- Lin, S.; Gong, Z.H.; Han, Z.H.; Shi, H.B. Multi-angle face recognition algorithm based on multi-RKHS. Acta Photonica Sin. 2013, 42, 1436–1441. [Google Scholar]
- Wang, T.S.; Shi, P.F. Kernel grassmannian distances and discriminant analysis for face recognition from image sets. Pattern Recognit. Lett. 2009, 30, 1161–1165. [Google Scholar] [CrossRef]
- Galoogahi, H.K.; Sim, T. Face Sketch Recognition by Local Radon Binary Pattern: LRBP. In Proceedings of the 2012 IEEE International Conference on Image Processing (ICIP), Orlando, FL, USA, 30 September–3 October 2012; pp. 1837–1840. [Google Scholar]
- Mignon, A.; Jurie, F. Pcca: A New Approach for Distance Learning from Sparse Pairwise Constraints. In Proceedings of the 2012 IEEE Conference on Computer Vision and Pattern Recognition (CVPR), Providence, RI, USA, 16–21 June 2012; pp. 2666–2672. [Google Scholar]
- Sun, Y.; Wang, X.; Tang, X. Deeply Learned Face Representations Are Sparse, Selective, and Robust. In Proceedings of the 2015 IEEE Conference on Computer Vision and Pattern Recognition (CVPR), Boston, MA, USA, 7–12 June 2015; pp. 2892–2900. [Google Scholar]
- Schroff, F.; Kalenichenko, D.; Philbin, J. Facenet: A Unified Embedding for Face Recognition and Clustering. In Proceedings of the 2015 IEEE Conference on Computer Vision and Pattern Recognition (CVPR), Boston, MA, USA, 7–12 June 2015; pp. 815–823. [Google Scholar]
- Liu, W.; Wen, Y.; Yu, Z.; Li, M.; Raj, B.; Song, L. SphereFace: Deep Hypersphere Embedding for Face Recognition. In Proceedings of the 30th IEEE Conference on Computer Vision and Pattern Recognition (CVPR), Honolulu, HI, USA, 21–26 July 2017; pp. 6738–6746. [Google Scholar]
- Huang, G.; Mattar, M.; Berg, T.; Miller, E. Labeled Faces in The Wild: A Database Forstudying Face Recognition in Unconstrained Environments. In Proceedings of the Workshop on Faces in’Real-Life’Images: Detection, Alignment, and Recognition, Marseille, France, 16–18 October 2008. [Google Scholar]
- Wolf, L.; Hassner, T.; Maoz, I. Face Recognition in Unconstrained Videos with Matched Background Similarity. In Proceedings of the 2011 IEEE Conference on Computer Vision and Pattern Recognition (CVPR), Colorado Springs, CO, USA, 20–25 June 2011; pp. 529–534. [Google Scholar]
- Zhang, K.; Zhang, Z.; Li, Z.; Qiao, Y. Joint face detection and alignment using multi-task cascaded convolutional networks. IEEE Signal Process. Lett. 2016, 23, 1499–1503. [Google Scholar] [CrossRef] [Green Version]
- Wu, D.; Wu, X.; Qin, H. Research on multi-view face recognition with regression algorithm. Tech. Acoust. 2015, 34, 172–175. [Google Scholar]
- Hu, J.L.; Lu, J.W.; Tan, Y.P. Discriminative Deep Metric Learning for Face Verification in The Wild. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition (CVPR), Columbus, OH, USA, 23–28 June 2014; pp. 1875–1882. [Google Scholar]
- Ioffe, S.; Szegedy, C. Batch Normalization: Accelerating Deep Network Training by Reducing Internal Covariate Shift. In Proceedings of the International Conference on Machine Learning (ICML), Lille, France, 6–11 July 2015. [Google Scholar]
- Wang, X.; Tang, X. Face photo-sketch synthesis and recognition. IEEE Trans. Pattern Anal. Mach. Intell. (TPAMI) 2009, 31, 1955–1967. [Google Scholar] [CrossRef] [PubMed]
- Patil, S.; Shubhangi, D.C. Froensic Sketch Based Face Recognition Using Geometrical Face Model. In Proceedings of the 2017 International Conference for Convergence in Technology, Mumbai, India, 7–9 April 2017; pp. 450–456. [Google Scholar]
- Hu, Y.; Mian, A.; Owens, R. Sparse Approximated Nearest Points for Image Set Classification. In Proceedings of the 2011 Conference on Computer Vision and Pattern Recognition (CVPR), Colorado Springs, CO, USA, 20–25 June 2011; pp. 121–128. [Google Scholar]
- He, K.; Zhang, X.; Ren, S.; Sun, J. Deep Residual Learning for Image Recognition. In Proceedings of the 2016 IEEE Conference on Computer Vision and Pattern Recognition (CVPR), Las Vegas, NV, USA, 27–30 June 2016; pp. 770–778. [Google Scholar]
- Liu, J.; Bae, S.; Park, H.J.; Li, L.; Yoon, S.B.; Yi, J. Face photo-sketch recognition based on joint dictionary learning. In Proceedings of the 14th Iapr International Conference on Machine Vision Applications (MVA), Tokyo, Japan, 18–22 May 2015; pp. 77–80. [Google Scholar]
- He, K.; Zhang, X.; Ren, S.; Sun, J.L. Delving Deep into Rectifiers: Surpassing Human-Level Performance on Imagenet Classification. In Proceedings of the 2015 IEEE International Conference on Computer Vision (ICCV), Santiago, Chile, 7–13 December 2015; pp. 1026–1034. [Google Scholar]












{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Method | Dataset | FD (%) | FV (%) |
|---|---|---|---|
| KGDA [15] | FERET | 58 | N/A |
| Multi-RKHS [14] | FERET | 77 | N/A |
| Wu et al. [24] | Private | 90.10 | N/A |
| MTCNN [23] | AFLW | 93.10 | N/A |
| Ours | CNBC | 96.62 | 90.58 |
| Ours | FERET | 98.91 | 96.78 |
| Ours | CNBC + FERET | 98.13 | 94.69 |
| Method | Models | Accuracy (%) |
|---|---|---|
| PMML [12] | 1 | 76.40 |
| STRFD + PMML [13] | 1 | 89.35 |
| DDML [25] | 1 | 87.83 |
| DDML (combined) [25] | 6 | 90.68 |
| DeepFace [13] | 3 | 97.35 |
| DeepID2+ [18] | 1 | 98.70 |
| PCCA (SIFT) [17] | 1 | 83.80 |
| SphereFace-20 [20] | 1 | 99.26 |
| SphereFace-36 [20] | 1 | 99.35 |
| SphereFace-64 [20] | 1 | 99.42 |
| ArcFace (5.1 M) [6] | 1 | 99.83 |
| AMsoftmax [7] | 1 | 99.17 |
| CosFace (5 M) [8] | 1 | 99.73 |
| Ours (1 M) | 1 | 99.38 |
| Method | Models | Accuracy (%) |
|---|---|---|
| LBP + DDML [22] | 1 | 81.26 |
| STRFD + PMML [13] | 1 | 79.48 |
| DDML [25] | 1 | 82.30 |
| DDML (combined) [25] | 6 | 82.34 |
| DeepFace [13] | 1 | 91.40 |
| DeepID2+ [18] | 1 | 93.20 |
| SphereFace-20 [20] | 1 | 94.10 |
| SphereFace-36 [20] | 1 | 94.30 |
| SphereFace-64 [20] | 1 | 95.00 |
| ArcFace (5.1 M) [6] | 1 | 98.02 |
| CosFace (5 M) [7] | 1 | 97.60 |
| Ours (1 M) | 1 | 94.30 |
| Face (s) | Number | Recognition | Accuracy (%) | Time (ms) |
|---|---|---|---|---|
| 1 | 125 | 123 | 98.40 | 83 |
| 2 | 125 | 118 | 94.40 | 92 |
| 3 | 125 | 118 | 94.40 | 101 |
| 4 | 125 | 119 | 95.20 | 99 |
| Total | 500 | 481 | 95.60 |
Publisher’s Note: MDPI stays neutral with regard to jurisdictional claims in published maps and institutional affiliations. |
© 2022 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Huang, X.; Zeng, X.; Wu, Q.; Lu, Y.; Huang, X.; Zheng, H. Face Verification Based on Deep Learning for Person Tracking in Hazardous Goods Factories. Processes 2022, 10, 380. https://doi.org/10.3390/pr10020380
Huang X, Zeng X, Wu Q, Lu Y, Huang X, Zheng H. Face Verification Based on Deep Learning for Person Tracking in Hazardous Goods Factories. Processes. 2022; 10(2):380. https://doi.org/10.3390/pr10020380
Chicago/Turabian StyleHuang, Xixian, Xiongjun Zeng, Qingxiang Wu, Yu Lu, Xi Huang, and Hua Zheng. 2022. "Face Verification Based on Deep Learning for Person Tracking in Hazardous Goods Factories" Processes 10, no. 2: 380. https://doi.org/10.3390/pr10020380
APA StyleHuang, X., Zeng, X., Wu, Q., Lu, Y., Huang, X., & Zheng, H. (2022). Face Verification Based on Deep Learning for Person Tracking in Hazardous Goods Factories. Processes, 10(2), 380. https://doi.org/10.3390/pr10020380