
Quantitative Method for Liquid Chromatography–Mass Spectrometry Based on Multi-Sliding Window and Noise Estimation

 ,
,
Abstract
:1. Introduction
2. Materials and Methods
2.1. The Introduction of Chromatographic Signal
- (1)
- Peak baseline refers to the distance from the beginning to the end of the peak on the baseline;
- (2)
- Peak height refers to the height from the highest point of the peak to the baseline of the peak;
- (3)
- Peak width refers to the distance between the two tangents made at the inflection points on both sides of the peak and the two intersection points of the baseline;
- (4)
- Half-peak width refers to the width of the peak at half of the peak height.
2.2. Reagents and Instruments
2.3. Data Processing Algorithm
2.3.1. Data Pre-Processing
2.3.2. Signal-to-Noise Ratio Estimation Algorithm Based on Histogram Statistics
2.3.3. A Multi-Sliding Window Peak Identification Algorithm
- (1)
- For each datum Xi of the sliding window, is calculated as .
- (2)
- If is larger than n∗std, Xi can be classified as the part of the peak area, and the flag of Xi is set to 1.
- (3)
- If is smaller than n∗std, Xi can be classified as the part of the peak valley, and the flag of Xi is set to −1.
- (4)
- If is within n*std, Xi can be classified as the normal signal, and the flag of Xi is set to 0.
- (1)
- The peak threshold is input to filter all mass spectral peaks with peaks greater than the threshold.
- (2)
- If Flagi = 1, we determine the previous point of the data point as the peak starting point Sstart and define a variable peakstart that stores the point’s position.
- (3)
- If Flagi ≠ 1, Flagi+1 ≠ 1, and peakstart is non-empty, we determine the point as the peak end point Send and set the peakstart to empty.
- (4)
- In the range of Sstart to Send, we find the position of the data point with the highest intensity, that is, the peak point.
- (5)
- The intensity of the peak point is compared with the threshold; if it is greater than the threshold, the peak information can be output.
- (6)
- The above process is repeated until the completion of the search for all peaks.
2.3.4. Multi-Window-Based Signal-to-Noise Ratio Estimation Algorithm
2.3.5. Quantitative Analysis Method
2.4. Steroid Analysis
2.4.1. Calibration Samples
2.4.2. Liquid Chromatography–Tandem Mass Spectrometry Conditions
2.4.3. Sample Preparation
2.4.4. Method Validation
3. Results
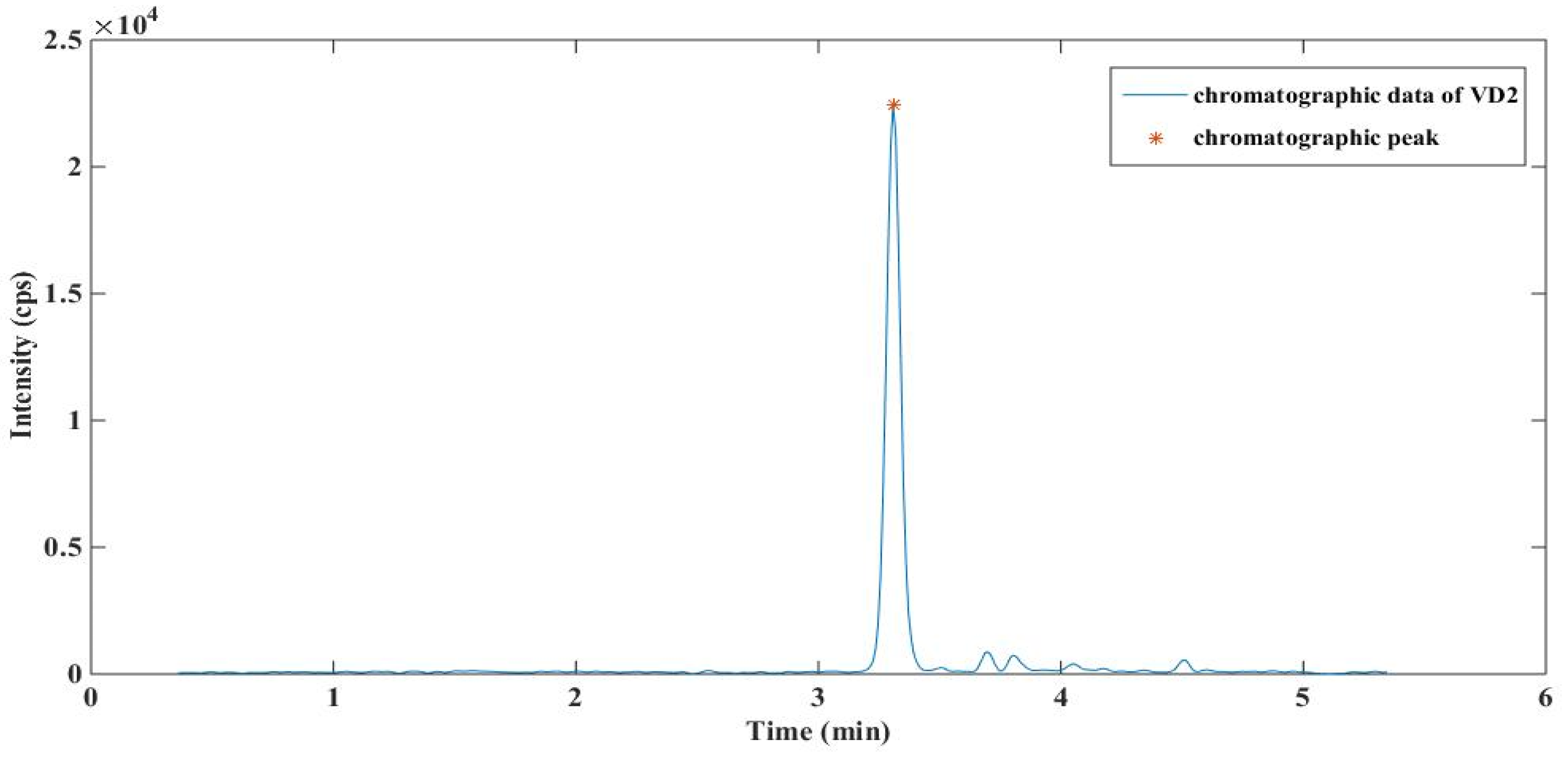
3.1. Analysis of Spectral Peak Identification
3.2. Methodological Examination
3.2.1. Lower Limit of Quantification (LLOQ)
3.2.2. Recovery
3.2.3. Precision
4. Discussion
5. Conclusions
Author Contributions
Funding
Data Availability Statement
Conflicts of Interest
References
- Wu, A.H.B.; French, D. Implementation of liquid chromatography/mass spectrometry into the clinical laboratory. Clin. Chim. Acta 2013, 420, 4–10. [Google Scholar] [CrossRef] [PubMed]
- Nielen, M.W.F.; Hooijerink, H.; Zomer, P.; Mol, J.G.J. Desorption electrospray ionization mass spectrometry in the analysis of chemical food contaminants in food. TrAC Trends Anal. Chem. 2011, 30, 165–180. [Google Scholar] [CrossRef]
- Yang, Y.; Liang, Y.S.; Yang, J.N.; Ye, F.Y.; Zhou, T.; Li, G.K. Advances of supercritical fluid chromatography in lipid profiling. J. Pharm. Anal. 2019, 9, 1–8. [Google Scholar] [CrossRef] [PubMed]
- Bos, T.S.; Knol, W.C.; Molenaar, S.R.A.; Niezen, L.E.; Schoenmakers, P.J.; Somsen, G.W.; Pirok, B.W.J. Recent applications of chemometrics in one- and two-dimensional chromatography. J. Sep. Sci. 2020, 43, 1678–1727. [Google Scholar] [CrossRef] [PubMed]
- Lin, J.S.; Liu, X.F.; Wang, J.; Li, D.; Zhu, W.Q.; Chen, W.B.; Zhang, X.H.; Li, Q.M.; Li, M. An artifactual solution degradant of pregabalin due to adduct formation with acetonitrile catalyzed by alkaline impurities during HPLC sample preparation. J. Pharm. Biomed. Anal. 2019, 175, 7. [Google Scholar] [CrossRef]
- Zhang, Z.M.; Tong, X.; Peng, Y.; Ma, P.; Zhang, M.J.; Lu, H.M.; Chen, X.Q.; Liang, Y.Z. Multiscale peak detection in wavelet space. Analyst 2015, 140, 7955–7964. [Google Scholar] [CrossRef]
- Wei, X.L.; Shi, X.; Kim, S.; Patrick, J.S.; Binkley, J.; Kong, M.Y.; McClain, C.; Zhang, X. Data dependent peak model based spectrum deconvolution for analysis of high resolution LC-MS data. Anal. Chem. 2014, 86, 2156–2165. [Google Scholar] [CrossRef]
- Li, B.Q.; Siu, S.; Evans, J.W. Microcomputer processing of chromatographic data. J. Chromatogr. Sci. 1987, 25, 281–285. [Google Scholar] [CrossRef]
- Parilla, P.; Galera, M.M.; Vidal, J.M.; Frenich, A.G. Determination of fenamiphos and folpet in water by time-domain differentiation of high-performance liquid chromatographic peaks. Analyst 1994, 119, 2231–2236. [Google Scholar] [CrossRef]
- Asnin, L.D. Peak measurement and calibration in chromatographic analysis. TrAC Trends Anal. Chem. 2016, 81, 51–62. [Google Scholar] [CrossRef]
- Shao, X.; Cai, W.; Sun, P. Determination of the component number in overlapping multicomponent chromatogram using wavelet transform. Chemom. Intell. Lab. Syst. 1998, 43, 147–155. [Google Scholar] [CrossRef]
- Dinç, E.; Komsta, Ł.; Vander Heyden, Y.; Sherma, J. Chemometric strategies in chromatographic analysis of pharmaceuticals. Chemom. Chromatogr. 2018, 95, 381–414. [Google Scholar]
- Du, P.; Kibbe, W.A.; Lin, S.M. Improved peak detection in mass spectrum by incorporating continuous wavelet transform-based pattern matching. Bioinformatics 2006, 22, 2059–2065. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Li, Y. Dynamic particle swarm optimization algorithm for resolution of overlapping chromatograms. In Proceedings of the 2009 Fifth International Conference on Natural Computation, Tianjin, China, 14–16 August 2009; pp. 246–250. [Google Scholar]
- Dromey, R.G.; Stefik, M.J.; Rindfleisch, T.C.; Duffield, A.M. Extraction of mass spectra free of background and neighboring component contributions from gas chromatography/mass spectrometry. Anal. Chem. 1976, 48, 1368–1375. [Google Scholar] [CrossRef]
- Zeng, Z.D.; Chin, S.T.; Hugel, H.M.; Marriotta, P.J. Simultaneous deconvolution and re-construction of primary and secondary overlapping peak clusters in comprehensive two-dimensional gas chromatography. J. Chromatogr. A 2011, 1218, 2301–2310. [Google Scholar] [CrossRef]
- Grushka, E. Chromatographic peak capacity and the factors influencing it. Anal. Chem. 1970, 42, 1142–1147. [Google Scholar] [CrossRef]
- Sorensen, M. Ultrahigh Pressure Capillary Liquid Chromatography-Mass Spectrometry for Metabolomics and Lipidomics. Ph.D. Thesis, University of Michigan, Ann Arbor, MI, USA, 2021. [Google Scholar]
- Foley, J. Equations for chromatographic peak modeling and calculation of peak area. Anal. Chem. 1987, 59, 1984–1987. [Google Scholar] [CrossRef]
- Roy, I.G. An optimal Savitzky–Golay derivative filter with geophysical applications: An example of self-potential data. Geophys. Prospect. 2020, 68, 1041–1056. [Google Scholar] [CrossRef]
- Ruffin, C.; King, R.L. The analysis of hyperspectral data using Savitzky-Golay filtering-theoretical basis. In Proceedings of the IEEE 1999 International Geoscience and Remote Sensing Symposium, IGARSS’99 (Cat. No.99CH36293), Hamburg, Germany, 28 June–2 July 1999; Volume 752, pp. 756–758. [Google Scholar]
- Zhang, Z.; McElvain, J.S. Optimizing spectroscopic signal-to-noise ratio in analysis of data collected by a chromatographic/spectroscopic system. Anal. Chem. 1999, 71, 39–45. [Google Scholar] [CrossRef]
- Tautenhahn, R. Feature-Detektion, Annotation und Alignment von Metabolomik LC-MS Daten. Ph.D. Thesis, Martin-Luther-Universität Halle-Wittenberg, Halle, Germany, 2009. [Google Scholar]
- Rebentrost, P.; Mohseni, M.; Lloyd, S. Quantum support vector machine for big data classification. Phys. Rev. Lett. 2014, 113, 130503. [Google Scholar] [CrossRef]
- Tan, A.; Lévesque, I.A.; Lévesque, I.M.; Viel, F.; Boudreau, N.; Lévesque, A. Analyte and internal standard cross signal contributions and their impact on quantitation in LC–MS based bioanalysis. J. Chromatogr. B 2011, 879, 1954–1960. [Google Scholar] [CrossRef] [PubMed]
- Morris, J.S.; Coombes, K.R.; Koomen, J.; Baggerly, K.A.; Kobayashi, R. Feature extraction and quantification for mass spectrometry in biomedical applications using the mean spectrum. Bioinformatics 2005, 21, 1764–1775. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Carmona, R.A.; Hwang, W.L.; Torresani, B. Multiridge detection and time-frequency reconstruction. IEEE Trans. Signal Processing 2015, 47, 492. [Google Scholar] [CrossRef] [Green Version]






{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Step | Data Process |
|---|---|
| 1 | Input: SmoothData y, threshold n. peak threshold n1 |
| 2 | Logarithm of SmoothData X = log(y) |
| 3 | Calculate the mean avg and standard deviation std in a large sliding window whose window length is m. Calculate the flags of all data. For each yi If log(yi) − avg > n∗std, flagi = 1; If log(yi) − avg < n∗std, flagi = −1; Otherwise flagi = 0; If flagi ≠ 1, the window slides forward one point, repeat step 3. |
| 4 | For each flagi If flagi = 1, the variable peakstart is i − 1; set Sstart = i − 1; If flagi ≠ 1, flagi+1 ≠ 1, and peakstart ! = null, peakstart = null; set Send = i; In the range from Sstart to Send, MWPeakswindow1.Intenstity = max[ySstart,ySend], MWPeakswindow1.peakpoint = the time corresponding to the maximum value. |
| 5 | Define a small sliding window whose window length is m1, repeat the steps of 3–5. The information of MWPeakswindow2 can be obtained. |
| 6 | Combine MWPeakswindow1 and MWPeakswindow2 into MWPeaks. Remove the duplicate peaks in MWPeaks. |
| 7 | Combine MWPeakswindow1 and MWPeakswindow2 into MWPeaks. Remove the duplicate peaks in MWPeaks. |
| 8 | For each MWPeaks If MWPeaks[i]. Intenstity < n1, delete the peak. |
| 9 | Output: set of peaks MWPeaks |
| Compound | Retention Time (min) | Precursor (m/z) | Quantifier (m/z) | DP (V) | CE (V) |
|---|---|---|---|---|---|
| E1 | 3.50 | 269.0 | 145.1 | −100 | −50 |
| E1-d4 | 3.49 | 273.1 | 147.1 | −120 | −55 |
| E2 | 3.49 | 271.0 | 145.1 | −120 | −57 |
| E2-d4 | 3.48 | 275.1 | 147.1 | −120 | −58 |
| E3 | 3.27 | 287.1 | 171.1 | −120 | −52 |
| E3-d3 | 3.27 | 290.1 | 173.1 | −125 | −53 |
| 17-OHPreg | 3.56 | 331.1 | 287.2 | −80 | −27 |
| 17-OHPreg-d3 | 3.56 | 334.1 | 287.2 | −80 | −28 |
| Ald | 3.30 | 359.1 | 189.0 | −78 | −25 |
| Ald-d7 | 3.29 | 366.1 | 194.1 | −80 | −27 |
| DHEAS | 3.08 | 367.1 | 97.0 | −100 | −25 |
| DHEAS-d6 | 3.08 | 373.1 | 98.0 | −100 | −20 |
| Compound | Linear Range (ng/mL) | Correlation Coefficient (r2) | Regression Equation y = ax + b | LLOQ (ng/mL) | Recovery (%) | Precision (CV%) |
|---|---|---|---|---|---|---|
| E1 | 0.02–2.00 | 0.9988 | y = 4.79200x + 0.06490 | 0.02 | 97.91 | 7.96 |
| E2 | 0.05–2.00 | 0.9952 | y = 2.21100x − 0.04550 | 0.05 | 94.60 | 5.20 |
| E3 | 0.10–50.00 | 0.9958 | y = 0.43900x + 0.20800 | 0.10 | 102.70 | 8.61 |
| 17-OHPreg | 0.50–200.00 | 0.9998 | y = 0.09930x + 0.00454 | 0.50 | 100.42 | 7.06 |
| Ald | 0.10–10.00 | 0.9954 | y = 2.24200x − 0.33100 | 0.10 | 102.70 | 7.82 |
| DHEAS | 10.00–5000.00 | 0.9998 | y = 0.00386x − 0.04550 | 10.00 | 99.12 | 7.43 |
| Compound | Low Level (n = 5) | Medium Level (n = 5) | High Level (n = 5) | ||||||
|---|---|---|---|---|---|---|---|---|---|
| Spike (ng/mL) | Test (ng/mL) | Recovery (%) | Spike (ng/mL) | Test (ng/mL) | Recovery (%) | Spike (ng/mL) | Test (ng/mL) | Recovery (%) | |
| E1 | 0.05 | 0.046 | 92.49 | 0.50 | 0.536 | 107.13 | 1.50 | 1.65 | 110.03 |
| E2 | 0.10 | 0.102 | 102.15 | 0.80 | 0.815 | 101.82 | 1.50 | 1.628 | 108.51 |
| E3 | 0.50 | 0.54 | 107.40 | 5.00 | 4.410 | 88.20 | 25.00 | 23.10 | 92.41 |
| 17-OHPreg | 1.00 | 1.29 | 110.35 | 10.00 | 10.310 | 101.27 | 100.00 | 102.65 | 102.46 |
| Ald | 0.25 | 0.28 | 110.28 | 1.00 | 1.050 | 105.38 | 5.00 | 4.71 | 94.23 |
| DHEAS | 50.00 | 48.12 | 96.25 | 500.00 | 469.420 | 93.88 | 2500.00 | 2656.60 | 106.26 |
| Compound | Low Concentration | Medium Concentration | High Concentration | ||||||
|---|---|---|---|---|---|---|---|---|---|
| CV Intra (%) | CV Inter (%) | CV Overall (%) | CV Intra (%) | CV Inter (%) | CV Overall (%) | CV Intra (%) | CV Inter (%) | CV Overall (%) | |
| E1 | 8.75 | 3.43 | 7.62 | 8.39 | 4.78 | 8.30 | 8.10 | 3.94 | 7.36 |
| E2 | 7.65 | 0.34 | 7.24 | 6.65 | 2.08 | 6.13 | 8.40 | 2.16 | 5.91 |
| E3 | 8.70 | 2.20 | 7.74 | 5.41 | 2.07 | 4.37 | 5.10 | 1.15 | 4.15 |
| 17-OHPreg | 9.56 | 8.44 | 9.33 | 7.77 | 7.85 | 8.32 | 9.82 | 11.51 | 11.53 |
| Ald | 9.24 | 1.06 | 7.38 | 7.70 | 2.52 | 7.34 | 6.99 | 4.83 | 7.07 |
| DHEAS | 4.19 | 0.10 | 3.44 | 4.95 | 1.45 | 3.91 | 4.01 | 0.71 | 3.46 |
Publisher’s Note: MDPI stays neutral with regard to jurisdictional claims in published maps and institutional affiliations. |
© 2022 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Jia, M.; Wu, M.; Li, Y.; Xiong, B.; Wang, L.; Ling, X.; Cheng, W.; Dong, W.-F. Quantitative Method for Liquid Chromatography–Mass Spectrometry Based on Multi-Sliding Window and Noise Estimation. Processes 2022, 10, 1098. https://doi.org/10.3390/pr10061098
Jia M, Wu M, Li Y, Xiong B, Wang L, Ling X, Cheng W, Dong W-F. Quantitative Method for Liquid Chromatography–Mass Spectrometry Based on Multi-Sliding Window and Noise Estimation. Processes. 2022; 10(6):1098. https://doi.org/10.3390/pr10061098
Chicago/Turabian StyleJia, Mingzheng, Meng Wu, Yanjie Li, Baolin Xiong, Lei Wang, Xing Ling, Wenbo Cheng, and Wen-Fei Dong. 2022. "Quantitative Method for Liquid Chromatography–Mass Spectrometry Based on Multi-Sliding Window and Noise Estimation" Processes 10, no. 6: 1098. https://doi.org/10.3390/pr10061098